- 배경
- KV 캐시는 배치 사이즈와 컨택스트 길이가 증가함에 따라 메모리 병목의 새로운 요인이 됨
- ex) Batch size: 512, Context length: 2048일때 KV Cache: 3TB (540B 모델 파라미터의 3배 크기)
- 메모리 병목이 발생하면 연산 코어가 IDLE 상태가 되기에 추론 속도가 제한되는 문제가 발생함
- 기존 연구들은 2비트 양자화의 경우 정확도가 급격히 하락하고, KV 이상치 분포에 대한 이해가 부족했다 지적
- 제안 방법
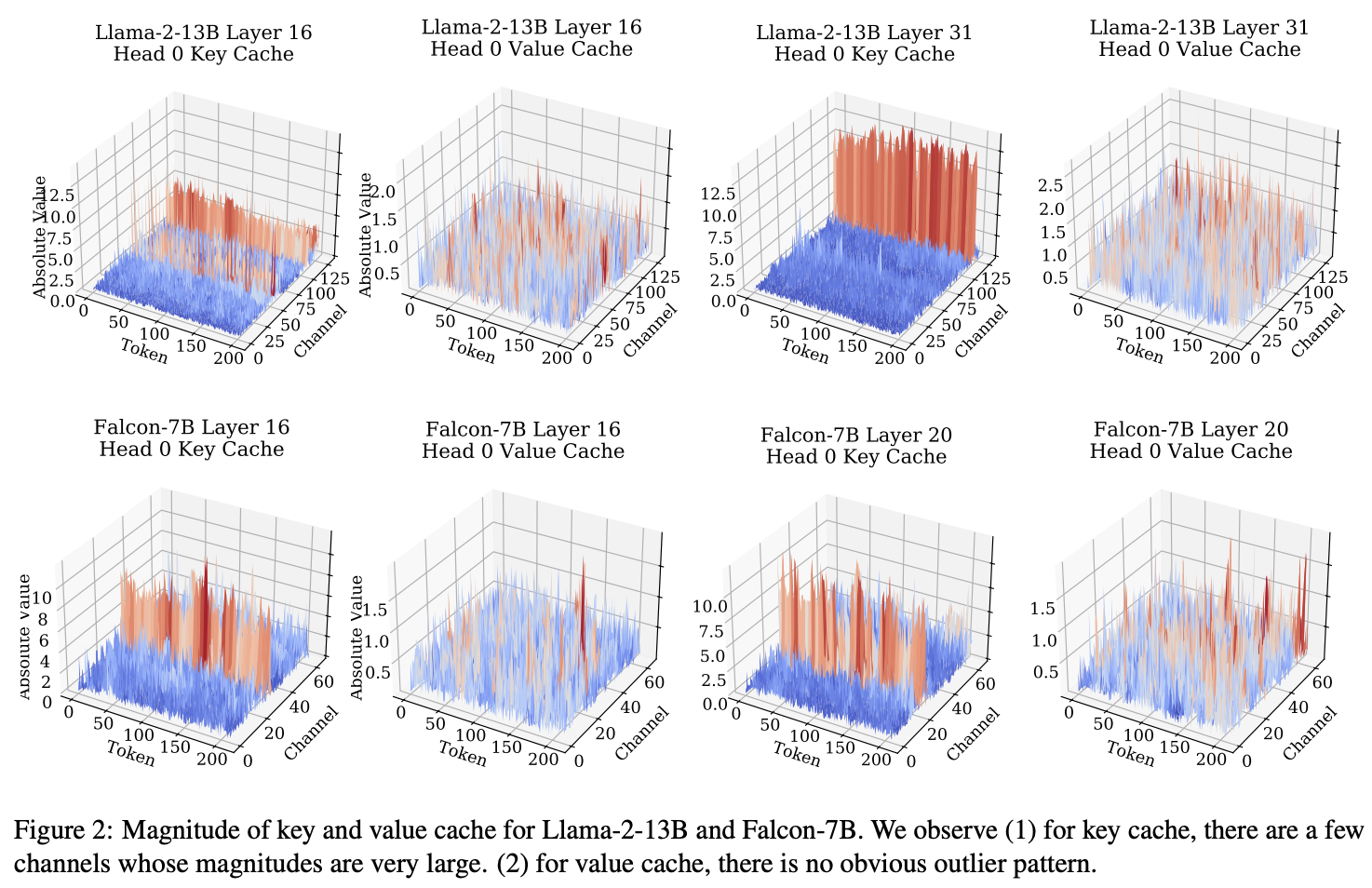
- Key, Value의 이상치 분포에 대한 분석을 바탕으로 Key는 채널별(per-channel), Value는 토큰별(per-token) 양자화 방법 제안
