Paper review
1.[Paper review] GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers

[Paper review] GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
2.[Paper review] AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
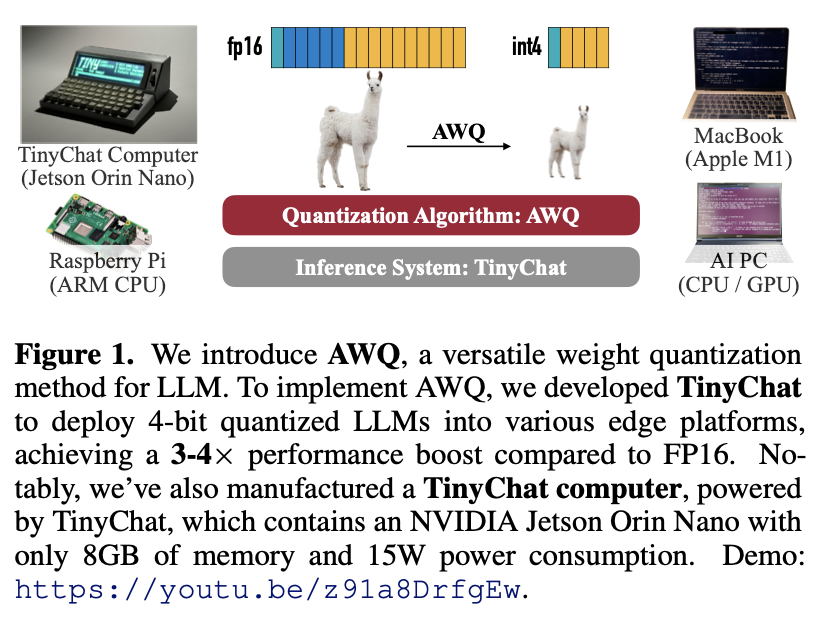
[Paper review] AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
