- 배경
- NLP 분야에서 일반(범용) 도메인 데이터를 이용해 대규모 모델을 사전 학습하고, 이를 특정 태스크/도메인에 맞게 적응(Adaptation)시키는 방식이 중요한 흐름으로 작용하고 있음
- 다만, 사전학습하는 모델의 크기가 커짐에 따라 전체 파라미터를 재학습하는 Full fine-tuning이 불가능해짐 (학습 비용, 시간 등의 문제)
- 이를 해결하기 위해 Adapter, Prompt Tuning 등의 적은 수의 파라미터만을 이용해 효율적으로 학습하려는 기법들이 등장했지만(PEFT) 추론 지연, 입력 길이 제한 등의 한계점을 가졌음
- 제안
- 사전학습된 모델의 가중치는 유지(Freeze)하고, 학습가능한 저랭크 분해 행렬을 트랜스포머의 각 레이어에 삽입하여 학습하는 LoRA(Low-Rank Adaptation) 제안
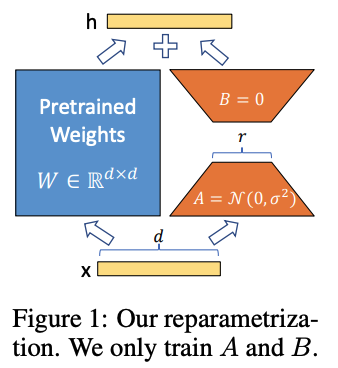
- 사전학습된 모델의 가중치는 유지(Freeze)하고, 학습가능한 저랭크 분해 행렬을 트랜스포머의 각 레이어에 삽입하여 학습하는 LoRA(Low-Rank Adaptation) 제안
- 핵심 아이디어
-
거대 언어 모델이 새로운 태스크/도메인에 대한 적응 과정에서 가중치의 변화량()은 낮은 내재적 랭크(Low intrinsic rank)를 가진다
- 모델은 매우 많은 파라미터를 가지지만, 특정 태스크를 수행하기 위해 적응하는 과정에서 변해야하는 차원의 수는 극히 일부라는 것
- Rank란?
- 행렬을 구성하는 행 또는 열 벡터 중 서로 독립적인 벡터의 최대 개수
- ⇒ 행렬이 정보를 얼마나 담고있는지를 나타냄
- ex) 행렬이 아무리 크더라도 모두 같은 벡터로 이루어져 있다면 rank는 1
- Low rank의 의미
- 소수의 행렬이 핵심 정보/패턴을 가지고 있다
- ex) 100만 픽셀의 사진 가 있지만, 해당 사진의 색이 단 3가지인 경우 ()
-
해당 가설이 등장한 배경
- Measuring the Intrinsic Dimension of Objective Landscapes (ICLR 2018)
- 딥러닝 모델의 파라미터 공간은 매우 고차원이지만, 실제로 손실 함수가 최소화되는 지점은 훨씬 낮은 차원의 부분 공간에서도 찾을 수 있음을 증명
- 실험
- Fully Connected 모델(784–200–200–10), MNIST, 약 20만개의 파라미터
- 약 750개의 차원(파라미터)만을 학습해 원본 모델의 90%의 성능을 달성
- 약 20만개의 파라미터를 직접 학습시키는 것보다 훨씬 적은 수의 차원을 랜덤한 행렬을 이용해 고차원으로 투영하여 학습시킴
- Fully Connected 모델(784–200–200–10), MNIST, 약 20만개의 파라미터
- 모델이 과잉 매개변수화되어 있더라도, 학습에 필요한 내재적 차원은 작다는 것을 의미
- Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning (ACL 2021)
- 앞선 연구를 Pretrained Language Model의 파인튜닝 영역으로 확장
- (앞선 연구는 Train from Scratch에서의 실험 및 증명)
- 실험
- RoBERTa-Base/Large 모델, GLUE, 약 1.25억/ 3.55억개의 파라미터
- RoBERTa-Base/Large 파라미터 계산 수식
-
Embeddings:
-
Word: Vocab size(V) * Hidden size(H)
-
Position: Max sequence length(S) * H
-
Token Type: 1 * H
-
LayerNorm: 2* H (Weight + Bias)
-
-
Encoder Layers (L개 만큼 반복) :
-
Self Attention:
-
Weight: 4 (H H) (Q, K, V, O 각각 H*H)
-
Bias: 4 * H
-
