[Paper review] KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization
Paper review
- 배경
- LLM의 성능을 올리기 위해서는 처리 문장 길이를 늘려야함 (장문 문서 요약, 질의응답, 코드 분석 등)
- LLM의 추론 시, 작은 배치 사이즈에서 계산 과정 중 메모리 병목(memory bound) 발생
- 배치 사이즈가 작을수록 한번에 처리하는 계산량이 적음
- → 데이터를 계산하는 시간보다 메모리에서 읽어오는 시간이 더 오래걸림
- → 데이터를 기다리면서 GPU가 놀게되는 현상 발생
- 메모리 사용량 확인 (병목의 원인 파악)
- 짧은 문장- 모델 가중치, 긴 문장- KV Cache 가 메모리의 대부분을 차지함 → 병목의 주 원인
- → KV Cache를 잘 압축하는 것이 긴 문장 추론 시 중요
- 기존 방법들은 정확도 감소 문제를 가짐
- 이유: KV Cache activation의 outlier 구조로 저비트 양자화(4bit 이하)시 정확도 손실이 크게 발생
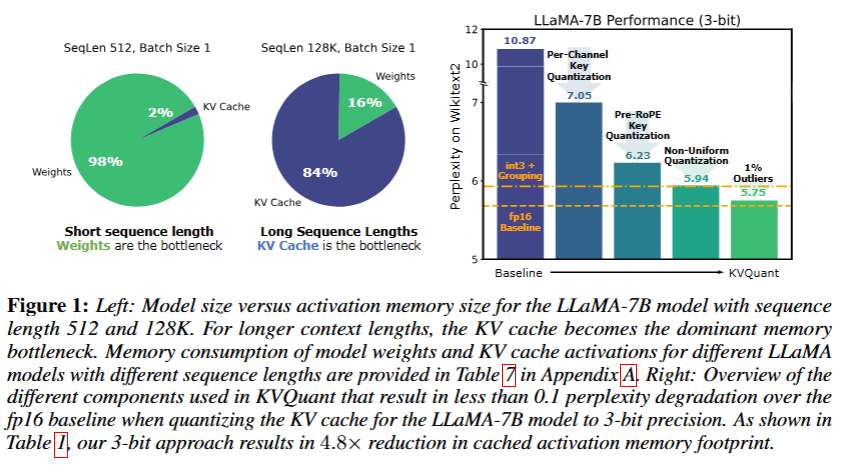
- 이유: KV Cache activation의 outlier 구조로 저비트 양자화(4bit 이하)시 정확도 손실이 크게 발생
- 사전 지식
- KV Cache
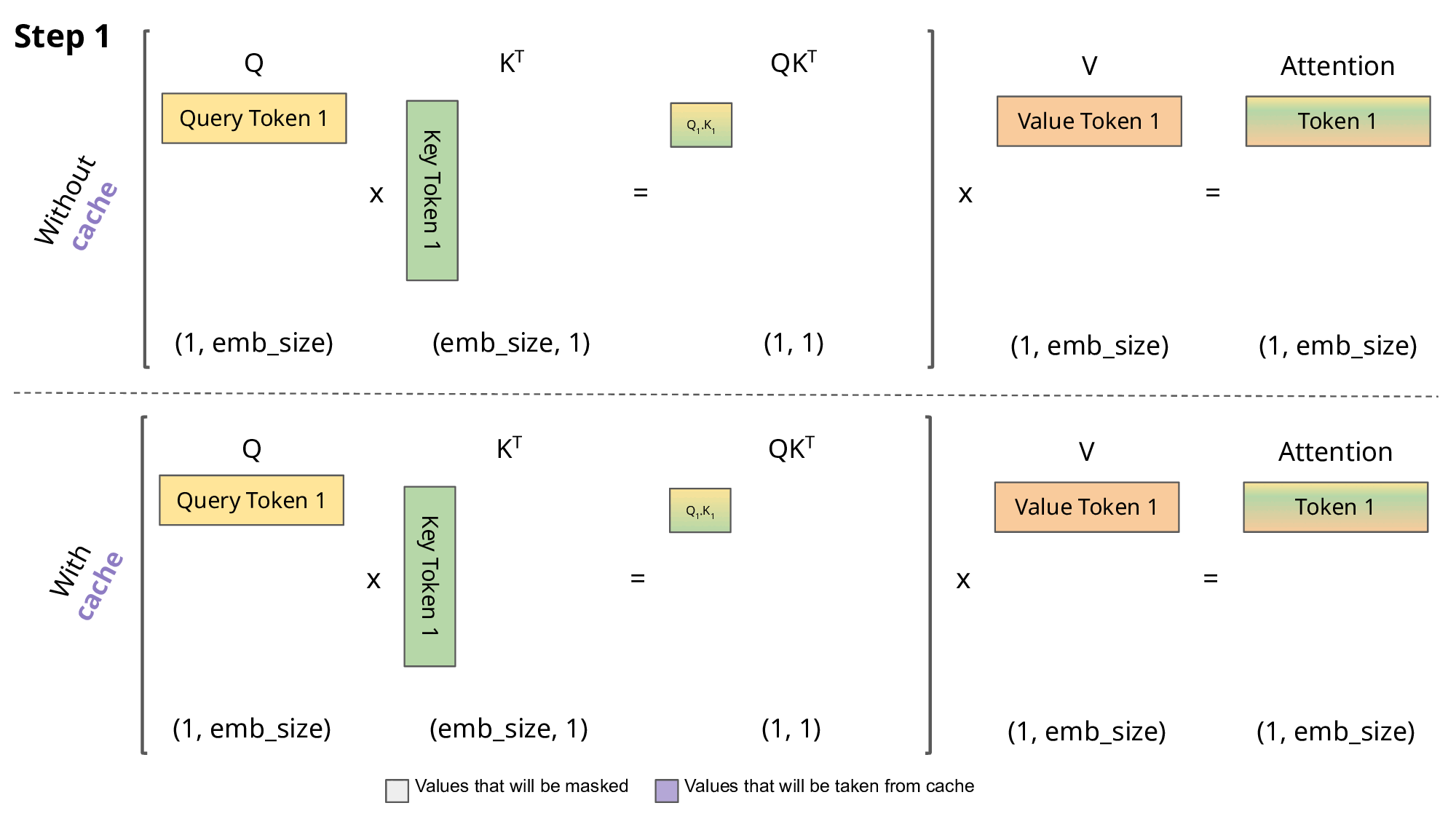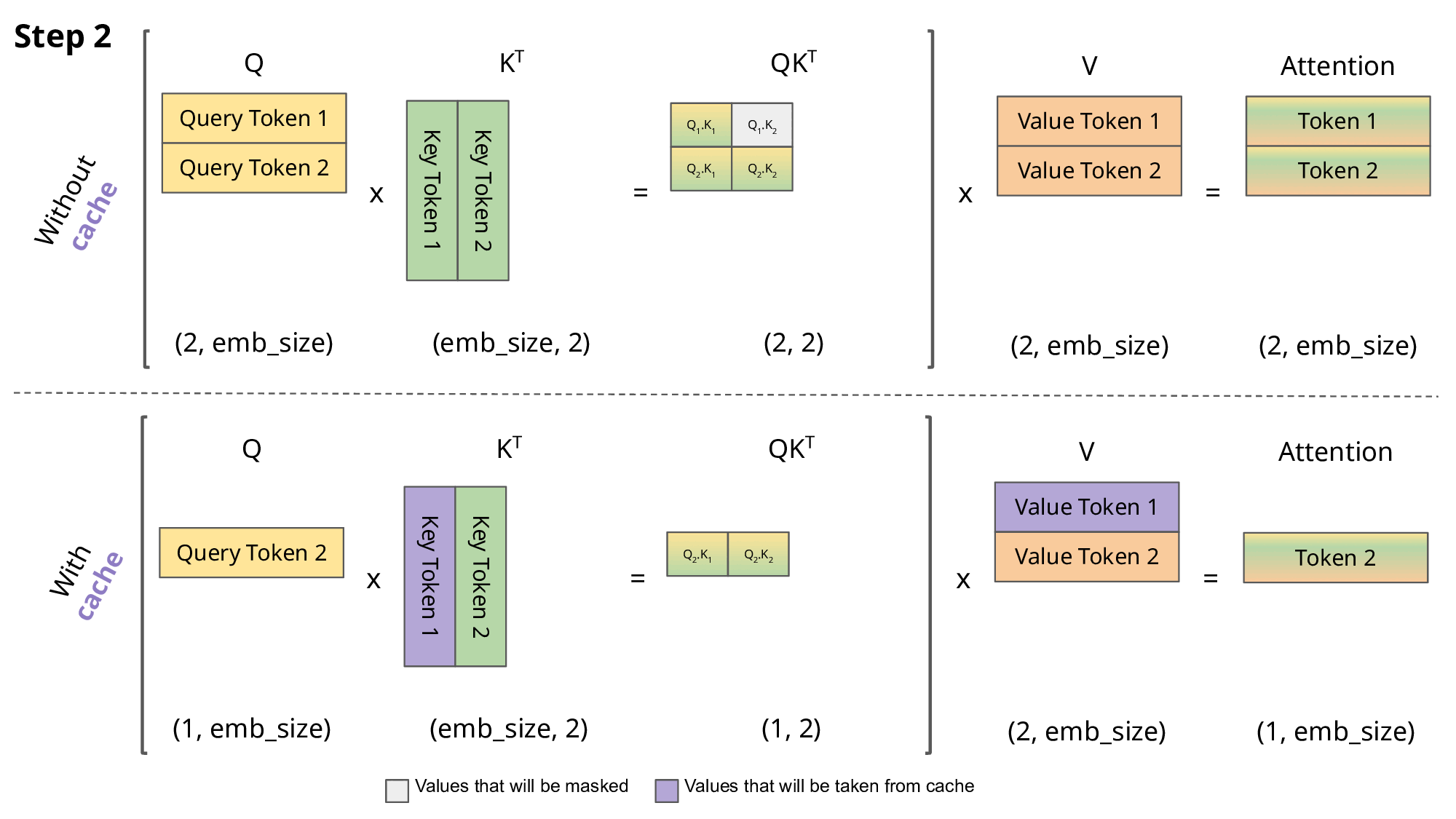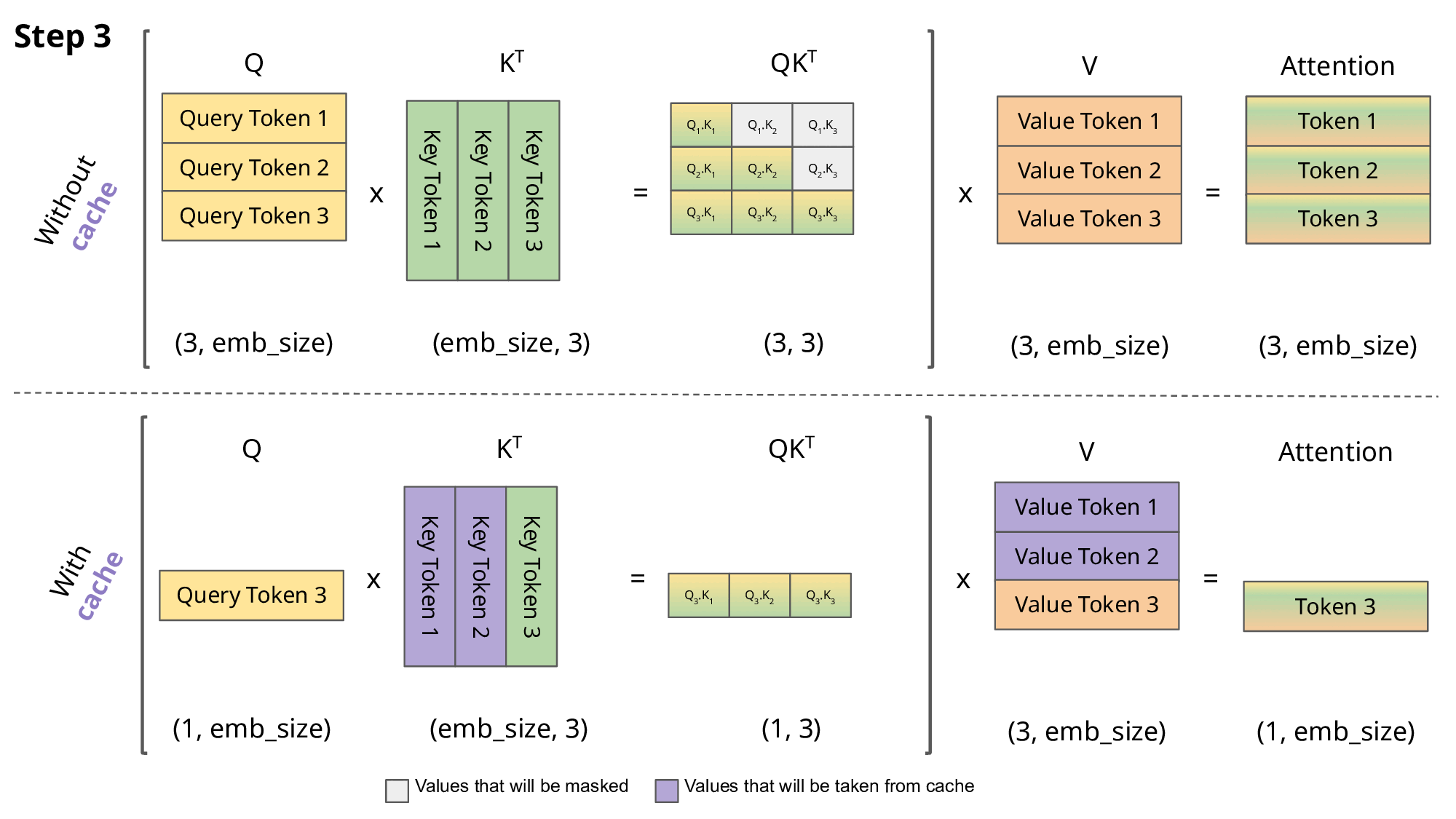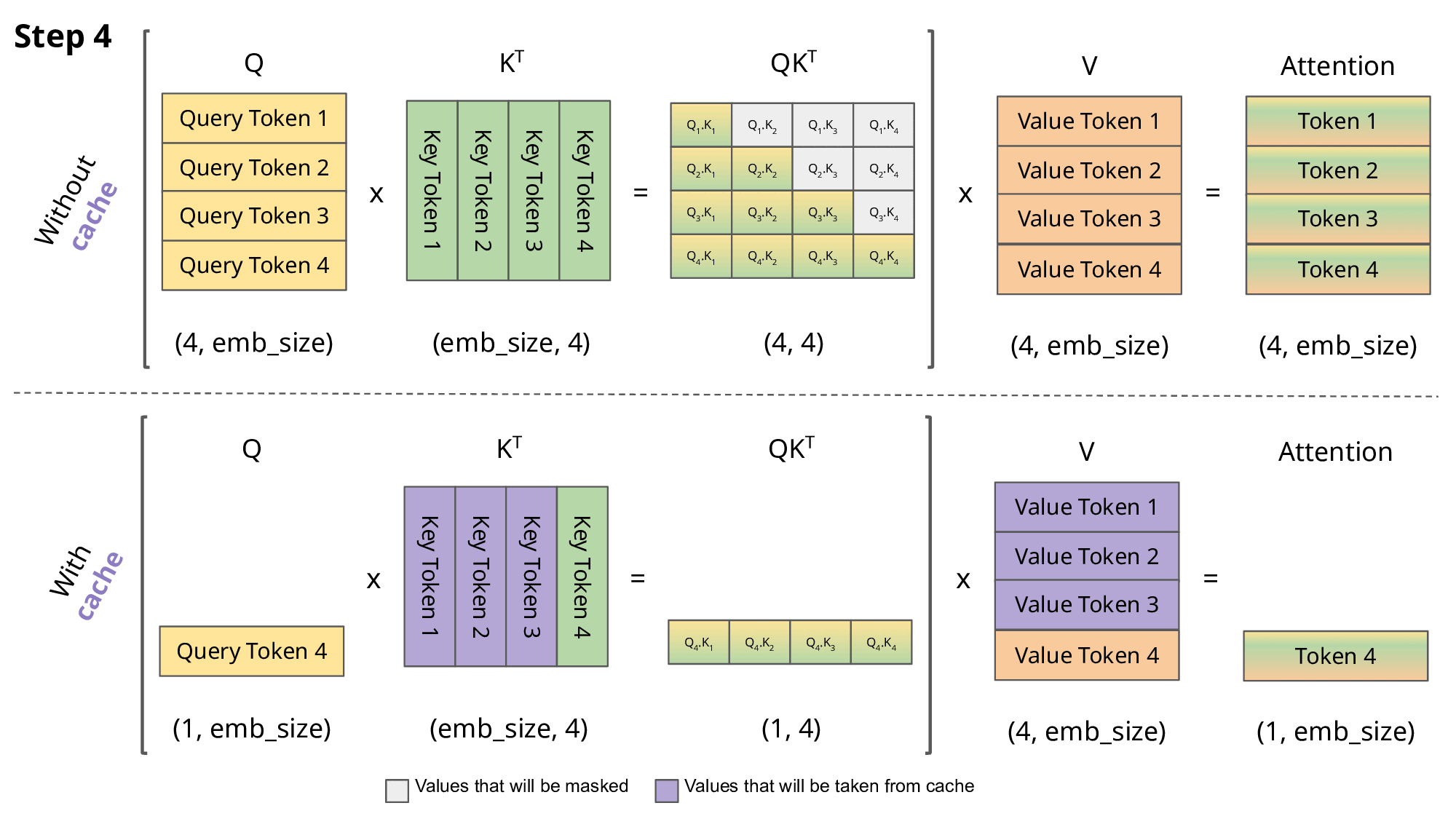
- LLM의 동작 방식
- 다음 토큰(단어)를 예측할 때 이전까지의 토큰들을 모두 가지고 예측함 → Auto-regressive 함
- 그 다음 토큰을 예측할 때 이전까지의 결과값을 다시 계산한다면? → 누적되었을 때 상당한 시간 손해
- 그러면 이미 계산한 정보는 저장해두면 좋지 않을까? → KV Cache 등장
- 예시