- Per-token VS Per-channel quantization 비교
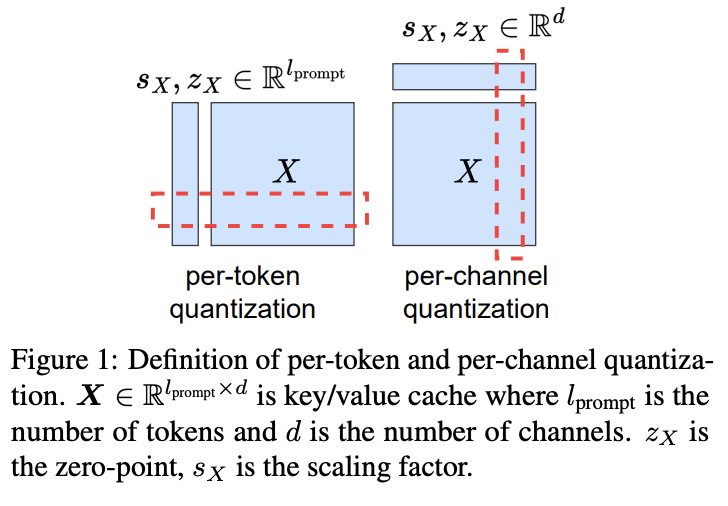
- Per-token quantization (토큰별 양자화)
- 각 토큰 내의 모든 채널을 동일한 스케일로 양자화
- 스트리밍(실시간) 추론 환경에 적합
- 이미 존재하는 양자화된 Value Cache 뒤에 바로 양자화된 텐서를 붙이면 됨
- +) 이상치 값이 양자화에 어떤 악영향을 주는지?
- 양자화는 데이터의 최솟값(min)과 최댓값(max)을 기준으로 스케일링 팩터 S를 결정
- Per-channel quantization
- 각 채널 내의 모든 토큰을 동일한 스케일로 양자화
- 특정 채널에 분포되어있는 이상치 값 처리에 유리함
- 스트리밍(실시간) 추론 환경에 적합하지 않음
- 여러 토큰의 값이 필요 (여러 토큰을 모아서 한번에 처리해아함)
