
DBMS의 운영에서 가장 중요한 요소는 확장성과 가용성이다. 이 두 가지 요소를 만족시키기 위해 일반적으로 사용되는 기술이 복제이고, MySQL에서는 어떻게 구현되어 있으며, 어떻게 작동하는지 등에 대해서 알아보고자 한다.
개요
복제는 한 서버에서 다른 서버로 데이터가 동기화 되는 것을 말하며, 원본 데이터를 가진 서버 (소스 서버)에서 복제된 데이터를 가지는 서버 (레플리카)에 변경 내용을 전달해 소스 서버에 저장된 데이터와 동기화 하는 기능이다.
그렇다면, 복제를 통해서 얻고자 하는 것은 무엇일까?
-
Scale Out
레플리카 서버를 통해서 한 DB 서버의 Scale-Up 보다는 동일한 데이터를 가진 여러 대의 레플리카 DB 서버를 두어 트래픽을 효과적으로 분산할 수 있다.
-
데이터 백업
보통 DB 서버에 저장된 데이터를 주기적으로 백업을 하는데, 현재 사용자 쿼리를 처리하고 있는 서버에서 백업이 실행되는 경우 처리 속도에 문제가 생길 수 있지만 레플리카 서버를 통해 데이터 백업을 수행한다면, 백업에 대한 오버헤드를 줄일 수 있을 것이다.
-
지리적 분산
보통 통신 시간을 최적으로 줄이기 위해서는 어플리케이션 서버와 DB 서버의 지리적인 위치도 중요하다. 레플리카 서버를 통해 어플리케이션 서버와 지리적인 응답 속도를 개선할 수 있다.
MySQL 복제 작동 원리
MySQL 서버에서 발생하는 모든 변경 사항은 별도의 로그 파일에 순서대로 기록되는데, 이를 Binary Log라고 한다. 해당 로그에는 데이터의 변경 내역 뿐 아니라 데이터베이스나 테이블의 구조 변경과 계정이나 권한 변경 정보까지 모두 저장되며, MySQL에서 복제는 이 바이너리 로그를 기반으로 구현되어 있다.
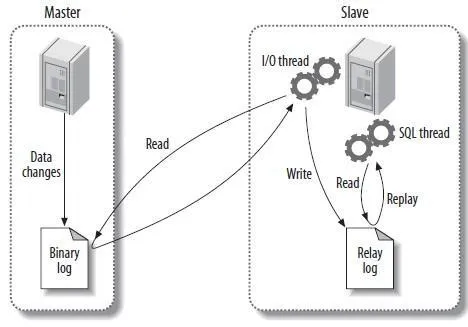
소스 서버에서 생성된 바이너리 로그가 레플리카 서버로 전송되고 이를 릴레이 로그에 저장한 후, 레플리카 서버에 동기화가 된다.
복제 타입
MySQL의 복제는 소스 서버의 바이너리 로그에 기록된 변경 내역을 식별하는 방식에 따라, 바이너리 로그 파일 위치 기반 복제와 글로벌 트랜잭션 ID 기반 복제 두 가지로 나눌 수 있다.
바이너리 로그 파일 위치 기반 복제
바이너리 로그 파일 위치 기반 복제는 기존 방식의 복제로, 복제 시작 시점의 바이너리 로그 파일 이름과 위치(Offset)를 기준으로 복제를 시작하는 방식이다.
그렇게 때문에 각각의 이벤트들이 바이너리 로그 파일명과 파일 내 위치 값의 조합으로 식별이 된다. 하지만, 이 상황에서 문제는 이 식별이 바이너리 로그 파일이 저장되어 있는 소스 서버에서만 유효하다는 것이다. 동일한 이벤트가 레플리카 서버에서도 동일한 파일명의 동일한 위치에 저장된다는 보장이 없다. 즉, 복제에 투입된 서버들마다 동일한 이벤트에 대해 서로 다른 식별 값을 가지게 된다는 것이다.
이로 인해 생기는 문제점은 복제를 구성하는 서버들이 서로 정보가 호환되지 않기에 트랜잭션 추적이 불가하여 장애 복구가 어렵다는 문제가 존재한다.
