Ch 5: Large and Fast: Exploiting Memory Hierarchy
1. Introduction
1) principle of locality
- Program들은 어떤 특정 시간에는 주소공간 내의 비교적 작은 부분에만 접근한다.
- 즉 access하는 부분을 계속 access한다.
- Temporal locality
- 최근에 참조된 Item이 또 참조될 가능성이 크다.
- e.g., instructions in a loop, induction variables
- 최근에 참조된 Item이 또 참조될 가능성이 크다.
- Spatial locality
- 어떤 Item이 참조되면 그 근처에 있는 item이 참조될 가능성이 높다.
- e.g., sequential instruction access, array data
- 어떤 Item이 참조되면 그 근처에 있는 item이 참조될 가능성이 높다.
2) Takeing Advantage of Locality
- Memory hierarchy
- 자주 사용하는 데이터를 점점 고속의 저장소, 그리고 CPU에 가깝게
- 모든 것을 disk에 저장
- 최근에 access한 항목들을 disk에서 더 작은 DRAM memory로 복사한다.
- Main memory
- 조금 더 최근의 항목들은 DRAM에서 더 작은 SRAM으로 복사한다.
- Cache memroy attached to CPU
3) Memory Hierarchy Levels
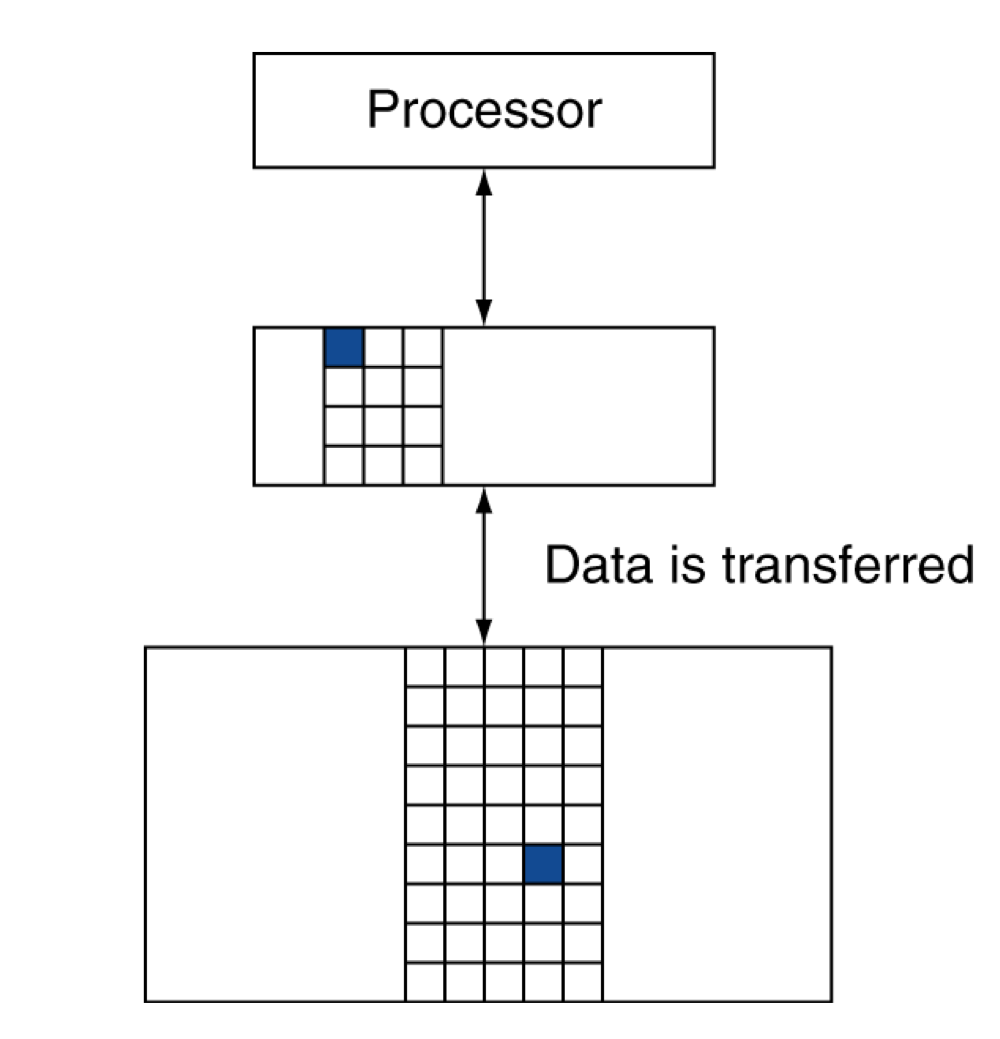
- Block (aka line): 복사의 단위 (unit of copying)
- May be multiple words
- Spatial locality, 근처에 있는 것 까지 다 같이 복사해서 word size보다 큰 것이 좋다.
- May be multiple words
- 만약 원하는 데이터가 upper level에 존재한다면,
- Hit: access satisfied by upper level
- Hit ratio: hits/accesses
- Hit: access satisfied by upper level
- 만약 원하는 데이터가 없다면,
- Miss: block copied from lower level
- Time taken: miss penalty
- Miss ratio: misses/accesses = 1 - hit ratio
- 상층부로 복사해와서, 이제 상층부에서 데이터를 접근한다.
- Miss: block copied from lower level
2. Memory Technology
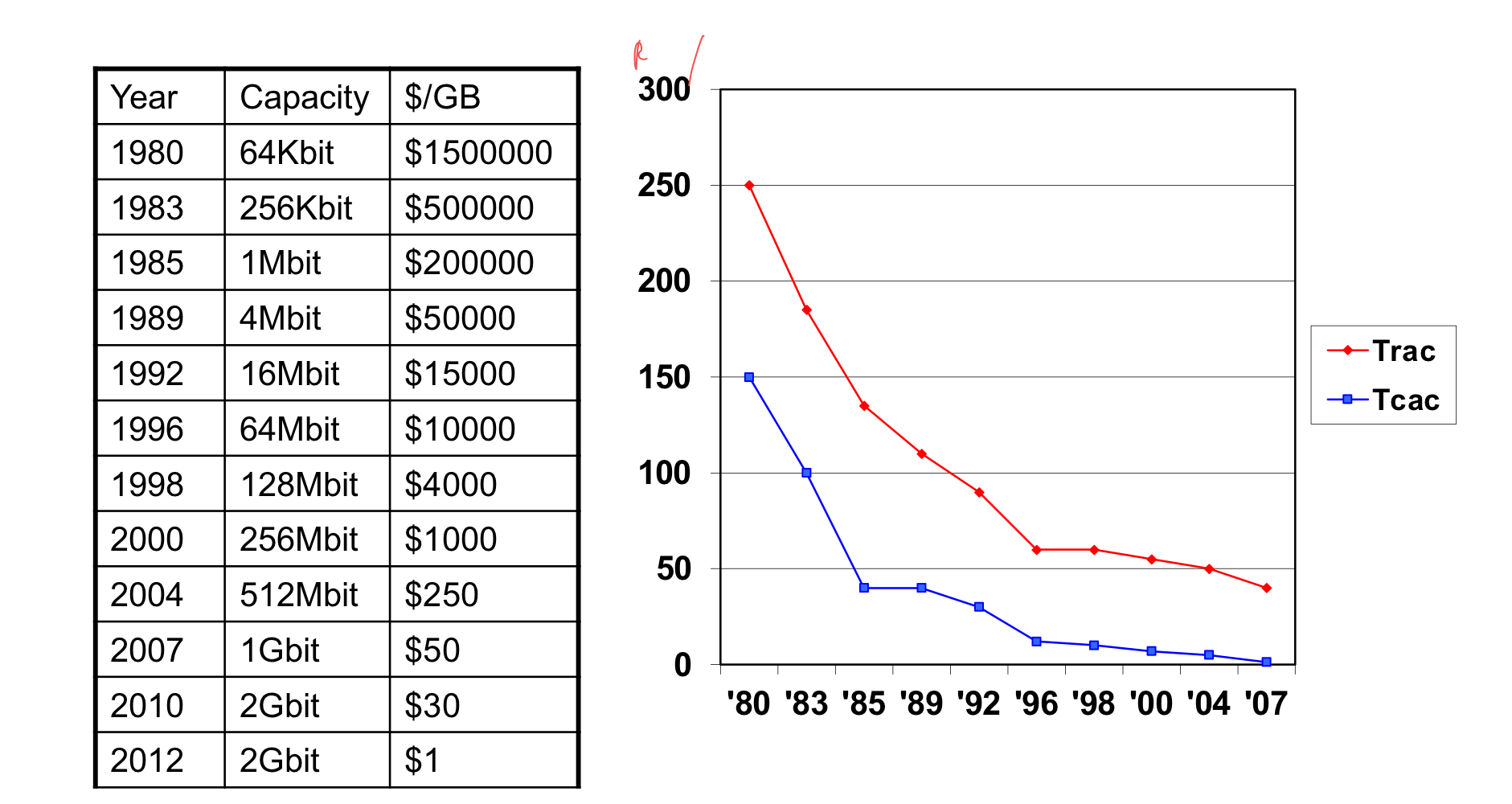
1) Memory Technology (in 2012)
- Static RAM (SRAM)
- 0.5ns - 2.5ns, $500 - $1000 per GB
- Dynamic RAM (DRAM)
- 50ns - 70ns, $10 - $20 per GB
- Flash-based drive (SSD)
- 5us - 50us, $0.75-$1 per GB
- Magnetic disk
- 5ms - 20ms, $0.05 - $0.1 per GB
- 가격 차이가 약 10, 100, 1000배로 늘어난다.
- Ideal memory
- Access time of SRAM, but capacity and cost/GB of disk
2) DRAM Technology
- SRAM → Static RAM, DRAM → Dynamic RAM
- Data는 capacitor(축전기, 콘덴서)의 충전으로써 저장된다.
- Single transistor가 charge(전하)에 access하기 위해 사용된다.
- 주기적으로 데이터를 다시 써 줘야한다.
- Read contents and write back
- DRAM의 “row”에 수행?
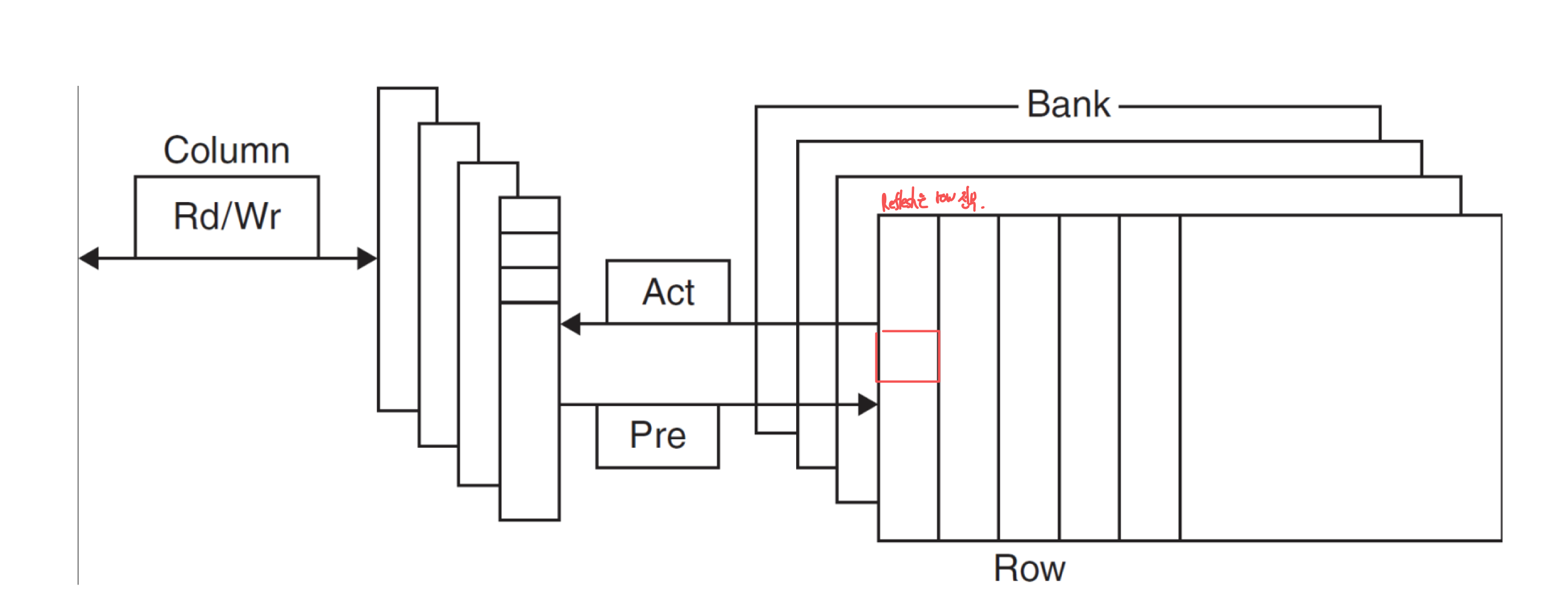
a) Advanced DRAM Organization
- DRAM의 bit들은 rectangular array로 구성된다.
- DRAM은 row에 전체적으로 access한다.
- Burst mode: 감소된 latency으로 row로부터 연속적인 word를 제공
- 추가 주소지정 대신 클럭이 연속적인 비트들을 버스트 모드로 전송하게 할 수 있게 한다.
- Double data rate (DDR) DRAM
- rising and falling clock edge에서 데이터가 전송
- Quad data rate (QDR) DRAM
- DDR의 input과 output을 분리
b) DRAM Performance Factors
- Row buffer
- 병렬적으로 여러 word를 읽고 다시 쓸 수 있도록 한다.
- Synchronous DRAM
- 각각의 주소를 보내지 않더라도, 연속된 주소에는 burst하게 접근 할 수 있도록 해줌
- bandwidth를 향상
- DRAM banking
- 여러 DRAM에 동시에 access할 수 있도록 해줌
- bandwidth를 향상
c) Main Memory Supproting Caches
- DRAM을 Main memory로 사용
- 고정된 사이즈(width) (e.g., 1word)
- 고정된 사이즈의 데이터를 access
- fixed-width clocked bus에 연결되어 있음.
- bus clock은 전형적으로 CPU clock보다 느리다.
- 고정된 사이즈(width) (e.g., 1word)
- cache block read의 예시로, 아래와 같은 조건이라면,
- address transfer에 1 bus cycle
- DRAM access에 15 bus cycle
- data transfer에 1 bus cycle
- 4-word block을 access 할 때, 1-word-wide DRAM에서,
- miss penalty = 1 + 415 + 41 = 65 bus cycles.
- bandwidth = 16 bytes / 65 cycles = 0.25 byte/cycle
d) Increasing Memory Bandwidth
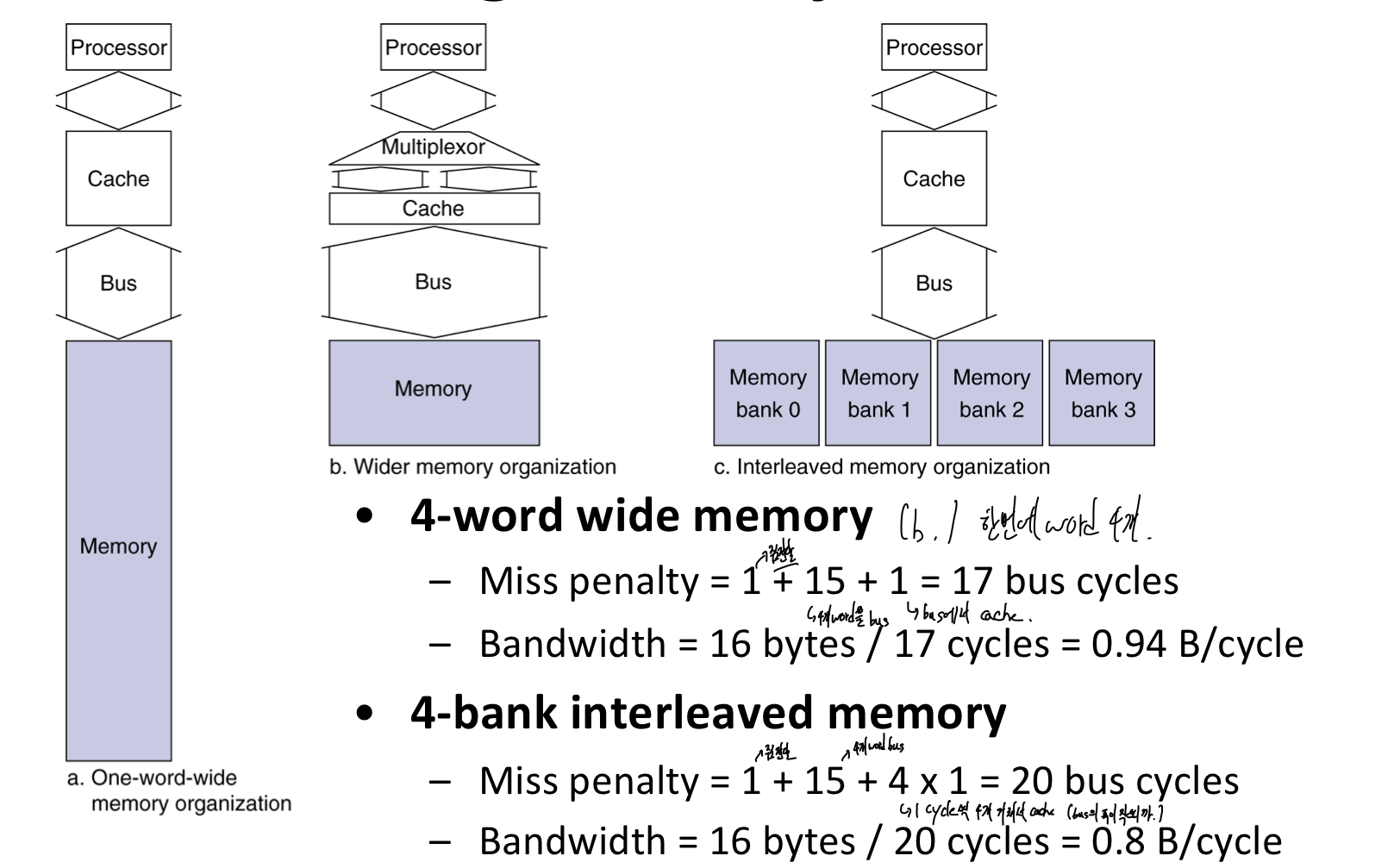
- 성능은 b가 가장 좋지만, 많은 하드웨어 자원 (큰 bus, …)이 사용되므로, c 형태가 주로 사용된다.
3) Flash Storage
- Nonvolatile semiconductor storage
- 100x - 1000x faster than disk
- Smaller, lower power, more robust
- But more $/GB (beween disk and DRAM)
a) Flash Types
- NOR flash: bit cell like a NOR gate (병렬로 연결)
- Random read/write access
- 임베디드 시스템에서의 instruction memroy로 사용된다.
- NAND flash: bit cell like a NAND gate (직렬로 연결)
- Denser (bits, area), but block-at-a-time access (읽는건 오래 걸리지만 기록에 유리하다.)
- Cheaper per GB
- Used for USB keys, media storage,…
- Flash bit들은 1000’정도의 접근 후 마모된다.
- RAM이나 disk의 대체에는 적합하지 않다.
- Wear leveling: 덜 사용한 block에 data를 remap해서 마모 균등화.
