
파티션이란?
파티션은 논리적으로는 하나의 테이블이지만 물리적으로는 여러 개의 테이블로 분리해서 관리할 수 있게 해주는 것이다. 주로 대량의 데이터를 효율적으로 관리하고, 쿼리 성능을 최적화하기 위해 사용된다.
그렇다고 해서, 무조건적으로 성능이 빨라지는 것이 아니며 오히려 성능이 나빠지는 경우도 발생할 수 있다. 어떻게 사용하면 효율적일지 이해하기 위해 MySQL의 파티션 방법들을 알아보면서 주의사항도 같이 알아보고자 한다.
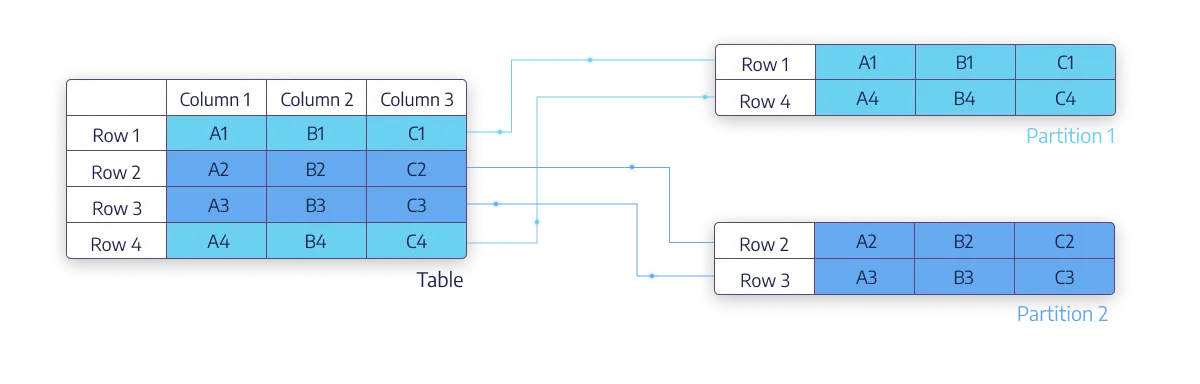
데이터 조회의 빠른 처리
파티션을 사용하면 데이터가 여러개의 독립적인 파티션으로 나뉘어 저장되므로, MySQL 서버의 연산이 특정 파티션에서만 수행되어 처리속도가 향상된다.
일반적으로 인덱스는 SELECT를 위한 것으로 많이 생각하는데, UPDATE와 DELETE 쿼리 중 특정 행을 찾기 위한 용도로도 많이 사용된다.
그러나 인덱스가 커지게 된다면 SELECT의 성능 저하는 당연한것이고 INSERT나 UPDATE,DELETE 작업도 마찬가지로 느려진다. 만약 인덱스의 크기가 MySQL이 사용 가능한 메모리 공간보다 더 크다면 그 영향은 더 심각하다.
테이블의 크기가 크면 자연스럽게 인덱스의 크기도 커진다. 테이블은 당연히 메모리보다 크기가 큰 것이 당연하지만, 활발하게 사용되는 인덱스의 크기가 메모리보다 크다면 성능 저하에 미치는 영향이 더 클 것이다. 이러한 상황에서 파티션은 테이블과 인덱스를 조각화해서 메모리를 효율적으로 사용할 수 있도록 만들어준다.
데이터 저장소 분리
데이터 파일이나 인덱스 파일이 차지하는 공간이 크다면, 백업이나 관리 작업이 어려워진다.
하지만, 파티션을 통해 파일의 크기를 조절하거나 각 파티션별 파일들이 저장될 위치나 디스크를 구분해서 저장할 수 있다.
이력 데이터의 효율적인 관리
일정 기간이 지나면 특정 파티션을 삭제하는 방식으로 이력 데이터 관리가 가능하다.
요즘 거의 모든 어플리케이션이 로그를 가지고 있는데, 단기간에 대량으로 쌓임은 물론 일정 기간이 지나면 필요 없어진다. 하지만, 일반 테이블에서 이를 백업하고 삭제하는 작업은 굉장히 고부하의 작업이다.
이러한 목적의 테이블을 파티션 테이블로 관리한다면, 불필요한 데이터 삭제는 단순히 파티션을 추가하거나 삭제하는 방식으로 간단하게 해결할 수 있다.
