[Paper review] Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Paper review
1. 배경 지식
Open Domain Question Answering
- 정해진 지문 없이, 방대한 문서 집합(Wikipedia)에서 질문에 대한 답을 찾아내는 태스크
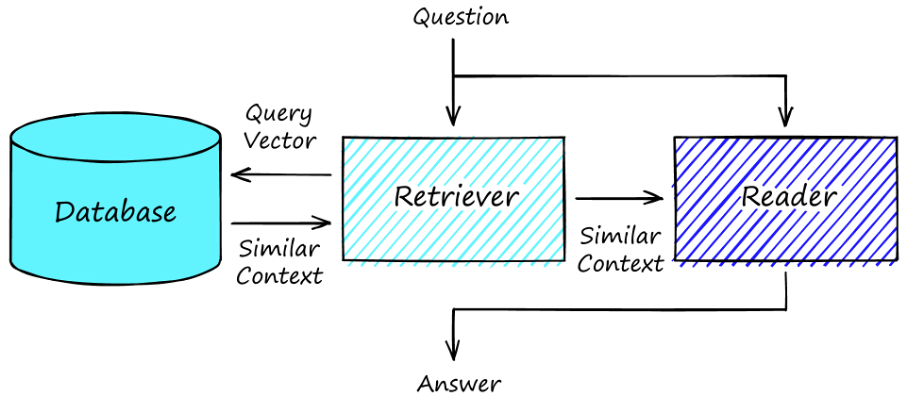
- Question에 대해 Retriever가 Knowledge Base에서 Search하여 불러온 Passage에서 Reader가 Answer를 추론
Knowledge-Intensive Task (KIT)
- 단순히 언어적 능력(문법, 문맥 파악)만으로는 풀 수 없고, 반드시 외부 지식에 접근해야만 해결이 가능한 문제
-
학습 이후의 지식에 대한 문제, 정확한 사실에 대한 답변을 해야하는 문제
-
Ex) “오늘 삼성전자 주가 알려줘”, “로또 1회차 당첨번호 알려줘”
-
Open Domain Question Answering (ODQA), Fact Checking, Slot Filling, …

-
Parametric Memory & Non-parametric Memory
- Parametric Memory
- 학습을 통해 모델이 기억하고 있는 지식 (모델 파라미터에 저장된 지식)
- Ex) 중간고사를 위해서 전공 책의 200페이지 까지만 공부한 학생
- 문제점 (LLM의 한계점)
- 학습이 끝난 이후의 지식 존재 X (200페이지 이후로는 지식이 없음)
- Hallucination 발생 (공부를 했음에도 잘못된 답을 작성)
- 학습에 사용된 모든 지식을 기억하려면 모델의 크기가 커져야 함
- Non-parametric Memory
- 모델 외부에 존재하는 거대한 문서 데이터베이스
- Ex) 시험 시 참고할 수 있는 컨닝 페이퍼
- 아이디어
- Closed-book test가 아닌 Open-book test처럼 모델이 답변을 생성해낼 때 자료를 찾아보게 하자