- “오늘 날씨는” 문장이 입력되고 다음 단어를 예측하려고 함
- “오늘”, “날씨는” 등 문장의 모든 Token에 대해 Key와 Value를 계산하는 Attention 연산을 함
- 이를 이용해 다음 단어 “맑음”을 예측
- 그 다음 단어를 예측하려고 할때
- KV Cache X: “오늘”, “날씨는”에 대한 K, V를 계산하고, “맑음”에 대해서도 계산
- KV Cache O: 저장된 “오늘”, “날씨는”에 대한 K, V를 가져오고, “맑음”에 대해서만 새로 계산
- KV Cache가 있다면 이러한 과정에서의 시간이 단축됨
- LLM의 동작 방식
-
방법
-
Per-Channel Key Quantization
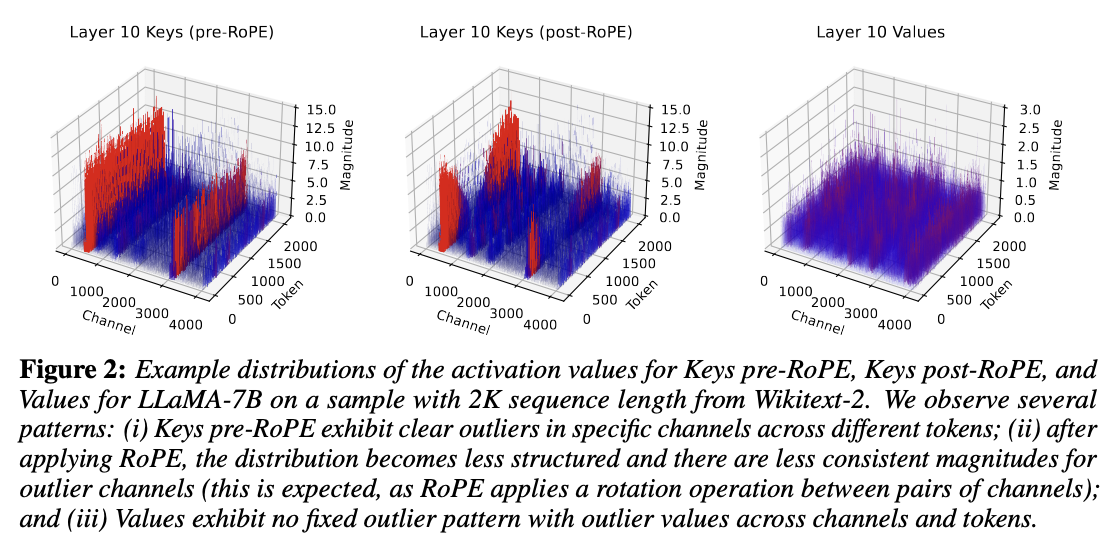
- Key activation: 특정 채널이 모든 토큰에 대해 일관되게 큰 값을 가지는 outlier channel 구조
- Value activation: 이러한 특징이 보이지 않음
- 제안 방법
- Key는 채널별(per-channel)로 양자화, Value는 기존처럼 토큰별(per-token)로 양자화
- 채널별로 양자화하게 되면 outlier값이 다른 채널에 영향을 주지 않음
-
Pre-RoPE Key Quantization
- RoPE가 적용되면 기존의 특정 채널의 outlier 값이 일반적인 채널 들과 섞이게 됨
- ⇒ 채널별로 비슷한 범위를 가지는 구조가 망가지게 됨 ⇒ 양자화시 범위 설정에 불리함
- 제안 방법
- RoPE(Rotary Position Embedding)을 적용하기 전에, Key 값들을 양자화하여 캐시에 저장
- 추론 중에 캐시에서 Key값을 불러오고, 비양자화해 실시간(on-the-fly)으로 RoPE를 적용
-
nuqX: An X-Bit Per-Layer Sensitivity-Weighted Non-uniform Datatype
-
Query, Key activation이 non-uniform 하기에 non-uniform quantization을 하려고 함.
