[Paper review] HERMES: KV Cache as Hierarchical Memory for Efficient Streaming Video Understanding
Paper review
목록 보기
13/14
1. 배경
-
Streaming Video Understanding의 어려움
- MLLM(Multimodal Large Language Model)은 오프라인 비디오 이해에서 큰 성과를 보임
- 그러나 실시간 스트리밍 비디오로 확장하면 3가지를 동시에 달성하기 어려움
- 안정적인 이해 성능
- 실시간 응답 (낮은 TTFT)
- 낮은 GPU 메모리 사용량
- 실제 예시
- 실시간 비디오 스트림에서 사용자가 질문을 던지면, 모델이 즉시 응답해야 함
- 하지만 비디오가 길어질수록 KV cache가 선형적으로 증가 → 메모리 폭발
-
기존 방법의 한계
- ReKV
- 모든 프레임의 KV cache를 저장하고 질문 시 retrieval 수행
- 메모리 소비가 매우 큼 (offloading해도 비효율적)
- 긴 비디오에서는 실용적이지 않음
- LiveVLM
- FIFO(First-In-First-Out) 방식으로 KV cache 관리
- 오래된 프레임의 KV를 무조건 삭제
- 초반 정보가 중요한 경우에도 잃어버림
- 공통 문제
- 질문이 도착하면 추가 연산(retrieval, re-encoding) 필요 → 실시간 응답 불가
- 모든 레이어에 동일한 압축 전략 적용 → 레이어별 역할 차이 무시
- ReKV
-
제안: HERMES
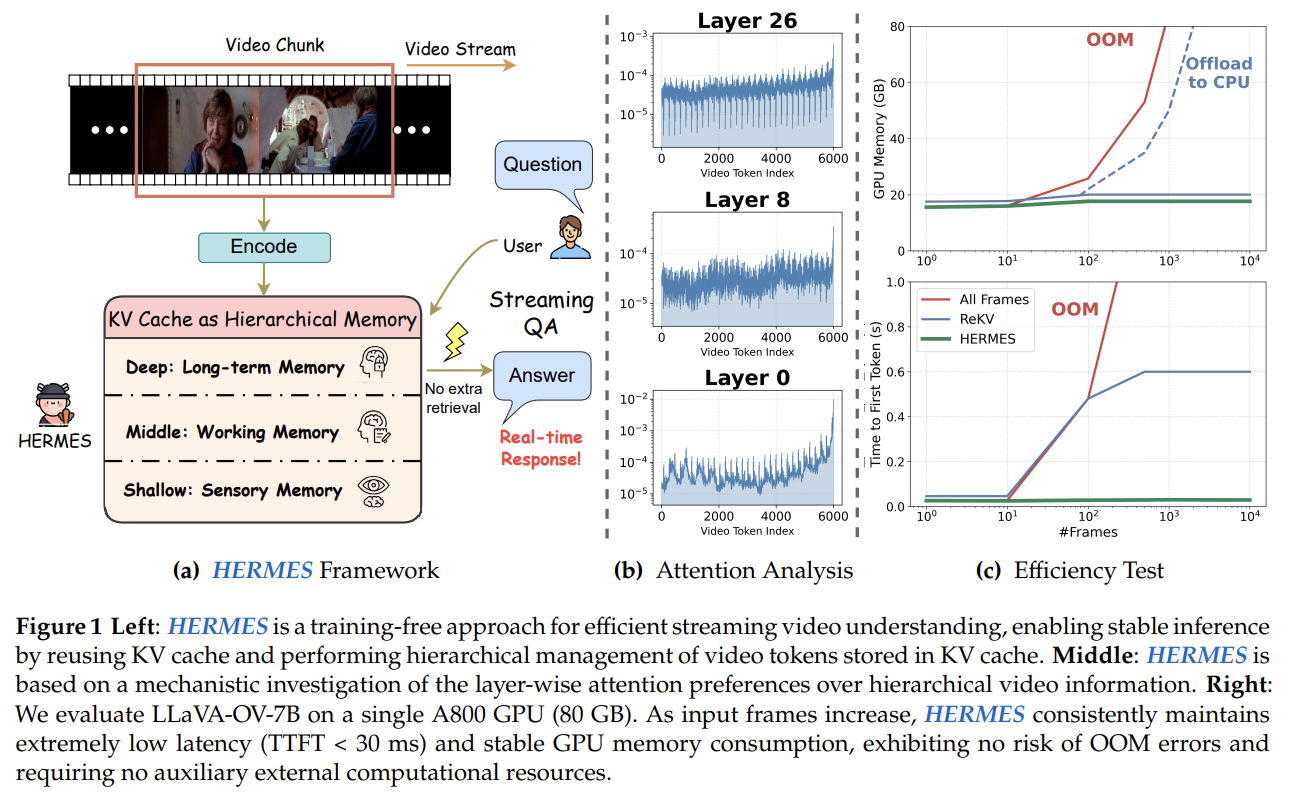
- 핵심 아이디어
- KV cache를 계층적 메모리(Hierarchical Memory)로 재해석