Prior Works in Open Domain Question Answers (ODQA)
- DrQA (Reading Wikipedia to Answer Open-Domain Questions, Chen et al, ACL 2017)
- 정답을 외부 데이터베이스에서 찾자 (단순 키워드 매칭)
- ORQA (Latent Retrieval for Weakly Supervised Open Domain Question Answering, Lee et al, ACL 2019)
- Retriever(검색기)를 훈련시키자
- REALM (REALM: Retrieval-Augmented Language Model Pre-Training, Guu et al, PMLR 2020)
- Retriever와 Reader를 하나의 모델 처럼 end-to-end 학습시키자
- ODQA 연구들의 한계점
- 문장을 생성하는 것이 아닌 단순 정답 추출 작업으로만 연구가 됨 (정답을 찾아 표시하는 것)
2. 서론
Limitations of Prior Works
- Extraction (추출형 방식)
- 기존 ODQA 연구들은 대부분 문서에서 정답을 찾아내는 추출 방식
- 질문에 대해 설명하거나, 여러 정보를 종합해 문장을 만들어내는 생성형 답변이 불가능
- Training Overhead
- REALM은 사전학습 단계에서부터 Retriever를 학습시켜야 함
Limitations of Generative Models
- Hallucination
- 일반적인 답변이나 문장은 잘 생성해내지만, 사실이 아닌 답을 사실처럼 생성할 수 있음
- Non-Explainable
- 어떤 근거로 답변을 생성해냈는지 명확하게 알 수 없음
- Hard to expand or revise
- 새로운 지식을 주입(재학습, 파인튜닝 등)하기 어려움
Motivation
- 똑똑하고 말 잘하는 생성 모델(BART)에 검색 모델(Retriever)을 붙이고 하나의 모델처럼 학습시키자
