
Ch 4: The Processor
1. Introduction
- CPU의 성능 요인들
- Instruction Count (ISA와 Compiler에 의해서 결정된다.)
- CPI & Cycle Time (CPU hardware에 의해서 결정된다.)
- MIPS에서의 구현
- 간단한 version (No pipeline)
- pipelined version
- 간단한 instruction의 예시만
- Arithmetic / logical : add, sub, and ,or ,slt
- Memory reference : lw, sw
- Control transfer : beq, j
1) Instruction Execution
- PC → instrcution memory, fetch instruction
- Register Numbers → register file, read registers
- Depending on instruction class
- ALU는 계산을 위해서 사용한다.
- arithmetic result
- load, store를 위한 메모리 주소
- target address로 branch
- load / store를 통한 data memory 접근
- PC ← target address or PC + 4 (branch or instruction fetch)
- ALU는 계산을 위해서 사용한다.
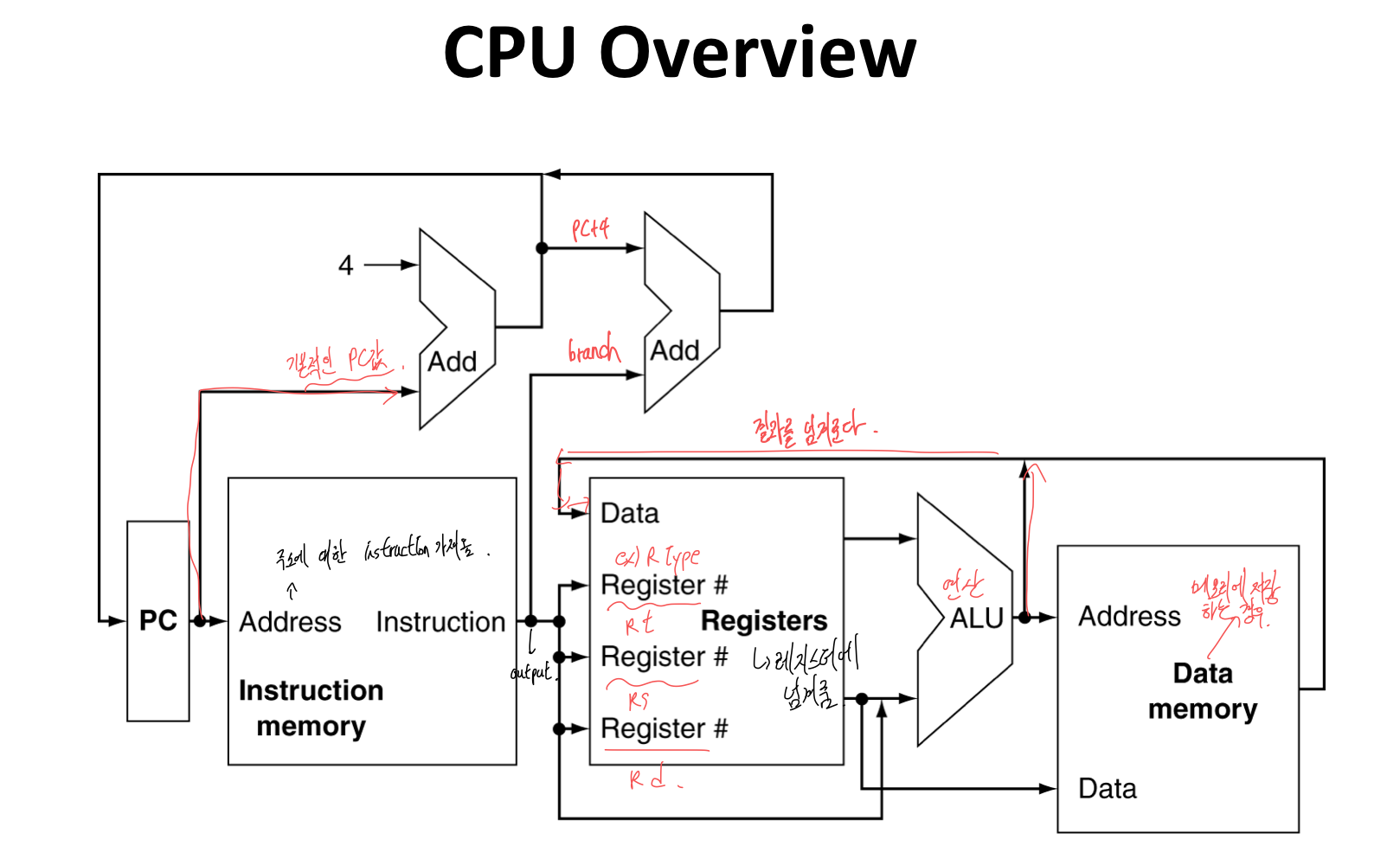
CPU의 개요
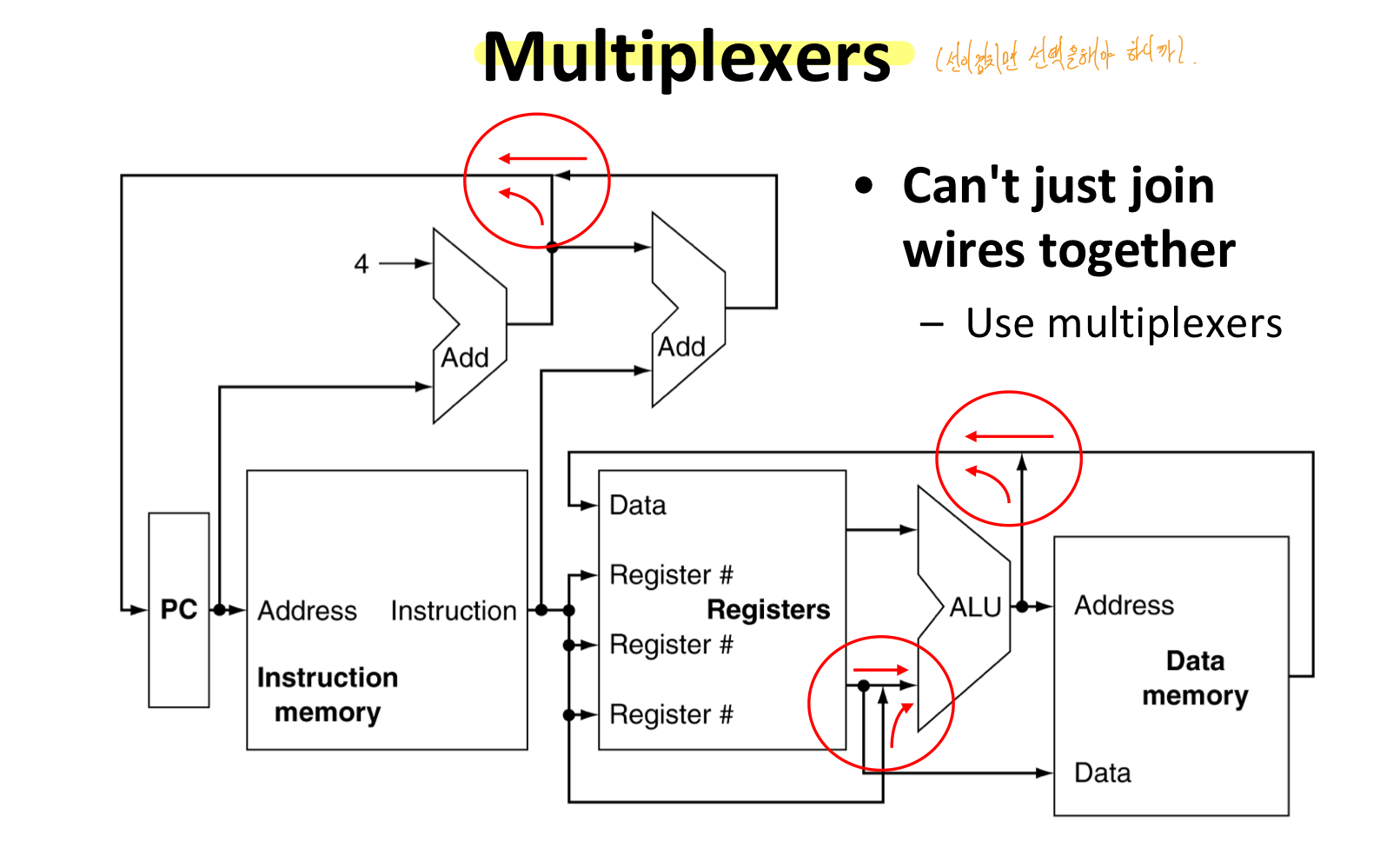
선이 겹친다면 선택을 해야하니, MUX를 추가
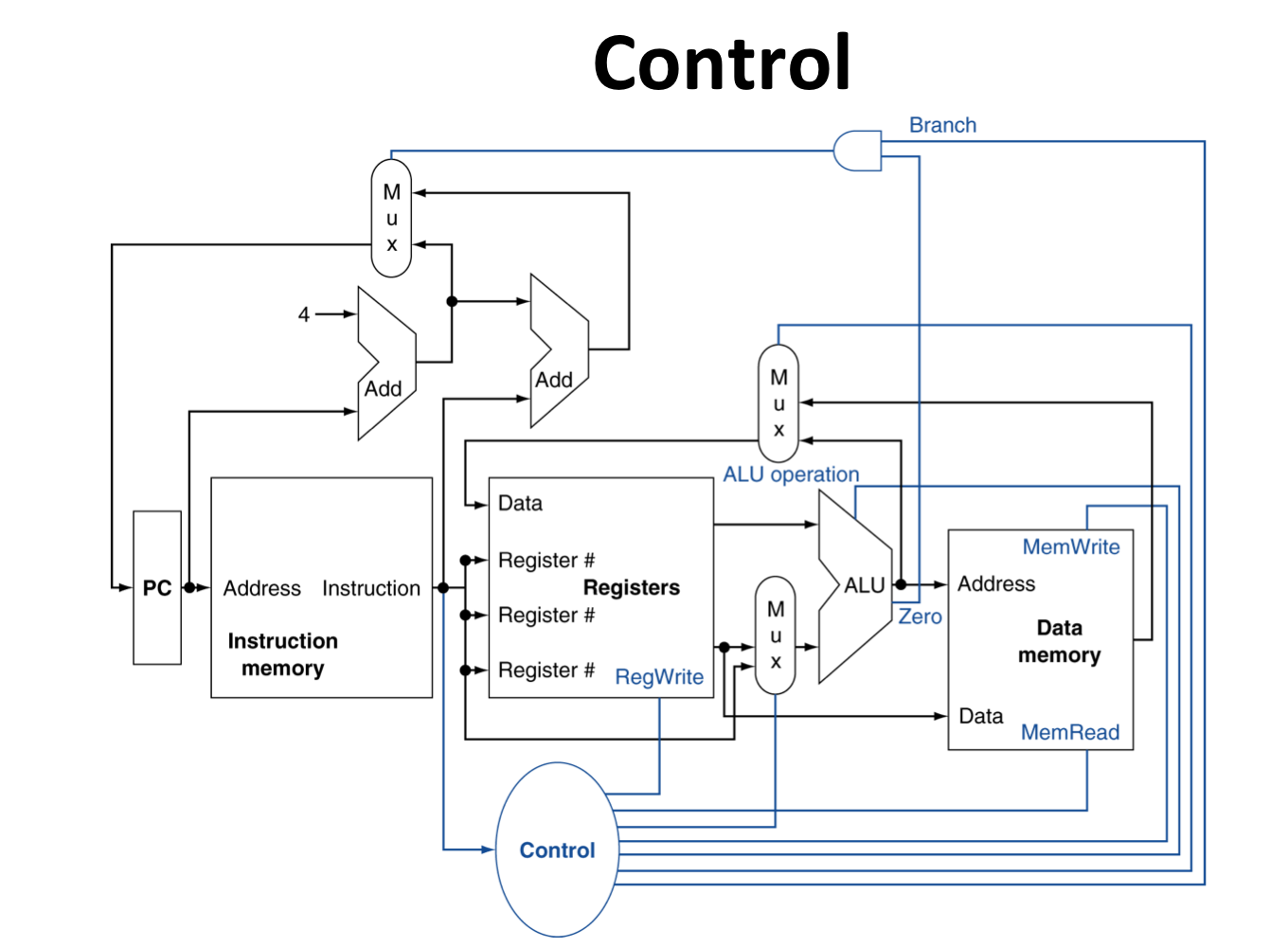
Control 추가
2) Logic Design Basics
- 정보는 Binary로 encode된다.
- Low voltage = 0, High voltage = 1
- bit당 1개의 wire
- Multi-bit data는 multi-wire buses(32-bit 데이터 묶은 것)으로 encode 되어 있다.
- Combinational Elements
- 데이터를 작동한다.
- Output is a function of input
- State(sequential elements)
- 정보를 저장한다.
a) Combinational Elements
- Input에 의해서 Output이 결정된다. 즉, input이 같다면 output도 같다.
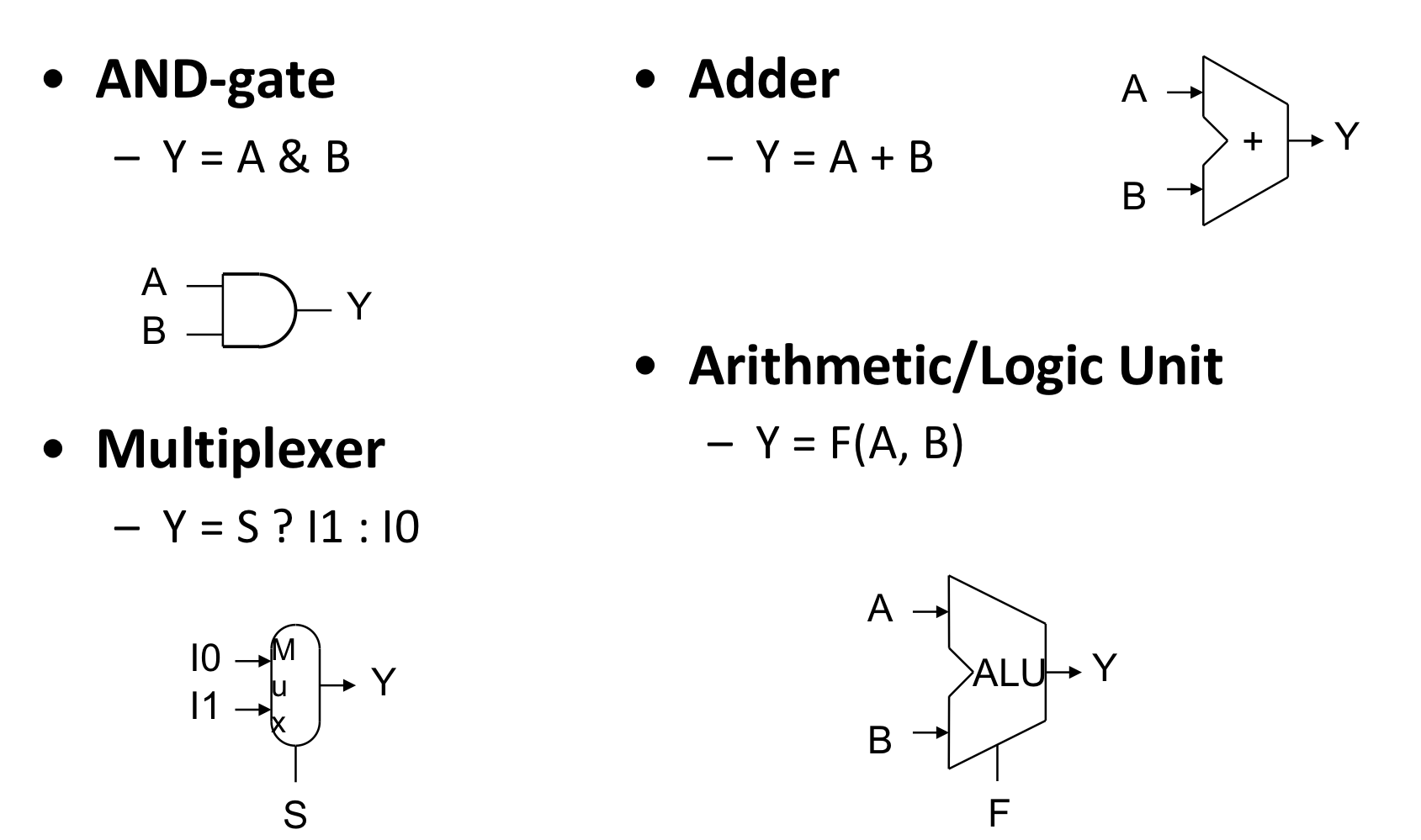
b) Sequential Elements
- Register : 회로에 데이터 저장
- Clock signal → 저장된 value를 언제 업데이트 할지 결정하기 위해 사용
- Edge-triggered : clk가 0에서 1로 바뀔때 update
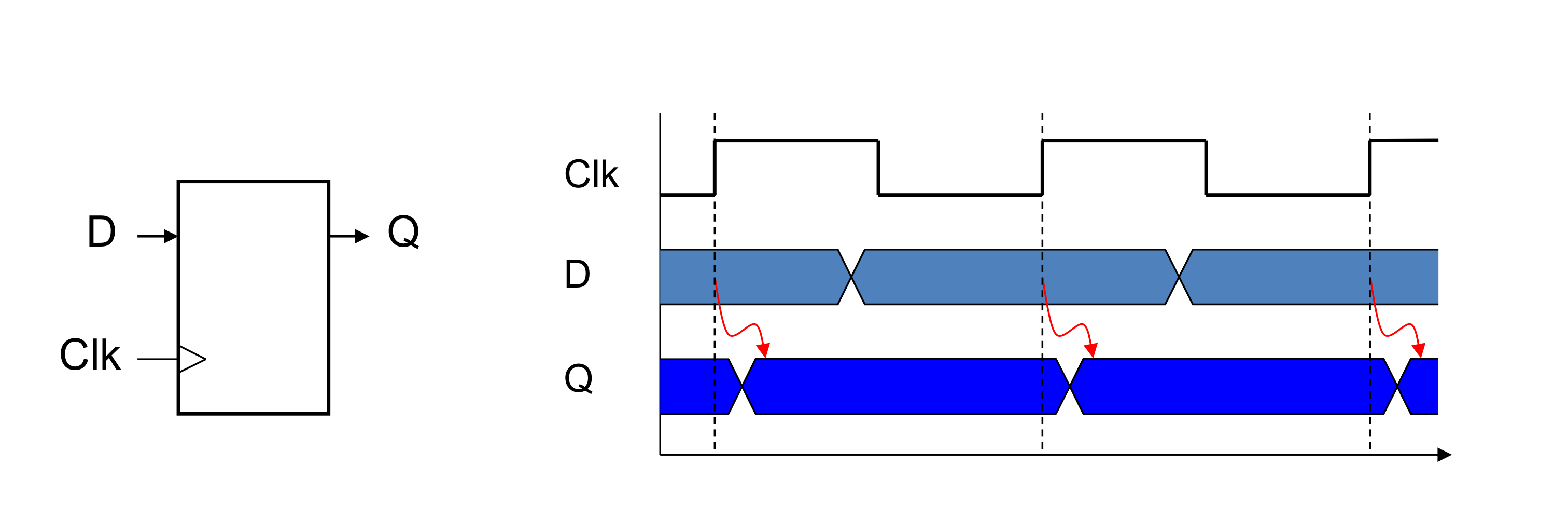
- Register with write control
- clock edge일 때, write가 1인 경우에만 update
- 저장된 value가 나중에 필요해 질 때, update
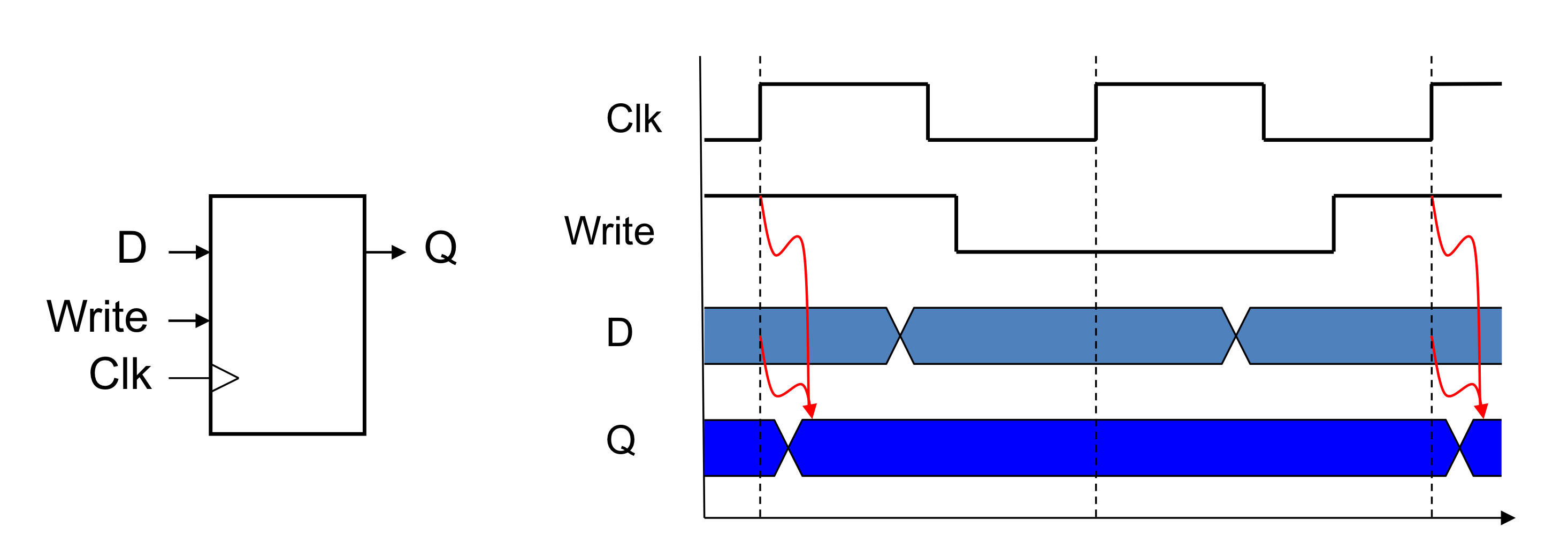
c) Clockng Methodology
- Combination logic은 clock cycle동안 데이터를 변경한다.
- 즉 clock edge 사이에
- state elements 부터 input을 받고 state element로 output을 보낸다.
- 가장 큰 지연시간이 clock period를 결정한다.
3) Building a Datapath
- Datapath
- CPU에 있는 process data와 address들의 elements
- Registers, ALUs, mux’s, memories, …
- CPU에 있는 process data와 address들의 elements
a) Instruction Fetch
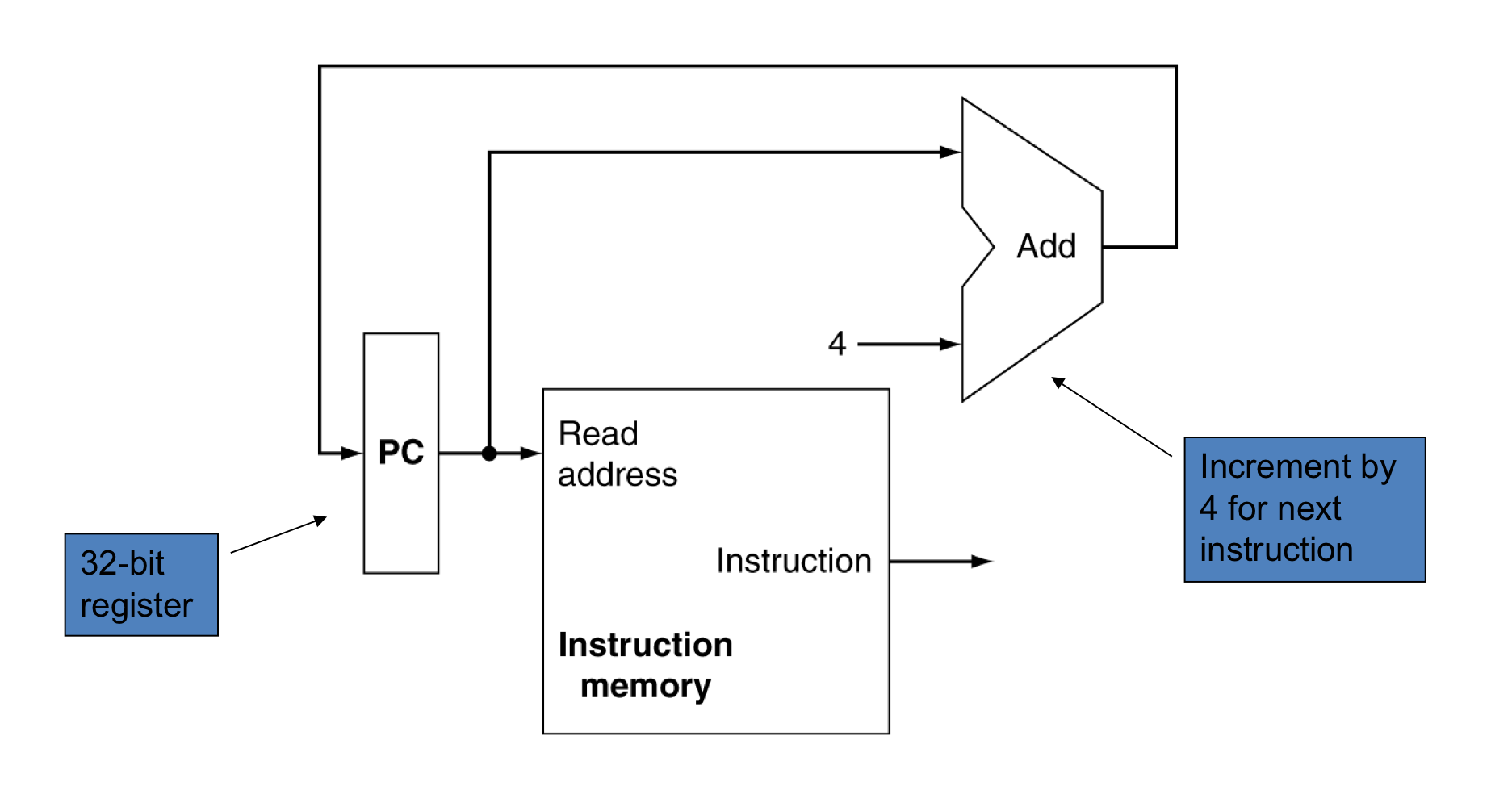
Instruciton fetch
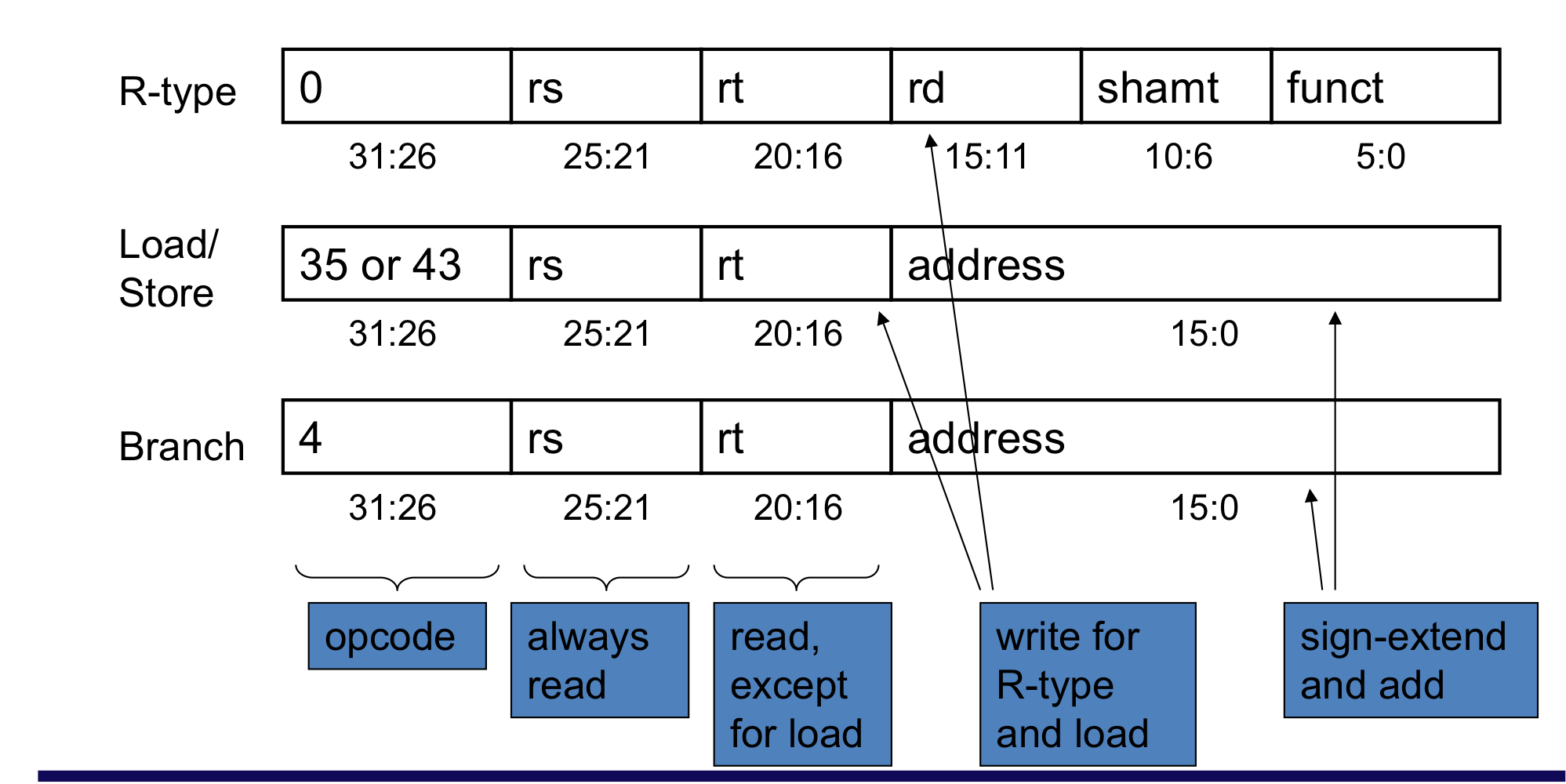
b) R-format instructions
- 2개의 register operand를 읽는다.
- arithmetic/logical 명령을 수행한다.
- register에 결과를 쓴다.