- Transformer의 각 레이어가 서로 다른 granularity로 비디오 정보를 저장한다는 관찰에 기반
- 주요 기여
- Training-free 아키텍처: 추가 학습 없이 기존 MLLM에 plug-and-play 적용
- 질문 도착 시 추가 연산 없이 KV cache를 바로 재사용 → 실시간 응답 보장
- 비디오 토큰을 최대 68% 줄이면서도 성능 유지 또는 향상
- 핵심 아이디어
2. 사전 지식
- KV Cache
- 정의
- Transformer의 self-attention에서 이전 토큰의 Key와 Value를 저장해둔 캐시
- 디코딩 시 이전 토큰을 다시 계산하지 않아도 되므로 추론 속도 향상
- 문제점
- 입력 시퀀스가 길어질수록 KV cache 크기가 선형 증가
- 스트리밍 비디오에서는 프레임이 계속 들어오므로 무한히 증가
- 정의
- Streaming Video Understanding
- 정의
- 비디오가 실시간으로 입력되는 상황에서 모델이 이해 및 질의응답을 수행하는 것
- 기존 방법과의 차이
- 오프라인: 전체 비디오를 한번에 입력 → uniform sampling 가능
- 스트리밍: 비디오 길이를 모르고, 질문 시점도 모름 → 동적 관리 필요
- 왜 어려운가?
- 메모리 제한 내에서 과거 정보를 유지해야 함
- 질문이 언제 올지 모르므로 항상 응답 준비 상태여야 함
- 정의
3. 방법
-
전체 아이디어
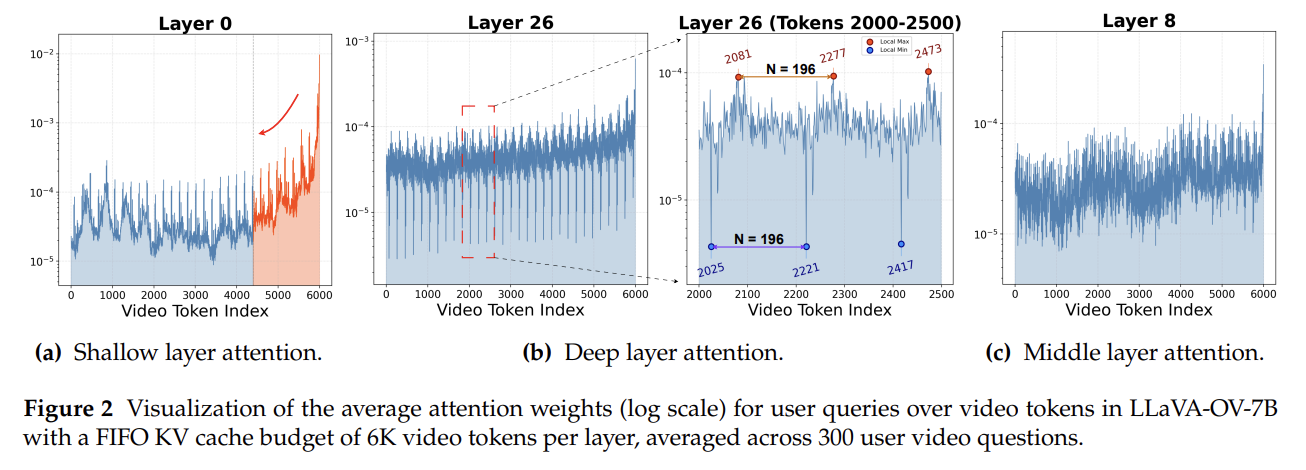
- Attention pattern에 대한 기계적 분석(mechanistic investigation)을 통해, LLM의 각 레이어가 비디오 정보를 서로 다른 수준으로 처리한다는 것을 발견