3. 방법
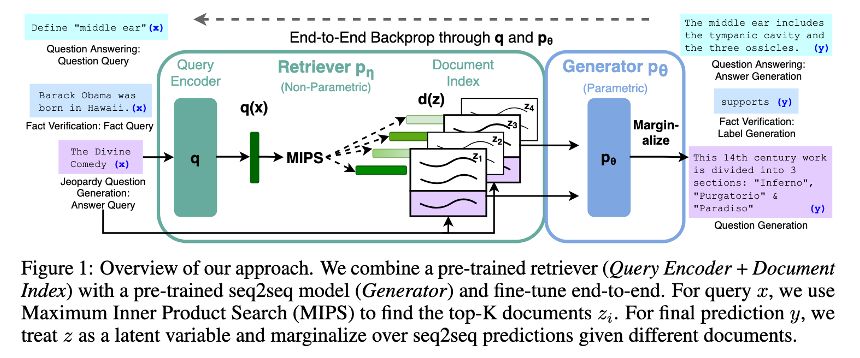
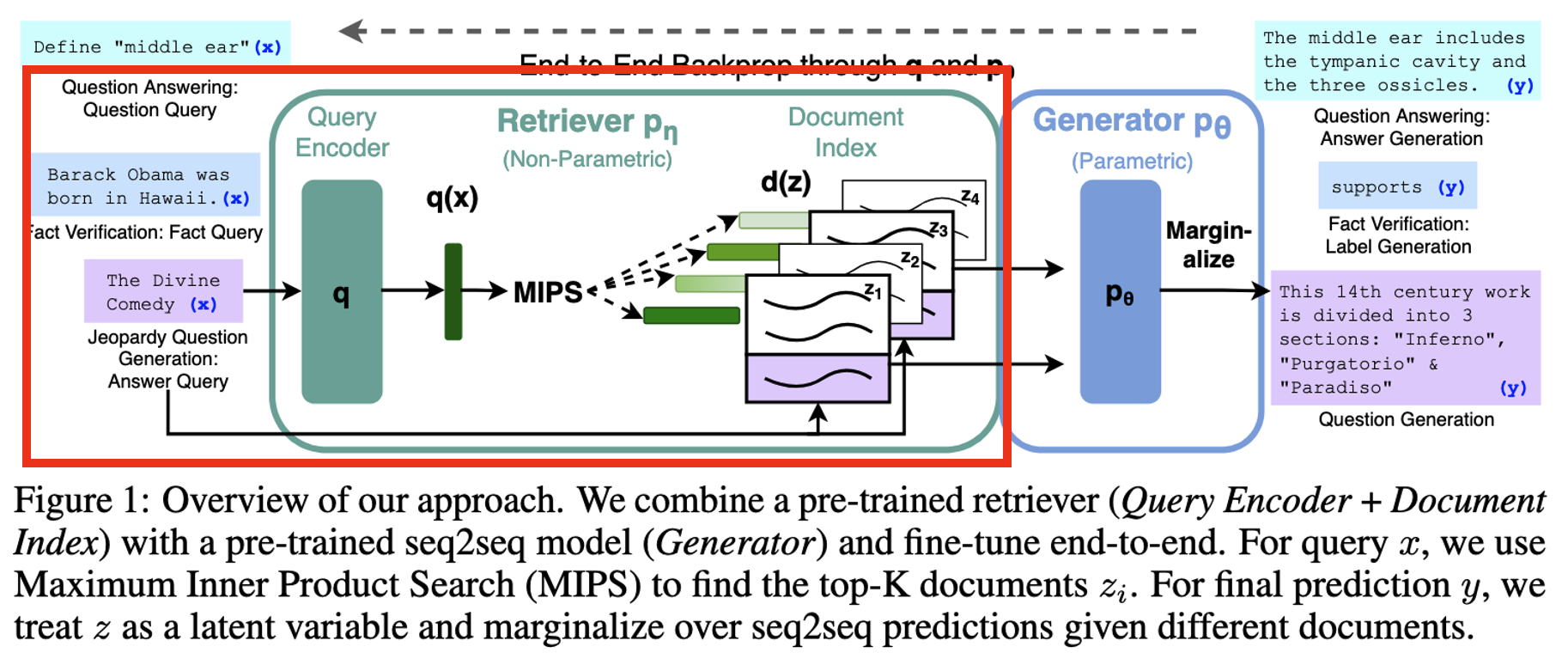
Retrieval-Augmented Generation (RAG)
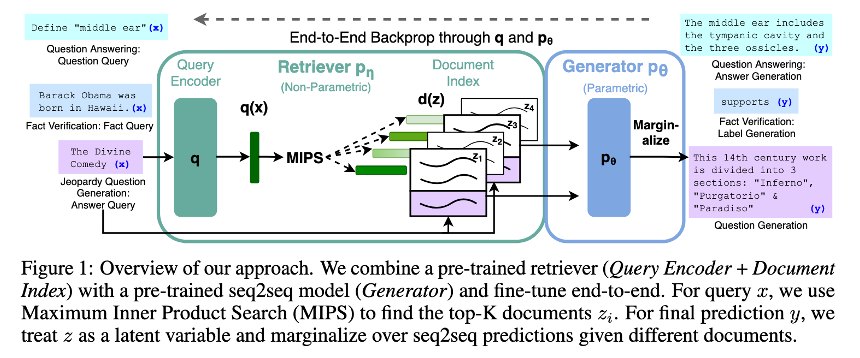
- 입력 시퀀스 x가 주어졌을 때, 외부 지식 문서 z를 검색하고, 이를 바탕으로 출력 시퀀스 y를 생성하는 모델
Step 1. Retrieval ()
- DPR (Dense Passage Retrieval)를 통해 질문과 문서를 벡터 공간으로 변환
- Document Encoder
- 참고할 문서 를 를 통해 벡터 로 변환 및 저장
- Query Encoder
- 사용자의 질문 를 를 통해 벡터 로 변환
- MIPS (Maximum Inner Product Search)
- 질문 벡터와 내적이 가장 큰 Top-K 문서를 검색
- : Retriever의 학습 가능한 파라미터
Step 2. Generator ()
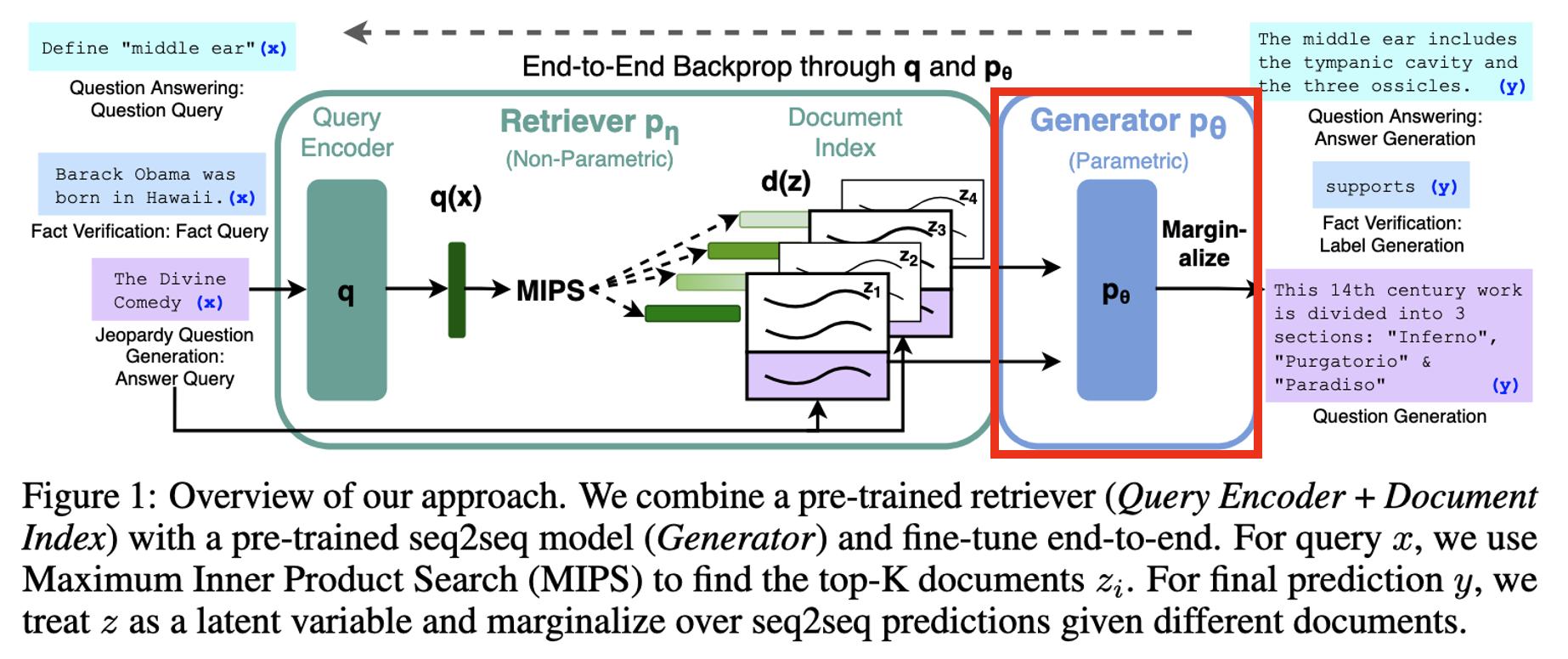
- Generator
- 검색된 문서 와 질문 를 concat하여 BART-large에 입력으로 넣음
- 각 토큰 를 생성할 확률은 이전 토큰들 , 원래 질문 , 검색된 문서 에 의존
- 는 Generator의 학습 가능한 파라미터
Step 3. Marginalize
- RAG-Sequence Model
- 하나의 문서 – 하나의 문장
- RAG-Token Model
- 하나의 문서 – 하나의 토큰 (각 토큰 마다 다른 문서를 참고할 수 있음)
- 여러 문서의 정보를 활용 해야할 때 이점
Step 4. Training
- 정답 가 나올 확률 를 최대화하는 것이 목표 -> Negative Log-likelihood를 이용해 최소화
Step 5. Decoding
- RAG-Token