-
non-uniform 방식을 사용한다고 할 때 역양자화 오버헤드가 크다(시간이 오래걸림)는 문제점이 있음
- 역양자화 오버헤드: 양자화된 값을 복원할 때 Lookup Table에서 원래 값을 가져오는 과정에서 발생 → 어차피 KV Cache 때문에 메모리 병목에 걸려있음 → 병목에 걸려있을 때 역양자화를 하겠다!
- 역양자화 오버헤드: 양자화된 값을 복원할 때 Lookup Table에서 원래 값을 가져오는 과정에서 발생 → 어차피 KV Cache 때문에 메모리 병목에 걸려있음 → 병목에 걸려있을 때 역양자화를 하겠다!
-
추가로, 기존에는 non-uniform 방식에서 signpost(매핑이 되는 기준)을 k-means 방식으로 구함
- 매 토큰을 생성할 때마다 signpost를 k-means로 구해야하는데, 너무 느려 KV Cache 양자화에 적용할 수 없음 (Value가 런타임중에 동적으로 양자화되기 때문) → 매번 k-means로 signpost를 구하는 것이 아닌 맨 처음에만 k-means로 signpost를 구하자
- 매 토큰을 생성할 때마다 signpost를 k-means로 구해야하는데, 너무 느려 KV Cache 양자화에 적용할 수 없음 (Value가 런타임중에 동적으로 양자화되기 때문) → 매번 k-means로 signpost를 구하는 것이 아닌 맨 처음에만 k-means로 signpost를 구하자
-
제안 방법
-
Offline: 추론 전, Calibration 데이터셋을 이용해 non-uniform datatype(signpost)을 미리 구해놓음
-
Online: 추론 시 Channel이나 Token에 맞게 non-uniform datatype의 스케일을 조절하여 사용
- 미리 데이터를 [-1, 1]로 정규화하기때문에 스케일링만으로 대응할 수 있음
-
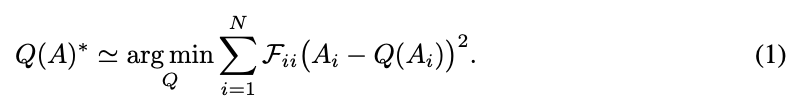
- : 대각 피셔 정보 행렬 (중요도 점수)- i값에 대한 중요도
- 단순히 양자화 오차를 계산하는 것이 아닌, 중요도점수 * 양자화 오차 를 구해 중요한 값에서의 정보 손실을 방지함
-
-
-
Per-Vector Dense-and-Sparse Quantization
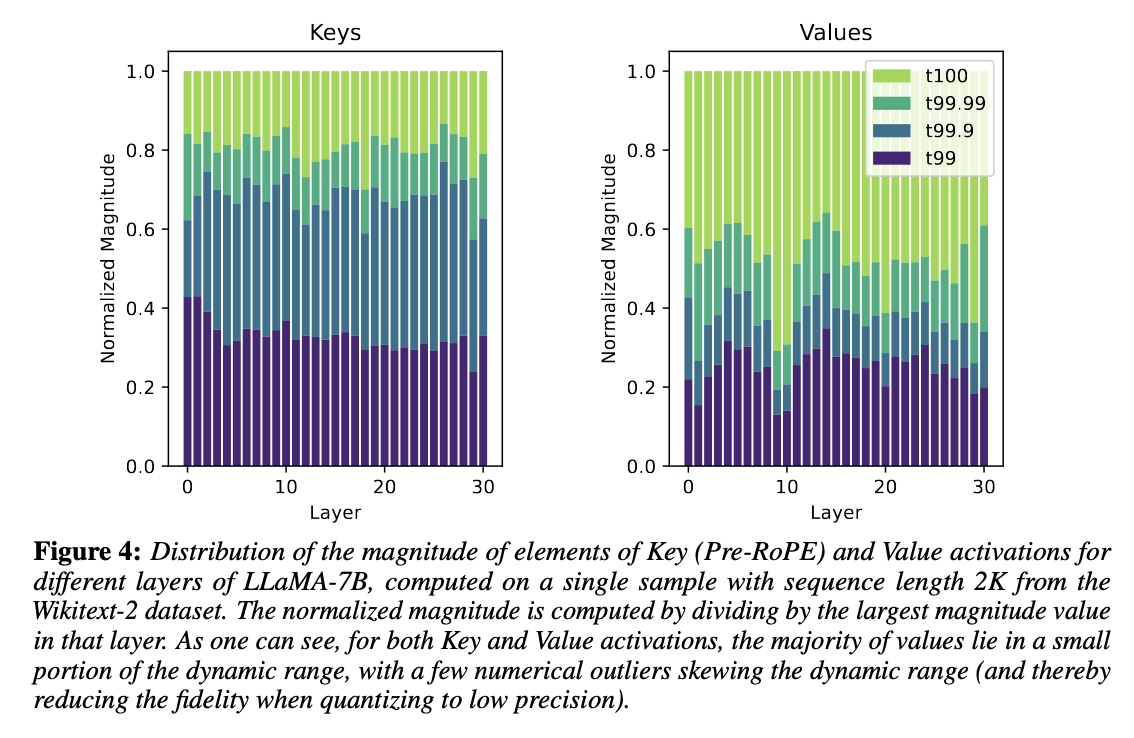
- Fig 4를 보면 Key와 Value의 99%의 값이 Dynamic range에서 일부분만 차지함
- 1%의 outlier 값이 크게 떨어져있음 → 양자화 범위를 넓힘
- → 이런 1%의 outlier 값을 제외하자 → 그럼 어떻게 outlier 값을 구할건지?
