📚 정규화
결정자에 의해 함수적 종속을 가진 일반 속성을 의존자로 입력, 수정, 삭제하여 이상 현상을 제거하는 것이다.
쉽게 말해, 데이터를 잘게 나누어서 쓸데없이 중복되어 생기는 오류를 없애는 작업.
📍 형태
⭐️ 제 1 정규형 (1NF)
하나의 칼럼에는 하나의 원자값만 포함되어야 한다는 것.
테이블의 중복 데이터를 분리해 유사한 속성이 반복되지 않도록 테이블을 분리하는 작업이다.

⭐️ 제 2 정규형 (2NF)
제 1 정규형을 만족하고, 기본키가 복합키일 때 테이블을 기본키(복합키) 하나씩을 기준으로 분리하여
기본키 전체에 모든 속성이 의존되도록 한다.
하지 않을 경우 데이터 조회, 수정, 추가 등에 어려움을 겪을 수 있다.
복잡하게 관련 없는 기본키까지 기억하여 쿼리를 작성해야 하기 때문이다.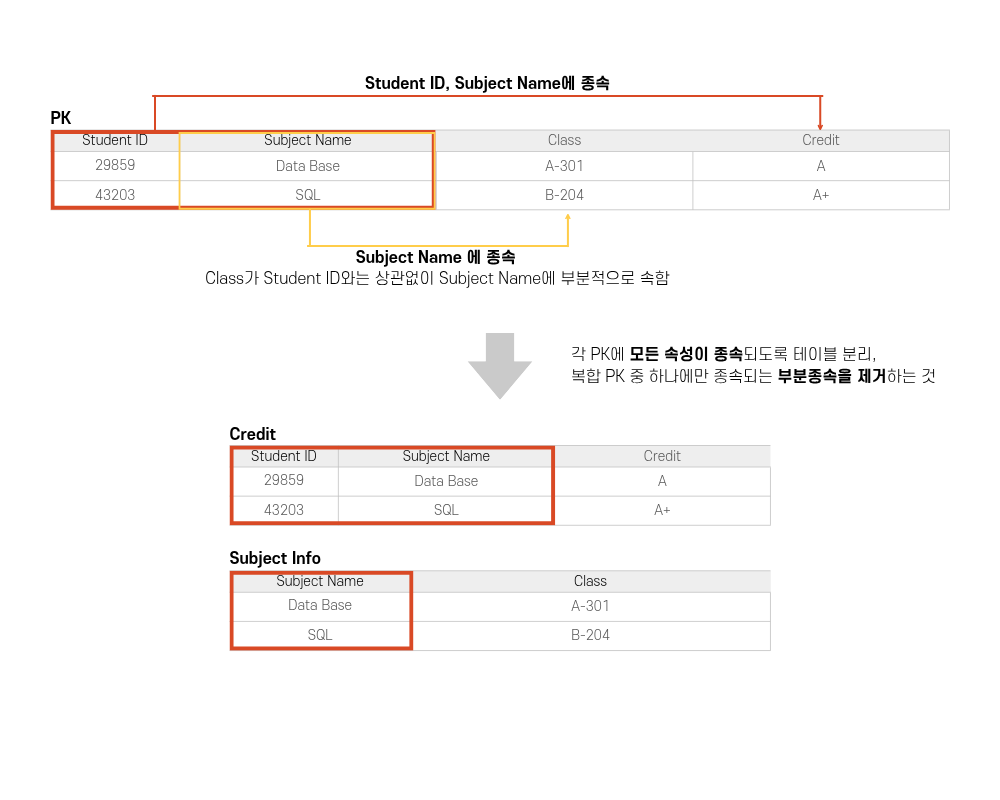
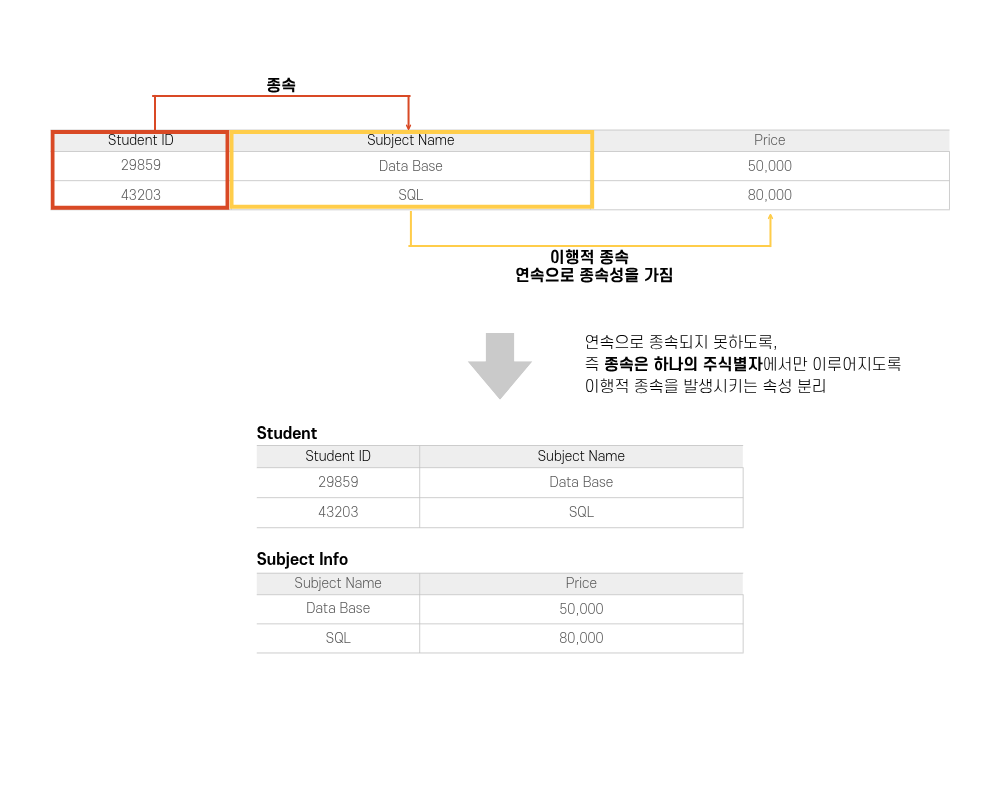
⭐️ 제 3 정규형 (3NF)
속성이 모든 주식별자에만 종속되고, 비주요속성 간 의존하지 않게끔 분리하는 역할을 한다.
만약 의존하고 있는 비주요속성이 존재할 경우,
해당 속성을 주요 식별자로 취급한 후 종속되는 속성을 모두 한 테이블에 묶는다.
💡 장점
- 데이터의 중복과 수정, 삽입, 삭제 이상을 막아 준다.
- 정규화로 인한 간결해진 구조 덕분에 유지보수가 편하다.
💡 단점
- 중복을 없애는 과정이기 때문에 테이블 분리로 인한 개수가 많아질 수있다.