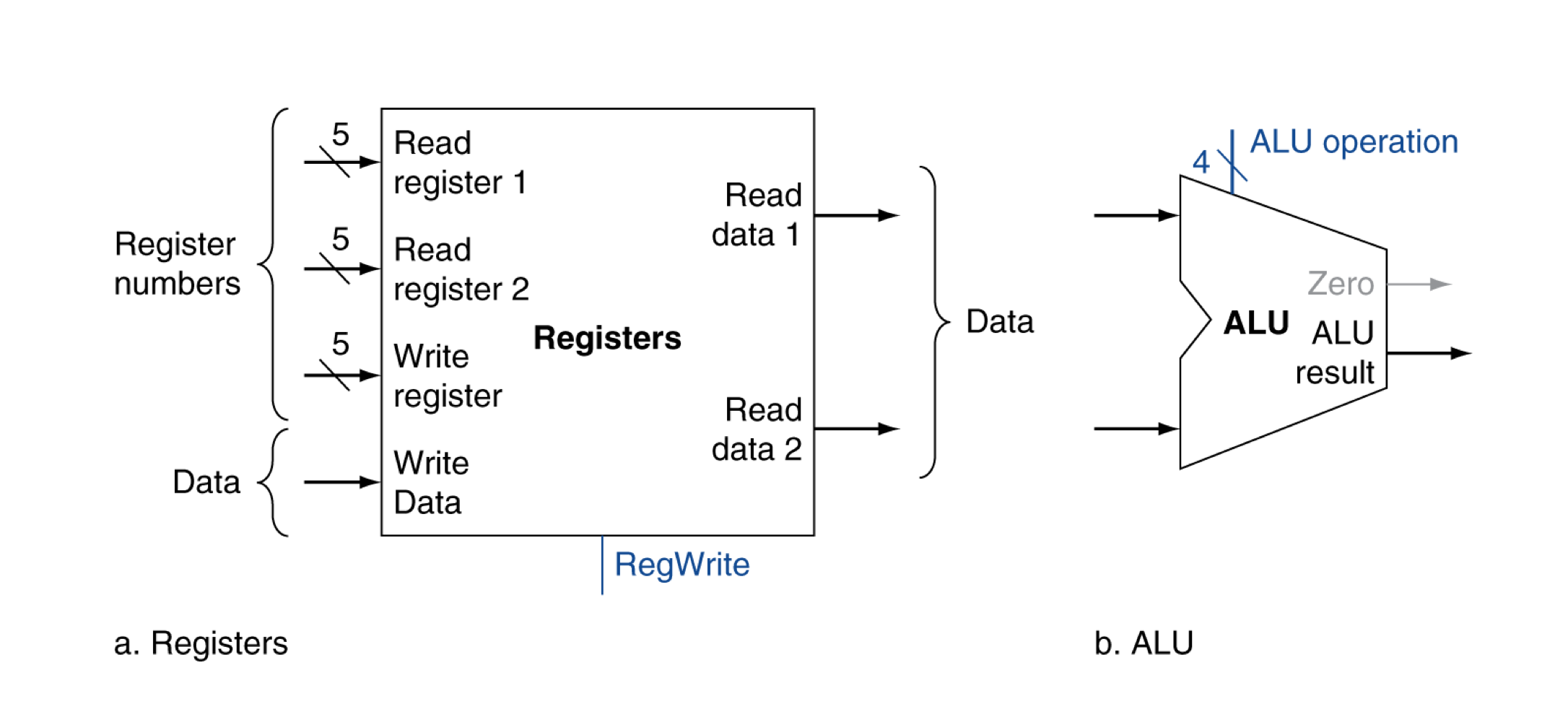
R-format instrcutions
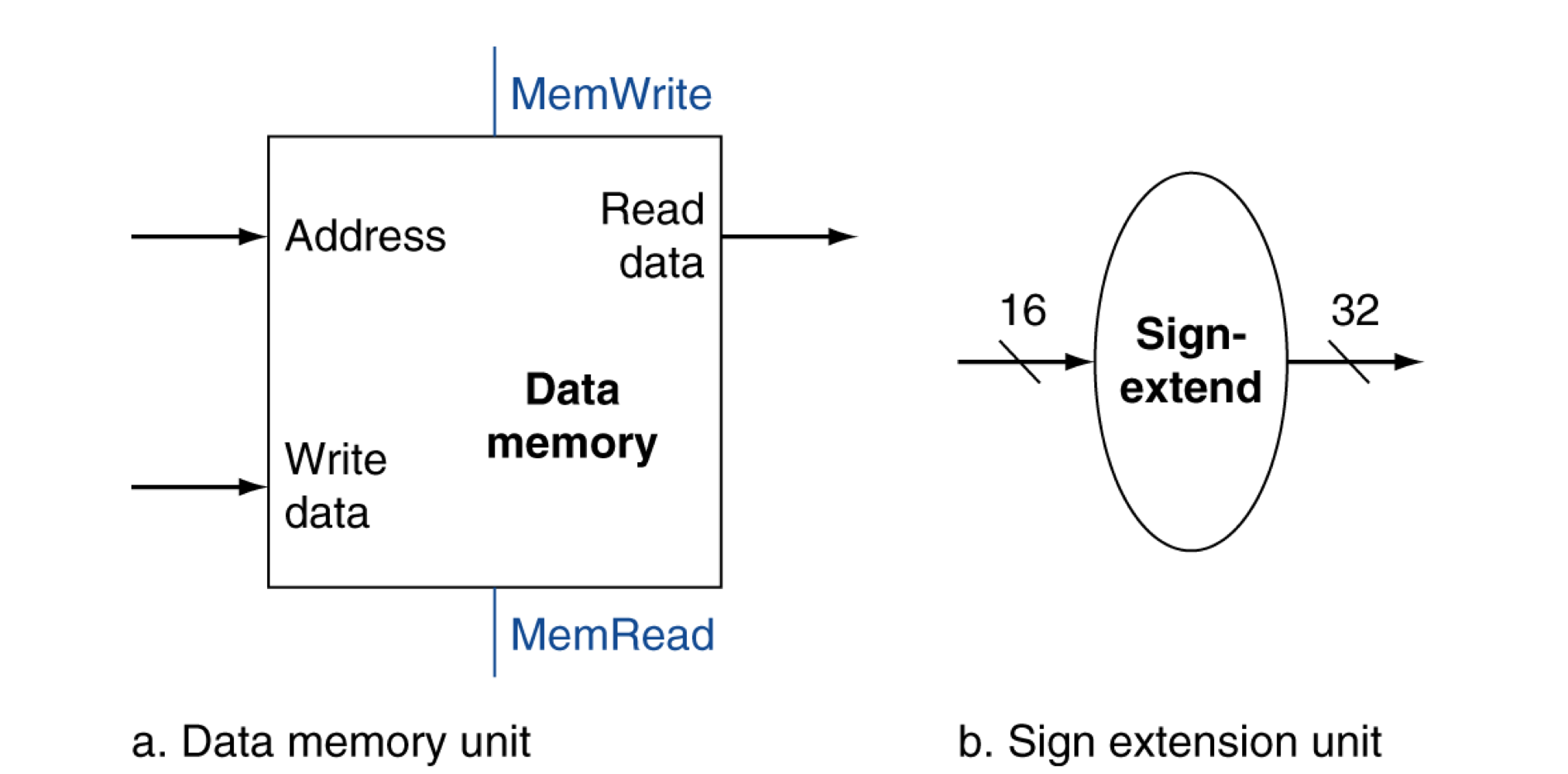
c) Load/Store instructions
- register operand들을 읽는다.
- 16-bit offset 주소를 계산한다.
- ALU를 사용해서 계산하고, sign-extend (32 bit)를 사용한다.
- Load : 메모리를 읽고 레지스터 업데이트
- Store : 레지스터 값을 메모리에 쓴다.
4) Branch instructions
- register operand들을 읽는다.
- operand를 비교한다.
- ALU사용하고, sub연산을 수행햐여 두 operand가 같은지 확인한다.
- target address를 계산한다.
- Sign-extend (32 bit)
- Shift left 2 places (word displacement)
- Add to PC + 4
- 이미 instruction fetch에 의해서 계산이 되어있음.
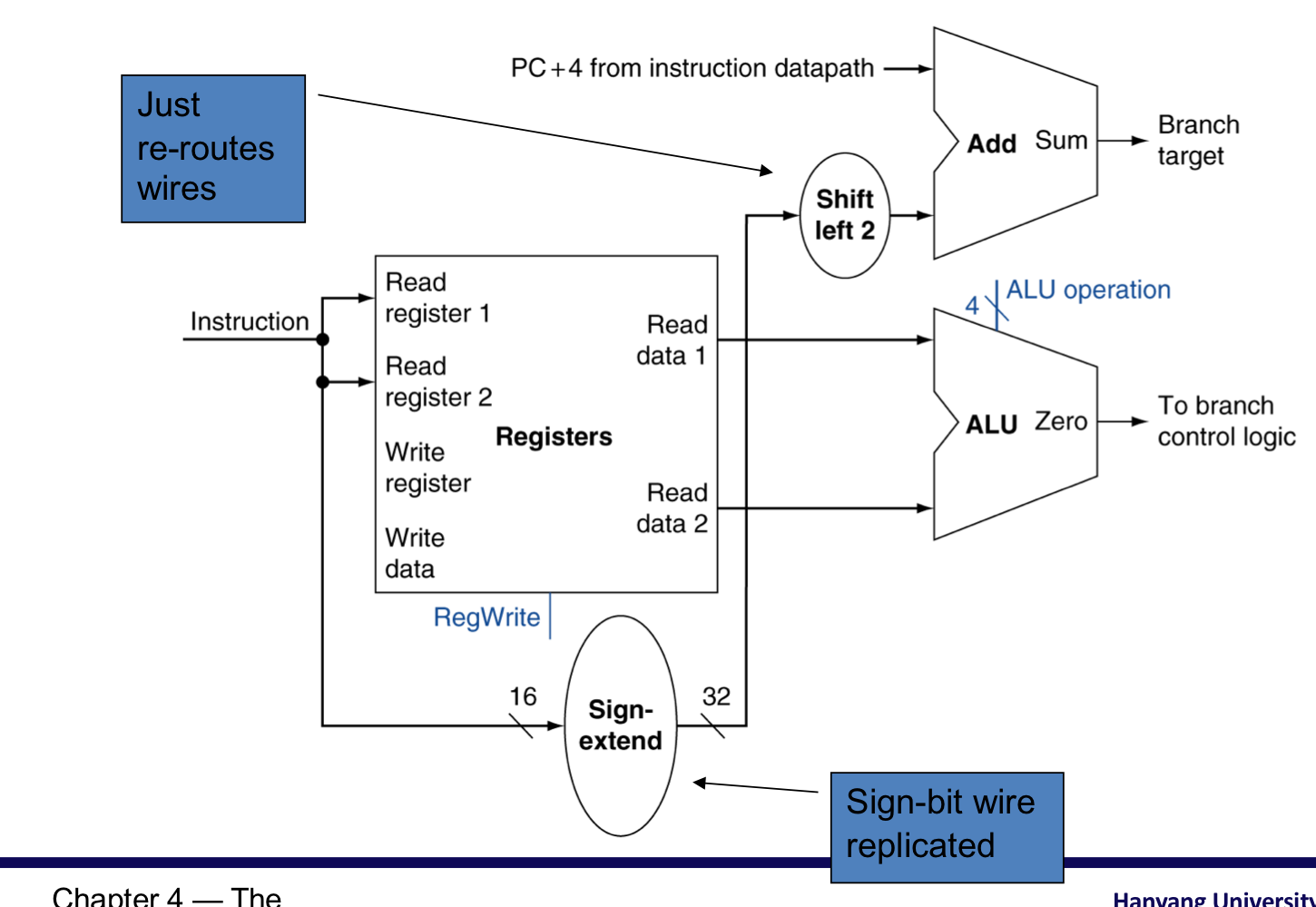
branch instrcutions
3) Composting the Elements
- 각 요소들을 통합하여 한 사이클에 동작할 수 있도록 한다.
- 한 번에 하나의 function만을 수행 할 수 있다.
- 그래서 data memory와 instruction을 분리.
- Data source가 교차하는 곳에서 MUX를 사용하여 다른 instruction들을 올바르게 사용.

R-Type/Load/Store Datapath
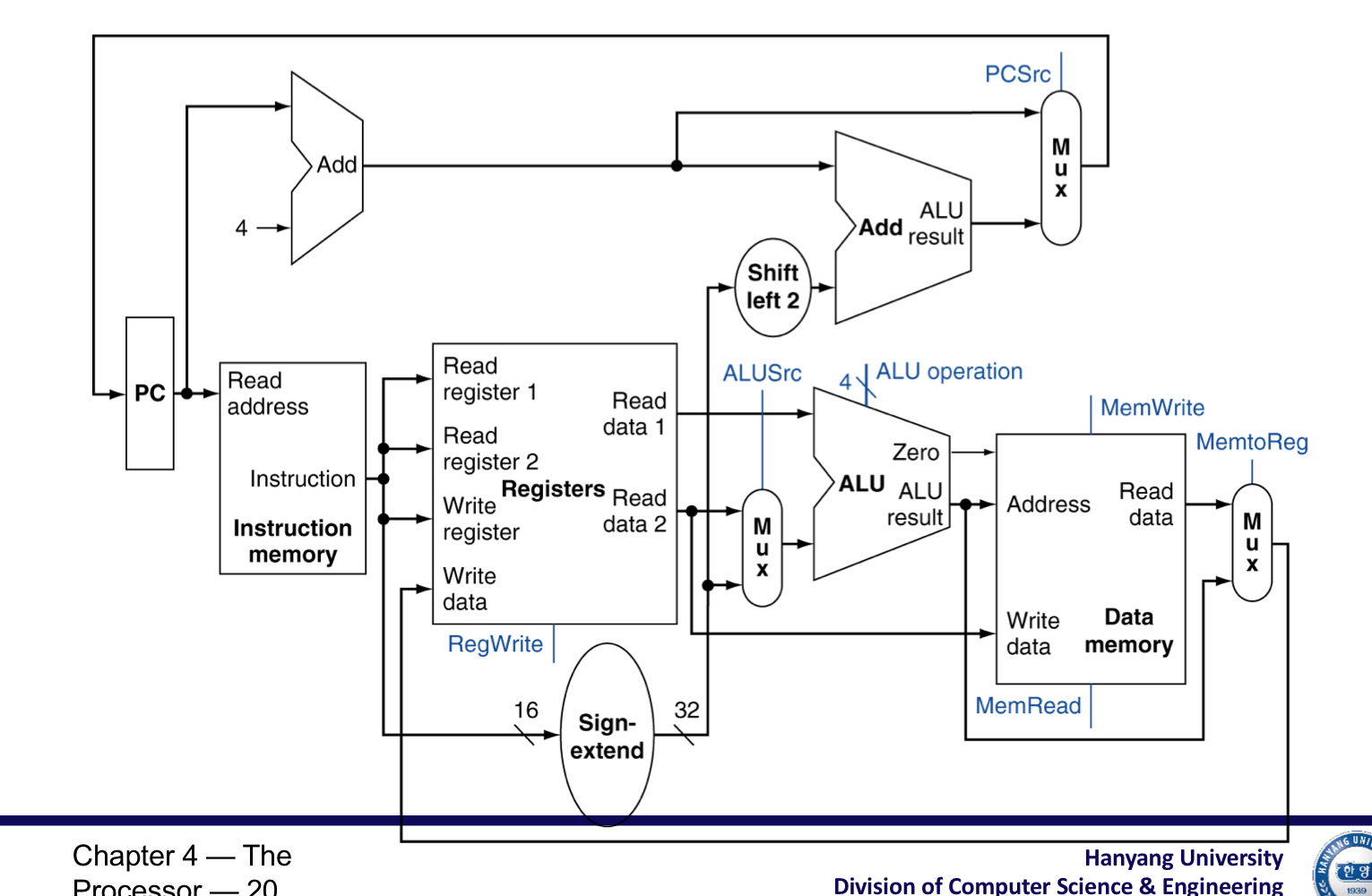
Full Datapath (같은 클럭에 주소 값 연산과, ALU연산을 한 개의 hardware에서 할 수 없기에 2개의 hardware)
4) ALU Control
- ALU의 사용
- Load/Store : F = add
- Branch : F = subtract
- R-type : F는 funct field에 따라 다르다.
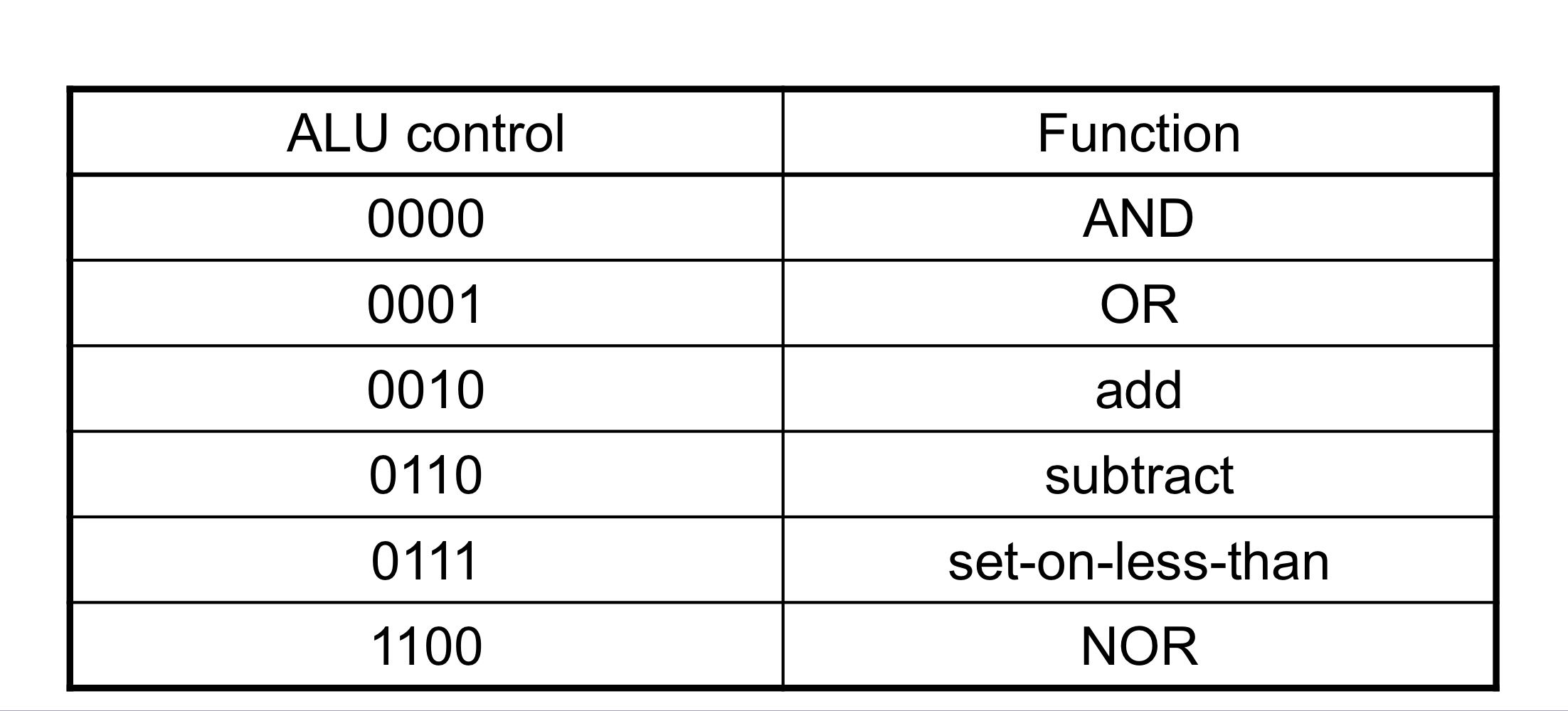
ALU Control
- opcode에서 2-bit의 ALUOp를 추출한다.
- Combinational logic을 사용해서 ALU Control을 만들어 낸다.

5) The Main Control Unit
- Control signal이 instruction으로 부터 나온다.
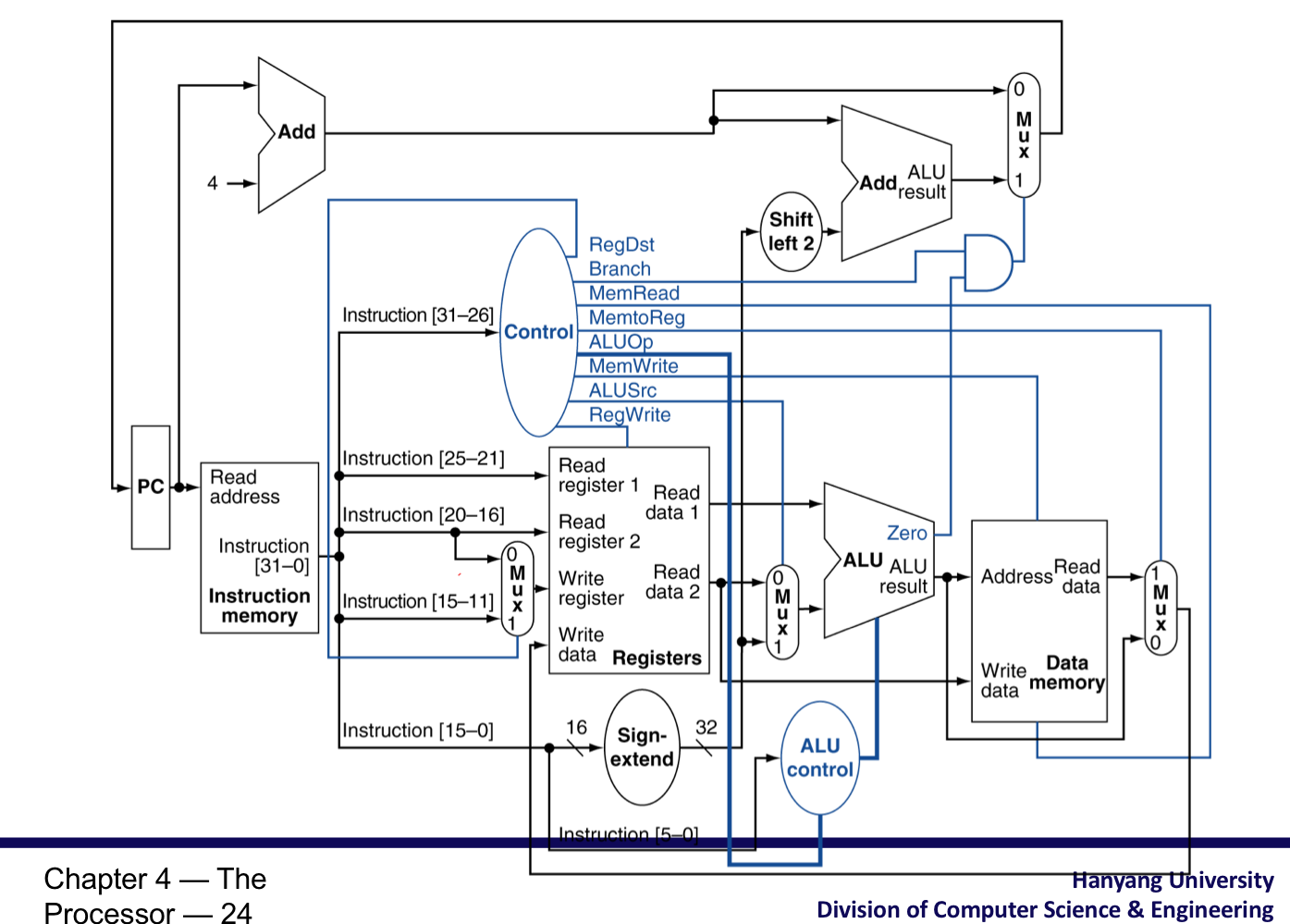
Datapath with Control
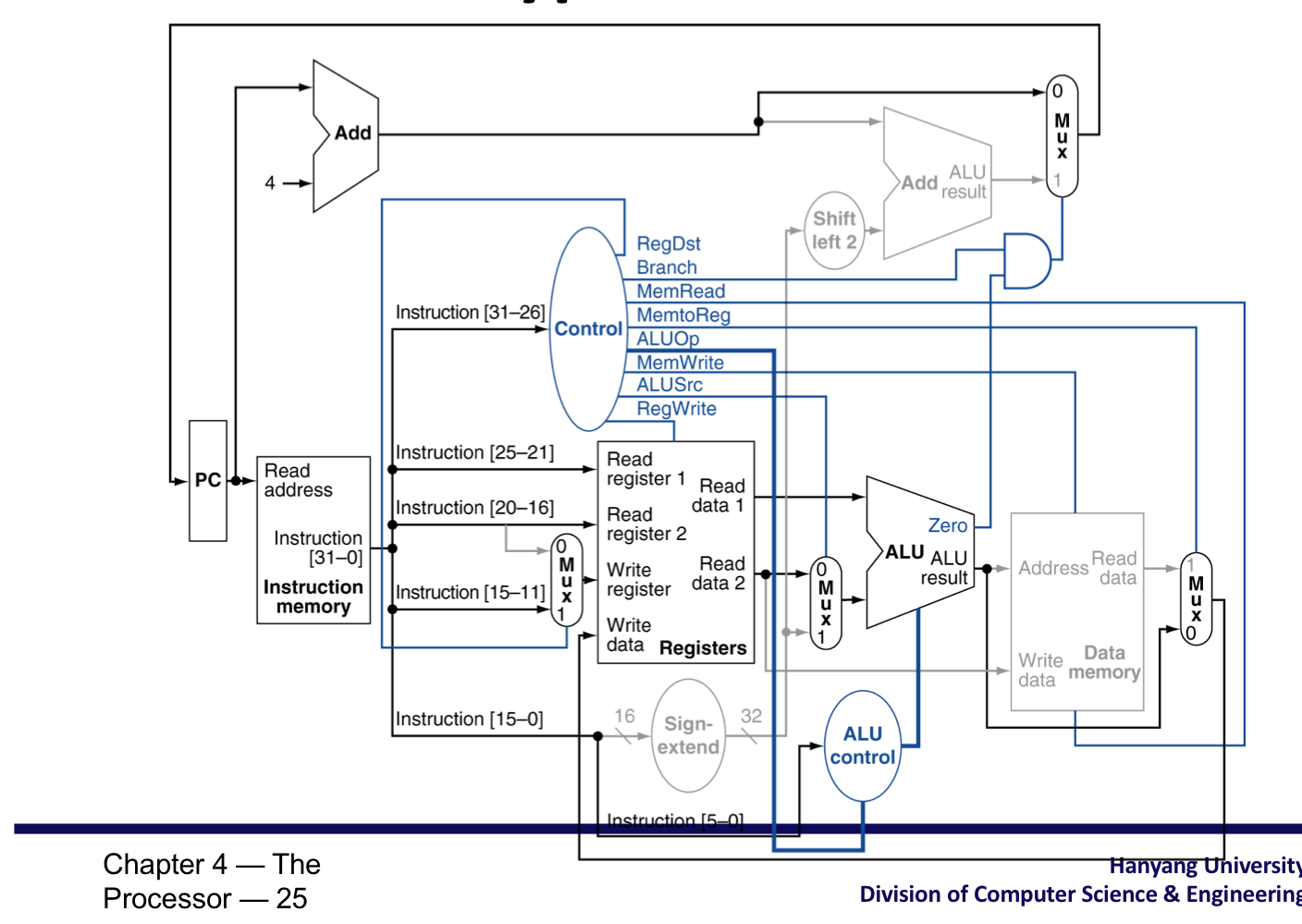
R-type instruction
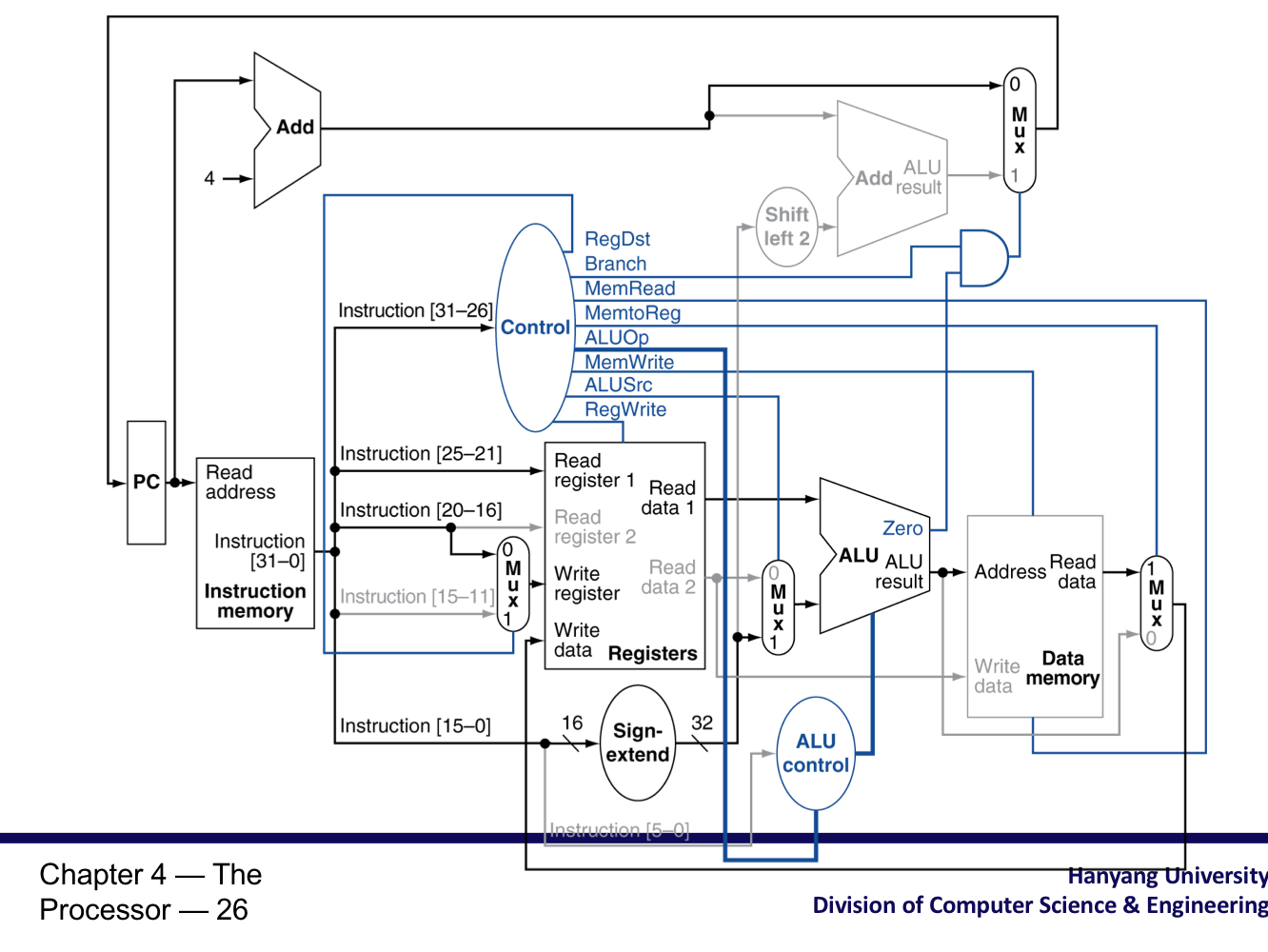
Load instruction
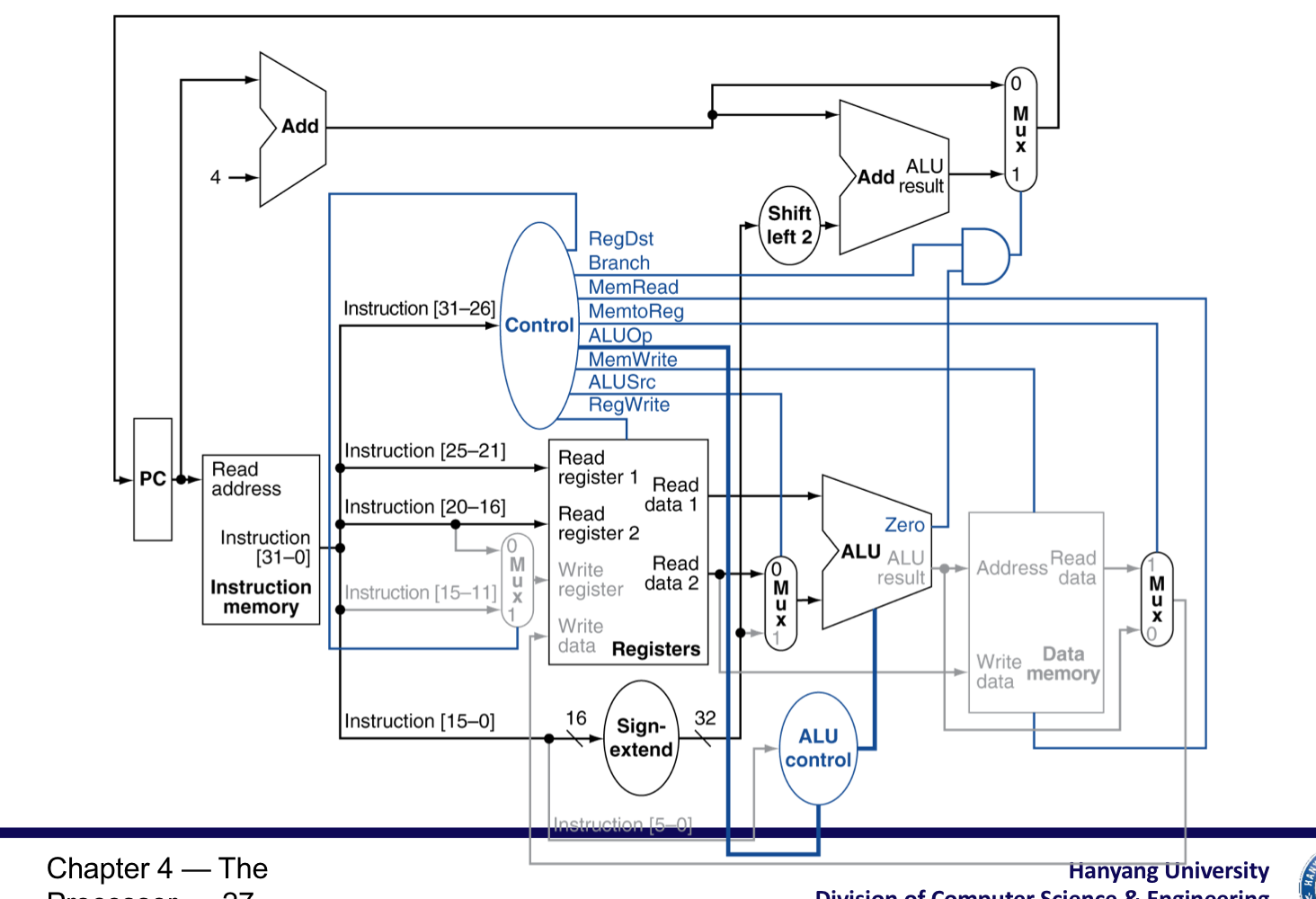
Beq instruction
6) Implementing Jumps

- Jump는 word address를 사용한다.