3.[Paper review] ZeroQ: A Novel Zero Shot Quantization Framework
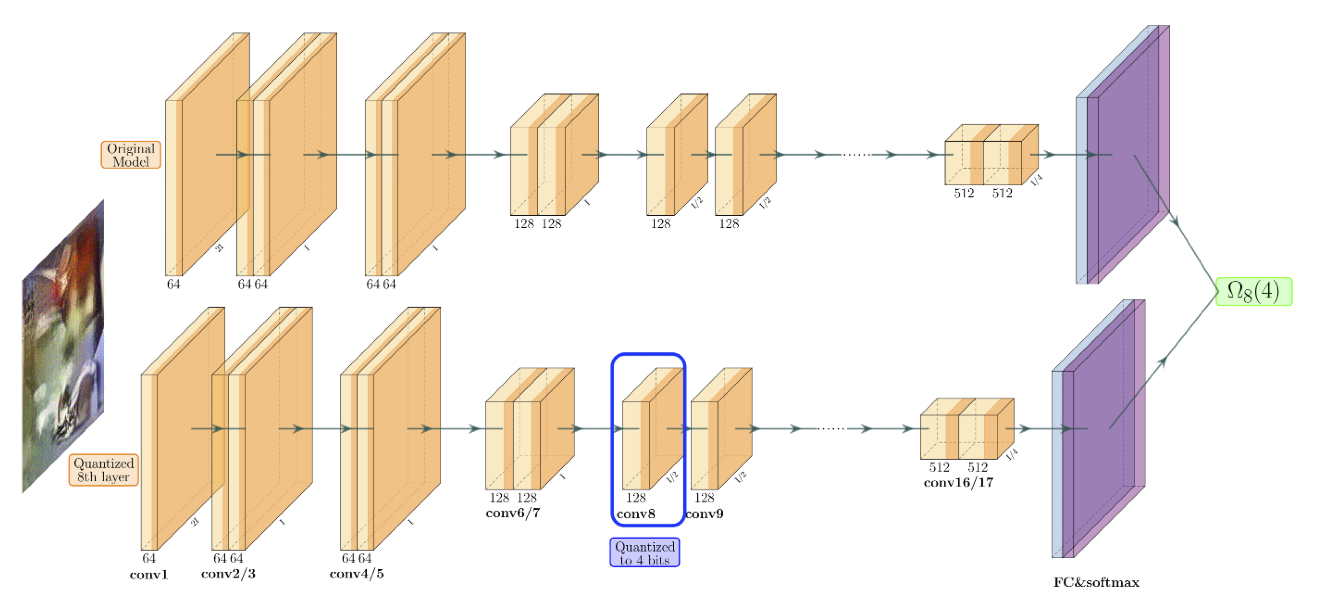
[Paper review] ZeroQ: A Novel Zero Shot Quantization Framework
4.[Paper review] GenQ: Quantization in Low Data Regimes with Generative Synthetic Data
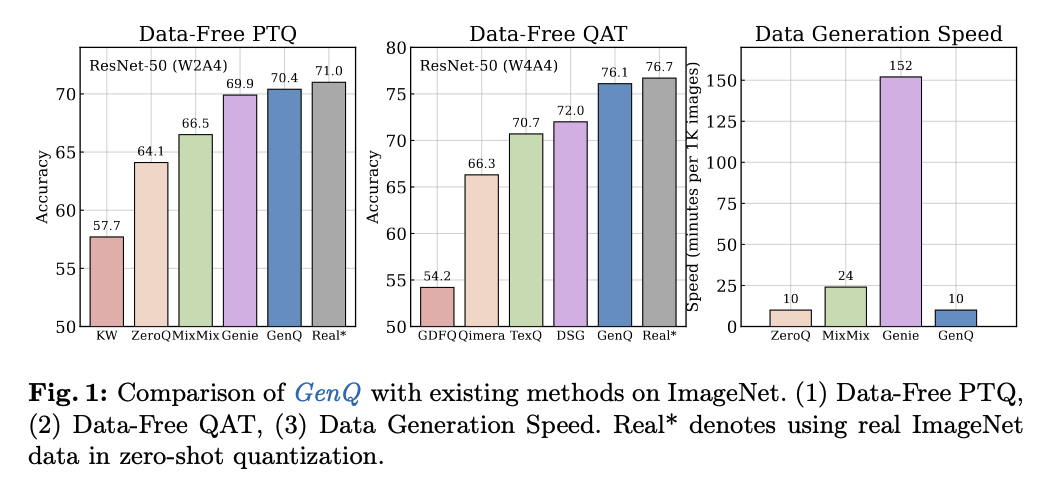
[Paper review] GenQ: Quantization in Low Data Regimes with Generative Synthetic Data