LayerNorm: 2* H
-
-
Feed Forward Network:
-
(구조: H → 4H → H)
-
Intermediate: H * 4H + 4H (Weight + Bias)
-
Output: 4H * H + H (Weight + Bias)
-
LayerNorm: 2* H
-
-
RoBERTa-Base
-
Layer: 12, Hidden size: 768 (d=768), Vocab size: 50265
-
Embeddings: 약 39M
-
Encoder Layers: 약 85M
-
전체: 약
-
-
RoBERTa-Large
-
Layer: 24, Hidden size: 1024 (d=1024), Vocab size: 50265
-
Embeddings: 약 52M
-
Encoder Layers: 약 302M
-
전체: 약
-
-
- RoBERTa-Base/Large 파라미터 계산 수식
- RoBERTa-Base: 약 900~2,000개의 차원만 학습하여 Full Fine-tuning 성능의 90% 달성
- RoBERTa-Large: 약 200~500개의 차원만 학습하여 Full Fine-tuning 성능의 90% 달성
- ⇒ 모델의 크기가 커질수록 오히려 필요한 Intrinsic Dimension의 수는 줄어듦
- RoBERTa-Base/Large 모델, GLUE, 약 1.25억/ 3.55억개의 파라미터
- 모델이 거대할수록 파인튜닝 시 변화해야하는 내재적 차원이 더 적다라는 것을 의미
- 학습 시 랜덤한 행렬을 이용해 고차원으로 투영하였는데, 적응 과정(Fine tuning)에서 투영하는 랜덤한 행렬을 학습한다면 더 낮은 차원(low rank)으로 가능하지 않을까? 란 아이디어가 된 것 같음
- 앞선 연구를 Pretrained Language Model의 파인튜닝 영역으로 확장
- Measuring the Intrinsic Dimension of Objective Landscapes (ICLR 2018)
- 선행 연구 및 한계점
-
Adapter Layers
-
트랜스포머 블록 사이에 파라미터 수가 적은 별도의 레이어(Adapter)를 삽입해 학습하는 방식
-
한계점: 추론 지연
-
파라미터의 수는 적지만 모델의 depth를 증가 시킴
-
Adapter는 순차적으로 처리되어야해 병목 현상이 발생

- 배치 크기에 따라 다르긴 하지만 추론 속도 지연이 발생함을 보이는 실험
- 그에 비해 LoRA는 파인 튜닝과 동일한 속도(추론 지연이 발생하지 않음)
- 왜 병목이 발생하는 가?
- Adapter
- Self-Attention 통과 [Adapter 1] 통과 Add & Norm Feed Forward(MLP) 통과 [Adapter 2] 통과 Add & Norm
- 추가적인 Layer가 직렬적으로 추가됨으로 인해 해당 층을 통과하면서 지연 발생
- LoRA
- (학습 시) Self-Attention 수행(Left) & LoRA()수행 → 두 결과 Add
- 배포 할때는 원본 가중치에 LoRA 모듈을 더함 ()
- 이 때문에 추론 시 추가 연산이 없기에 지연 없음(원본 모델과 구조는 동일)
- Adapter
-
-
-
Prompt Tuning / Prefix Tuning
- 입력 문장 앞에 학습 가능한 특수 토큰을 추가하여 모델의 동작을 제어하는 방식
- 한계점: 최적화 난이도, 입력 길이 제한
- 파라미터 수에 따라 성능이 일정하게 오르지 않음(비선형적 변화) → 학습이 불안정, 까다로움
- 프롬프트 토큰이 입력 공간 차지 → 원래 문장이 입력될 Context window가 줄어들음
-
방법
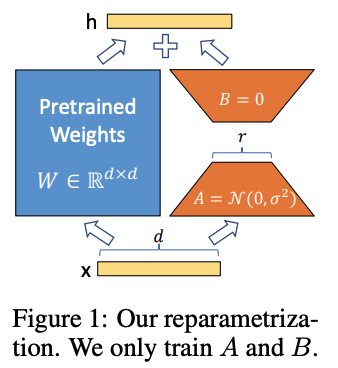
-
Low-Rank Parameterized Update
- 사전학습된 가중치 행렬 는 고정(freeze)하여 업데이트 하지 않음
- 그러면 뭘 학습하냐?