- Shallow layers: 최근 프레임에 집중 → 세밀한 시간적 정보
- Deep layers: 프레임 전반에 균일하게 attention → 전체적인 의미 정보
- Middle layers: 두 패턴의 중간
- 이를 인간의 기억 체계에 비유하여 계층적 메모리로 개념화
- Sensory Memory: Shallow layers → 방금 일어난 이벤트
- Working Memory: Middle layers → 중간 다리 역할
- Long-term Memory: Deep layers → 프레임 수준의 의미적 앵커
- Attention pattern에 대한 기계적 분석(mechanistic investigation)을 통해, LLM의 각 레이어가 비디오 정보를 서로 다른 수준으로 처리한다는 것을 발견
-
Hierarchical KV Cache Management
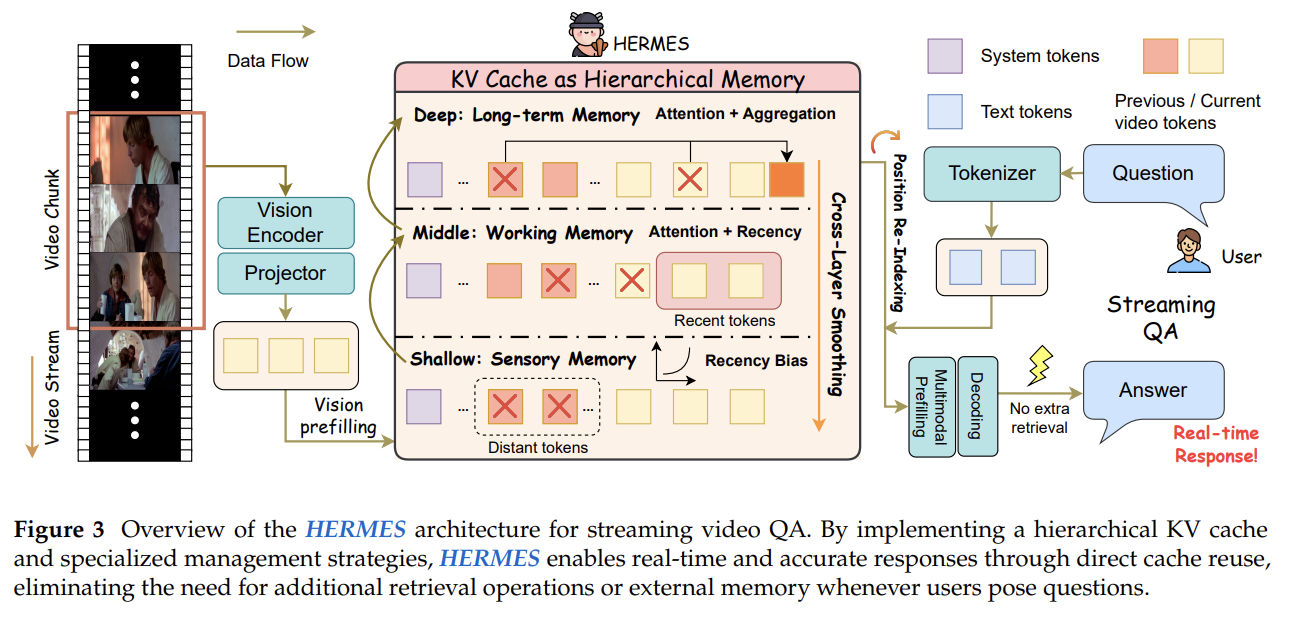
- 역할
- 레이어별로 서로 다른 KV cache 관리 전략을 적용
- 구체적 방법
- Shallow layers (Sensory Memory)
- 최근 프레임의 KV Cache를 더 많이 유지
- FIFO 방식에 가깝지만, 최신 정보에 높은 비중
- Deep layers (Long-term Memory)
- 프레임 수준에서 균일하게 KV Cache를 유지
- 오래된 프레임의 의미 정보도 보존
- Middle layers (Working Memory)
- 두 전략을 보간(interpolation)하여 적용
- Shallow layers (Sensory Memory)
- 왜 이 방법인가?