- 다음 단어 하나 y_i를 생성할 때마다 검색된 상위 k개의 문서 z들의 확률을 합쳐서 계산
- 를 그대로 표준 빔 서치 디코더에 넣어 사용
- RAG-Sequence

- 한 문장을 하나의 문서에서 생성 -> 토큰 단위로 분해 X -> 일반적인 빔 서치 사용 불가
- 문서마다 빔 서치를 돌리고 나중에 합치는 방식
- 상위 k개의 각 문서 z에 대해 각각 빔 서치를 수행하여 가능한 답변 후보 집합 Y생성
- 생성된 답변 후보 y가 특정 문서의 빔 서치 결과에 없는 경우 (빨간 박스)
- Thorough Decoding
- Y가 생성될 확률을 구함 (Forward Pass 수행) -> Y가 커지면 계산이 많아져 느림
- Fast Decoding
- Y가 생성될 확률을 0으로 가정 -> Forward Pass가 필요 없어 빠름
4. 실험
Experimental Setup
- Non-parametric knowledge source
- Wikipedia(2018.12 Dump), Disjoint 100-word chunks, 21M Documents
- Vector Indexing
- FAISS (Facebook AI Similarity Search)
- Model
- Retriever
- BERT-base 기반의 DPR
- Generator
- BART-large (406M Parameters)
- Max Length: 1024 token (Question + Top-k Documents(k: 5/10))
- Retriever
5. 결과
Open Domain Question Answering & Generation/ Classification
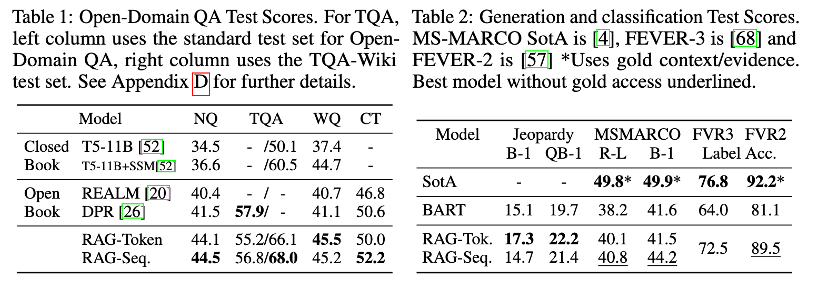

- Task
- Natural Questions (NQ), TriviaQA (TQA), WebQuestions (WQ), CuratedTrec (CT)
- Jeopardy Question Generation: 정답을 보고 질문 생성