예를 들어, 1년 단위로 데이터를 관리하는 경우 3년이 지나면 데이터는 삭제해야한다고 하면, 년도마다 파티션을 만든 후 3년이 지난 파티션은 삭제하는 것이다.
MySQL 파티션의 내부 처리
CREATE TABLE log_data (
id INT NOT NULL AUTO_INCREMENT,
event_date DATE NOT NULL,
message TEXT NOT NULL,
PRIMARY KEY (id, event_date)
)
PARTITION BY RANGE (YEAR(event_date)) (
PARTITION p2022 VALUES LESS THAN (2023),
PARTITION p2023 VALUES LESS THAN (2024),
PARTITION p2024 VALUES LESS THAN (2025)
);event_date의 연도를 기준으로 파티셔닝을 하는 테이블을 기준으로 예시를 살펴보도록 하자.
INSERT
INSERT INTO log_data (event_date, message) VALUES
('2022-06-15', 'System reboot'),
('2023-03-10', 'User logged in'),
('2024-12-25', 'Backup completed');INSERT 쿼리가 실행되면 MySQL 서버는 INSERT 되는 값 중에서 파티션 키인 event_date를 기준으로 자동으로 적절한 파티션에 삽입된다.
UPDATE
UPDATE log_data SET message = 'System rebooted' WHERE event_date = '2022-06-15';UPDATE를 수행하면 변경 대상 레코드가 어느 파티션에 저장되어 있는지 찾아야 한다. 이때, UPDATE의 WHERE 조건에 파티션 키 컬럼이 조건으로 존재하면 레코드가 저장된 파티션에서 빠르게 대상 레코드를 검색할 수 있다.
하지만, 파티션 키 컬럼이 검색 조건으로 설정되어 있지 않다면, 대상 레코드를 찾기 위해 테이블의 모든 파티션을 검색해야한다.
UPDATE log_data SET event_date = '2023-12-23' WHERE event_date = '2022-06-15';UPDATE 시에 추가적으로 고려해야할 것이 있는데 바로 UPDATE의 대상이 파티션 키인 경우이다. 이러한 경우에는 기존의 레코드가 존재하는 파티션에서 해당 레코드를 삭제한다. 그리고 새로 변경되는 파티션 키 컬럼을 보고 새로운 파티션을 결정해서 새로 저장한다.
즉, 한번의 UPDATE로 삭제와 추가 두 가지 연산이 수행되는 것이다.
검색
파티션 테이블을 검색할 때, 성능에 크게 영향을 미치는 조건은 다음과 같다.
- WHERE 절의 조건으로 검색해야 할 파티션을 선택할 수 있는지
- WHERE 절의 조건이 인덱스를 효율적으로 사용하는지
인덱스를 효율적으로 사용해야하는 것은 파티션 테이블이든 아니든 모두 똑같이 적용되는 사항이다. 하지만, 파티션 테이블에서는 파티션을 선택할 수 있는지에 대한 부분도 고려해야한다.
그렇기에 총 4가지의 조합이 가능한데, 다음과 같다.
| 경우 | 파티션 선택 | 인덱스 사용 | 동작 방식 |
|---|---|---|---|
| ① 파티션 선택 + 인덱스 사용 | 가능 | 가능 | 가장 효율적이며, 꼭 필요한 파티션의 인덱스만 찾아 레인지 스캔 수행 |
| ② 파티션 선택 X + 인덱스 사용 | 불가능 | 가능 | 모든 파티션을 대상으로 검색하지만, 인덱스를 활용하여 레인지 스캔 후 결과 병합 |
| ③ 파티션 선택 + 인덱스 사용 불가 | 가능 | 불가능 | 선택된 파티션에서 풀 테이블 스캔 수행 |
| ④ 파티션 선택 X + 인덱스 사용 X | 불가능 | 불가능 | 모든 파티션에서 풀 테이블 스캔 수행 (가장 비효율적) |
인덱스 스캔과 정렬
파티셔닝된 테이블에서 인덱스는 모두 로컬 인덱스에 해당한다. 즉, 각 파티션마다 별도의 인덱스를 가지며, 테이블 전체 단위로 글로벌한 하나의 통합 인덱스는 지원하지 않는 것이다.
별것처럼 보이지 않을 수 있지만, 각 파티션은 개별적으로 정렬되기에 최종적으로 결과를 병합한 후 추가적인 정렬이 필요하다.
