[Paper review] KVTuner: Sensitivity-Aware Layer-Wise Mixed-Precision KV Cache Quantization for Efficient and Nearly Lossless LLM Inference
Paper review
- 배경
- LLM의 추론 과정에서 이전에 처리한 Key, Value 토큰을 별도 캐시(KV-Cache)에 저장
- 이를 통해 다음 토큰을 예측할 때 이전에 처리한 값을 불러와 중복 계산을 피하게되어 추론 효율성이 좋아짐
- 하지만, KV-Cache의 메모리 사용량은 배치 크기 & 입력 시퀀스 길이에 따라 선형적으로 증가함
- 또한, 긴 시퀀스(문장)에 대해 병목 현상의 원인이 됨
- 기존 KV Cache 양자화 방법들의 한계
- 모든 레이어를 동일한 정밀도로 양자화 → 양자화에 민감한(양자화 오차가 큰) 레이어가 있다면 불리함
- 4 bit 이하로 양자화시 큰 성능 손실(붕괴) 발생 → 낮은 정밀도에서의 사용할 수 없는 성능
- 실시간으로 토큰의 중요도를 판단하여 양자화 → 추론 시 오버헤드로 작용함
- 해당 논문에서 제시하는 방법
- 각 레이어마다 다른 정밀도로 양자화
- 4 bit 이하의 정밀도에서도 성능 유지
- 추론 전 미리 레이어별 정밀도를 찾아두고, 추론 시에는 해당 정밀도로 바로 양자화 (오버헤드 X)
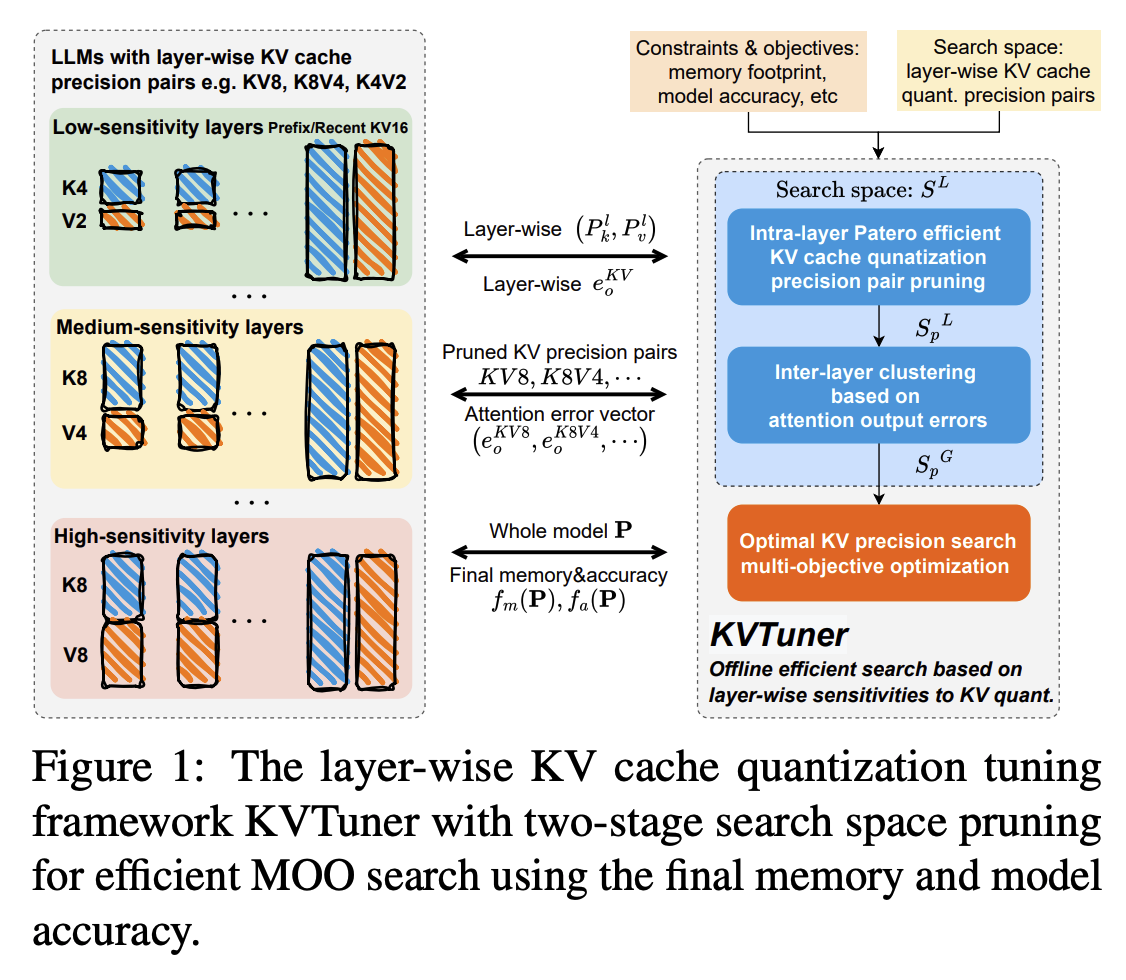
- 관찰
- 관찰 1. 오류 누적
- LLM은 이전 계층의 출력이 다음 계층의 입력이 되는 순차적인 구조를 가지고 있음
- KV Cache 양자화 시, 이전 레이어의 출력에 오류가 있다면 다음(현재) 레이어에 오류를 전달
- ⇒ KV Cache 양자화는 2차원의 오류 축적으로 이어짐
- 왜 2차원인가?