GTID 기반 복제
GTID(Global Transaction Identifier) 기반 복제는 MySQL 5.6 이상에서 도입된 방식으로, 각 트랜잭션에 대해 고유한 식별자(ID)를 부여하고 이를 기준으로 복제를 수행하는 방식이다. GTID는 "서버 UUID:트랜잭션 번호"의 형태로 구성된다.
3E11FA47-71CA-11E1-9E33-C80AA9429562:23예를 들어 위와 같은 GTID는 “UUID를 가진 서버에서 실행된 23번째 트랜잭션”을 의미한다.
앞서, 바이너리 로그 파일 위치 기반 복제의 문제점을 언급하였는데 예시를 보며 GTID 기반 복제가 왜 필요한지에 대해서 더 서술하려고 한다.
GTID가 필요한 이유
소스 서버 A가 있고, 그 아래 B와 C 두 대의 레플리카 서버가 복제 중인 상황을 가정해보자.
- B는 복제를 잘 따라가고 있고,
- C는 네트워크 문제 등으로 인해 복제 지연이 발생하고 있음 (트랜잭션 누락 중)
이 상태에서 A 서버에 장애가 발생해 사용할 수 없게 되었다고 가정해보자.
장애 복구를 위해 B를 새로운 Master로 승격시키고,
C는 이제 B를 새로운 소스로 삼아 복제를 이어가야 한다.
파일 위치 기반 복제?
- C는 이전까지 A의 mysql-bin.000004, position 45678까지 복제를 했고
- B는 A의 binlog를 복제한 후, 현재 자신만의 mysql-bin.000001, position 12345를 사용 중임
이 경우 C는 “나는 A의 binlog의 45678까지 했는데, B에게 어디서부터 받아야 하지?“라는 문제에 직면한다.
binlog 파일명과 위치 정보는 A에서만 의미가 있는 값이기 때문에, C가 B에게 정확히 어디서부터 복제를 이어받을지 판단할 수가 없다.
결과적으로, C는 B에게 정확한 복제 위치를 알 수 없으므로 전체 데이터를 다시 덤프받고 초기화해야 할 수도 있는 상황에 놓이게 된다.
GTID 기반 복제?
- 모든 트랜잭션에는 GTID라는 고유한 식별자가 부여되어 관리된다.
- B는 A에서 발생한 GTID 중 UUID-A:1~1000까지 복제해왔다고 기록되어 있다.
- C는 UUID-A:1~800까지만 복제했음
이때 C가 B에게 “나는 UUID-A:800까지 복제했어요”라고 알려주면,
B는 “너는 801~1000을 복제하지 않았구나, 내가 그걸 줄게” 하고 정확하게 이어서 복제를 재시작할 수 있다.
GTID 덕분에 각 서버는 트랜잭션의 진행 상태를 명확하게 공유하고, 장애 후 복제도 중단 없이 이어나갈 수 있는 것이다.
복제 구축
Docker를 사용해서 간단하게 실제 MySQL 환경에서 GTID기반 복제를 구성해보며, 어떻게 복제를 구성하는지 더 알아보자.
디렉토리 구조
mysql-gtid-replication/
├── docker-compose.yml
├── master/
│ └── my.cnf
└── replica/
└── my.cnfdocker-compose.yml
version: '3.8'
services:
master:
image: mysql:8.0
container_name: mysql-master
hostname: master
ports:
- "3307:3306"
environment:
MYSQL_ROOT_PASSWORD: root
MYSQL_DATABASE: testdb
volumes:
- ./master/my.cnf:/etc/mysql/my.cnf
replica:
image: mysql:8.0
container_name: mysql-replica
hostname: replica
ports:
- "3308:3306"
environment:
MYSQL_ROOT_PASSWORD: root
volumes:
- ./replica/my.cnf:/etc/mysql/my.cnfmy.cnf
master/my.cnf
[mysqld]
server-id=1
log-bin=mysql-bin
gtid-mode=ON
enforce-gtid-consistency=TRUE
binlog-format=ROWreplica/my.cnf
[mysqld]
server-id=2
log-bin=mysql-bin
relay-log=relay-bin
gtid-mode=ON
enforce-gtid-consistency=TRUE
read-only=1컨테이너 실행
docker-compose up -dMaster 설정 및 복제 계정 생성
docker exec -it mysql-master mysql -uroot -prootCREATE USER 'repl'@'%' IDENTIFIED WITH mysql_native_password BY 'replpass';
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%';
FLUSH PRIVILEGES;현재는 설정을 단순화하기 위해서 호스트 제한을 ‘%’로 설정했지만, 실제 환경에서는 보안을 위해 꼭 필요한 IP 대역에 대해서만 복제 연결이 가능하도록 설정하는 것이 좋다.