- PC를 해당 정보로 업데이트
- Top 4 bits of old PC
- 26-bit jump address
- 00 (word address)
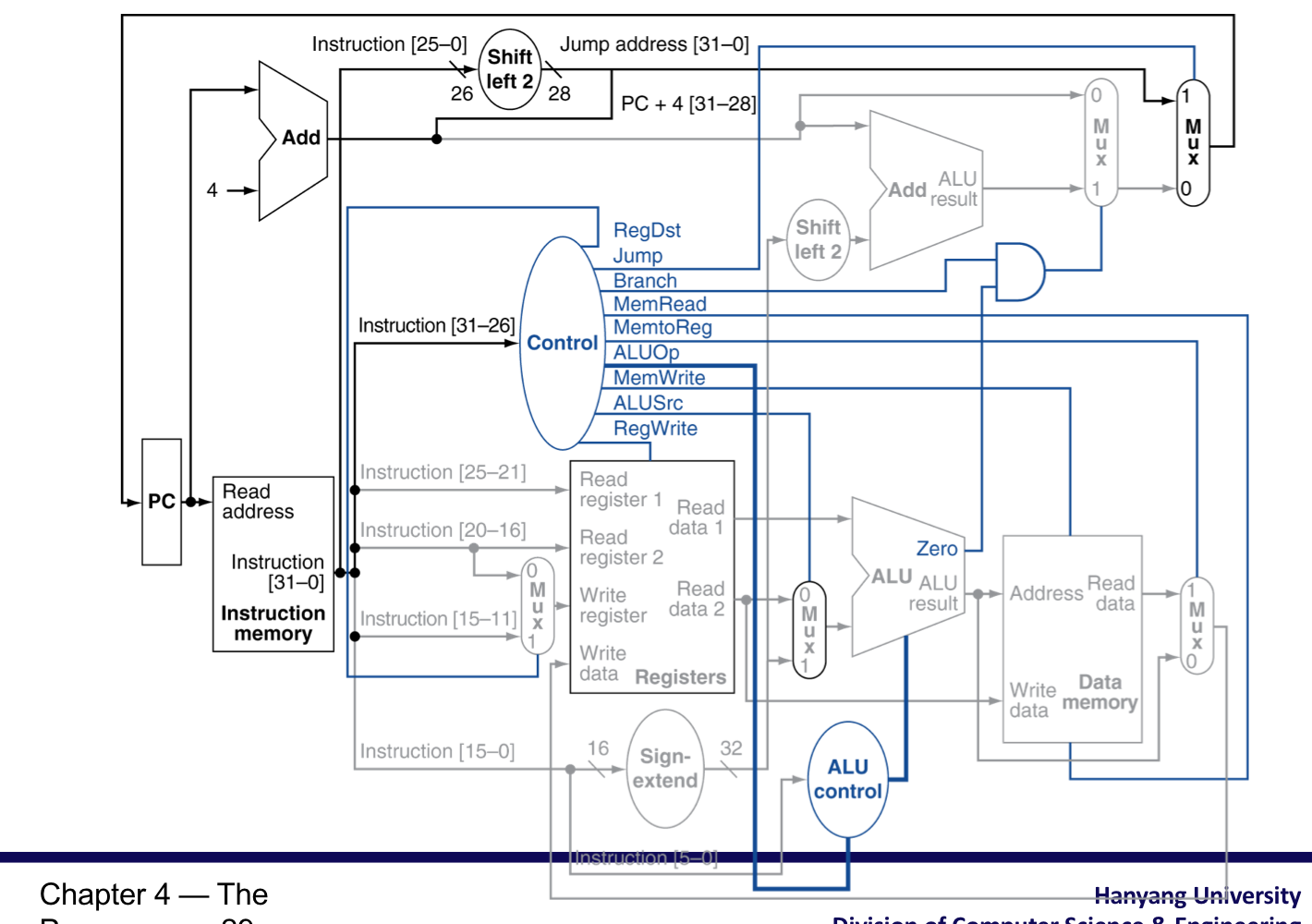
Jump instruction
7) Performance Issues
- 가장 긴 delay가 clock period를 결정한다.
- 가장 느린 instruction → load instruction
- instruction memory → register file → ALU → data memory → register file
- 다른 instrcution마다 다양한 period를 가지게 하는 것은 불가능하다.
- 이것은 design 원칙을 어긴다.
- Making the common case fast
- 가장 긴 거리를 clock period로 설정해야 하는데, 아무리 common case를 빠르게 해도, clock period가 그대로면 영향이 없다.
- Making the common case fast
2. Pipeline
1) Pipelining Analogy
- Pipelined laundry: 겹치는 실행
- Parallelism(병령 처리)는 성능을 향상시켜준다.
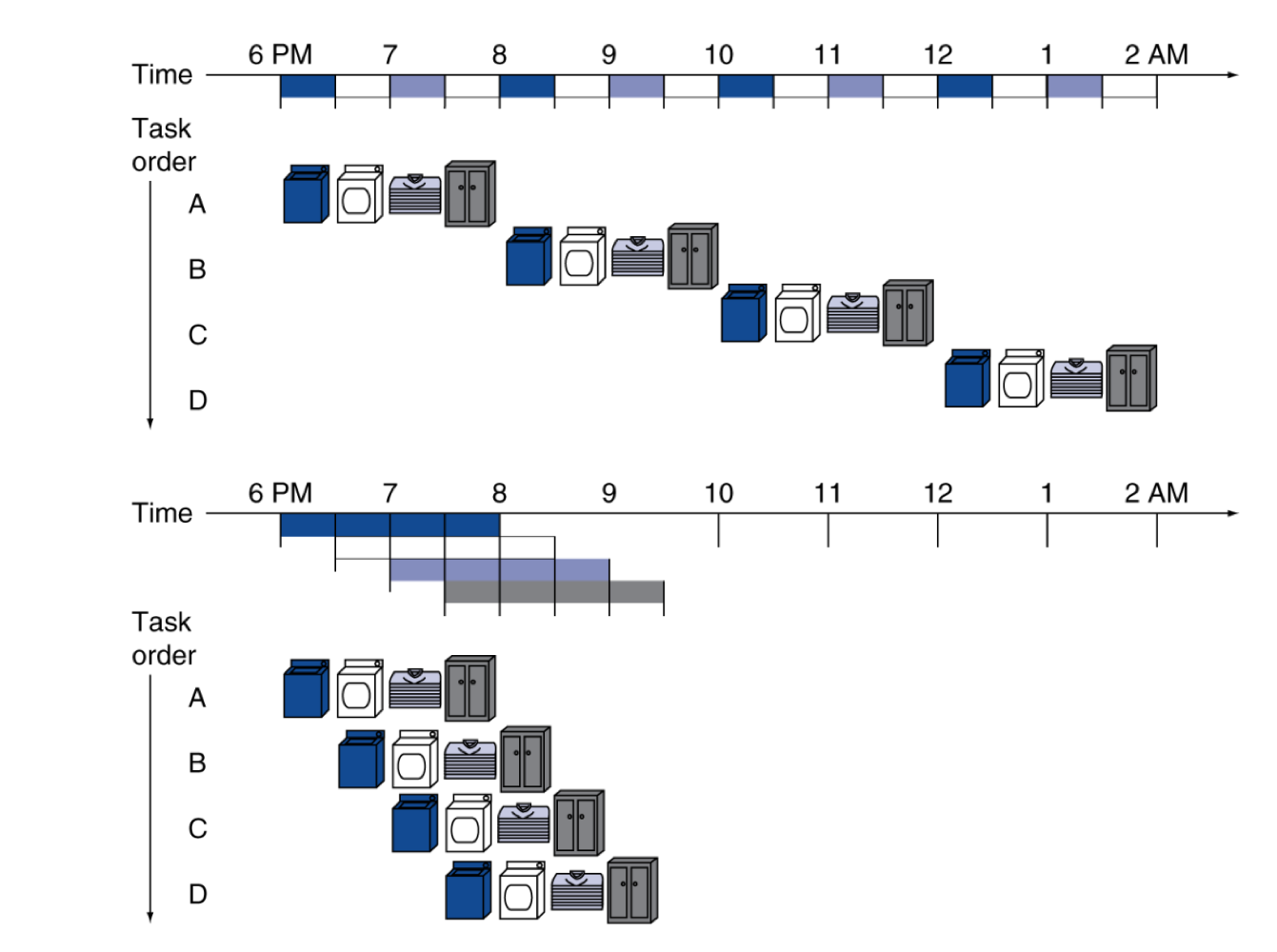
병렬의 예시
- Four loads:
- Speedup = 8/3.5 = 2.3
- Speedup = 8/3.5 = 2.3
- Non-stop(이상적인 상황):
- Speedup = 2n/0.5n + 1.5 → 4에 근사함 = number of stages
- Speedup = 2n/0.5n + 1.5 → 4에 근사함 = number of stages
2) MIPS Pipeline
- 5개의 stages, stage당 하나의 step
- IF: Instruction fetch from memory
- ID: Instruction decode & register read
- EX: Execution operation or calculate address
- MEM: Access memory operand
- WB: Write result back to register
3) Pipleline Performance
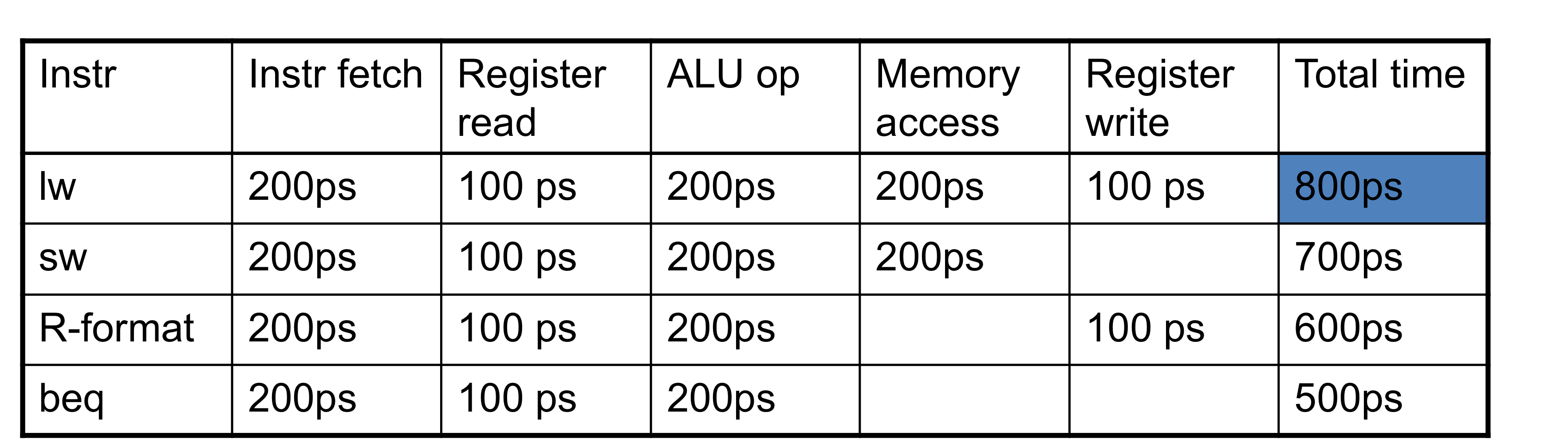
- 각 stage별 시간을 측정해보면,
- register read나 write에는 100ps
- 다른 stagesms 200ps
- pipeline화 된, 데이터 경로와 single-cycle의 데이터 경로를 비교해보면
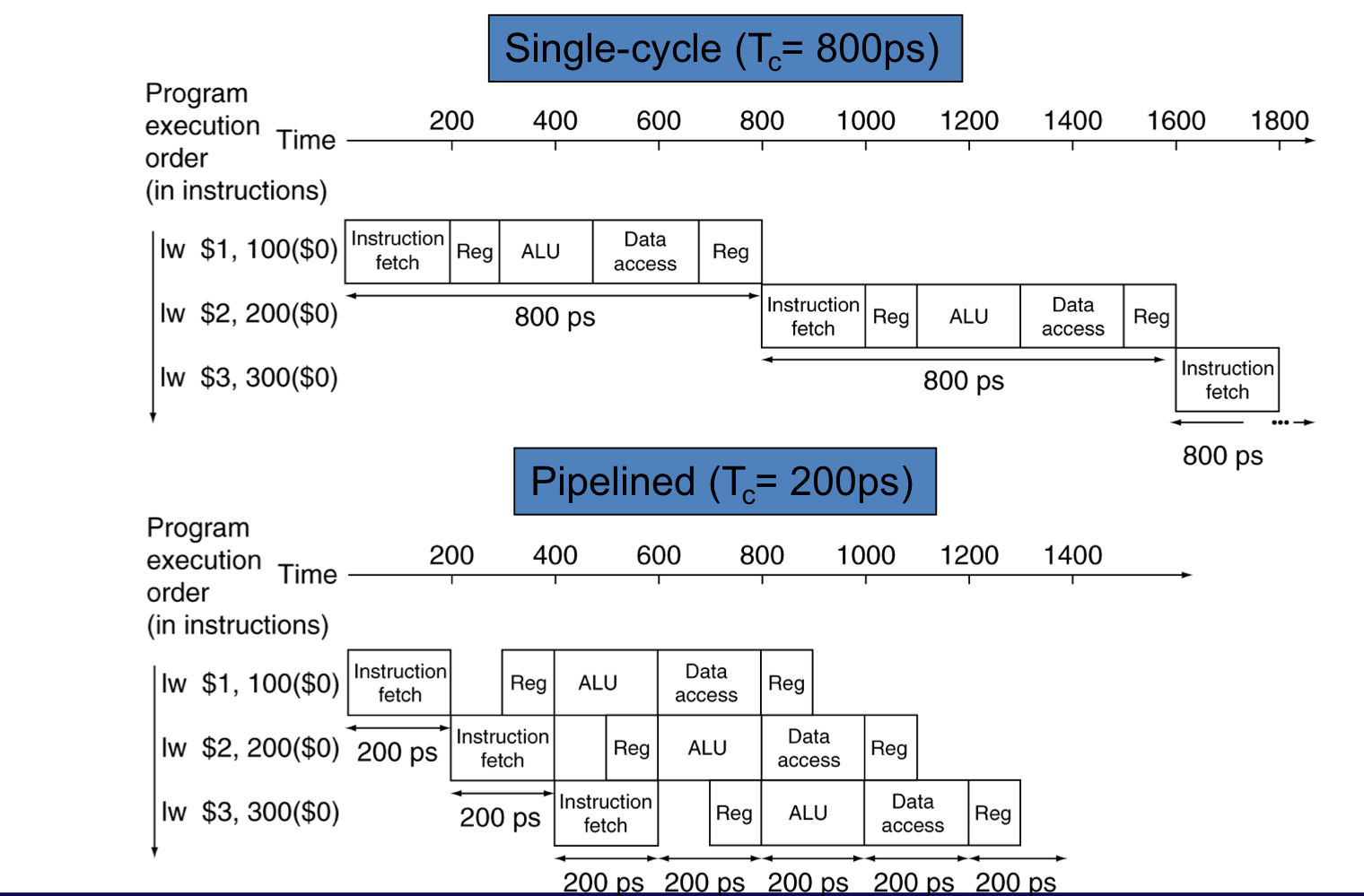
4) Pipeline Speedup
- 만약 모든 stage들이 비슷한 처리 시간을 갖는다면
-
즉, 모두 같은 시간이라면 “stage의 수”배의 성능향상 효과를 갖는다.
-
- 만약 모든 stage가 균등하지 않다면, 속도향상의 효과는 더 적다.
- 가장 느린 stage에 맞춰지기 때문이다.
- 속도 향상은 throughput을 늘려서 얻은 결과이다.
- latency(각 instruction하나 실행에 걸리는 시간) 자체는 줄어들지 않는다.
5) Pipelining and ISA Design
- MIPS ISA는 Pipelining에 적합한 구조이다.
- 모든 instruction들이 32-bits
- 1 cycle안에 fetch와 decode가 쉽다.
- c.f. x86: 1- to 17-byte instructions
- 적은 종류, 그리고 규격화 된 instruction formats
- 한 번에 decode하고, register을 read 가능 하다.
- Load/Store addressing
- 주소 계산은 3rd stage에서, 메모리 접근은 4th stage에서 할 수 있다.
- 즉, stage별로 다른 작업을 수행할 수 있다.
- Memory operands의 정렬(주소가 word단위로 정렬되어 있다.)
- 메모리 접근이 한 cycle에 이루어 진다.
- 모든 instruction들이 32-bits
3. Hazards
- 다음 cycle에서 다음 instruction이 실행되는 것을 막아버리는 상황
- 즉 매 cycle마다 instruction을 수행해야하는데 그렇지 못하는 상황
- Structure hazards
- 요청된 자원이 사용중인 경우.
- Data hazard
- instruction을 수행하기 위한 데이터가 있는데, 다른 instruction이 해당 데이터의 read/write할 때 까지 기다려야한다.
- Control hazard
- 어떤 instruction을 수행하기 위한 control action이 이전 instruction에 종속적인 경우.
1) Structure Hazards
- 자원을 사용하는 것에서의 충돌
- single memory를 사용하는 MIPS pipeline에서
- Load/store는 data access를 필요로한다.
- Instruction fetch도 instruction을 가지고 오기 위해 memory에 접근한다.
- 서로 동시에 진행될 순 없기에, 한 쪽은 대기를 해야하는 stall이 발생 할 수 있다.
- pipeline에 “bubble”을 야기
- 그러므로, pipelined datapaths는 분리된 instruction/data memory를 필요로한다.
- 혹은, instruction/data caches를 분리
2) Data Hazards
- instruction은 이전 instruction에 대한 데이터 접근이 완전히 끝나는 것에 종속적이다.
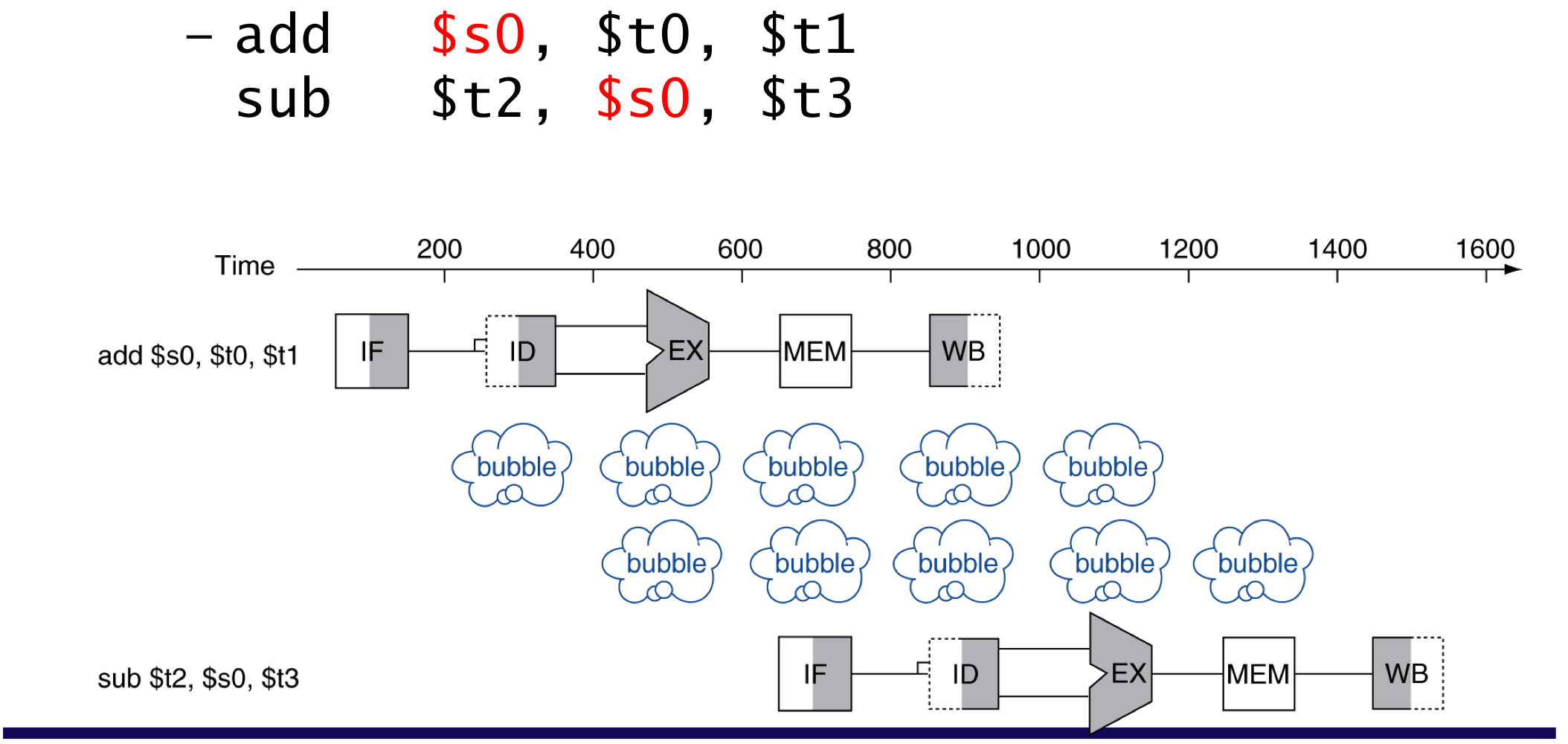
add연산에서 s0레지스터에 결과 값을 써야 sub가 정상적으로 동작
a) Forwarding (aka Bypassing)
- 계산된 직후의 결과를 바로 사용한다.
- register에 저장되는 것을 기다리지 않는다.
- datapath에 추가적인 연결이 필요하다.
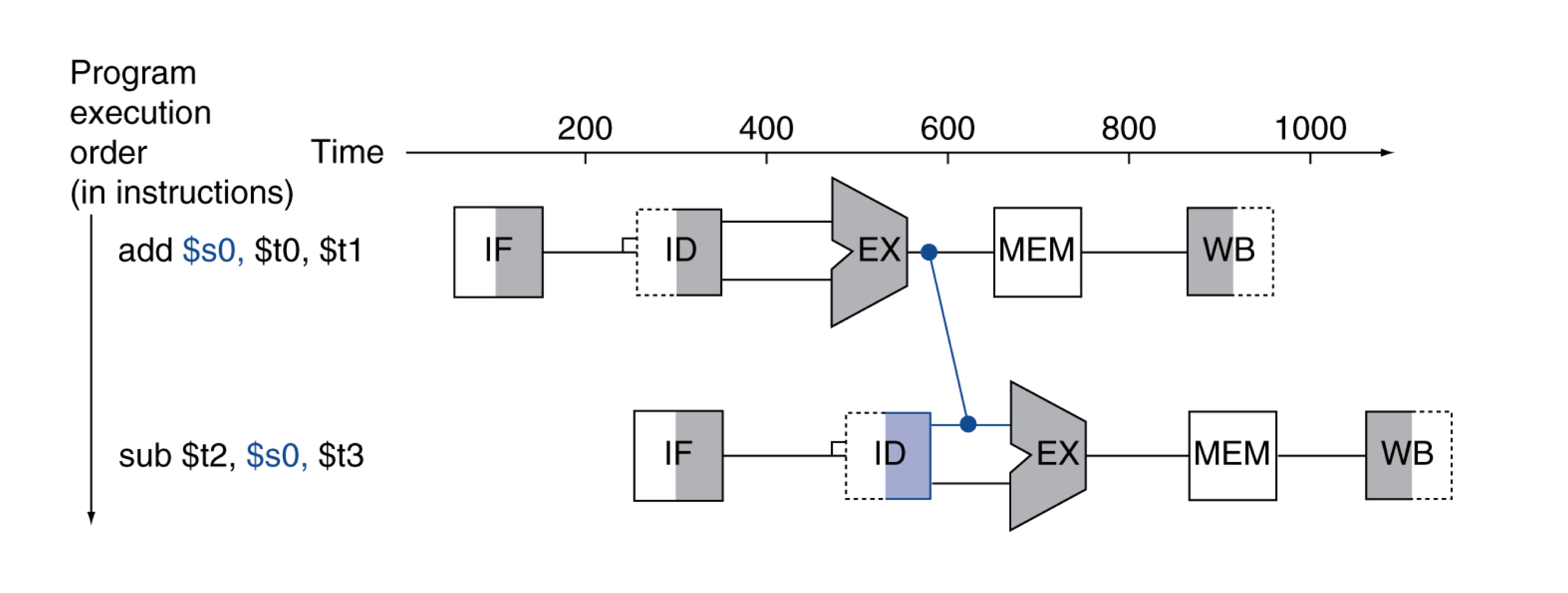
EX단계에서 나오는 값을 바로 사용
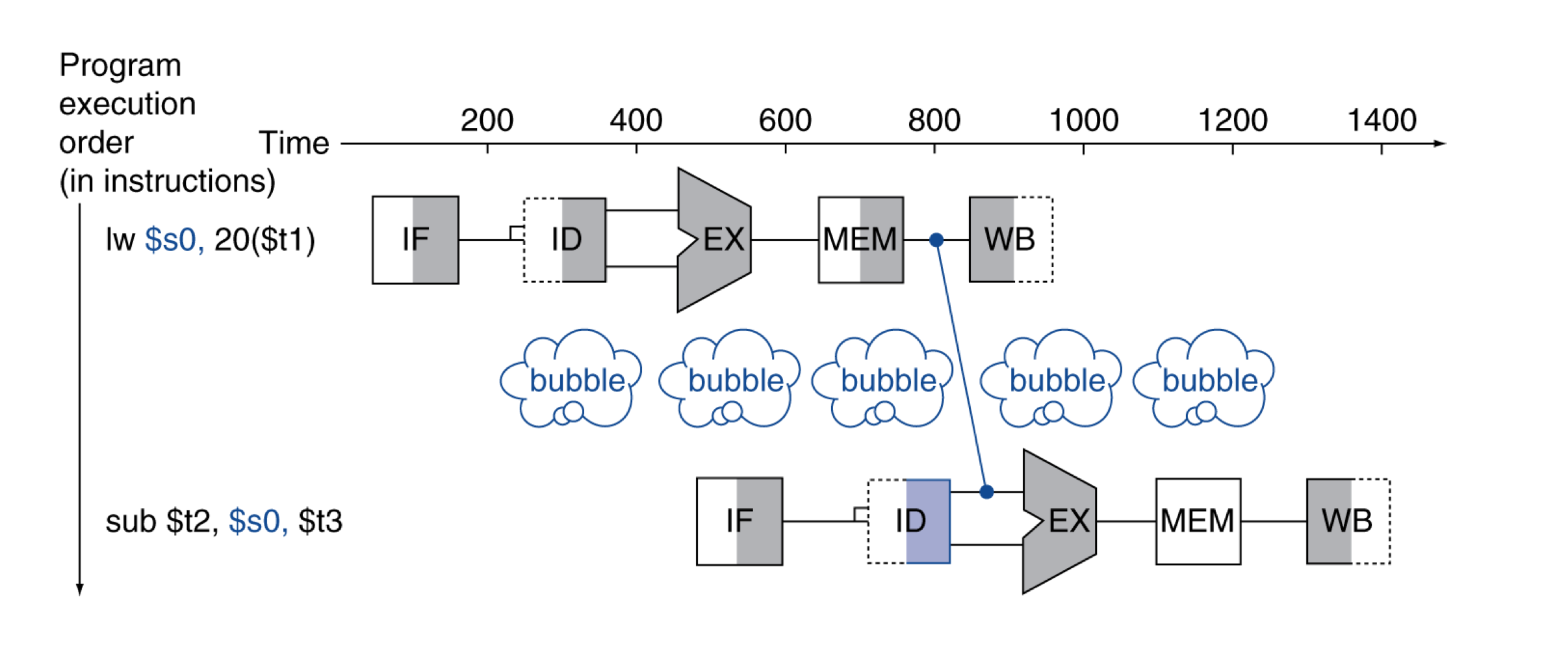
b) Load-Use Data Hazard
- 항상 forwarding으로 stall을 피할 수 없다.