- 1차원: 레이어 방향 (이전 레이어의 오차 누적)
- 2차원: 토큰 방향 (이전 생성된 토큰까지의 오차 누적)
- 왜 치명적인가?
- 단일 토큰 혹은 레이어에서의 양자화 오류는 무시할 수 있는 정도
- 하지만, 전체 레이어와 긴 시퀀스에 걸쳐 오류가 축적되면 토큰 플리핑 현상이 발생해 생성 과정에 오류를 만들어냄
- 토큰 플리핑: 낮은 비트로의 양자화시 정보 손실이 누적되어 다음 토큰 예측 시 정답이 아닌 엉뚱한 토큰을 생성하는 오류 현상
-
ex) 20 - 4 - 4 = ? 의 결과를 예측할 때 “20, -, 4, -, 4, =, 12”의 토큰을 생성해야 하는데, “20 - 4” 이후 “-” 가 아닌 “+”처럼 잘못된 토큰을 생성하는 현상
→ 오류로 인해 계산의 결과가 완전히 달라지게 됨 (20 - 4 + 4 = 20)
-
- 축적되는 오류와 토큰 플리핑은 수학적, 논리적 추론 과정을 불리하게 하거나, 긴 문장 추론 모델에서 불필요한 연산 오버헤드를 만들어냄

- 관찰 2. 양자화 모드/정밀도에 따른 민감도 차이
- Key Cache의 경우 per-channel-asym이 per-token-asym보다 같은 비트에서 상대 오차가 낮음
- 왜 그런가?
- Key에서 Channel 방향으로 outlier 값이 뚜렷하게 나타나기 때문
- (KVQuant 그림)
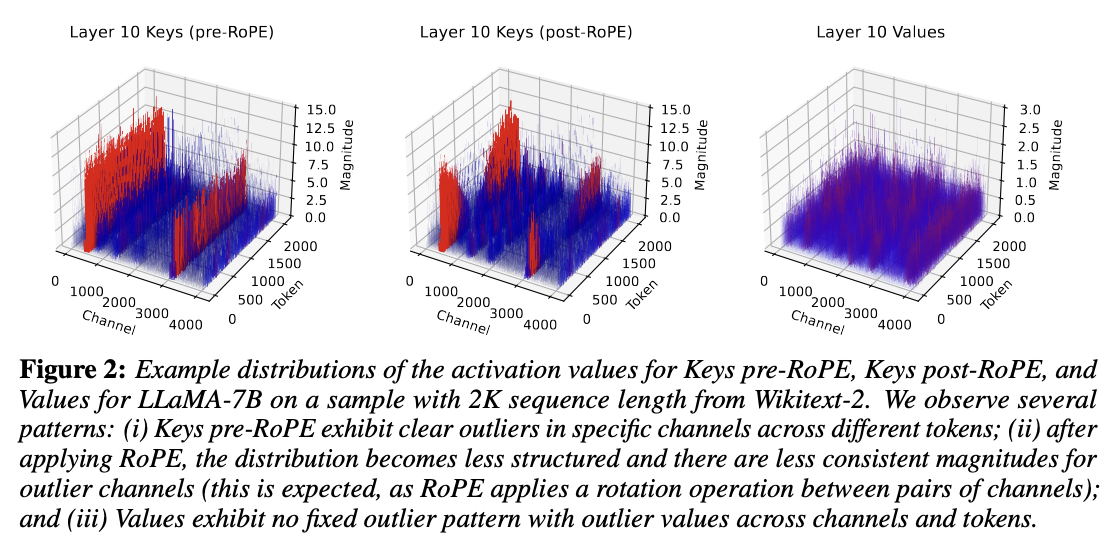
-
관찰 3. 왜 Key가 더 중요한가?