- ⇒ 이제 이 부분을 어떻게 처리할 것인지가 이 논문의 주요 방법 중 하나
- 이 과정에서 이상치 값이 있다면 최댓값과 최솟값 사이의 범위가 매우 커짐
- 2bit, 4bit와 같이 제한된 비트 내에서는 표현할 수 있는 단계가 한정되어있음 → 범위가 넓어지면 각 단계 사이의 간격이 벌어지게 됨 → 대다수를 차지하는 일반적인 값들이 정밀하게 표현되지 못하고 하나의 값으로 뭉개지는 현상 발생 → 정확도 손실
- 방법
-
Asymmetric Quantization (비대칭 양자화)
-
Key Cache: Per-channel quantization
- 특정 채널에 이상치가 존재하므로 채널별로 양자화해 값의 범위를 줄임
-
Value Cache: Per-token quantization
- 뚜렷한 이상치가 존재하지 않고, 어텐션 스코어의 sparsity로 인해 특정 토큰의 중요도가 높으므로 토큰별로 양자화
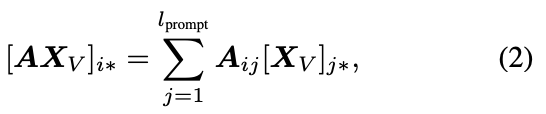
- 어텐션 출력은 각 토큰의 value 값을 어텐션 스코어로 가중 합산한 결과 → 어텐션 스코어가 Sparse 함 → 일부 중요한 토큰들의 Value 값에 의해 결정됨
- 뚜렷한 이상치가 존재하지 않고, 어텐션 스코어의 sparsity로 인해 특정 토큰의 중요도가 높으므로 토큰별로 양자화
-
-
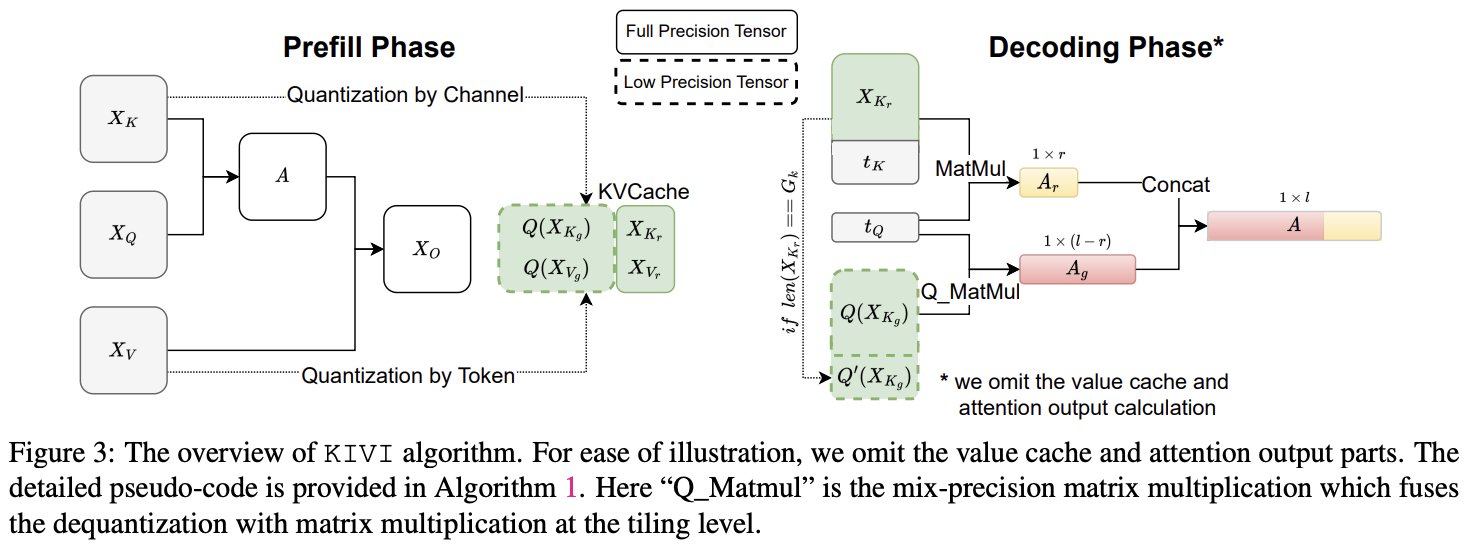
Grouped & Residual Cache
- 채널별 양자화는 여러 토큰의 값이 필요하므로 스트리밍 환경에서 바로 적용하기 어려움