- 를 로 두 개의 low-rank matrix로 분해하여 근사하여 이를 학습
- 핵심 수식:
- 는 0으로 초기화
- 는 랜덤 가우시안으로 초기화
- d는 차원, r는 LoRA rank (, r = 1, 2, 4, …)
- ⇒ 학습해야할 파라미터 수의 감소
- 에서 로 획기적으로 감소
-
Initialization
- 왜 A 와 B를 랜덤 가우시안과 0으로 초기화하는지?
- 학습 시작 시점에 이 되도록 하여 모델이 사전 학습된 상태와 동일한 상태에서 시작하도록 함
- 그러면 A와 B 모두 0으로 하면 안되나요?
- 두 행렬이 모두 0 이라면 역전파 시 대칭성 문제로 인해 모든 뉴런이 똑같이 업데이트 되는 현상 발생
- → 한쪽은 랜덤하게 가우시안 노이즈로 초기화하여 비대칭성을 줌
- 왜 A 와 B를 랜덤 가우시안과 0으로 초기화하는지?
-
Scaling
- 에(에) 항상 scaling factor 을 곱해줌 (는 상수(ex: 16))
- r은 하이퍼파라미터 → 학습 과정에서 성능에 따라 바꿀 수 있음
- 다만 r이 커지면 A와 B 행렬에 들어가는 숫자들의 값도 같이 커짐 → 학습률을 매번 다시 조정해야함
- ⇒ scaling factor에서 r 로 나눠주어 랭크가 커졌을 때 전체적인 출력의 크기는 비슷하게 유지되도록 함
- 한마디로 learning rate tuning의 편리함을 위해 추가
-
Transformer에 LoRA를 적용하려면
- Transformer 구조에는 Self-attention에 4개(), MLP에 2개의 가중치 행렬이 있음
- 해당 연구에서는 Self-Attention에 대해서만 어떻게 적용할지 연구함
-
배포 시
- 배포 시 모델의 가중치에 학습한 LoRA 모듈을 반영하여 병합 ()
- 사실상 모델 구조에는 변화가 없음으로 원본 모델과 추론 속도 차이 없음
- 다른 태스크로 전환 시에도 A, B 행렬만 교체하면 되므로 매우 간단하게 전환 가능
- 메모리 효율성 GPT-3 175B 기준 VRAM 사용량 최대 3배 감소(1.2TB →350GB), 체크포인트 용량 10,000배 감소(350GB → 35MB) (rank = 4)
- 실험
-
실험 환경
