[Paper review] AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
Paper review
- 목적
- 배경
- LLM을 On-device에서 돌리는 것이 왜 중요한가?
- 개인 정보 보호
- 클라우드 비용 절감
- 빠른 속도/ 저지연
- 인터넷 연결 없이 사용 가능
- 거대한 크기를 가진 LLM을 어떻게 On-device에 올릴 수 있을까?
- GPT-3(175B Parameters, 350GB(FP16)) → 모델 크기를 줄여야 함
- LLM을 On-device에서 돌리는 것이 왜 중요한가?
- Quantization 방식
- QAT (Quantization-Aware Training)
- 양자화를 적용해 다시 학습하는 방식 (Fine tuning과 비슷하다고 생각하면 됨)
- 양자화 과정에서 발생하는 오차를 보정하기에 높은 정확도를 가짐
- Dataset 필요, 시간 오래 걸림, GPU 자원 필요 → 느리고 비쌈
- PTQ (Post-Training Quantization)
- 학습이 완료된 모델을 양자화하는 방식
- 추가 학습이 이루어지지 않기에 빠른 시간에 이루어짐, Dataset 불필요 → 빠르고 낮은 비용
- 상대적으로 낮은 정확도를 가짐, low-bit로 양자화할 수록 성능 손실 커짐 (ex. 4bit 이하)
- QAT (Quantization-Aware Training)
- GPTQ와 같은 기존 PTQ 방식은 calibration dataset에 overfit 될 수 있어 OOD(Out-of-Distribution, 학습되지 않은 데이터)에 대해 왜곡시킬 수 있어 일반화 성능이 낮아질 수 있음.
- 제안
- AWQ (Activation-aware Weight Quantization)
- TinyChat
- AWQ를 구현하기 위해 설계한 효율적인 추론 프레임워크
- on-the-fly dequantization (실시간 역양자화)를 통해 Linear Layer의 속도를 올림
- 4-bit weight packing, kernel fusion을 통해 추론 오버헤드(DRAM 접근, 커널 오버헤드) 최소화
-
- 방법
- AWQ: Activation-aware Weight Quantization

-
1%의 Salient Weights를 보존
-
LLM의 성능에 있어서 weight가 동등하게 중요하지 않음
-
0.1~1%의 salient weights가 성능에 큰 영향을 미침 → 양자화 하지 않음 → 손실 줄임
-
salient weights를 찾기 위해 activation 분포를 사용
- weight 분포가 아닌 activation 분포를 사용하는 이유?
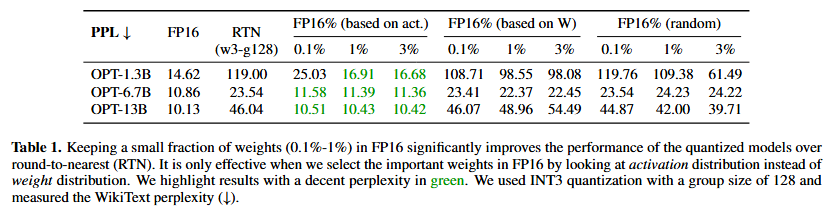
- weight / activation 분포를 기준으로 각각 선별해 FP16으로 유지했을 때 성능 측정 실험
- weight 기준: 성능 향상 거의 없음
- activation 기준: 성능이 매우 크게 향상됨
-
한계점
- 1%의 가중치를 16bit로, 나머지 값은 4bit 등으로 섞여있는 Mixed Precision (혼합 정밀도) 형태
- 이는 시스템 구현을 어렵게 함
- FP16으로 가중치를 남기는 것과 동일한 효과를 내지만 모든 가중치를 4bit로 통일하는 방법 필요
-
-
Activation-aware Scaling을 통해 Salient Weights 보존
-
양자화 오차를 줄이기 위해 Salient weights를 양자화 하기 전 크게 만들고, 양자화 후 작게 만듦
-
양자화 오차 분석
-
기존 양자화 방법
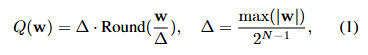
-
AWQ의 양자화 방법