SELECT * FROM log_data
WHERE id BETWEEN 10 AND 100 AND event_date BETWEEN '2023-01-01' AND '2024-12-31'
ORDER BY id;위 쿼리를 보면 2023 파티션과 2024년도 파티션에 대해 일치하는 id를 가져온 후 각 파티션의 결과를 병합하고 id로 한번 정렬해야 할 것 처럼 보인다. 만약 파티셔닝 테이블이 아니였다면, 인덱스는 id기준으로 전체가 정렬되어 있기에 바로 결과값을 반환 했으면 되었을 것이다.
다행히도, 실제 MySQL 서버는 여러 파티션에 대해 인덱스 스캔을 수행할 때, 각 파티션으로부터 조건에 일치하는 레코드를 읽으면서 우선순위 큐(Priority Queue)에 임시로 저장한다. 그 후에 필요한 순서대로 데이터를 가져가서 자연스럽게 정렬 작업을 별도로 수행하지 않고 스캔을 수행한다.
파티션 프루닝
파티션 프루닝은 안 읽어도 된다고 판단되는 파티션에는 접근하지 않는 것이다. 쿼리 실행 시 조건을 분석하여 필요하지 않은 파티션을 무시하고, 관련된 파티션만 스캔함으로써 성능을 향상시킨다.

위 쿼리의 실행 계획의 partitions을 보면, p2023만 표시되었다. 이는 쿼리를 수행하기 위해서 해당 파티션만 조회했다는 뜻이며, 나머지 파티션은 파티션 프루닝된 것이다.
주의사항
파티션의 제약 사항
- 파티션 테이블의 모든 유니크 인덱스는 파티션 키 컬럼을 포함해야 한다.
- MySQL의 파티셔닝은 데이터를 여러 개의 독립적인 파티션에 나눠 저장하는 방식이므로, 각 파티션 내부에서만 인덱스가 관리됨.
- 따라서 UNIQUE KEY가 파티션 키를 포함하지 않으면 전체 테이블 단위로 중복 검사할 수 없음.
- 스토어드 루틴, UDF, 사용자 변수 등을 파티션 표현식에 사용할 수 없다.
- 파티션은 데이터 저장 시점에서 결정되어야 하지만, 스토어드 루틴, UDF, 사용자 변수는 런타임에 수행된다.
- 일부 MySQL 내장 함수들은 파티션 생성은 가능하지만 파티션 프루닝을 지원하지 않을 수 있다.
- 일부 함수는 파티션 표현식에서 사용할 수 있지만, MySQL이 실행 시점에서 이를 정적으로 분석할 수 없어 프루닝을 적용하지 못하는 경우가 있음.
- 파티션별 인덱스를 생성할 수 없다.
- MySQL에서는 테이블 단위로만 인덱스를 관리하며, 개별 파티션마다 별도의 인덱스를 생성하는 기능을 제공하지 않음.
- 동일한 테이블의 파티션은 모두 동일 스토리지 엔진이다.
- MySQL은 하나의 테이블이 동일한 스토리지 엔진을 공유해야 일관성을 유지할 수 있기 때문.
- 최대 8192개의 파티션을 가질 수 있다.
- MySQL은 테이블의 각 파티션을 개별 파일로 관리하기 때문에, 너무 많은 파티션이 있으면 파일 시스템 및 성능에 부하를 줄 수 있음.
- 파티션 생성 이후 MySQL 서버의 sql_mode 변경은 파티션의 일관성을 깰 수 있다.
- sql_mode가 변경되면 데이터 타입, 정렬 방식 등이 달라질 수 있어 기존 파티션과 일관성이 깨질 위험이 있음.
- 외래 키를 사용할 수 없다.
- 각 파티션은 개별적인 테이블처럼 동작하므로, MySQL이 외래 키를 유지하는 것이 어렵기 때문.
- 전문 검색 인덱스 생성이나 전문 검색 쿼리를 사용할 수 없다.
- 공간 데이터를 저장하는 컬럼 타입을 사용할 수 없다.
- 임시 테이블은 파티션 기능을 사용할 수 없다.
파티션 사용 시 주의 사항
파티션과 유니크 키(PK 포함)
앞서 봤듯이 유니크 인덱스가 있으면 파티션 키는 모든 유니크 인덱스의 일부 또는 모든 칼럼을 포함해야한다.