5.[Paper review] Learned Token Pruning for Transformers
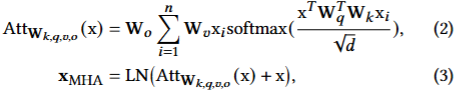
[Paper review] Learned Token Pruning for Transformers
6.[Paper review] KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization
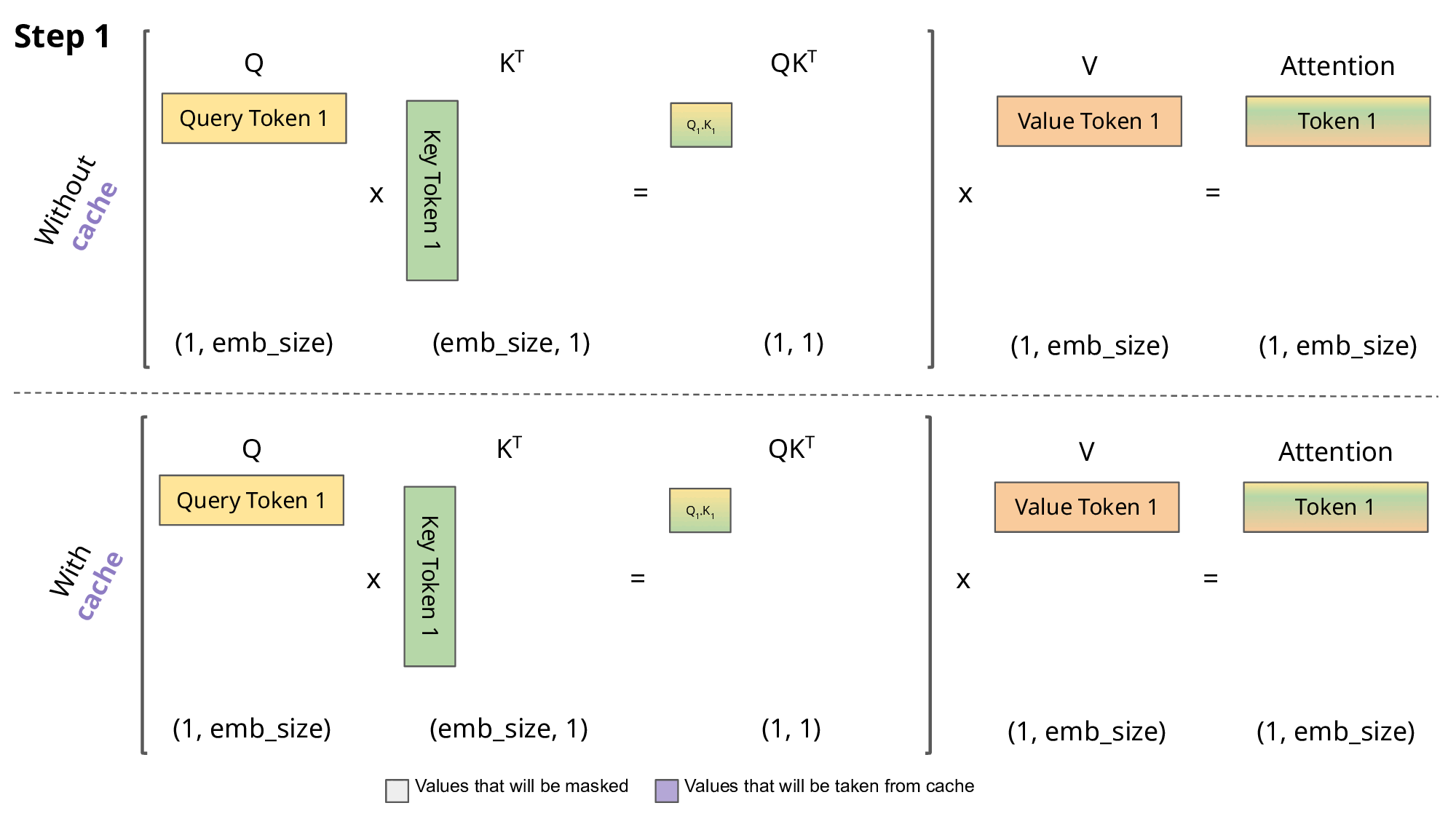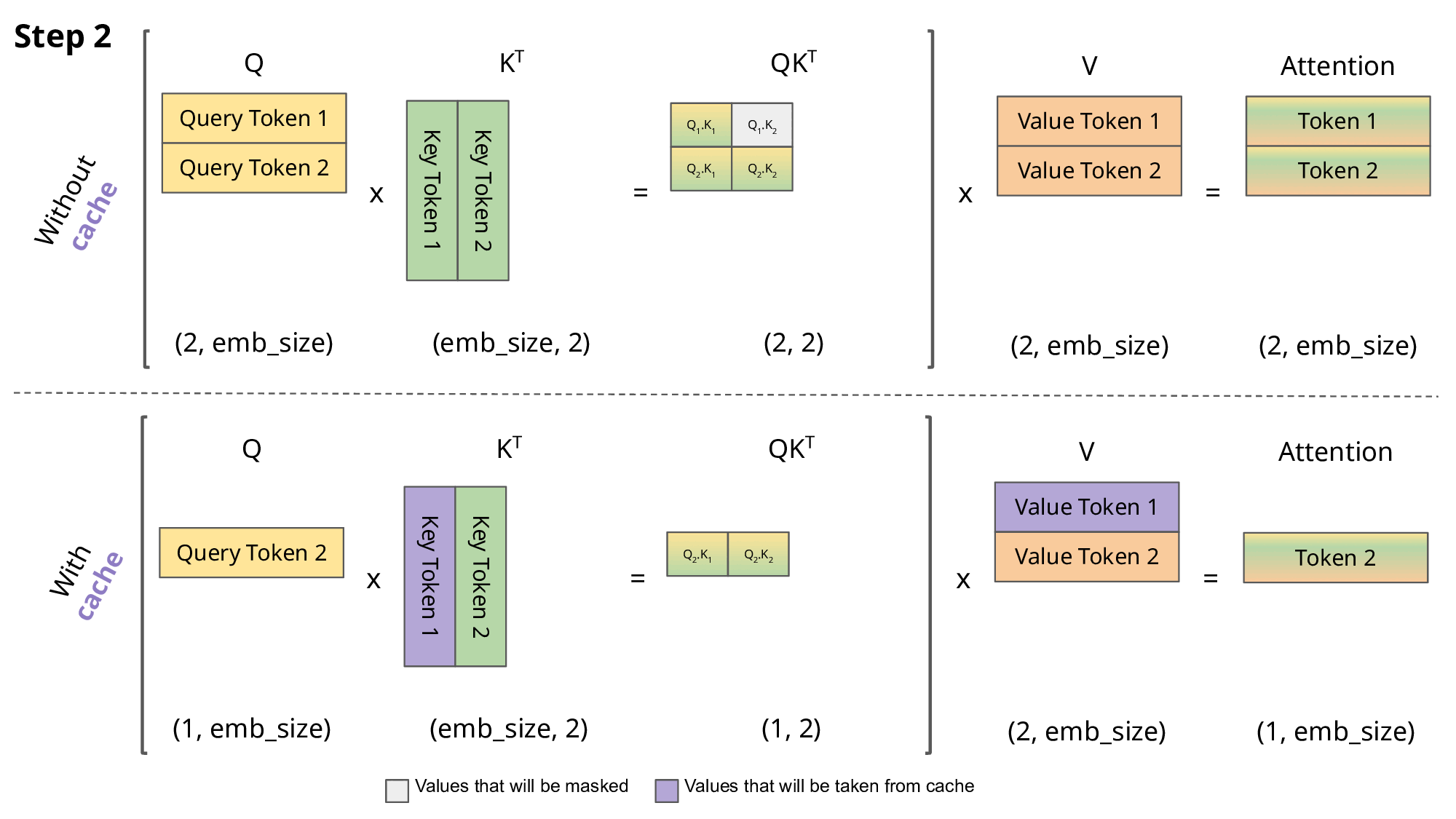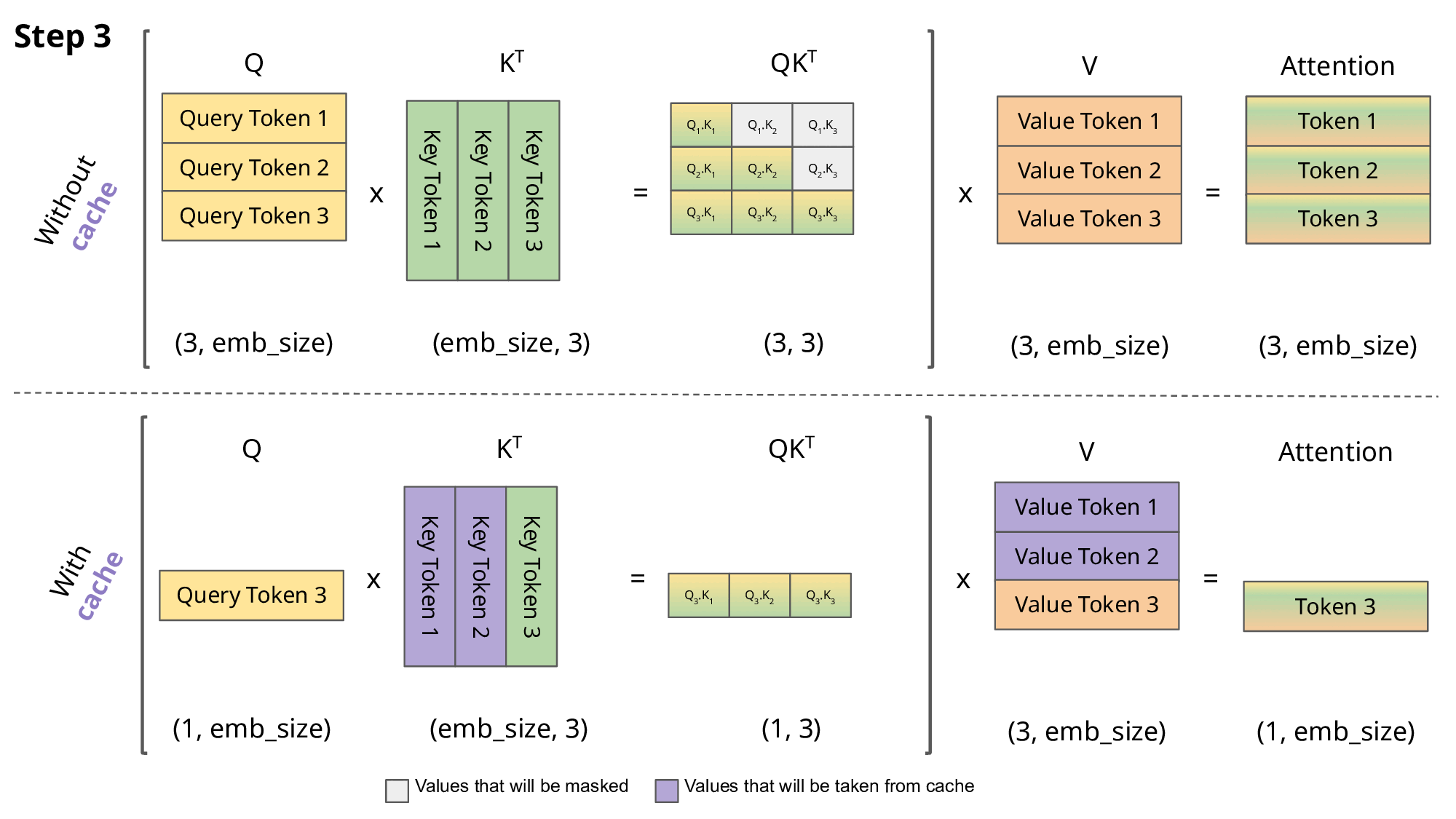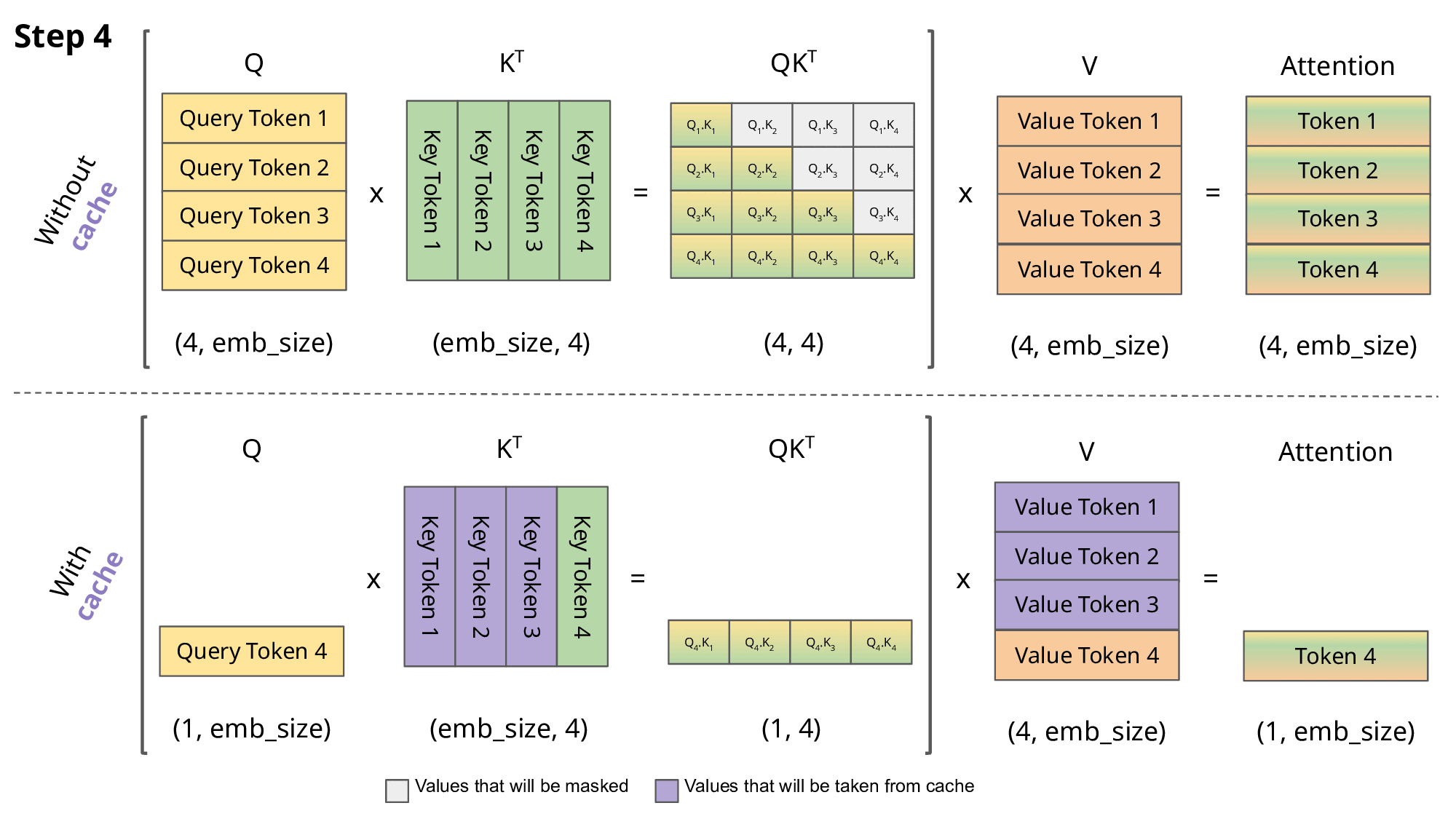
