RoBERTa: A Robustly Optimized BERT Pretraining Approach
RoBERTa는 BERT를 발전시킨 모델이다.
-
Introduction
BERT가 상당히 덜 훈련되었음을 발견하고, BERT 모델 훈련을 개선하기 위한 방법을 제안한다. 그리고 이를 RoBERTa라고 명명했다.BERT와 다른 점은 다음과 같다.
1) 더 긴 시간동안 더 큰 배치 크기로 더 많은 데이터를 사용해 훈련.
2) 다음 문장 예측 목표를 제거.
3) 더 긴 시퀀스로 훈련.
4) 훈련 데이터에 적용되는 마스킹 패턴을 동적으로 변경
5) 비공개 데이터셋과 크기가 비슷한 대규모 데이터셋(CC-NEWS)를 수집하여 훈련데이터 크기의 영향을 더 잘 통제.GLUE와 SQuAD에서 기존 BERT보다 향상된 성능을 보여주었고, GLUE 작업 중 4개(MNLI, QNLI, RTE, STS-B), SQuAD, RACE에서 SOTA를 달성했다.
이 논문의 contribution은 다음과 같다.
1) BERT의 중요한 설계 선택 및 훈련 전략을 제시하고, 더 나은 다운스트림 작업 성능을 이끄는 대안을 도입
2) 새로운 데이터셋인 CC-NEWS를 사용하여, 사전 학습에 더 많은 데이터를 사용하는 것이 다운스트림 작업 성능을 더욱 향상시킨다는 것을 확인.
3) 적절한 설계 아래에서 masked language model 사전 학습이 다른 방법들과 경쟁력이 있음. -
Background
이 섹션에서는 BERT(Devlin et al., 2019)의 사전 학습 접근 방식과 다음 섹션에서 실험적으로 검토할 일부 훈련 선택 사항에 대해 간략히 설명한다.
2.1. Setup
BERT는 두개의 세그먼트 과 을 입력받는다. 세그먼트는 보통 두 개 이상의 자연어 문장으로 구성된다. 이 두 세그먼트는 BERT에 하나의 입력 시퀀스로 제공되며, 특수 토큰이 이를 구분한다: [CLS] [SEP], [EOS]. M과 N은 M+N < T가 되도록 제한하며, 여기서 T는 훈련 중 최대 시퀀스 길이를 제어하는 파라미터이다.
모델은 먼저 대규모 라벨이 없는 텍스트 말뭉치에서 사전 학습되며, 이후에 최종 작업용 라벨이 있는 데이터를 미세 조정된다.
2.2.Architecture
BERT는 현재 널리 사용되는 트랜스포머 아키텍처를 사용한다. 우리는 L개의 층을 가진 트랜스포머 아키텍처를 사용한다. 각 블록은 A개의 셀프 어텐션 헤드와 hidden layer H를 사용한다.
2.3.Training Objectives
pretraing 중 BERT는 두 가지 목표를 사용한다. Masked Language Model과 next sentence prediction(NSP).
1) MLM: 입력 시퀀스에서 임의로 선택된 일부 토큰이 선택되어 특수토큰 [MASK]로 대체된다. MLM의 목표는 마스크된 토큰을 예측하는 교차 엔트로피 손실이다. BERT는 입력 토큰의 15%를 균일하게 선택하여 대체할 가능성이있는 토큰을 지정한다. 선택된 토큰 중 80%는 [MASK]로 대체되고, 10%는 변경되지 않으며, 나머지 10%는 무작위로 선택된 어휘 토큰으로 대체된다.
2) NSP: 두 세그먼트가 원래 텍스트에서 서로 이어지는지 여부를 예측하는 이진 분류 손실이다. 긍정 예시는 텍스트 말뭉치에서 연속적인 문장을 가져와 생성되며, 부정 예시는 서로 다른 문서의 세그먼트를 짝지어 생성된다. 긍정 및 부정 예시는 동일한 확률로 샘플링된다. NSP의 목표는 문장 쌍 간의 관계를 추론해야 하는 자연어 처리와 같은 다운스트림 작업 성능 개선을 위해 설계되었다.