- Per-Vector
- Key는 per-channel, Value는 per-token으로 양자화하기에 outlier도 해당 기준에 맞게 찾아야함
- per-vector라는 말은 각 기준에 맞게 하겠다라는 뜻
- Dense-and-Sparse
- 99%의 값(Dense)만 양자화, 1%의 outlier 값(Sparse)는 Full Precision으로 유지
- Fig 4를 보면 Key와 Value의 99%의 값이 Dynamic range에서 일부분만 차지함
-
Attention Sink-Aware Quantization
- Attention sink: 첫번째 토큰에 높은 어텐션 점수를 할당하는 현상
- → 첫번째 토큰이 양자화 오차에 민감해짐
- 제안 방법
- 첫번째 토큰은 양자화하지 않고 Full Precision으로 유지
-
Offline Calibration versus Online Computation
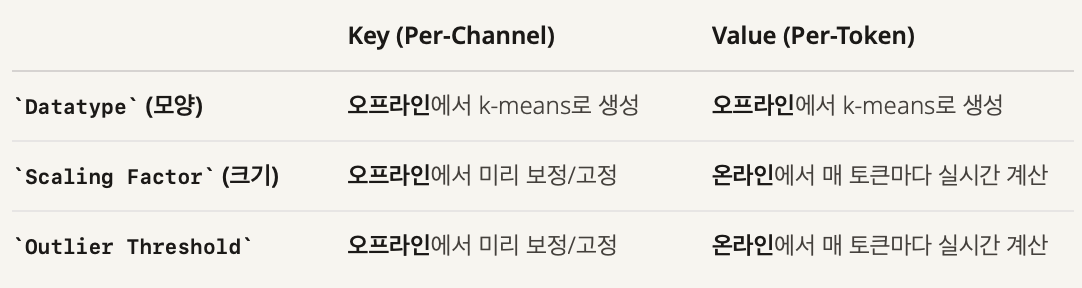
- 양자화에 필요한 통계 정보 (scaling factor, outlier threshold)를 언제 구할 것인가?
- Key(per-channel)의 통계 정보는 안정적, Value(per-token)의 통계 정보는 동적임
