
Introduction
Adversarial의 사전적 의미는 적대적이라는 뜻을 갖습니다. 말 그대로 두 모델이 대립하면서 동시에 학습시킵니다.
Fake Image를 만들어내는 Generator, 기존 진짜 이미지와 Generator로 만들어진 가짜 이미지를 평가하는 Discriminator 두 모델이 싸우면서 두 모델의 성능이 계속 올라가는 것입니다. G와 D가 정의되어 있기 때문에 다층 퍼셉트론으로 역전파 학습이 가능하게 되고, 마르코프 연쇄 등 복잡한 연쇄가 필요 없음을 증명합니다.
GAN
모델의 목적
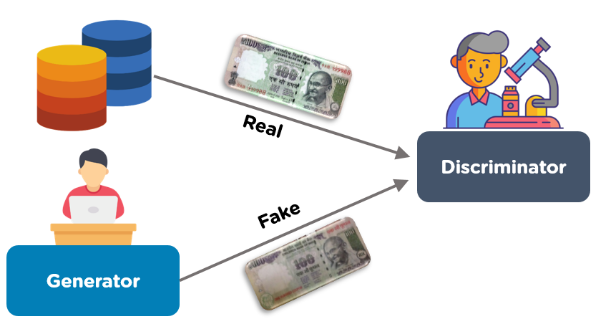
위와 같이 지폐 위조범(Generator)와 지폐 판별기(Discriminator)가 있다고 가정한다. 이 지폐 위조범은 최대한 판별 기를 속여야 할 것이고 반면에 판별 기는 이 지폐가 Real인지 Fake인지 구별을 잘해야 할 것이다. 이 프레임워크의 목적은 판별기의 성능이 최대한으로 좋은 모델인데 여기서 지폐 위조범이 모두다 감쪽같이 속인다면 누구도 무엇이 Real인지 Fake인지 구별하지 못할 것이다. 결과적으로 Real, Fake 모두 Real로 구별하여, 구별할 확률이 0.5에 이른 다는 것이 궁극적인 목표이다.
Discriminator model은 Fake, Real의 label값을 알려주고 학습을 하는 지도학습이고 Generator model은 label없이 latent code(잠재 노이즈)를 가지고 Real의 이미지와 비슷하게 만드는 비지도 학습이다.
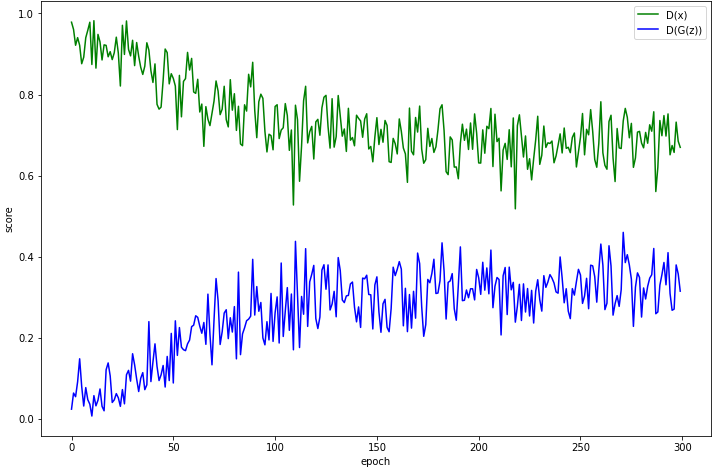
이 그래프는 Discriminator의 판별 확률을 나타낸 그래프이다 세로축은 Discriminator가 Real이미지로 판별할 확률이고 가로축은 epoch이다.
- D(x): Real 이미지를 사용한 판별 스코어
- D(G(Z)): Fake 이미지를 사용한 판별 스코어
epoch가 높아질수록 Discriminator가 진짜와 가짜이미지를 잘 판별하지 못하는 것을 알 수 있고 0.5근처로 확률이 수렴함을 볼 수 있다.