-
Key와 Value Cache 양자화 비트 조절 시 PPL 성능
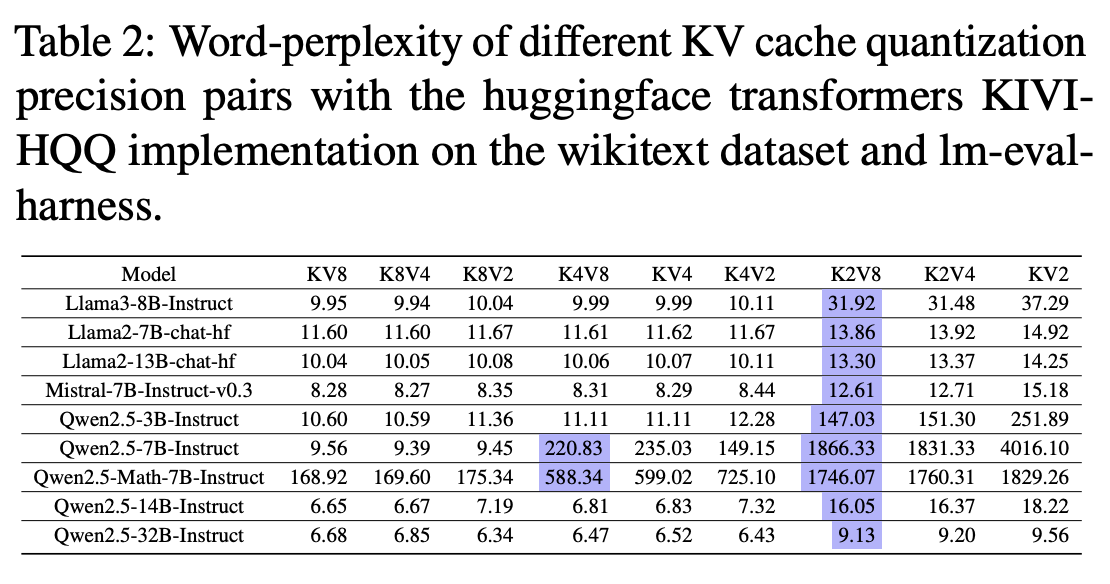
- Key Cache 고정, Value Cache 양자화 비트만 낮출 때 정확도 손실이 거의 없음
- Key Cache 양자화 비트가 낮아질 때 일반적으로 2bit 부터 큰 정확도 손실(Qwen2.5-7B는 4bit 부터)
-
Key와 Value Cache 양자화 비트 조절 시 상대적 attention output error

-
-
동일 평균 비트의 출력 오차율 비교
6bit Key 8bit, Value 4bit Key 4bit, Value 8bit 0.100 0.168 5bit Key 8bit, Value 2bit Key 2bit, Value 8bit 0.401 0.882 3bit Key 4bit, Value 2bit Key 2bit, Value 4bit 0.453 0.892 -
Key or Value Cache 각 양자화 비트 감소 시 출력 오차율
Key 8bit, Value 8bit Key 8bit, Value 4bit Key 8bit, Value 2bit 0.014 0.100 0.401 Key 8bit, Value 8bit Key 4bit, Value 8bit Key 2bit, Value 8bit 0.014 0.168 0.882 -
모두 Key Cache를 높게 양자화 하는 것이 오차율이 더 적음
⇒ Key Cache가 Value Cache 보다 양자화에서 더 중요하다!
⇒ Key Cache는 최대한 높게, Value Cache는 최대한 낮게 하는 것이 KV-Cache 양자화에 유리
-
관찰 4. KV 양자화 오류와 어텐션 패턴의 상관관계
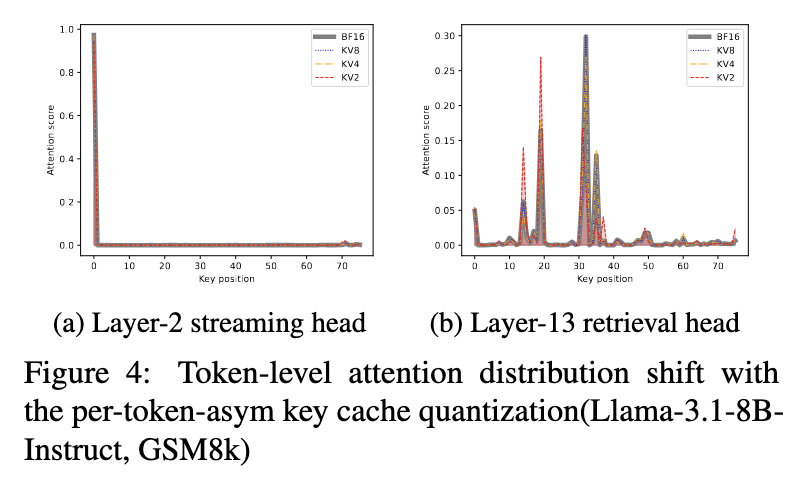
- 어텐션 패턴이 Sparse → 강건함 (양자화 오류가 적음)
- Fig 4(a)와 같이 Sparse한 어텐션 패턴을 가지는 레이어에서는 양자화 비트가 낮아지더라도 정보를 잘 표현하고 있음
- 어텐션 패턴이 non-sparse → 취약함 (양자화 오류가 큼)
- Fig 4(b)와 같이 non-sparse 하고 분산되어있는 어텐션 패턴을 가지는 레이어에서는 양자화 비트가 낮아지면 정보의 왜곡이 발생함 (더 높게/ 낮게 표현)
- Lemma 1. Only attention heads with sparse and concentrated patterns demonstrate consistent robustness to low-precision KV cache quantization.