-
양자화 오차

-
스케일링을 적용 했을 때 오차가 배 됨 (s>1일때)
-
-
스케일링의 효과 증명
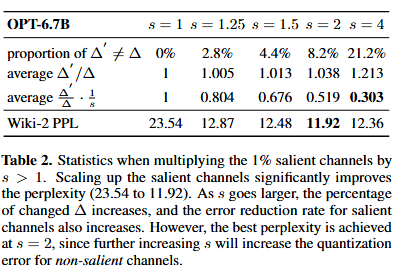
- s=2 일때 최적의 성능(PPL)
- 왜 s가 더 클 때 성능이 안좋아지나?
- non-salient channels의 오차가 커져 성능 손실이 일어남
- → Salient weight와 non-Salient weight 모두를 고려한 스케일링 값(s) 찾아야 함
-
최적의 스케일링 값 탐색
-
양자화 했을 때 원본과 차이가 가장 적은 s 값을 찾는 최적화 수식
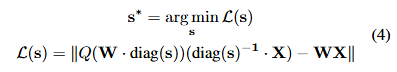
- : weight를 스케일링 후 양자화
- : activation을 역으로 스케일링
- : 양자화 하기 전
- 하지만, 양자화 함수는 미분 불가능하기에 역전파 방식으로 최적화할 수 없음
- ⇒ 탐색 공간을 정의하여 해결
-
탐색 공간 정의