4) Disk Storage
- Nonvolatile, rotating magnetic storage
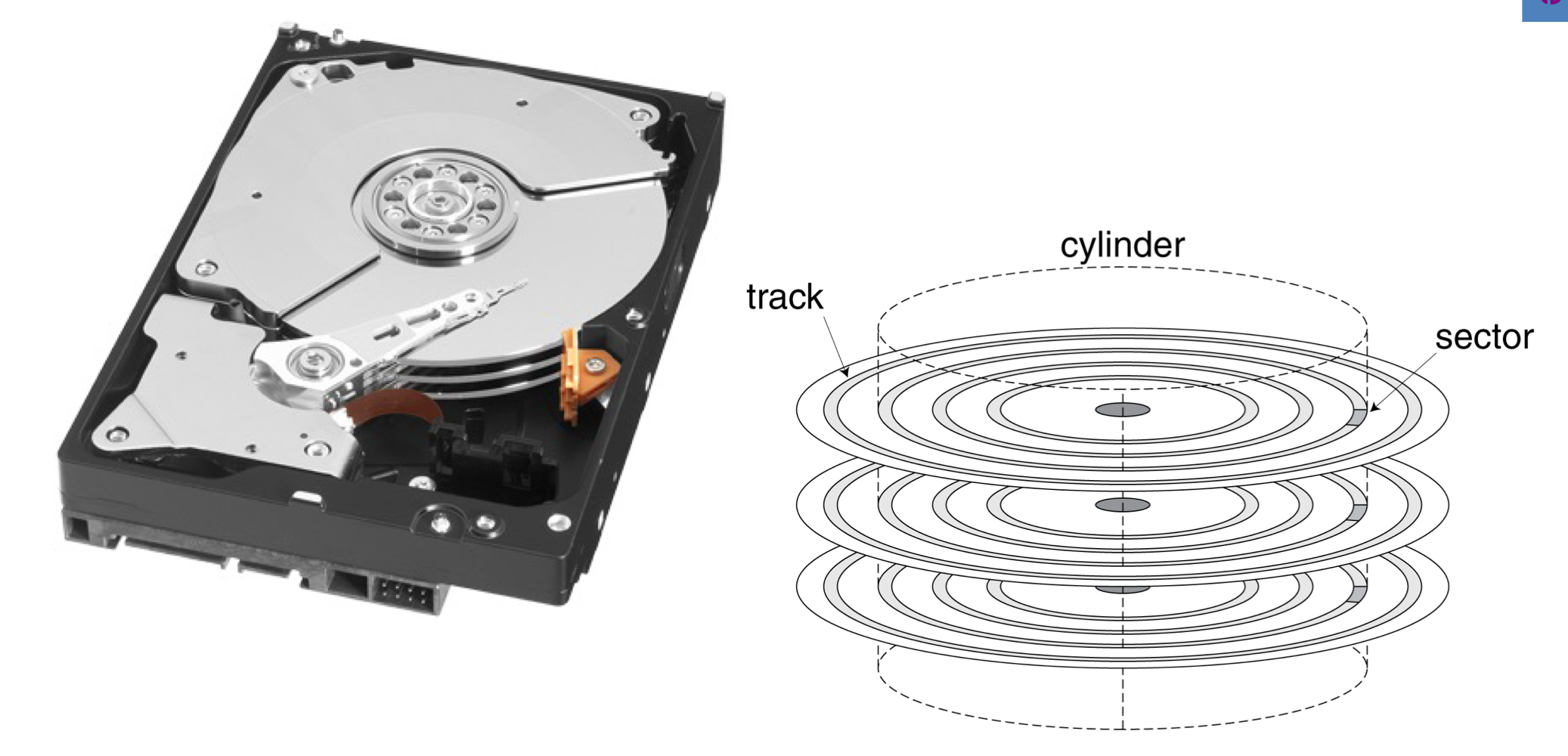
a) Disk Sectors and Access
- Each sector records
- Sector ID
- Data (512 byte ~ 4096 byes)
- Error correcting code (ECC)
- 결함과 recording error들을 숨기기 위해 사용된다.
- fields와 gaps를 동기화
- Access to a sector involves
- 다른 요청이 먼저 처리되는 것을 기다리는 시간.
- Seek: head를 움직인다.
- Rotational latency
- HDD에서 헤드가 올바른 섹터 위에 위치하면 디스크 자체가 회전하여 올바른 데이터를 헤드 아래로 가져와야 한다.
- Data transfer
- 블록 하나를 전송하는 시간
- Controller overhead
- 저장 장치의 컨트롤러가 요청을 처리하고, 데이터를 읽거나 쓰는 데 필요한 추가 시간을 말한다.
b) Disk Access Example
- Given
- 512B sector, 15,000rpm, 4ms average seek time, 100MB/s transfer rate, 0.2ms controller overhead, idle disk
- Average read time
- 4ms seek time
- 1/2 / (15,000)60 = 2ms rotational latency
- 512 / 100MB/s = 0.005ms transfer time
- 0.2ms controller delay
= 6.2ms
- 만약에 average seek time이 1ms라면
- Average read time = 3.2ms
c) Disk Performance Issues
- 제조사들은 평균 seek time을 제공한다.
- 모든 가능한 seek에 기반하여서,
- Locality and OS scheduling은 실제 average seek time을 더 줄인다.
- 스마트 디스크 컨트롤러는 디스크상의 physical sector를 할당한다.
- 호스트에게 logical sector interface를 제공한다.
- SCSI, ATA, SATA
- Disk는 cach를 포함하고 있다.
- 접근이 예상되는 sector를 prefetch
- seek과 rotational delay를 피하게 해준다.
