
Introduction
오늘 리뷰할 논문은 VAE(variation auto-encoding)이다.
Auto-Encoder가 기존의 데이터를 효과적으로 압축시키고 복원시키는 것을 목표로 하는 것에 반해 VAE는 원본의 데이터를 사용해서 원본과 약간은 다른 데이터를 생성하는 것을 목표로 한다.
이 포스팅은 VAE의 전체적인 구조와 작동방식을 직관적으로 이해하는 것을 목표로 한다.
구조설명
아래는 VAE의 구조이다.
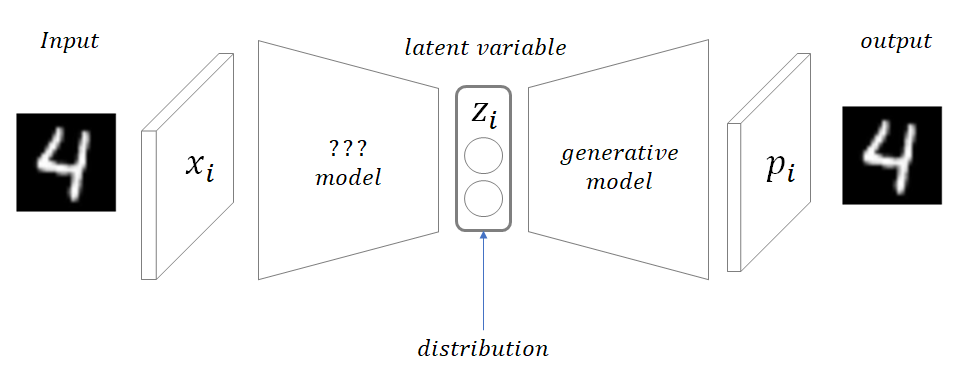
VAE의 목표는 Generative model의 목표와 같다.
input 의 분포와 비슷한 latent variable 를 통해 와 다른 새로운 를 생성하는 것이 목표이다.
내가 환타를 모델어 집어넣으면 탄산음료지만 환타와는 다른 사이다가 나오길 바라는 것이다.
좀 더 자세하게 살펴보자
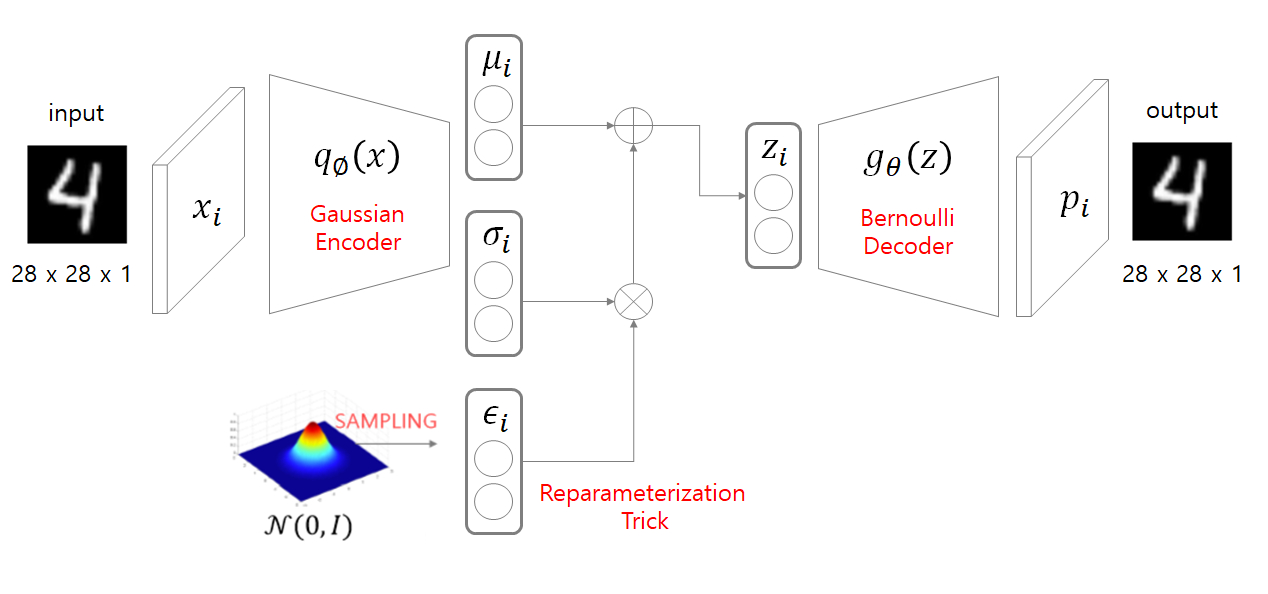
구조는 크게 Gaussian Encoder, Reparameterization Trick(Sampling), Decoder 로 나눌 수 있다.
-
Gaussian Encoder는 의 정보를 압축하는 부분이라고 생각하면 된다. -
Reparameterization Trick(Sampling)은Gaussian Encoder를 거쳐온 정보들에 Noise를 추가하는 단계라고 보면 된다. ( 미분이 가능하도록 수식을 변경하는 부분이기도 함) -
Decoder는 샘플링 된 를 디코딩 하는 하여 원본과 비슷한 이미지를 만드는 단계이다.