2.4.optimization
1) BERT는 Adam(Kingma and Ba, 2015) 옵티마이저를 사용하여 최적화되며, 다음과 같은 파라미터로 설정된다: β₁ = 0.9, β₂ = 0.999, ǫ = 1e-6, 그리고 0.01의 L2 weight decay.
2) 학습률은 처음 10,000 스텝 동안 점진적으로 증가하여 1e-4의 최대값에 도달한 후, 선형적으로 감소한다.
3) BERT는 모든 층과 어텐션 가중치에 0.1의 드롭아웃을 적용하며, GELU 활성화 함수(Hendrycks and Gimpel, 2016)를 사용한다.
4) 모델은 최대 길이 T = 512 토큰으로 구성된 B = 256 시퀀스를 포함하는 미니배치로 S = 1,000,000번 업데이트하는 동안 사전 학습된다.
2.5 data
총 16GB의 압축되지 않은 텍스트
1) BERT는 BOOKCORPUS(Zhu et al., 2015)
2) 영어 WIKIPEDIA의 조합 -
Experimental Setup
3.1.Implementation
1) 주로 2장에서 제시한 BERT 최적화 하이퍼파라미터를 따르되, 최대 학습률과 워밍업 단계 수는 각각의 설정에 맞게 별도로 조정했다.
2) Adam 옵티마이저의 epsilon 값에 대해 훈련이 매우 민감하다는 것을 발견했으며, 경우에 따라 이를 튜닝하면 성능이 향상되거나 안정성이 개선되는 것을 확인했다.
유사하게, 대용량 배치 크기로 훈련할 때 β₂를 0.98로 설정하면 안정성이 향상된다는 것을 발견했다.
3) 최대 T = 512 토큰 길이의 시퀀스로 사전 학습을 진행했다. 오직 전체 길이 시퀀스로만 훈련했으며 혼합 정밀도 부동소수점 연산을 사용했다.
3.2.Data
BERT-style pretraining은 대량의 텍스트에 크게 의존한다.
다양한 크기와 도메인의 영어 말뭉치 5개를 사용했으며, 이는 압축되지 않은 텍스트 기준으로 160GB 이상의 데이터를 포함한다.
1)BOOKCORPUS + WIKIPEDIA
2)CC-NEWS
3)OPENWEBTEXT
4)STORIES
3.3.Evaluation
세 가지 벤치마크를 사용하여 다운스트림 작업에서 평가한다.
1) GLUE
2) SQuAD
3) RACE -
Training Procedure Analysis
BERT 모델을 사전학습하기 위해 중요한 선택 요소들을 탐구하고 정량화한다.
4.1. static vs Dynamic Masking
BERT는 토큰을 무작위로 마스킹하고 예측하는 방식에 의존한다. 원래 BERT 구현은 데이터 전처리 중에 한번 마스킹을 수행했으며, 그 결과 단일 정적 마스크가 생상된다. 각 훈련 에포크에서 동일한 마스크를 사용하지 않기 위해, 훈련 데이터는 10번 복제되었고 각 시퀀스는 40번의 에포크동안 10가지 다른 방식으로 마스킹되었다. 따라서 각 훈련 시퀀스는 훈련 중 동일한 마스크로 4번 보게 된다.
이 전략을 동적 마스킹과 비교한다. 동적 마스킹에서는 매번 시퀀스를 모델에 입력할 때마다 새로운 마스킹 패턴을 생성한다. 이는 더 많은 스텝으로 사전학습을 하거나 더 큰 데이터셋으로 작업할 때 중요하다.
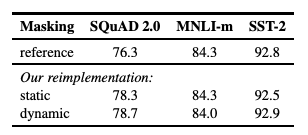
정적 마스킹을 사용했을 때 원래 BERT 모델과 유사한 성능을 보였으며, 동적 마스킹이 정적 마스킹과 비교할 때 유사하거나 약간 더 나은 성능을 보인다. 따라서 이후 실험에서는 동적마스킹을 사용한다.