Training
글씨가 개판
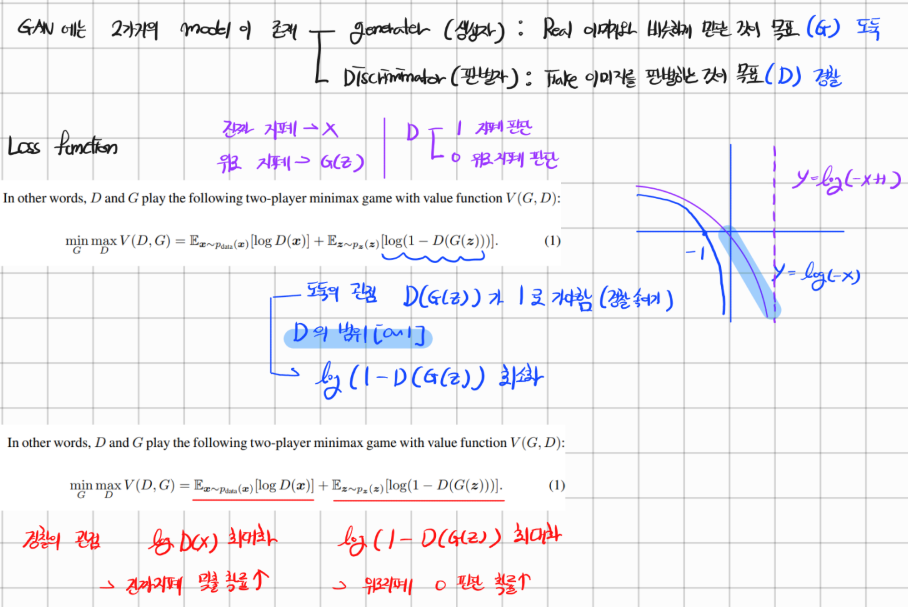
자 위의 V(D, G)가 object function이다. 당연히 D의 입장에서는 likelihood값을 maximize하길 원하고 G의 입장에서는 minimize하길 원할 것이다.
- 도둑의 관점
도둑의 입장에서는 도독이 생성한 지폐( ) 에 대해 경찰(D)가 진짜라고 판단하길 원한다. 따라서 가 1(진짜라고 판단)이 되는 것이 도둑(Generator)가 원하는 것이다.
가 1이 되면 오른쪽 그래프처럼 V(G, D)가 최소가 된다.
- 경찰의 입장
경찰의 입장에서는 도둑이 생성한 지폐 ()에 대해 경찰(D)가 가짜라고 판단하길 원한다. 따라서 가 0(가짜라고 판단)이 되는 것이 경찰(Discriminator)가 원하는 것이다.
그리고 진짜 지페()에 대해서 진짜라고 판단하는 것이 경찰이 원하는 판단이기 때문에 이 되어야 한다.
Training과정
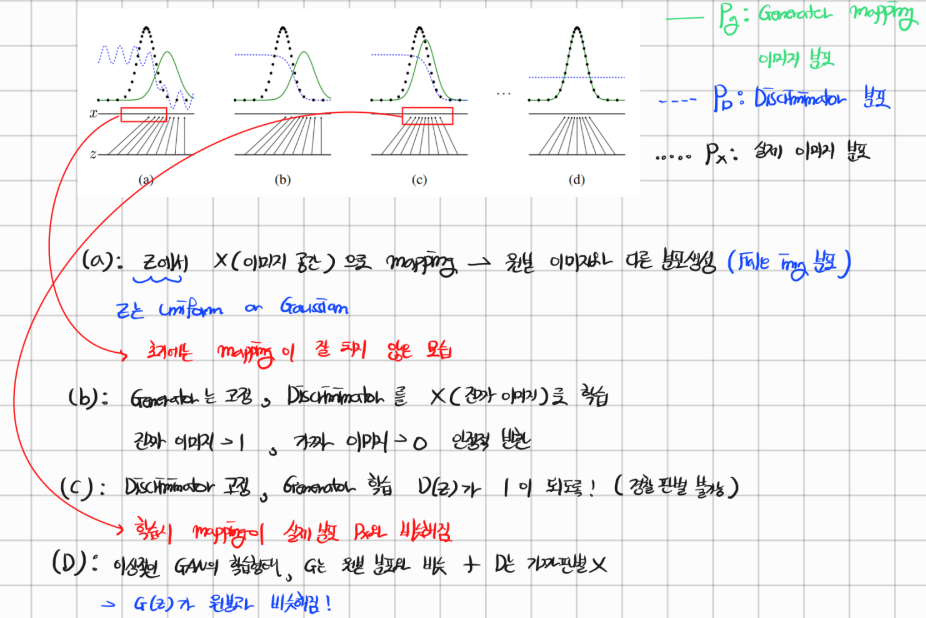
(a): 먼저 z(latent code)에서 이미지(지폐)의 공간으로 mapping을 해서 지폐를 만들어낸다.
(b): Generator는 고정시킨 상태로 Discriminator를 Real 화폐를 이용하여 학습시킨다. (이로써 Generator는 진짜와 가짜를 잘 판별함.)
(c): Discriminator는 고정시킨 상태로 Generator를 학습시킨다. 학습 과정은 D(z)가 1이 되도록 하는 것 (= 경찰을 속이는 것)
그래프를 보면 G(z)의 그래프가 원본의 그래프와 비슷해진 것을 확인할 수 있다.