Loss
그렇다면 우리가 이 시스템을 만들기 위해 해야 될 작업은 무엇일까?
MLE(Maximum Likelihood Estimation)
바로 를 최대화 하는 것이다.
: 를 넣었을때 나오는 모델의 output
를 넣었을때 가 나올 확률을 Maximize해주는 분포를 만들어주는 모델의 파라미터 를 찾아야 한다. (분포를 찾는 것과 동일)
모든 식은 이 에서 나온다.
수식의 전개는 다음과 같다.
수식의 첫 번째 줄은 z에 대한 수식이 없기 때문에 단순히 상수에 z에 대한 평균을 취한 것과 동일하다고 생각하면 된다.
EX) 와 같음
두 번째 줄의 수식은 Bayes rule이 사용되었다.
세 번째 줄의 수식은 분자와 분모에 모두 를 곱해주었다.
네 번째 줄의 수식은 수식을 분리하였고
마지막 줄은 분리된 수식에 대해서 KL-Divergence로 변경을 해주었다.
KL-Divergence 변환 과정
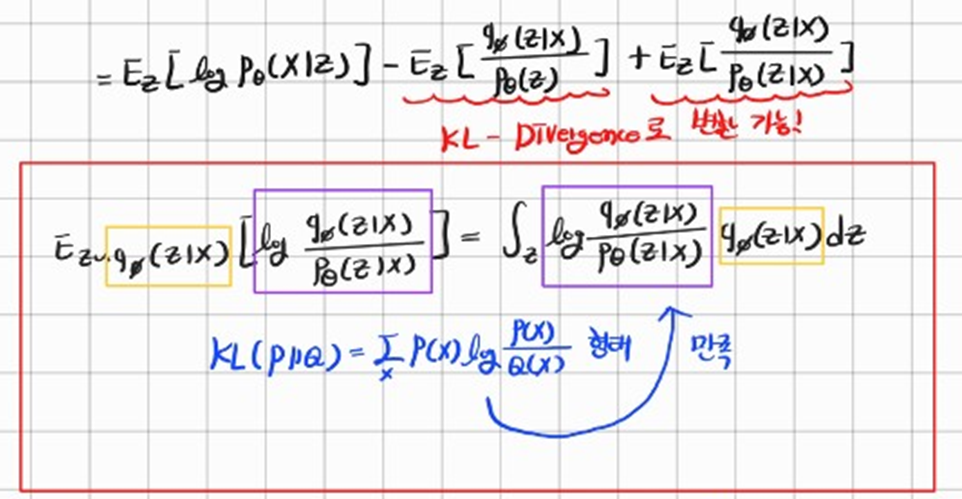
마지막 수식을 살펴보자
-
첫 번째 항: Encoder로 부터 를 sampling하고 sampling된 로 부터 output을 뽑아낼 수 있다. (계산 가능함 + 에서 가 나올 확률을 극대화함.)
-
두 번째 항: Encoder를 통과한 가 우리가 정의한 의 분포와 비슷해지도록 만든다. (계산이 가능함)
-
세 번째 항: 는 계산이 가능하지만 는 의 정답분포는 구할 수 없다. (계산이 불가능함. 하지만 KL-Divergence가 항상 양수임은 알 수 있음.)
우리는 우리가 계산할 수 있는 부분만 살펴볼 수 있다.
세 번째 항은 알 수 없기 때문에 논문에서는 첫 번째와 두 번째항을 최대화시킨다.
계산할 수 있는 부분을 ELBO라고 한다.
ELBO는 항상 다음의 수식을 만족한다. (세 번째 항은 항상 양수이기 때문)
Reconstruction Error
우리는 이제 이 부분을 Reconstruction Error라고 부른다.
Reconstruction Error는 다음과 같이 표현이 가능하다.
의 계산으로 나타낼 수 있다.
하지만 모든 구간의 에 대해 적분할 수 없기 때문에 논문에서는 Monte Carlo Method를 사용한다.
이를 다음과 같이 표현가능하다.
근사가 잘 되기 위해서는 매우 큰 값을 선택해야 하는데 우리는 한번 sample을 뽑을 때마다 계산을 해야한다. 연산량이 커지는 것이다.
논문에서는 이를 막기위해 로 고정시켜 Random sample을 1개 뽑아 사용한다.
따라서 Reconstruction Error는 다음과 같게 된다.
이 수식을 계산하기 위해서 우리는 원본의 분포를 가정해야 한다.
논문에서는 두 가지 분포를 가정한다.
- 베르누이 분포
베르누이 분포를 따른다고 가정했을 때 다음과 같이 수식을 전개할 수 있다.
최종적으로 베르누이 분포를 따르는 Reconstruction Error는 Cross Entropy Loss가 나온다.
- 가우시안 분포
가우시안 분포를 따른다고 가정했을 때 다음과 같이 수식을 전개할 수 있다.