CREATE TABLE users (
id INT NOT NULL AUTO_INCREMENT,
email VARCHAR(100) NOT NULL,
name VARCHAR(50) NOT NULL,
created_at DATE NOT NULL,
UNIQUE KEY (email)
)
PARTITION BY RANGE (YEAR(created_at)) (
PARTITION p2022 VALUES LESS THAN (2023),
PARTITION p2023 VALUES LESS THAN (2024),
PARTITION p2024 VALUES LESS THAN (2025)
);위의 쿼리는 잘못된 테이블 파티션을 생성하는데, email컬럼은 UNIQUE 키 이지만, 파티션 키를 포함하지 않기에 잘못 생성되는 파티션 테이블이다.
CREATE TABLE users (
id INT NOT NULL AUTO_INCREMENT,
email VARCHAR(100) NOT NULL,
name VARCHAR(50) NOT NULL,
created_at DATE NOT NULL,
PRIMARY KEY (id, created_at),
UNIQUE KEY (created_at, email)
)
PARTITION BY RANGE (YEAR(created_at)) (
PARTITION p2022 VALUES LESS THAN (2023),
PARTITION p2023 VALUES LESS THAN (2024),
PARTITION p2024 VALUES LESS THAN (2025)
);위 처럼 파티션 키를 포함시켜 UNIQUE KEY를 만들어야지 제대로된 파티션 테이블이 생성된다.
MySQL은 전체 테이블 기준의 UNIQUE 검사가 어렵다. 검사를 위해 많은 파일을 탐색하는 부하가 더 클 것이기 때문이다. 그렇기에, 각 파티션에 대해서만 중복 검사가 가능한데 그렇기 때문에 UNIQUE KEY에 파티션 키를 포함시켜야 하는 것이다.
MySQL 파티션의 종류
레인지 파티션
파티션 키의 연속된 범위로 파티션을 정의하는 방법이다. MAXVALUE라는 키워드를 사용해서 명시되지 않은 범위의 키 값이 담긴 레코드를 저장하는 파티션 정의도 가능하다.
용도
특정 범위에 따라 나눌 수 있는 성격의 데이터에 대해서는 레인지 파티션을 사용하는 것이 좋다. 보통 날짜나, 범위 기반으로 균등하게 나눌 수 있는 숫자 데이터가 적합하다.
데이터베이스에서 파티션의 대표적인 장점은 큰 테이블을 분리하는 것과 필요한 파티션만 접근할 수 있다는 두 가지의 장점인데 레인지 파티션은 필요한 파티션에만 접근 가능하다는 장점의 효과가 큰 편이다.
예를 들어, 앞서 보았던 로그 테이블에 대해 레인지 파티션을 저장하면 쓰기는 모두 가장 최근 데이터를 저장하는 파티션에만 이루어지기에 이러한 장점이 극대화 된다.
테이블 생성
CREATE TABLE sales (
id INT NOT NULL,
sale_date DATE NOT NULL,
amount DECIMAL(10,2) NOT NULL,
PRIMARY KEY (id, sale_date)
) PARTITION BY RANGE (YEAR(sale_date)) (
PARTITION p2022 VALUES LESS THAN (2023),
PARTITION p2023 VALUES LESS THAN (2024),
PARTITION p2024 VALUES LESS THAN (2025),
PARTITION p_max_value VALUES LESS THAN MAXVALUE
);위 예제처럼 파티션 테이블은 PARTITION BY RANGE키워드로 레인지 파티션을 정의한다. 파티션 키를 통해 어떤 기준으로 파티셔닝이 될 것인지 명시한다.
현재는 MAXVALUE를 설정해주어서 2025년에 대한 데이터가 들어온다면 p_max_value 파티션에 삽입이 될텐데, 만약 이 줄이 없다면 Table has no partition for value 2025이라는 메시지가 표시된다.