- 정리 1. 오직 희소하고(sparse) 집중된(concentrated) 패턴을 가진 어텐션 헤드만이 낮은 정밀도의 KV 캐시 양자화에 대해 일관된 강건함(robustness)을 보인다.
- 어텐션 패턴이 Sparse → 강건함 (양자화 오류가 적음)
-
관찰 5. KV 양자화시 레이어별 민감도
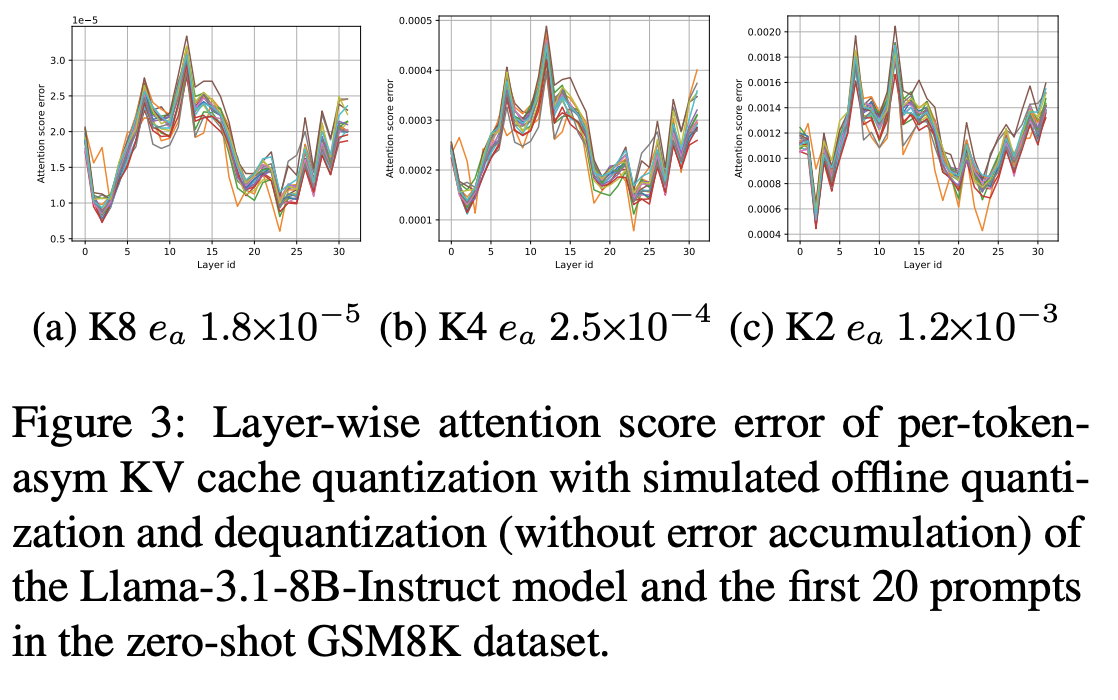
- 입력 프롬프트와 무관하게 레이어별 오차 분포가 일정함.
- →LLM의 고유한 특성
- 민감한 레이어에서 오차가 증폭되어 전체 성능이 저하됨
- Offline 탐색으로 최적의 Key, Value 양자화 비트 쌍을 찾으면 Online 추론시 오버헤드 없이 사용 가능
- 입력 프롬프트와 무관하게 레이어별 오차 분포가 일정함.
