[Paper review] Going Down Memory Lane: Scaling Tokens for Video Stream Understanding with Dynamic KV-Cache Memory
Paper review
1. 배경
-
스트리밍 비디오 이해의 어려움
- 모델이 연속적인 비디오 스트림을 실시간으로 인코딩·저장·검색해야 함
- 긴 영상은 LLM의 context length를 초과
- 예: 수십 분짜리 영상을 프레임 단위로 처리하면 토큰 수가 폭증
- 매 질문마다 영상을 재인코딩하면 latency, 메모리 모두 비효율
-
기존 방법의 한계
- Temporal subsampling (대표 키프레임 선택)의 문제
- 시간적 세밀함(temporal granularity)이 떨어짐
- 중요한 프레임이 누락될 수 있음
- Spatial subsampling (프레임당 적은 토큰)의 문제
- fine-grained 시각적 디테일 손실
- 세밀한 물체 속성이나 미묘한 동작 인식 불가
- ReKV (SOTA 선행 연구)의 문제
- Causal sliding window attention으로 KV-cache에 영상 정보 축적
- 프레임당 토큰 수를 늘리면 성능이 오히려 하락하는 현상 발생
- 내부 KV 특성이 retrieval과 QA를 동시에 담당 → 서로 trade-off 발생
- Temporal subsampling (대표 키프레임 선택)의 문제
-
제안: MemStream
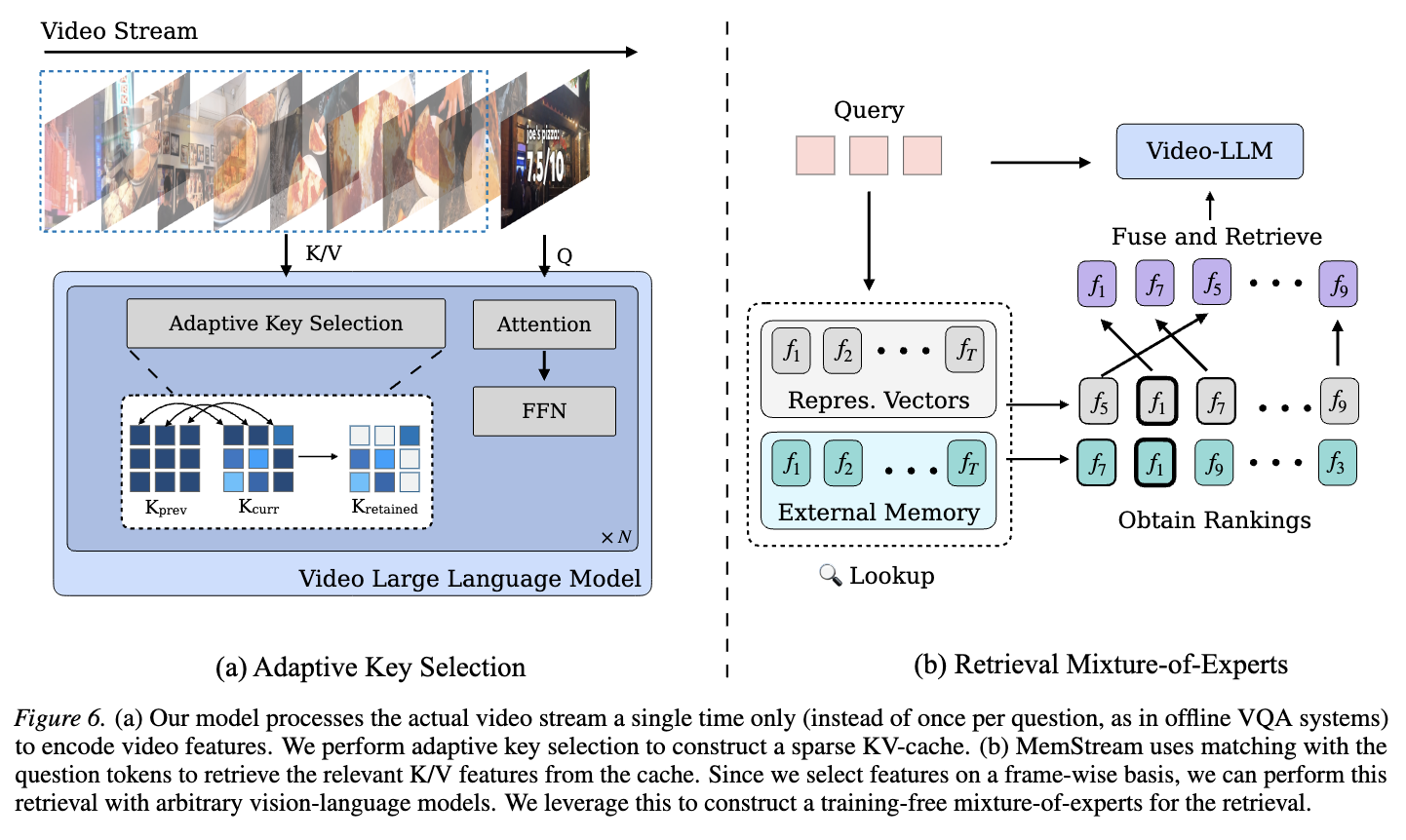
- 핵심 아이디어