- MS-MARCO: 질문에 대한 긴 서술형 답변 생성
- FEVER: 사실 검증
- Table 2의 SotA에 붙어있는 *: 정답 문서(Gold context)를 미리 알고 품
- Table 1(ODQA)는 Thorough Decoding, Table 2는 Fast Decoding 사용
Document Posterior Analysis (Jeopardy Question Generation)

- RAG-Token 모델이 문장을 생성할 때, 각 단어를 생성할 때 마다 어떤 문서를 참고하는지 시각화 한 표
- “The Sun Also Rises” 생성 시
- Doc 2에 진한 파란색 => Doc 2 참고하여 생성
- “A Farewell to Arms” 생성 시
- Doc 1에 진한 파란색 => Doc 1 참고하여 생성
- 그 외
- 전반적으로 색깔 변화가 없음
- 문서를 참고하지 않고 BART 모델의 기본 능력 만으로 생성
- “The Sun Also Rises” 생성 시에도 모든 토큰이 Doc2가 진한 것이 아니라 “Sun”만 진함
- Guide 역할, “The Sun” 이후로는 BART가 알고 있기에 모델 자체의 지식(parametric memory)으로 생성
Other Experiments
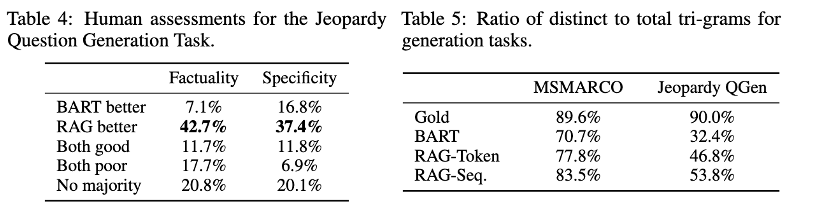
- Table 4
- BART / RAG 가 생성한 문장을 인간이 평가(사실인지?/ 구체적인지?)
- Table 5
- 생성된 텍스트의 다양성(tri-gram) 평가
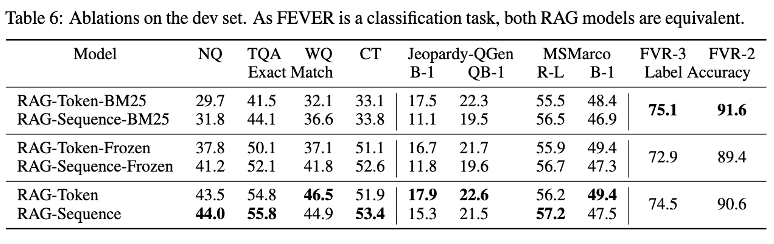
- Table 6
- Retriever를 DPR이 아닌 BM25 사용/ Generator만 학습(Retriever 고정) / Retriever & Generator 모두 학습
- Index hot-swapping
- 2016년 wiki와 2018년 wiki의 인덱스(문서 데이터베이스)만 교체 (모델은 그대로)