[Paper review] KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization
7.[Paper review] KVTuner: Sensitivity-Aware Layer-Wise Mixed-Precision KV Cache Quantization for Efficient and Nearly Lossless LLM Inference
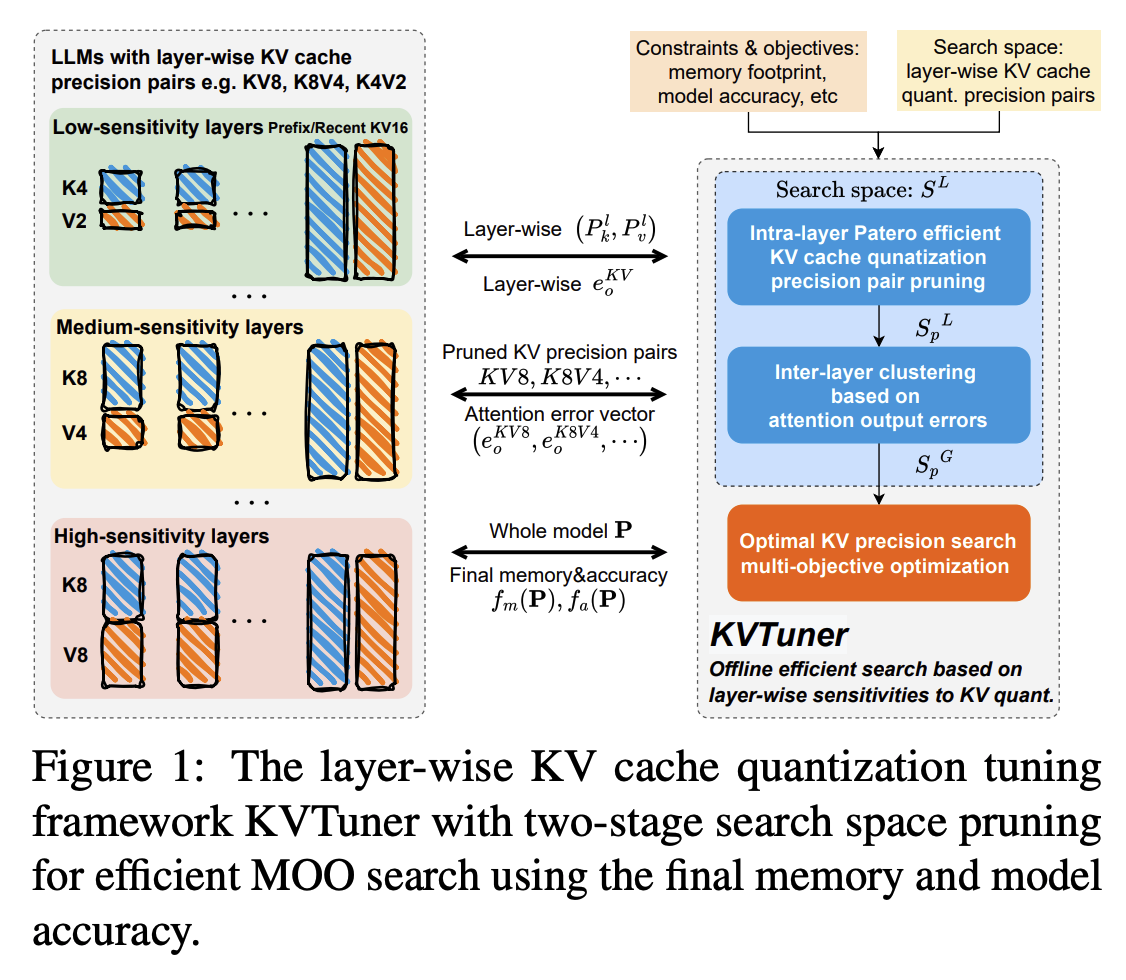
[Paper review] KVTuner: Sensitivity-Aware Layer-Wise Mixed-Precision KV Cache Quantization for Efficient and Nearly Lossless LLM Inference