- 결과가 필요한 순간에 아직 계산이 완료되지 않았다면.
- 시간을 뒤로 돌리는 것은 불가능하다.
c) Code scheduling to avoid stalls
- code scheduling으로 stall을 피하기
A = B+C;
C = B+F;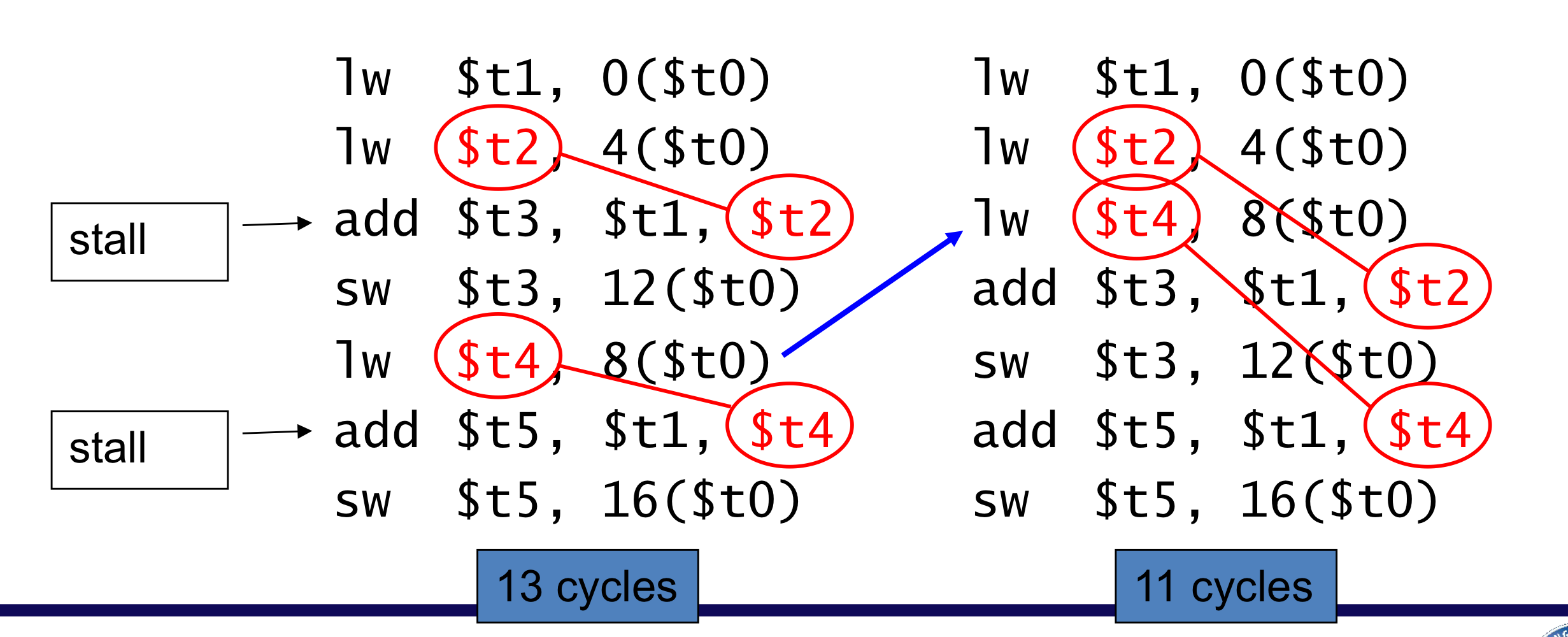
- 원래는 t2에 대한 load 후 바로 add연산을 수행, t4에 대한 loadd 후 바로 add연산 수행 때문에 2개의 stall이 발생 했지만, 순서를 바꾸어서 stall을 제거
3) Control Hazards
- Branch는 control의 flow를 결정한다.
- branch 결과를 통해서 다음 instruction을 결정
- Pipeline은 항상 올바른 instruction을 가져올 수 없다.
- branch의 ID stage가 여전히 작업중이기 때문에.
- In MIPS pipeline
- register를 비교하는 것과 점프 대상 주소 계산을 미리 해야한다.
- ID stage에 Add hardware
a) Stall on Branch
- 다음 Instruction을 가져오기 전에 branch 결과가 결정되는 것을 기다린다.

b) Branch Prediction
- 긴 pipeline에서는 이전의 branch 결과가 결정되는 것을 기다릴 수 없다.
- stall로 인한 불이익이 매우 커질 수 있다.(결과를 최대한 당겨도 여러 cycle의 stall, stage수가 많기 때문에)
- branch결과를 예측
- 만약 예측이 틀렸을 경우에만 stall이 발생
- In MIPS pipeline
- branch 결과를 “일어나지 않은 것”으로 예측 할 수 있다.
- 이렇게 해서 instruction fetch를 delay 없이 가능
c) MIPS with Predict Not Taken
- 즉, 순차적인 흐름으로 예측한다.
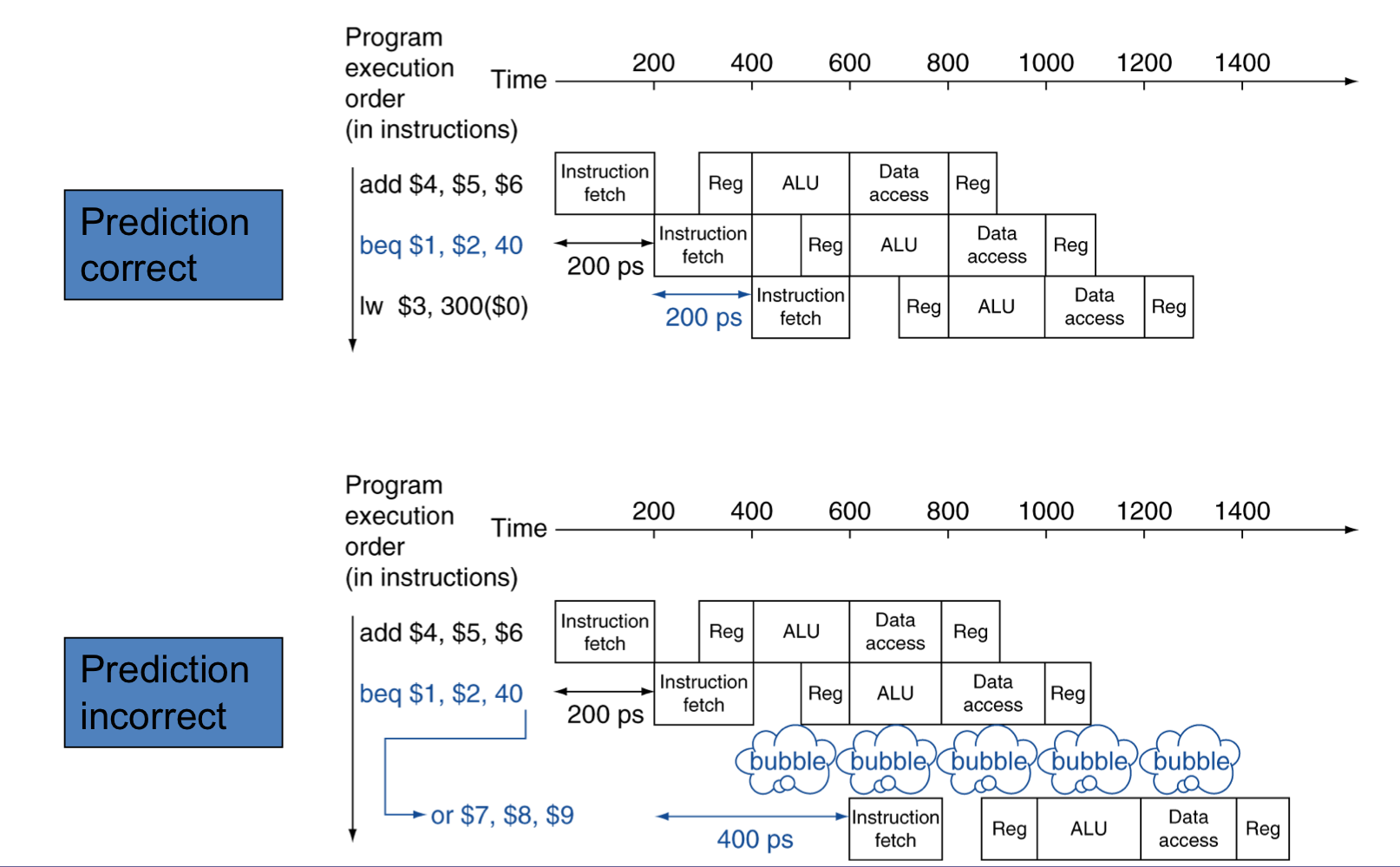
d) More-Realistic Branch Prediction
- Static branch prediction
- 전형적인 branch 동작에 기인한다.
- Example: loop and if-statement branches
- 되돌아가는 branch는 일어날 것으로 예상한다.
- 진행하는 branch는 일어나지 않을 것으로 예상한다.
- Dynamic branch prediction
- hardware가 실제의 branch 동작을 예측한다.
- e.g. 각 branch의 최근 history를 기록한다.
- 미래의 동작이 그동안의 경향을 따를 것으로 예측한다.
- 틀린다면, stall이 발생하고 re-fatching 그리고, history를 업데이트
- hardware가 실제의 branch 동작을 예측한다.
4) Pipeline Summary
- Pipelining은 instruction throughput을 늘림으로써 성능을 개선한다.
- multiple instruction들을 병령적으로 실행한다.
- 각 instruction은 같은 latency를 가진다.
- Subject to harzards
- Structure, data, control
- Instruction set은 pipeline 구현의 복잡도에 영향을 미친다.
- ISA가 간단하면 Pipeline 구현도 쉽다.
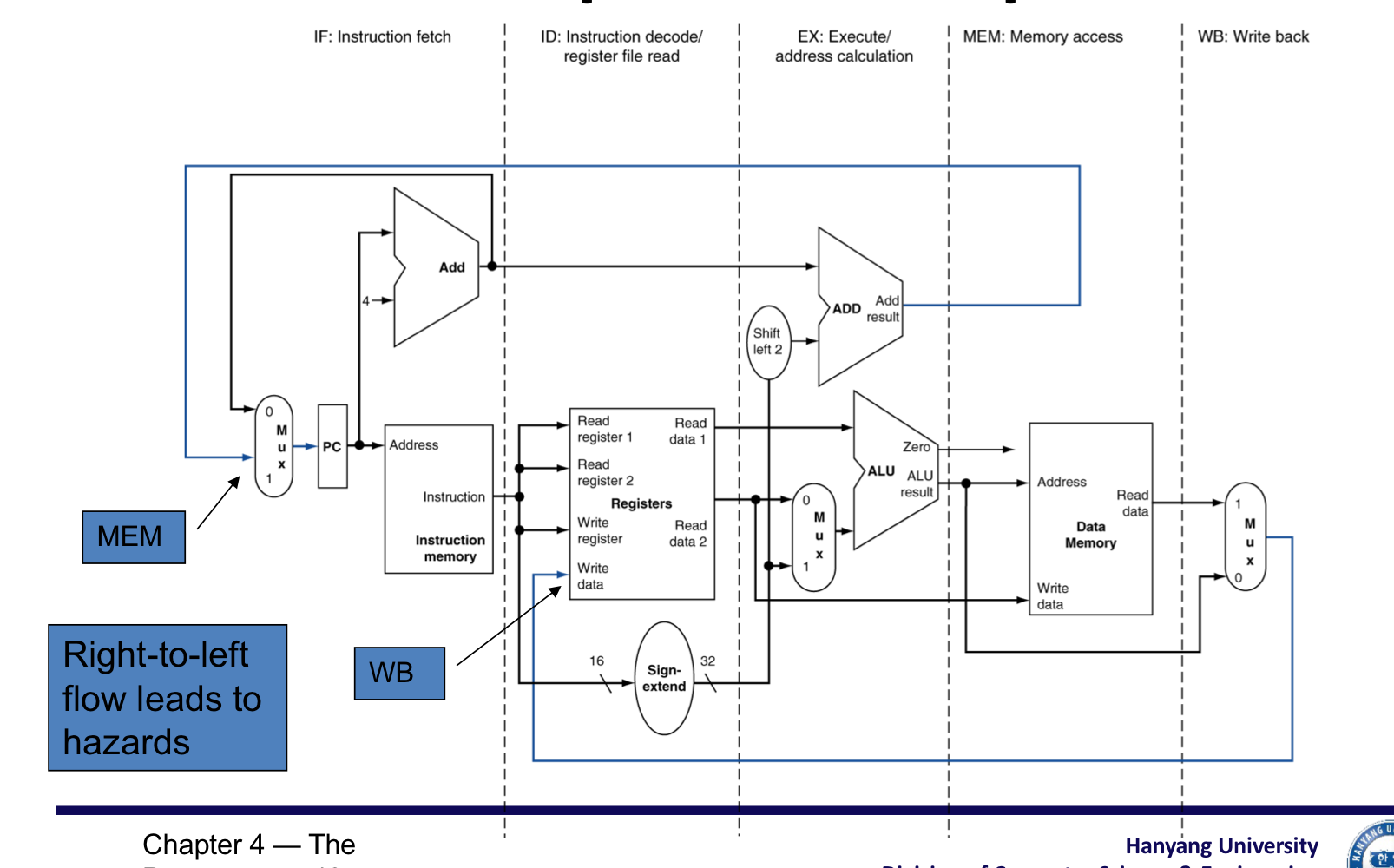
MIPS Pipelined Datapath
4. Pipeline registers
- state 사이에 register가 필요하다.
- sequential element를 추가
- 이전 cycle에서 만들어진 정보를 유지하기 위해서
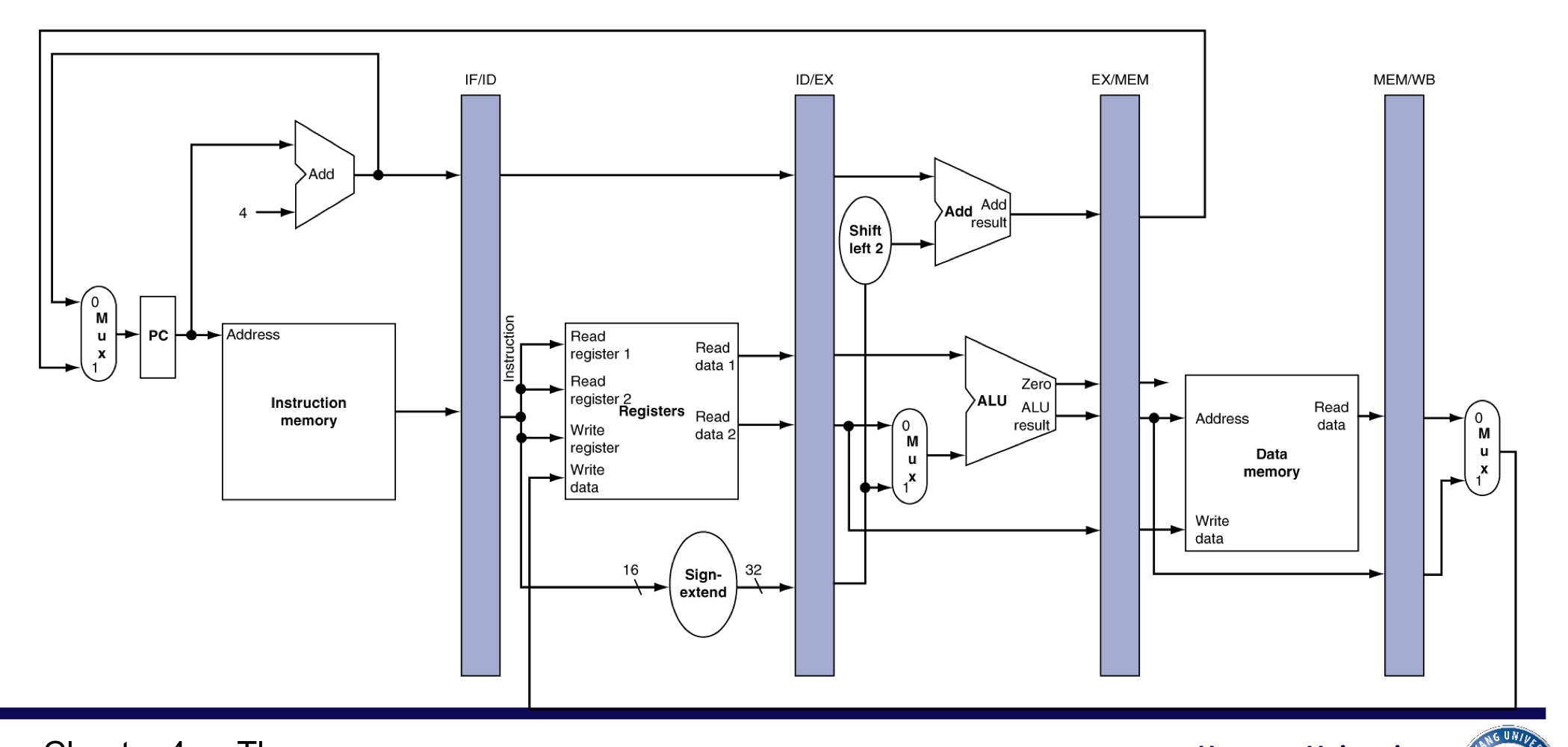
1) Pipeline Operation
- pipeline datapath를 통한 instruction의 cycle-by-cycle flow
- “Single-clock-cycle” pipeline diagram
- single cycle을 사용하는 pipeline을 보여준다.
- 사용되고 있는 하드웨어 자원을 강조 표시
- c.f. “multi-clock-cycle” diagram
- 시간 경과에 따라 operation을 보여주는 그래프
- “Single-clock-cycle” pipeline diagram
a) Load, Store instructions

IF for Load, Store,…
- branch나 jump가 아니기에 그저 PC+4를 수행
- Instruction memory에서 instruction을 fetch
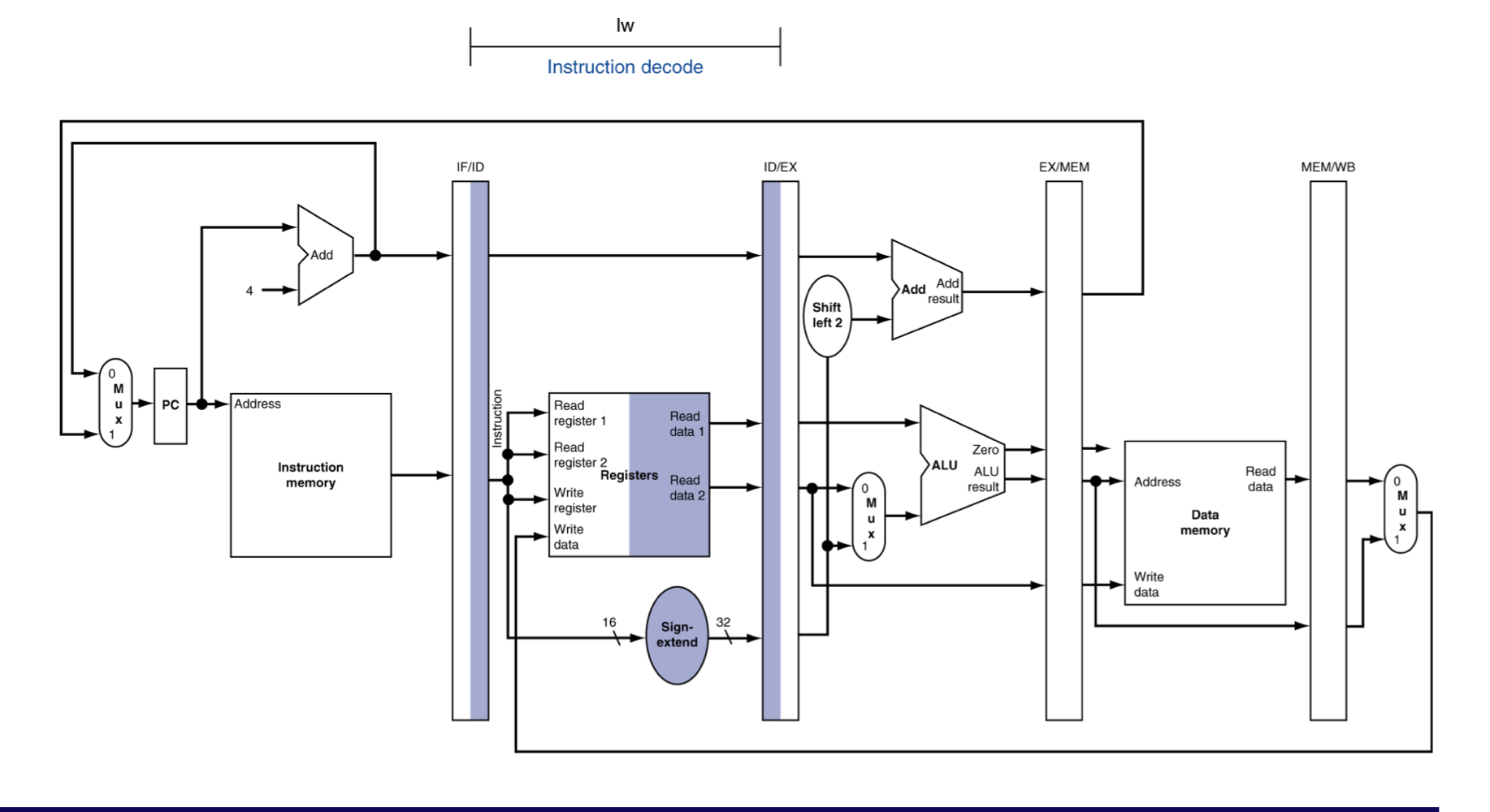
ID for Load, Store, …
- register을 읽고, 대기
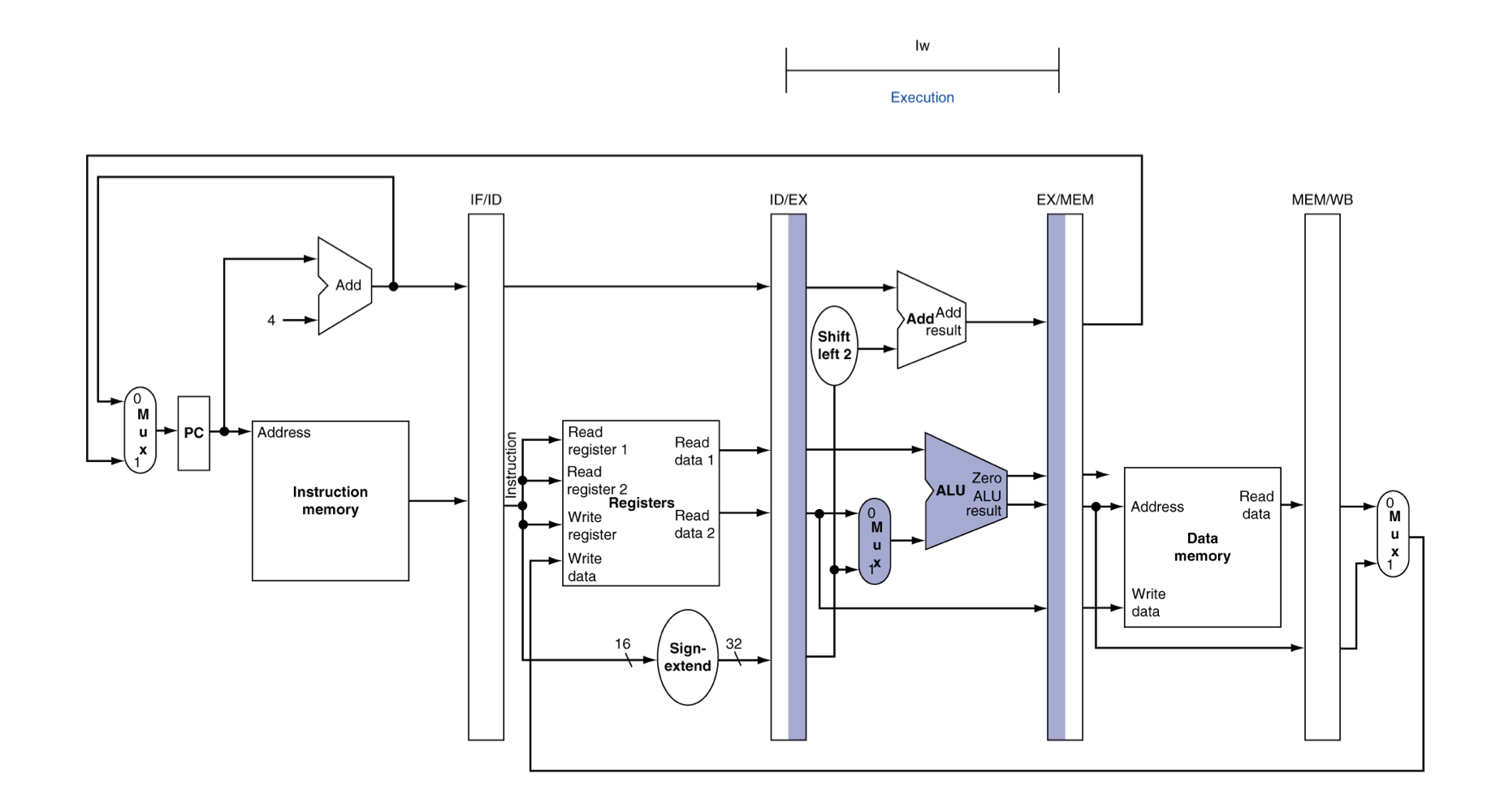
EX for Load
- 주소 계산
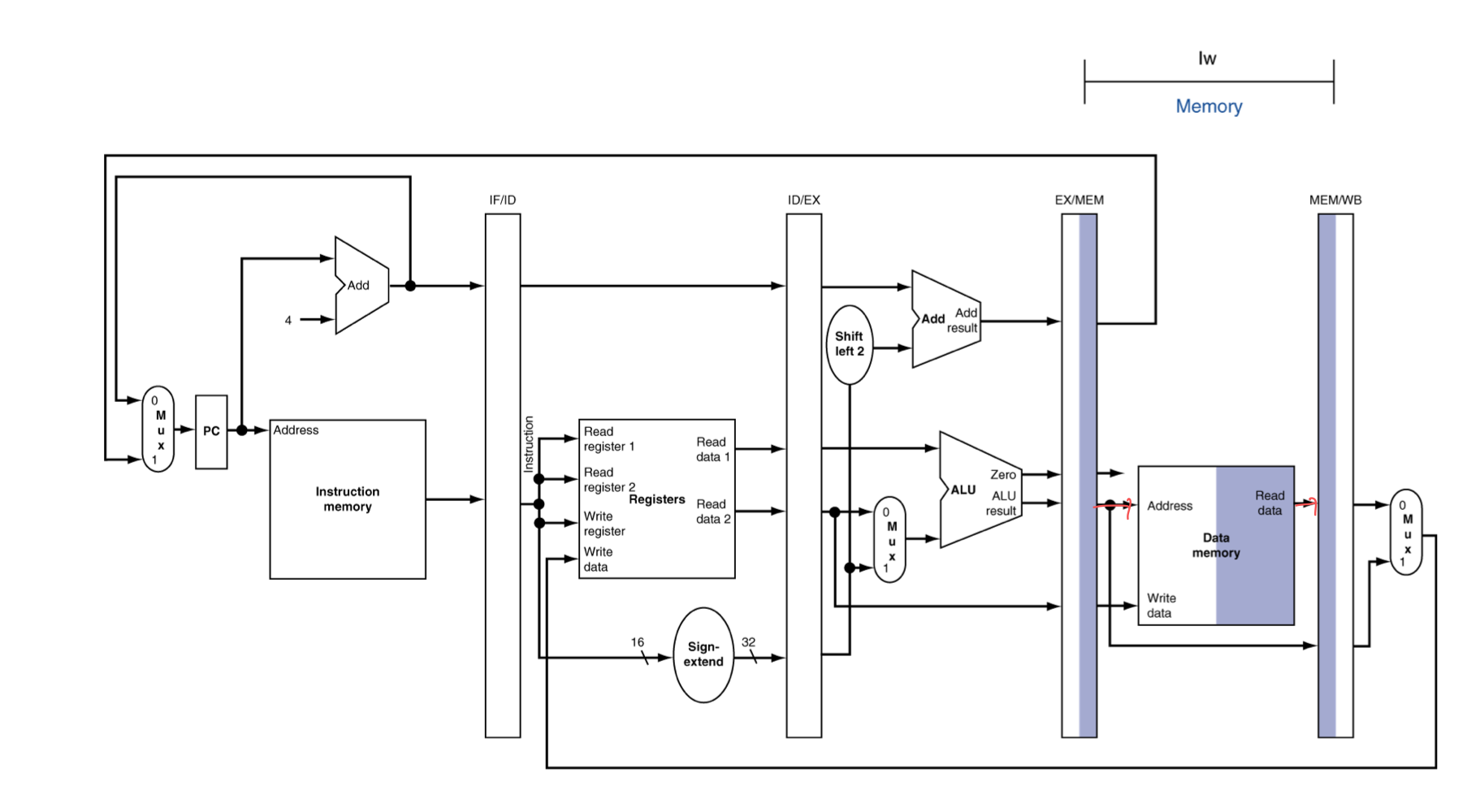
MEM for Load
- 해당 주소에서의 값을 읽고, write back 해준다.