4.2.Model Input Format and Next Sentence
원래 BERT 사전 학습 절차에서는, 모델이 두개의 문서 세그먼트를 관찰하며, 이는 동일한 문서에서 연속적으로 샘플링되거나 별개의 문서에서 샘플링된다.
NSP 손실은 원래 BERT 모델을 훈련하는데 중요한 요소로 가정되었다. 그러나, 최근 연구들은 NSP 손실의 필요성에 대해 의문을 제기하고 있다.1) SEGMENT-PAIR+NSP : 원래 BERT에서 사용했던 방법, 각 입력에는 두 개의 세그먼트가 포함되며, 각 세그먼트는 여러 자연어 문장을 포함할 수 있지만, 전체 길이는 512 토큰 미만이어야 한다.
2) SENTENCE-PAIR+NSP : 각 입력에는 자연어 문장의 쌍이 포함되며, 이는 하나의 문서의 연속적인 부분에서 샘플링된다. 이러한 입력은 512 토큰보다 훨씬 짧기 때문에 배치 크기를 늘려 1과 비슷한 총 토큰 수를 유지한다.
3) FULL-SENTENCES : 각 입력에는 하나 이상의 문서에서 연속적으로 샘플링된 전체 문장이 포함되어 있으며, 총 길이가 512 토큰을 넘지 않도록 한다. 입력은 문서 경계를 넘을 수 있으며, 한 문서의 끝에 도달하면 다음 문서에서 문장을 샘플링하고 문서 사이에 구분자를 추가한다.
4) DOC-SENTENCES : 3과 유사하게 구성되지만, 문서 경계를 넘을 수 없다. 문서 끝에서 샘플링된 입력은 512 토큰보다 짧을 수 있으며, 이 경우 배치 크기를 동적으로 늘려 3과 비슷한 총 토큰 수를 유지한다.
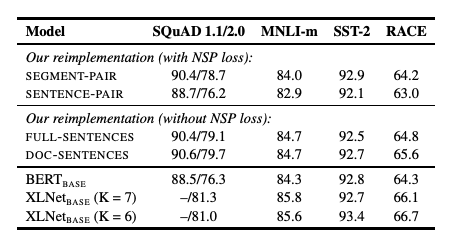
1과 2를 비교했을 때, 두 형식 모두 NSP 손실을 유지하지만 후자는 단일 문장을 사용한다. 단일 문장을 사용하는 것이 다운스트림 작업 성능에 부정적인 영향을 미친다는 것을 발견했다. 이는 모델이 장거리 의존성을 확습할 수 없기 떄문이라고 가정할 수 있다.
4는 1보다 성능이 우수하고 NSP를 제거해도 다운스트림 작업 성능이 동일하거나 약간 향상된다는 것을 발견했다. BERT 구현이 손실 항목만 제거하고 1 입력 형식을 그대로 유지했을 가능성이 있다.
4가 3보다 약간 더 나은 성능을 보였지만, 4는 가변적인 배치 크기를 초래하므로, 괸련 연구와의 비교를 쉽게 하기 위해 이후 실험에서는 3을 사용한다.
4.3 Training with large batches
BERT가 대용량 배치 훈련에 적합하며, 실험에서도 배치 크기를 증가시키면서 BERTBASE의 최종 작업 성능을 관찰하였으며, 훈련 데이터에 대한 반복 횟수를 동일하게 유지한 상태에서 배치 크기가 커지면 MLM 목표에 대한 퍼플렉시티와 최종 작업 정확도가 모두 개선되는 것을 확인했다. 또한 대용량 배치는 분산 데이터 병렬 훈련을 통해 쉽게 병렬화할 수 있따. 이후 실험에서는 8,000개의 시퀀스를 포함한 배치로 훈련을 진행했다.
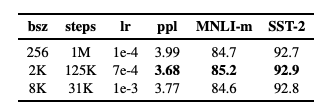
배치크기가 퍼플렉시티와 최종 작업 성능에 미치는 영향을 보여준다. 특히 대규모 배치를 사용하면 퍼플렉시티가 낮아지고, 이는 모델이 더 잘 최적화되었음을 나타내며, 개발 세트 정확도도 개선될 수 있다.