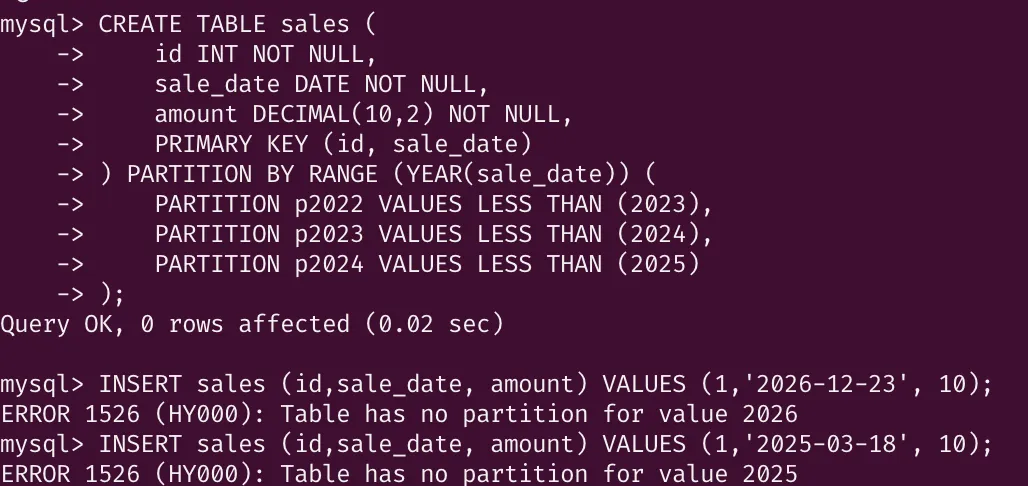
파티션 추가
ALTER TABLE sales ADD PARTITION (
PARTITION p2025 VALUES LESS THAN (2026)
);위의 명령을 통해 2025년도에 대한 레코드를 저장하기 위한 추가적인 p2025 파티션을 생성할 수 있다.
이때, 주의할 점이 MAXVALUE파티션을 가지고 있다면 아래와 같은 에러가 발생한다.
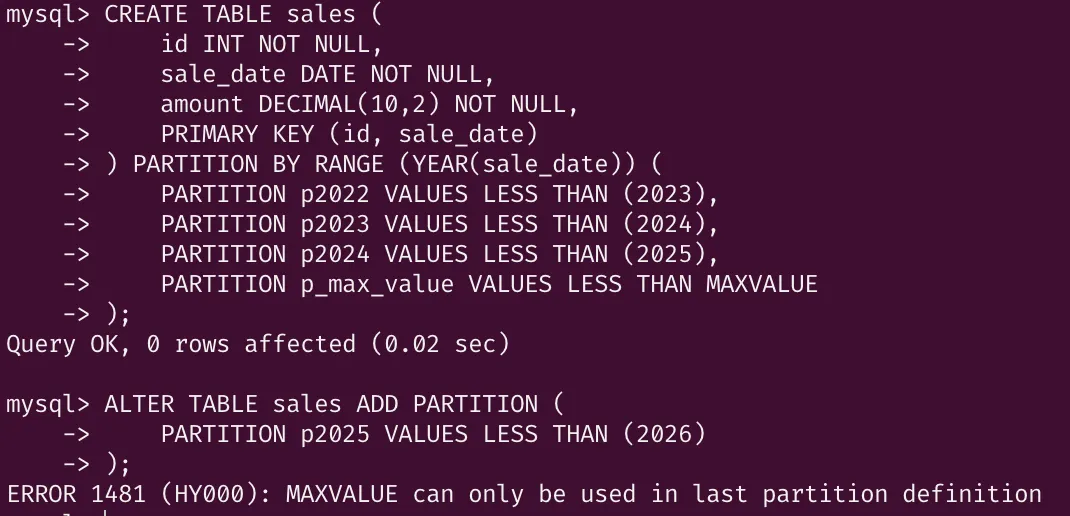
이미 MAXVALUE 파티션이 2024년 이후의 모든 레코드를 가지고 있는 상태에서 p2025가 추가된다면 이후 추가되는 2025년에 대한 레코드는 2개의 파티션에 나뉘어 저장되는 형태를 보일 것이다. 그래서 아래와 같은 명령으로 추가한다.
ALTER TABLE sales ALGORITHM=INPLACE, LOCK=SHARED, REORGANIZE PARTITION p_max_value INTO(
PARTITION p2025 VALUES LESS THAN (2026),
PARTITION p_max_value VALUES LESS THAN MAXVALUE
);위의 명령은 기존 p_max_value 파티션을 모두 새로운 두 개의 파티션으로 복사하는 작업이며, 만약 레코드가 많다면 매우 오래걸릴 것이다.
그래서 일반적으로 LESS THAN MAXVALUE를 사용하는 것은 권장하지 않고 이후에 추가될 파티션을 미리 여러개 만들어두는 형태로 테이블을 생성하기도 하는 방식으로도 만든다고 한다.
