
https://arxiv.org/pdf/2105.09680
Machine Reading Comprehension (MRC): identify an answer span within a paragraph given a question.
Task Overview

Dataset Construction
답변은 다음을 만족해야한다.
답변이 여러가지 형태로 표현될 수 있을 때는 작업자들이 모든 답변 span을 표시해야한다.
주요 주제나 제목이 아니어야 한다. (주어진 지문에서 가장 자주 등장하는 단어가 답이 될 가능성이 높다는 알려진 문제를 방지하자고 함.)
질문에 대해서
질문을 생성할 때 지문의 문장을 패러프레이징하는데 중점을 둔다. 이는 질문과 지문 간의 단어 중복을 줄이기 위한 것이다.

다중 문장 추론을 요구하는 질문을 만드는데 중점을 둔다. 다중 문장 추론은 모델이 지문 내에서 적어도 두 문장을 기반으로 답을 추론하도록 요구한다. MRC 모델이 지문 전체에 분산된 정보를 종합적으로 통합하여 답변 스팬을 추론할 수 있는지 평가하는데 중점을 둔다.

주어진 지문 내에서 답변할 수 없는 질문을 만드는 것을 목표로 한다.

최종 데이터셋 KLUE-MRC는 12,207개의 패러프레이징 기반 질문, 7,895개의 다중 문장 추론 질문, 9,211개의 답변할 수 없는 질문으로 구성되어 있다. 총 29,313개의 예시가 22,343개의 문서와 23,717개의 지문으로 만들어졌다.
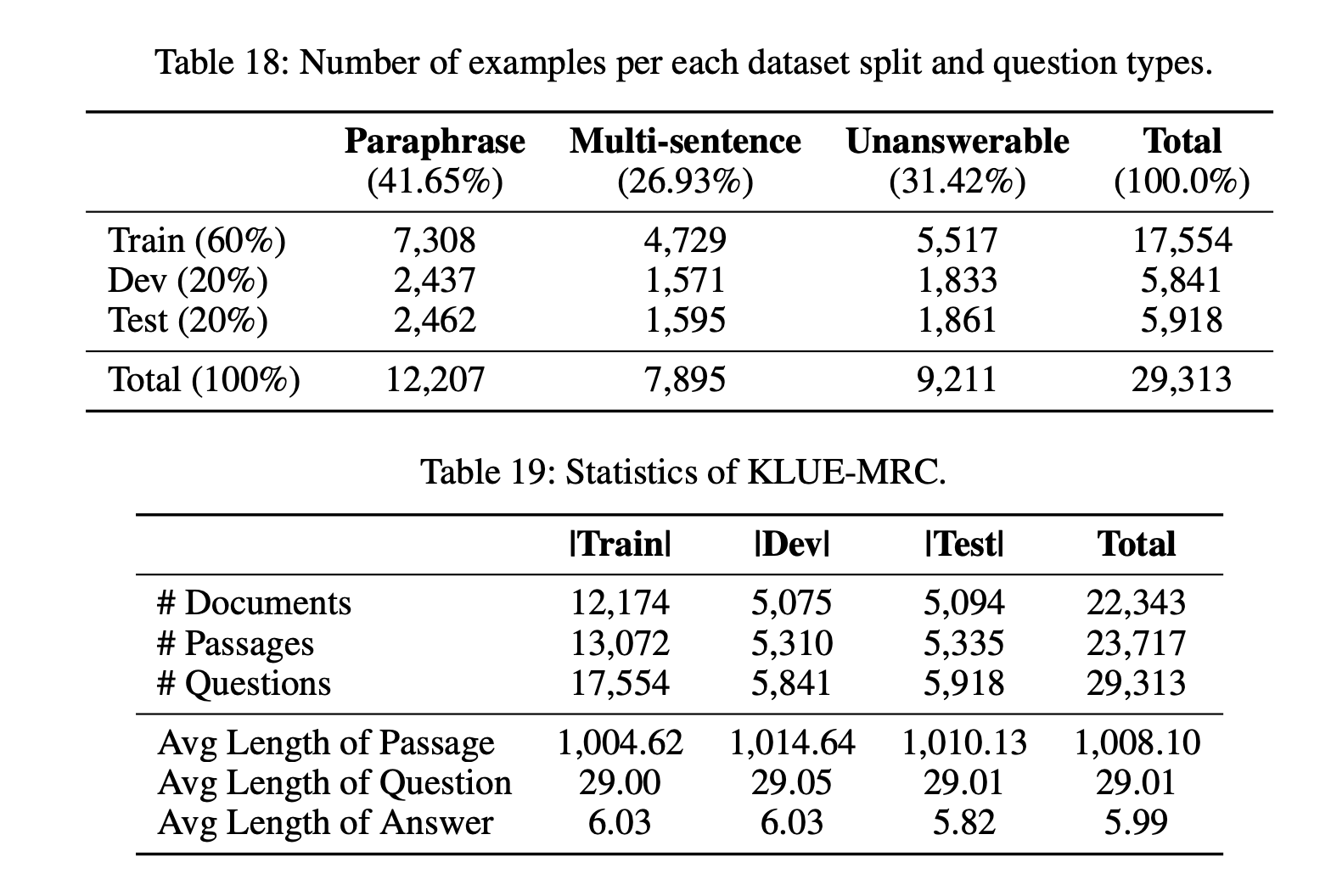