- 모델
- RoBERTa (Base/Large), DeBERTa (XXL), GPT-2 (medium, large), GPT-3 175B
- 데이터셋
- GLUE benchmark, E2E NLG Challenge, WikiSQL, SAMSum 등
- 비교 대상
- Full Fine-Tuning, Bais-only/ LayerNorm-only tuning, Adapter, Prefix-embedding tuning, Prefix-layer tuning
- 모델
-
주요 성능 결과
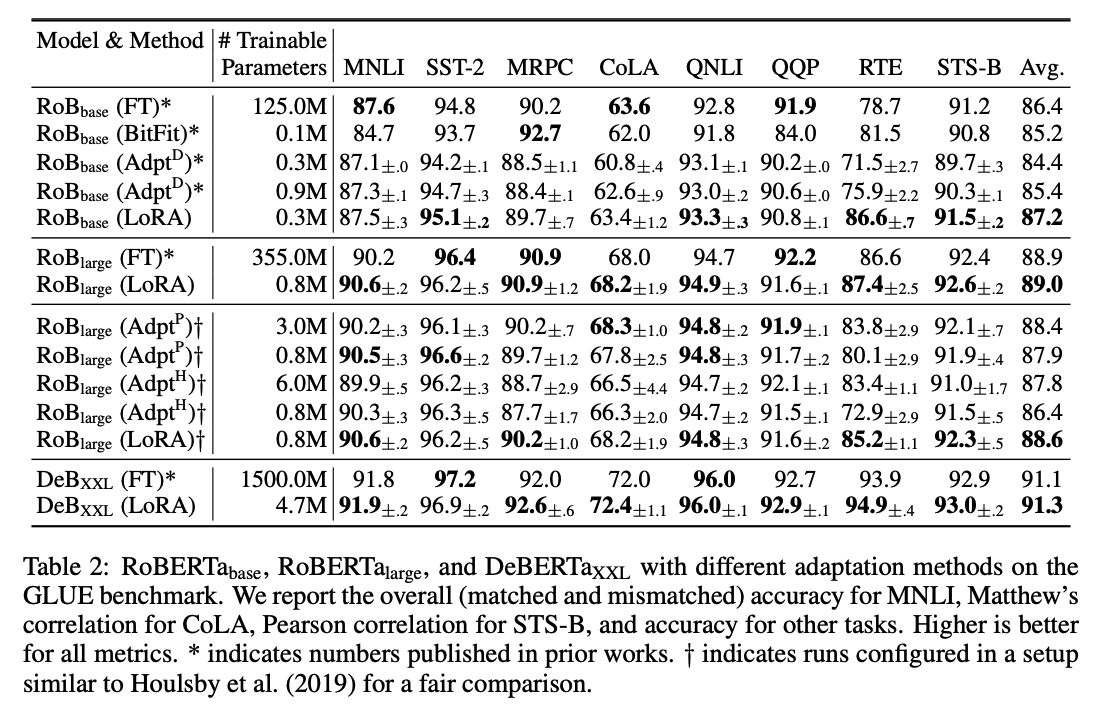
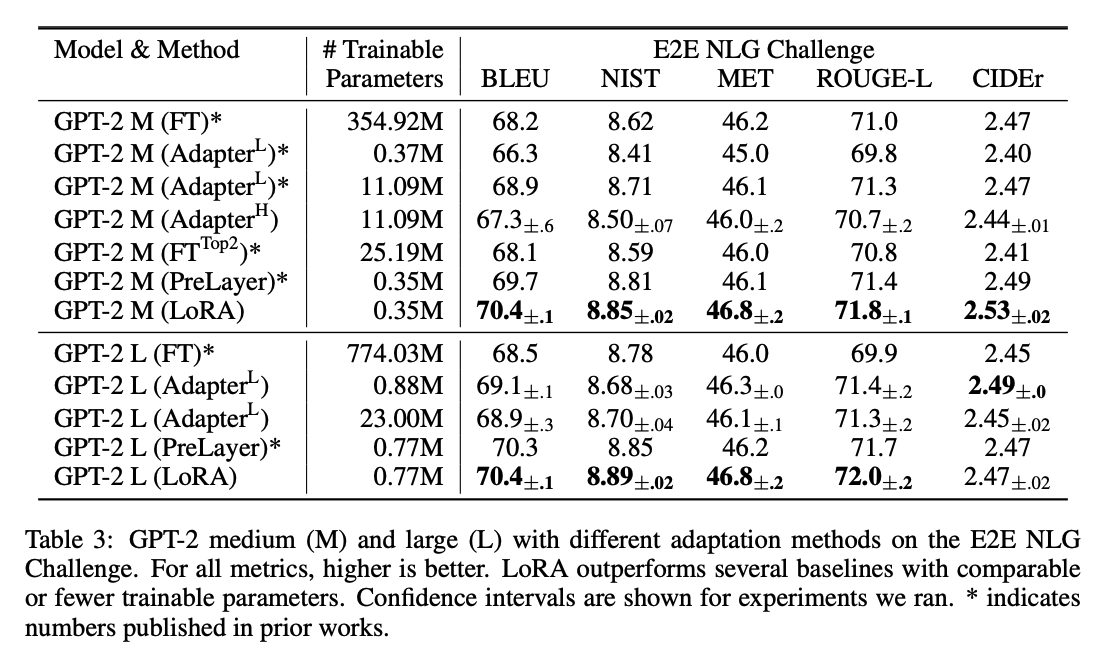
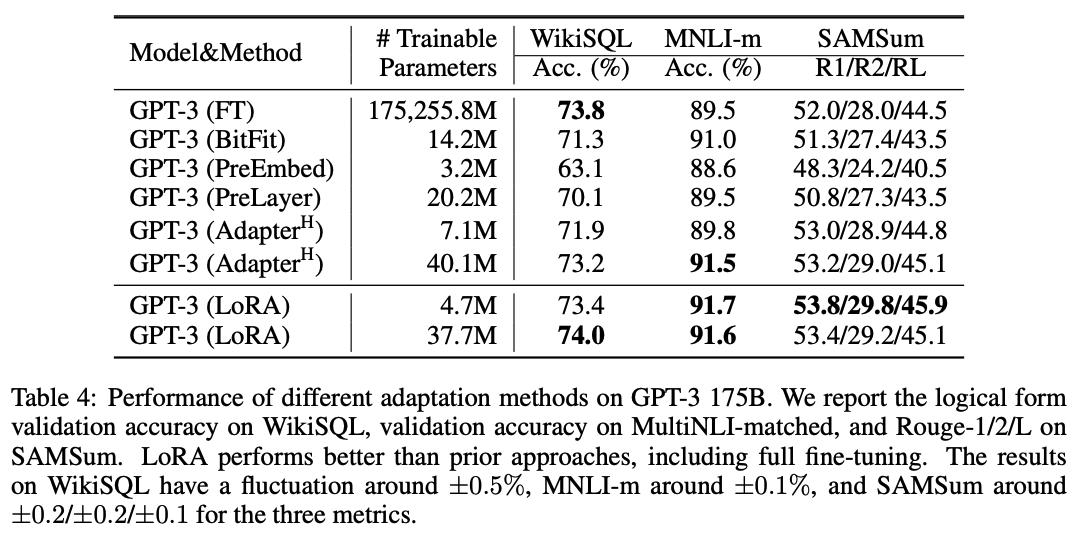
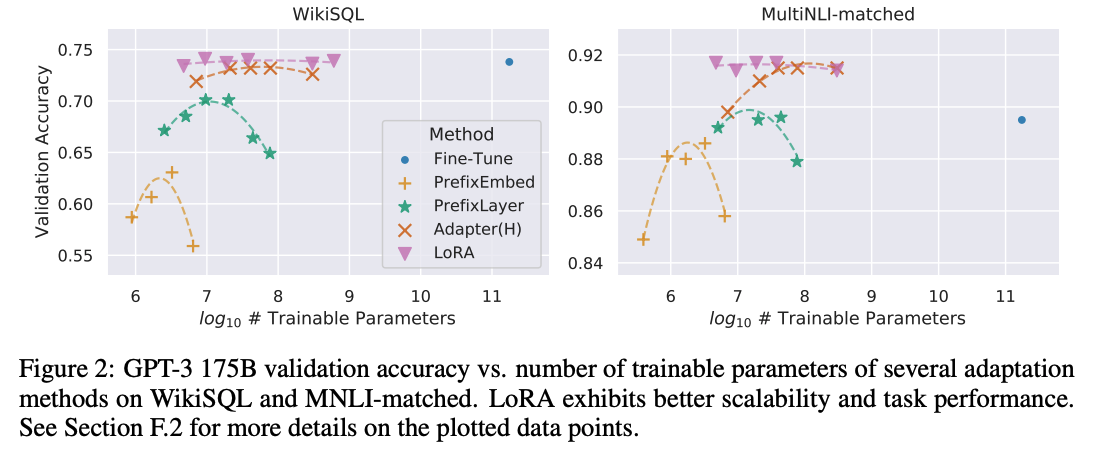
- Low-Rank의 이해
-
왜 low rank로 충분한 건지? 왜 LoRA가 좋은 성능을 내는 건지? 에 대한 부분
-
어떤 가중치에 LoRA를 붙이는 것이 효과적인지?