- 모든 레이어에 동일한 전략을 적용하면 특정 레이어의 정보 처리 특성을 무시하게 됨
- 레이어별 attention 패턴이 다르다는 실증적 관찰에 기반
- ⇒ 레이어별 최적화된 KV Cache 관리로 성능과 효율 동시 달성
- 역할
-
Cross-Layer Memory Smoothing
- 문제점
- 레이어마다 독립적으로 KV Cache를 관리하면, 인접 레이어 간 불일치 발생 가능
- 예: 어떤 레이어에서는 프레임 A의 KV 값이 유지되고, 바로 다음 레이어에서는 삭제됨
- 해결책
- 인접 레이어 간 KV Cache 구성을 smoothing
- 레이어 간 급격한 변화를 방지하여 안정적인 정보 흐름 유지
- ⇒ 계층적 메모리의 자연스러운 전환
- 문제점
-
Position Re-indexing
- 문제점
- KV cache에서 일부 토큰이 eviction되면, 남은 토큰의 position ID에 공백(gap)이 생김
- Transformer의 positional encoding이 연속적인 위치를 기대하므로 성능 저하 가능
- 해결책
- Lazy Re-indexing (스트리밍용)
- position index가 모델 한계에 근접할 때만 재할당 수행
- 연산 오버헤드가 낮고, 최근 토큰의 위치 정보를 안정적으로 보존