Analysis
KorQuAD 2.0은 KorQuAD 1.0 및 우리 데이터셋과는 내용 구성이 상당히 다르다. 특히, HTML 태그와 표 등의 요소가 포함되어 있다.
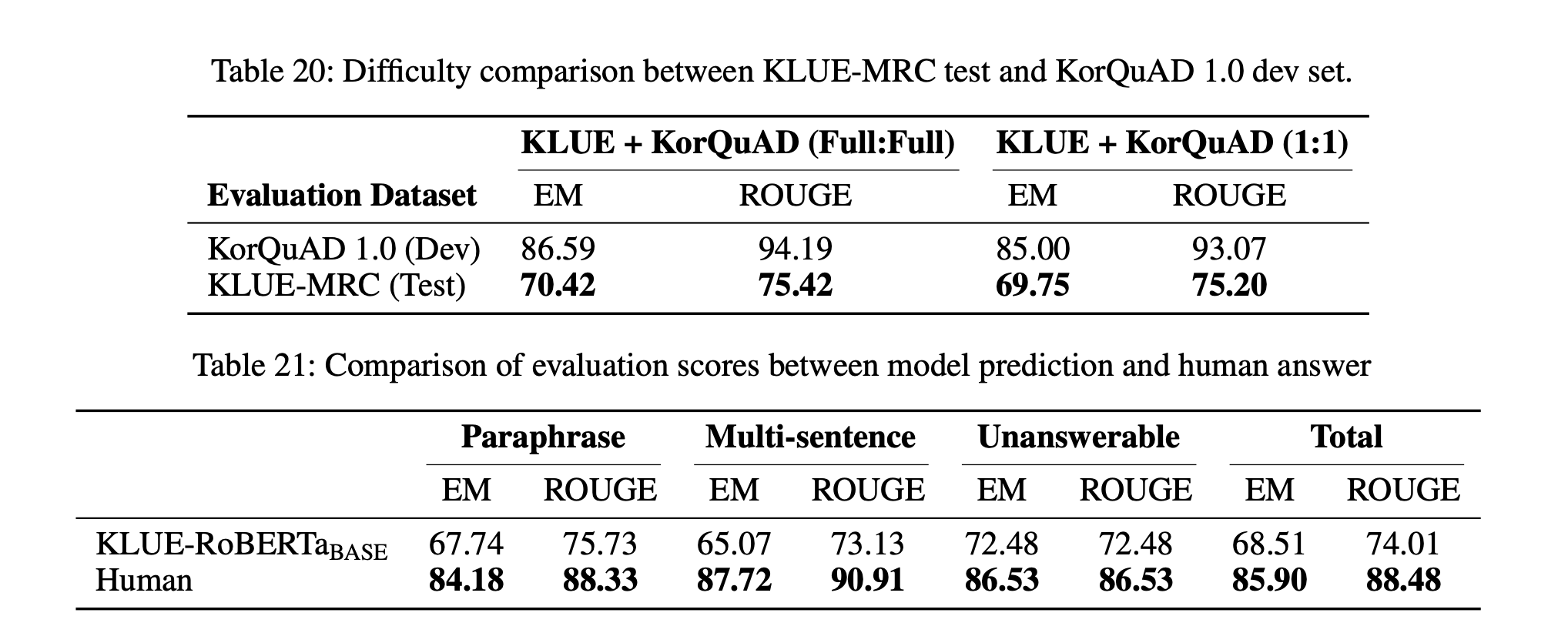
KorQuAD 1.0 훈련 예시는 60,407개로 KLUE-MRC(17,554개)의 거의 4배에 달하며, 이는 KorQuAD 1.0 개발 세트에서 더 높은 성능을 나타내게 한 원인일 수 있다. 우리는 공정한 비교를 위해 두 데이터셋의 동일한 양의 훈련 데이터를 사용하여 추가적인 파인튜닝을 진행했다. KLUE-MRC 훈련 세트의 크기에 맞추기 위해 KorQuAD 1.0 훈련 세트를 무작위로 샘플링하여 조정했다. 표 20에 따르면, KLUE-MRC는 KorQuAD 1.0에 비해 일관되게 낮은 점수를 보였다. 따라서 훈련 세트 크기에 관계없이 KLUE-MRC가 더 도전적인 데이터셋임을 알 수 있다.
우리 데이터셋과 KorQuAD 1.0의 어휘 중복도를 계산했다. 어휘 중복률은 질문과 지문 사이의 공통 구성 요소 수를 질문의 구성 요소 수로 나누어 계산된다다. 계산 시 조사를 비롯한 기능성 형태소와 어미는 한국어 형태소 분석기를 사용해 제외했다. 결과적으로, 우리 데이터셋의 어휘 중복률은 KorQuAD 데이터셋(70%)보다 약 10%포인트 낮은 것으로 나타났다. 질문 유형별로는 Type 1과 Type 3의 중복률이 55%에서 59% 사이로 유사한 비율을 보였으며, Type 2는 68%의 중복률을 나타냈다.