- 프레임당 토큰 수(token budget)를 늘리되, 중복 토큰을 제거하는 적응형 압축 전략 도입
- 외부 모델을 활용한 training-free Mixture-of-Experts 기반 retrieval 보강
- 주요 기여
- 기존 KV-cache 방식의 인코딩·검색 한계를 분석한 extensive analysis 제공
- Sparse Sliding-Window Attention을 위한 Adaptive Key Selection (AKS) 설계
- Training-free Retrieval Mixture-of-Experts 방법 제안
- 핵심 아이디어
2. 사전 지식
-
KV-Cache 기반 온라인 비디오 이해
- 정의
- 영상 프레임을 순서대로 인코딩하며 LLM 내부의 key-value 쌍을 누적 저장
- 질문이 들어오면 저장된 KV-cache에서 관련 프레임 정보를 검색해 답변 생성
- Sliding Window Attention 구조
- 프레임 를 인코딩할 때 직전 개 프레임의 KV만 참조
- Window 안의 key/value를 concat해 attention 계산
- window를 벗어난 프레임의 KV는 offload되고, average-pool된 대표 벡터 만 GPU에 보존
- QA 시 retrieval 과정
- 질문 embedding 와 저장된 대표 벡터들의 cosine similarity로 top-k 프레임 선택
- 선택된 KV 쌍을 LLM에 주입:
- 정의
-
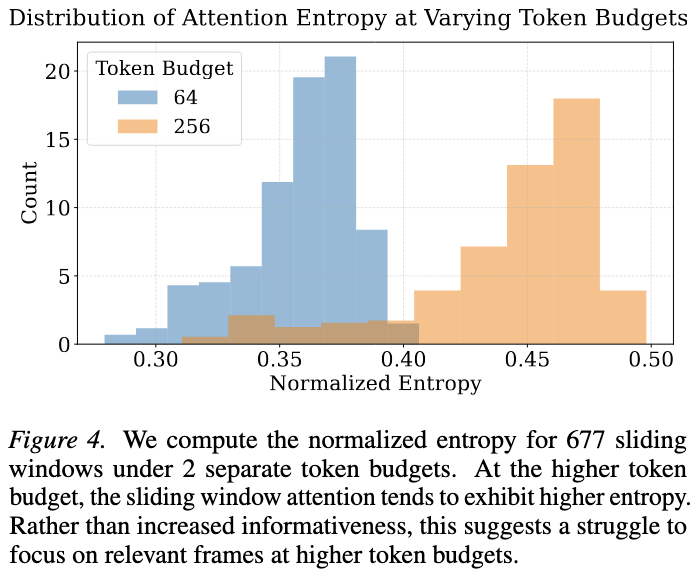
왜 토큰 수를 늘리면 문제가 생기는가?