3. The Basics of Caches
1) Cache Memory
- Cache memory
- 메모리 계층에서 가장 CPU와 가까운 단계이다.
- X1, …, Xn-1, Xn으로 cache에 접근한다고 했을 때,

2) Direct Mapped Cache
- 위치는 주소로 인해서 결정이 된다.
- Direct mapped: only one choice
- (block address) modulo (#Blocks in cache)
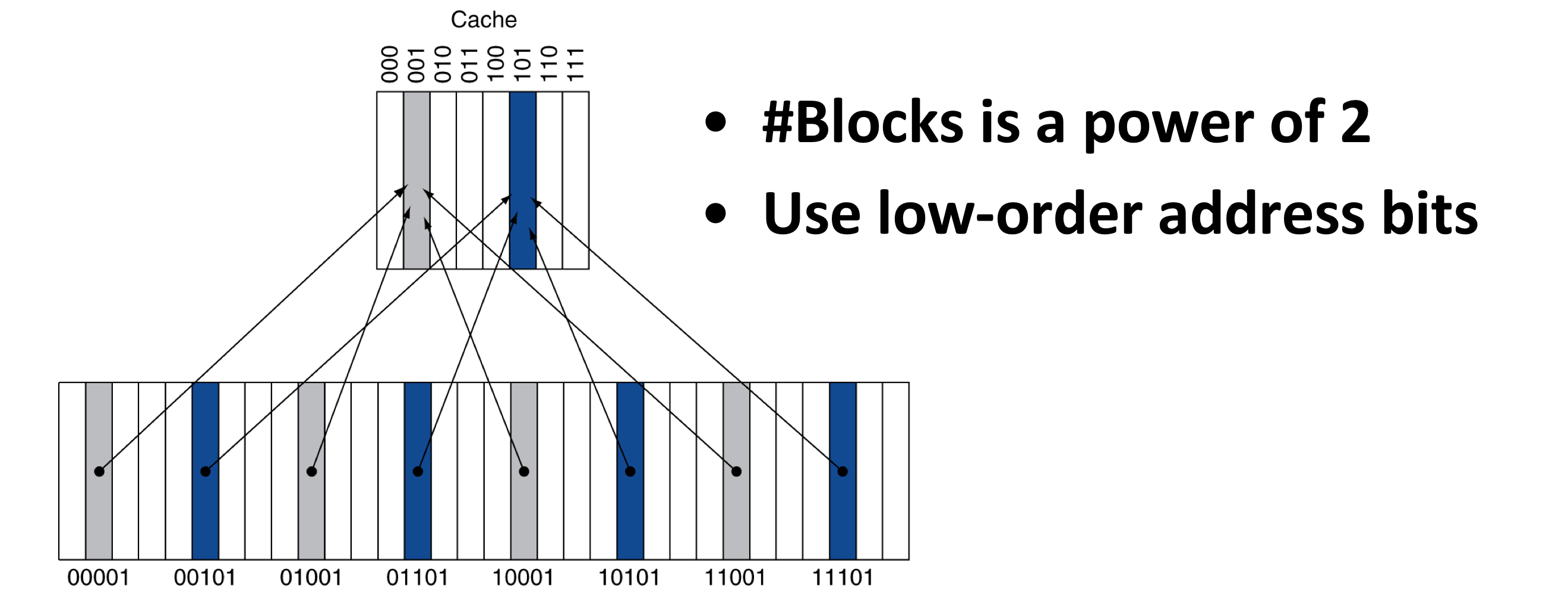
- block의 수는 2^n개 이다.
- 최하위 n비트를 address bits로 사용한다.
a) Tags and Valid Bits
- 캐시의 위치에 매핑된 데이터가, 메모리의 어느 특정 block과 일치하는지 알 수 있는가?
- block address를 data처럼 저장한다.
- 실제로는, 오직 상위 비트만을 필요로한다.
- called tag
- 만약 location에 data가 없다면?
- valid bit: 1 = present, 0 = not present
- Initially 0
b) Cache Example
- 8-blocks, 1 word/block, direct mapped
- Initial state
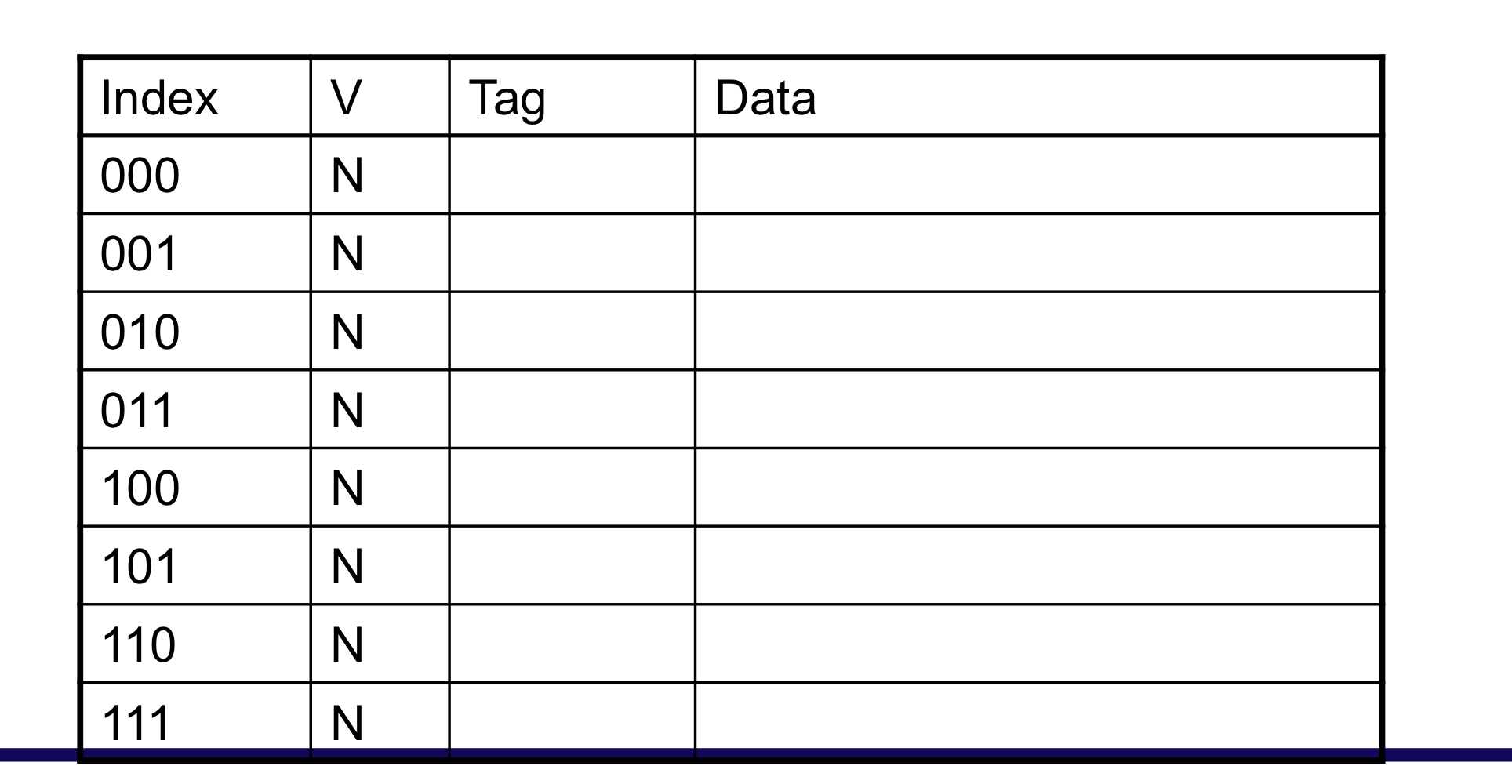
초기 상태
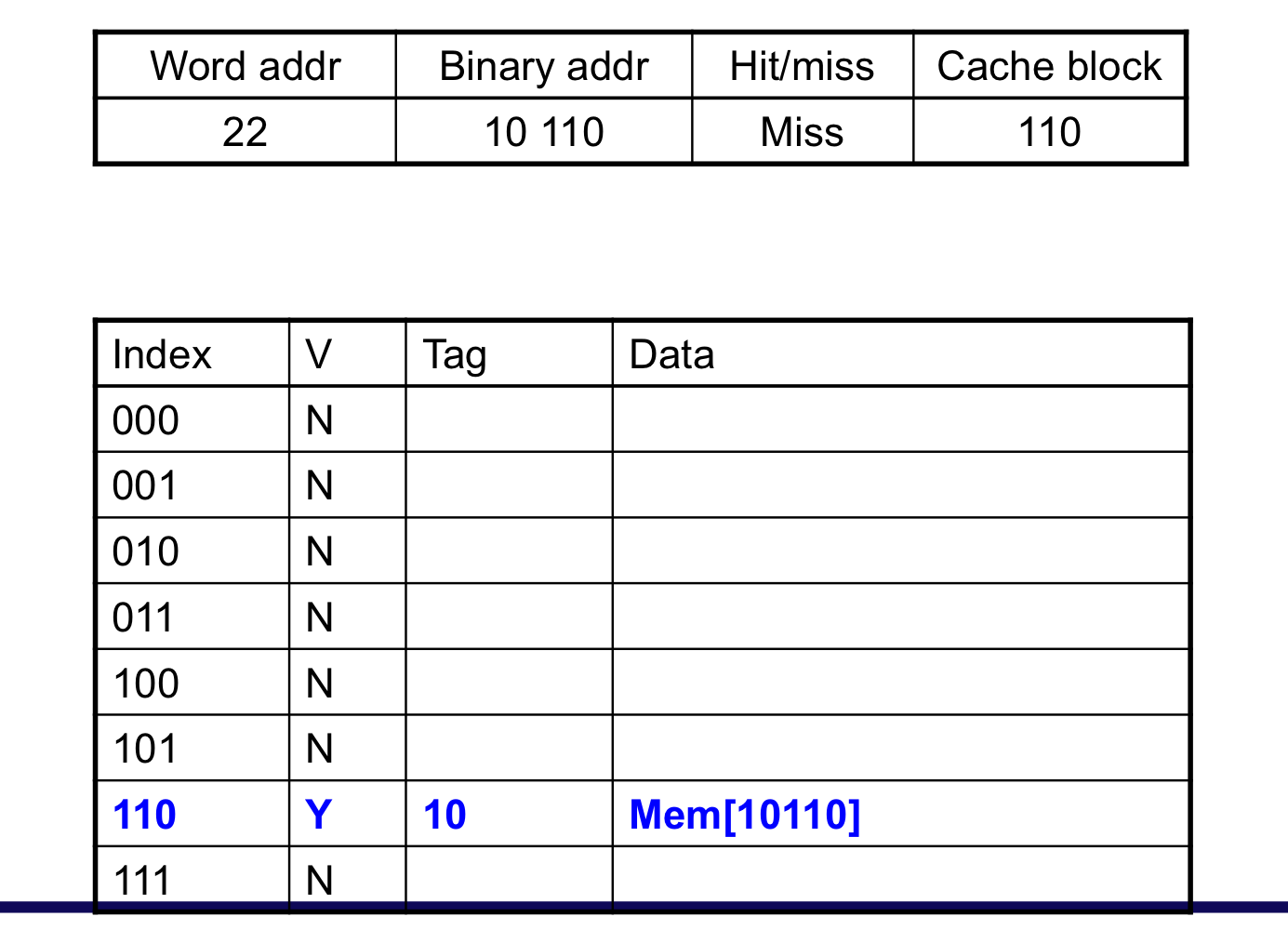
한개의 data가 들어 왔을 때, cache miss 발생 후 채워 넣음
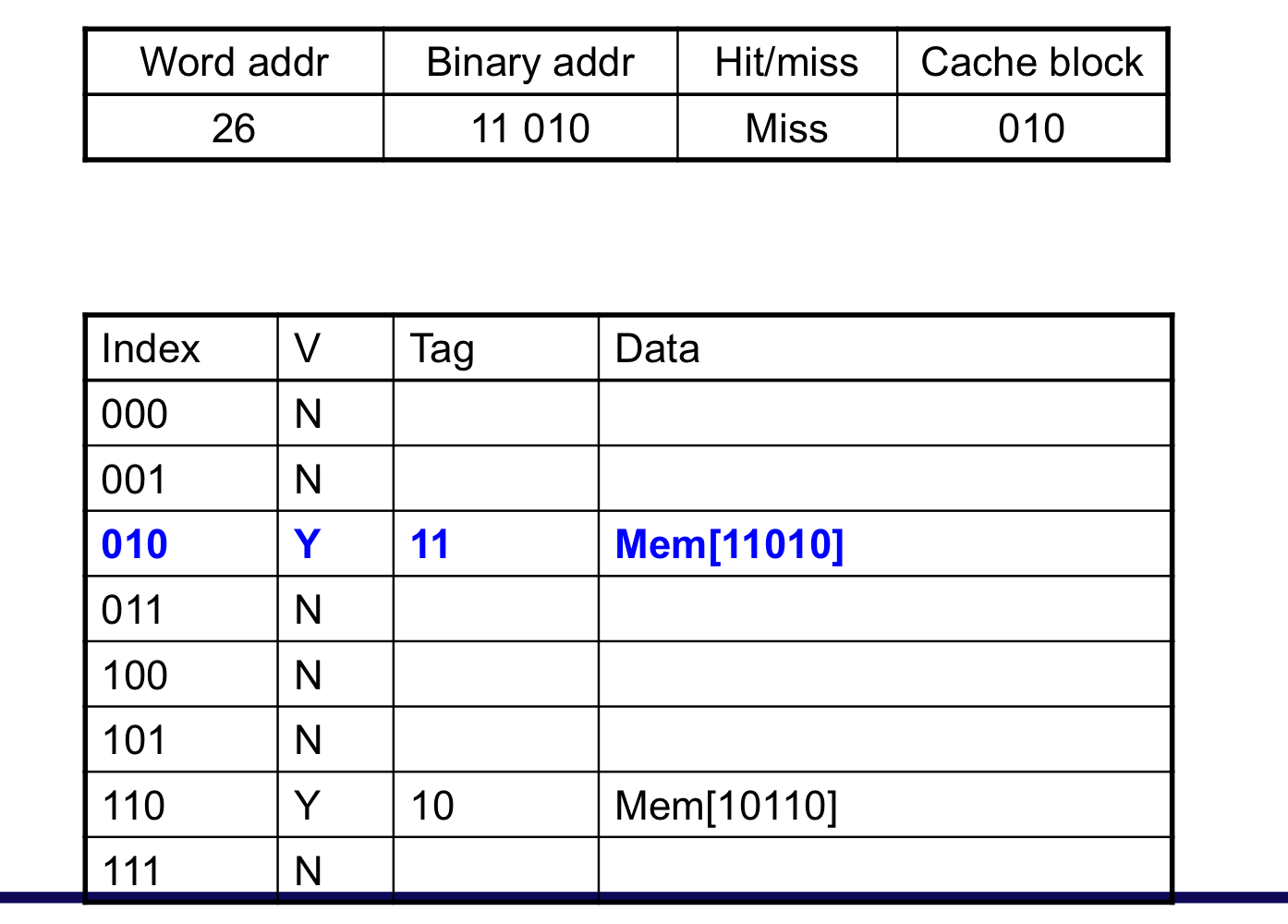
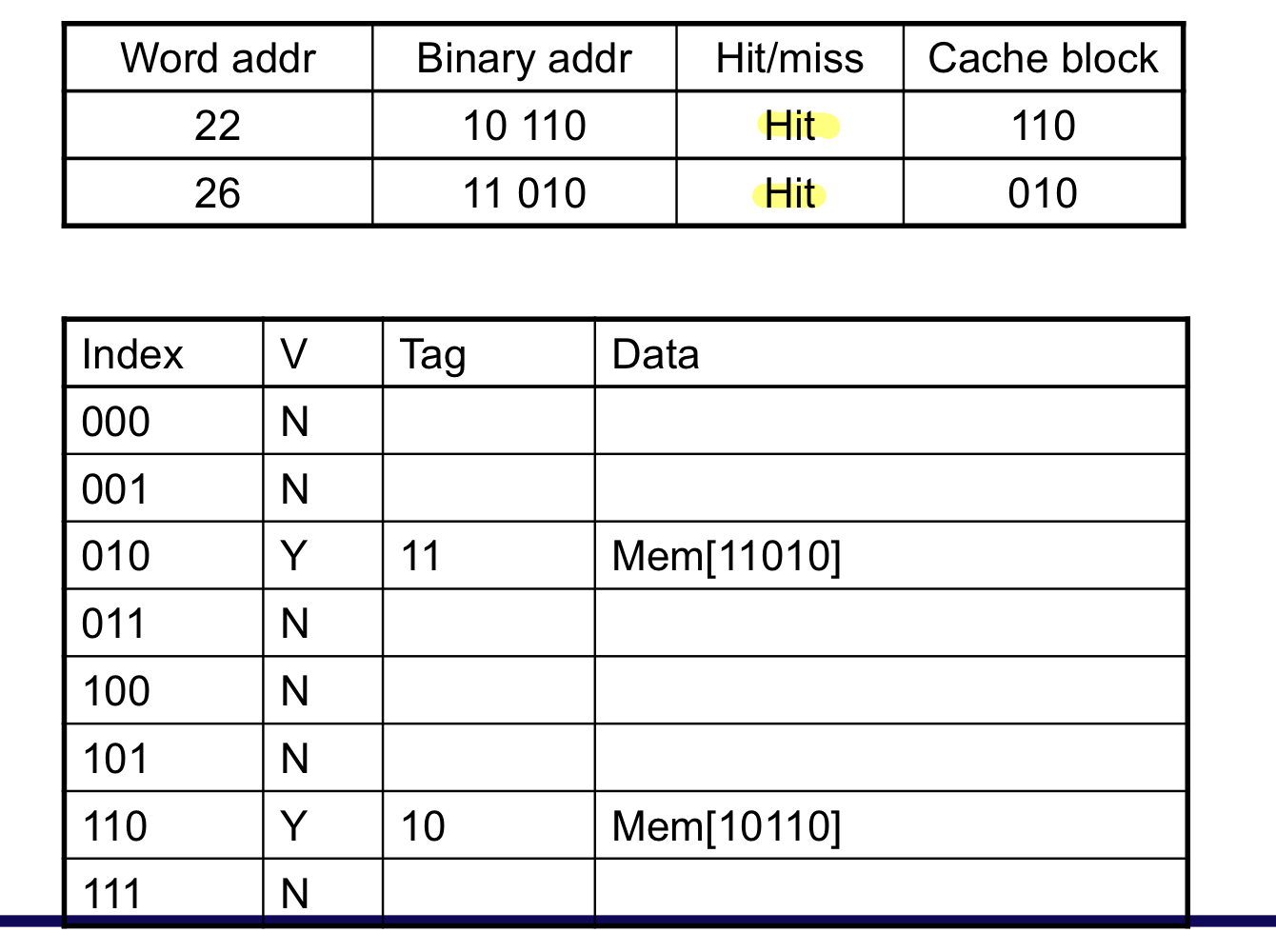
이미 cache에 데이터가 존재하므로 cache hit
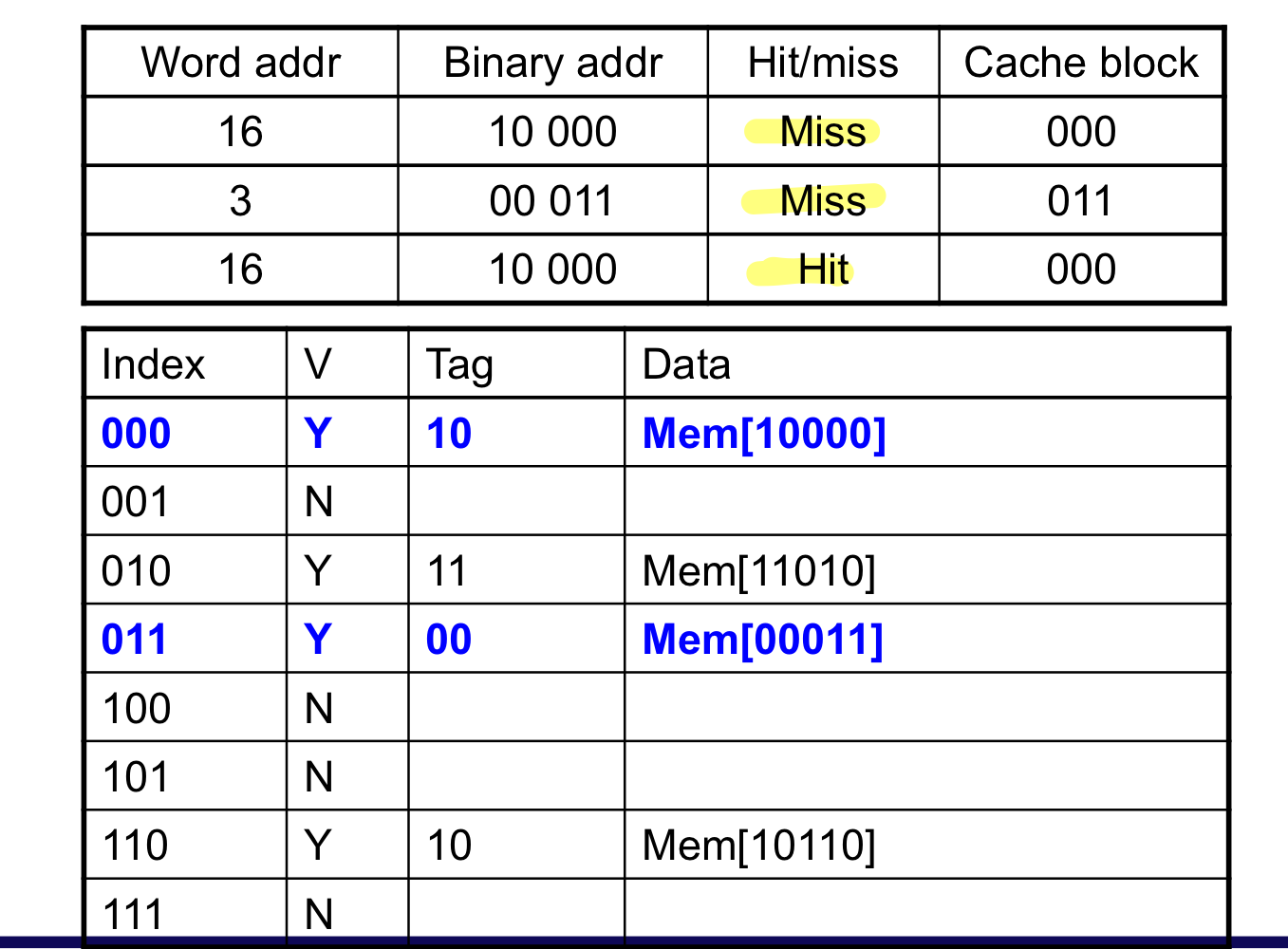
1개는 cache에 존재하고, 2개는 없기에 miss
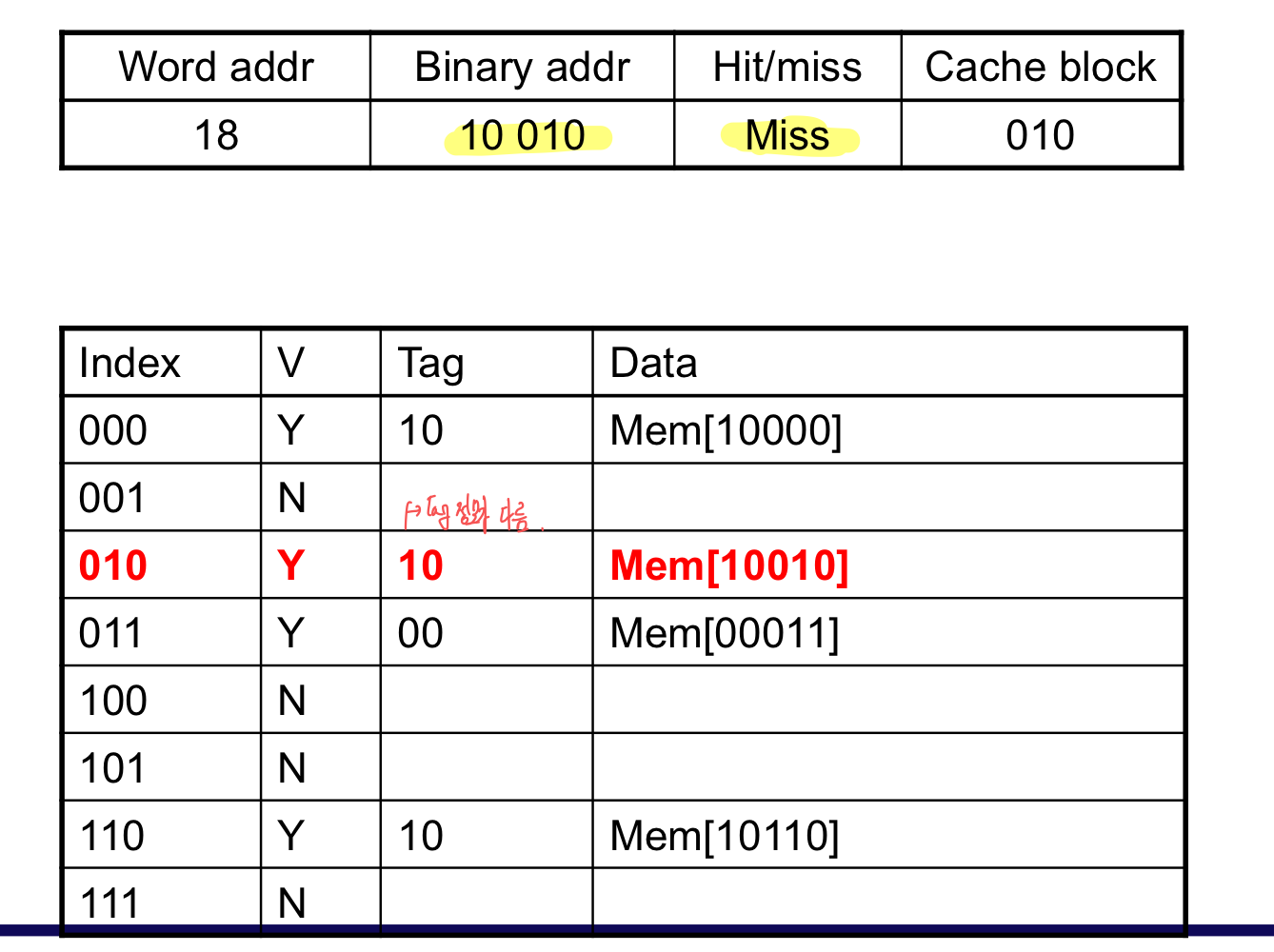
block은 같지만, tag가 다르기에 miss
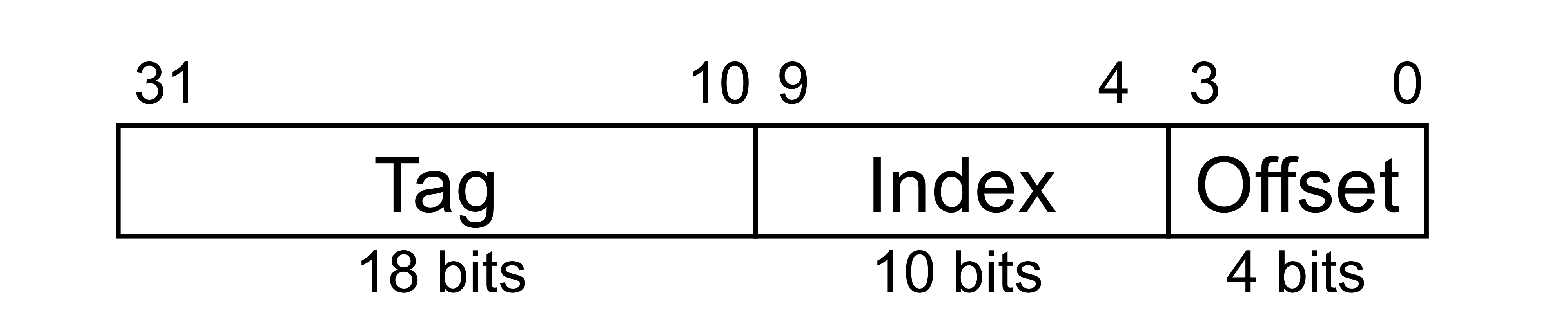
c) Address Subdivision
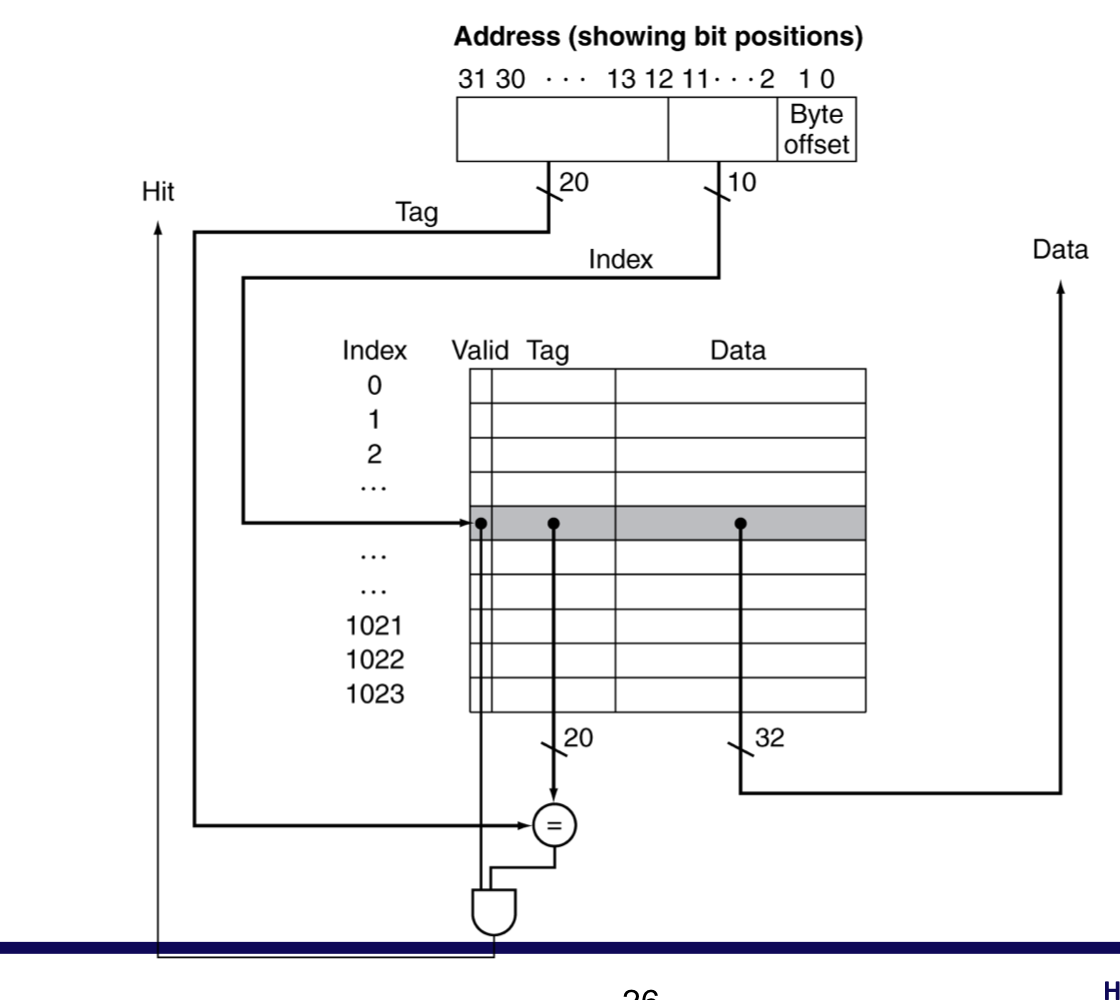
- 1024개를 위한 index는 1024 = 2^10이므로, 10개의 비트
- word 단위로 정렬이 되어 있기에, 하위 2 bit는 무시 할 수 있다.
- 나머지 비트인 상위 20 bit가 tag가 된다.