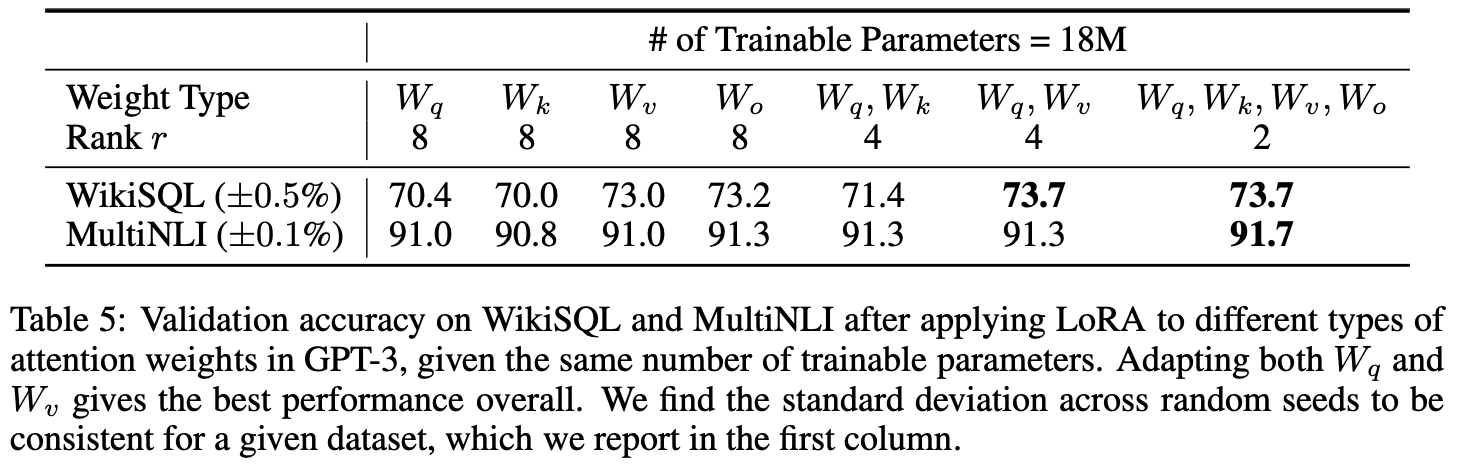
- 각각에만 적용한 경우 낮은 성능
- 에 같이 적용한 경우 가장 좋은 성능을 보임
-
LoRA의 최적의 Rank r은?
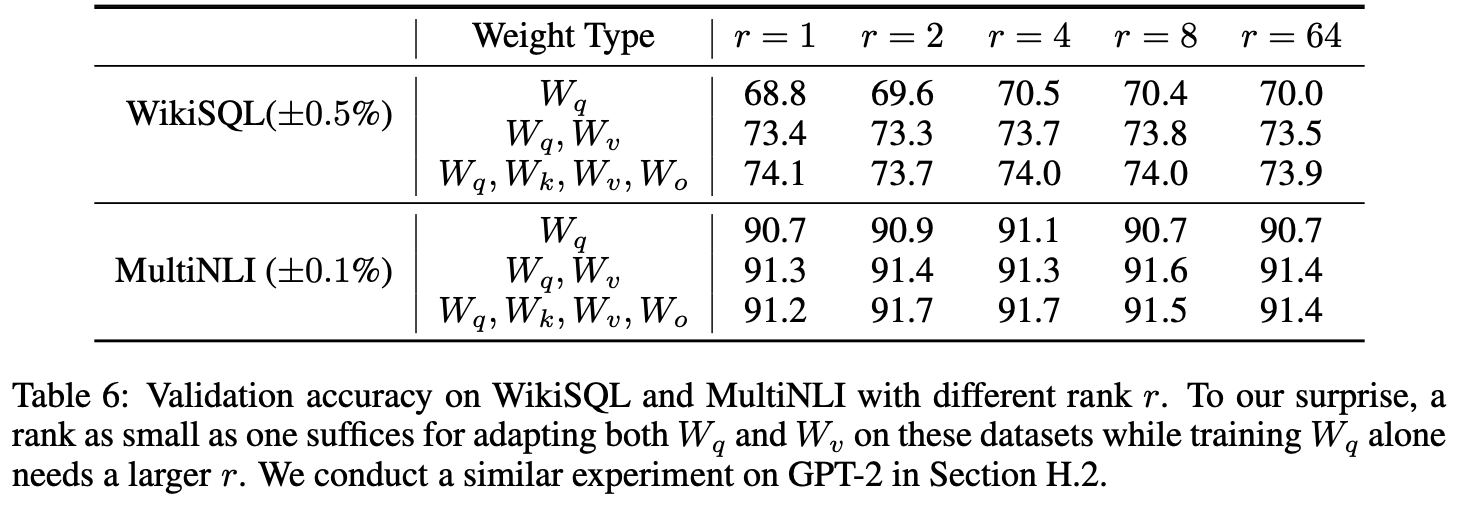
-
/ 에 적용 (는 단순 비교용)
-
에서 매우 작은 rank에서도 경쟁력 있는 성능을 보임
- → 가 매우 작은 내재적 랭크를 가진다는 것을 보임
-
Rank를 늘린다고 해서 성능이 크게 더 좋아지지 않음
- Rank를 늘리는 것이 더 의미있는 부분공간을 커버하는 것이 아님을 보임
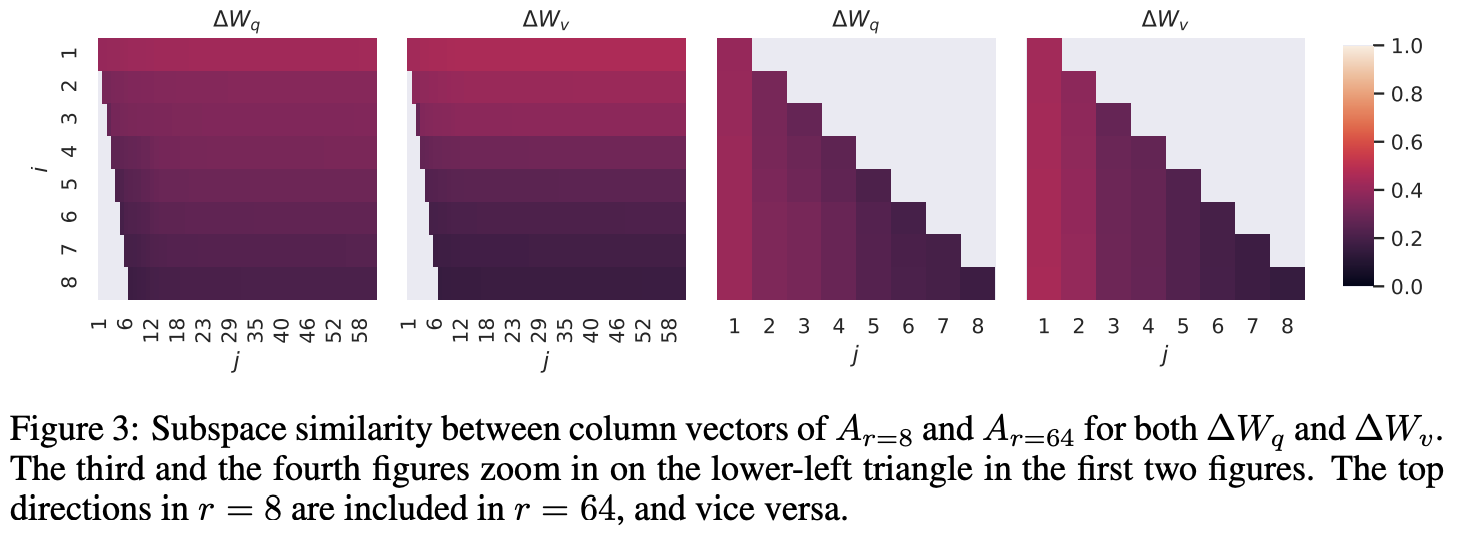
- r=8, r=64로 모델이 각각 학습한 부분 공간이 얼마나 유사한지 Grassmann distance 기반 유사도로 측정
- (1, 1) 지점의 유사도가 매우 높음 ( > 0.5) ⇒ 랭크가 달라도 중요한 정보는 동일하게 학습한다