-
토큰이 많아지면 window 내 유사 토큰이 폭증 → key feature들이 서로 뭉침
-
뭉친 key feature는 질문과의 유사도가 후반 프레임에 편향되는 Recency Bias 유발
-
self-similarity matrix 분석 결과, 토큰 수가 많을수록 서로 다른 프레임의 대표 벡터들이 점점 유사해짐 (= 구별력 감소)
-
sliding window attention entropy 분석 결과, 토큰 수가 많을수록 attention이 덜 selective해짐
-
-
Layer-wise Retrieval이 불안정한 이유
- 정의
- QA 시점에 질문의 query feature가 각 layer별로 캐시에서 유사한 프레임을 검색
- 왜 layer-wise retrieval이 불안정한가?
-
일부 layer는 관련 프레임을 잘 찾지만, 다른 layer는 아예 못 찾음 (median recall = 0인 layer 존재)
-
내부 KV feature만으로는 fine-grained 시각 정보가 부족할 때가 많음
-
⇒ layer 간 retrieval 일관성을 높여줄 보완 메커니즘이 필요

-
- 정의
3. 방법
-
전체 아이디어
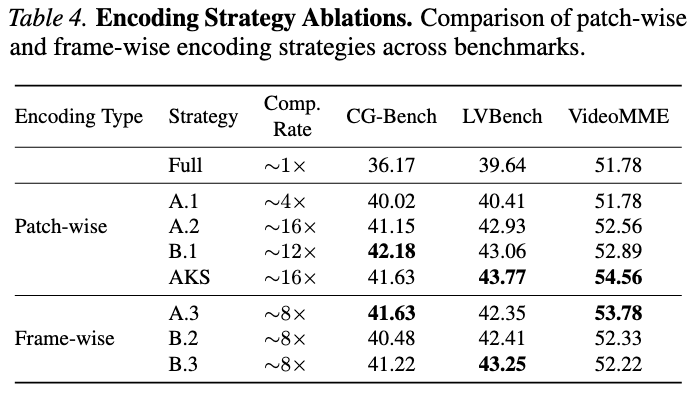
- MemStream은 2단계로 구성
- 인코딩 단계: Adaptive Key Selection (AKS)으로 sliding window 내 중복 토큰 제거
- QA 단계: Training-free Retrieval Mixture-of-Experts (MoE)로 관련 프레임 검색 보강
- 두 컴포넌트는 독립적으로 작동하며 합산된 효과를 냄
- MemStream은 2단계로 구성
-
컴포넌트 A: Adaptive Key Selection (AKS) for Sparse Sliding-Window Attention
- 역할
- Sliding window 내의 중복 토큰을 줄여 인코딩된 KV feature의 discriminability를 높임
- 프레임당 토큰 수를 늘리면서도 retrieval recall이 떨어지지 않게 함
- 구조
- 인접한 두 프레임의 key feature 와 사이의 patch-wise cosine similarity 계산
- 유사도가 낮은(= 가장 distinctive한) top-k 패치 feature만 선택하여 attention에 사용
- 선택은 attention에만 적용되며, full key feature는 KV-cache에 그대로 저장
- 왜 이 방법인가?
