Ch06 비지도 학습
06-1 군집 알고리즘
비지도 학습, Unsupervised Learning은 가장 큰 특징이 타겟 데이터가 없다. 현실 세계에서 라벨 작업을 하거나 타겟까지 있는 데이터를 구하는 것은 쉬운 일이 아니어서 점점 비지도 학습의 중요성이 증가하고 있으며 최근 나온 ChatGPT도 비지도학습을 이용한 대표적 사례라 할 수 있다.
06-2 k-평균
K-평균 알고리즘의 경우 랜덤하게 클러스터 개수를 정해서 시작한다. 여기에서 클러스터 수 , 즉 K값을 몇개로 하는 것이 가장 좋을까 하는 문제가 발생한다. 적절한 K값을 찾기 위해 엘보우(Elbow) 방법을 사용한다. inertia값과 클러스터 개수의 그래프를 그려서 그 그래프의 변곡점이 생기는(마치 엘보우 처럼 보이는 위치)위치에서 최적의 K값을 결정한다.
06-3 주성분 분석(PCA)
주성분 분석은 특성값이 너무 많은 경우 차원 축소를 위해 사용하는 방법이다.
Kaggle에서 대표적인 비지도 학습 데이터 Set : Fruits-360
https://www.kaggle.com/datasets/moltean/fruits
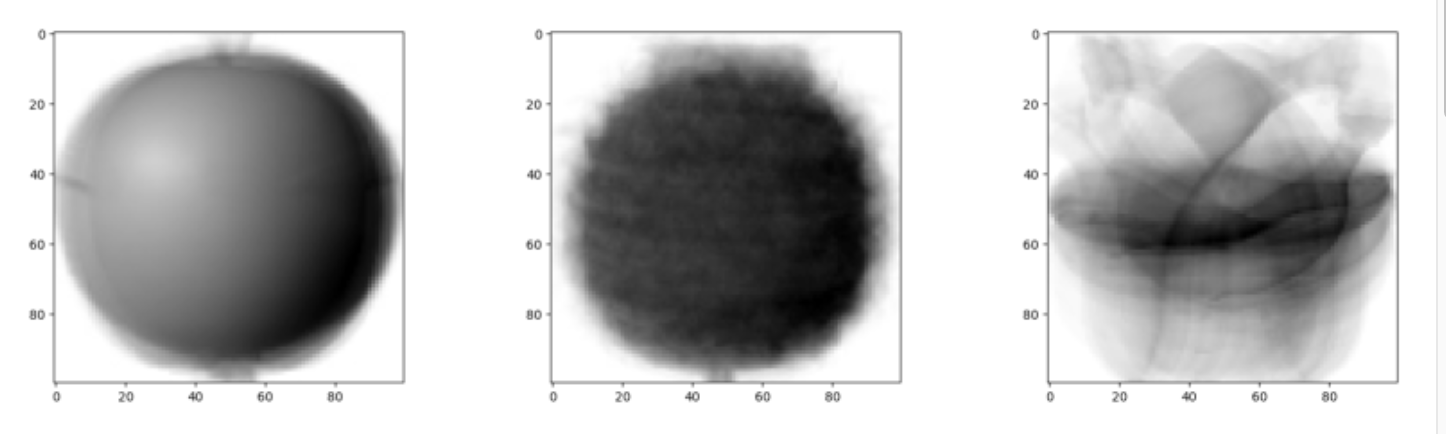
apple_mean=np.mean(apple,axis=0).reshape(100,100)
pineapple_mean=np.mean(pineapple,axis=0).reshape(100,100)
banana_mean=np.mean(banana,axis=0).reshape(100,100)
fig,axs=plt.subplots(1,3,figsize=(20,5))
axs[0].imshow(apple_mean,cmap='gray_r')
axs[1].imshow(pineapple_mean,cmap='gray_r')
axs[2].imshow(banana_mean,cmap='gray_r')
plt.show()왼쪽부터 사과, 파인애플, 바나나.

친해져요