- 방법
-
Automatic Layer-wise KV Cache Quantization Precision Pair Search
-
Problem Formulation
-
레이어별 KV 정밀도 쌍 튜닝 문제를 이산 조합 최적화 문제로 정의
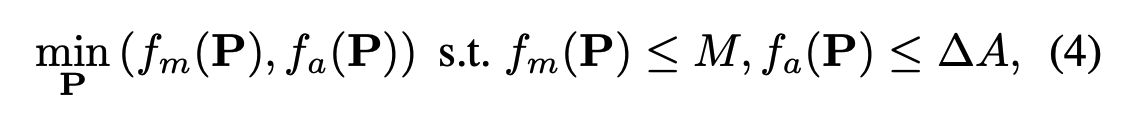
- (메모리 사용량: 양자화된 전체 KV 캐시의 평균 비트 수)
- (정확도 손실량: 16bit Half Precision 대비 정확도 손실량)
-
-
Intra-Layer KV Cache Quantization Precision Pair Pruning
- 각 레이어에 적용할 수 있는 Key, Value 양자화 정밀도 조합 {2, 4, 8} * {2, 4, 8}
- 한 레이어 당 9개의 경우의 수 → 전체 레이어에 대해 의 조합을 가짐 → 탐색 불가능(너무 큼)
- 발견: 대부분의 경우 좋은 성능이 나오는 조합이 정해져 있음 (KV8, K8V4, KV4, K4V2, KV2)
- → 각 레이어마다 최적의 조합을 미리 찾아서 탐색 공간을 줄이자(Pruning 하자)