- : 채널별 평균 활성화 크기
- : salient & non-salient channel의 균형을 맞추는 하이퍼파라미터
- 과정
- 소량의 calibration dataset을 모델에 넣어 를 구함
- [0, 1] 사이의 값의 후보를 돌면서 최적의 값 구함 (0, 0.05, 0.1, …, 1/ 간격: 20)
- → 이 되어 스케일링 하지 않는 것과 동일 (non-salient 가중치에 중점)
- → 이 되어 강한 스케일링을 함 (salient 가중치에 중점)
-
-
- TinyChat
- W4A16 양자화를 통해 모델 크기를 로 줄였다고 해서 속도가 4배 빨라지는 것이 아님
- 4bit 정수 weight와 16bit 실수 activation을 곱해야하기 때문
- 하드웨어는 형식이 다른 두 데이터 간의 곱셈을 지원하지 않기에 계산 직전에 4bit 정수를 16bit 실수로 변환하는 실시간 역양자화(on-the-fly dequantization) 필요
- 이 실시간 역양자화를 비효율적으로 구현시 속도 향상 효과가 사라짐
- TinyChat은 실시간 역양자화를 효율적으로 수행하기 위해 설계된 시스템
- 왜 AWQ가 On-device LLM을 가속하는데 도움이 되는가?
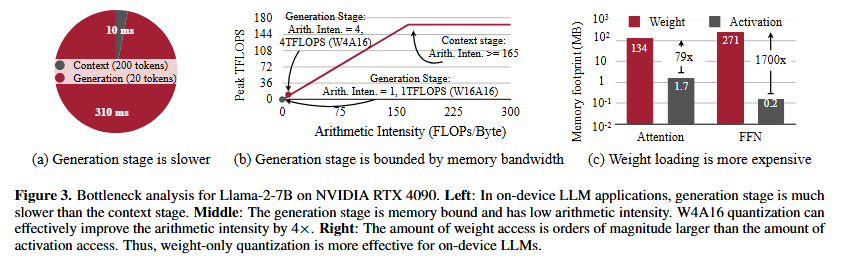
- 생성 단계에서의 병목
- LLM의 추론
- 처음 입력된 프롬프트를 처리하는 문맥 단계 (Context)
- 답변을 만들어내는 생성 단계 (Generation)
- 위 두 단계 중 생성 단계에서 병목이 발생함
- LLM의 추론
- 병목의 원인은 메모리
- 생성 단계에서 병목이 발생하는 이유: 거대한 모델 전체의 가중치를 메모리에서 읽어와야 함
- GPU의 계산 속도 > 메모리의 데이터 읽기 및 전송 속도
- 메모리에서 데이터를 읽어올 때 병목이 발생함
- 메모리 트래픽의 주 원인은 가중치
- 데이터의 99%는 Weight이고 Activation은 극히 일부
- Activation을 양자화 하는 것은 큰 영향이 없음
- 가장 큰 원인인 Weight를 집중해 양자화 하는 것이 가장 효율적
- 생성 단계에서의 병목
- TinyChat에서 위 문제들을 해결하면서 속도를 높인 방법
- 실시간 가중치 역양자화 (On-the-fly weight dequantization)
- 4bit int→ 16bit float로 변환된 가중치를 DRAM에 저장하지 않음
- 역양자화 과정과 행렬 곱셈 과정을 하나의 연산처럼 융합
- 메모리 접근 생략하여 속도 향상
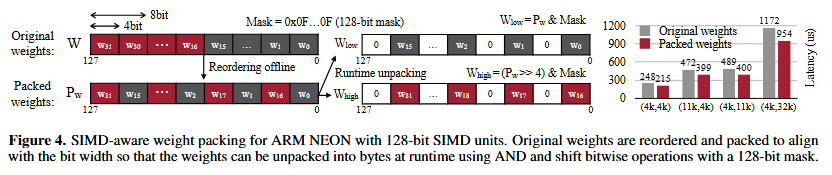
- SIMD 인식 가중치 패킹 (SIMD-aware weight packing)
-
실시간 가중치 역양자화는 메모리 접근을 줄이지만 아직 비싸다.
-
변환 과정에서 여러 연산을 수행하는데 한번에 하나의 4bit 가중치만 연산함.
-
최신 CPU는 SIMD (Single Instruction, Multiple Data, 한번에 여러 개의 데이터 처리) 기능 가지고 있음
-
모델의 데이터를 저장할 때 SIMD로 처리하기 좋은 순서로 데이터를 저장
-
w0, w1, w2 …(기존 순서) → w0, w16, w1, w17 …
-
SIMD에 맞는 순서로 저장하여 역양자화 속도 향상
-
- 커널 퓨전 (Kernel fusion)
- 여러 연산을 각각 호출시 호출하는 과정에서 오버헤드가 발생할 수 있음
- Layer normalization을 위해서 곱셈, 나눗셈, 제곱근 취하는 연산들을 하나의 커널로 융합
- Attention Layer를 위해서 QKV projection, Positional Embedding Calculation 등 융합
- 여러 개의 함수(커널)을 하나의 커널로 합쳐 속도 향상
- 실시간 가중치 역양자화 (On-the-fly weight dequantization)
- W4A16 양자화를 통해 모델 크기를 로 줄였다고 해서 속도가 4배 빨라지는 것이 아님
-
실험
-
성능 평가
-
기본 언어 모델
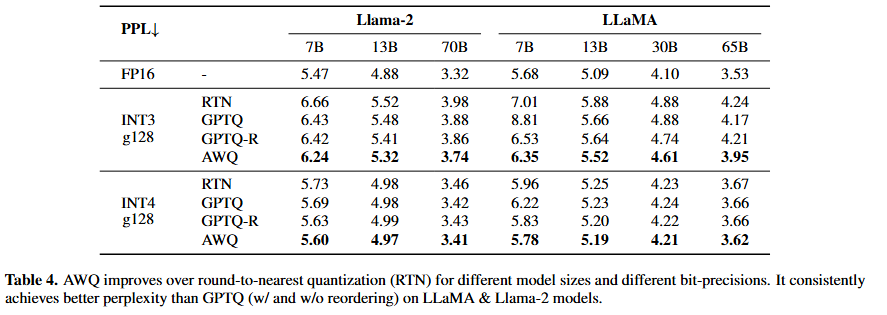
-
GQA, MOE 모델
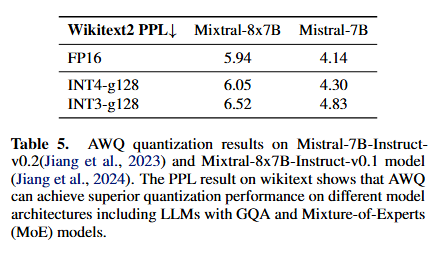
-
대화형 모델 (GPT-4를 이용해 답변 평가)