데이터 복사
Replica를 진행하기 전에 Master와 Replica의 데이터 상태를 일치시켜야한다. 일반적으로 mysqldump가 많이 사용되며, mysqldump를 통해 Master의 전체 데이터를 백업한 뒤, 해당 덤프 파일을 Replica에 적재하는 방식을 사용한다.
데이터 덤프
docker exec -i mysql-master mysqldump -uroot -proot \
--all-databases \
--master-data=2 \
--single-transaction \
--set-gtid-purged=ON > ./init.sql각 옵션에 대해서 간단히 설명하자면 아래와 같다.
| 옵션 | 설명 |
|---|---|
| --all-databases | 전체 DB 백업 (보통 복제는 전체 DB 단위로 수행) |
| --master-data=2 | 현재 binlog 위치를 주석으로 덤프 파일에 포함 |
| --single-transaction | 백업 시 일관성 보장 |
| --set-gtid-purged=ON | 복제 시작 지점 기록 |
여기서 주의깊게 보아야 할 옵션은 --set-gtid-purged이다. GTID 기반 복제에서 레플리카 서버는 gtid_executed 값을 기반으로 다음 복제 이벤트를 소스 서버로 부터 가져온다. 하지만, 이는 읽기 전용 변수로 우리가 바꿀 수 없는 값이고, gtid_purged 변수 값만 수정 가능하다.
처음에는 이 두 변수 값이 비어 있는데 gtid_purged에 값을 설정해주면 gtid_executed에도 자동으로 동일한 값이 설정된다. 그렇기 때문에 덤프가 시작된 시점의 GTID를 덤프 파일에 기록해주어, 해당 시스템 변수를 설정해준다.
또한, sql_log_bin시스템 변수도 비활성화하는 구문도 기록되는데, 이는 덤프 파일을 실행할 때 적용되는 트랜잭션들이 레플리카 서버에서 새로운 GTID를 발급 받는 것을 방지하는 것이다.
--- ./init.sql
SET @@SESSION.SQL_LOG_BIN= 0;
SET @@GLOBAL.GTID_PURGED=/*!80000 '+'*/ '786c9169-087f-11f0-85b3-0242ac150002:1-15';덤프 파일을 복사
docker cp ./init.sql mysql-replica:/init.sql
docker exec -i mysql-replica mysql -uroot -proot < ./init.sqlReplica 설정
앞선 SET @@GLOBAL.GTID_PURGED로 전달받은 GTID 기준 으로 이후 트랜잭션 부터 동기화가 시작된다.
덤프를 통해 데이터를 복사하는 과정에서 추가적인 복제 지연이 발생할 수 있기에 소스 서버 백업 시점 부터 현재까지의 트랜잭션 복사가 이루어진다.