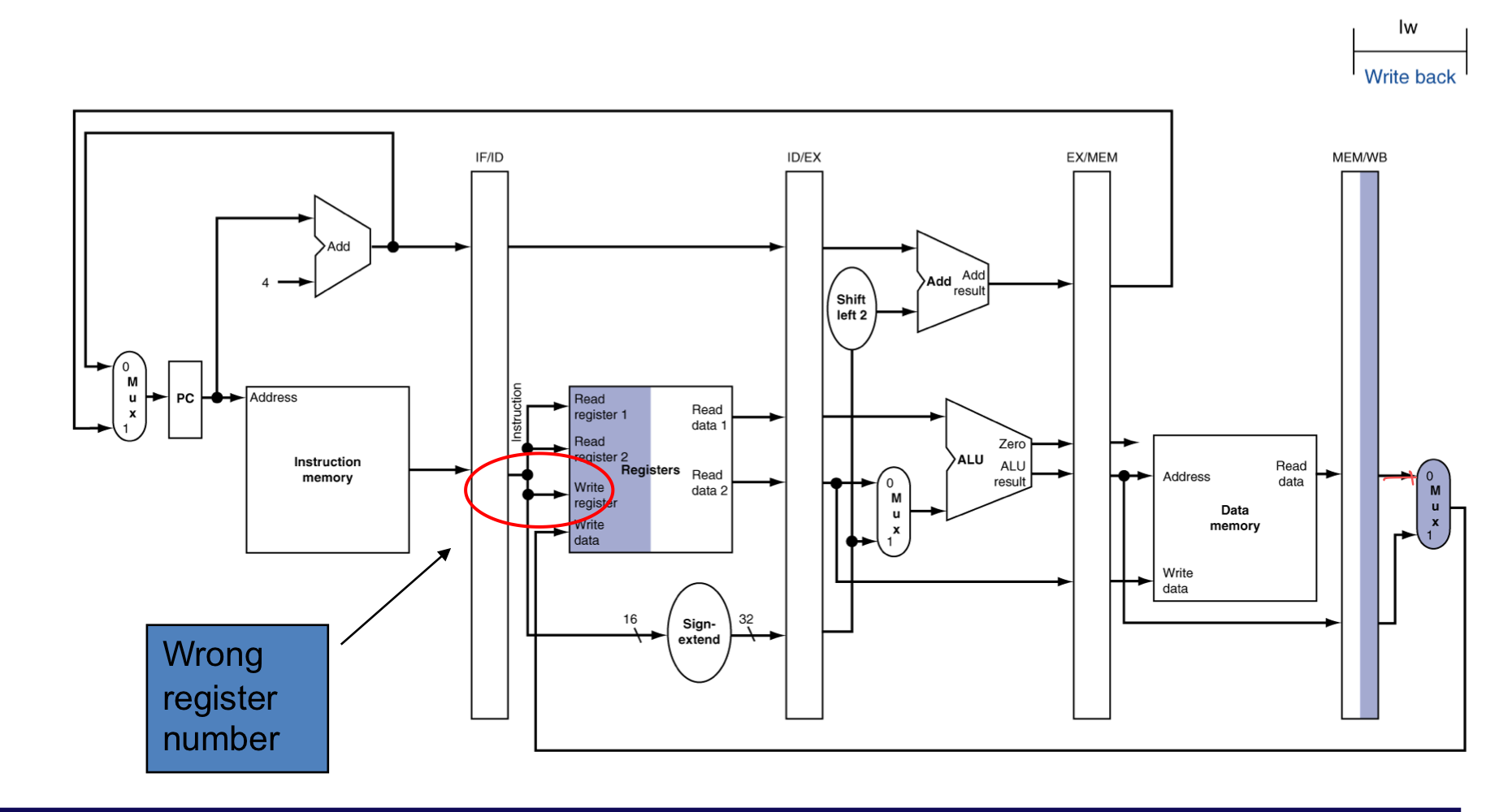
WB for Load
- 현재, write back에서 문제점은 다시 ID stage로 데이터를 보내야한다.
- 하지만, ID는 현재 사용하고 있기에 레지스터에는 이미 다른 명령어를 해석하고 있다.
- 그래서, WB를 위해서 기존의 rt레지스터를 보존해야한다.
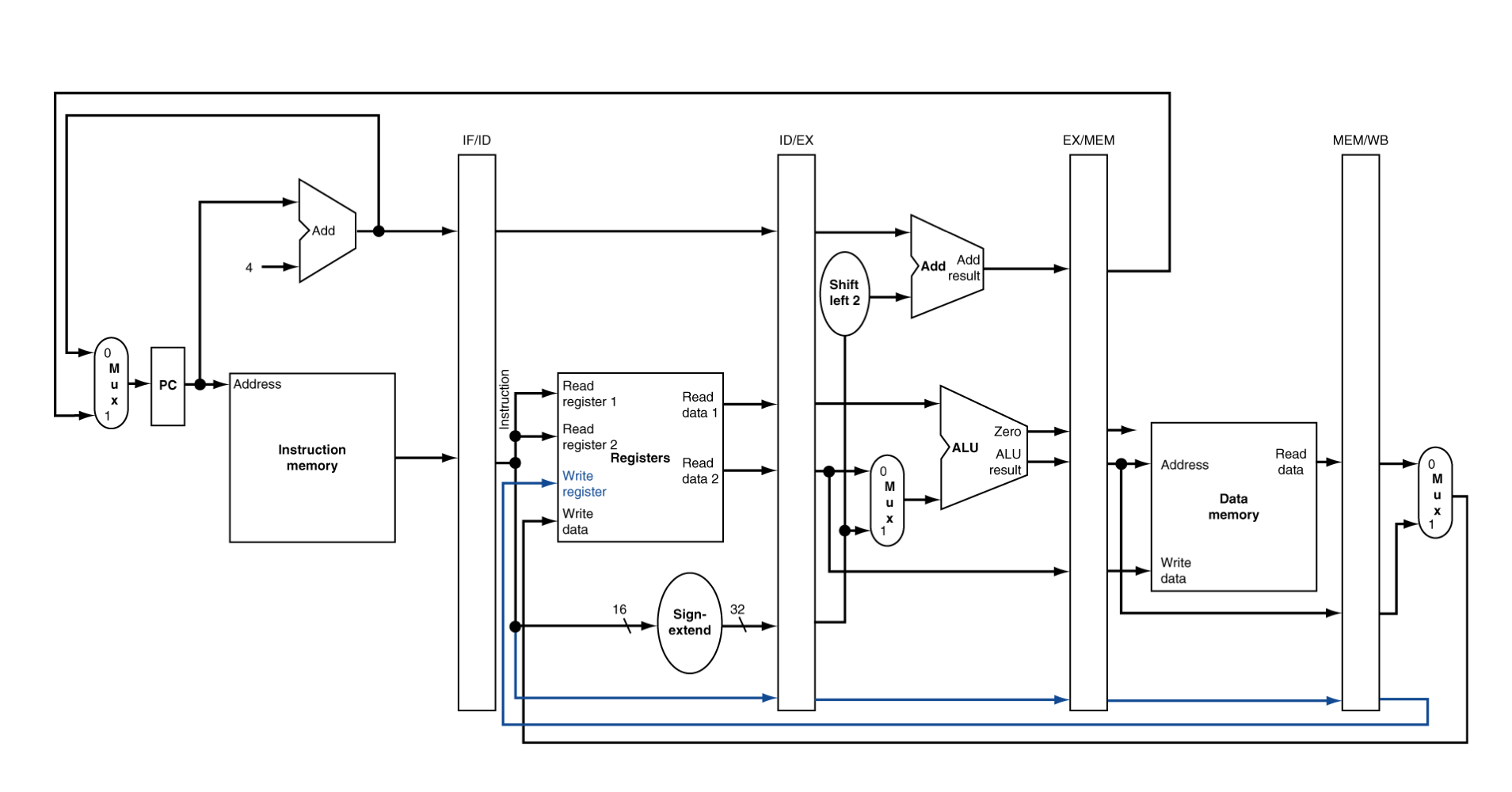
Corrected Datapath for Load
- $rt의 보존을 위해, ID영역에서 읽은 register 번호를 pipeline register에 넘겨준다.
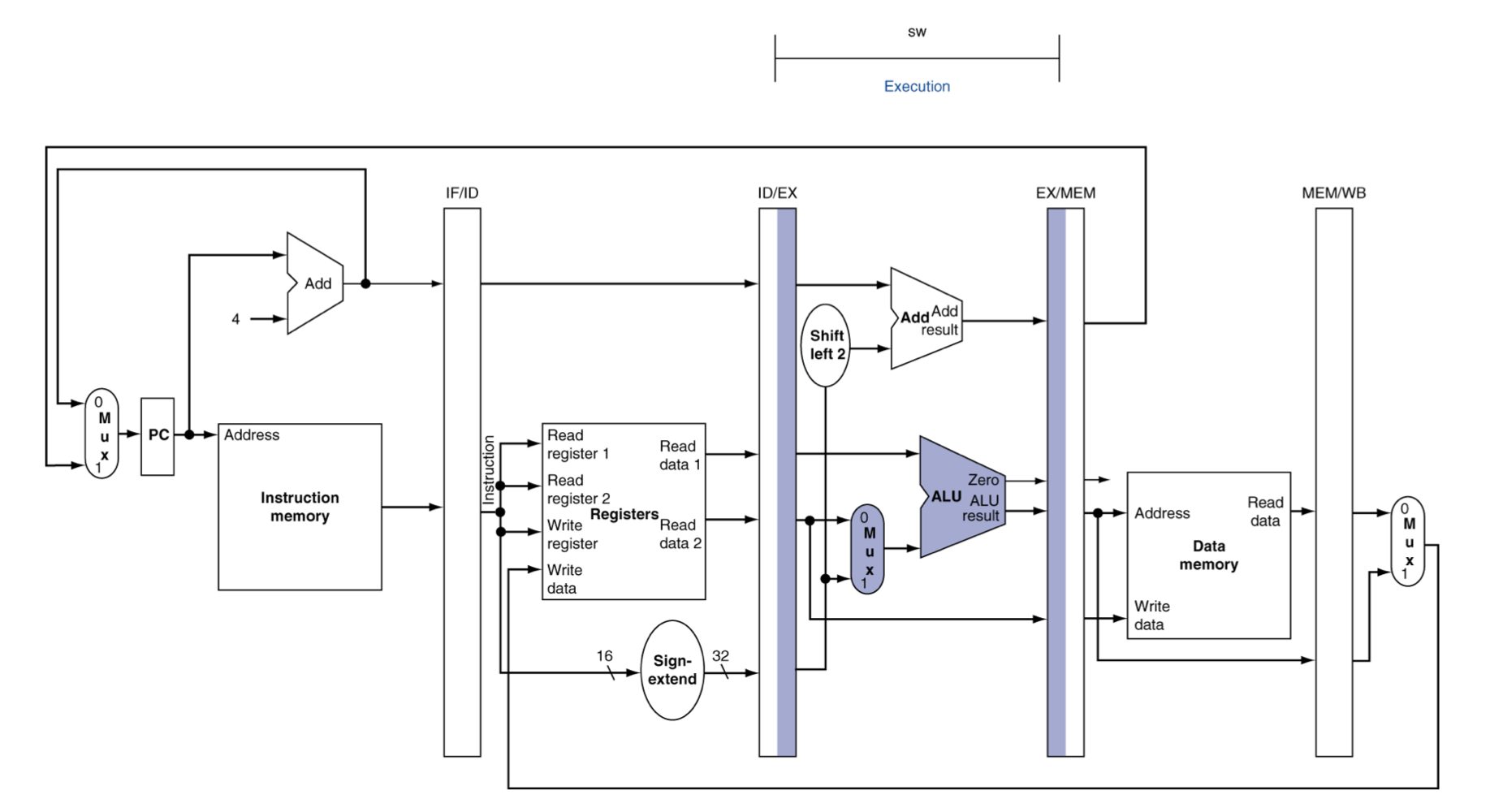
EX for Store
- Load와 다른 점은 Write data도 넘겨준다.
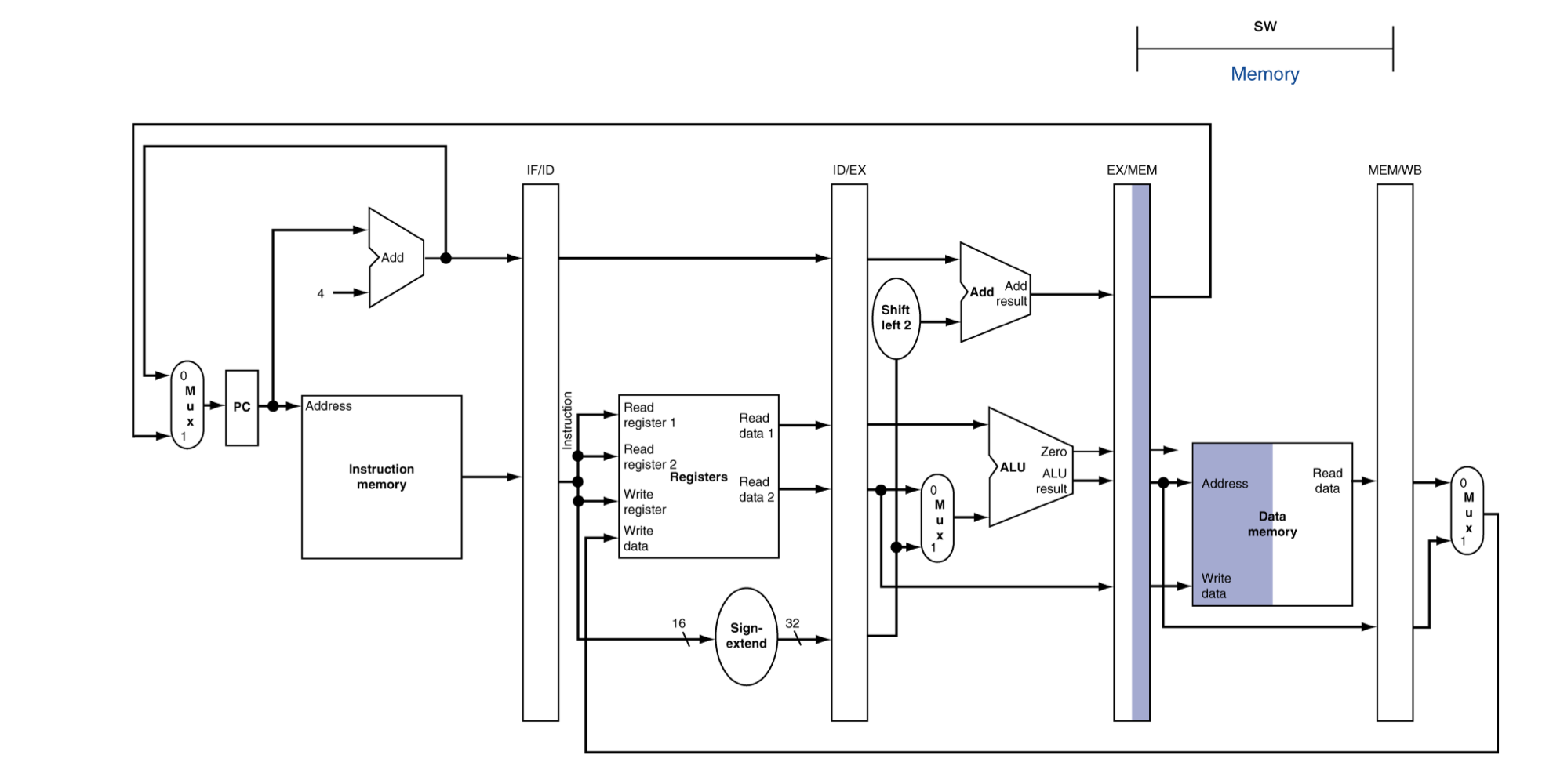
MEM for Store
- Load와 다른 점은 Data memory에 쓰기 작업을 수행하는 것이다.
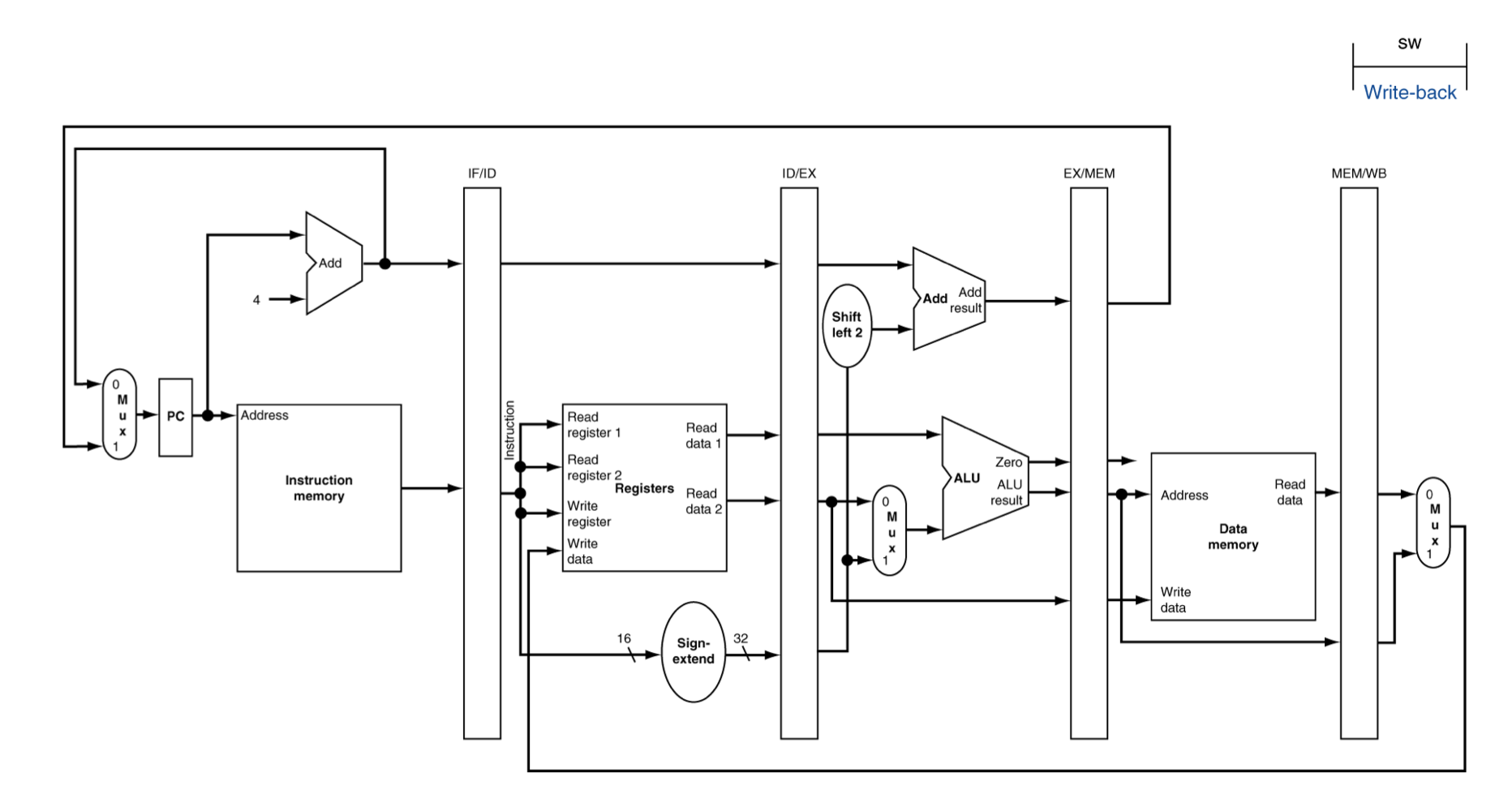
WB for Store
- Store 명령에서는 WB를 사용하지 않는다.
b) Multi-cycle pipeline diagram
- 시간과 명령어에 따른 resource의 사용을 보여준다.

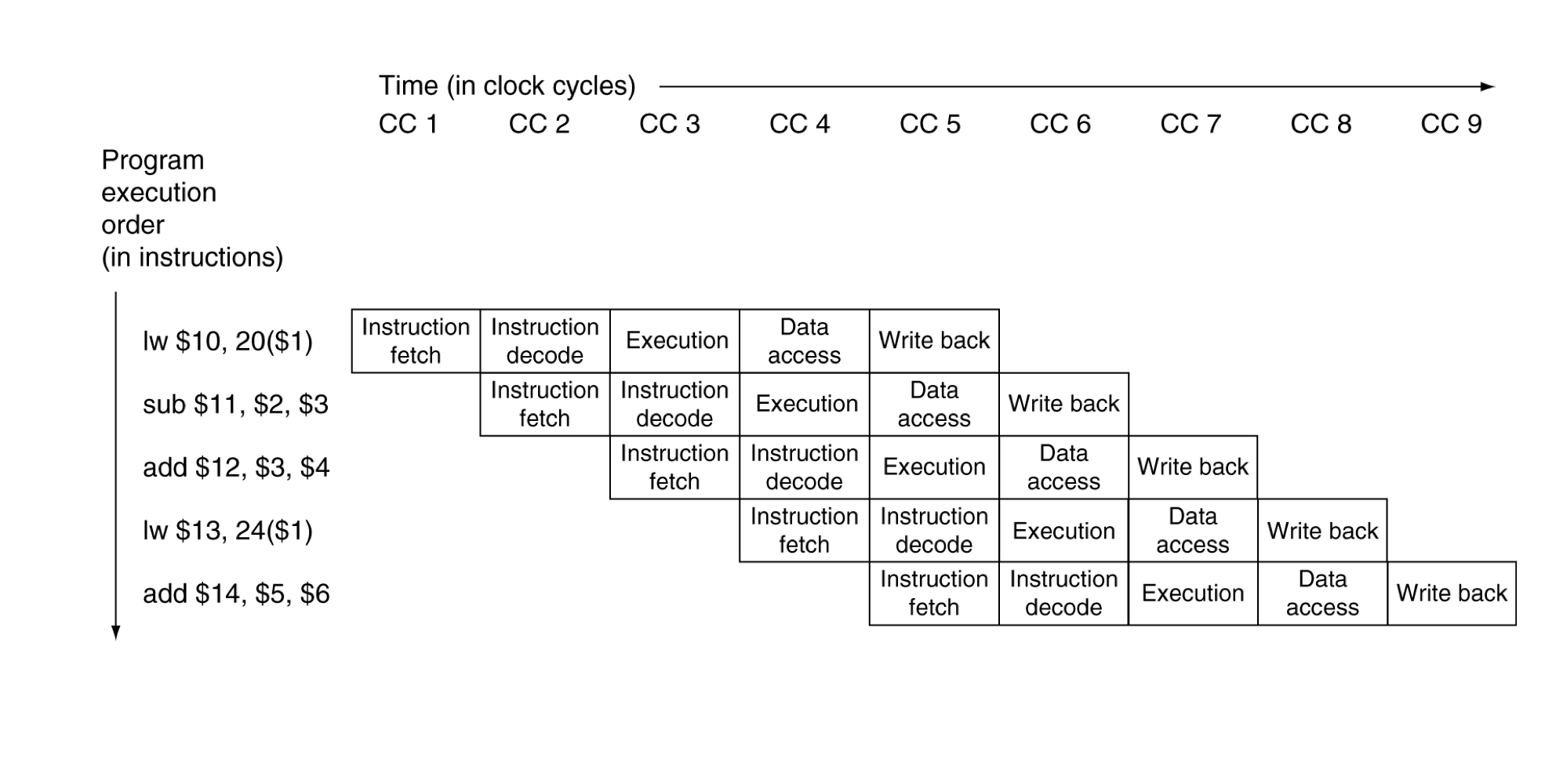
일반적인 형태
c) Single-cycle pipeline diagram
- 주어진 cycle에서 pipeline의 상태
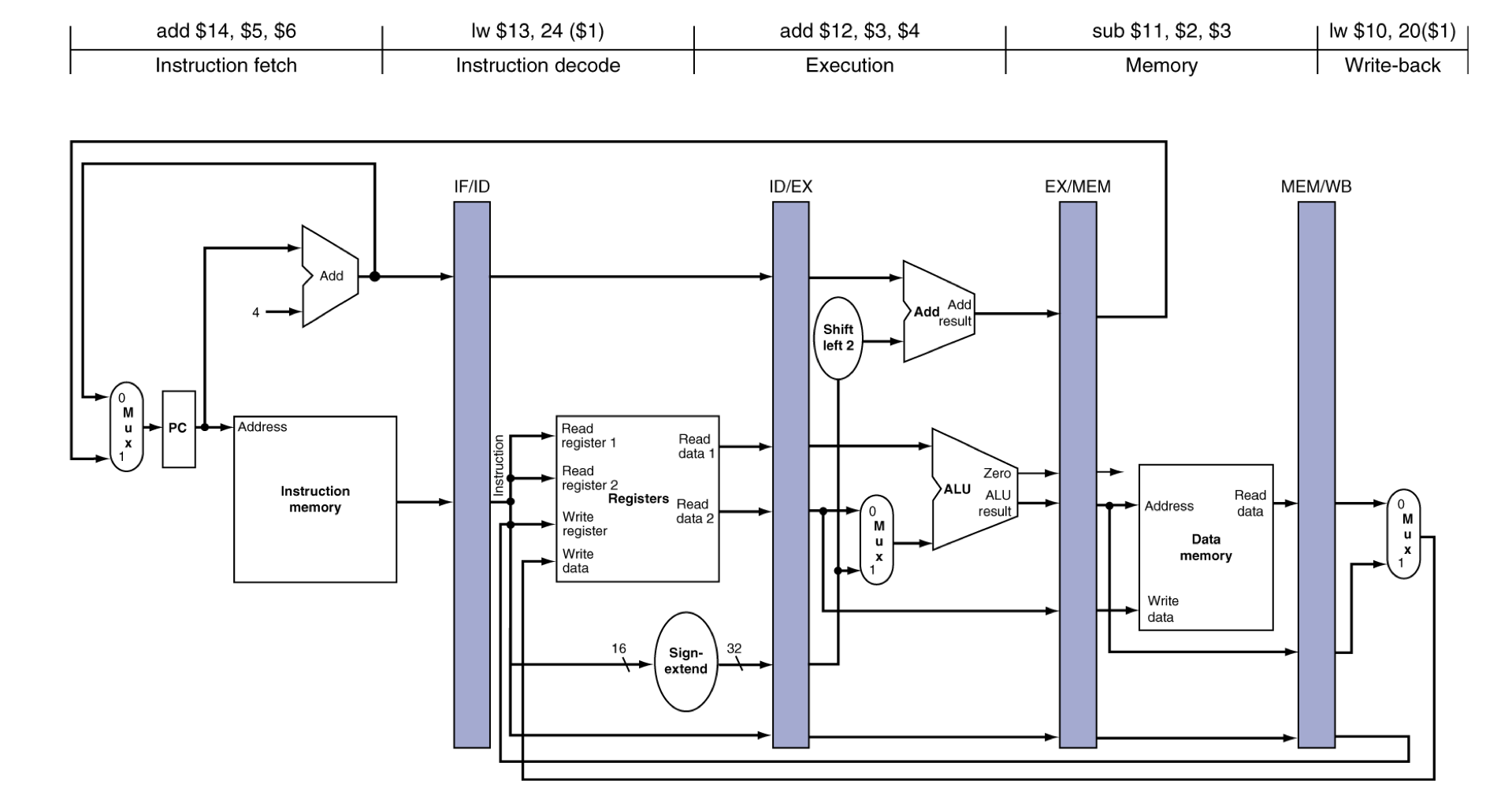
4) Pipelined Control (Simplified)
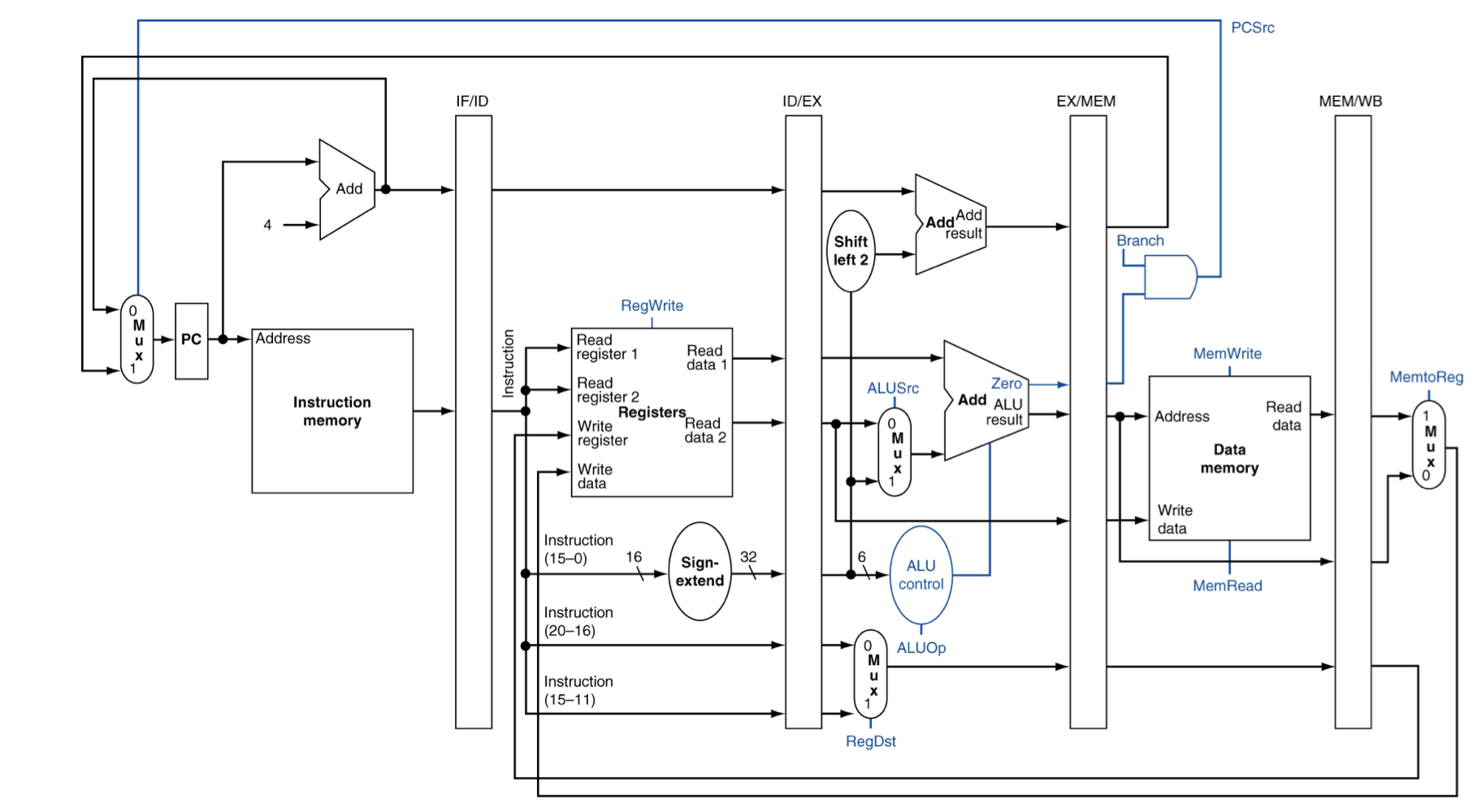
5) Pipelined Control
- Control signal들은 instruction으로 부터 파생된다
- As in single-cycle implementation
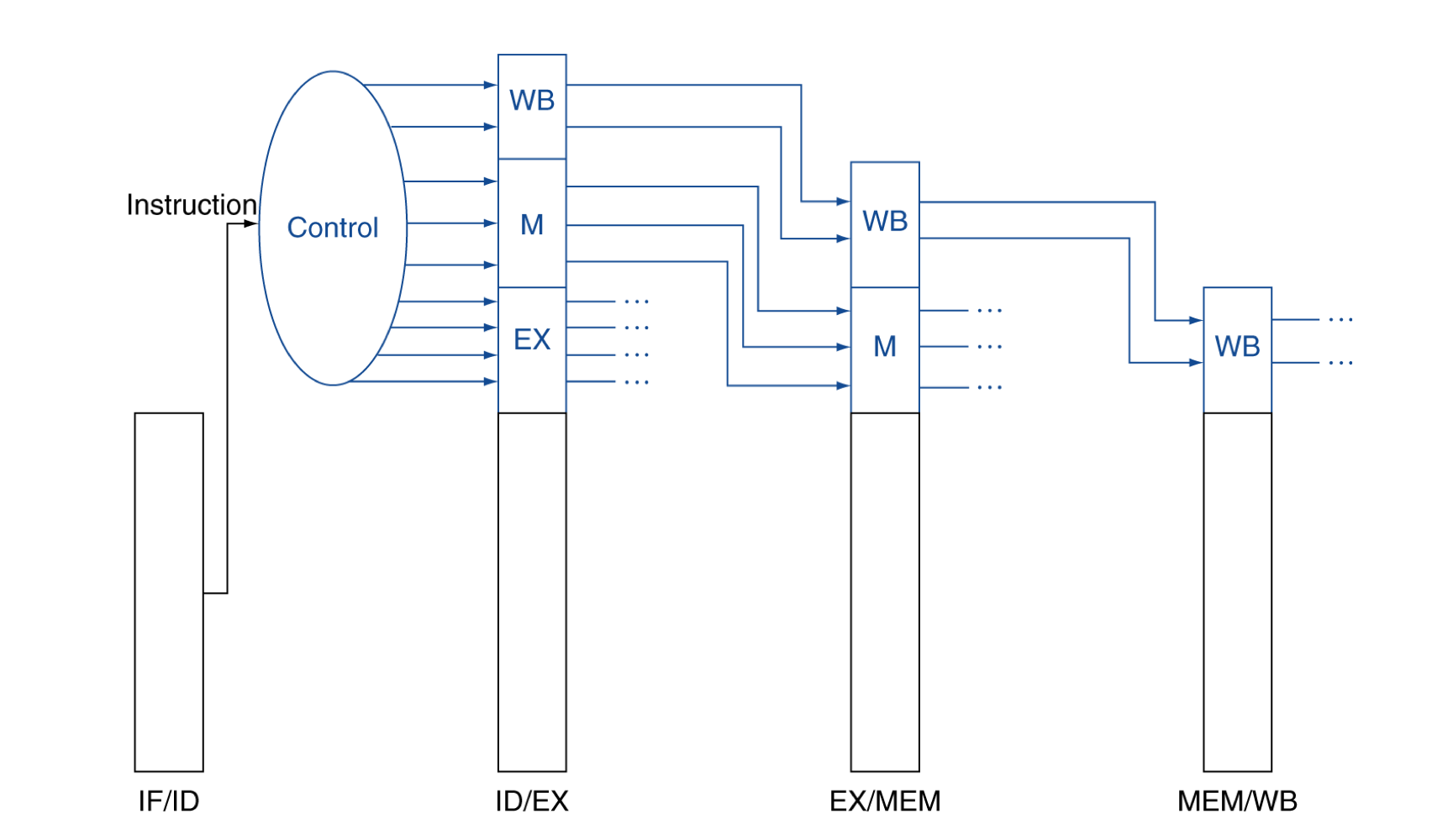
- EX단계에서 사용되는 signal → ALUOP0, ALUOP1, ALUSrc, RegDst
- MEM단계에서 사용되는 signal → Branch, MemWrite, MemRead
- WB단계에서 사용되는 signal → MemtoReg, RegWrite
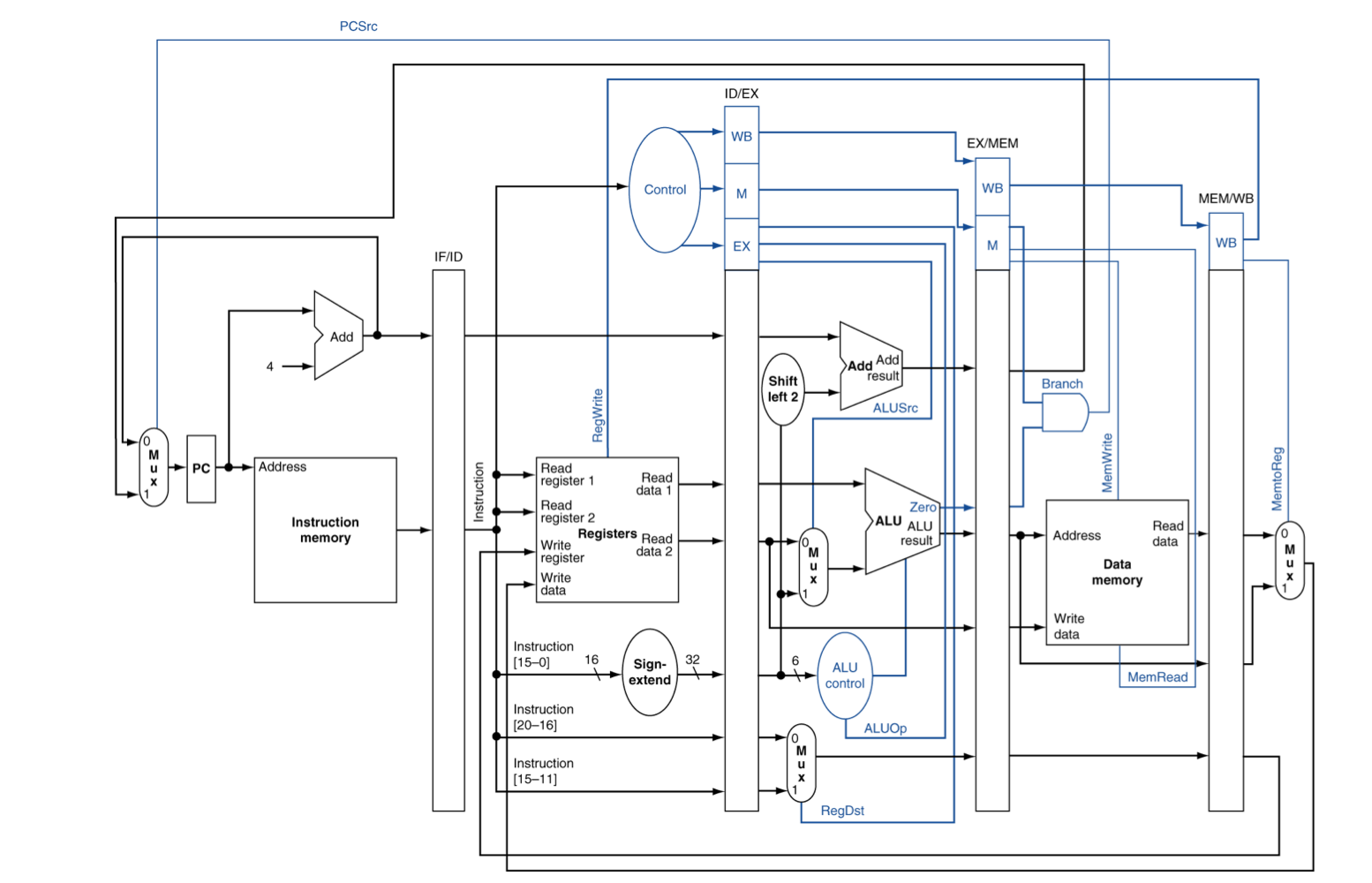
Pipelined Control
2) Data Hazards in ALU Instructions
- 이전의 결과를 바로 사용해야 하는데, 아직 연산이 진행 중이기 때문에 바로 사용하지 못하는 Hazard
sub $2, $1, $3
and $12, $2, $5
or $13, $6, $2
add $14, $2, $2
sw $15, 100($2)- 우리는 forwarding을 사용하여 hazard를 해결 할 수 있다.