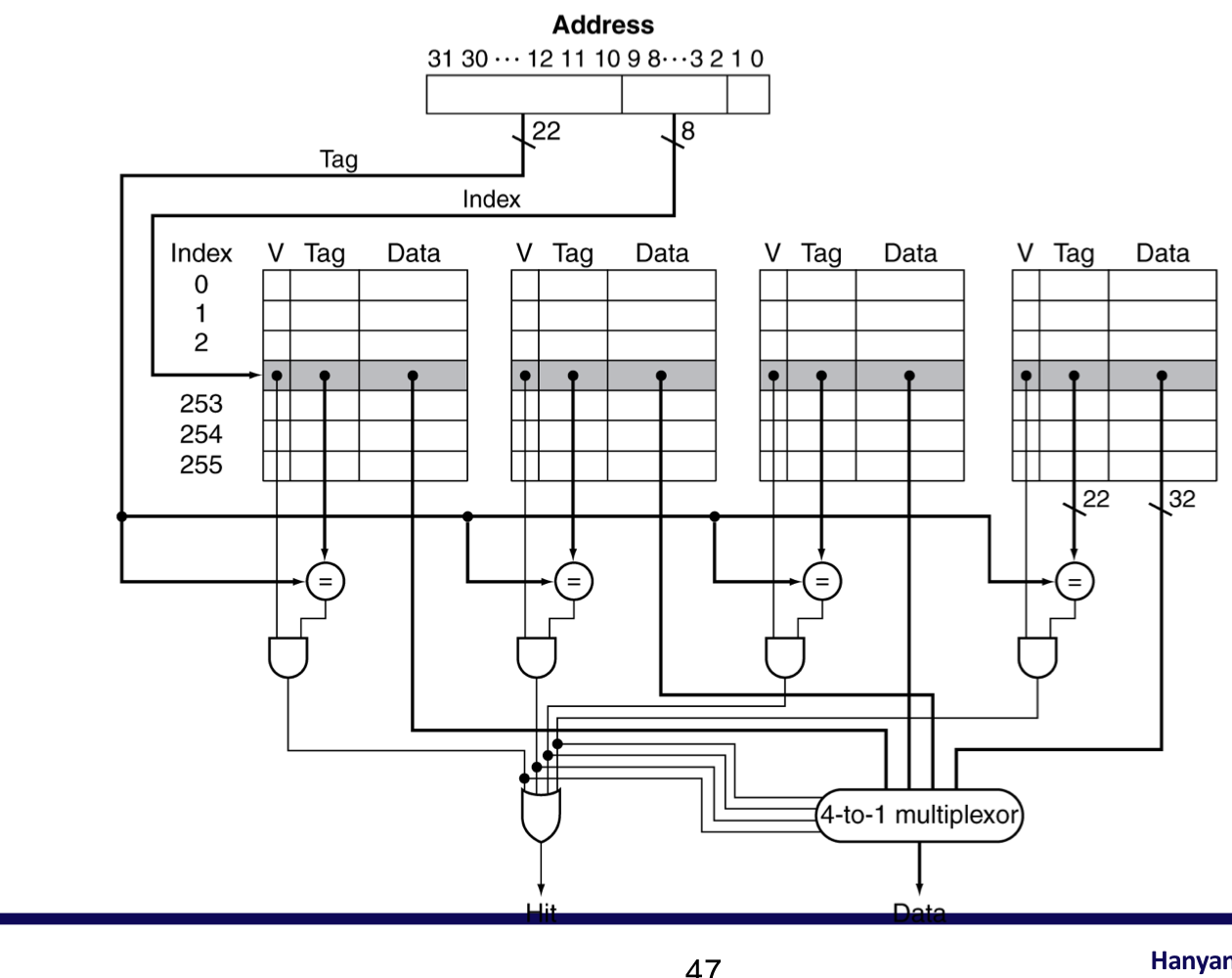
- 즉, cache memory에서 데이터는 32bit이고, index는 10 bit, tag는 20 bit, valid는 1 bit
- and gate를 통해서 valid가 1인지, Tag와 address의 tag가 일치하는지 확인 후 Hit, Miss 결정
- 해당 cache는 teporal locality만 사용한다. 최근 데이터만 사용하기 때문에
d) Example: Larger Block Size
- 64 blocks, 16 bytes/block
- 주소가 1200인 block은 어떤 block number 매핑 되는 가?
- Block address = [1200/16] = 75
- Block number = 75 modulo 64 = 11
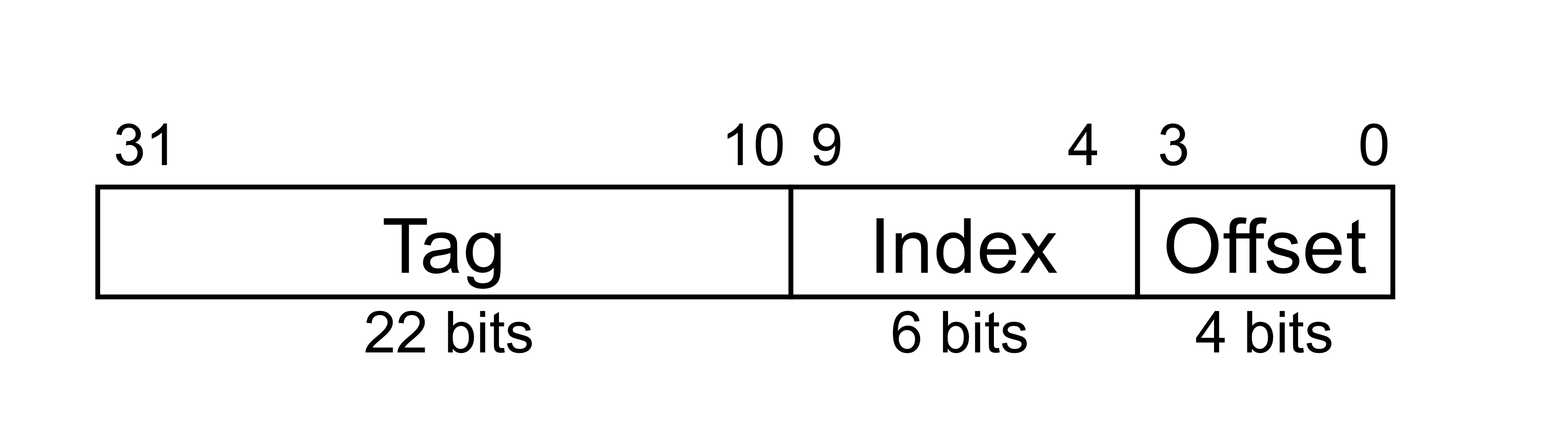
- 16-byte이니까, 최하위 4개의 bit를 offset으로
- 64개의 block이기에 6 bit를 Index로 사용한다.
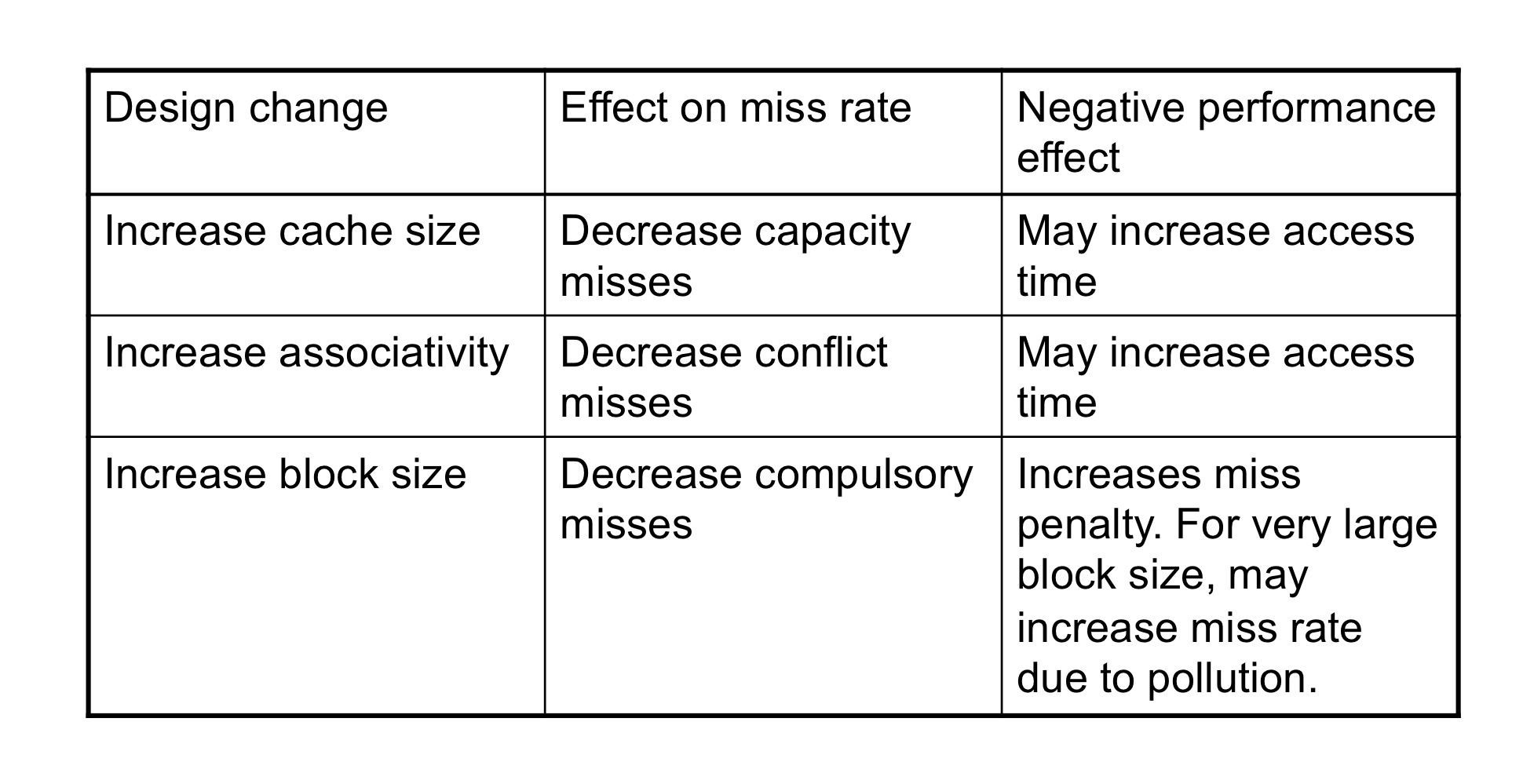
3) Block Size Consideration
- 더 큰 block은 miss rate를 줄인다.
- Due to spatial locality
- 하지만 fixed-sized cache
- Larger blocks → block 개수가 줄어듬
- More competition → increased miss rate
- Larger blocks → pollution
- Larger blocks → block 개수가 줄어듬
- 더 큰 miss penalty
- 줄어든 miss rate의 장점을 상쇄시킬 수 있다.
- “Early restart” and “critical-word-first”가 도와줄 수 있다.
- Early restart → 블록 전체를 기다리지 않고, 블록 내의 요청된 워드가 도달하면 곧바로 실행을 시작하는 것.
- Critical-word-first → 요청한 워드를 먼저 메모리에서 캐시로 전송할 수 있도록 하는 방식
4) Cache Misses
- On cache hit, CPU는 보통처럼 동작한다.
- On cache miss
- CPU pipeline에 stall을 발생시킨다.
- 메모리의 다음 계층에서 해당 block을 fetch 해온다.
- Instruction cache miss인 경우
- instruction fetch가 재시작.
- Data cache miss인 경우
- data access를 완료한다.
5) Write-Through
- data-write hit가 발생하면, cache의 block를 바로 업데이트 할 수 있다.
- 하지만 그렇게 한다면 memory와 cache는 동일한 값을 갖지 않는다.
- Write through: cache와 함께 memory도 업데이트 한다.
- 하지만 그렇게 한다면 write가 더 오래 걸린다.
- e.g., if base CPI = 1, 10% of instructions are stores, 메모리에 write가 100cycles,
- Effective CPI = 1 + 0.1*100 = 11
- e.g., if base CPI = 1, 10% of instructions are stores, 메모리에 write가 100cycles,
- Soultion: write buffer
- 메모리에 쓸 data를 여기서 가지고 있는다.
- CPU는 즉시 계속 진행한다.
- write buffer가 이미 가득 찬 경우에서만 stall이 발생한다.
6) Write-Back
- Alternative: On data-write hit, cache의 block만 업데이트 한다.
- 각 블록이 다른지(dirty) 추적해야 한다. → dirty bit
- dirty block이 제거될 때에
- 그 때에 메모리에 Write it back 해준다.
- 여기에도 write buffer를 사용해서 메모리에 쓰는 것을 CPU가 기다리지 않게 할 수 있다.
7) Write Allocation
- write miss가 발생한다면?
- write-through의 대안
- Allocate on miss: block을 fetch
- Write around: block을 fetch하지 않음
- 캐시에는 write 하지 않고, 메모리만 직접 업데이트
- 어떤 프로그램은 자주 읽기 전에 전체 block을 쓰기 때문이다.
(e.g., initialization)
- For write-back
- 주로 fetch the block
- what if a write miss on a dirty block?
8) Example: Intrinsity FastMATH
- Embedded MIPS processor
- 12-stage pipeline
- 각 cycle마다 instruction과 data 접근.
- Split cache: I-cache와 D-cache가 나누어져 있음.
- 각각 16KB: 256 blocks x 16 words/block
- D-cache: write-through or write-back (OS가 결정)
- SPEC2000 miss rates
- I-cache: 0.4%
- 해당 접근은 매 cycle마다 이루어짐.
- D-cache: 11.4%
- 해당 접근은 Instruction에 비해서는 확연히 적음
- Weighted average: 3.24% (unified cache: 3.18%)
- 그래서 접근 빈도를 고려햐여 miss비율을 계산하면 확연히 적음
- I-cache: 0.4%
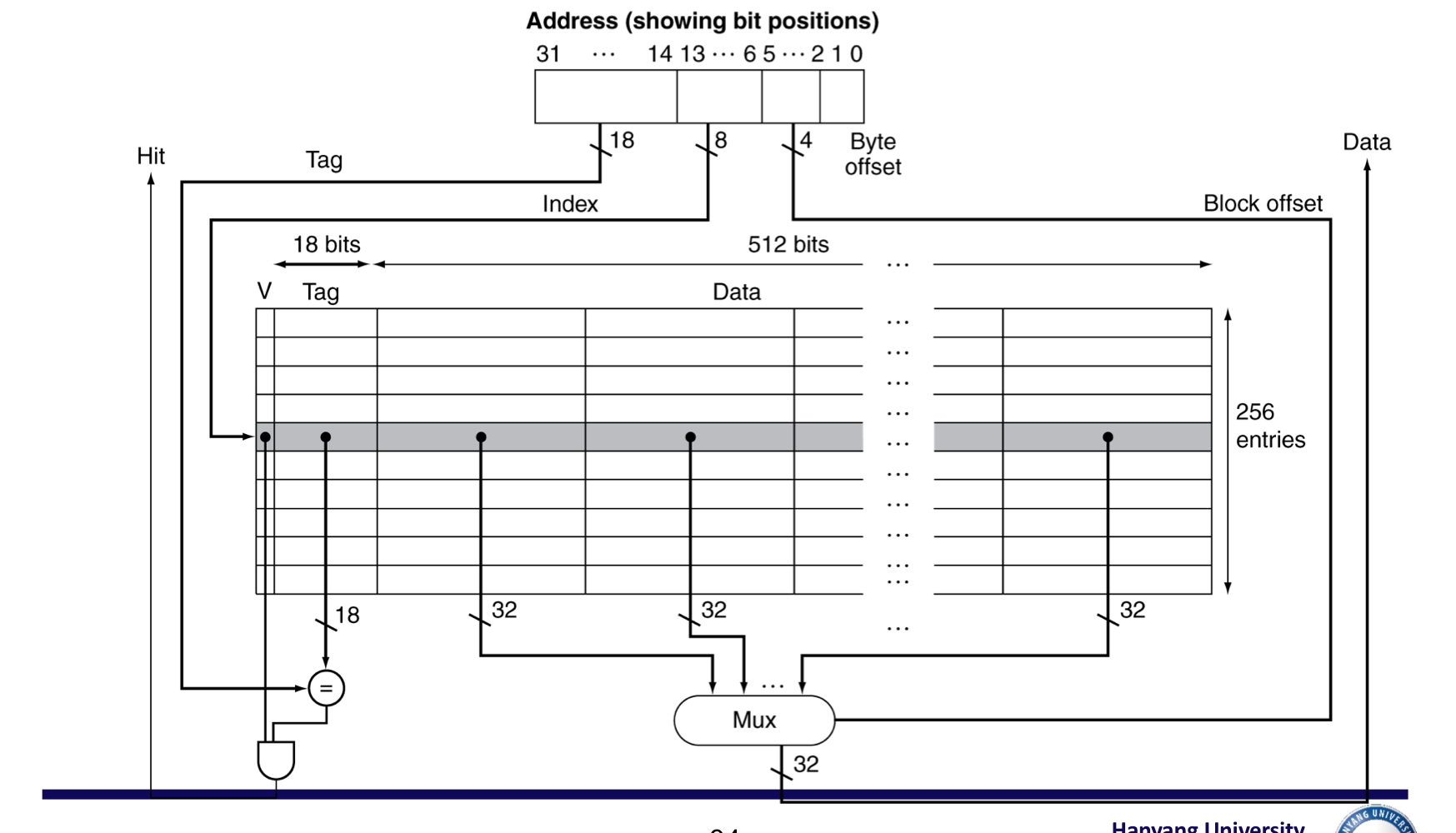
- 각 block 당 16개의 word가 있으므로 어떤 것을 선택할 지 4개의 bit 사용
- 총 블록이 256개이므로 index에 8개의 bit 사용
9) Main Memory Supporting Caches
- main memory를 위해서 DRAMs 사용
- Fixed width (e.g., 1 word)
- fixed-width clocked bus와 연결 됨.
- Bus clock은 전형적으로 CPU clock보다 느리다.
- Example cache block read
- 1 bus cycle for address transfer
- 15 bus cycles per DRAM access
- 1 bus cycle per data transfer
- 4-word block에 대하여, 1-word-wide DRAM
- Miss penalty = 1 + 4x15 + 4x1 = 65 bus cycles
- Bandwidth = 16 bytes / 65 cycles = 0.25 B/cycle
4. Measuring and Improving Cache Performance
1) Measuring Cache Performance
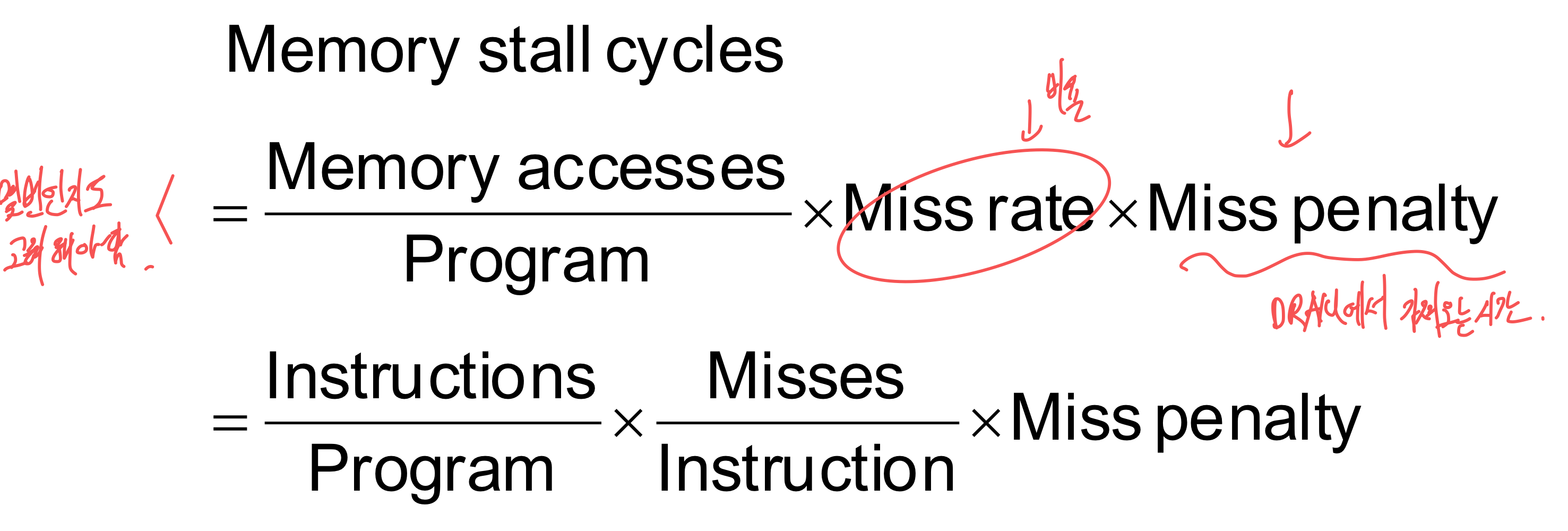
- CPU time (cycle과 clock time)
- (Execution cycles + Memory stall cycles) * Clock cycle time
- Components of CPU time
- Program execution cycles
- Includes cache hit time
- Memory stall cycles
- 주로 cache miss
- Program execution cycles
- With simplifying assumptions:
a) Cache Performance Exmaple
- Given
- I-cache miss rate = 2%
- D-cache miss rate = 4%
- Miss penalty = 100 cycles
- Base CIP (ideal cache) = 2
- Load & stores are 36% of instructions
- instrution당 Miss cycles
- I-cache: 0.02 * 100 = 2
- D-cache: 0.36 0.04 100 = 1.44
- Actual CPI = 2 + (2 + 1.44) = 5.44
- Ideal CPU is 5.44/2 = 2.72 times faster
2) Average Access Time
- Hit time도 performance에 중요하다.