-
Multi-modal language model
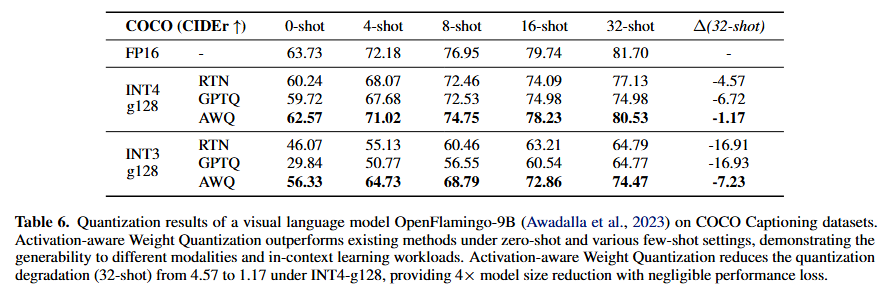
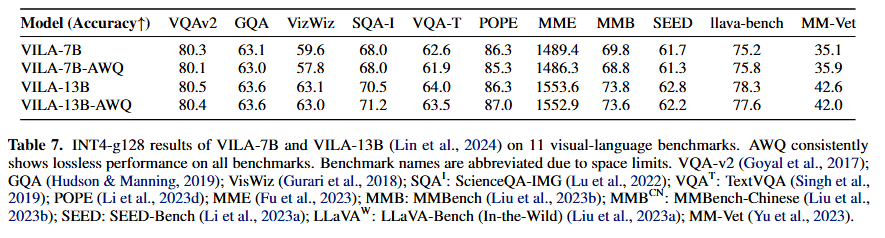

-
코딩, 수학 문제 풀이 데이터셋에서의 추론 능력 평가
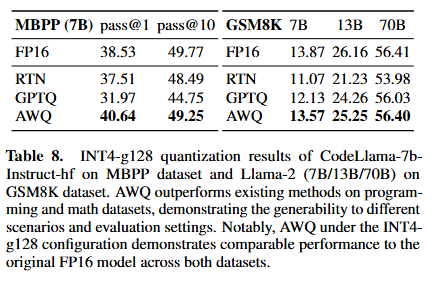
-
Extreme Low-bit Quantization (INT2)
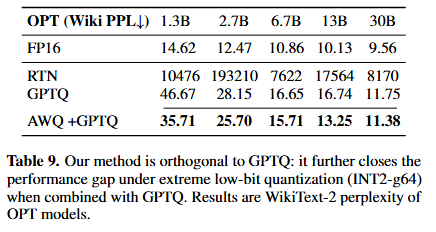
-
-
데이터 효율성 및 일반화 성능 평가
- 적은 calibration set (a), robust (b)

- 적은 calibration set (a), robust (b)
-
속도 향상 평가

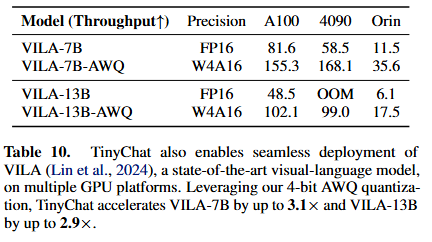

-
- 결과
- 모든 분야(기본 언어 모델, 대화, 코딩, 수학)에서 양자화 적용했을 때 최고의 성능 보임
- 훨씬 적은 calibration 데이터로 양자화가 가능하고, 과적합 문제가 없음
- TinyChat을 통해 AWQ의 이론적인 메모리 절감 효과를 실제 환경(데스크톱 및 모바일 GPU)에서도 이루어냄 (속도 3.2~3.3배 향상)
- 위 모든 과정을 통해 LLM이 On-device에 올라갈 수 있도록 대중화함
