
신경망 기계번역에서 최적화된 데이터 증강기법 고찰 을 읽고 정리한 내용입니다.
요약
Transformer와 같은 성능이 좋은 모델들은 대량의 병렬 코퍼스를 가지고 학습을 진행했는데 대량의 병렬 코퍼스를 구축하는 것은 시간과 비용이 많이 드는 작업이다. 이러한 단점을 극복하기 위하여 합성 코퍼스를 만든 기법들이 연구되고 있으며 대표적으로 Back Translation 기법이 존재한다. 본 논문에서는 Back Translation 기법 뿐만 아니라 Copied Translation 방식을 통한 다양한 실험을 통하여 데이터 증강기법이 기계 번역 성능에 미치는 영향에 대해서 살펴본다.
실험 결과 Back Translation과 Copied Translation과 같은 데이터 증강기법이 기계번역 성능향상에 도움을 줌을 확인 할 수 있었으며 Batch를 구성할 때 상대적 가중치를 두는 것이 성능향상에 도움이 됨을 알 수 있었다.
서론
Back Translation이란 기존의 훈련된 반대 방향 번역기를 사용해 단일 언어 코퍼스에 대한 번역을 진행하며 합성 병렬 코퍼스를 만든 후, 이것을 기존 양방향 병렬 코퍼스에 추가하여 훈련에 사용하는 방식이다.
Copied Translation이란 단일 언어 코퍼스 활용하는 방법이다. 소스 쪽과 타깃 쪽에 똑같은 데이터를 넣어 훈련시키는 방법이다.
신경망 기계번역에서 데이터 증강기법
100만 병렬 말뭉치가 있을 시, BackTranslation을 위한 역방향 기계번역 모델을 제작 후 데이터를 증강시키고 Copied Translation까지 적용할 경우 학습데이터가 300만 문장까지 늘어나게 된다.
실험 및 실험 결과
데이터
Back translation을 진행했을 시 1839242개의 학습데이터 Copied translation을 진행했을 시 2758863개의 학습데이터가 구축되었다. Uniform 확률로 각각 5,000 문장을 선택하여 개발(Dev) 셋과 평가(Test)셋을 구성하였다.
모델
모델은 모든 실험에 동일하게 Transformer 모델을 사용한다.
실험결과
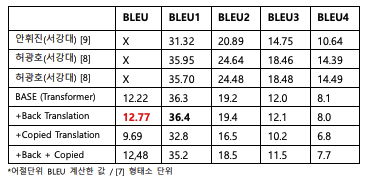
실험결과 BackTranslation을 이용한 모델과 Copied Translation을 함께 사용한 모델의 경우 기존 BASE 보다 높은 BLEU점수를 보였으나 Copied Translation만을 이용했을 경우 오히려 BASE보다 성능이 많이 떨어지는 모습을 보였다. 이는 Copied Translation은 Back Translation과 함께 사용을 해야 효과를 볼 수 있음을 시사하며 원인으로는 한-영 기계번역에서 언어 쌍 끼리의 Character set이 다르기에 애초에 Share되는 Vocab이 적기 때문으로 판단된다.
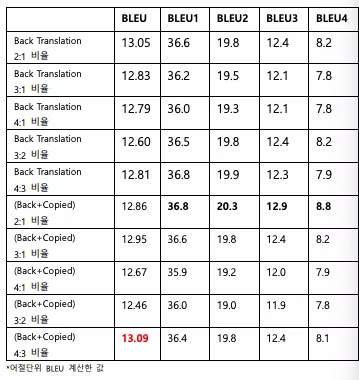
실험결과 Back Translation과 Copied Translation을 함께적용하여, 4대3의 상대적 비율을 적용하여 학습을 진행했을 때 가장 높은 BLEU 점수를 보였다. 이는 합성 코퍼스의 양만 많다고 높은 성능의 모델이 만들어짐이 아님을 시사하며 원본 코퍼스와 합성 코퍼스의 적당한 비율을 가지고 훈련을 진행하는 것이 좋은 성능의 모델을 만들 수 있음을 시사한다.
결론적으로 Back Translation과 Copied Translation과 같은 데이터 증강기법이 기계번역 성능향상에 도움을 준다.
결론
본 논문은 기계번역의 데이터 증강기법들에 대해 다양한 실험을 진행하였다. Back Translation과 Copied Translation과 같은 데이터 증강기법이 기계번역 성능향상에 도움을 줌을 볼 수 있었으며 Batch를 구성할 때 상대적 가중치를 두는 것이 성능향상에 도움이 됨을 알 수 있었다.