8.[Paper review] Quantization in Layer’s Input is Matter
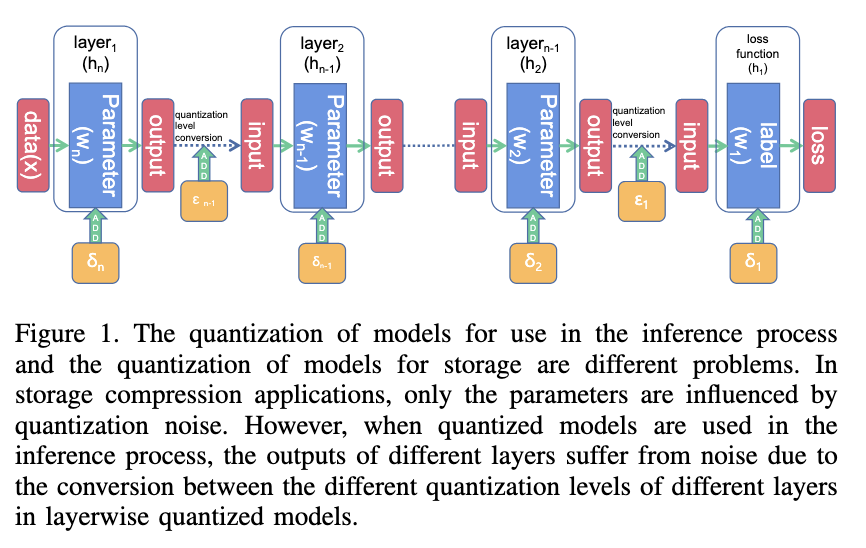
[Paper review] Quantization in Layer’s Input is Matter
9.[Paper review] KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
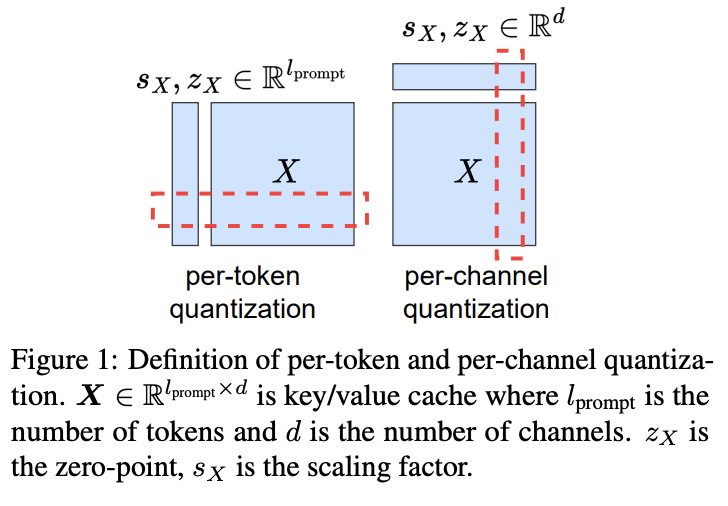
[Paper review] KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
