RAG 품질을 개선할 때 가장 위험한 접근은 "답변이 이상하니까 프롬프트를 고치자"로 바로 들어가는 것이다.
프롬프트가 문제일 수는 있다. 하지만 RAG는 단일 LLM 호출이 아니라 Retrieval -> Context 구성 -> Generation으로 이어지는 파이프라인이다. 따라서 최종 답변만 보고 원인을 판단하면 엉뚱한 레이어를 수정하게 된다.
기업교육에서 RAG 실습을 진행할 때도 비슷한 장면이 자주 나온다.
"답이 틀렸는데 프롬프트를 더 강하게 쓰면 될까요?"
내가 보통 먼저 확인시키는 것은 프롬프트가 아니라 검색 결과다.
Failure mode를 먼저 나눈다
RAG 실패는 최소한 아래 두 가지로 나눠 봐야 한다.
| 구분 | 질문 | 대표 지표 |
|---|---|---|
| Retrieval failure | 필요한 근거 청크가 검색 결과에 들어왔는가 | Hit@K, Recall@K |
| Generation failure | 생성 답변이 검색된 근거를 벗어나지 않았는가 | Faithfulness |
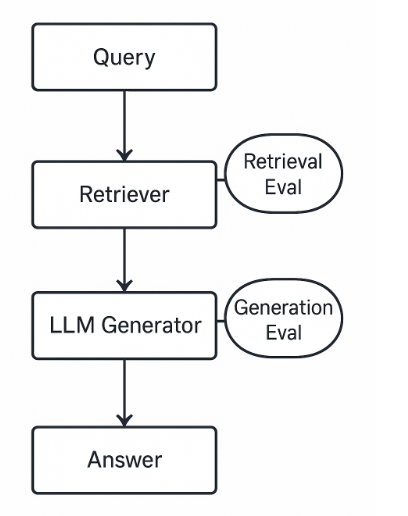
RAG에서 "답변이 틀렸다"는 말은 너무 넓다.
- 애초에 정답 근거를 못 찾았을 수도 있다.
- 정답 근거는 찾았지만 LLM이 문서 밖의 내용을 섞었을 수도 있다.
- 검색 결과는 맞고 답변도 맞지만 citation이나 형식이 깨졌을 수도 있다.
- 특정 사용자 질문에서만 query 표현이 문서 표현과 어긋났을 수도 있다.
이걸 한 덩어리로 보면 모든 개선이 감으로 흐른다.
1. 검색 문제인지 확인한다
검색 평가는 "retriever가 가져온 문서가 좋아 보이는가"를 감으로 보는 일이 아니다.
최소한 평가셋에 정답 근거 청크를 같이 넣어야 한다.
test_cases = [
{
"query": "보이스피싱 피해금 환급절차에서 공고 기간은 얼마인가요?",
"relevant_doc_ids": [42, 43],
"reference": "채권소멸절차 개시 공고 후 일정 기간 내 이의제기가 없으면 환급 절차가 진행됩니다."
}
]여기서 중요한 필드는 relevant_doc_ids다. 이것이 있어야 top-k 검색 결과와 정답 근거를 비교할 수 있다.
def retrieved_ids(docs):
return [doc.metadata.get("id") for doc in docs]
def hit_at_k(retrieved_docs, relevant_doc_ids):
pred_ids = {doc.metadata.get("id") for doc in retrieved_docs}
return bool(pred_ids & set(relevant_doc_ids))
def recall_at_k(retrieved_docs, relevant_doc_ids):
pred_ids = {doc.metadata.get("id") for doc in retrieved_docs}
relevant_ids = set(relevant_doc_ids)
matched_ids = pred_ids & relevant_ids
return len(matched_ids) / len(relevant_ids)Hit@K는 관련 청크가 하나라도 들어왔는지 본다. Recall@K는 필요한 관련 청크 중 얼마나 회수했는지 본다.
질문별로 관련 청크가 1개뿐이면 Hit@K와 Recall@K가 비슷하게 보일 수 있다. 실무 평가셋에서는 가능하면 질문별 근거 청크를 2개 이상 지정해 두는 편이 더 낫다.
검색 결과에 정답 근거가 없다면 그 시점의 문제는 프롬프트가 아니다.
이때 봐야 할 후보는 다음 쪽이다.
- PDF 파싱 품질
- chunk size / chunk overlap
- 구조 기반 청킹
- embedding model
- dense retrieval vs BM25
- hybrid retrieval
- query rewriting
- multi-query
- HyDE
- reranking
2. 검색이 맞으면 생성 문제를 본다
검색 결과에 정답 근거가 들어왔는데 답변이 틀리면 Generation failure를 의심한다.
