수업자료_강화학습
1.강화학습 기초 1

강화학습(RL)은 에이전트(agent)가 환경과 상호작용을 통해 보상(reward)을 최대화하는 방법을 학습하는 알고리즘입니다. 에이전트는 여러 상태(state)에서 가능한 행동(action)을 선택하고, 그에 따라 결과와 보상을 받으며 학습합니다. 이 과정에서 에이전
2024년 12월 25일
2.강화학습 기초 2
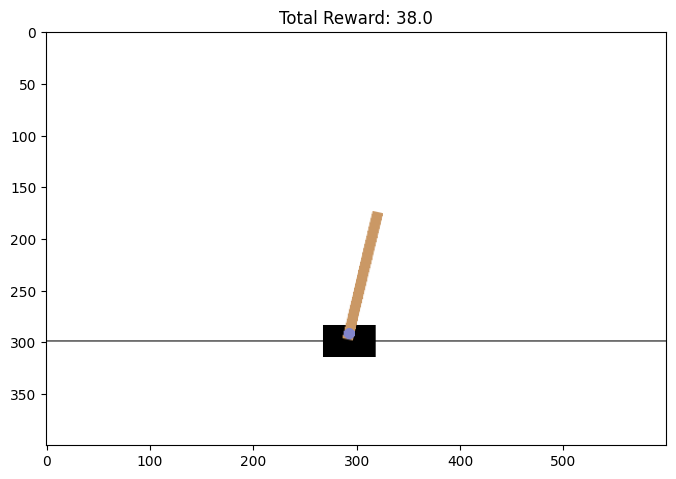
강화학습은 에이전트가 환경과 상호작용하며 최적의 행동을 학습하는 방식입니다. 이 과정에서 중요한 구성 요소들이 있습니다: 에이전트, 환경, 상태, 행동, 보상입니다.에이전트는 강화학습의 주체로, 환경과 상호작용하며 행동을 취하고 보상을 받습니다. 에이전트는 주어진 목표
2024년 12월 25일
3.강화학습 기초 3
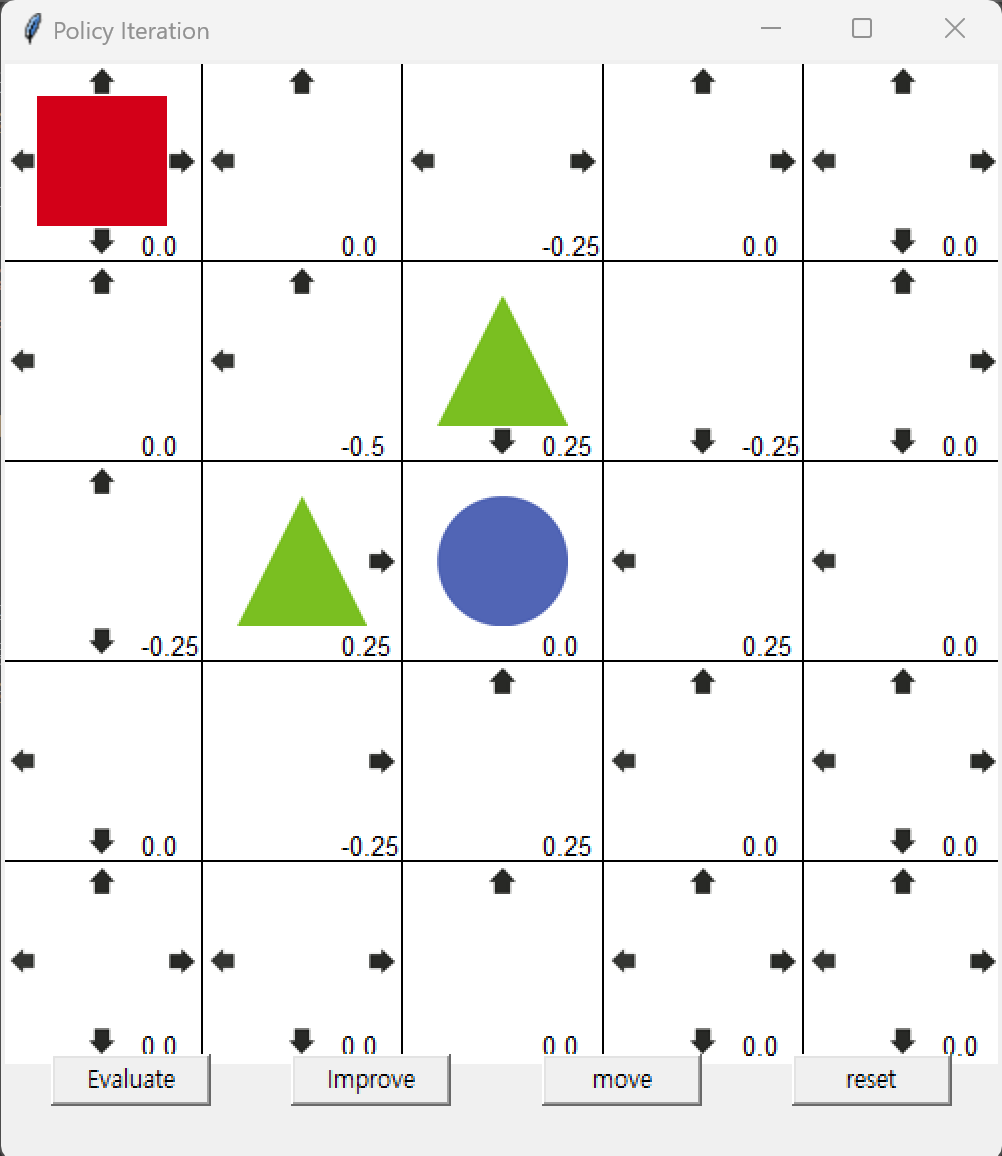
가치 기반 학습 (Value-Based Learning)상태(state)의 가치를 학습하여 최적의 정책을 유도하는 방식입니다.대표적인 알고리즘: Q-Learning, SARSA.Q-값(Q-Value): 특정 상태 $s$에서 행동 $a$를 취했을 때 기대되는 총 보상 $
2024년 12월 25일