- Eager Re-indexing (오프라인용)
- 매 압축 단계마다 position ID를 재할당
- 연산 비용은 높지만 장기적인 위치 정보 안정성 확보
- ⇒ 용도에 따라 전략을 선택하여 positional encoding의 일관성 보장
- Lazy Re-indexing (스트리밍용)
- 문제점
-
전체 동작 Flow
- 순서
- 1단계: 새로운 비디오 프레임 chunk가 도착하면, visual encoder로 인코딩 후 LLM에 통과시켜 KV cache 생성
- 2단계: 각 레이어별로 계층적 메모리 전략에 따라 KV cache를 관리 (sensory/working/long-term)
- 3단계: Cross-layer smoothing으로 레이어 간 일관성 유지
- 4단계: Position re-indexing으로 위치 정보 정리
- 5단계: 사용자 질문이 도착하면, 추가 연산 없이 현재 KV cache를 그대로 재사용하여 응답 생성
- ⇒ 질문 도착 시 추가 retrieval/re-encoding 없이 즉시 응답 가능
- 순서
4. 실험
-
실험 1: Streaming Video QA
- 환경
- StreamingBench, OVO-Bench: 실시간 비디오 이해 벤치마크
- 실시간 시각 인식(real-time visual perception)과 과거 회상(backward tracing) 태스크 포함
- 실험 결과
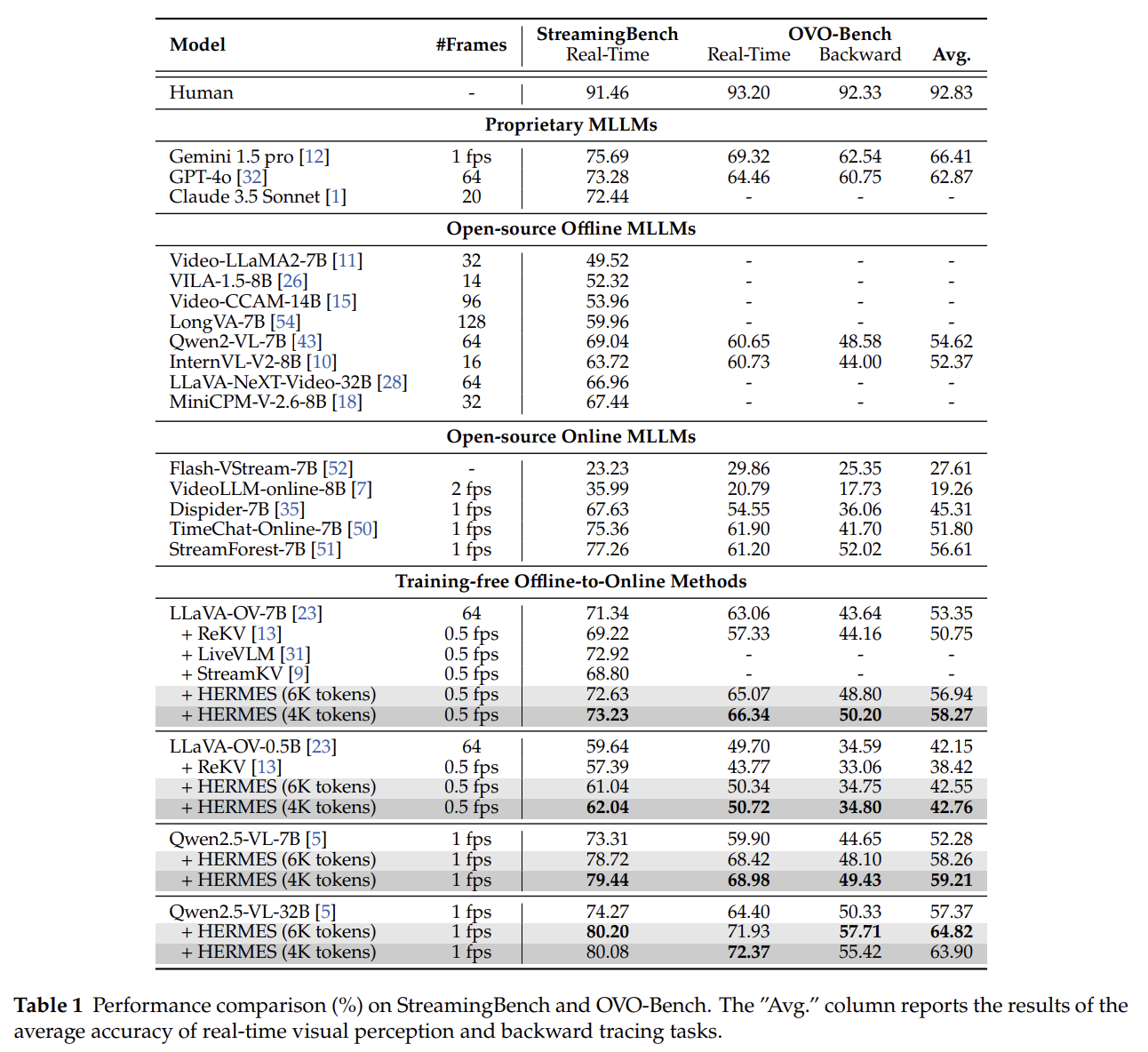
- 분석
- HERMES가 base model 및 training-free 방법들을 능가
- 기존 방법 대비 적은 비디오 토큰(4K/6K)으로도 더 높은 정확도 달성
- ⇒ 계층적 메모리가 스트리밍 환경에서 효과적임을 입증
- HERMES가 base model 및 training-free 방법들을 능가
- 환경
-
실험 2: RVS-Ego, RVS-Movie
- 환경
- 에고센트릭(1인칭) 비디오와 영화 비디오에서의 스트리밍 QA
- GPT-3.5-turbo-0125로 정확도(Acc)와 점수(Score, 1~5점) 평가
- 실험 결과
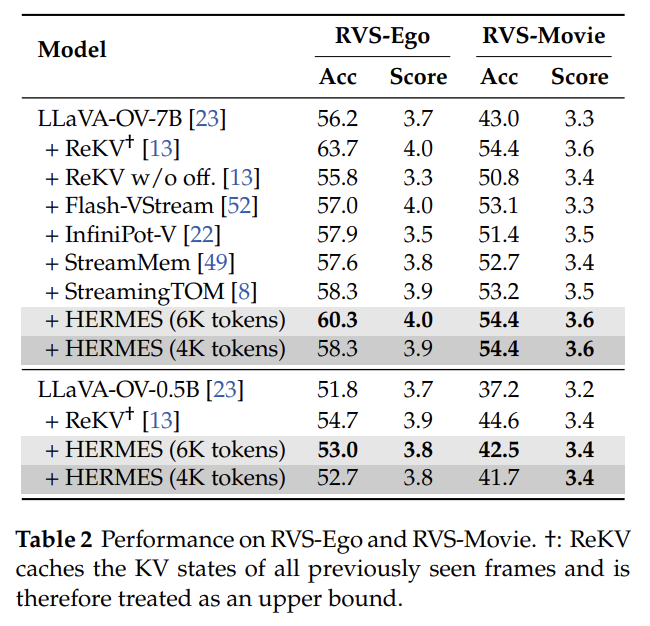
- 분석
- ReKV는 모든 프레임을 KV Cache에 저장하므로 성능 상한선(upper bound) 역할
- HERMES는 base model대비 최대 11.4% 성능 향상 (RVS-Movie 기준)
- 훨씬 제한된 메모리 예산(4K~6K 토큰)만으로도 ReKV에 근접하는 성능 달성