- 제안 방법
- Channel의 통계 정보는 offline으로 Calibration dataset을 이용해 사전에 구함
- Value의 통계 정보는 online으로 들어오는 토큰에 대해 실시간으로 구함
- Datatype, scaling factor, outlier threshold 비교표
- 실험
-
성능 평가
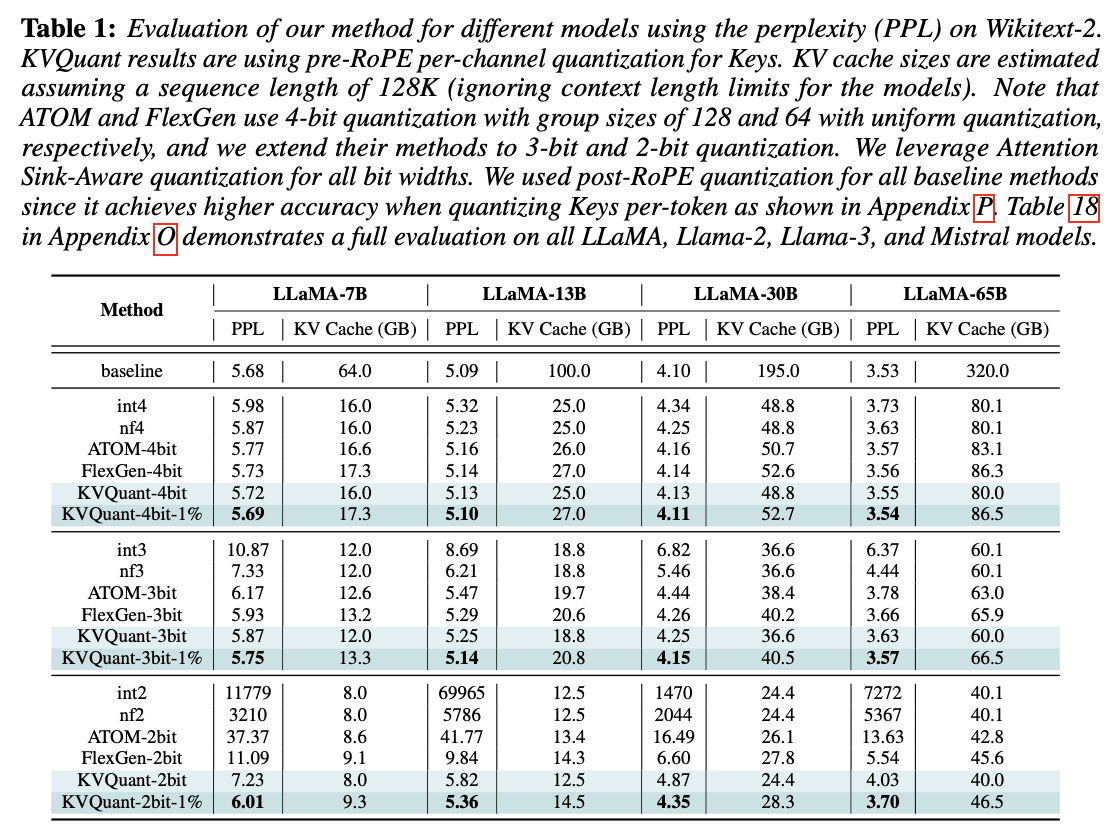
- 4bit - baseline에 비해 거의 차이가 없는 성능
- 3bit, 2bit - 매우 낮은 비트로의 양자화지만 성능 하락이 거의 없음. (약 0.3% 내외 차이)
-
장문 컨텍스트 성능 평가
-
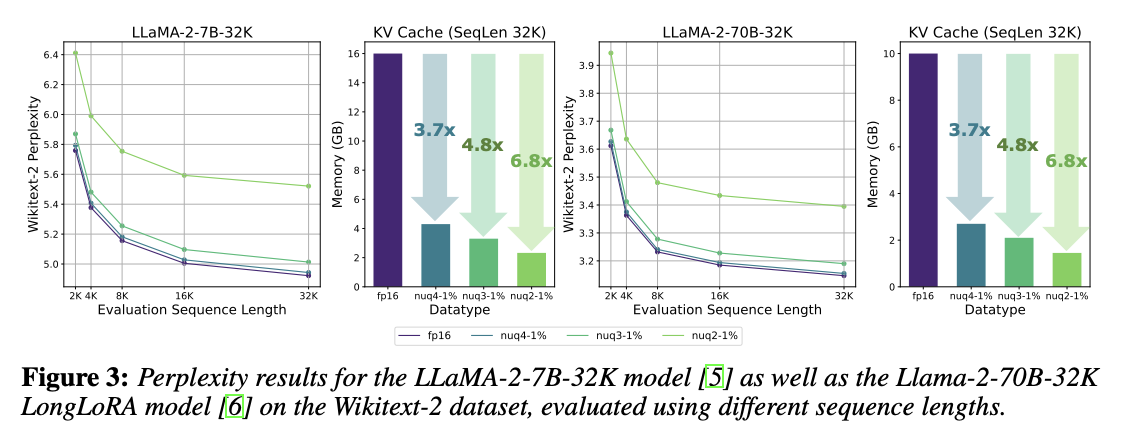
PPL 측정, KV cahce 용량 비교 (4bit 양자화시 거의 성능 차이 없이 3.7배의 KV Cache 감소 효과)
-
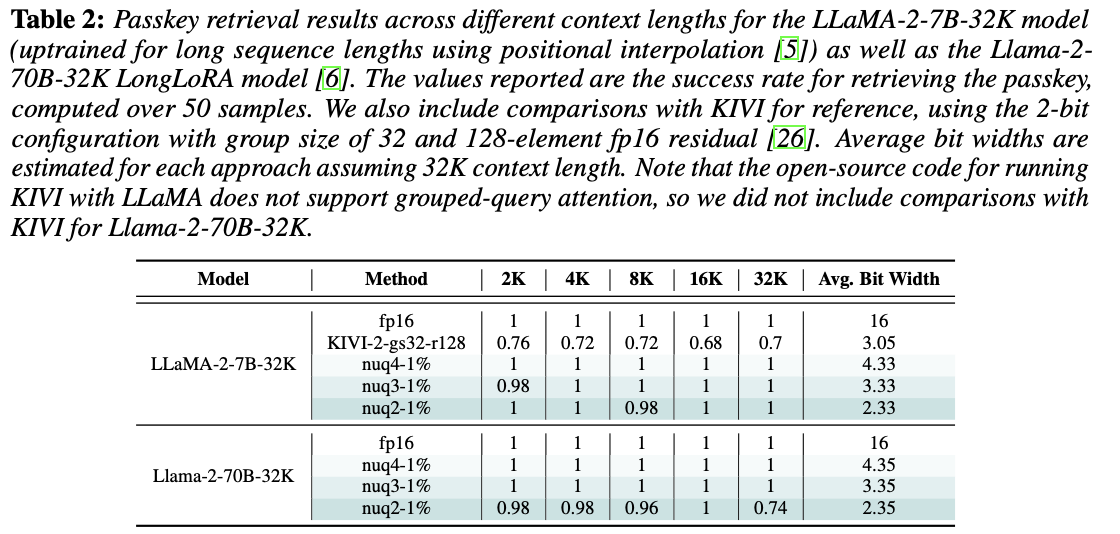
Passkey Retrieval 측정 (장거리 정보 유지 성능 측정. 3bit 까지도 거의 원본에 가까운 성능을 유지함)
-
LongBench 측정 (다양한 장문 과제에서의 성능 측정(질의응답, 요약 등), 3bit임에도 성능 차이 0.7%)
