강화학습의 정의, 특징 및 응용 분야
1. 강화학습(Reinforcement Learning) 정의
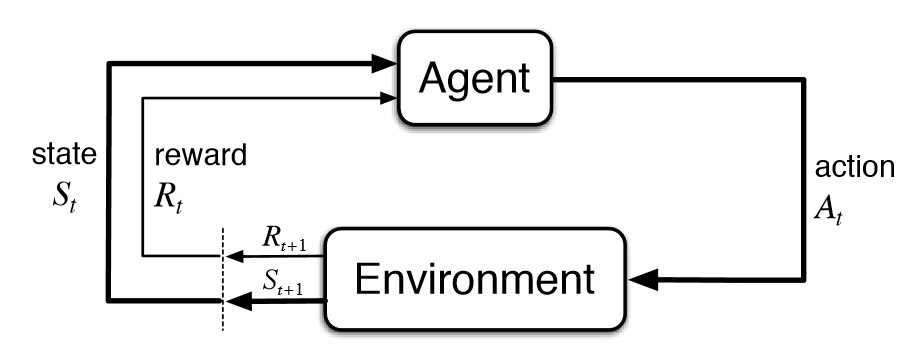
강화학습(RL)은 에이전트(agent)가 환경과 상호작용을 통해 보상(reward)을 최대화하는 방법을 학습하는 알고리즘입니다. 에이전트는 여러 상태(state)에서 가능한 행동(action)을 선택하고, 그에 따라 결과와 보상을 받으며 학습합니다. 이 과정에서 에이전트는 최적의 정책(policy)을 학습하려고 합니다.
- 에이전트(Agent): 의사 결정을 내리는 주체
- 환경(Environment): 에이전트가 상호작용하는 대상
- 상태(State): 환경의 현재 상태
- 행동(Action): 에이전트가 선택할 수 있는 가능한 행동
- 보상(Reward): 행동에 대한 피드백, 에이전트가 목표를 얼마나 잘 달성했는지 평가하는 기준
2. 강화학습의 특징
- 시간적 지연: 에이전트는 즉각적인 보상을 받지 않고, 장기적인 보상을 고려하여 학습해야 합니다.
- 탐험과 착오(Exploration vs. Exploitation): 에이전트는 새로운 행동을 시도(탐험)할지, 이미 알고 있는 최적의 행동을 반복(착오)할지 결정해야 합니다.
- 연속적인 학습: 강화학습은 주어진 작업에 대한 완전한 해답을 찾을 때까지 학습을 지속적으로 수행합니다.
- 상태 공간과 행동 공간: 상태와 행동의 공간이 매우 커질 수 있어, 이를 효율적으로 다루는 기술이 필요합니다.
3. 강화학습의 응용 분야
강화학습은 다양한 분야에서 강력한 성능을 발휘합니다. 주요 응용 분야는 다음과 같습니다:
-
게임: 알파고(AlphaGo), 체스, 바둑 등에서의 승패 예측 및 최적의 전략 학습
-
로봇 제어: 로봇의 동작 및 경로 최적화
-
자율주행차: 자율주행차가 주행 경로와 행동을 선택하는 데 강화학습을 사용
-
금융: 주식 투자, 포트폴리오 관리, 알고리즘 트레이딩
-
자연어 처리: 대화형 에이전트, 챗봇의 학습
-
의료: 치료 방법 최적화, 약물 개발

강화학습과 지도학습/비지도학습 비교
1. 지도학습(Supervised Learning)과 강화학습의 비교
| 특성 | 지도학습(Supervised Learning) | 강화학습(Reinforcement Learning) |
|---|---|---|
| 목표 | 입력과 출력의 관계를 학습하여 주어진 데이터에 대한 예측을 수행 | 보상을 최대화하는 행동을 학습하여 장기적인 목표 달성 |
| 데이터 | 레이블이 있는 데이터셋을 사용 | 보상에 기반한 경험을 통해 학습 |
| 학습 방식 | 주어진 입력에 대한 정확한 출력 값을 예측 | 행동을 통해 경험을 쌓고, 보상을 통해 정책을 학습 |
| 에러 | 예측 오차(손실 함수)를 최소화하는 방향으로 학습 | 보상(또는 페널티)을 통해 잘못된 행동을 수정하며 학습 |
| 주요 알고리즘 | 선형 회귀, 로지스틱 회귀, 신경망, SVM 등 | Q-learning, Deep Q-Network(DQN), 정책 그라디언트 등 |
2. 비지도학습(Unsupervised Learning)과 강화학습의 비교
| 특성 | 비지도학습(Unsupervised Learning) | 강화학습(Reinforcement Learning) |
|---|---|---|
| 목표 | 데이터 내의 숨겨진 패턴을 학습 | 최적의 행동을 선택하여 보상을 최대화하는 정책을 학습 |
| 데이터 | 레이블이 없는 데이터셋을 사용 | 에이전트의 상호작용을 통한 보상 기반 데이터 사용 |
| 학습 방식 | 데이터 내의 군집화나 차원 축소를 통해 패턴을 찾음 | 행동을 통해 경험을 쌓고 보상을 통해 학습 |
| 주요 알고리즘 | K-평균, DBSCAN, PCA, Autoencoders 등 | Q-learning, DQN, REINFORCE 등 |
결론
- 강화학습은 에이전트가 환경과 상호작용하며 보상을 통해 정책을 학습하는 과정으로, 주어진 목표를 달성하는 데 중요한 도구가 됩니다.
- 지도학습과 비지도학습은 주로 데이터가 주어졌을 때 예측을 하는 데 초점을 맞추며, 강화학습은 행동을 통해 경험을 쌓고, 장기적인 보상을 극대화하는 데 중점을 둡니다.

인공지능을 공부하고 가르치는 김민수 강사입니다. 공부한 내용 및 수업 자료가 업로드 됩니다.