- 단, RVS-Ego에서는 ReKV(63.7%)를 완전히 따라잡지는 못함
- RVS-Movie에서는 동등한 수준(54.4%) 달성
- ⇒ 효율적인 KV Cache 관리만으로도 전체 KV Cache 저장에 근접한 성능 달성 가능
- 환경
-
실험 3: Offline Video Benchmarks
- 환경
- 오프라인 비디오 이해 벤치마크 (기존 방법들과의 공정 비교)
- 실험 결과
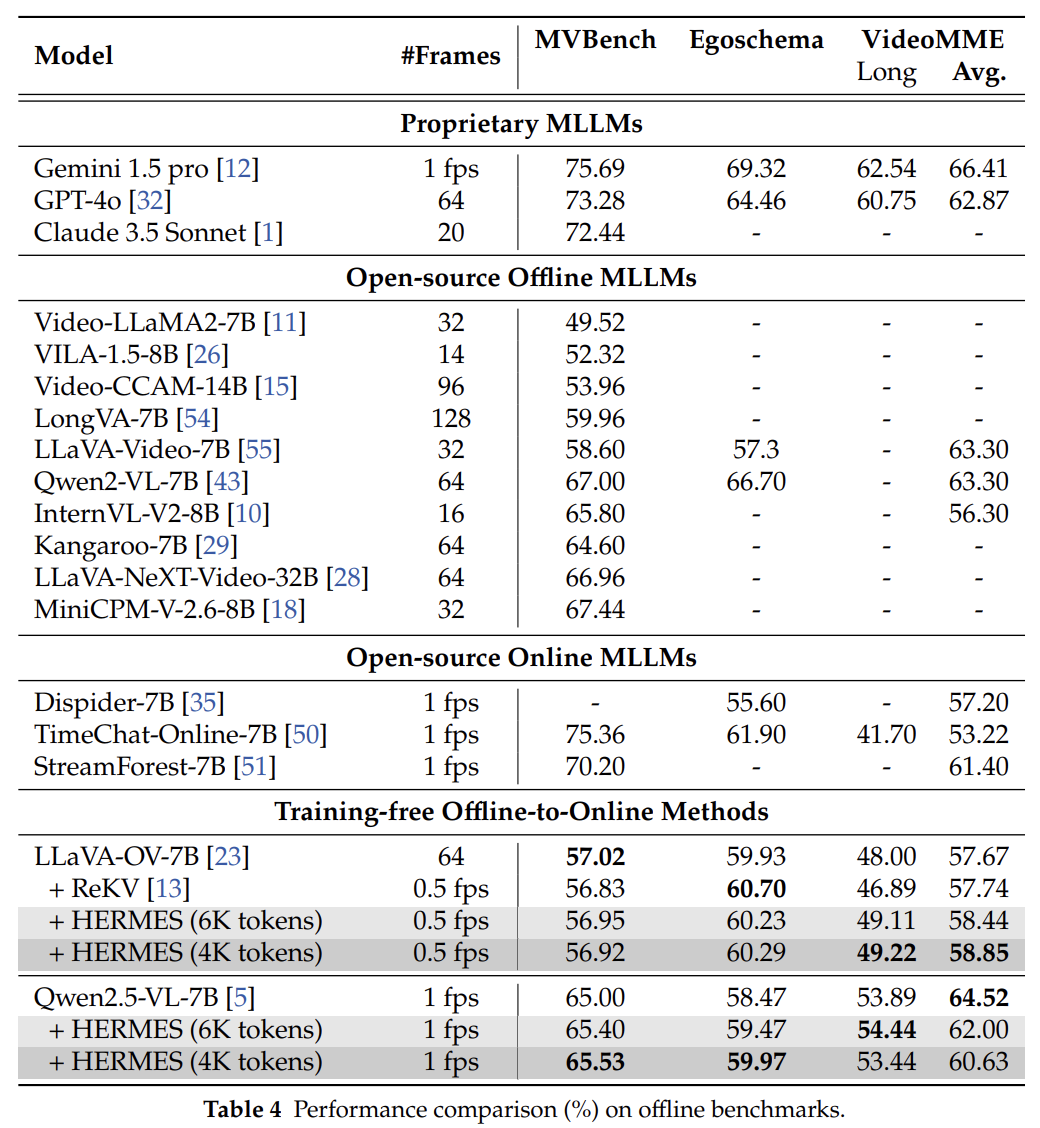
- 분석
- 고정된 메모리 예산에서도 동등하거나 조금 더 나은 성능 달성
- 스트리밍뿐 아니라 오프라인에서도 나쁘지 않은 성능
- 환경
-
효율성 분석
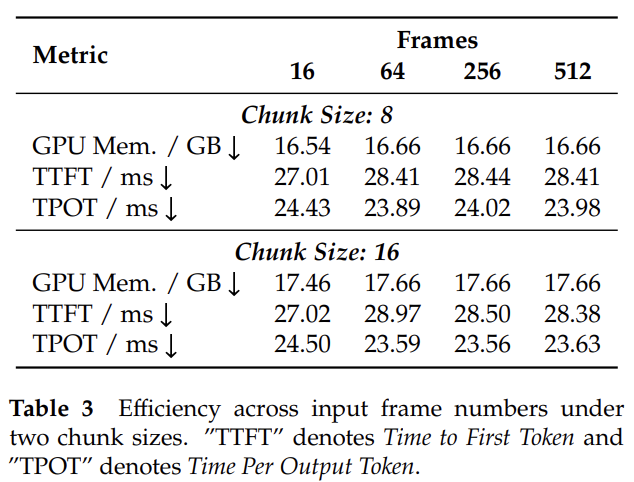
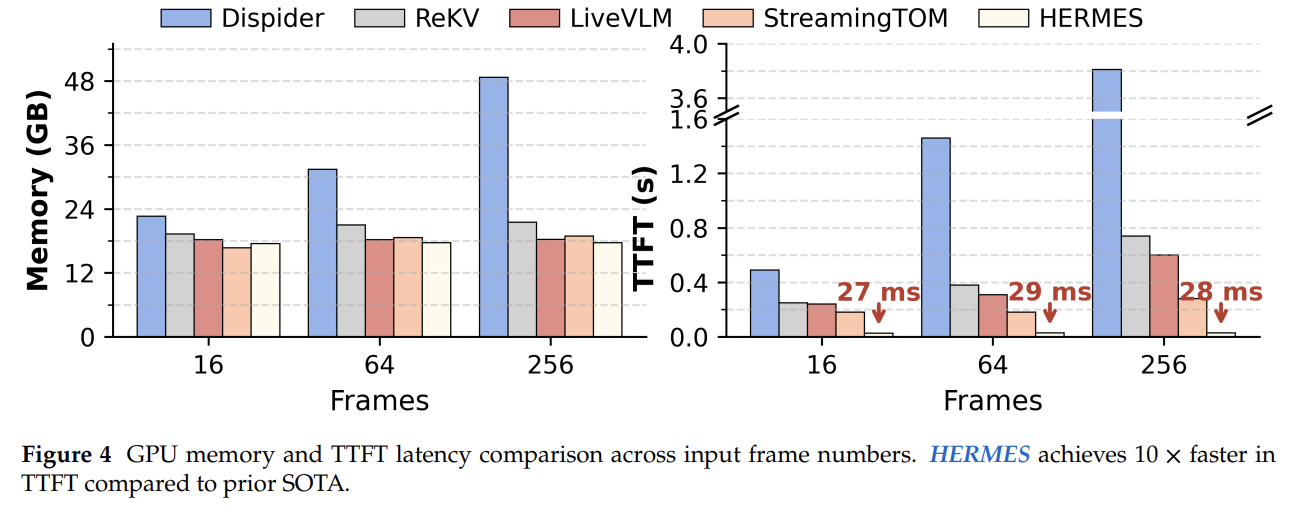
- TTFT (Time to First Token)
- 기존 SOTA인 StreamingTOM 대비 10배 빠른 TTFT 달성
- 프레임 수와 무관하게 TTFT 약 27~29ms 수준으로 일정하게 유지 (Table 3)
- GPU 메모리
- 16프레임~512프레임까지 약 16~17GB로 안정적 유지 (Table 3)
- 고정 메모리 예산 덕분에 프레임이 늘어도 OOM 위험 없음
- 256프레임 기준 LiveVLM 대비 약 절반 정도의 peak 메모리 (Figure 4)
- TPOT (Time Per Output Token)
- 약 23~25ms 수준으로 프레임 수 및 청크 크기와 무관하게 안정적 (Table 3)
- => 실시간 응답이 가능함을 보임
- TTFT (Time to First Token)
5. 결과
- 기존 Streaming Video MLLM은 실시간 응답, 성능 유지, 낮은 메모리 사용을 동시에 달성하지 못했으며, 특히 ReKV는 메모리 과다, LiveVLM은 FIFO 기반으로 초기 정보를 잃는 한계가 있었음
- HERMES는 Transformer 레이어별 attention 패턴을 분석하여 KV cache를 Sensory/Working/Long-term Memory로 계층화하고, cross-layer smoothing과 position re-indexing을 적용한 training-free 아키텍처를 제안
- 고정된 메모리 예산만으로도 streaming 벤치마크에서 성능 향상과 대폭 빠른 응답 속도를 동시에 달성하여, 실시간 스트리밍 비디오 이해에 효율성과 정확성을 모두 확보함

브라우니맛있디