4.4.Text Encoding
BPE는 문자와 단어 수준 표현을 결합한 방식으로, 자연어 말뭉치에서 흔히 발생하는 대규모 어휘를 처리할 수 있다. BPE는 전체 단어 대신 하위 단어 단위를 사용하며, 이는 훈련 말뭉치에 대한 통계적 분석을 통해 추출된다. -
RoBERTa
RoBERTa(Robustly optimized BERT approach)는 동적마스킹(4.1),NSP 손실없는 FULL-SENTENCES(4.2),대규모미니배치(4.3),BPE(4.4)를 사용하여 훈련된다.또한 이전 연구에서 강조되지 않은 두가지 중요한 요인을 조사한다.
(1) 사전 학습에 사용된 데이터 (2) 데이터에 대한 학습 반복 횟수
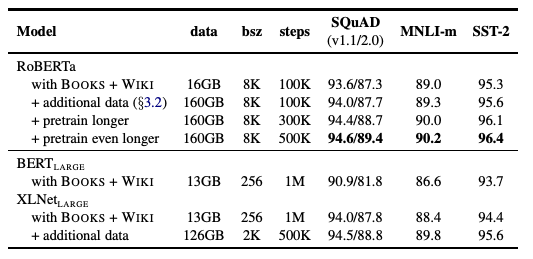
학습데이터를 통제할 때, RoBERTa가 BERTLARGE 결과보다 큰 성능 향상을 제공하며 이는 4장에서 탐구한 설계 선택의 주요성을 재확인해준다.
3.2절의 세가지 추가 데이셋을 이 데이터에 결합하여 동일한 10만 스텝동안 학습한 결과, 모든 다운스트림 작업에서 성능이 추가로 향상되는 것을 관찰했고 이는 사전 학습에서 데이터 크기와 다양성의 중요성을 검증해준다.
마지막으로 RoBERTa를 더 오랜 기간동안 학습하여 사전 학습 스텝 수를 10만에서 30만, 그리고 다시 50만으로 늘렸을 때 다운스트림 작업 성능이 크게 향상되는 것을 확인했다. 또한 가장 오랜 기간동안 학습된 모델조차도 데이터에 과적합하지않았다.
5.1. GLUE Results
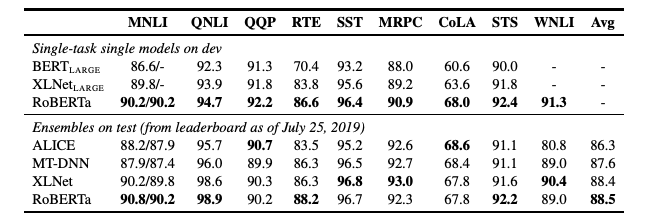
RoBERTa가 BERTLARGE와 동일한 마스크드 사전 학습 목표와 아키텍처를 사용하면서도 BERTLARGE와 XLLNETLARGE를 꾸준히 능가한다. 이는 모델 아키텍처와 사전 학습 목표의 상대적 중요성에 대해 의문을 제기하며, 이 연구에서 탐구한 데이터셋 크기와 훈련 시간과 같은 세부 사항이 더 중요한 역할을 할 수 있음을 시사한다.
5.2.SQuAD Results
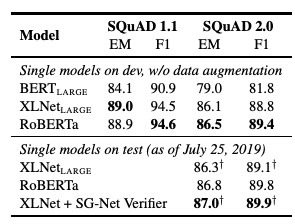
5.3.RACE
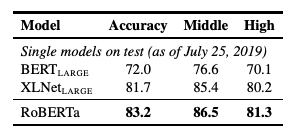
-
Related Work
-
Conclusion
모델을 더 오래 훈련하고, 더 큰 배치 크기로 더 많은 데이터를 처리하며, NSP를 제거하고 더 긴 시퀀스를 사용해 훈련하며, 훈련 데이터에 적용되는 마스킹 패턴을 동적으로 변경하면 성능이 크게 향상될 수 있다는 것을 발견했다.