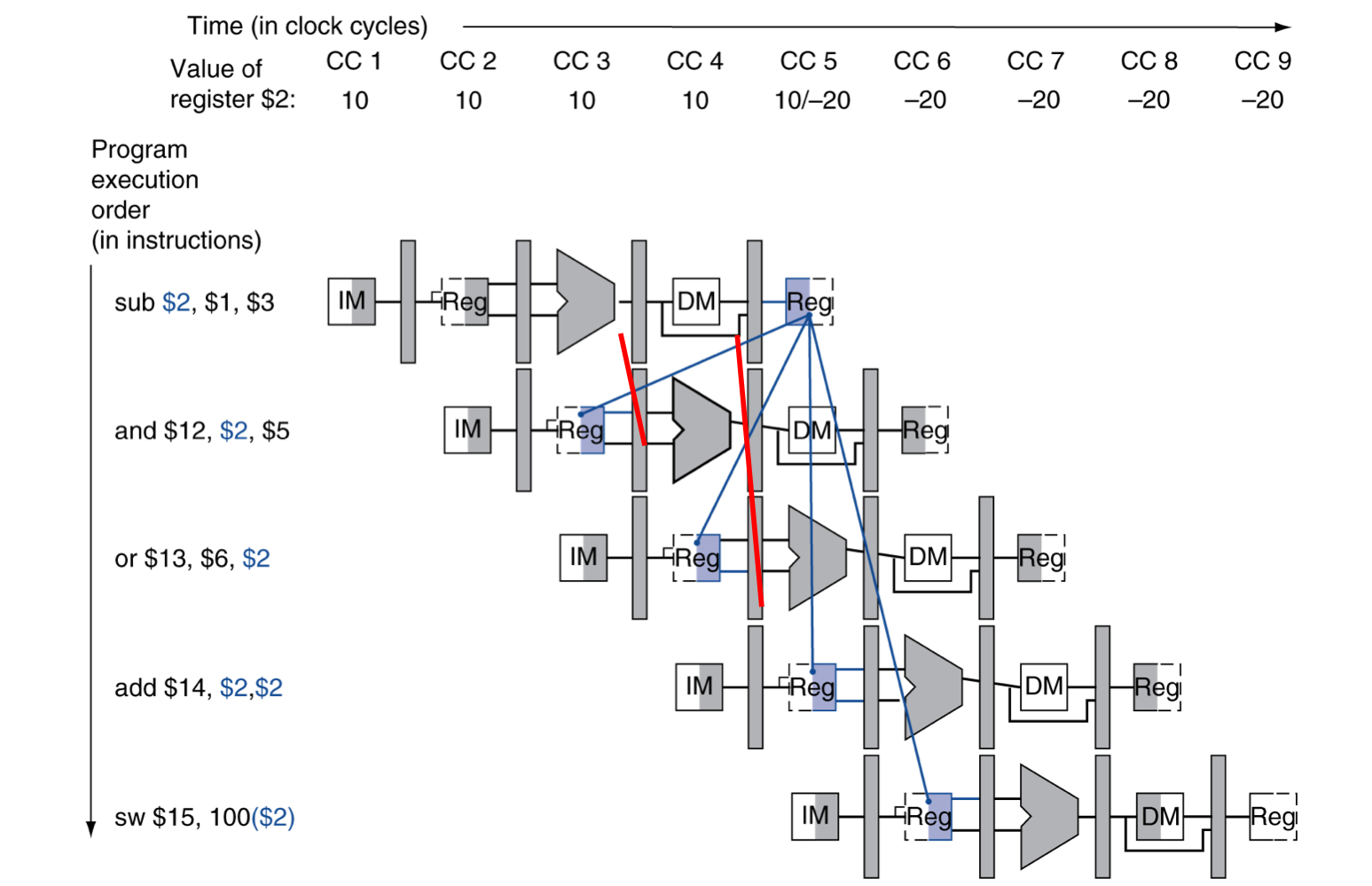
Dependencies & Forwarding
- ALU에서 나온 연산 값을 바로 넘겨준다. (1 cycle만에 사용해야 할 때)
- MEM단계에서 가지고 있는 값을 바로 넘겨준다. (2 cycle만에 사용해야 할 때)
- add, sw 연산은 data hazard가 발생하지 않는다.
a) Detecting the Need to Forward
- pipeline을 통해서 Register number들을 넘겨준다.
- e.g., ID/EX.RegisterRs = register number for Rs sitting in ID/EX pipeline register
- EX stage에서 ALU operand register number는 다음과 같다.
- ID/EX.RegisterRs, ID/EX.RegisterRt
- Data hazard가 발생하는 경우
- EX/MEM.RegisterRd = ID/EX.RegisterRs
- EX/MEM.RegisterRd = ID/EX.RegisterRt
- MEM/WB.RegisterRd = ID/EX.RegisterRs
- MEM/WB.RegisterRd = ID/EX.RegisterRt
- 1,2 는 EX의 피연산자들이 이전 cycle의 MEM Rd와 같을 때,
- 즉, 1cycle 전의 instruction에서, EX 직후 계산된 Rd를 끌어옴
- 3,4는 EX의 피연산자들이 WB의 Rd와 같을 때,
- 즉, 2cycle 전의 instruction에서, WB에 사용 될 Rd를 끌어온다.
- 하지만 Rd 레지스터가 업데이트 되지 않는 경우도 있다.
- EX/MEM.RegWrite, MEM/WB.RegWrite
- 그리고, Rd가 $zero이면 업데이트 될 수 없으니까 해당 경우도 제외한다.
- EX/MEM.RegisterRd ≠ 0, MEM/WB.RegisterRd ≠ 0
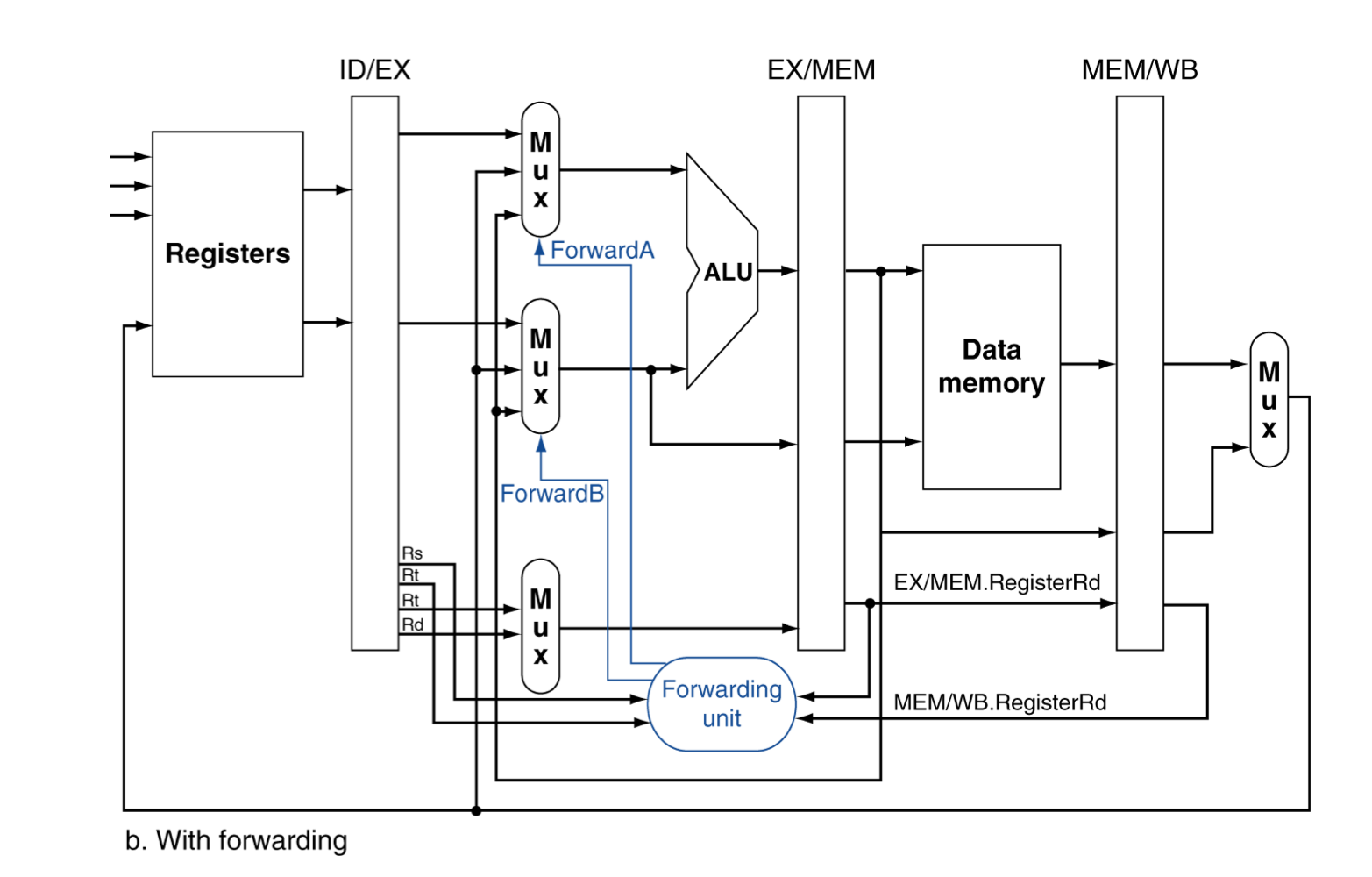
Forwarding Paths
b) Forwarding Conditions
- EX hazard
- if (EX/MEM.RegWrite and (EX/MEM.RegisterRd ≠ 0) and (EX/MEM.RegisterRd = ID/EX.RegisterRs))
- ForwardA = 10
- if (EX/MEM.RegWrite and (EX/MEM.RegisterRd ≠ 0) and (EX/MEM.RegisterRd = ID/EX.RegisterRt))
- ForwardB = 10
- if (EX/MEM.RegWrite and (EX/MEM.RegisterRd ≠ 0) and (EX/MEM.RegisterRd = ID/EX.RegisterRs))
- MEM hazard
- if (MEM/WB.RegWrite and (MEM/WB.RegisterRd ≠ 0) and (MEM/WB.RegisterRd = ID/EX.RegisterRs))
- ForwardA = 01
- if (MEM/WB.RegWrite and (MEM/WB.RegisterRd ≠ 0) and (MEM/WB.RegisterRd = ID/EX.RegisterRt))
- ForwardB = 01
- if (MEM/WB.RegWrite and (MEM/WB.RegisterRd ≠ 0) and (MEM/WB.RegisterRd = ID/EX.RegisterRs))
- 00이라면 no hazard
c) Double Data Harzard
- Consider the sequence:
add $1, $1, $2
add $1, $1, $3
add $1, $1, $4- 양 쪽 모두 hazard가 발생한다면,
- 조금 더 최근에 것을 사용하고 싶다.
- 즉, double일 경우에는 MEM hazard의 조건이 변경된다.
- EX hazard가 아닐 경우에만 MEM hazard forwarding
- 즉, double이라면 항상 EX hazard로 인식한다.
d) Revised Forwarding Condition
- EX hazard (그대로)
- if (EX/MEM.RegWrite and (EX/MEM.RegisterRd ≠ 0) and (EX/MEM.RegisterRd = ID/EX.RegisterRs))
- ForwardA = 10
- if (EX/MEM.RegWrite and (EX/MEM.RegisterRd ≠ 0) and (EX/MEM.RegisterRd = ID/EX.RegisterRt))
- ForwardB = 10
- if (EX/MEM.RegWrite and (EX/MEM.RegisterRd ≠ 0) and (EX/MEM.RegisterRd = ID/EX.RegisterRs))
- MEM hazard
- if (MEM/WB.RegWrite and (MEM/WB.RegisterRd ≠ 0) and not (EX/MEM.RegWrite and (EX/MEM.RegisterRd ≠ 0) and (EX/MEM.RegisterRd = ID/EX.RegisterRs)) and (MEM/WB.RegisterRd = ID/EX.RegisterRs))
- ForwardA = 01
- if (MEM/WB.RegWrite and (MEM/WB.RegisterRd ≠ 0) and not (EX/MEM.RegWrite and (EX/MEM.RegisterRd ≠ 0) and (EX/MEM.RegisterRd = ID/EX.RegisterRt)) and (MEM/WB.RegisterRd = ID/EX.RegisterRt))
- ForwardB = 01
- if (MEM/WB.RegWrite and (MEM/WB.RegisterRd ≠ 0) and not (EX/MEM.RegWrite and (EX/MEM.RegisterRd ≠ 0) and (EX/MEM.RegisterRd = ID/EX.RegisterRs)) and (MEM/WB.RegisterRd = ID/EX.RegisterRs))
- 00이라면 no hazard
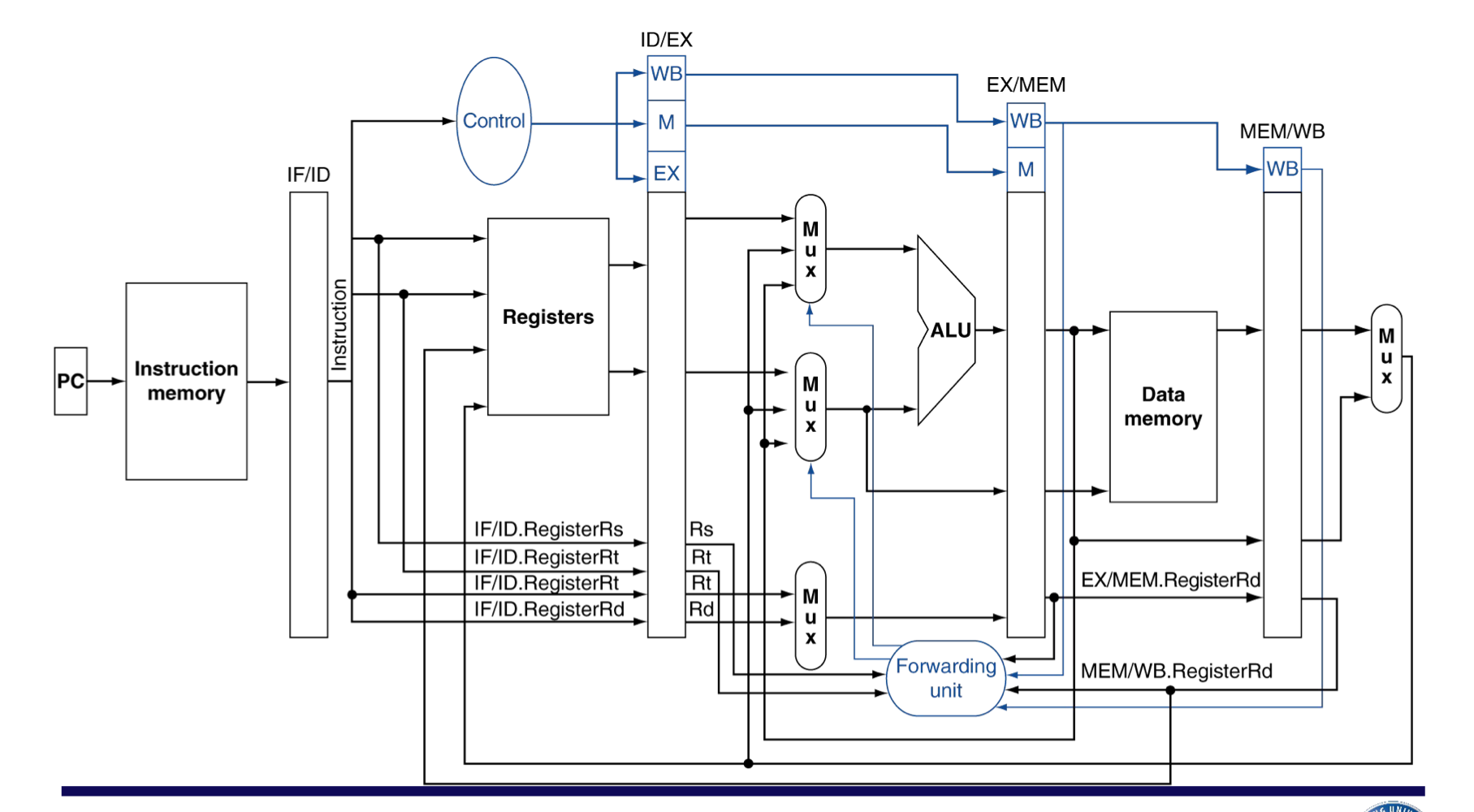
Datapath with Forwarding
3) Load-Use Data Hazard
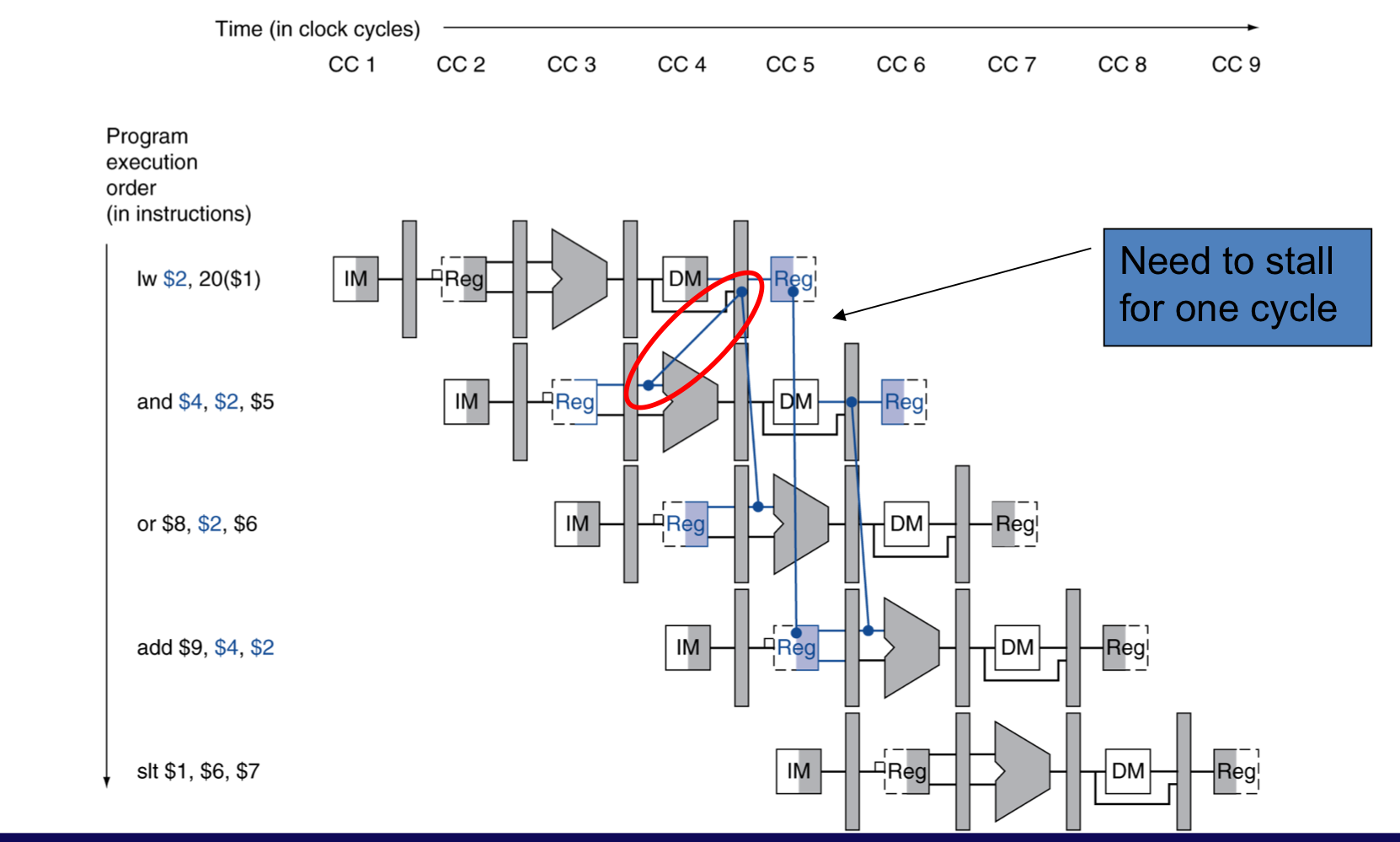
- 시간을 역행을 할 순 없다.
a) Load-Use Hazard Detection
- 현재 cycle의 ID stage에서 instrcution에 필요한 부분이 아직 준비되지 않았는지 검사한다.
- ID stage에서 ALU 피연산자의 register 번호
- IF/ID.RegisterRs, IF/ID.RegisterRt
- Load-use hazard when
- ID/EX.MemRead and ((ID/EX.RegisterRt = IF/ID.RegisterRs) of (ID/EX.RegisterRt = IF/ID.RegisterRt))
- 만약, 감지 된다면 stall이 발생 할 것이고, 해당 부분에 bubble을 삽입
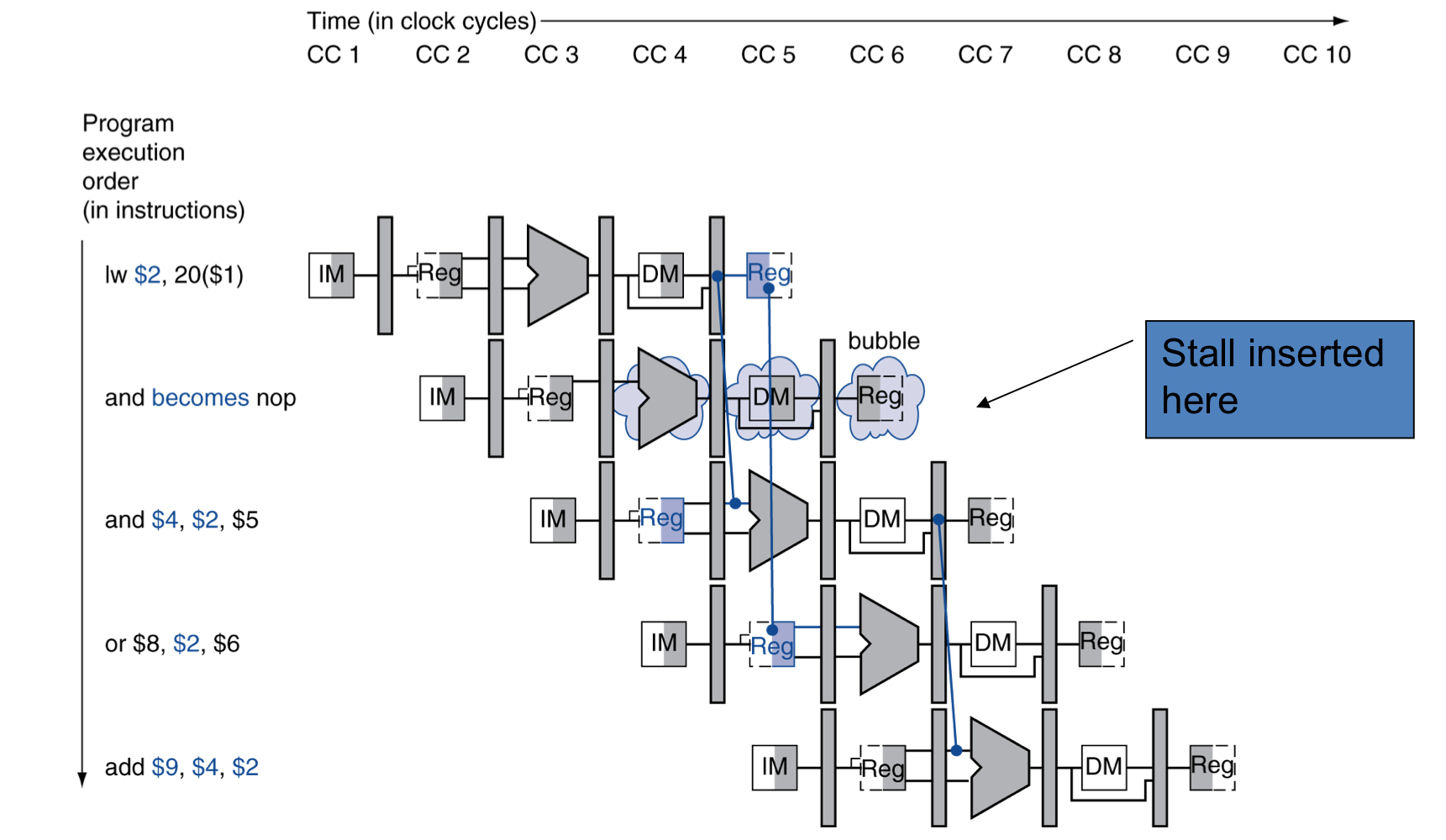
b) How to Stall the Pipeline
- 강제로 ID/EX register의 값들을 모두 0으로 만든다.
- EX, MEM, WB는 nop (no-operation)
- PC와 IF/ID register의 업데이트를 방지한다.