- 이를 해결하기 위해 최신 R개의 토큰은 Residual Cache로서 Full-precision으로 유지하고, 일정 개수 G개가 모이면 그룹 단위로 양자화하여 저장
- 최신 토큰들을 고정밀도로 유지함으로써 수학적 추론과 같은 어려운 태스크에서의 정확도를 보존 (Sliding Window 효과)
-
overview
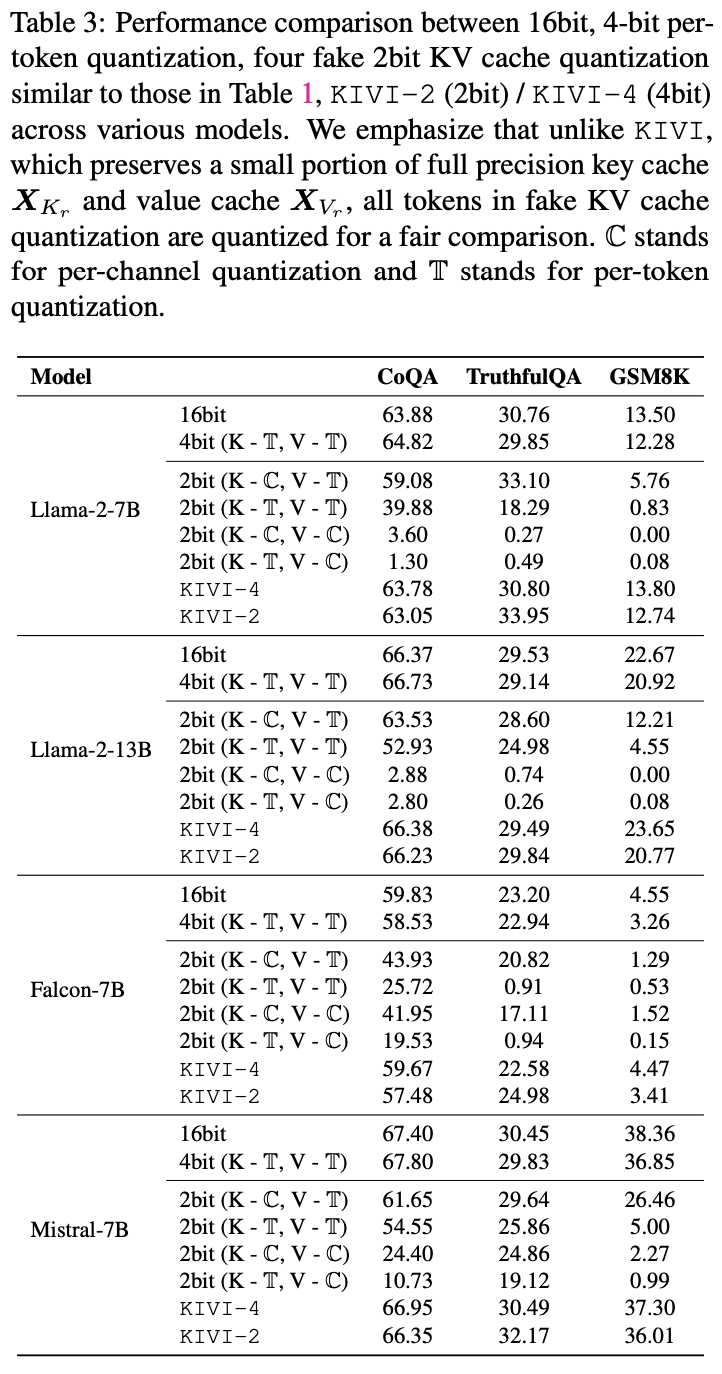
- 실험 결과
- 기본 성능 평가
- Key를 채널별, Value를 토큰별 양자화하는 KIVI 방식이 가장 효과적임을 입증
- Falcon-7B의 경우 multi-query attention이 적용되어있고, 한개의 헤드만 가짐 (다른 모델에 비해 이미 압축되어있다고 생각할 수 있음) → KIVI-2bit 양자화 시 성능 손실이 큼
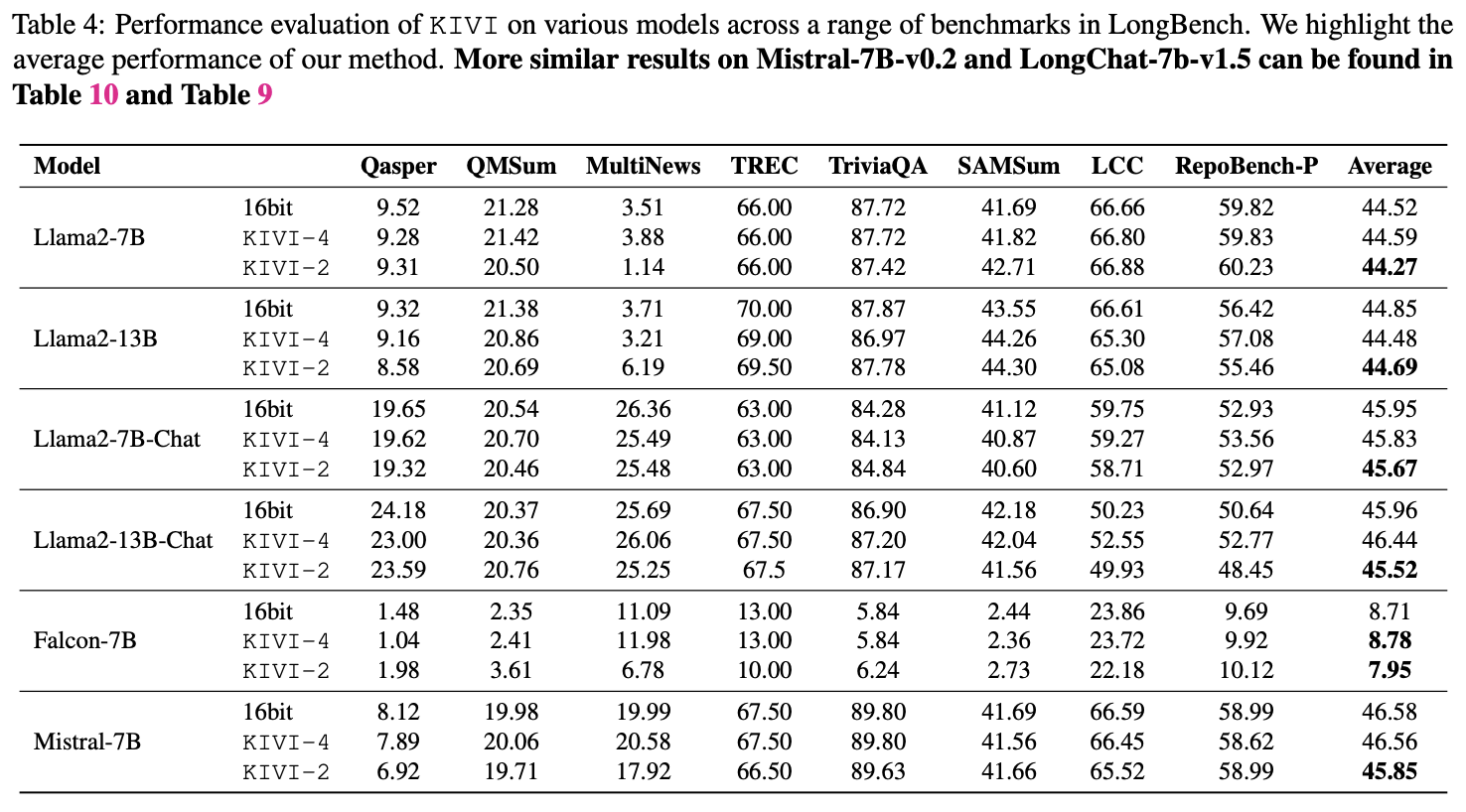