(D): GAN 학습의 이상적인 형태이다. G는 원본과 같은 분포로 생성되어 D가 구분할 수 없게된다. 따라서 D는 항상 0.5의 값을 내보낸다.
최적의 해
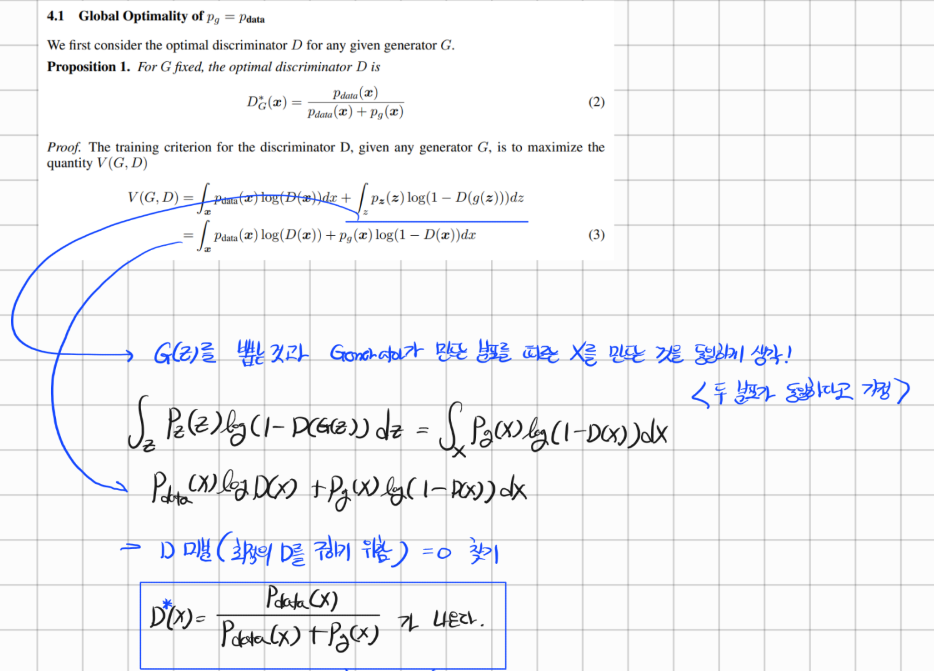

유도과정은 다음과 같다.

따라서 최적의 해의 loss값은 가 나온다!
GAN의 장단점

장점
- 가장 큰 장점은 바로 fidelity 즉, 생성된 이미지의 quality
인물을 예로 들면 현실 어딘가에 있을 법한 이미지를 잘 생성할 수 있다는 이야기이다.
단점
- GAN은 모델의 성능을 평가하는게 조금 까다롭다.
분류 모델처럼 정답/오답 혹은 확률 비교로 명확하게 평가할 수 있는게 아니기 때문이다.
- 학습의 불안정함
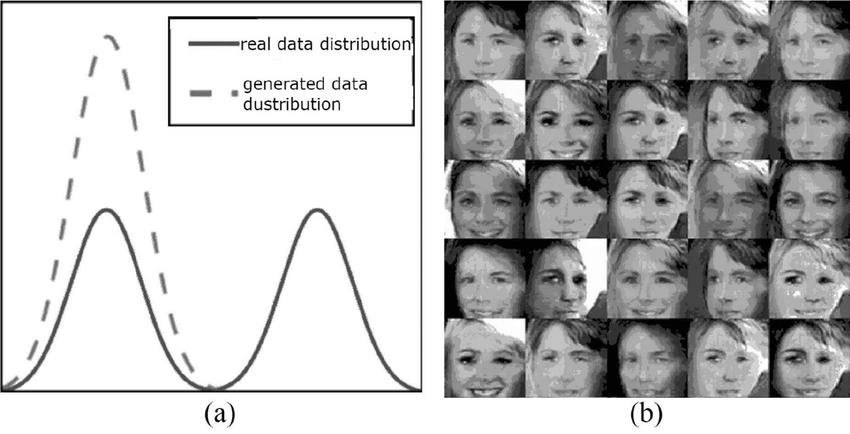
G(z)가 가장 많이 나오는 데이터에 대한 분포로 변해도 loss fuction은 성능이 잘 나온다고 평가한다. (loss는 낮기 때문에)
- 어떤 Noise vector에서 이미지가 생성되었는지 알 수 없음
알 수 있다면 어느 부분을 수정해야할지 알 수 있지만, 알 수가 없기 때문에 세부적인 조정이 불가능하다.
