📚 BeautifulSoup과 Selenium
📍 BeautifulSoup
정적 웹브라우저를 파싱 해 특정 요소를 탐색 및 수정 가능한 도구이다.
💡 정적 웹페이지 크롤링 순서
- 원하는 웹 페이지의 HTML 문서를 긁어 오고
- 긁어 온 HTML 문서를 파싱,
- 파싱한 HTML 문서에 원하는 태그를 가져와 사용한다.
파싱(Parsing) - 데이터나 문서를 AI 및 컴퓨터가 이해 가능하도록 문법적 구조를 분석해 정규화하고 필요한 정보만 구조화해 추출하는 과정.
비정형 데이터인 HTML, PDF, LOG 등을 JSON, CSV 등의 구조화된 포맷으로 변환해 활용성을 높이는 역할을 한다.soup = BeautifulSoup(data,'html.parser') # html 문서를 parsing
1️⃣ 라이브러리 import
import requests # HTML 문서를 불러올 때 사용하는 모듈
from bs4 import BeautifulSoup # 긴 HTML 문서를 정리되고 다루기 쉬운 형태로 만들어 주는 모듈2️⃣ 문서 불러오기 및 파싱
url = 'https://example.com'
response = requests.get(url) # url의 HTML 문서를 불러오고
html = response.text # HTML 문서를 text 형식으로 변환,
soup = BeautifulSoup(html, 'html.parser') # 컴퓨터가 알아보기 쉬운 형태로 parsing📍 Selenium
동적 웹 브라우저의 동작을 자동화 하는 오픈 소스 프레임워크다.
chromedriver을 제어하거나 원하는 정보를 얻기 위해 사용된다.
1️⃣ 라이브러리 import
from selenium import webdriver # selenium의 webdriver을 사용하기 위한 모듈
from selenium.webdriver.common.keys import Keys # key 조작을 위한 모듈
import time # 페이지 로딩을 기다리는 모듈
2️⃣ chrome driver 실행
driver = webdriver.Chrome() # Chrome 실행
driver.get('https://example.com') # get 안의 url 불러오기
time.sleep(3) # 페이지 완전히 로딩되도록 기다리는 시간
💡
time.sleep()의 경우, 동적 웹페이지에서 HTML 코드가 새로고침되거나 특정 버튼을 클릭할 때 잠시 코드가 꺼지거나 변경되는 경우가 있는데, 그동안은 HTML 코드 인식 불가로 인한 오류 발생 가능성이 있으므로 이를 방지하기 위해 웹이 로딩되기까지의 시간을 주는 것이다. 그래야 원하는 HTML 코드를 이용한 파싱 및 자동화가 가능하다.
📚 robots.txt 파일이란
검색 엔진 크롤러 bot에게 웹사이트의 어떤 부분을 수집 허용하고, 어떤 부분을 제한할지 안내하는 국제 표준 텍스트 파일이다. 주로 사이트의 크롤러 트래픽을 관리하고 중요하지 않은 페이지 또는 비슷한 페이지의 크롤링을 방지하는 역할을 한다. IETF에서 2022년 9월 표준화 문서를 발행했다.
해당 파일은 항상 사이트의 루트 디렉토리 ( https://example.com/robots.txt ), 로봇 배제 표준을 따르는 일반 텍스트 파일로 작성되어야 한다.
수집 조건에 대한 협약 존재 시, 광고주 정보 취득, 링크 미리보기 등의 수익성 크롤링은 robots.txt 내 규칙을 참조하지 않았거나 완벽히 준수되지 않았을 수 있다.
웹 페이지 크롤링 시 해당 문서를 참조하여 크롤링이 가능한 웹 페이지인지 사전에 확인이 필요하다. 그렇지 않으면 법적인 문제가 야기될 수 있다.
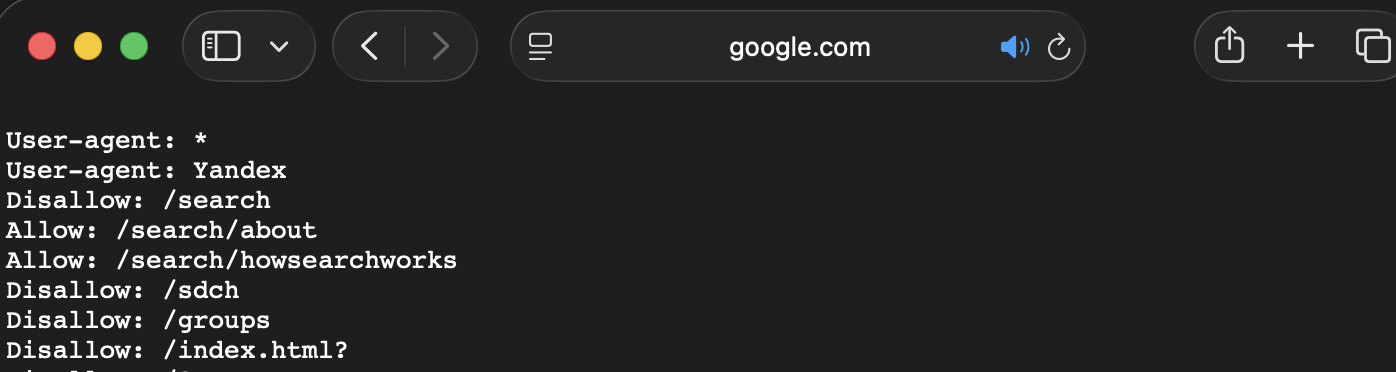
위는 구글에서 사용하는 robotst.txt다.
정확한 형식 및 표준 사용 방법은 공식 문서 및 네이버 문서 를 참고하길 바란다.