이때 핵심은 답변이 "그럴듯한가"가 아니라 "검색된 context에 근거하는가"다.
judge_prompt = """
다음은 RAG 모델이 생성한 답변과 참조 문서(Context)입니다.
질문:
{query}
참조 문서:
{context}
생성 답변:
{answer}
답변이 참조 문서에 근거했는지 0~1 점수로 평가하세요.
- 1: 모든 핵심 내용이 문서에 근거함
- 0.5: 일부는 근거가 있으나 일부는 추측 또는 누락
- 0: 문서에 없는 내용을 생성함
점수와 간단한 이유만 출력하세요.
"""이런 방식의 LLM-as-a-Judge는 완벽한 정답 채점기가 아니다. 그래도 Faithfulness를 따로 보게 해 준다는 점에서 디버깅에 도움이 된다.
검색은 성공했는데 답변이 문서 밖의 내용을 섞는다면 아래를 봐야 한다.
- "문맥에 없는 내용은 생성하지 말 것" 규칙이 있는가
- 답변이 출처를 함께 내도록 되어 있는가
- context가 너무 길어 핵심 근거가 묻히지 않는가
- 불필요한 청크가 많아 답변이 흔들리지 않는가
- 모델 temperature가 과하게 높지 않은가
여기서 청킹이나 retriever를 무작정 바꾸면 원인을 더 흐릴 수 있다.
3. RAGAS는 평가셋이 있을 때 힘이 난다
RAGAS를 쓰면 user_input, retrieved_contexts, response, reference 구조로 여러 케이스를 반복 평가할 수 있다.
ragas_rows = [
{
"user_input": case["query"],
"retrieved_contexts": [doc.page_content for doc in retrieved_docs],
"response": generated_answer,
"reference": case["reference"]
}
]RAGAS를 도구 이름으로 먼저 접근하면 애매해진다. 먼저 평가 질문과 기준 답변, 근거 청크를 설계해야 한다.
RAGAS에서 자주 보는 축은 다음과 같다.
| 평가 축 | 보는 것 |
|---|---|
| context_recall | 기준 답변에 필요한 근거가 검색 문맥에 들어왔는가 |
| faithfulness | 생성 답변이 검색 문맥에 근거하는가 |
| factual_correctness | 생성 답변이 기준 답변과 사실적으로 맞는가 |
수업에서는 보통 직접 만든 Hit@K, Recall@K로 검색 평가의 원리를 먼저 확인한 뒤, 문항 수가 늘어나는 시점에 RAGAS로 넘어간다. 그래야 점수가 나왔을 때 이 점수가 무엇을 의미하는지 해석할 수 있다.
4. 개별 요청은 trace로 본다
평가셋 기반 평가는 "전체적으로 좋아졌는가"를 비교하기 좋다.
하지만 운영 중 특정 요청이 실패했을 때는 trace가 필요하다.
RAG 디버깅에서 trace로 확인해야 할 것은 보통 이 순서다.
- 사용자의 원 질문
- query rewriting이 있었다면 변환된 검색 질의
- retriever가 가져온 top-k 문서
- context로 조립된 최종 문자열
- LLM에 들어간 prompt
- model output
- latency, token, cost
이 순서가 남아 있으면 "검색이 문제인지, 문맥 구성이 문제인지, 생성이 문제인지"를 훨씬 빨리 좁힐 수 있다.
실무 디버깅 순서
내가 RAG 교육이나 프로젝트 멘토링에서 권하는 순서는 아래와 같다.
1. 실패 질문을 모은다.
2. 질문별 기준 답변과 정답 근거 청크를 지정한다.
3. top-k 검색 결과를 출력한다.
4. Hit@K / Recall@K로 검색 실패 여부를 본다.
5. 검색이 맞은 케이스만 Generation 평가로 넘긴다.
6. Faithfulness를 확인한다.
7. 개별 실패 요청은 Langfuse trace로 본다.
8. 원인별로 하나씩만 바꿔 실험한다.마지막 8번이 중요하다.
검색 방식, chunk size, reranker, prompt, model을 한 번에 바꾸면 어떤 변경이 품질을 올렸는지 알 수 없다.
정리
RAG 답변이 틀렸을 때 바로 프롬프트를 고치면 안 된다.
먼저 정답 근거가 검색됐는지 본다. 검색이 실패했다면 Retrieval 문제다. 검색이 성공했는데 답변이 근거를 벗어나면 Generation 문제다.
RAG 품질 개선은 "더 좋은 프롬프트"보다 "더 정확한 실패 분류"에서 시작한다.