- 또한 테이블을 분리할수록 JOIN을 이용해 쿼리를 작성해야 할 경우가 잦아져 성능 저하가 우려된다.
=> 이를 대비하기 위해,
무조건적인 정규화가 아닌 테이블을 합치거나 원 상태로 두는 반정규화를 선택하기도 한다.
📚 논리적 모델링
데이터를 어떻게 구조화할지 개념적으로 설계하는 단계다.
해당 과정에서 정규화를 진행한다.
📍 엔터티 Entity
업무에 필요한 정보를 저장 및 관리하기 위한 실체/객체이다.
집합에 속하는 개체 특정을 설명하는 속성을 필수적으로 소유한다.
다른 데이터에 의존하지 않고 독립적으로 존재해야 한다.
식별자에 의해 식별이 가능해야 한다.
또한 타 엔터티와 한 개 이상의 관계를 가지고 있어야 한다.
📍 속성 Attribute
업무에 필요로하는 최소한의 데이터 단위이며, 더는 분리할 수 없다.
엔터티를 설명하며 인스턴스의 구성요소라고 할 수 있다.
주식별자에 함수적인 종속성을 가져야 한다.
즉 PK를 알고 있다면 자연스럽게 종속된 속성을 알 수 있어야 한다.
꼭 한 개의 값만을 가져야(제 1 정규형을 만족해야) 한다.
💡 분류
PK : 엔터티를 식별할 수 있다.
FK : 타 엔터티와의 관계를 나타낸다.
일반 : PK/FK에 포함되지 않는 엔터티의 일반 속성이다.
📍 관계 Relationship
엔터티 간 상호연관성이 있는 상태이다.
엔터티의 인스턴스 간 연관성을 가지는 존재이며,
서로에게 연관성이 부여된 것을 말한다.
카디널리티(관계차수)
두 엔터티 간 관계에서 몇 개까지 종속될 수 있는지를 나타낸다.
ex) 1 : 1 / 1 : N / M : N ...