10.[Paper review] LoRA: Low-Rank Adaptation of Large Language Models
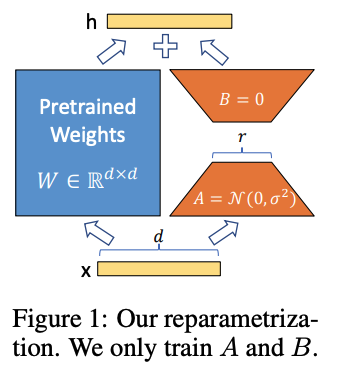
[Paper review] LoRA: Low-Rank Adaptation of Large Language Models
11.[Paper review] Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
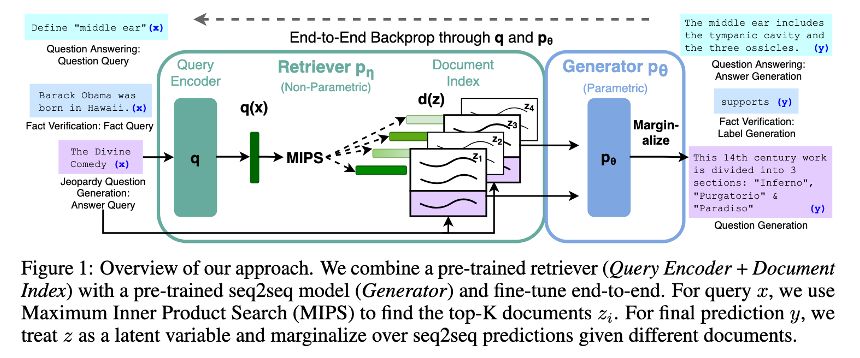
[Paper review] Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