docker exec -it mysql-replica mysql -uroot -prootCHANGE MASTER TO
MASTER_HOST='master',
MASTER_PORT=3306,
MASTER_USER='repl',
MASTER_PASSWORD='replpass',
MASTER_AUTO_POSITION=1;
START SLAVE;SHOW SLAVE STATUS\G --- 복제 상태 확인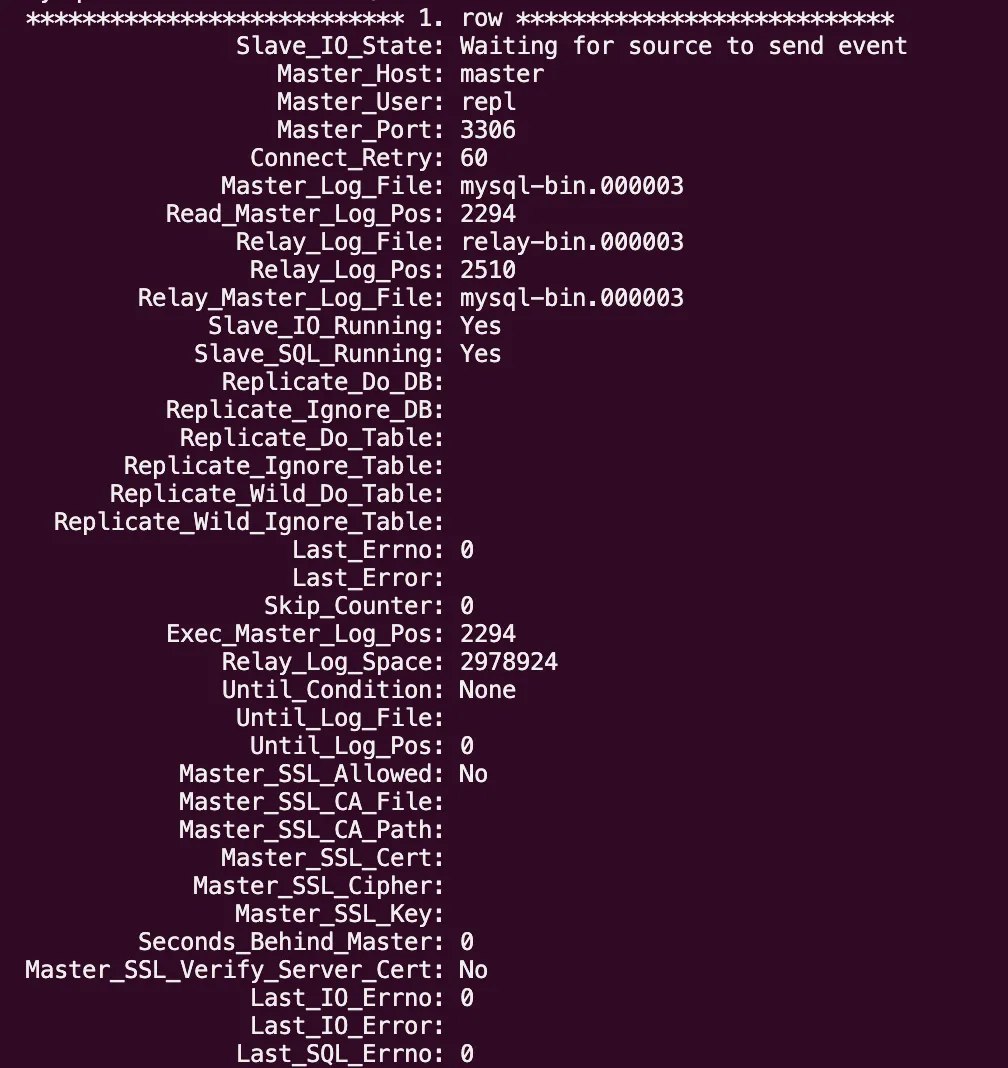
테스트
Master에서 데이터 생성
USE testdb;
INSERT INTO hello VALUES (1, 'hello GTID replication');Replica에서 확인
SELECT * FROM testdb.hello;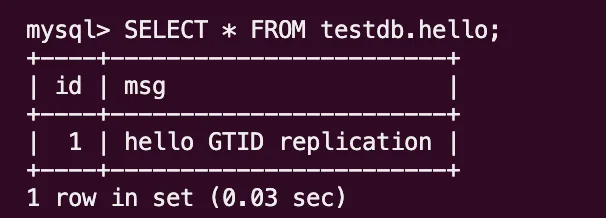
참조
Real MySQL 8.0 (1권)
https://hoing.io/archives/3633
https://hoing.io/archives/3111
http://dkswnkk.tistory.com/725