최종적으로 가우시안 분포를 따르는 Reconstruction Error는 Squared Error가 나온다.
Reconstruction Error가 베르누이 분포를 따를 때 Decoder를Bernoulli Decoder라고 하고 가우시안 분포를 따를 때 Decoder를Gaussian Decoder라고 한다.
Regularization
우리는 수식의 두번째 항을 Regularization이라고 부른다.
우리가 정의한 분포인 분포와 와 비슷하게 만들기 때문이다.
Regularization이 없다고 가정해보자.
그렇다면 를 사용하여 원본 가 나올 확률만을 극대화 하도록 만들 것이다.
따라서 분포를 어느정도 조정함으로써, VAE가 Reconstruction task만을 잘하는 것을 방지한다. 그렇기 때문에 Regularization 불리는 것이다
계산방식은 다음과 같다.

Reparameterization Trick
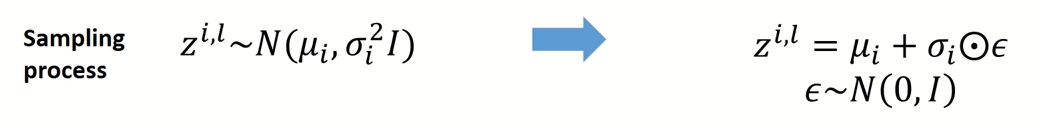
이 부분은 latent space 에 대해서 Sampling을 하는 부분이다. 물론 그냥 Sampling을 하면 안된다. (미분이 불가능함)
단순히 확률 분포에서 Sample을 뽑는 것은 backpropagation이 불가능 하기 때문에 Normal distribution을 따르는 을 사용하여 샘플링 한다. (오른쪽 방식)
Decoder의 output은 (평균)와 (표준편차)가 나오는데 우리는 noise를 섞어줌과 동시에 미분이 가능하도록 오른쪽과 같은 수식으로 를 Sampling한다.
sampling을 하는 은 backpropagation하지 않기 때문에
Decoder방향으로 미분이 가능함
코드 구현
import torch
from torch import nn, optim
import torch.utils.data
from torch.nn import functional as F
from torchvision import datasets, transforms
from torchvision.utils import save_image
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=True, download=True,
transform=transforms.ToTensor()),
batch_size=128, shuffle=True, num_workers=4, pin_memory=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=False, download=True,
transform=transforms.ToTensor()),
batch_size=128, shuffle=False, num_workers=4, pin_memory=True)
class VAE(nn.Module):
def __init__(self, input_dim=784, h_dim=400, latent_dim=20):
super(VAE, self).__init__()
self.fc1 = nn.Linear(input_dim, h_dim)
self.fc2_mu = nn.Linear(h_dim, latent_dim)
self.fc2_var = nn.Linear(h_dim, latent_dim)
self.fc3 = nn.Linear(latent_dim, h_dim)
self.fc4 = nn.Linear(h_dim, input_dim)
def encode(self, x):
out = F.relu(self.fc1(x))
return self.fc2_mu(out), self.fc2_var(out)
def reparameterize(self, mu, log_var):
std = torch.exp(0.5 * log_var)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, x):
out = F.relu(self.fc3(x))
return torch.sigmoid(self.fc4(out))
def forward(self, x):
mu, log_var = self.encode(x.view(-1, 784))
z = self.reparameterize(mu, log_var)
return self.decode(z), mu, log_var
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = VAE().to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
def loss_function(recon_x, x, mu, log_var):
BCE = F.binary_cross_entropy(recon_x, x.view(-1, 784), reduction='sum')
KLD = -0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp())
return BCE + KLD
def train(epoch):
model.train()
train_loss = 0
for idx, (data, _) in enumerate(train_loader):
data = data.to(device)
optimizer.zero_grad()
recon, mu, log_var = model(data)
loss = loss_function(recon, data, mu, log_var)
loss.backward()
train_loss += loss.item()
optimizer.step()
print('====> Epoch: {} Average loss: {:.4f}'.format(
epoch, train_loss / len(train_loader.dataset)))
def test(epoch):
model.eval()
test_loss = 0
with torch.no_grad():
for idx, (data, _) in enumerate(test_loader):
data = data.to(device)
recon, mu, log_var = model(data)
test_loss += loss_function(recon, data, mu, log_var).item()
if idx == 0:
n = min(data.size(0), 10)
comparison = torch.cat([data[:n],
recon.view(-1, 1, 28, 28)[:n]])
save_image(comparison.cpu(),
'./results/epoch_' + str(epoch) + '.png', nrow=n)
test_loss /= len(test_loader.dataset)
print('====> Test set loss: {:.4f}'.format(test_loss))
if __name__ == "__main__":
s = torch.randn(64, 20).to(device)
for epoch in range(0, 101):
train(epoch)
test(epoch)
if epoch % 10 == 0:
sample = model.decode(s).cpu()
save_image(sample.view(64, 1, 28, 28),
'results/sample_{}_result.png'.format(epoch))실행 결과