- Average memory access time (AMAT)
- AMAT = Hit time + Miss rate * miss penalty
- Example
- CPU with 1ns clock, hit time = 1 cycle, miss penalty = 20 cycles, I-cache miss rate = 5%
- AMAT = 1 + 0.05 * 20 = 2ns
- 2 cycles per instruction
3) Performance Summary
- CPU 성능이 향상되면,
- miss penalty가 점점 더 중요해진다.
- 더 많은 비중을 차지하게 된다.
- 총 시간 중에 프로세서에게 소모되는 시간이 줄어들기에 “메모리에서 소요되는 시간”이 더 많이 차지한다.
- Decreasing base CPI
- 총 시간 중에, 메모리 stall에 소요되는 시간의 비중이 더 크다.
- Increasing clock rate
- 메모리 stall에 걸리는 CPU cycle이 더 많아진다.
- 시스템 성능을 평가할 때, cache behavior을 무시 할 수 없다.
4) Associative Caches
- n-way set associative
- 각 set은 n개의 entries
- Block number는 어떤 set에 매핑되는지 결정한다.
- (Block number) modulo (#Sets in cache)
- 해당 set의 entries들을 한번에 검색해야한다.
- n개의 comparators (fully보다는 비용이 적다.)
- Fully associative
- block이 cahce어디에서나 들어갈 수 있다.
- 모든 entry를 한번에(즉시 동시에) 검색해야 한다.
- entry마다 comparator가 필요하다. (expensive)
a) Associative Cache Example
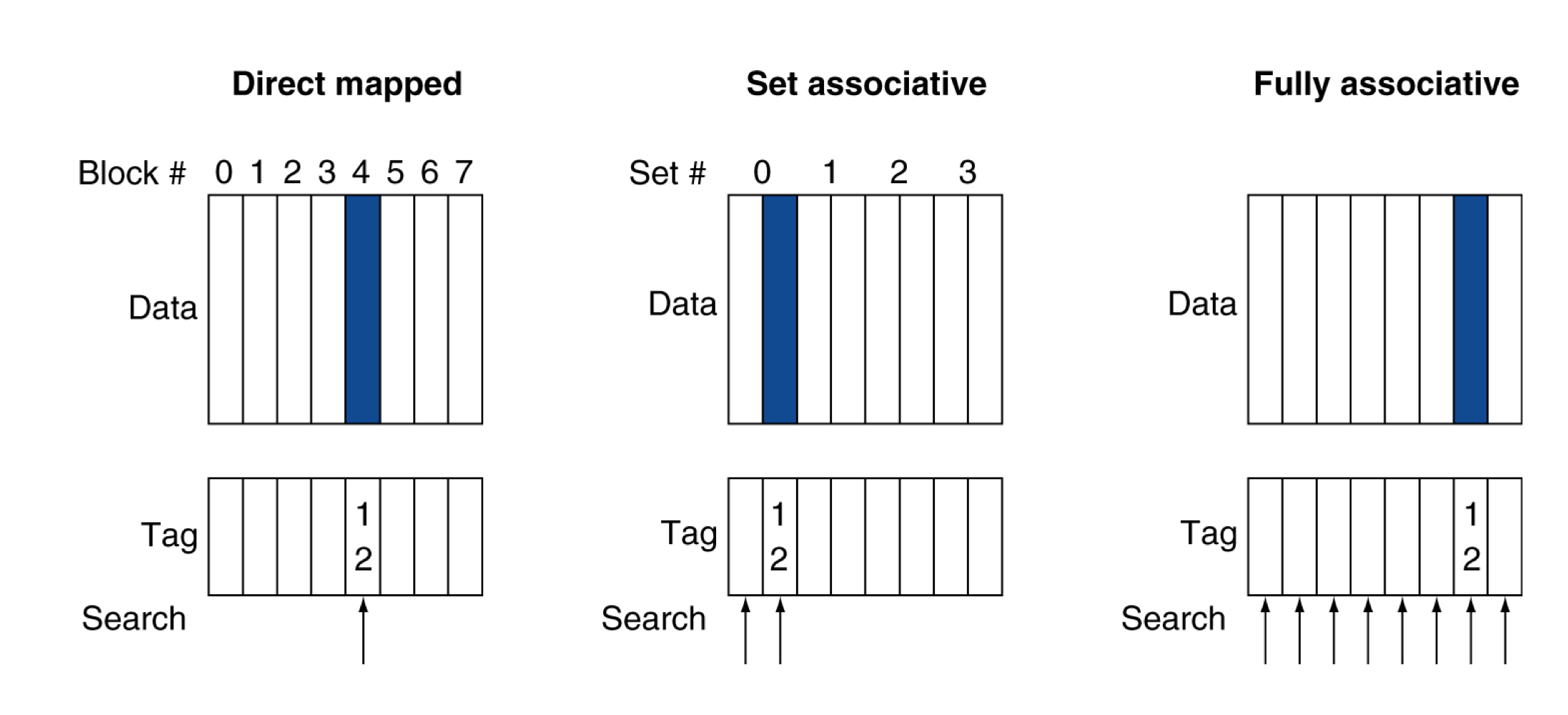
Fully associative는 set이 1개나 다름없다.
b) Spectrum of Associativity
- 8개의 entry를 가진 cache
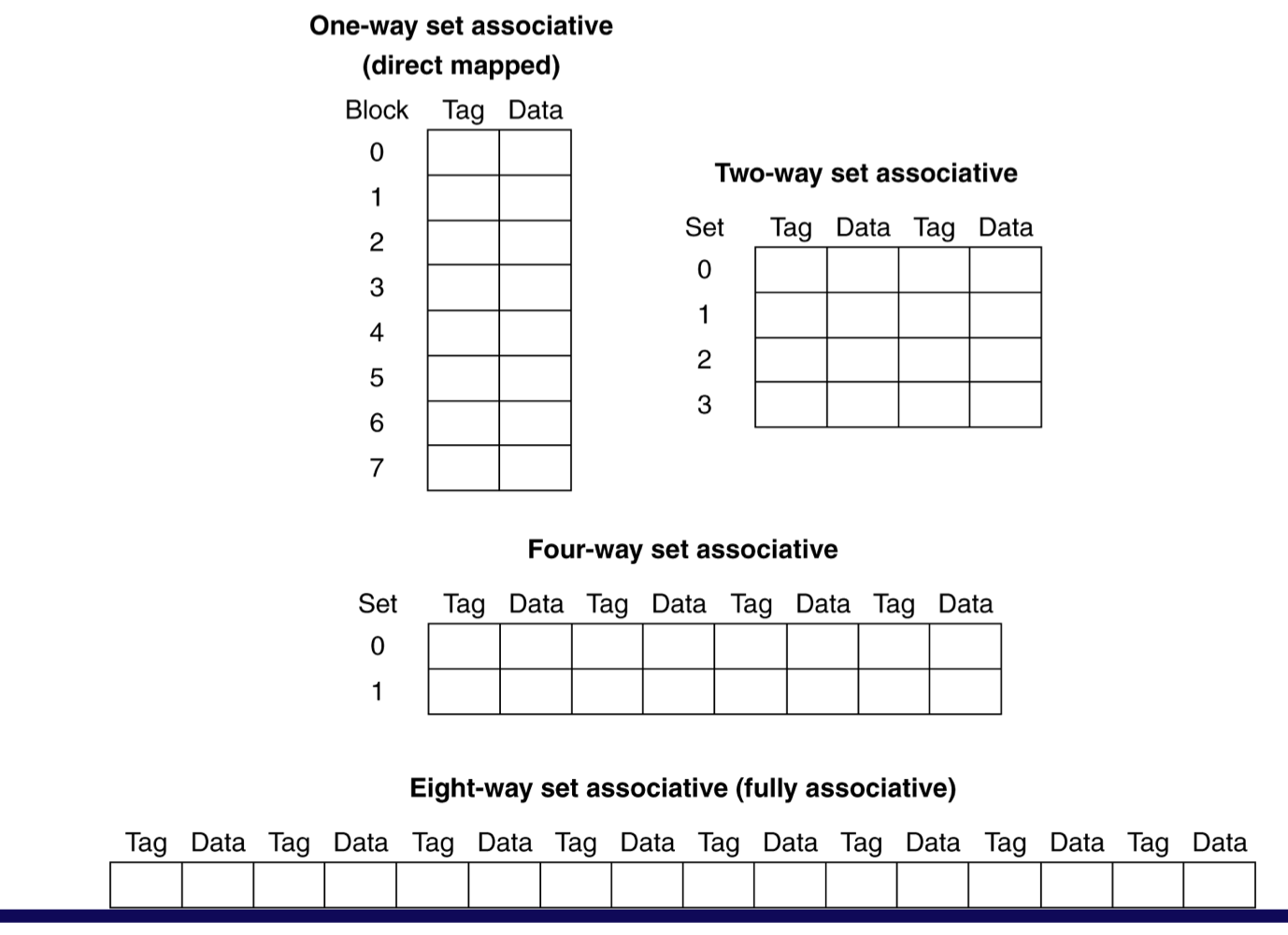
c) Associativity Example
- 4-block의 caches를 비교
- Direct mapped, 2-way set associative, fully associative
- Block address sequence: 0, 8, 0 , 6, 8
- Direct mapped
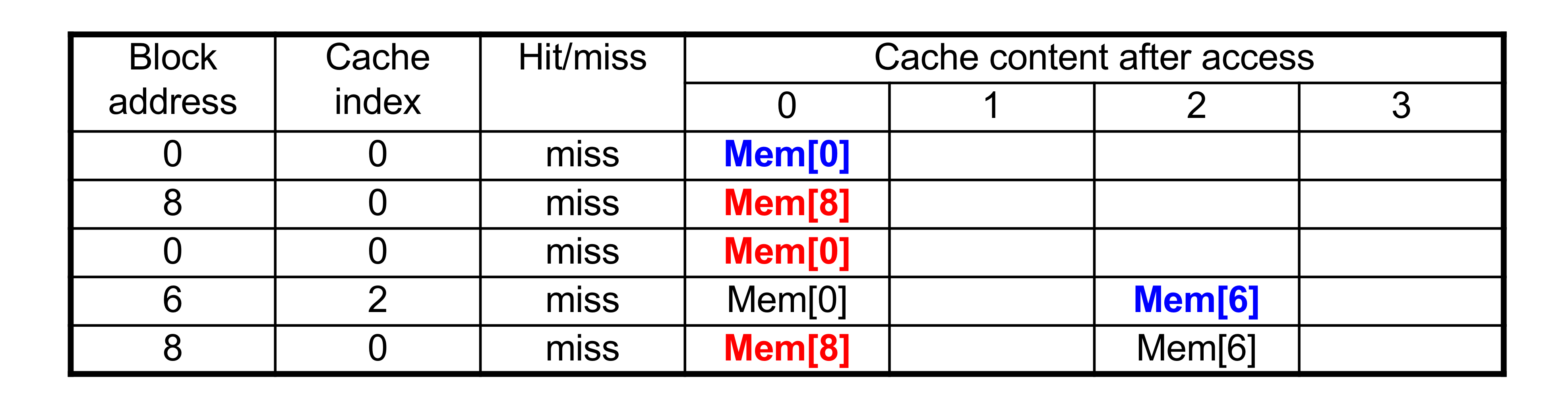
5번의 access에 5번의 miss
- 2-way set associative
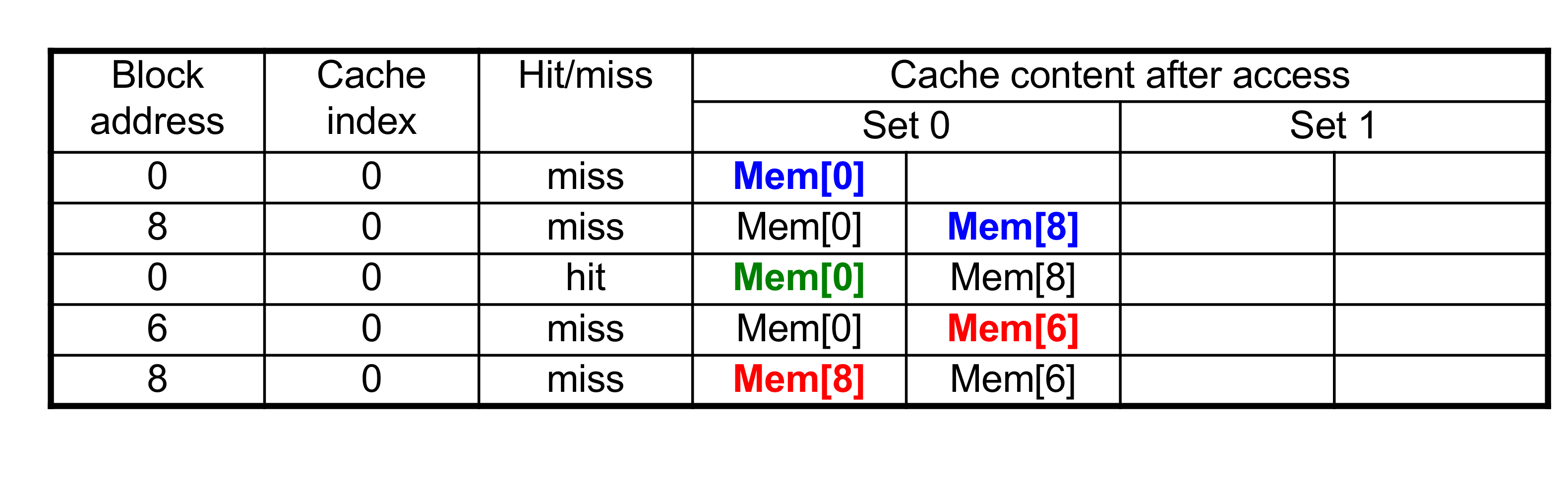 5번의 access에 4번의 miss, 1번의 hit
5번의 access에 4번의 miss, 1번의 hit
- Fully associative
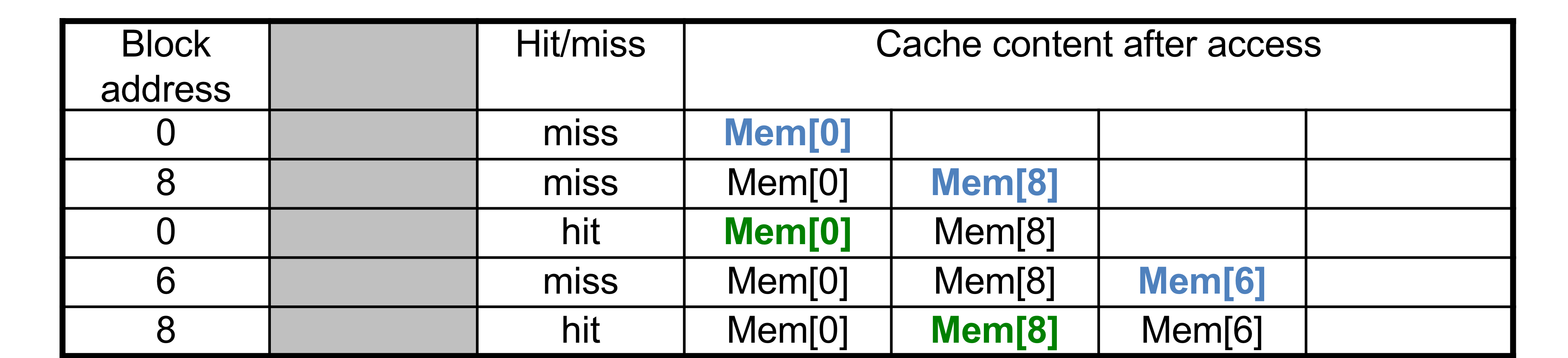
5번의 access에 3번의 miss, 2번의 hit
d) How Much Associativity
- associativity를 증사키리 수록 miss rate는 낮아진다.
- 하지만 점차 그 효과는 낮아진다. (효율)
- 16-word blocks의 64KB D-cache를 SPEC2000으로 시뮬레이션 한 결과
- 1-way: 10.3%
- 2-way: 8.6%
- 4-way: 8.3%
- 8-way: 8.1%
4-way set associative cache
5) Replacement Policy
- Direct mapped: no choice (그냥 무조건 교체)
- Set associative
- non-valid인 entry가 있다면, 선호한다.
- 그 다음으로는 두가지 방법 중 선택
- Least-recently used (LRU)
- 가장 오랫동안 안 쓴 것을 고른다.
- 2-way, 4-way에서는 할만 하지만, 그 이상은 어렵다.
- 가장 오랫동안 안 쓴 것을 고른다.
- Random
- high associativity에서는 LRU와 거의 유사한 성능 수준을 보여준다.
6) Multilevel Caches
- Primary cache는 CPU와 붙어 있다.
- Level-2 cache는 primary cache miss가 발생 했을 때에만 접근한다.
- L1보다 크고 느리지만, main memory에 비해서는 빠르다.
- Main memory는 L-2 cache miss가 발생 되었을 때에 동작한다.
- 최근의 고성능 시스템은 L-3 cache도 갖는다.
a) Multilevel Cache Example
- Given
- CPU base CPI = 1, clock rate = 4GHz
- Miss rate/instruction = 2%
- Main memory access time = 100ns
- primary cache만 사용 했을 때
- Miss penalty = 100ns/0.25ns = 400 cycles
- Effective CPI = 1 + 0.02 * 400 = 9
- L-2 cache를 추가 했을 때
- Access time = 5ns
- global miss rate to main memory = 0.5%
- Primary miss with L-2 hit
- Penalty = 5ns/0.25ns = 20 cycles
- Primary miss with L-2 miss
- Extra penalty = 400 cycles
- CPI = 1 + 0.02 20 + 0.005 400 = 3.4
- Performance ratio = 9/3.4 = 2.6
- L-2 cache를 사용하는 것은 2.6배의 속도 향상이다.
7) Multilevel Cache Considerations
- Primary cache
- hit time을 줄이는 것에 초점을 둔다.
- L-2 cache
- miss rate를 줄여서 메인메모리에 access하는 것을 줄이는 것에 초점을 둔다.
- hit time은 전체 성능에 큰 영향이 없다.
- 결과
- L-1 cache는 single cache보다 보통 작다.
- L-2 cache는 L-1 cahce보다 더 큰 set associativity를 사용한다.
- L-1 block size는 L-2 block size보다 더 작다.