- 토큰이 많아지면 window 내 유사 패치가 많아져 key feature들이 서로 뭉침
- 뭉친 key feature는 질문과의 유사도가 후반 프레임에 편향되는 recency bias 유발
- ⇒ AKS로 window를 sparse하게 만들면 각 프레임의 key feature가 더 구별력 있게 됨
- 역할
-
컴포넌트 B: Training-free Retrieval Mixture-of-Experts (MoE)
- 역할
- 질문 답변 시 어떤 프레임을 KV-cache에서 가져올지 결정하는 retrieval 단계 보강
- LLM 내부 attention 신호 외에 외부 모델(CLIP, PECore)의 검색 신호도 함께 활용
- 구조
- 인코딩 중 외부 모델로 각 프레임의 visual feature 저장
- QA 시 질문 embedding 와 모든 프레임 embedding의 cosine similarity로 계산
- 내부 retrieval ranking 와 외부 retrieval ranking 을 Reciprocal Rank Fusion (RRF)으로 합산
- RRF score 기준 top-k KV 쌍을 LLM에 주입하여 최종 답변 생성
- 왜 RRF인가?
- 단순 L2-concat fusion은 서로 다른 embedding space의 거리가 비교 가능하다고 가정함 → 불안정
- RRF는 raw score 대신 ranking 기반으로 fusion → 두 space의 스케일 차이 영향 없음
- ⇒ 강한 retrieval 신호가 약한 신호를 보완하며 outlier 영향도 억제됨
- 왜 이 방법인가?
- LLM 내부 layer별 retrieval quality가 불안정 → 일부 layer는 관련 프레임을 아예 놓침
- 외부 비전-언어 모델은 내부 KV feature와 상보적인(complementary) retrieval 신호 제공
- ⇒ MoE aggregation으로 layer-wise retrieval 일관성 향상 및 전체 retrieval quality 개선
- 개인적인 의견
- 내부 attention이 retrieval과 QA를 동시에 담당한다는 구조적 한계를 외부 모델로 분리하는 아이디어가 인상적
- ReKV는 internal retrieval이 더 robust하다고 주장했지만, 실제로는 external과의 조합이 훨씬 효과적임을 보인 점이 흥미로움