- 장거리 문맥 태스크 성능 평가
-
원본 모델 대비 2bit 양자화에도 불구하고 비슷한 성능을 유지함
-
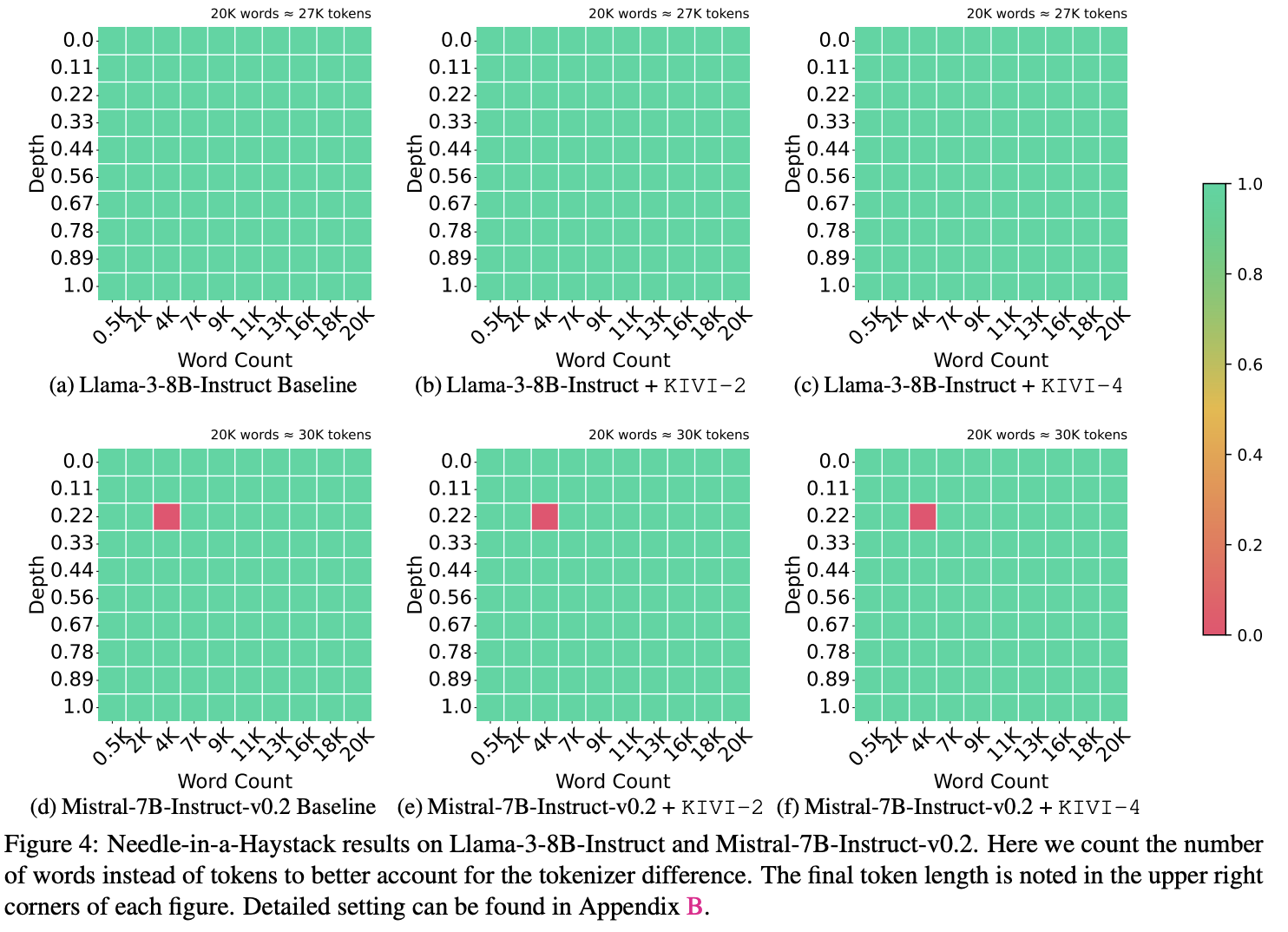
- Needle-in-a-Haystack (사막에서 바늘 찾기 - 수많은 토큰들 중 원하는 정보 찾는 능력 평가)
-
원본 모델과 비교해서 성능이 떨어지지 않음
-
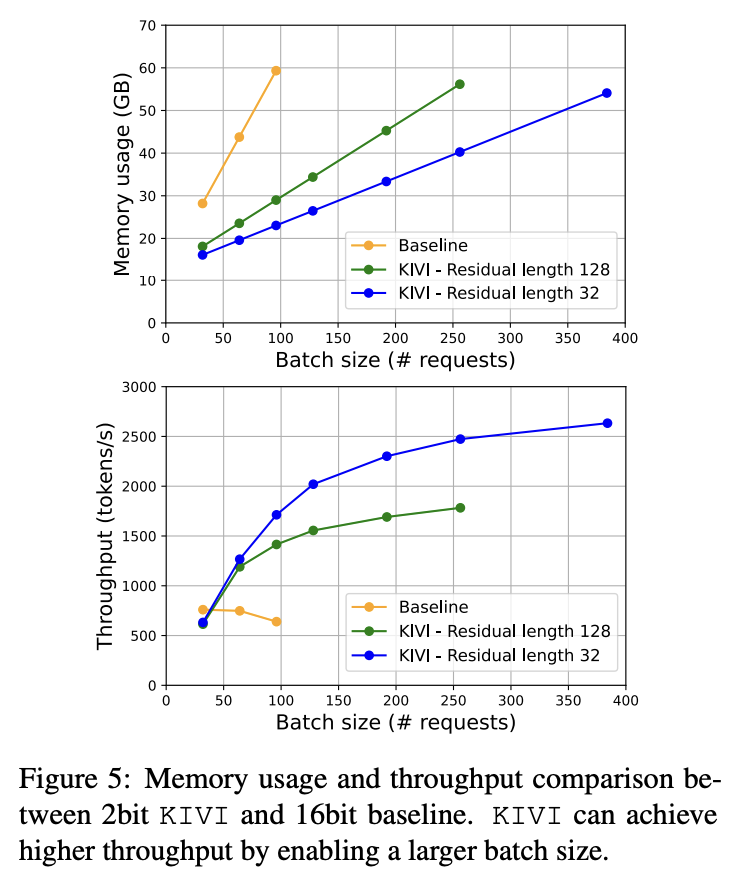
- 메모리 사용량 및 처리량
-
최대 4배 더 큰 배치 사이즈 처리 가능
-
배치 사이즈가 커짐에 따라 초당 토큰 처리량 2~3배 향상
-
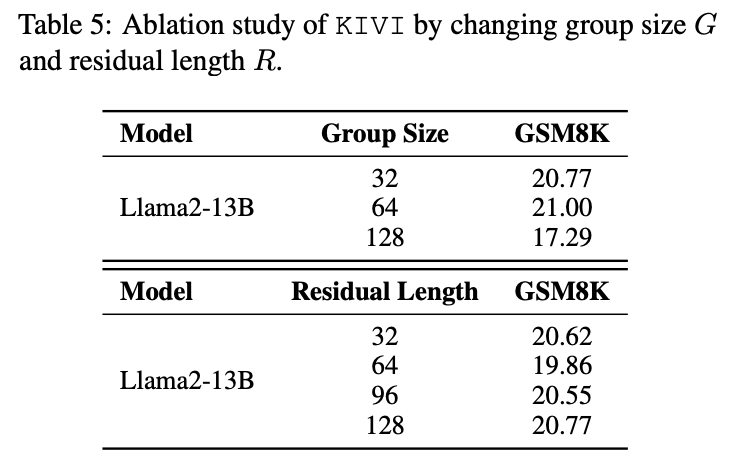
- 하이퍼파라미터 (그룹 사이즈 G & residual 길이 R)
-
G: 32~64정도에서 안정적인 성능
-
R: 너무 작아지면 성능이 떨어질 수 있음
-
- 결론
- LLM 추론 시 배치 사이즈와 문맥 길이가 길어짐에 따라 KV 캐시가 메모리 및 속도의 새로운 병목이 되고, 기존 KV 캐시를 2bit로 양자화하는 방법은 심각한 정확도 저하를 유발함
- Key 캐시는 채널별로 이상치가 분포되어 있기에 채널별로, Value 캐시는 어텐션 희소성을 활용한 토큰별로 양자화하는 Asymmetric quantization 방식과 채널별 양자화를 적용하기 위해 최신 토큰을 원본 정밀도로 유지하는 Residual Group 기법을 담은 KIVI 방법을 제안
- Llama-2 등 주요 모델에서 정확도 하락을 2% 이내로 유지하면서 KV 캐시 메모리를 약 2~3배 절감하였고, 이를 통해 배치 사이즈를 키워(약 4배) 최대 약 3배의 토큰 처리량 향상을 달성

브라우니맛있디