8) Interactions with Advances CPUs
- Out-of-order CPUs는 cache miss동안에도 instruction들을 실행할 수 있다.
- 보류된 stor동작은 load/store unit에서 머무른다.
- miss에 의존적인 instruction들은 reservation stations에서 기다린다.
- Independent instructions continue
- miss의 효과는 프로그램의 data flow에 의존적이다.
- Much harder to analyze
- Use system simulations
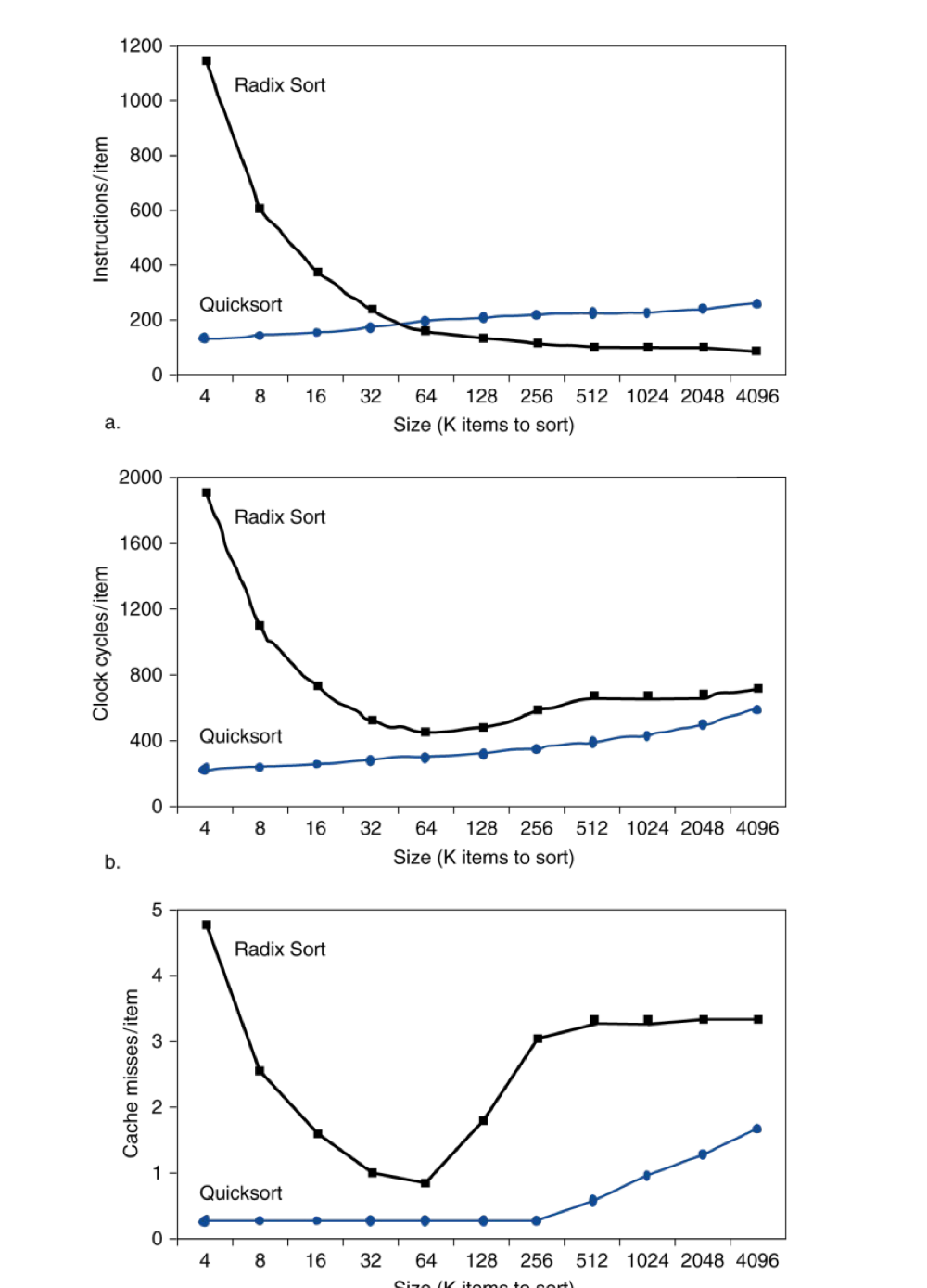
9) Interactions with Software
- Misses는 memory access patterns에 의존적이다.
- algorithm behavior
- Compiler는 메모리 접근을 최적화 한다.
- 이미 효율적인 access를 하는 Quick sort와는 다르게 Radix Sort에서는 컴파일러의 최적화로 더 많은 데이터를 정렬할 때 miss 빈도가 감소하기도 한다.
10) Software Optimization via Blocking
- 목표: replace되기 전에 데이터에 대한 접근을 최대화 한다.
- Consider inner loops of DGEMM:

a) DGEMM Access Pattern
- C, A, and B arrays
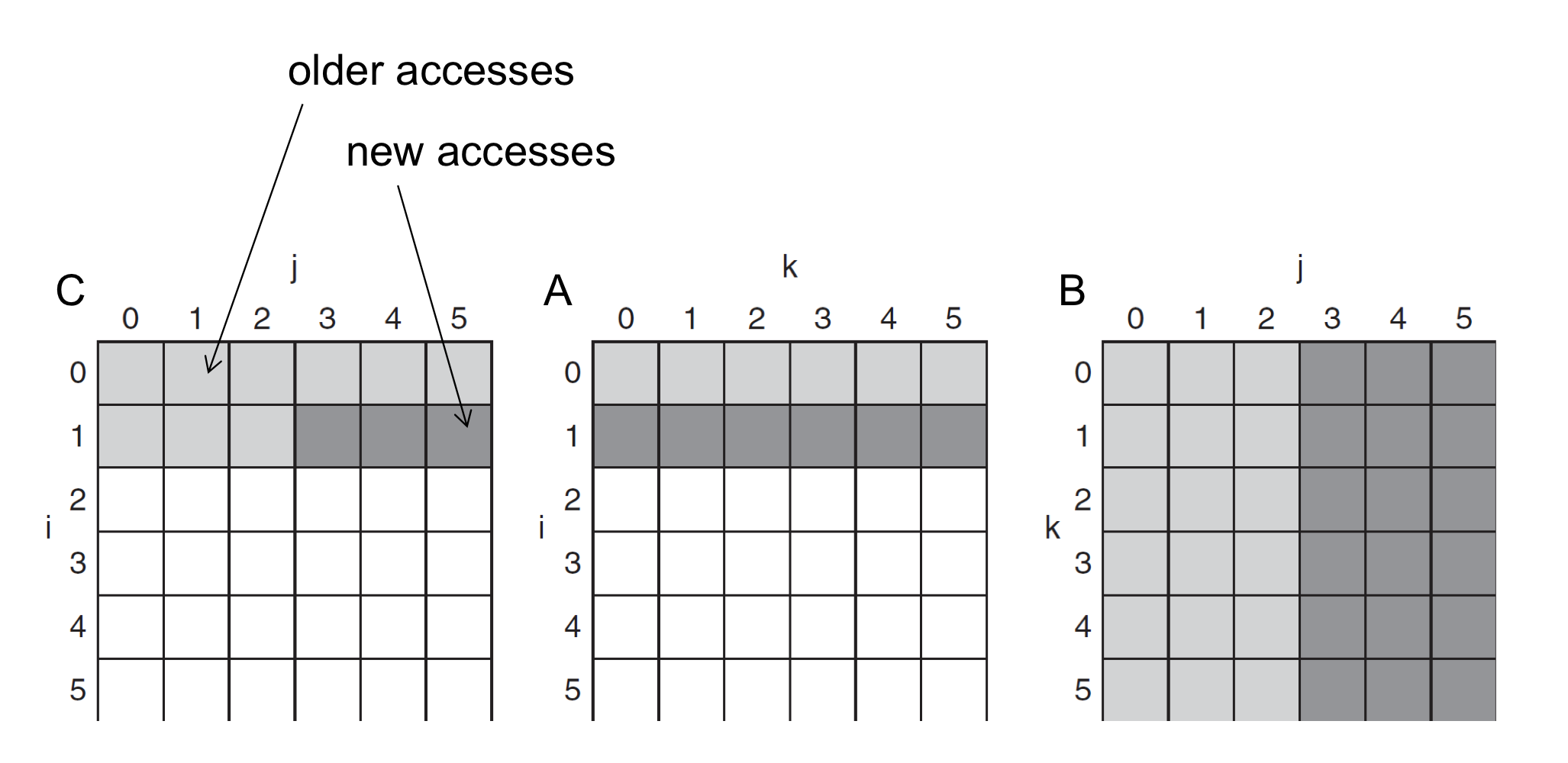
- 행렬의 element가 늘어날 수록 cache miss 비율이 커진다
- cache에 남아 있어야 빨리 데이터를 fetch할 수 있기 때문에.
b) Cache Blocked DGEMM

c) Blocked DGEMM Access Pattern
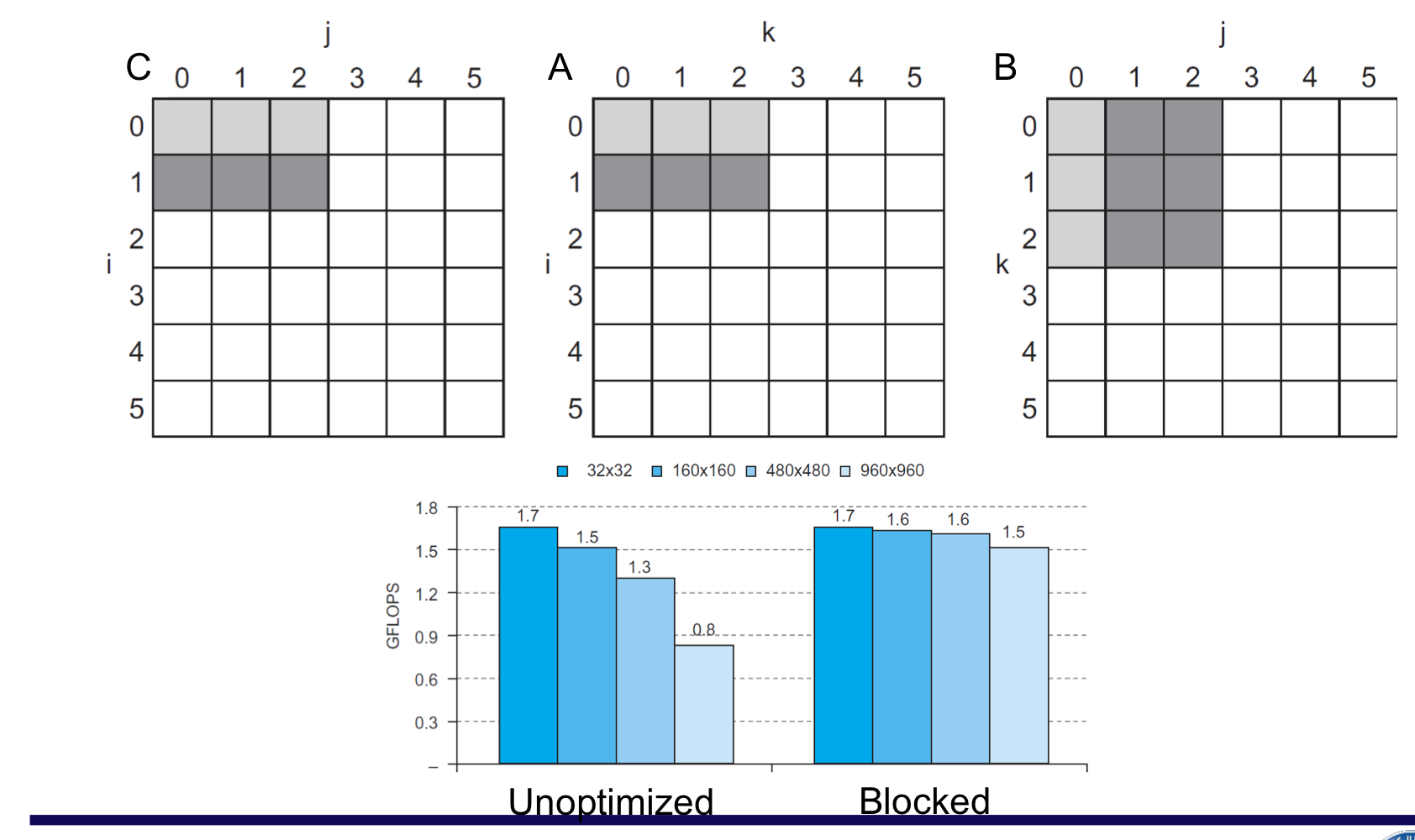
5. Virtual Machines
1) Virtual Machines
2) Virtual Machines Monitor
3) Example: Timer Virtualization
4) Instruction Set Support
6. Virtual Memory
1) Virtual Memory
- Main memory를 secondary(disk) storage의 “cache”로써 사용한다.
- CPU와 OS가 공동으로 관리한다.
- Programs share main memory
- 각 프로그램들은 private한 virtual address space를 갖게 되며, 자주 사용하는 code와 data를 여기에 두고 사용한다.
- 이 private한 영역은 다른 프로그램으로부터 보호된다.
- CPU와 OS는 virtual address를 physical addresses로 번역한다.
- VM “block” is called a page
- VM translation “miss” is called a page falut
2) Address Translation
- Fixed-size pages (e.g., 4K)
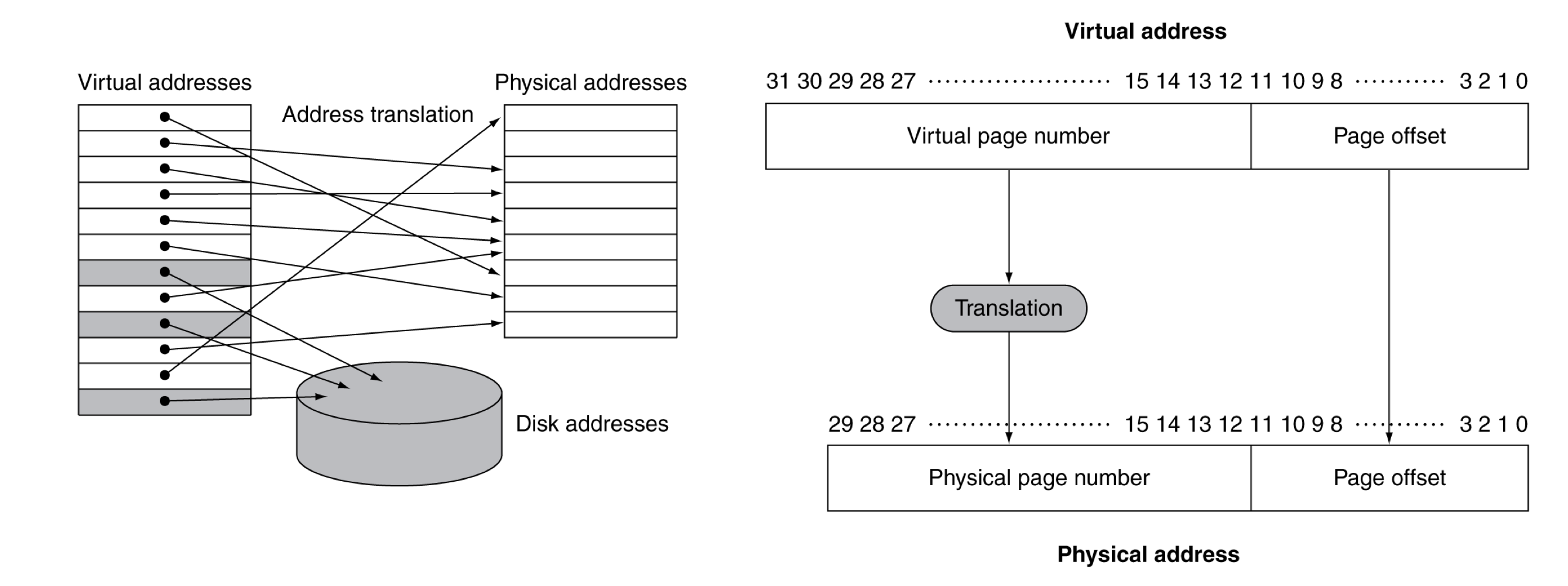
3) Page Fault Penalty
- Page fault가 일어나면 page를 반드시 disk로 부터 fetch해와야 한다.
- 수백만의 clock cycle이 소요된다.
- OS code에 의해 처리된다.
- page fault rate를 최소화하기 위한 노력
- Fully associative placement
- Smart replacement algorithms
4) Page Tables
- placement 정보를 가지고 있음
- page table entry들이 배열로 되어 있고, virtual page number로 색인화 되어 있다.
- 개수가 너무 많기에 빨리 찾기 위해 index 구조
- CPU에 있는 Page table register가 page table이 존재하는 physical memory영역을 가리킨다.
- page table entry들이 배열로 되어 있고, virtual page number로 색인화 되어 있다.
- page가 메모리에 있다면,
- PTE(page table entry)가 physical page number을 갖고 있다.
- 그 와 다른 상태 정보들도 비트로 갖는다. (referenced, dirty, …)
- page가 메모리에 없다면,
- PTE는 Disk에 있는 swap space 정보를 가리키게 된다.