- 현재 명령어가 ID stage에서 다시 decode되도록 한다.
- 직후 명령어(PC+4)가 IF stage에서 다시 fetch되도록 한다.
- 1-cycle의 stall은 lw가 충분히 데이터를 MEM에서 읽을 수 있도록 한다.
- 이제 현재 명령어가 EX stage로 진행
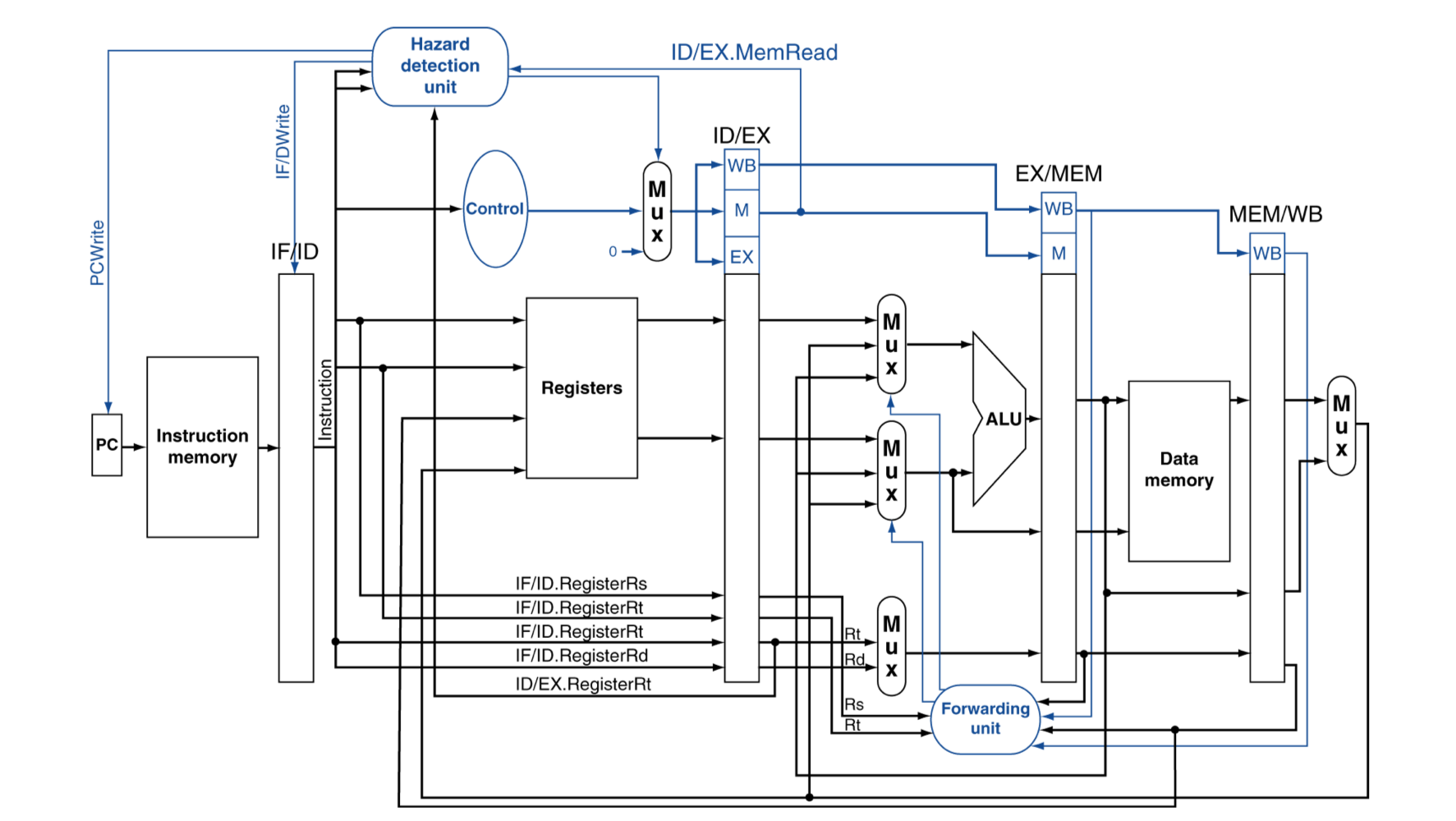
Datapath with Hazard Detection
- Hazard detection unit에 ID/EX.MemRead 신호가 전달 된다. (1-cycle 전)
- 그리고, ID/EX register에 Rt가, (1-cycle 전)
- IF/ID register의 Rs,Rt가 전달됨. (현재)
- 이를 토대로 Load-Use Data hazard를 감지하면,
- ID/EX register의 제어신호를 모두 0으로 초기화 (bubble 생성)
- PC에는 PCWrite 제어신호를 0으로 하여 PC가 업데이트 되는 것을 방지
- IF/IDWrite 제어신호를 보내서 현재 명령어가 다시 decode되게 함
c) Stalls and Performance
- Stall은 performance를 저하시킨다.
- 하지만 정확한 결과를 얻기 위해서는 꼭 필요하다.
- 컴파일러는 code를 재배치해서 hazard를 피하고 stall를 방지할 수 있다.
- 이를 위해 컴파일러는 해당 프로세서의 Pipeline의 구조를 정확히 이해해야한다.
4. Branch Hazards (Control Hazards)
- 만약 branch의 결과가 MEM에서 결정된다면?
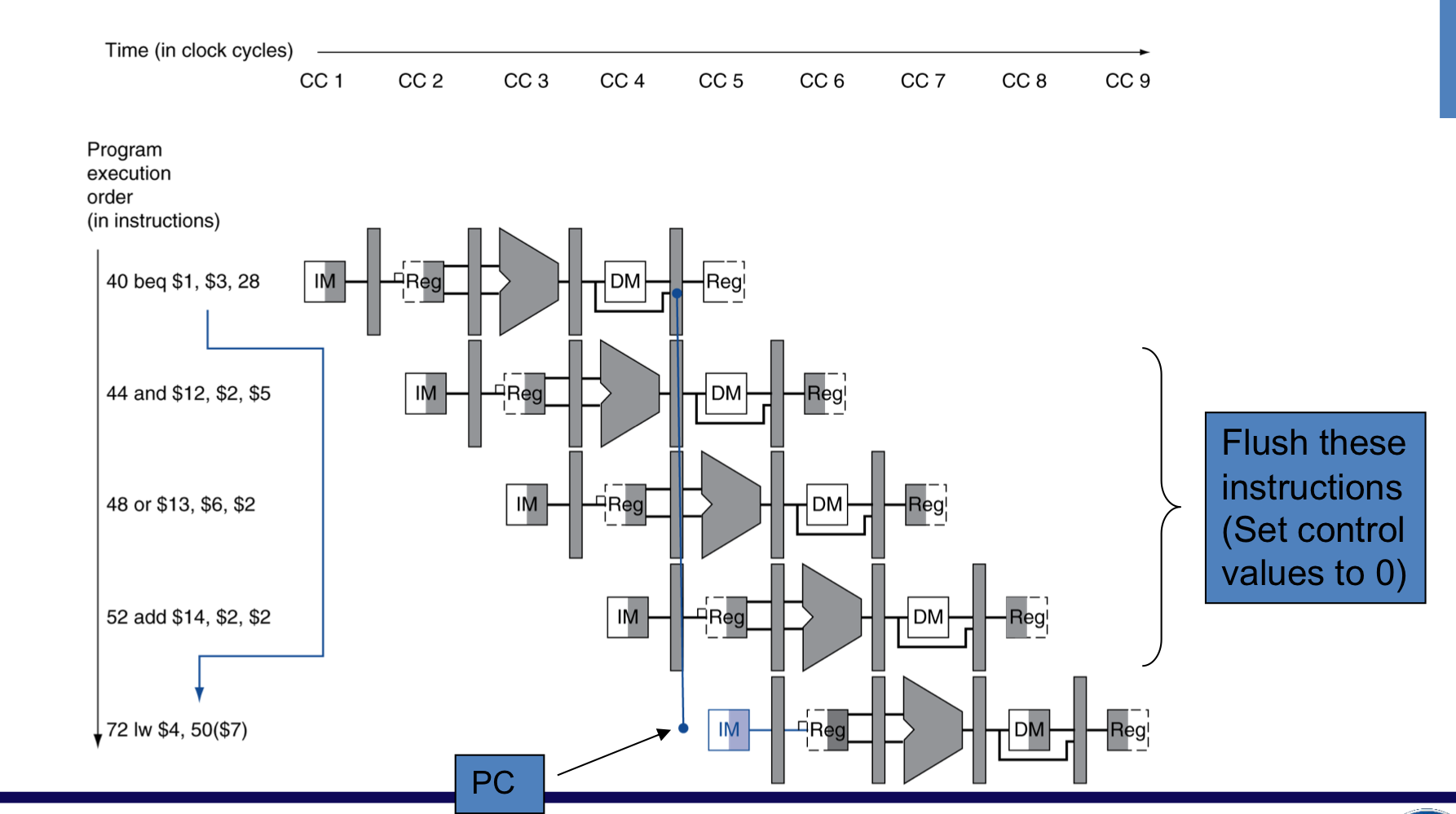
- branch 결과가 항상 거짓임을 가정하여, 해당 가정이 틀렸으면 flush를 해야한다.
a) Reducing Branch Delay
- 예측에 실패하더라도 버려지는 instruction을 줄여보자.
- branch 결과를 구하는 것을 ID stage에서 할 수 있도록 하드웨어를 옮긴다.
- target address adder (대상 주소를 구하던 adder를 땡겨온다.)
- register comparator (ALU로 비교해서 zero인지 했던 것)

branch의 주소는 44 or 72
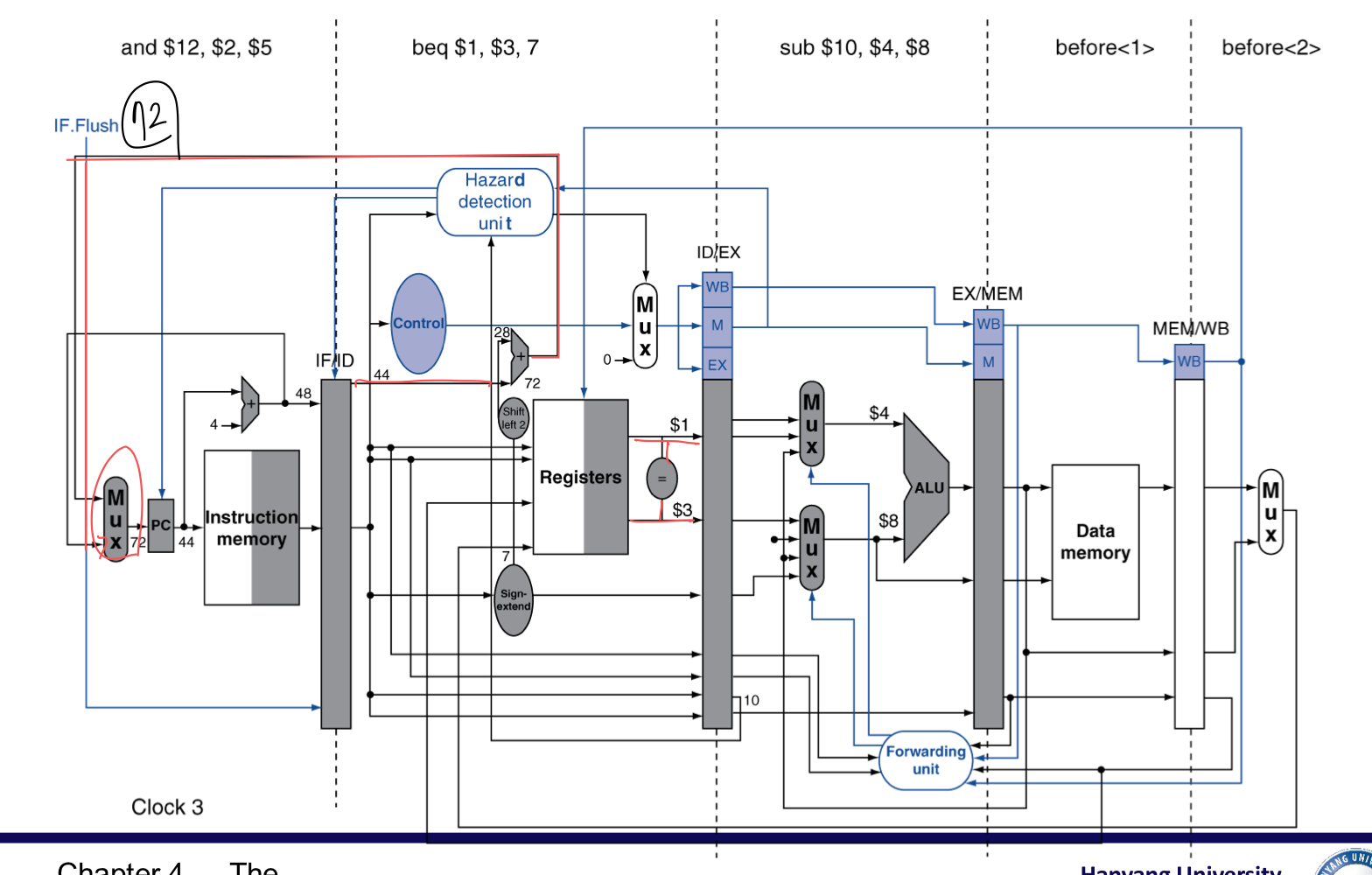
ID 단계에서 주소 계산과 값 비교가 가능하도록 옮김
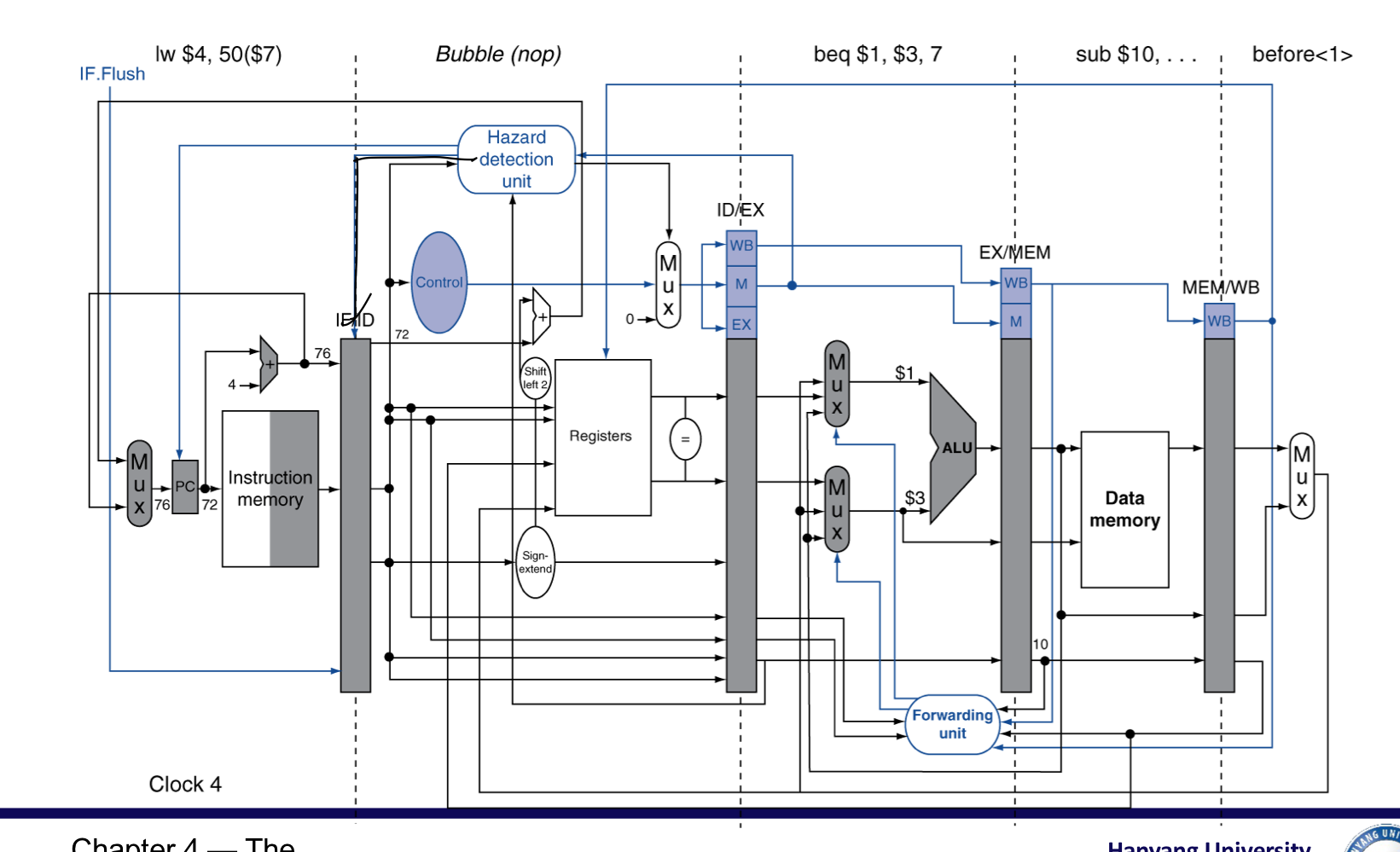
예측이 틀렸다면 Bubble 하나 삽입 (and)
- 한개의 bubble로 처리 할 수 있음.
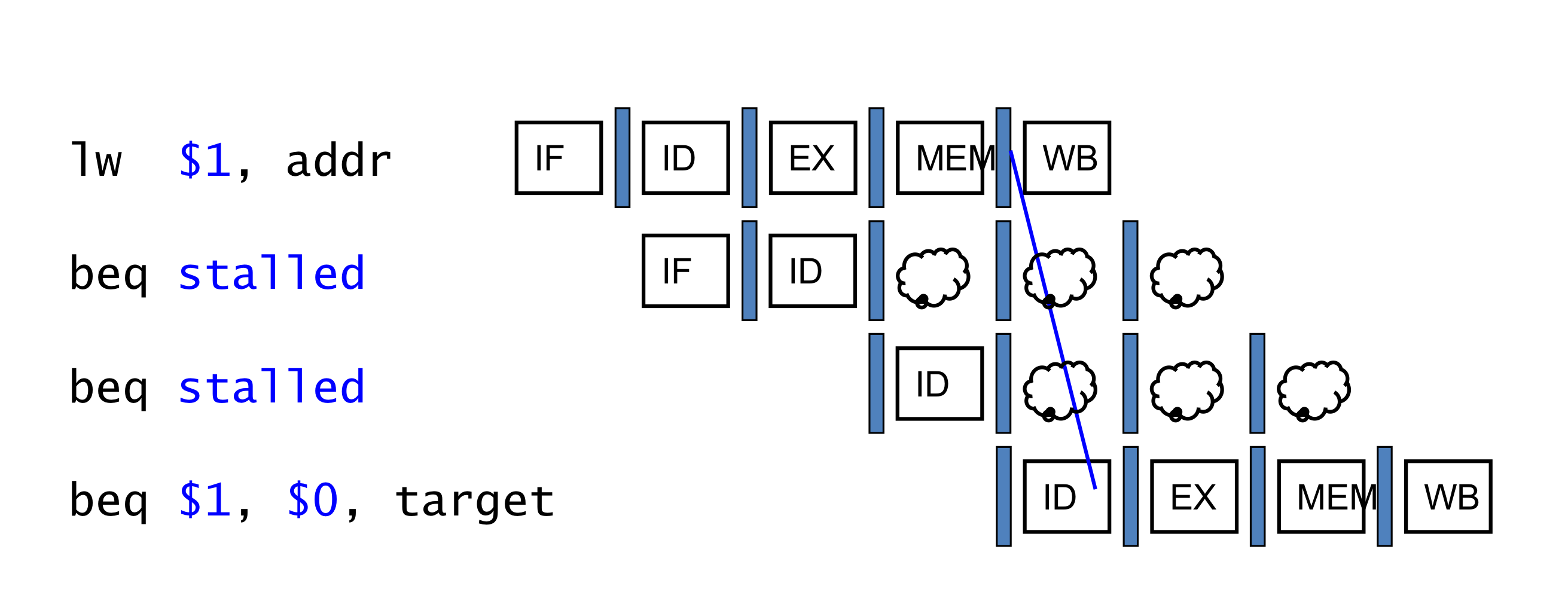
b) Data Hazards for Branches
- 만약 branch에서 비교하려는 레지스터가 2-cycle 전이나, 3-cycle 전의 ALU instrcution의 결과라면

- forwarding을 사용하여 해결할 수 있다.
- 이전에 본 forwarding은 현재 cycle이 Ex stage였다. (ALU에 필요한 피연산자)
- 하지만 이제 branch의 ALU는 ID stage에 있기 때문에, 2, 3전 cycle에 대해서 forwarding을 해야한다.
- 만약, 비교하려는 레지스터가 1cycle 전의 ALU instrcution의 결과 거나 2 cycle 전의 load instruction의 결과 값이라면,
- forwarding이 불가능 하고 하나의 stall이 발생 할 수 밖에 없다.
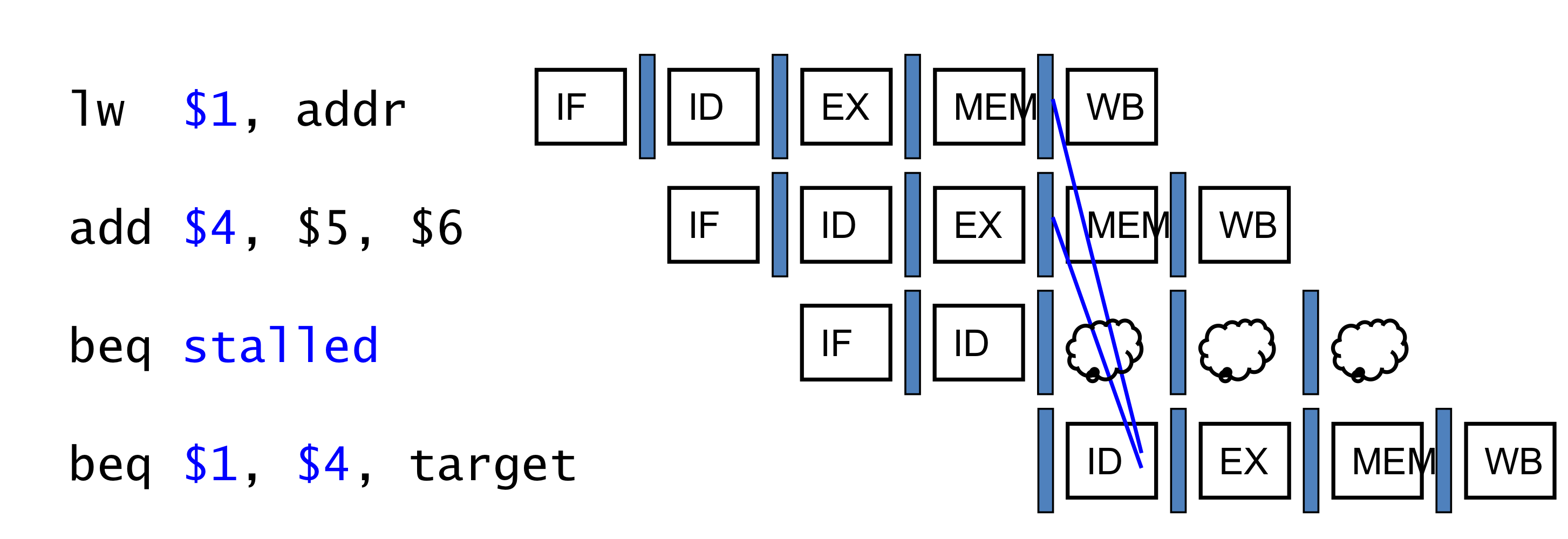
- 만약 비교하려는 레지스터가 직전의 load instruction의 결과 값일 때,
- 2개의 stall이 필요하다.
c) Dynamic Branch Prediction
- 초대형 (depper and superscalar (stage가 아주 많은)) pipeline 일수록, branch 패널티는 더 중요하다.
- stage 수가 많으면 나눠서 일을 하니까 속도가 올라가는데, 그만큼 stall의 개수가 더 많아 질 수 잇다.
- 또한, 복잡도가 올라가서 branch의 결과도 ID stage가 아니라 조금 더 진행이 된 상태에서 알 수 있게 된다.
- 그러면 예상이 틀렸을 때, 미리 진행한 명령어들을 flush하게 되면서 stall이 많아진다.
- dynamic prediction의 사용
- Branch prediction buffer(aka. branch history table)을 둔다.
- 가져온 branch instruction의 주소들을 index 화 한다.
- 결과를 저장한다 (taken, not taken)
- branch를 수행하려면
- 테이블을 살펴보고 결과를 예측한다.
- 순서대로 진행하든, target이든 예상을 통해서 진행한다.
- 만약, 틀렸으면 pipeline을 비우고 예측을 뒤엎는다.
d) 1-Bit Predictor: Shortcoming
- 1-Bit. 바로 전의 결과만 사욯나는 경우.
- 다중 loop에서 inner look는 예측 실패를 2번 겪는다.
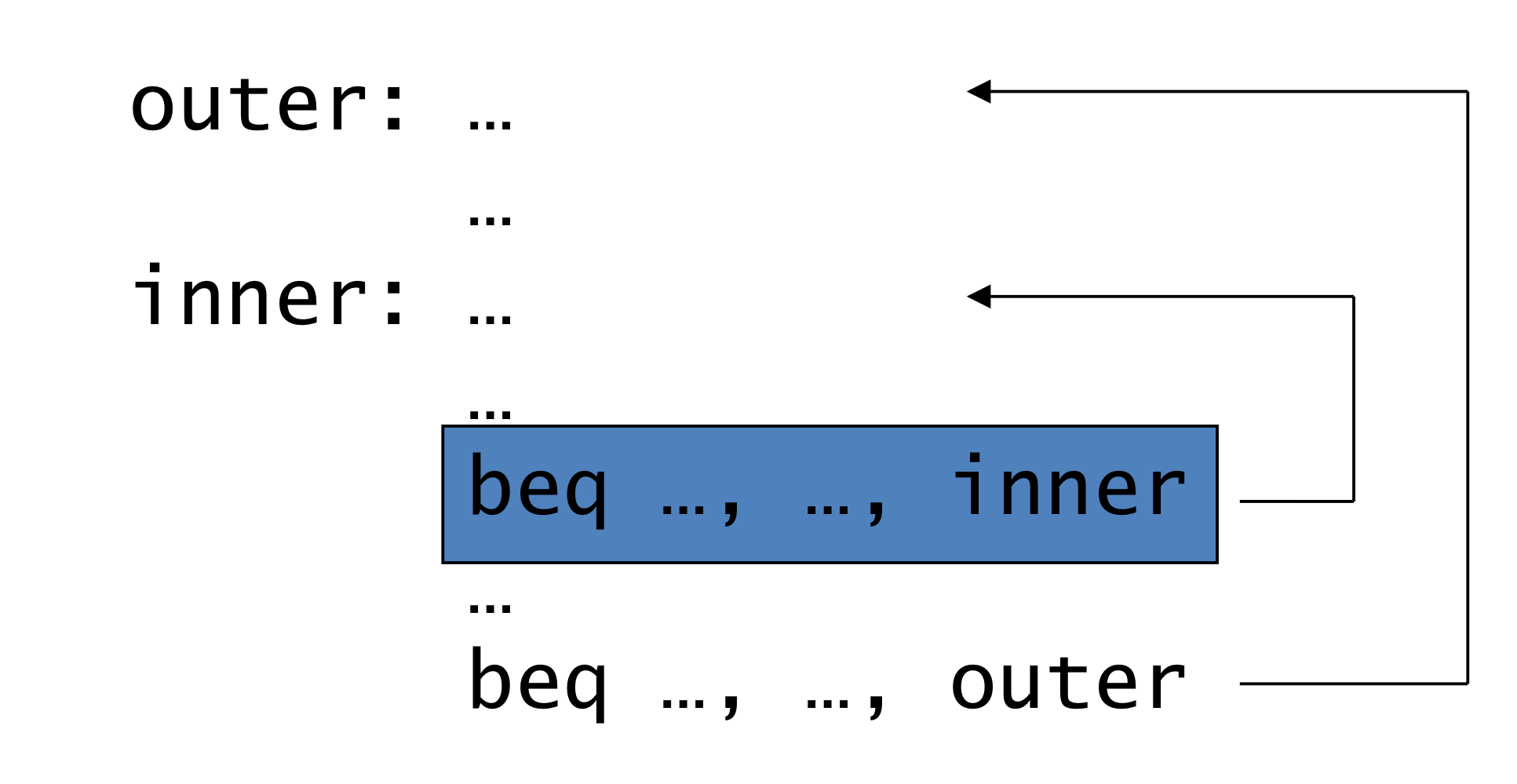
- inner loop의 반복 중 마지막에서, 예측실패는 taken
- inner loop에서, 내부가 반복되었기 때문에 이번에도 그럴 것으로 예상하기 때문에
- inner loop의 반복 중 첫번째에서, 예측실패는 not taken
- inner loop의 가장 최근은 not taken이기에, 이번에도 그럴 것이라고 예측한다.
e) 2-Bit Predictor
- 2번의 연속된 예측 실패가 일어나야만 예측이 바뀐다.
f) Calculation the Branch Target
- predictor을 사용하더라도 여전히 target address는 계산해야 한다.
- branch마다 1-cycle의 패널티
- Branch target buffer
- 대상 주소의 cache
- instruction fetch 때 PC에 의해서 index화 된다.
- 반복될 branch라면, 대상 주소를 기억해두고 재활용
- 만약 예측이 적중하면 target을 즉시 fetch할 수 있다.
- 이미 buffer에 있는 주소라면, 주소 계산을 하지 않는다.
5. Exceptions and Interrupts
- “Unexpected” 이벤트는 control flow의 변화를 필요로 한다.
- 다른 ISA마다 term을 다르게 사용한다.
- Exception
- CPU 내부에서 발생한다.
- e.g, undefined opcode, overflow, syscall…
- CPU 내부에서 발생한다.
- Interrupt
- 외부 I/O controller 로부터 발생한다.
- 성능을 희생하지 않고서 이 문제들을 다루는 것은 어렵다.
1) Handling Exceptions
- MIPS 에서 exception은 System Control Coprocessor (CP0)에 의해서 관리가 된다.
- 문제가 생긴 (offending, interrupted) instruction의 PC를 저장한다.
- In MIPS: Exception Program Counter (EPC)
- 문제의 종류를 저장한다.
- In MIPS: Cause register
- 1-bit로 가정한다면,
- undefined opcode는 0, overflow는 1
- 8000 00180(미리 정해진) handler로 jump한다.
a) An Alternate Mechanism
- Vectored Inerrupts
- 원인에 따른 handler 주소가 다르게 저장되어 있다.
- Example:
- Undefined opcode: C000 0000
- Overflow: C000 0020
- …: C000 0040
- Instructions either
- 해당 interrupt를 다루거나,
- reald handler(문제를 제대로 처리 할 수 있는)로 jump한다.
b) Handler Actions
- cause를 읽고, 관련된 handler로 넘겨준다.
- 필요한 동작을 결정한다.