- 그러면 어떻게 줄일 것인가?
- 독립적으로 각 레이어마다 9가지의 경우의 수를 탐색하며 최적의 정밀도 조합 추림(5~6개)
- (상대적 어텐션 출력 에러를 이용해 측정)
- 경우의 수: → 으로 좁혀짐
- ex) 만약 Layer가 32라면?
- ->
- 각 레이어에 적용할 수 있는 Key, Value 양자화 정밀도 조합 {2, 4, 8} * {2, 4, 8}
-
Intra-Layer Clustering
- 이전 단계를 통해 탐색 공간을 줄였음에도 여전히 큰 탐색 공간을 가짐 ()
- 비슷한 조합을 가지는 레이어끼리 그룹을 나눠서 탐색하자!
- 비슷한 정밀도 조합을 가진 레이어끼리 그룹을 나눔
- 해당 그룹끼리 같은 조합을 사용한다면 그룹에 대해 한번씩만 탐색을 하면 됨
- ex) 만약 Layer가 32, 그룹이 6개라면?
- →
- → 충분히 탐색 가능하다!
-
MOO(Multi-Objective Optimization) Search (여기까지가 Offline)
- 0번에서 도출된 공식을 바탕으로 축소된 탐색 공간에서 최적의 정밀도 쌍 탐색
-
KV Cache 양자화 적용 (Online)
- Offline으로 미리 결정된 정밀도 비트 쌍으로 추론시 바로 양자화 적용
-
- 실험 및 결과
-
파레토-최적의 KV Cache 양자화 정밀도 쌍 찾기
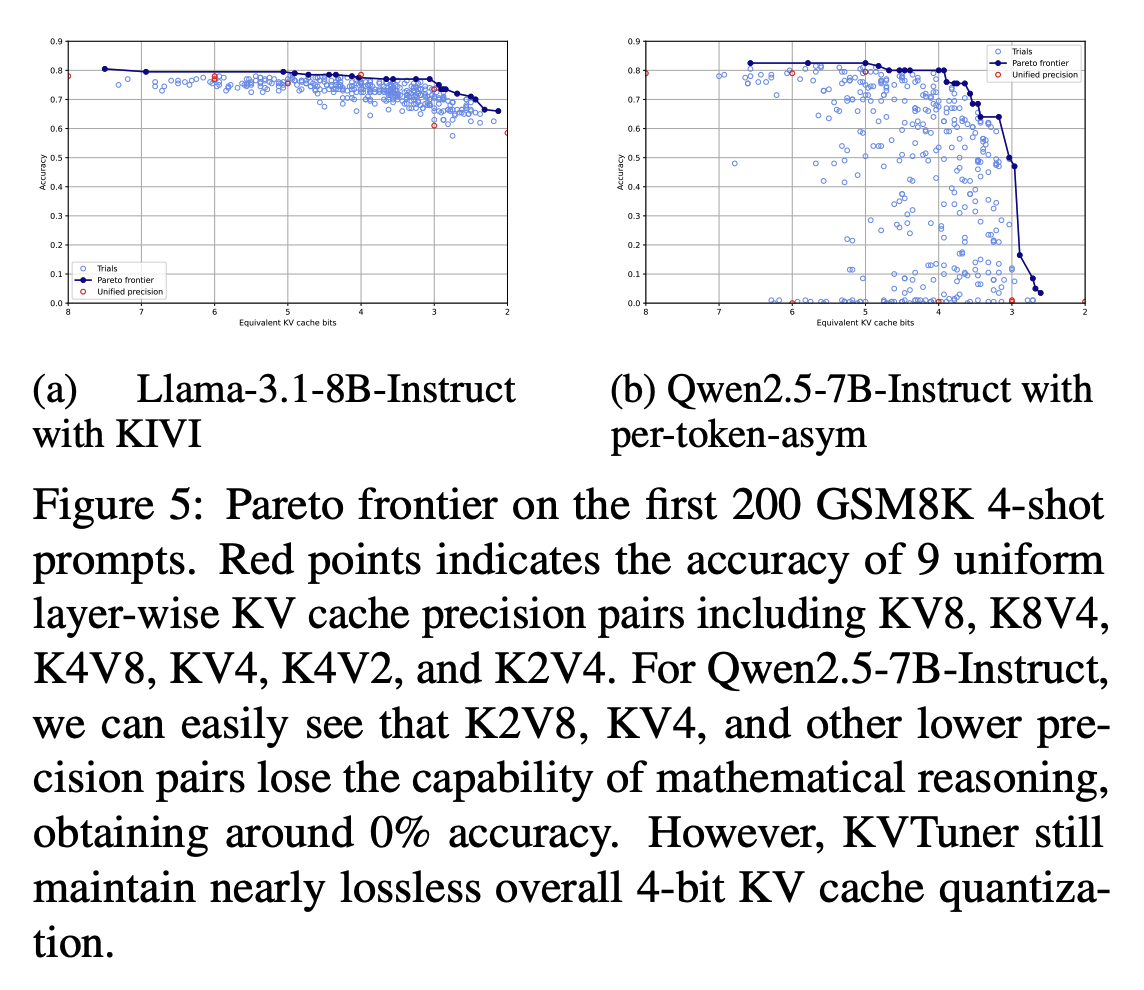
- Llama-3.1-8B 모델에서 KV8과 비슷한 정확도를 가지게 평균 3.06 bit로 양자화
- Qwen2.5-7B 모델에서 KV4는 양자화 시 정확도가 0%가 되었지만, 평균 3.92 bit로 거의 손실 없이 양자화
- ⇒ 강건한 모델 & 민감한 모델 모두 평균적으로 낮은 비트로의 양자화시 정확도 손실을 최소화함
-
수학 및 과학 추론 능력 평가
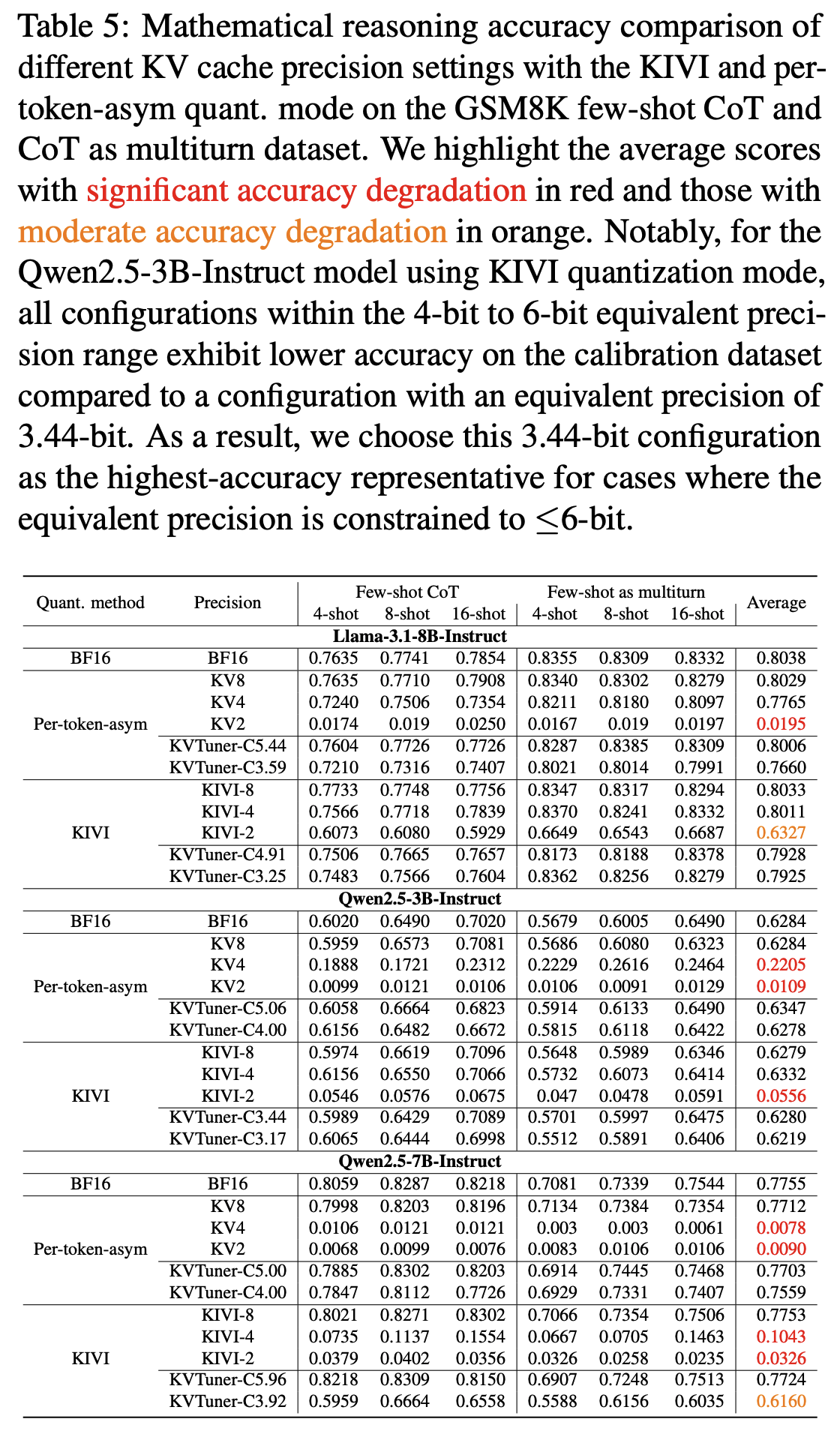
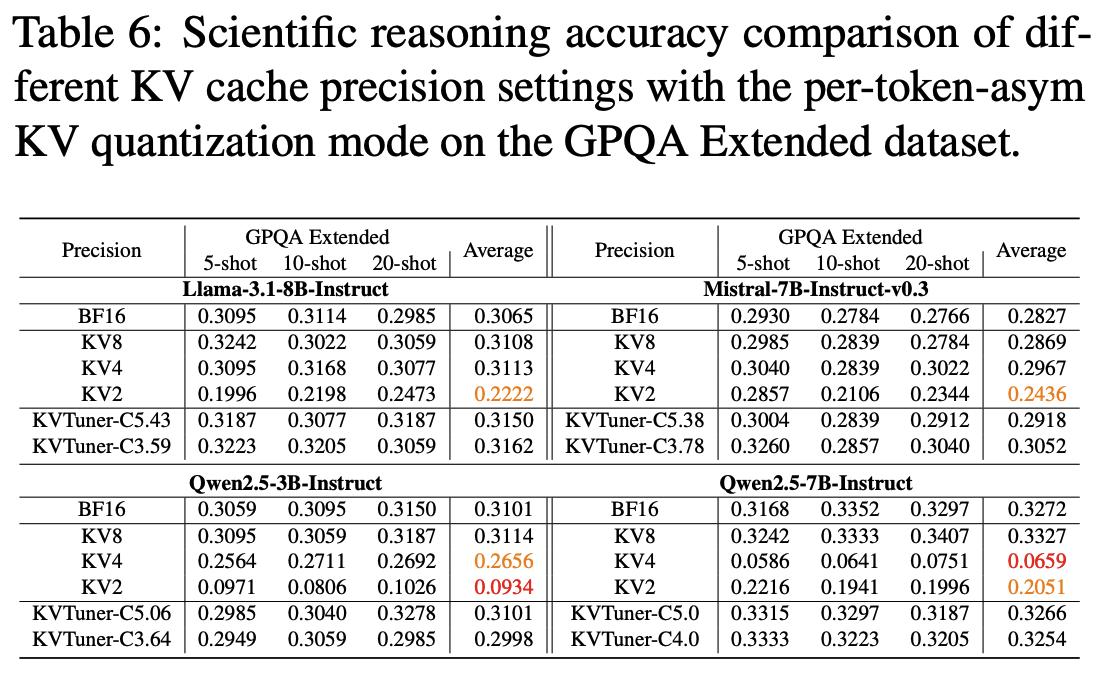
- LLama-3.1-8B 모델에서 평균 3.25 bit로 양자화시 정확도 손실 거의 없음