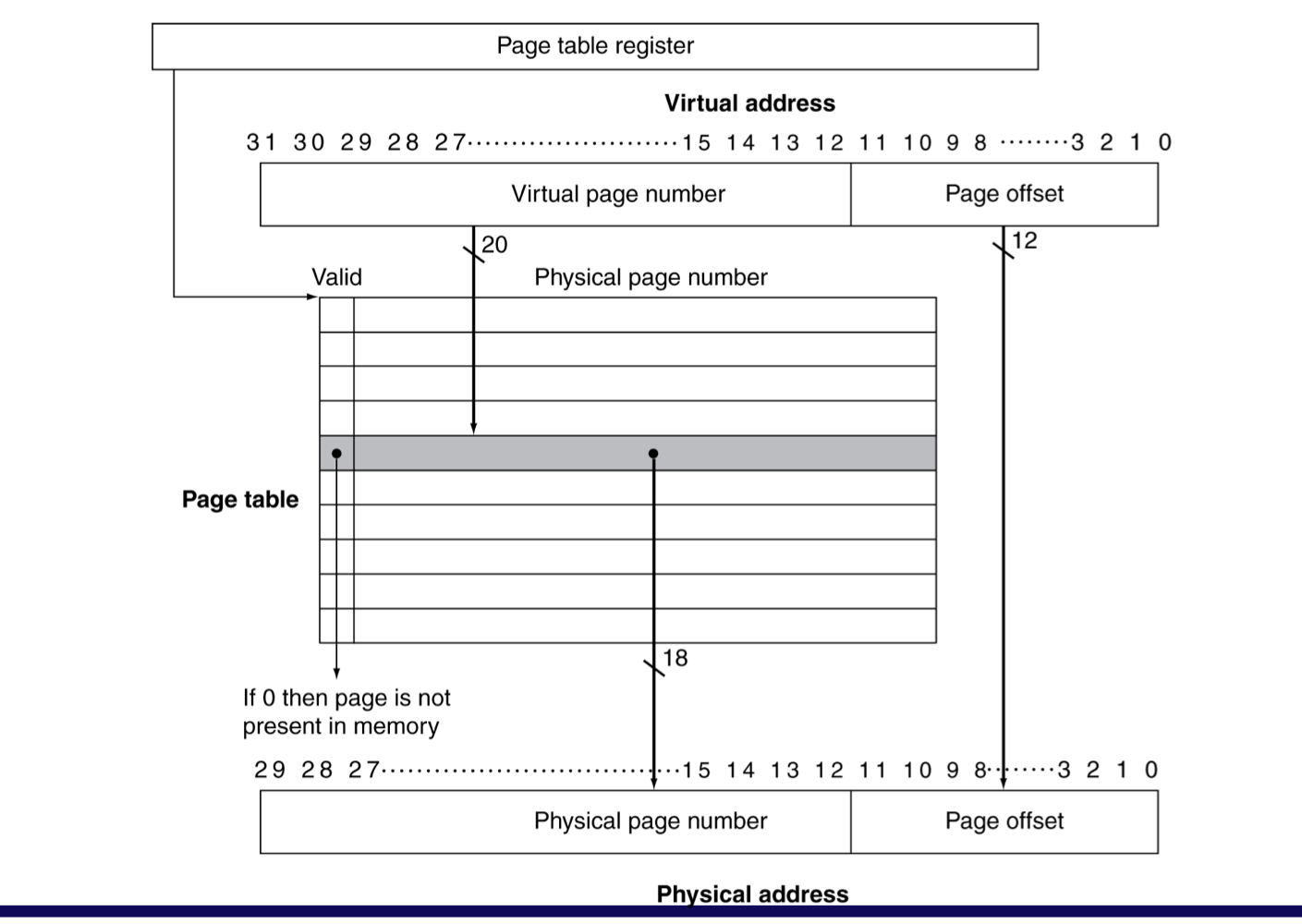
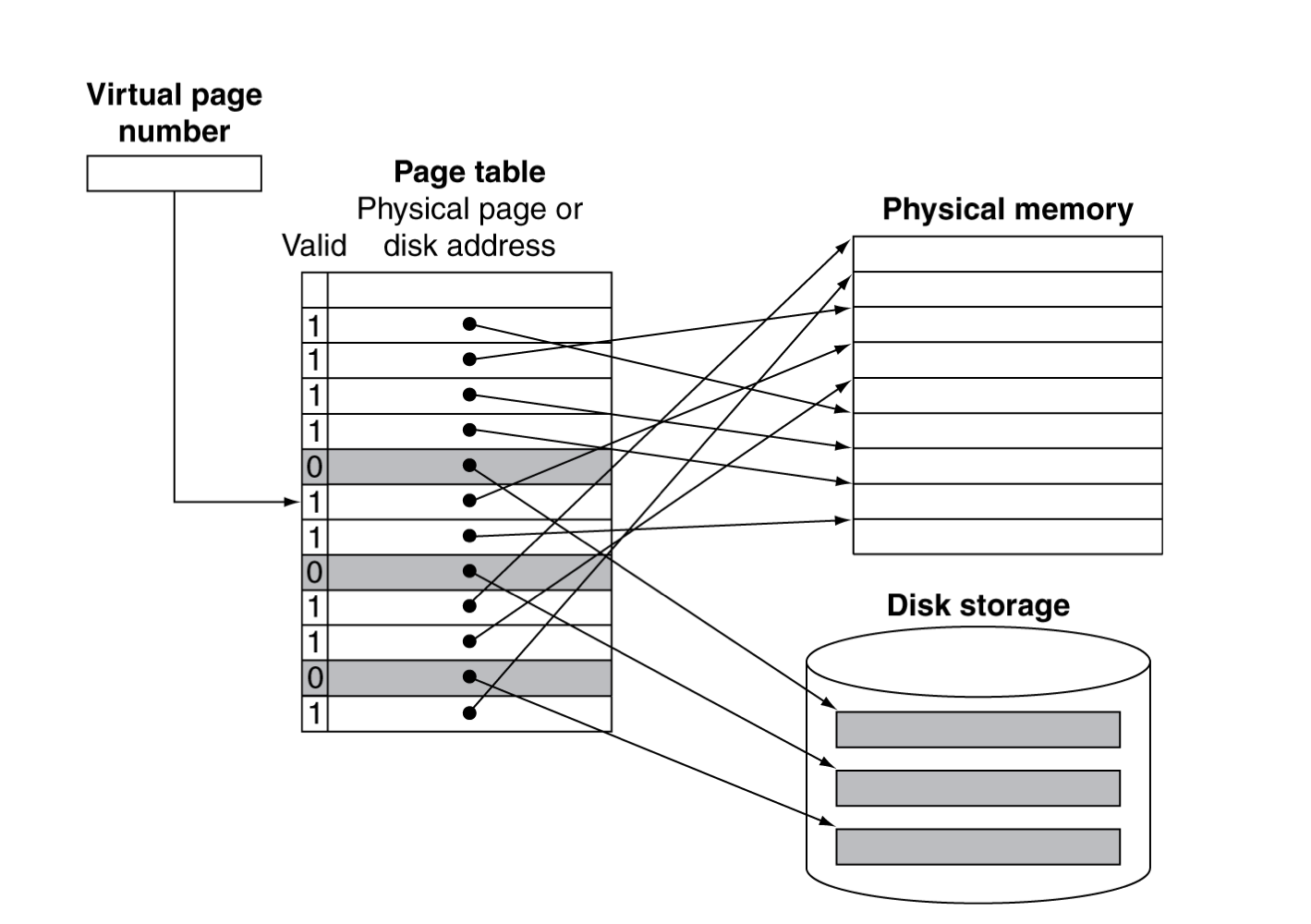
valid가 1이라는 것은 메인 메모리, 0이라면 disk
5) Replacement and Writes
- page fault rate를 줄이기 위해서 LRU 알고리즘이 선호된다.
- page에 접근할 때, Reference bit (aka use bit) in PTE set to 1
- OS는 주기적으로 0으로 초기화 시킨다.
- 즉, page reference bit가 0이라는 것은, 최근에 사용되지 않았다는 것.
- Disk write는 수백만 cycle이 소요된다.
- 한번에 block단위로, 개별적인 byte로 이루어지지 않는다.
- 캐시와 메모리를 함께 업데이트 하는 write-through방식은 비효율 적이다.
- Use write-back
- page가 업데이트 된 것을 알기 위해서 PTE에 dirty bit를 두고 표시한다.
6) Fast Translation Using a TLB
- 원래라면 address translation은 추가적인 memory reference를 필요로 한다. (page table도 메모리에 있기에)
- One to access the PTE
- 실제로 memory access할 때,
- 하지만 page table로의 access는 good locality를 가진다.
- 그래서 PTE를 위한 빠른 cache를 CPU에 두고 사용한다.
- Translation look-aside Buffer (TLB)
- Typical: 16-512 PTEs, 0.5-1 cycle for hit, 10-100 cycles for miss, 0.01%-1% miss rate
- miss는 하드웨어와 소프트웨어에 의해 처리된다.
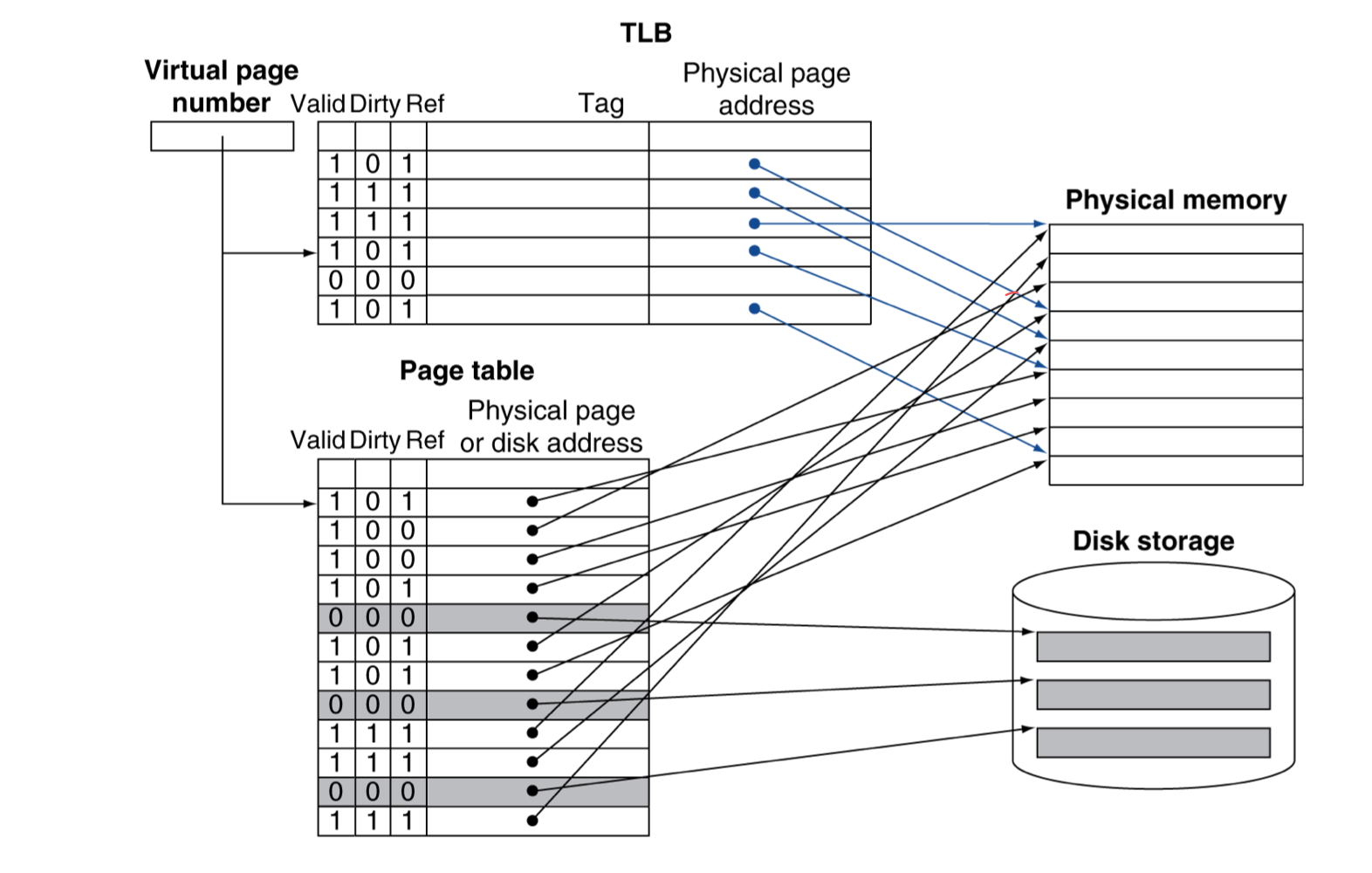
a) TLB Misses
- 만약 page가 메모리에 있다면,
- page table에 가서 PTE를 받아와서 다시 시도한다.
- hardware에서 처리할 수도 있다.
- 그러려면 page table의 구조가 더 복잡해 지고, 하드웨어 또한 복잡해 진다.
- software가 처리한다면,
- 특별한 exception을 발생시키고, optimized handler로 처리한다.
- 만약 page가 memory에 없다면, (page fault)
- OS가 처리하며, disk로부터 page를 fetch하고, page table을 업데이트 한다.
- 그러고는 fault가 발생했던 instruction을 재시작한다.
b) TLB Miss Handler
- TLB miss indicates
- page는 존재하지만, PTE not in TLB
- page가 메인메모리에 존재하지 않는 것
- 대상 레지스터에 overwrite가 일어나기 전에 TLB miss임을 알아차려야 한다.
- Raise exception
- Handler는 page table로부터 PTE를 TLB로 복사해온다.
- 그리고는 Instruction을 재시작한다.
- 만약 page가 실제로 없다면, page fault가 발생한다.
c) Page Fault Handler
- page table의 PTE를 찾기 위한 virtual address가 잘못 되었을 때,
- main memory의 page를 찾으려고 해도 없을 경우
- disk의 swap space에 page를 할당시킨다.
- 교체할 page를 고른다.
- 만약 dirty가 있다면, 이를 disk에 먼저 쓴다.
- page를 메모리로 가져와서 page table을 업데이트 한다.
- 프로세스를 다시 실행가능한 상태로 만든다.
- 실패한 instruction을 재시작한다.
d) TLB and Cache Interaction
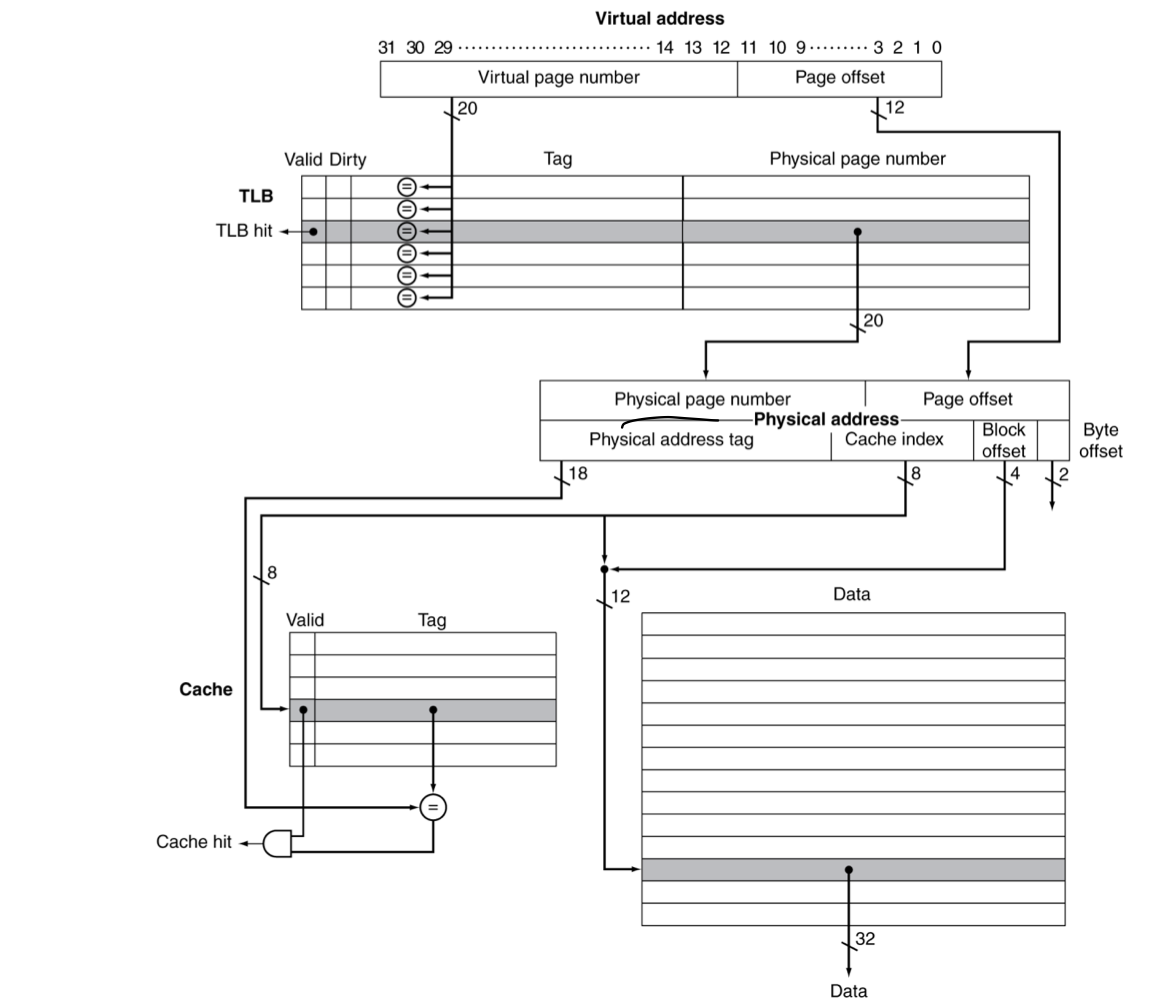
- 이전에 배운대로 physical address를 cache tag로 사용한다면,
- cache를 훓기 전에 translate가 필요하다.
- 다른 방식은 virtual address tag를 사용한다.
- TLB는 critical path 바깥에 있을 수 있다.
- aliasing때문에 복잡해진다,
- 다른 virtual address가 같은 shared physical address를 가르키는 것.
- Virtually indexed but physically tagged
7) Memory Protection
- 다른 작업은 각각 고유의 virtual address space를 사용한다.
- 하지만, 다른 작업이 같은 영역 일부를 공유할 수 있다.
- 이러한 잘못된 접근에 대해서 보호할 필요가 있다.
- OS의 도움
- Hardware는 OS protection을 지원한다.
- privileged supervisor mode (aka kernel mode)
- privileged instructions
- Page table과 기타 정보들은 오직 supervisor mode에서 접근 가능
- System call exception (e.g., syscall in MIPS)
- OS는 하나의 프로세스를 다른 것으로 바꿀 것으로 결정한다.
- Context swith는 TLB flushs를 필요로한다.
- 대체로 adding task identifiers
7. A Common Framework for Memory Hierarchy
1) The Memory Hierarchy
- common principle이 메모리 계층의 모든 단계에 적용된다.
- caching의 개념에 의거하여서
- 각 레벨의 hierarchy에서
- block placement
- Finding a block
- Replacement on a miss
- Write policy
2) Block Placement
- associativity에 따라서
- Direct mapped (1-way associative)
- placement에 오직 한가지 선택.
- n-way set associative
- set에 n개의 선택지
- Fully associative
- 어떤 부분이든 가능하다. 하나의 set 뿐이고, 해당 set에 모든 block이 들어가 있기 때문에.
- Direct mapped (1-way associative)
- associativity가 높을 수록 miss rate가 감소한다.
- 하지만 복잡성, 비용, 접근 시간이 증가한다.
3) Finding a Block

- Hardware caches
- 비용을 줄이기 위해서, comparison의 수를 줄였다.
- Virtual memory
- full lookup table이 full associativity를 가능하게 해준다.
- miss rate를 줄여서 이득을 보기 위해.
4) Replacement
- miss 발생 시, 교체할 entry를 선택하는 방법
- Least Recently Used (LRU)
- high associativity에서는 복잡하고, 비용이 증가한다.
- Random
- LRU에 근접하고, 구현하기 쉽다.
- Least Recently Used (LRU)
- Virtual memory
- 하드웨어의 도움으로 대락적으로 LRU를 구현한다.
- Hardware cache와 달리 LRU를 감당 할 수 있을 정도로 느리게 동작하기 때문이다.
- 하드웨어의 도움으로 대락적으로 LRU를 구현한다.
5) Write Policy
- Wirte-through
- upper level과 lower level을 함께 업데이트 한다.
- replacement를 간단하게 만들어주지만, write buffer을 필요로한다.
- Write-back
- 현재 upper level만 업데이트 한다.
- 업데이트 된 block이 교체 될 때, lower level에 업데이트 해야한다.
- 더 많은 상태를 유지해야한다.
- 상태 bit추가? (dirty bit)
- Virtual memory
- 오직 write-back만 가능하다. disk write latency 때문에.
6) Sources of Misses
- Compulsory misses (aka cold start misses)
- block에 처음 접근할 때,
- 처음에는 데이터가 없기에 모두 miss 발생한다.
- block에 처음 접근할 때,
- Capacty miss
- 유한한 cache size 때문에,
- cache 공간이 부족하기 때문에 행렬 곱에서 blocked cache 사용함.
- 교체된 블럭이 나중에 다시 접근되었을 때,
- 유한한 cache size 때문에,
- Conflict misses(aka collision misses)
- non-fully associative cache에서 발생한다.
- set에서의 entry끼리 경쟁으로 발생한다.