- 모델의 답변이 인덱스의 변화에 따라 바뀜 => 모델의 재학습 없이 인덱스만 바꾸더라도 지식 갱신 가능
Effect of Retrieved Documents
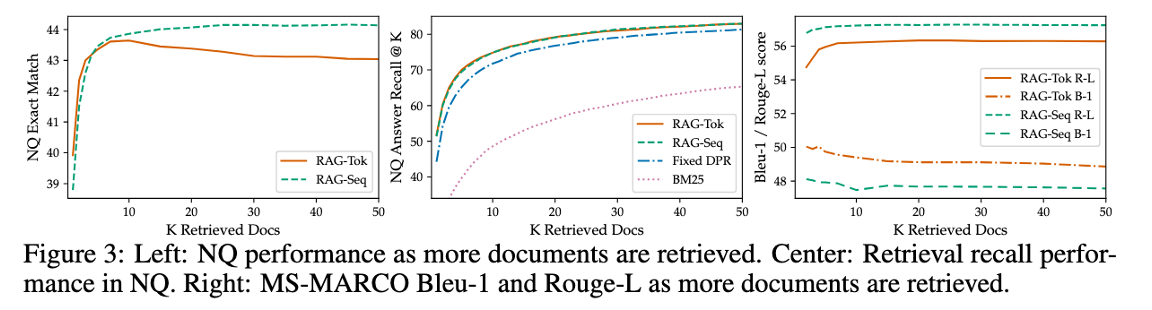
- 검색하는 문서의 개수 K를 늘렸을 때 성능 변화 그래프
- Left (QA 성능)
- RAG-Token 모델은 k=10 이후로 성능이 떨어짐 (너무 많은 정보는 오히려 성능 저하 요인으로 작용)
- Center (Recall 성능)
- 당연히 검색하는 문서가 많아질 수록 정답을 찾을 확률이 높아짐
- Right (Generation 성능)
- Bleu-1: 단어 일치, Rouge-L: 요약
- 요약(상단)의 경우 문서가 많아질수록 성능 상승
- 단어 일치(하단)의 문서가 많아질수록 성능 하락
6. 결론
-
기존 언어 모델은 지식을 파라미터로만 저장하여 새로운 정보를 학습하기 어렵고, 환각 문제가 발생하는 문제
-
이러한 문제를 해결하려는 사전 연구들은 정답을 단순히 추출하는 수준의 한계를 가짐
-
사전 학습된 Generation 모델(BART)와 Retriever 모델(DPR)을 결합하여 문서를 검색하고 이를 바탕으로 문장을 생성하는 과정을 End-to-End로 파인 튜닝하는 RAG(Retrieval-Augmented Generation) 모델을 제안
-
RAG 모델은 다양한 NLP task에서 SOTA 성능을 달성하였고, 기존 모델들보다 사실적이고 구체적인 텍스트를 생성해내는 능력을 가짐
-
또한, 모델의 재학습 없이 문서 데이터베이스(인덱스) 교체를 통해 지식을 갱신할 수 있는 유연성을 가짐
7. RAG의 등장 이후 제안된 방법들
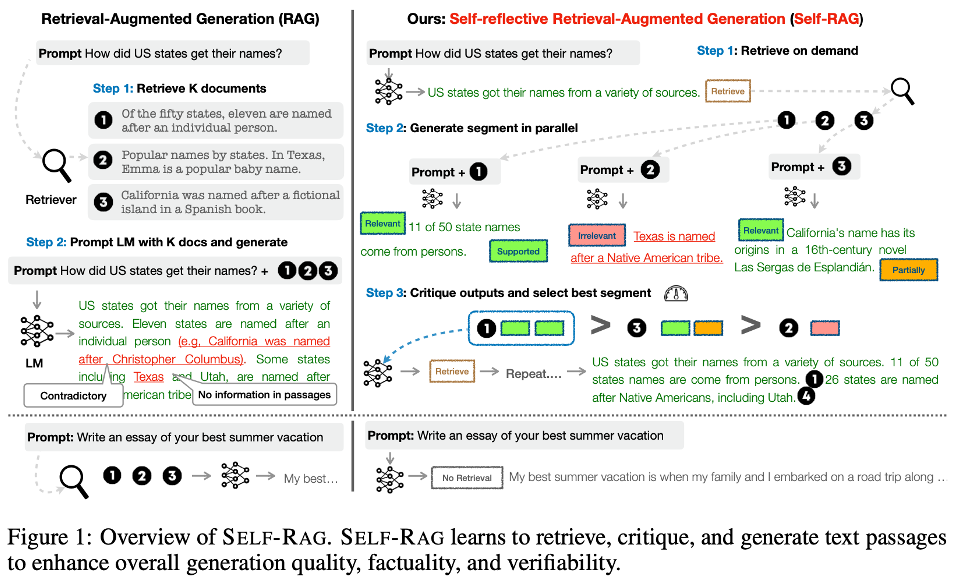
- Self-RAG (ICLR 2024 Oral)
-
Problem: 질문이 들어오면 무조건 답변하는 특성으로 검색된 문서에 정답이 없다면 잘못된 답변을 함
-
Key Idea: 스스로 비평하자!