- 양자화를 적용했을 때 오히려 성능이 더 좋아지는 경우도 있었음
-
긴 문장 생성 정확도
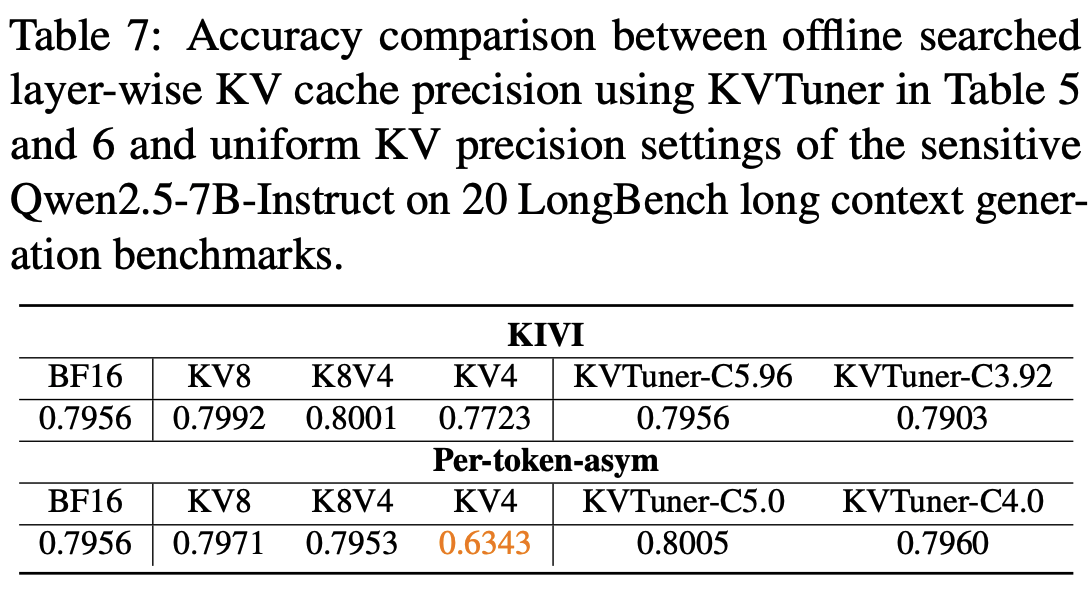
- 평균 4bit 양자화시 KV4로 양자화한 경우는 정확도가 붕괴하였지만, KVTuner는 정확도가 유지되고 있음
-
처리량 (추론 속도)
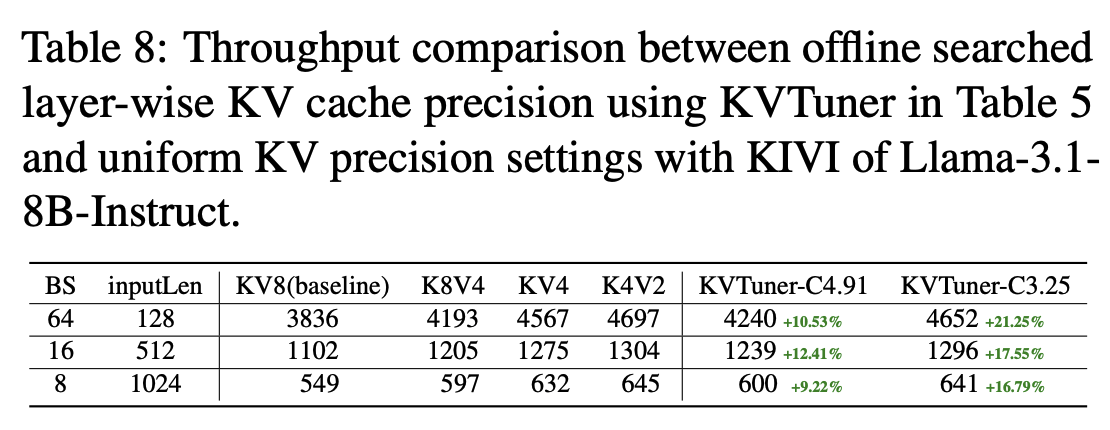
- 기존 방식보다 10~20%의 추론 속도 향상
- 결론
- 기존 KV 캐시 양자화는 모든 레이어에 동일한 정밀도로 양자화를 적용해 정확도가 손실되는 문제가 있었음. 특히 민감한 모델에서 해당 문제가 더 심각했음
- KVTuner는 미리 각 레이어별로 양자화 민감도를 측정해 최적의 혼합 정밀도 양자화 비트 쌍을 찾고, 추론 시 오버헤드 없이 KV Cache를 양자화하는 방법을 제시함.
- 이를 통해 양자화에 민감한 모델도 3~4 bit로의 혼합 정밀도 KV Cache 양자화를 정확도 손실을 거의 없이 이루어냈고, 실제 추론 속도도 10~20%정도 향상시키는 기여를 함.