- 전체 크기와 같은 fully associative cache에서는 발생하지 않는다??
7) Cache Design Trade-offs
8. Using a Finite-State Machine to Control a Simple Cache
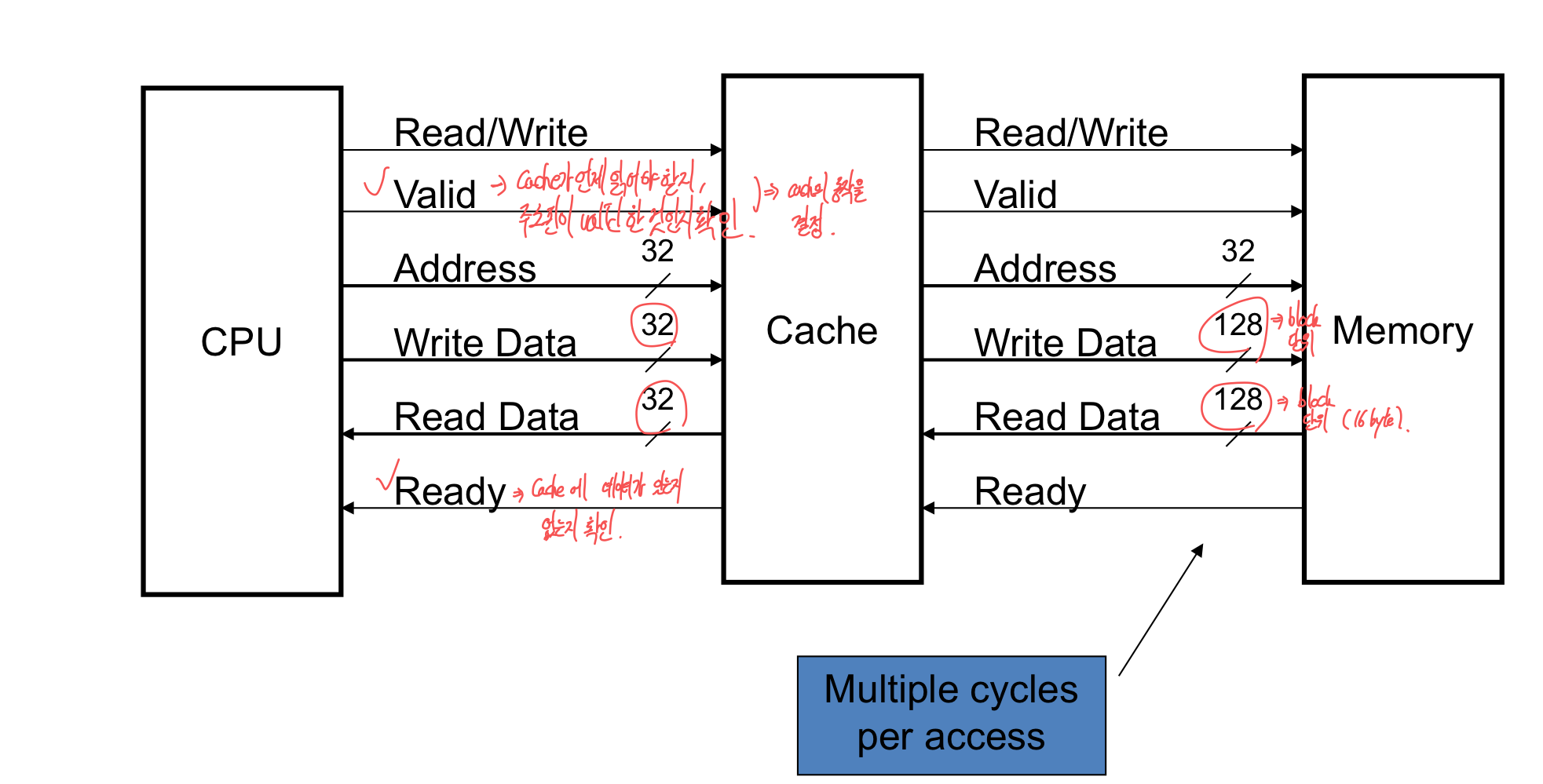
1) Cache Control
- Example cache characteritics
- Direct-mapped, write-back, write allocate
- Block size: 4 words (16 bytes)
- Cache size: 16 KB (1024 blocks)
- 32-bit byte addresses
- Valid bit and dirty bit per block
- Blocking cache
- CPU는 accee가 완료 될 까지 기다린다.
2) Interface Signals
3) Finite State Machines
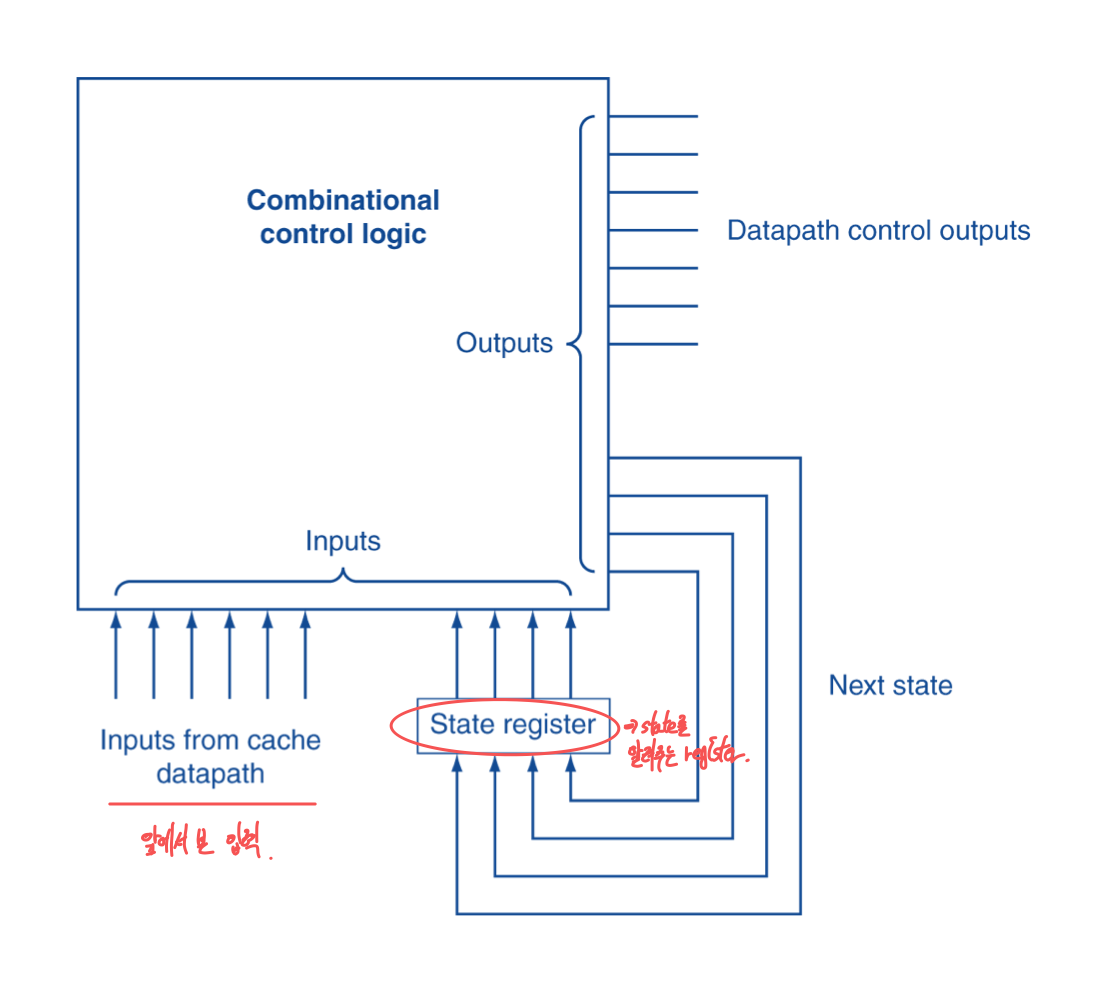
- contorl의 단계 진행을 위해서 Finite state machine (FSM)을 사용한다.
- state의 set과 transition을 각 clocke edge마다 한다.
- state의 값은 binary로 encode된다.
- 현재 state는 register에 저장되어 있다.
- 다음 state는, fn(current statem currten input)의 결과로 결정된다.
- Control output signal = f0(current state)
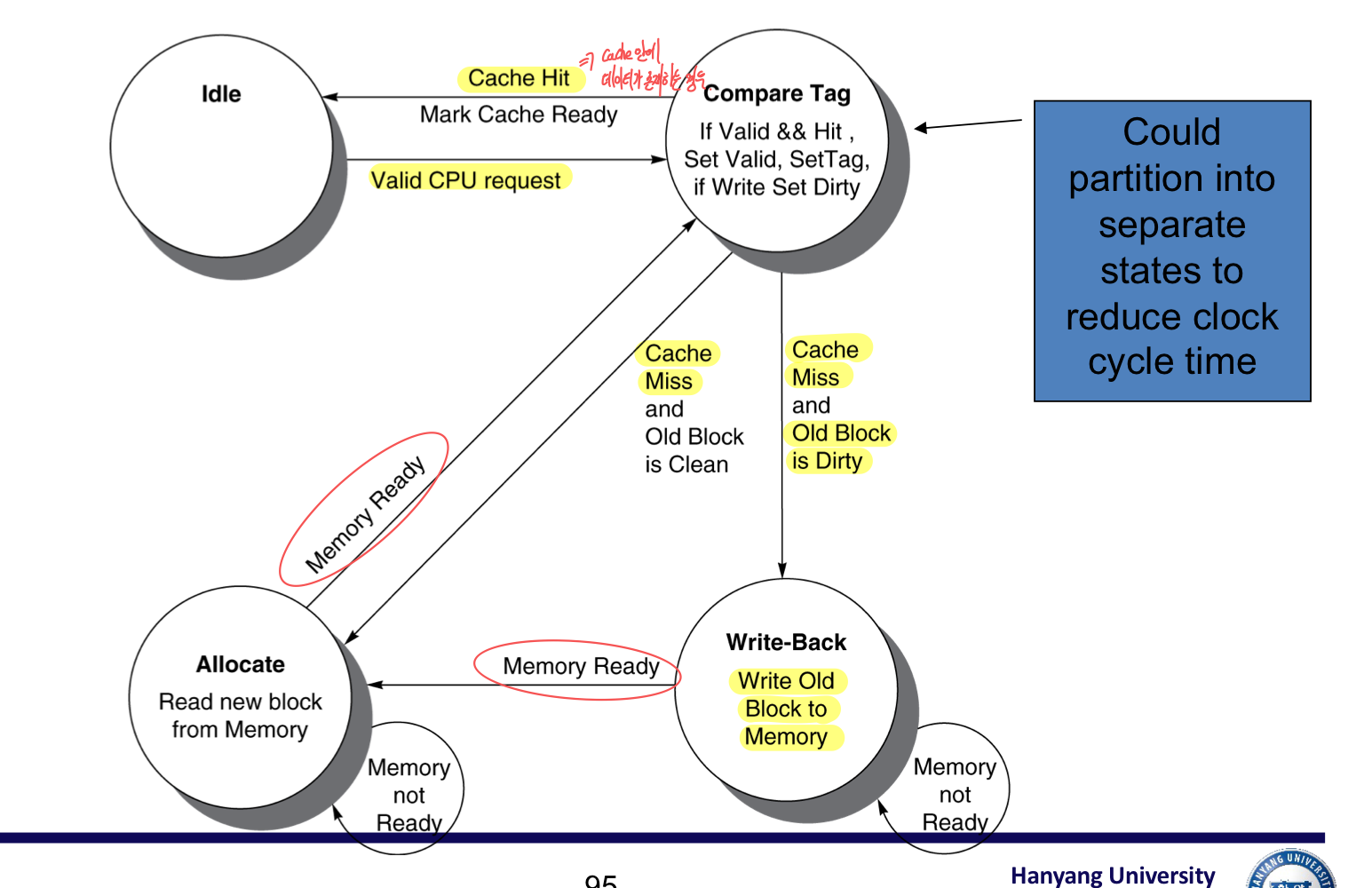
a) Cache Controller FSM
9. Parallelism and Memory Hierarchy: Cache Coherence
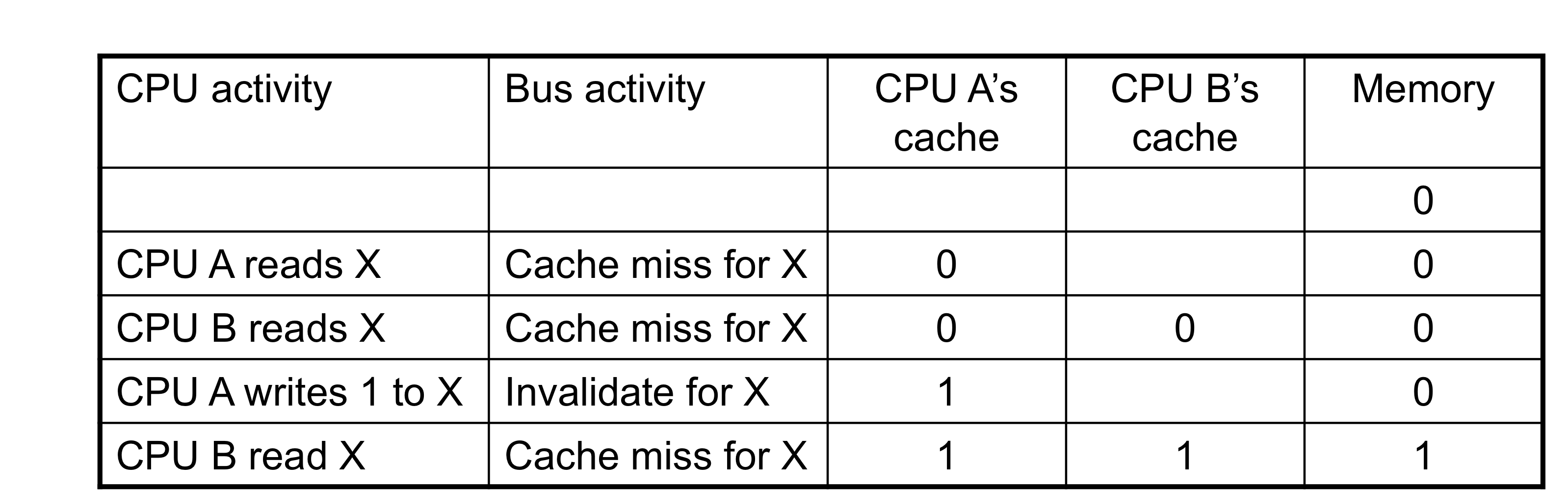
1) Cache Coherence Problem
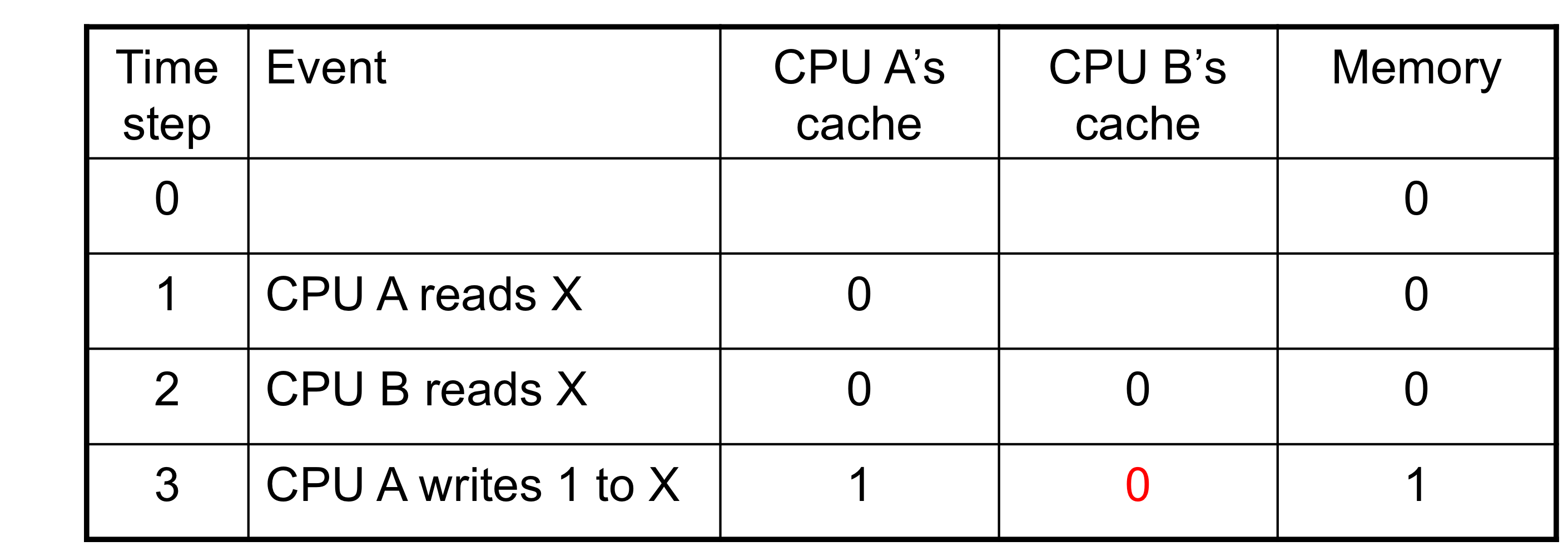
- 2개의 CPU core가 같은 physical address space를 공유한다고 한다면,
- Write-through caches
- A가 기록한 데이터가 B에는 반영이 안되어있다.
2) Coherence Defined
- Informally: 가장 최근에 쓰여진 값을 read한다.
- Formally:
- P 가 X를 쓰고, P가 X를 읽는다 (개입이 없다.)
- 제대로 된 값이 반영
- P1이 X를 쓰고, P2가 X를 읽는다 (충분히 늦게)
- 제대로 된 값이 반영
- P1이 X를 쓰고, P2가 X를 읽는다.
- 모든 프로세스에서 같은 순서에 write하는 것을 본다.
- 결국 X에 대해서 같은 final value를 갖는다?
- 모든 프로세스에서 같은 순서에 write하는 것을 본다.
- P 가 X를 쓰고, P가 X를 읽는다 (개입이 없다.)
3) Cache Coherence Protocols
- 멀티프로세서 환경에서 캐시에 의해 동작하는 작업들은 coherence를 보장해야한다.
- data를 local cache에서 주고 받는다.
- 단, shared memory의 bandwidth가 줄어든다.
- read-shared data는 복제한다.
- 접근을 위한 경쟁이 줄어든다.
- data를 local cache에서 주고 받는다.
- Snooping protocols
- 한 CPU가 값을 변경할 때, 다른 CPU에게 전달해서 변경을 알 수 있게 한다.
- 각각의 cache가 bus reads/writes를 보고 있다.
- 공유하고 있는 bus 혹은 network가 있어야한다.
- Directory-based protocols
- directory에서 캐시와 메모리가 블록들이 staring status를 recodrd 한다.
- directory에서 각각의 정보를 가지고 있고, 관리한다.
- directory에서 캐시와 메모리가 블록들이 staring status를 recodrd 한다.
4) Invalidating Snooping Protocols
- cache는 블록에 값을 쓸 때, 독특한 access를 진행한다.
- bus에 invalidate message를 뿌린다.
- 다른 캐시에서는 이후 read에서 cache miss가 발생 한다.
- 소유한 cache에서 업데이트 한 값을 공급해 준다.