- 역할
-
전체 동작 Flow
- 순서
- 1단계: 비디오 스트림을 프레임 단위로 수신
- 2단계: AKS를 적용한 sparse sliding window attention으로 각 프레임 인코딩 → KV-cache에 저장, 동시에 외부 모델로 frame visual feature 저장
- 3단계: 질문이 들어오면 내부 LLM + 외부 expert MoE가 RRF로 관련 프레임 top-k 선택
- 4단계: 선택된 KV 쌍을 LLM에 주입하여 최종 답변 생성
- ⇒ 토큰 수를 늘려도 retrieval recall이 유지되며, fine-grained 시각 정보를 보존한 채 정확한 VQA 가능
- 순서
4. 실험
-
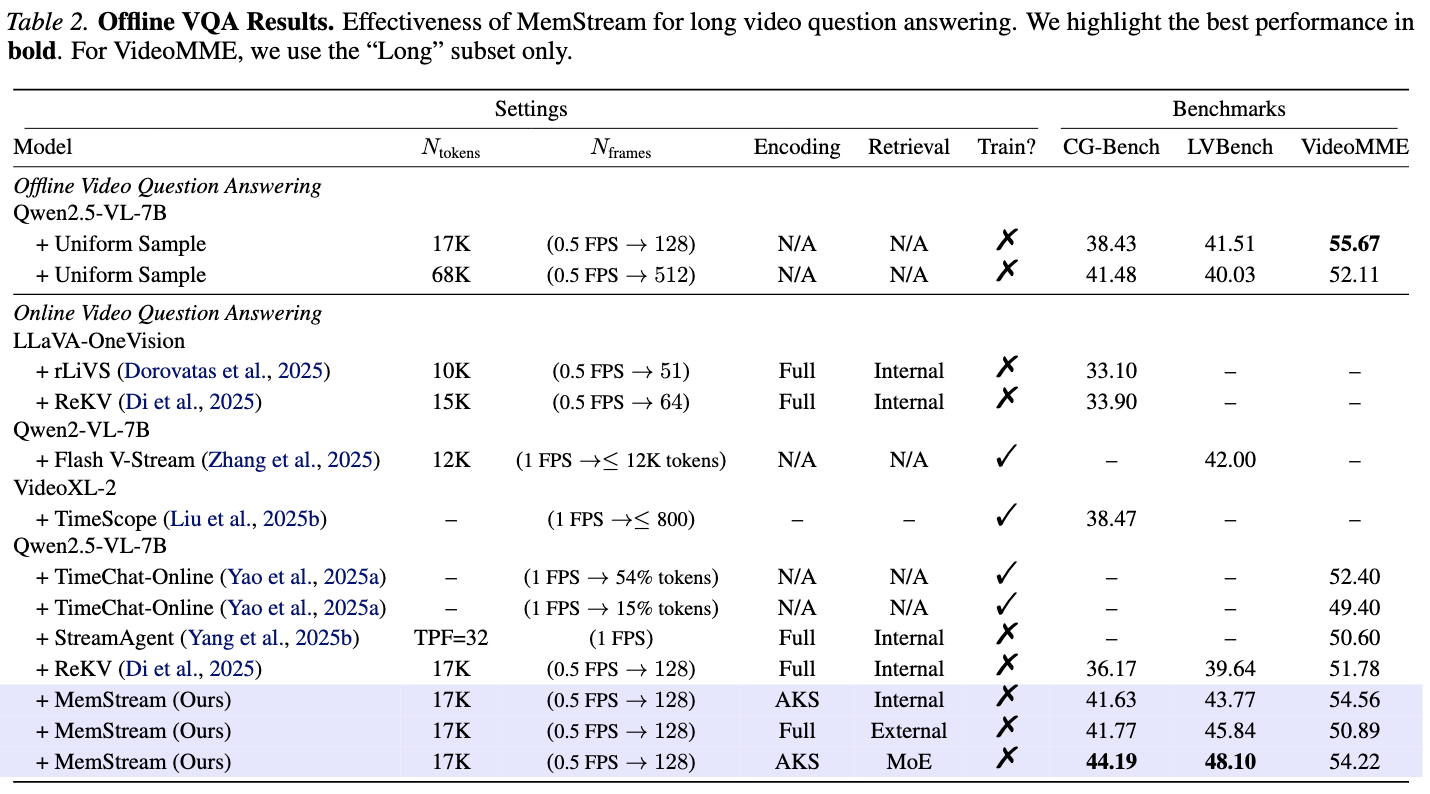
실험 1: Offline Long Video QA
-
환경
- 베이스 모델: Qwen2.5-VL-7B
- 샘플링: 0.5 FPS, 128 프레임 (Qwen2.5-VL 특성상 2프레임 = 1 feature → 64 frame features)
- 프레임당 토큰 수: 200~256 tokens (KV-cache 크기: 10.3~13.2 GB)
- Sliding window 크기: 약 17,000 tokens (64~68 frame features)
- 외부 모델: CLIP ViT-L, PECore ViT-L
-
벤치마크
- CG-Bench: 질문별 답변에 필요한 최소 프레임 annotation 포함 → retrieval 직접 진단 가능
- LVBench: 매우 긴 영상 이해 (높은 frame count 요구)
- VideoMME (Long): 평균 41분짜리 영상 300개
-
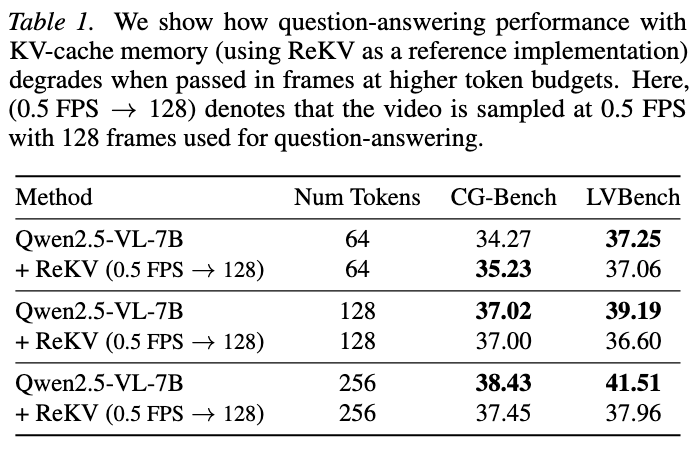
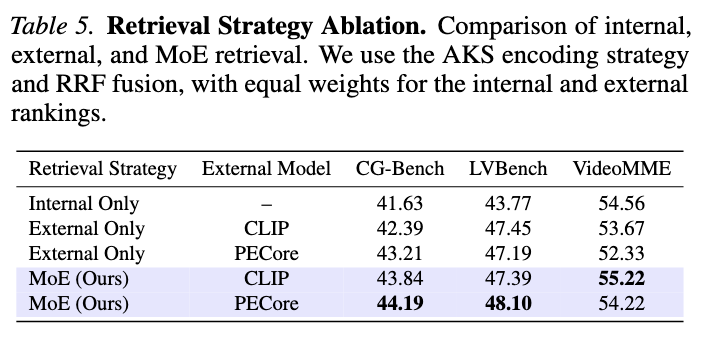
먼저, 토큰 수만 늘리면 성능이 하락함을 확인
-
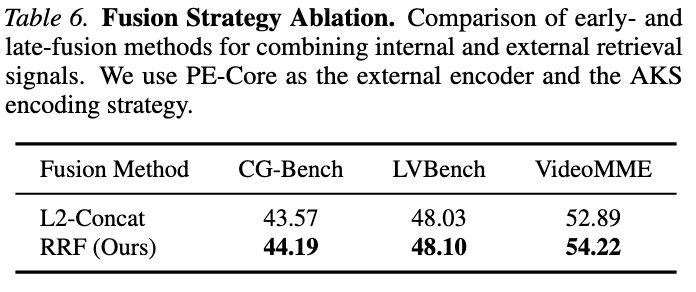
메인 실험 결과 (vs. ReKV)
-
분석
- AKS만 적용: CG-Bench +5.5%, LVBench +4.1%
- 이유: 인코딩 품질 향상으로 더 discriminative한 KV feature 생성
- AKS + MoE: CG-Bench 추가 +2.4%, LVBench 추가 +4.3%