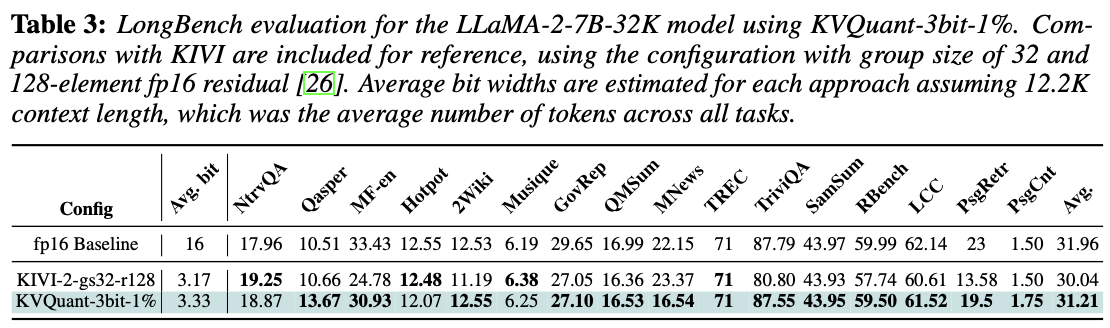
-
RULER 측정 (문장의 다양한 위치의 정보를 잘 사용하는 지 측정, 3bit 까진 유사한 성능)
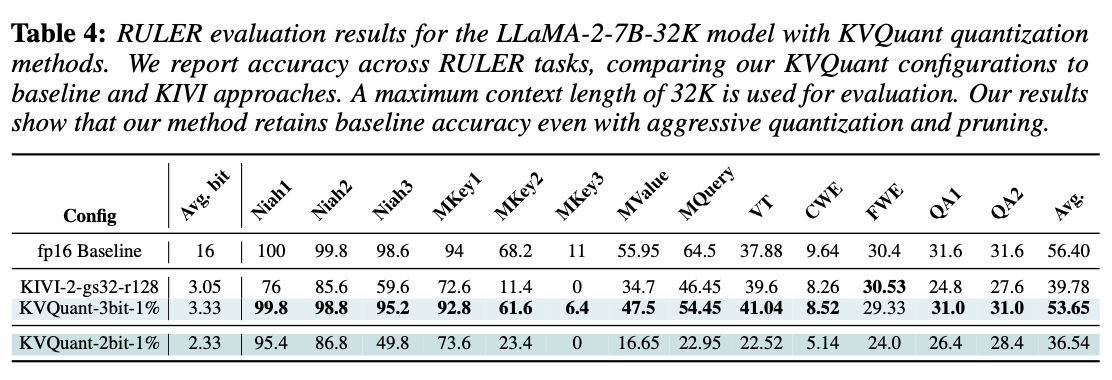
-
-
가중치 양자화와의 결합 시 성능 평가
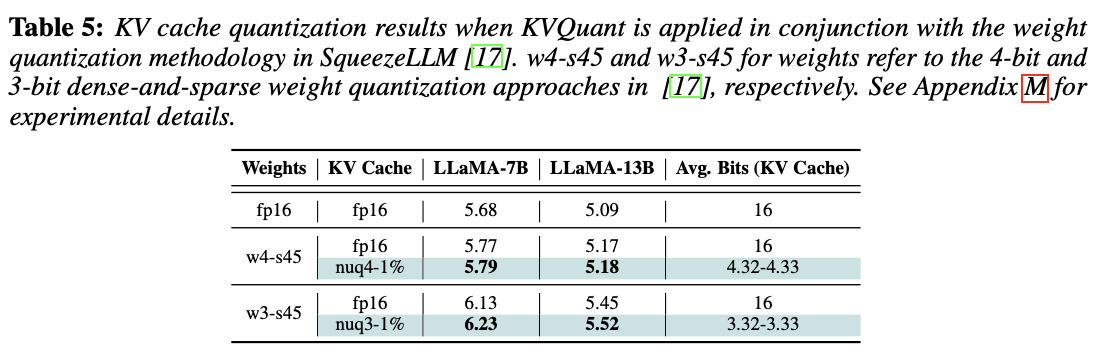
- 가중치및 KV Cache를 4bit/ 3bit로 각각 양자화. 성능이 꽤나 잘 유지되는 것을 볼 수 있음
-
실제 커널 성능 분석 및 메모리 절감 평가
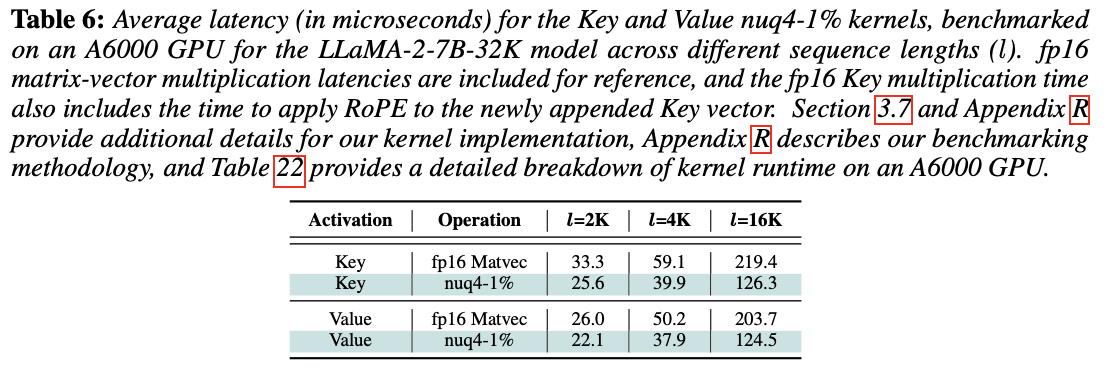
- 16,000 길이의 시퀀스가 입력될 때 실제 추론시 60~70%의 속도 향상
- → 단순히 메모리 절감만 이루어지는 것이 아닌 실제 환경에서 속도가 향상됨
- 결론
- LLM이 긴 컨텍스트를 추론 시 KV Cache의 메모리 병목으로 인해 추론 시간이 길어지는 문제가 있었음
- 다양한 기법(Outlier 값 보존 등)을 이용해 KV Cache를 Non-Uniform Quantization하는 방법을 제안함
- 이를 통해 3bit 양자화시 KV Cache를 4배 정도 압축하고도 성능을 유지하여 LLM의 긴 컨텍스트 추론 시간을 획기적으로 줄임