- 만약 해당 명령어를 재시작 가능하다면,
- 적잘한 동작으로 고쳐서 동작한다.
- EPC를 이용하여 다시 program으로 돌아갈 수 있도록 한다.
- 그렇지 않다면
- program을 중단한다.
- EPC, cause,.. 등을 사용하여 error를 보고한다.
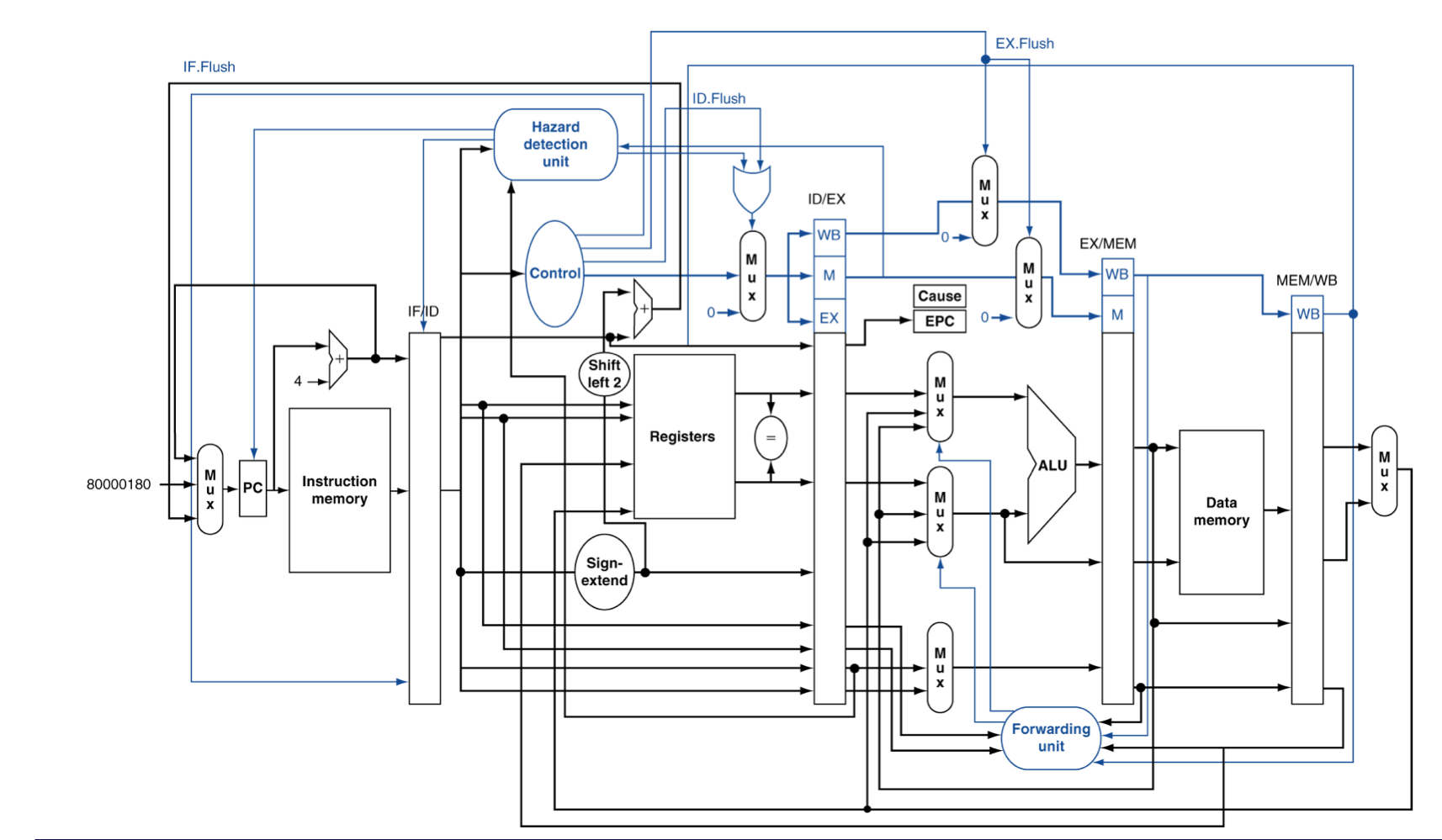
c) Exceptions in a Pipeline
- Control hazard의 또 다른 형태로 볼 수 있다.
- control hazard는 프로그램의 flow가 바뀔지도 몰라서 직후 명령어가 바로 실행 될 수 없는 hazard
- add명령어의 EX stage에서 overflow가 발생한 경우
- add $1, $2, $1
- $1에 잘못된 값이 쓰여지는 것을 막는다.
- 이전 명령들은 제대로 완수될 수 있도록 한다.
- add와 이후 명령어들을 flush한다.
- EPC와 Cause Register의 값을 세팅한다.
- handler로 제어권을 넘긴다.
- 예측실패한 branch와 유사하다.
- 동일한 하드웨어 자원을 많은 부분 함께 사용한다.
d) Exception Properties
- 재실행 가능한 명령어에 대한 exception
- pipeline은 명령어를 비운다.
- Handler가 실행 된 후, 원래의 instrcution으로 돌아감.
- 이번엔, 시정된 instruction을 실행한다.
- EPC register에 PC가 저장된다.
- 문제가 발생한 instruction을 식별가능
- 당연히 실제로는 PC+4가 저장 될 것이다.
- handler에서 반드시 조정해야함(-4를 PC를 넣어줘야 해당 instruction으로 돌아감.)

Exception example
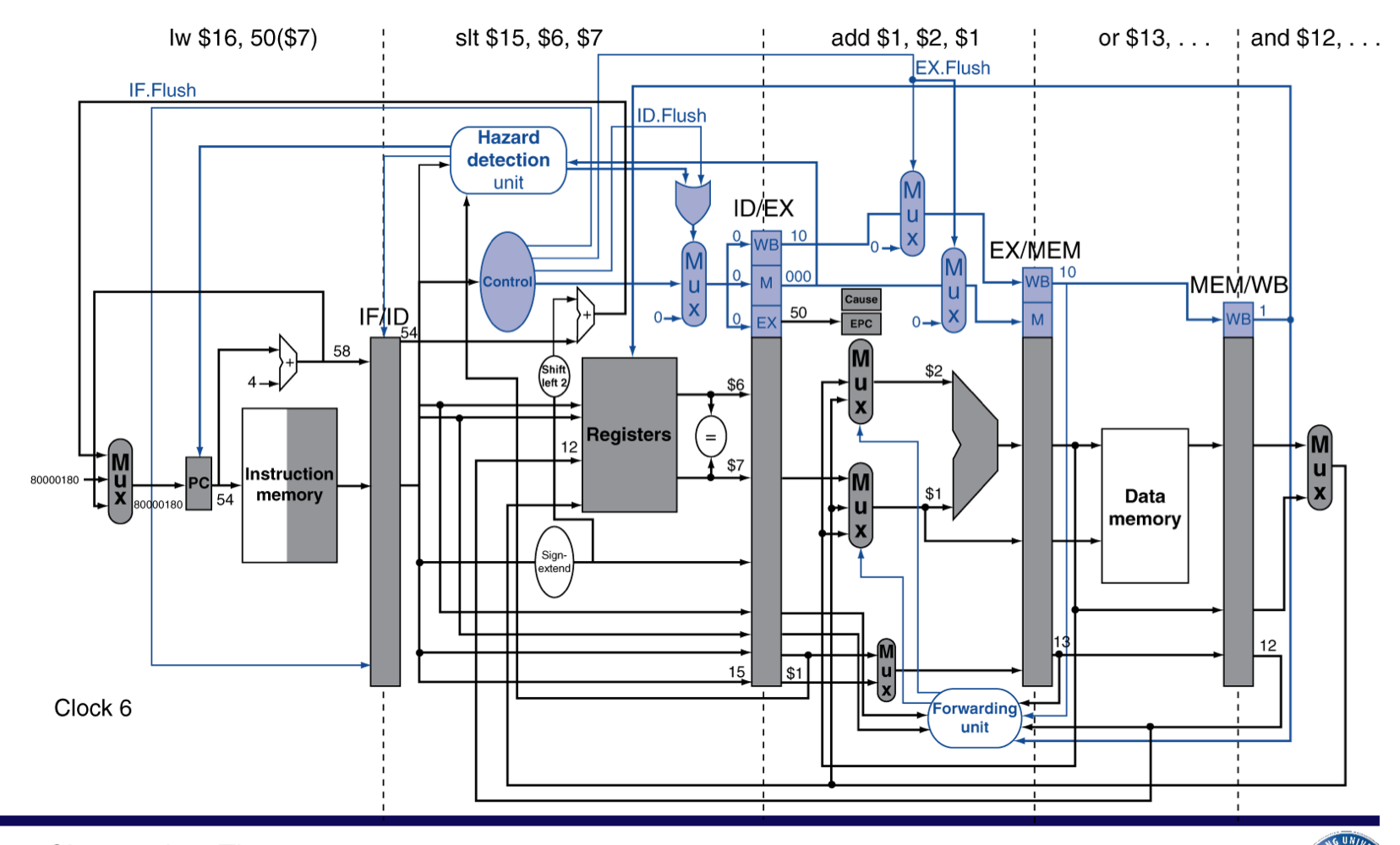
flush 후에 handler로 jump
e) Multiple Exceptions
- pipeline은 여러 명령어를 동시에 수행한다.
- 그러므로 동시에 여러 exception이 발생할 수도 있다.
- Simple approach: 더 일찍 실행된 instruction의 exception 부터 처리한다.
- 뒤이어 오던 Instruction은 함께 flush
- “Precise” exceptions
- In Complex pipeline
- cycle마다 여러 instruction을 실행할 수 있다.
- 명령어의 결과 순서가 실행 순서와 같지는 않다.(out-of-order)
- 정확한 exception을 지키기가 어렵다.
f) Imprecise Exception
- pipeline을 멈추고 현 상태(state)를 저장한다.
- exception cause(s)도 포함한다.
- 이제 handler가 동작하도록 한다.
- 어떤 instruction이 exceptions을 발생시켰는지,
- 어떤 것을 처리할지 혹은 flush할 지
- May require “manual” completion
- 하드웨어는 간결화 하되, handler software를 더 복잡하게 한다.
- 명령어를 다중 수행할 수 있는 out-of-order pipeline에서는 불가능
6. Parallelism via Instructions
1) Instruction-Level Parallelism
- Pipelining: 여러 instruction들을 병렬적으로(in parallel) 수행
- ILP를 향상 시키기 위해서
- Depper pipeline
- stage마다 더 적은 일을 하면 → clock cycle은 짧아진다.
- stage마다 같은 clock cycle을 가지므로, stage를 조금 더 세분화 해서 한 단계가 적은 일을 하면, 속도는 더 빨라진다.
- Multiple issue
- pipeline stage들을 복제 → multiple pipelines
- clock cycle마다 여러 instruction들을 동시에 시작
- 최근에는, CPI < 1이 되므로, IPC(Instructions per cycle)을 사용
- E.g., 4GHz 4-way multiple-issue
- 16 BIPS, peak CPI = 0.25, peak IPC = 4
- 하지만, 실제로는 instruction의 dependencies때문에 병렬성이 감소됨.
- Depper pipeline
a) Multiple Issue
- Static multiple Issue
- compiler가 Instruction들이 함께 issue될 수 있도록 묶어준다.
- “issue slots”으로 package 화 한다.
- compiler가 hazards를 감지하고 회피한다.
- Dynamic multiple Issue
- CPU가 instruction stream을 시험해보고, 각 cycle에 issue할 instruction을 고름
- compiler가 instruction 순서를 재배치 함으로써 도와줄 수 있다.
- runtime동안에 CPU는 advanced techniques로 hazard를 해결한다.
2) Speculation
- 어떤 instruction을 할 것인지 “Guess”하는 것
- operation을 가능한 빨리 시작해본다.
- 예상이 맞았는지 확인한다.
- 만약 맞다면 operation을 그대로 실행하여 마친다.
- 틀렸다면, roll-back하고 올바른 작업을 한다.
- static and dynamic multiple issue에서 모두 공통적으로 사용하는 형태이다.
- Example
- branch의 결과를 추측하는 것
- 만약 틀렸다면 Roll back한다.
- load 명령어에서
- 값이 변하지 않을 경우가 많기에 미리 저장된 location을 사용하지만,
- 주소 값이 변했다면 Roll back한다.
- branch의 결과를 추측하는 것
a) Compiler/Hardware Speculation
- Compiler는 Instruction의 순서를 재배치 할 수 있다.
- e.g., branch직전의 load(2칸의 여유가 필요)를 옮긴다.
- 예상이 실패 한다면, “fix-up” instruction을 끼워넣어서 복구 가능
- Hardware는 실행할 instruction들을 내다볼 수 있다.
- instruction들이 실제로 수행되어야 하는게 맞았는지 알기 전까지, buffer가 instruction들을 수행하여 결과를 갖고 있다가,
- 추측이 맞았으면 그대로 가져다가 쓰고,
- 추측이 실패하면 buffer를 비운다.
b) Speculation and Exceptions
- 만약 추측으로 실행하는 instruction에서 exception이 발생한다면?
- e.g., null-pointer 체크 전에 추측성 load 명령어
- Static speculation
- ISA의 도움을 받아서, exception들을 지연시킬 수 있다.
- Dynamic speculation
- instruction들이 완료 될 때 까지, exception들을 buffer화 할 수 있다. (마치 exception이 일어나지 않은 것처럼.)
c) Static Multiple Issue
- 컴파일러가 instruction들을 “issue packets”화 하여 그룹화한다.
- instruction 그룹은 한 single cycle에 issue될 수 있다.
- 해당 명령어들이 필요로하는 pipeline resource에 의해 묶여진다.
- 하나의 issue packet을, 아주 긴 instruction처럼 생각한다.
- 여러개의 동시 작업들(multiple concurrent operations)을 규정한다.
- → Very Long Instruction Word(VLIW)
2) Scheduling Static Multiple Issue
- 컴파일러는 반드시 some/all hazard를 제거해야한다.
- instruction들의 순서를 재배치하고, issue packet들로 묶는다.
- 한 packet은 의존성이 없도록 묶어진 것이다.
- 다른 packet들 사이에는 의존성이 있을 수 있다.
- ISA따라 다르고, compiler는 반드시 알아야한다.
- 그래서 만약 필요하다면, NOP(stall, bubble)을 삽입한다.
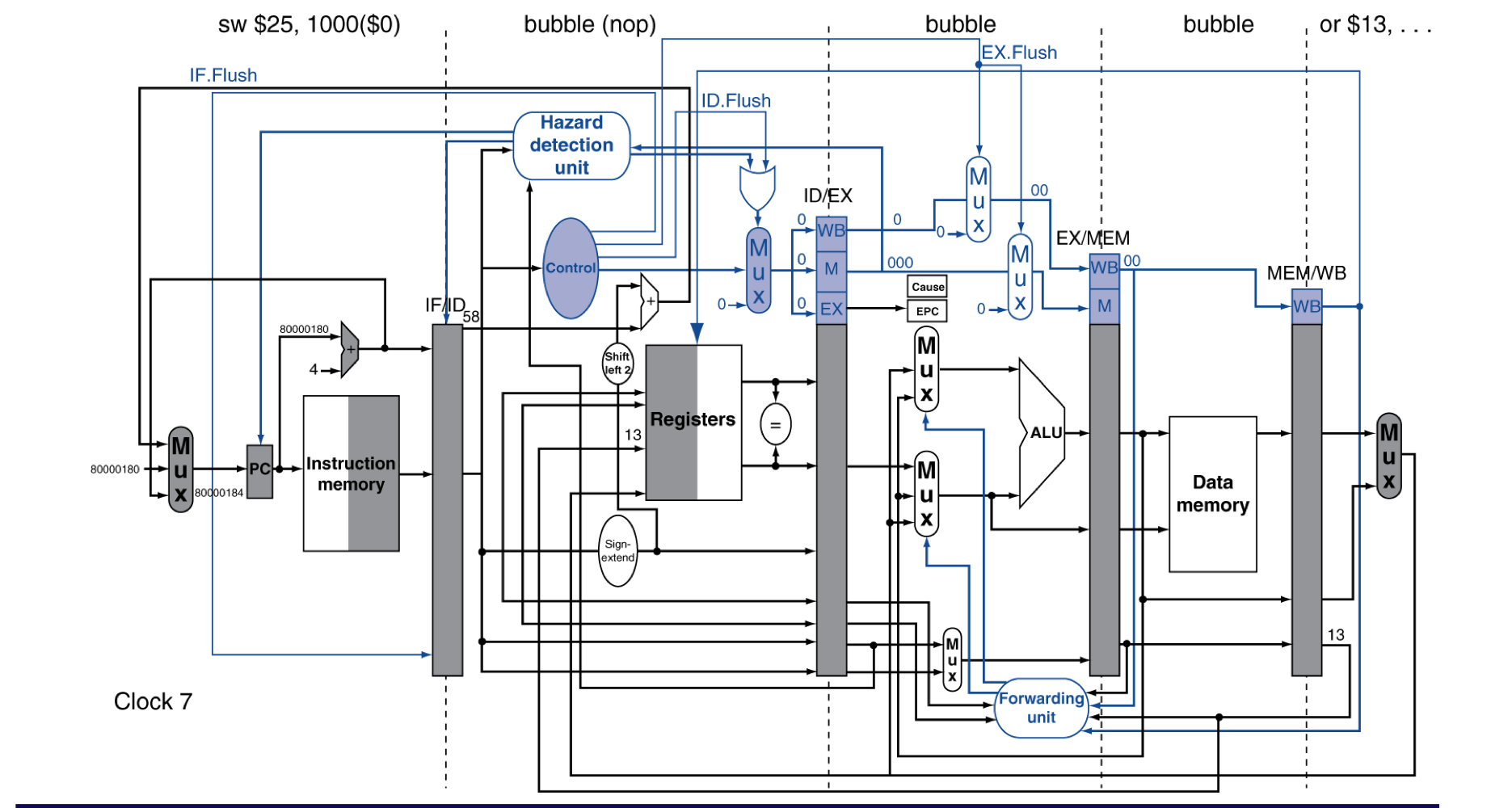
a) MIPS with Static Dual Issue
- Two-issue packets
- 1 ALU/branch instruction
- 1 load/store instruction
- 64-bit 정렬
- ALU/branch와 load/store
- 사용되지 않는 instruction은 nop(bubble)로 채운다.

- ALU/branch는 기존 hardware를 이용한다고 한다면,
- load/store를 위한 장치와 datapath등이 추가 되었다.
- ALU/branch는 메모리를 사용하지 않기 때문에, 메모리를 거치지 않고 바로 WB
b) Hazards in the Dual-Issue MIPS
- 병렬적으로 더 많은 instruction을 실행하는 형태
- EX data hazard
- single-issue에서 forwarding을 이용하여 stall을 피했다.
- 이제는 같은 packet에서의 load/store는 ALU result를 사용할 수 없다.
- add $t0, $s0, $s1 load t0)
- 두개의 packet으로 나누어도, stall은 발생(1 cycle)
- Load-use hazard
- 여전히 1-cycle의 latency가 필요하지만, 이번에는 2개의 instruction이 동시에 실행
- 더욱 aggressive한 scheduling이 필요해진다.
c) Scheduling Example
- dual-issue MIPS를 위한 schduling
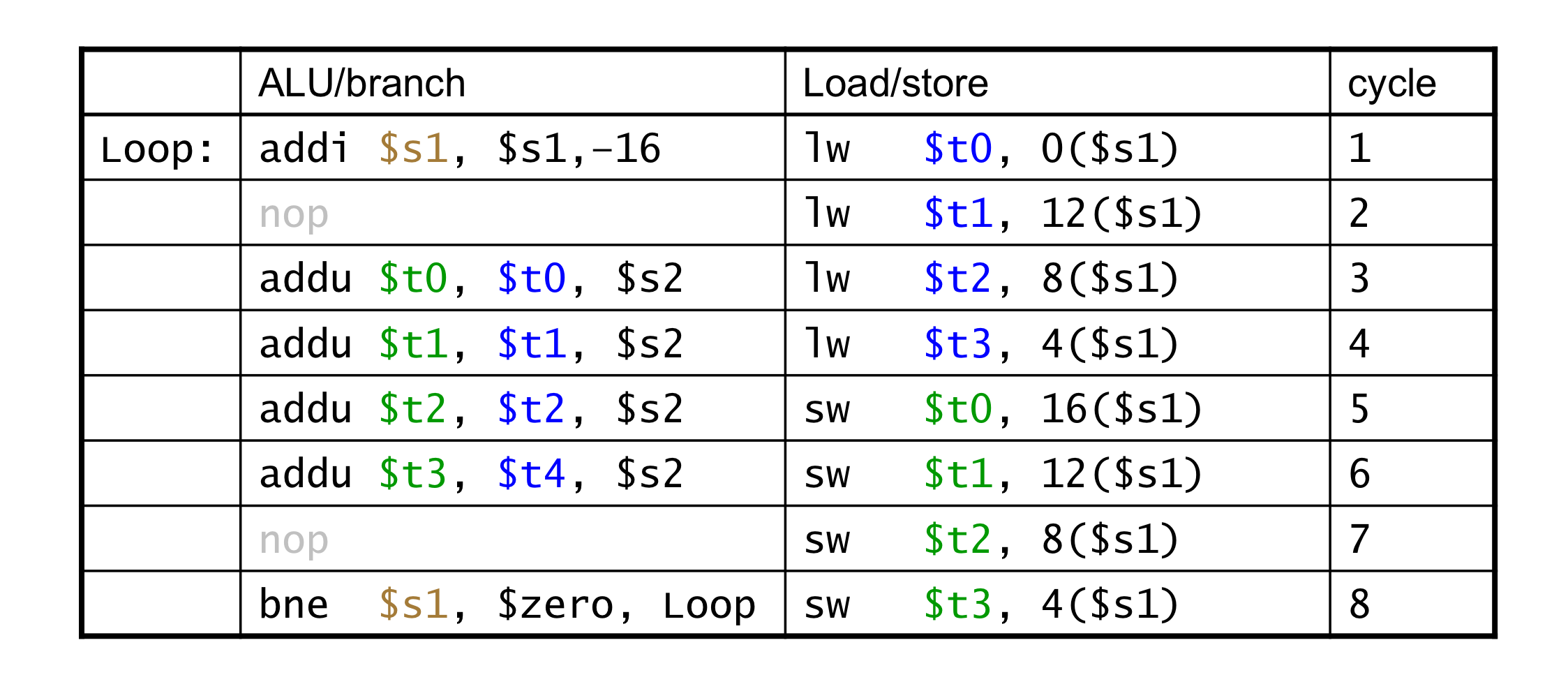
- IPC = 5/4 = 1.25 (c.f. peak IPC = 2)
d) Loop Unrolling
- loop body를 복제하여 더 병렬적인 형태로 만드는 것
- loop-control overhead를 줄여준다.
- replication 마다 다른 register를 사용하게 하한다.
- “register renaming”이라고도 한다.
- loop에서 나오는 “anti-dependencise”를 피하게 한다.
- 같은 레지스터를 load한 후 다시 store 할 때,
- Aka “name dependence”
- 레지스터 이름을 재사용
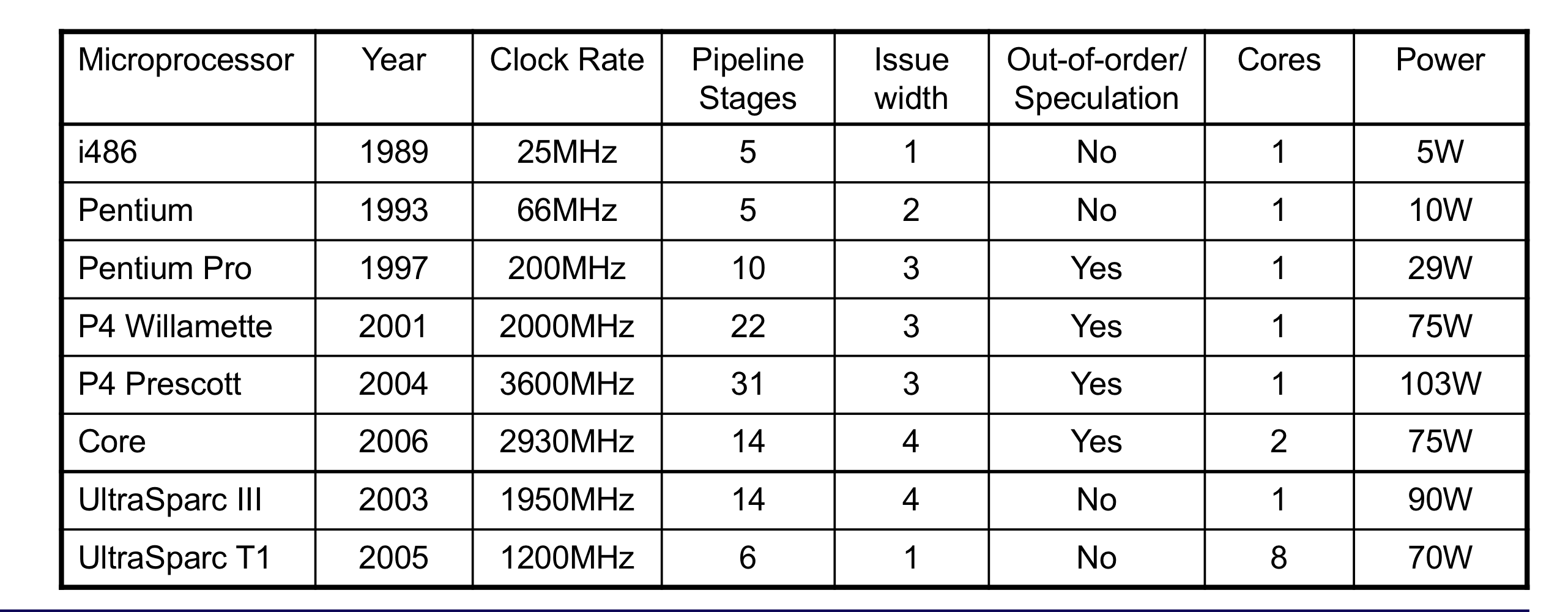
- IPC = 14/8 = 1.75
- 기존의 1.25보다 상승하여 더 2(peak IPC)에 가까워짐.
- 하지만, code의 길이와 레지스터의 비용은 증가
2) Dynamic Multiple Issue
- “Superscalar” processors
- CPU가 각각의 cycle에 어떤 instruction이 issue될 지 결정하는 것.
- runtime에 동적으로 (주체가 컴파일러가 아니라 CPU이기에)
- CPU가 향후 instruction들을 미리 내다보고, 시험 후 순서를 정하여 진행
- structure hazards, data hazards를 방지해줌.
- compiler scheduling의 필요성을 주줄임
- 그러나 여전히 도움이 될 수 있다.
- 전체적으로 code의 제어권은 CPU가 가진다.
a) Dynamic Multiple Scheduling
- CPU가 stall을 피하기 위해서 instruction을 순서에 관계없이 (out-of-order) 실행하도록 허용하는 것.
- 하지만, 레지스터에 결과를 반영하는 것은 순서대로.
- Example
- addu가 lw 때문에 기다리고 있는 동안, sub를 실행 할 수 있도록 해준다.
b) Dynamically Scheduled CPU
c) Register Renaming
- Reservation station과 reorder buffer는 효과적으로 register renaming을 제공.
- reservation station에 instruction issue가 진행될 때,
- 만약 operand가 reorder buffer나 register file에서 값을 사용할 수 있다면,
- reservation station으로 복사된다.
- 이제 레지스터는 필요 없으므로, overwritten(값이 다시 쓰여도 된다.)
- operand가 만약 준비되지 않았다면,
- function unit에서 값을 가져와서 reservation station으로 제공한다.
- Register update가 필요하지 않다.
- 만약 operand가 reorder buffer나 register file에서 값을 사용할 수 있다면,
3) Speculation
- branch를 예측해서 막힘없이 계속 issuing하는 것
- 제대로 branch결과가 결정되기 전까지는 commit하지 않는다.
- Load speculation
- load, cache miss의 delay를 방지한다.
- effective address를 예측한다.
- loaded value를 예측한다.
- 다른(단계적으로 이전) store가 완료되기 전에 값을 load gksek.
- load에서 레지스터에 값이 쓰일 단계는 생략한다.
- 추측히 확실히 되기 전까지는 load를 commit하지 않는다.
- load, cache miss의 delay를 방지한다.
4) Why Do Dynamic Scheduling?
- 왜 compiler schedule code(static)을 사용하지 않는가?
- 컴파일러가 모든 stall을 예측할 수 있는 것은 아니다.
- e.g., cache misses
- branch 주변은 항상 schedule할 수 있는 것이 아니다.
- branch 결과는 동적으로 결정되기 때문에
- 다른 ISA 구현 방식은 각자 다른 latency와 hazard를 야기한다.
5) Does Multiple Issue Work?
- 맞지만, 우리에는 기대에는 덜 미친다.
- 프로그램은 ILP(Instruction-Level Parallelism)을 제한시키는 의존성(real dependencies)을 가지고 있기 때문이다.
- 몇몇 dependencies는 제거하기가 힘들다.
- e.g., pointer aliasing
- 몇몇 parallelism은 활용하기가 힘들다. (hard to expose)
- Limited window size during instruction issue
- Memory delays and limited bandwidth
- pipeline이 full인 상태로 유지하기가 힘들다.
- Speculation이 잘 들어맞다면 도움을 줄 수 있다.
6) Power Efficiency
- dynamic scheduling과 speculation의 복잡성은 전력을 더 필요하게 만든다.
- Multiple simpler cores가 더 나을 수도 있다.
7. Fallacies and Pitfalls
1) Fallacies
- pipelining is easy
- 기본적인 개념은 쉽다.
- 하지만 상세히 파고든다면 상당히 어렵다.
- e.g., detecting data hazards
- pipelining은 기술에 의존적이지 않다.
- 그러면 왜 처음부터 pipelining을 하지 않았겠느냐.
- 더 많은 transistor는 더 발전된 기술을 가능하게 한다.
- Pipeline-related ISA design은 technology trend를 고려하여야한다.
- e.g., predicated instructions
2) Pitfalls
- Poor ISA design은 pipelining하기 더 힘들어지게 한다.
- e.g., complex instruction sets (VAX, IA-32)
- pipeline 동작을 하기 위해 더 큰 overhead가 발생한다.
- IA-32의 micro-op 방식
- e.g., complex addressing modes
- 레지스터 발전의 부작용, 메모리 우회법
- e.g., delayed branches
- 발전된 pipeline은 long delay slot을 사용하여 해결한다.
- e.g., complex instruction sets (VAX, IA-32)
3) Concluding Remarks
- ISA는 datapath와 control 설계에 영향을 미친다.
- Datapath와 control은 ISA설계에 영향을 준다.
- pipelining은 parallelism을 통하여 instruction의 throughput을 늘린다.
- 시간당 더 많은 instruction이 완료된다.
- 하지만 한 instruction의 latency가 줄어드는 것이 아니다.
- Hazards: structural, data, control
- Multiple issue and dynamic scheduling (ILP)
- dependenciㄷs는 parallelism을 방해한다.
- complextiy는 power wall로 향하게한다.
