Ch07
패션 MNIST
딥러닝에서 MNIST가 유명함 -> 손으로 쓴 0~9까지 숫자 자료. 패션 MNIST는 숫자 대신 패션 아이템으로 이루어짐
from tensorflow import keras
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()60,000개의 28*28 이미지로 되어 있음
print(train_input.shape, train_target.shape)
print(test_input.shape, test_target.shape)(60000, 28, 28) (60000,)
(10000, 28, 28) (10000,)
import matplotlib.pyplot as plt
fig, axs = plt.subplots(1, 10, figsize=(10,10))
for i in range(10):
axs[i].imshow(train_input[i], cmap='gray_r')
axs[i].axis('off')
plt.show()
로지스틱 회귀로 패션 아이템 분류하기
훈련 샘플이 6만개라 전체를 한꺼번에 하기보다는 하나씩 꺼내서 모델을 훈련하는 것이 좋다.
이럴 때 사용하는 것이 확률적 경사 하강법(SGDClassifier).
train_scaled = train_input / 255.0
train_scaled = train_scaled.reshape(-1, 28*28)
print(train_scaled.shape)(60000, 784)
train_scaled = train_input / 255.0
이 부분이 중요한데, 각 pixel이 0~255의 정수값을 가지는 값이다. 머신러닝에서 효율적으로 사용하기 위해 이 값을 0~1사이의 실수로 변경하여 정규화 시켜준다. 이를 위해 최대값으로 나누는 작업을 한다
from sklearn.model_selection import cross_validate
from sklearn.linear_model import SGDClassifier
sc = SGDClassifier(loss='log', max_iter=5, random_state=42)
scores = cross_validate(sc, train_scaled, train_target, n_jobs=-1)
print(np.mean(scores['test_score']))0.8195666666666668
max_iter=5는 SGDClassifier 반복 횟수
인공신경망
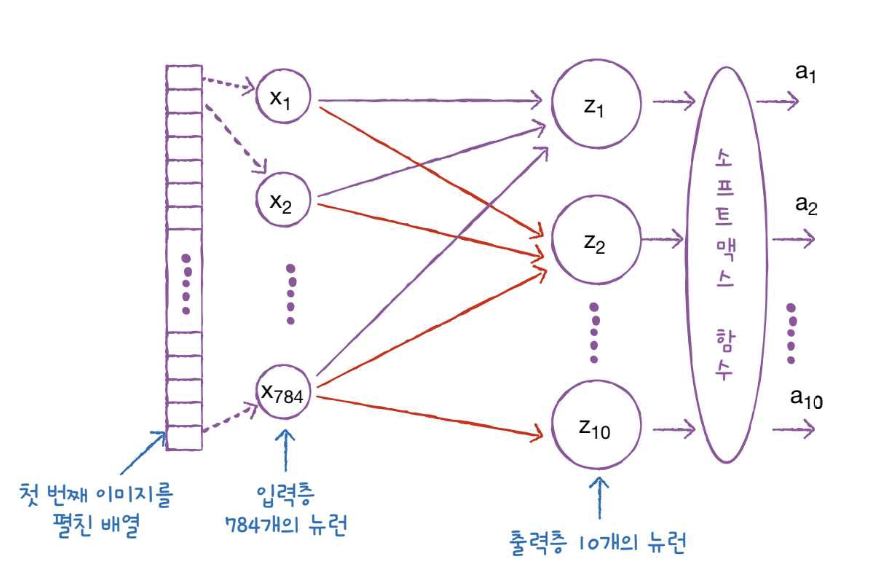{kind=link}
텐서플로와 케라스
import tensorflow as tf
from tensorflow import keras인공신경망으로 모델 만들기
from sklearn.model_selection import train_test_split
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42)
print(train_scaled.shape, train_target.shape)
print(val_scaled.shape, val_target.shape)(48000, 784) (48000,)
(12000, 784) (12000,)
dense = keras.layers.Dense(10, activation='softmax', input_shape=(784,))
model = keras.Sequential(dense)
인공신경망으로 패션 아이템 분류하기
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
print(train_target[:10])[7 3 5 8 6 9 3 3 9 9]
model.fit(train_scaled, train_target, epochs=5)결과가 할 때마다 다르게 나온다. 그러나 충분히 안정적으로 된다면 차이가 크지 않다.
model.evaluate(val_scaled, val_target)심층 신경망
2개의 층
- 케라스 API를 사용하여 패션 MNIST 데이터셋을 불러옴
- 입력층과 출력층 사이에 밀집층이 추가되었음
- 입력층과 출력층 사이에 있는 모든 층을 은닉층이라고 부름
심층 신경망 만들기
- dense1과 dense2 객체를 Sequential 클래스를 추가하여 심층 신경망을 생성
model = keras.Sequential([dense1, dense2])- summary를 통해 층에 대한 유용한 정보를 얻을 수 있음
(None, 100)
None : 샘플의 개수 →아직 정의되지 않아 None으로 출력됨
100 : 은닉층의 뉴런 개수
param 78500
샘플마다 784개의 픽셀값이 은닉층을 통과하면서 100개의 특성으로 압축됨
784 * 100 + 100 (절편)
층을 추가하는 다른 방법
Sequential 클래스의 생성자 안에서 바로 Dense 클래스의 객체를 만드는 경우
편리하지만 아주 많은 층을 추가하려면 Sequential 클래스 생성자가 매우 길어짐
Sequential 클래스의 객체를 만들고 이 객체의 add() 메서드를 호출하여 층을 추가함

렐루 함수
층이 많은 심층 신경망일수록 그 효과가 누적되어 학습을 더 어렵게 만드는데 이를 개선하기 위한 활성화 함수
이미지 분류 모델의 은닉층에 많이 사용
Flatten 클래스 사용하여 층 추가
- 배치 차원을 제외하고 나머지 입력 차원을 모두 일렬로 펼치는 역할
- 입력에 곱해지는 가충치나 절편이 없음 → 인공 신경망 성능을 위해 기여하는 바는 없음
옵티마이저Permalink
신경망의 가중치와 절편을 학습하기 위한 알고리즘 또는 방법
가장 기본적인 옵티마이저는 확률적 경사 하강법인 SGD임
SGD 옵티마이저를 사용하려면 compile() 메서드의 optimizer 매개변수를 ‘sgd’로 지정함