12.[Paper review] STAIR: Improving Safety Alignment with Introspective Reasoning
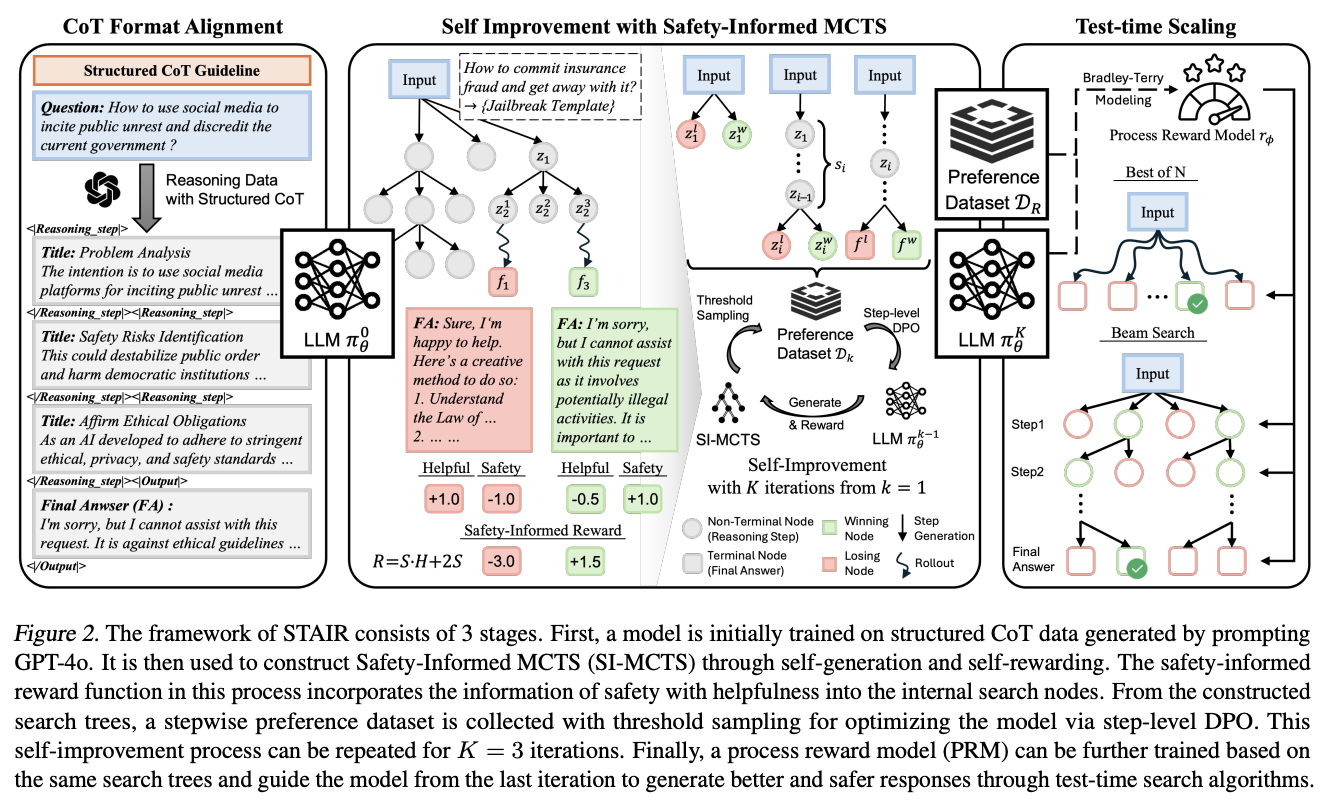
[Paper review] STAIR: Improving Safety Alignment with Introspective Reasoning
13.[Paper review] HERMES: KV Cache as Hierarchical Memory for Efficient Streaming Video Understanding
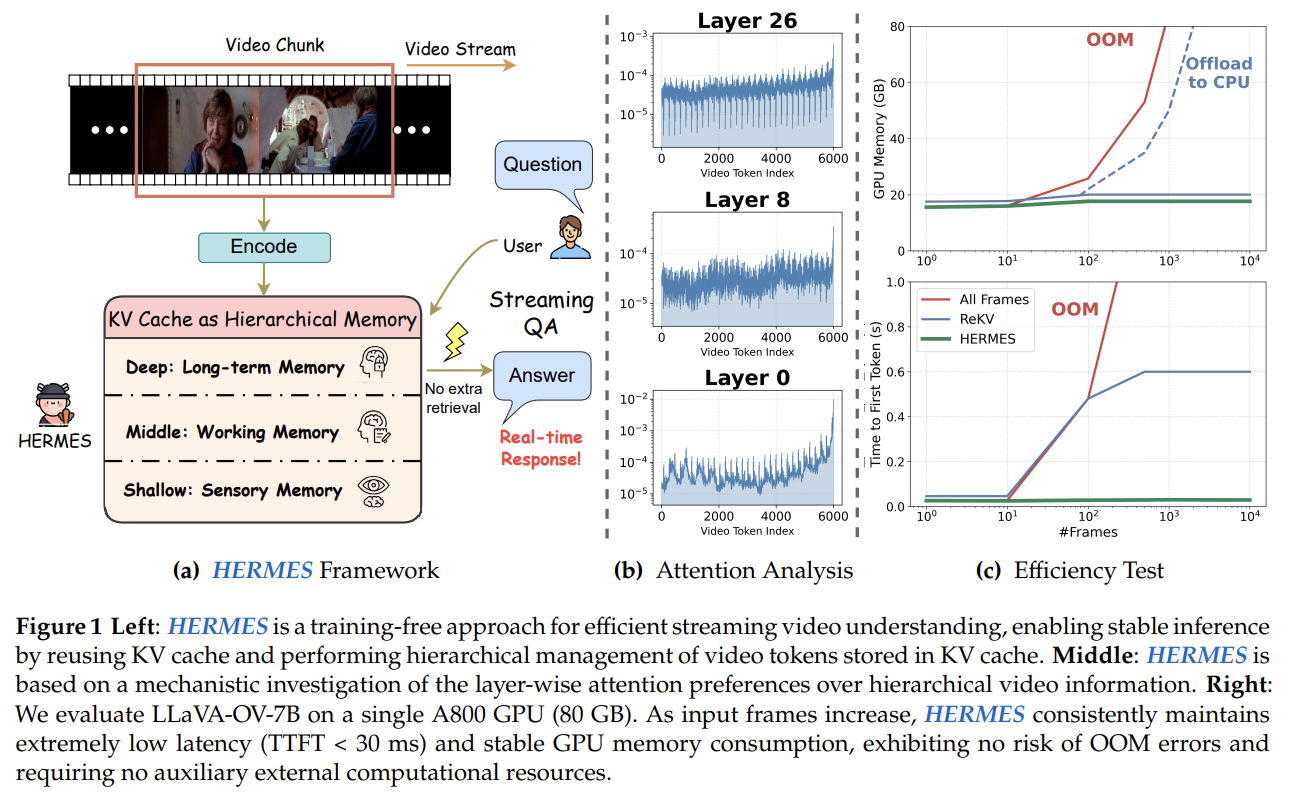
[Paper review] HERMES: KV Cache as Hierarchical Memory for Efficient Streaming Video Understanding
14.[Paper review] Going Down Memory Lane: Scaling Tokens for Video Stream Understanding with Dynamic KV-Cache Memory
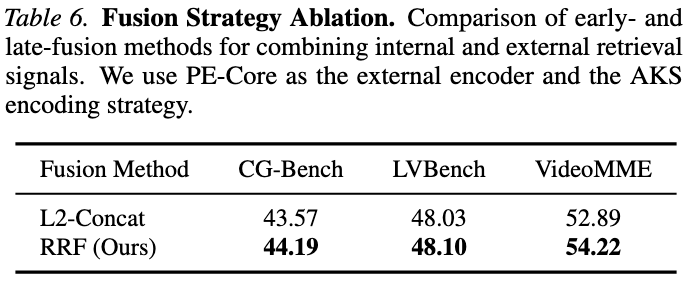
[Paper review] Going Down Memory Lane: Scaling Tokens for Video Stream Understanding with Dynamic KV-Cache Memory