- 이유: external retrieval 신호가 internal의 불안정성을 보완
- VideoMME에서는 external retrieval이 약간 성능 하락
- 이유: VideoMME는 holistic understanding 중심 → 특정 key frame 검색에 특화된 external retrieval과 맞지 않음
- 개인적인 의견
- 벤치마크의 성격(key frame retrieval vs. holistic understanding)에 따라 MoE의 효과가 달라진다는 점이 흥미로움
- AKS만 적용: CG-Bench +5.5%, LVBench +4.1%
-
-
실험 2: Online Streaming VQA

- 환경
- RVS-Ego, RVS-Movie: open-ended QA, LLM-as-a-Judge 방식으로 accuracy와 score 평가
- Latency, GPU memory, KV-Cache 크기도 함께 측정
- 분석
- RVS-Ego: ReKV 대비 +3.6%, latency는 거의 동일 (2.8s → 2.6s)
- RVS-Movie: 약 2% 하락
- 이유: AKS 압축이 너무 aggressive하게 작동했을 가능성
- KV-Cache 크기는 동일하게 유지 (11.1 GB/h)
- ⇒ 정확도와 효율성을 동시에 달성
- 환경
-
실험 3: Ablation - 인코딩 전략

- 정적 선택 (Variant A) vs. 동적 선택 (Variant B) 비교
- A.1 (Average pooling, ~4x): +3.85% (CG-Bench)
- A.2 (Dilated sampling, ~16x): +4.98% (CG-Bench)
- B.1 (Token merging, ~12x): +6.01% (CG-Bench)
- AKS (~16x): +5.46% (CG-Bench), 전반적으로 가장 안정적
- ⇒ 단순 token scaling이 아닌 adaptive compression이 필수임을 확인
- 정적 선택 (Variant A) vs. 동적 선택 (Variant B) 비교
-
실험 4: Ablation - Retrieval 전략
-
Internal only vs. External only vs. MoE 비교 (Table 5)
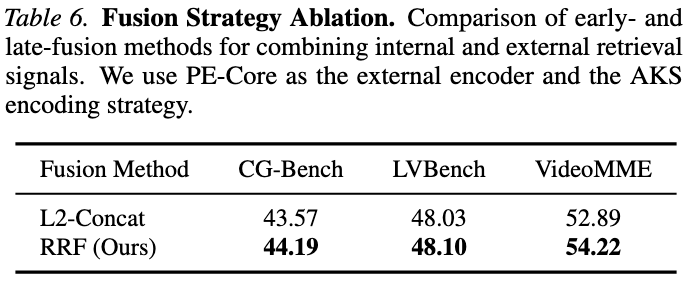