-
4가지 종류의 특수 토큰을 함께 학습 (지금 검색이 필요한가?, 문서와 질문이 관련이 있나? 등)
-
모델은 추론 과정에서 이 토큰들을 내뱉으며 스스로의 행동을 제어
-
- GraphRAG (2024, Microsoft)
-
Problem: 포괄적 질문에 대한 답변 성능이 떨어짐
-
Key Idea: 나무가 아닌 숲을 보자!
-
텍스트를 최적의 크기로 쪼개고, LLM을 통해 핵심 개체(Node)와 관계(Edge)를 추출
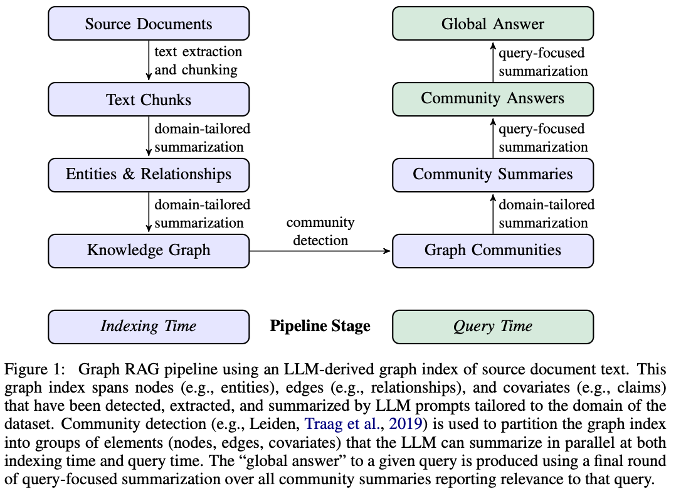
-
- Agentic RAG (Survey, 2025)
-
Problem: 복잡한 질문은 한 번의 검색으로 해결하기 어려움
-
Key Idea: 단순 검색이 아니라 스스로 생각해서 문제를 풀자!
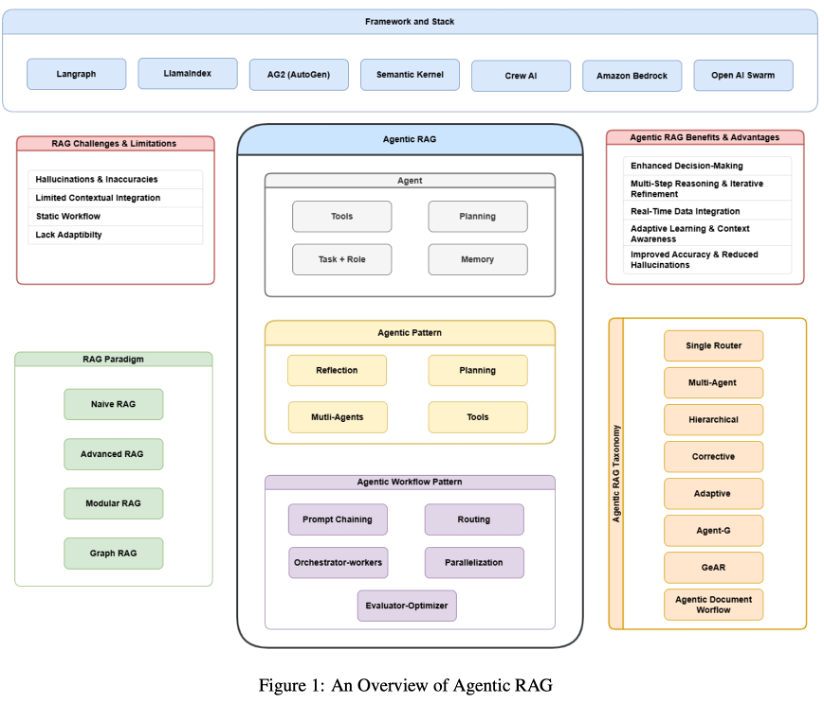
-