- Rank를 늘리는 것이 더 의미있는 부분공간을 커버하는 것이 아님을 보임
-
같은 rank, 다른 랜덤 시드에서의 부분공간 유사도 비교
- 동일한 설정에서 얼마나 비슷한 것을 학습하는지를 나타냄
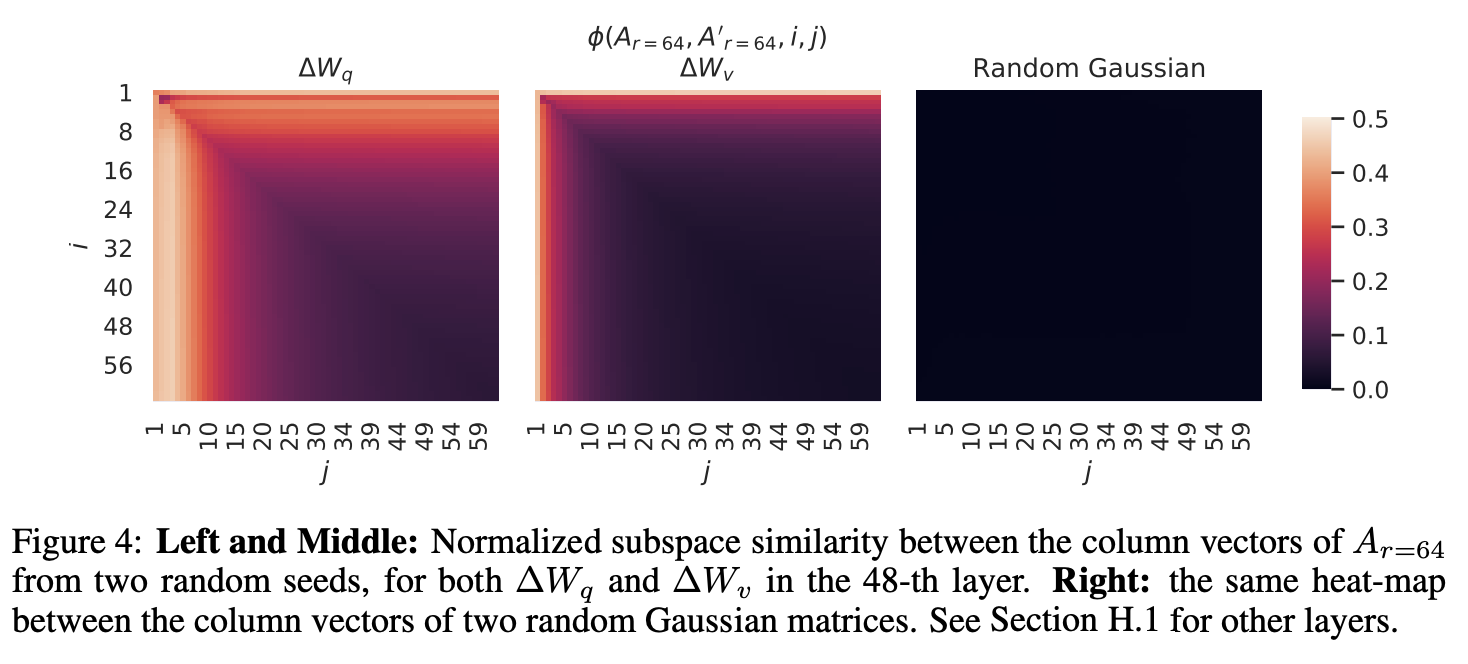
- 시드가 다르더라도 가 비슷한 방향으로 학습을 한다는 것을 확인 할 수 있음
- 가 보다 더 높은 내재적 랭크 성질을 보임 (더 일관되게 학습)
- 동일한 설정에서 얼마나 비슷한 것을 학습하는지를 나타냄
-
-
와 는 어떤 관계인가?
- 학습된 변화량 이 원본 가중치 와 얼마나 관련이 있는지

- : 학습된 를 SVD 한 상위 r개 singular vector
- → LoRA가 학습한 변화의 방향
- : 원래 모델의 가중치() 넣어 projection 시킴
- → LoRA가 학습한 변화의 방향()이, 원래 모델()이 가지고 있던 특징 방향과 얼마나 일치하는지?
- : 61.95 (모델의 전체 능력)
- : 0.32 (LoRA가 학습한 태스크에 대한 기존 모델에서의 능력)
- : 21.67 (모델이 가장 잘 하는 분야의 능력)
- Random: 0.02
- : 6.91 (LoRA가 학습한 태스크에 대한 학습된 모델에서의 능력)
- LoRA를 통해 0.32 → 6.91로 약 20배 특정 태스크에 대한 능력을 향상시킴
- 학습된 변화량 이 원본 가중치 와 얼마나 관련이 있는지
- 결론
- LLM의 크기가 커질수록 Full Fine-tuning이 불가능해지고, 기존의 파라미터 효율적 학습 방법(Adapter 등)은 추론 지연 같은 한계점이 뚜렷했음
- 이 논문에서는 사전 학습된 가중치는 고정하고, 을 나타내는 저랭크 행렬()만을 추가하여 학습하는 LoRA(Low-Rank Adaptation)를 제안
- 이를 통해 파라미터 수를 10,000배 줄이면서도 Full Fine-tuning과 비슷하거나 더 나은 성능을 낼 수 있었고, 배포 시 학습한 가중치를 모델의 가중치에 병합하여 구조적으로 변화가 없기에 추론 지연이 발생하지 않음