- External only (PECore): LVBench +3.42% (Internal 대비)
- MoE (PECore): CG-Bench와 LVBench 모두 최고 성능
- ⇒ 내부 + 외부 신호의 complementary 효과 실증
-
Fusion 방법 비교 (Table 6)
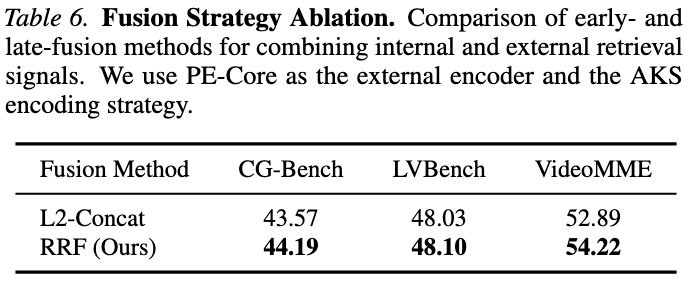
- L2-Concat vs. RRF
- RRF가 3개 벤치마크 모두에서 우수
- ⇒ 서로 다른 embedding space를 rank 기반으로 fusion하는 것이 raw score fusion보다 효과적
-
-
실험 5: Qualitative Results

- CG-Bench 샘플에서 ReKV(빨강)와 MemStream(파랑)의 retrieval 위치 비교
- ReKV: 영상 후반부에 편향된 retrieval → 잘못된 답변
- MemStream: ground-truth 세그먼트(초록)에 가까운 retrieval → 올바른 답변
- ⇒ AKS + MoE가 실제로 올바른 프레임을 찾는 데 효과적임을 질적으로도 확인
- CG-Bench 샘플에서 ReKV(빨강)와 MemStream(파랑)의 retrieval 위치 비교
5. 결과
-
기존 KV-cache 기반 스트리밍 방법(ReKV)은 프레임당 토큰이 적어 fine-grained 정보를 잃었고, 토큰 수를 늘리면 sliding window 내 중복으로 key feature의 구별력이 떨어져 query-frame 유사도가 후반 프레임에 편향되는 recency bias가 발생하며 retrieval quality와 QA 성능이 오히려 하락하는 문제가 있었음
-
인접 프레임 간 중복 패치를 제거하여 key feature의 변별력을 확보하는 Adaptive Key Selection과 내부 LLM과 외부 모델의 신호를 RRF로 결합하여 레이어별 Retrieval의 불안정성을 보완하는 Retrieval MoE를 활용한 MemStream 제안
-
Qwen2.5-VL-7B 모델에 대해 Offline/Streaming 환경에서 대부분 ReKV 대비 높은 성능을 달성하였음
-
한계점
- Qwen2.5-VL-7B 모델에 대해서만 실험이 이루어져 다른 모델에서의 일반화 성능이 불명확함
- 이전 논문과 마찬가지로 실험이 너무 부족하다고 느껴짐