파티션 삭제
ALTER TABLE sales DROP PARTITION p2022;위의 명령으로 단순하게 특정 파티션을 삭제할 수 있으며, 삭제하는 작업은 아주 빠르게 처리되므로, 날짜 단위로 파티션된 테이블에서 오래된 데이터를 삭제하는 용도로 아주 적합하다.
하지만, 파티션을 삭제할 때 항상 가장 오래된 파티션 순서로만 삭제할 수 있다. 레인지 파티션이 4개가 있는데, 중간에 있는 파티션을 먼저 삭제할 수는 없다.
기존 파티션의 분리
분리는 아까 잠깐 보았던 MAXVALUE에 파티션을 추가하는 아래의 명령처럼 수행하면 된다.
ALTER TABLE sales ALGORITHM=INPLACE, LOCK=SHARED, REORGANIZE PARTITION p_max_value INTO(
PARTITION p2025 VALUES LESS THAN (2026),
PARTITION p_max_value VALUES LESS THAN MAXVALUE
);p_max_value의 파티션을 p2025, p_max_value 두 파티션으로 분리하는 명령어이며 최소한 읽기 잠금은 필요하므로, 조금 여유로운 시간대에 수행해야 한다.
기존 파티션의 병합
여러 파티션을 하나의 파티션으로 병합하는 것도 REORGANIZE로 가능하다.
ALTER TABLE sales ALGORITHM=INPLACE, LOCK=SHARED, REORGANIZE PARTITION p2022, p2023 INTO(
PARTITION p20222023 VALUES LESS THAN (2024)
);파티션을 병합하는 경우에도 파티션에 대한 읽기 잠금이 필요하므로 이 부분을 고려해야한다.
리스트 파티션
리스트 파티션은 레인지 파티션과 많은 부분에서 흡사하게 동작하지만, 가장 큰 차이는 키 값 하나하나를 리스트로 나열해야 한다는 점이다. 또한 MAXVALUE 파티션을 정의할 수 없다.
용도
특정한 값 목록을 기준으로 데이터를 나누는 방식이며, 지역 혹은 카테고리 등의 데이터를 저장할 때 유용하다.
테이블 생성
CREATE TABLE users (
id INT NOT NULL,
country VARCHAR(50) NOT NULL,
PRIMARY KEY (id, country)
) PARTITION BY LIST COLUMNS(country) (
PARTITION p_usa VALUES IN ('USA', 'Canada'),
PARTITION p_asia VALUES IN ('Korea', 'Japan', 'China'),
PARTITION p_europe VALUES IN ('Germany', 'France', 'UK')
);PARTITION BY LIST 키워드로 리스트 파티션을 정의하며 이후 파티션 키를 정의한다.
해시 파티션
해시 파티션은 MySQL에서 정의한 특정 해시 함수에 의해 레코드가 저장될 파티션을 결정하는 방법이다. 여기서 MySQL가 정의한 해시 함수는 복잡한 알고리즘이 아니라 파티션 표현식의 결괏값을 파티션 개수로 나눈 나머지로 파티션을 결정하는 방식을 사용한다.
그래서, 파티션 키는 항상 정수 타입의 컬럼 혹은 정수를 반환하는 표현식만 사용될 수 있다. 또한, 해시 문제를 잘 알고 있다면, 전체를 나머지 값으로 배분하는 방식은 파티션 추가 혹은 삭제 시에 테이블 전체적으로 레코드를 재분배하는 비효율이 발생하는 것을 알고 있을 것이다.
용도
데이터를 균등하게 분산하는 것을 주 목적으로 하는 파티셔닝이다. 즉, 모든 레코드가 비슷한 사용 빈도를 보이지만 테이블이 너무 커서 파티션을 적용해야 할 때 사용하는 것이다. 가장 대표적인 예시가 회원 테이블이며, 오래 되었다고 사용하지 않는 데이터가 아니며 특정 컬럼이 사용 빈도에 미치는 영향이 전혀 없다.
테이블 생성
CREATE TABLE orders (
id INT NOT NULL,
customer_id INT NOT NULL,
order_date DATE NOT NULL,
PRIMARY KEY (id, customer_id)
) PARTITION BY HASH(customer_id) PARTITIONS 4;PARTITION BY HASH 키워드를 통해서 해시 파티션을 만든다. 이후 파티션 키를 명시한다.
또한, PARTITIONS 4 를 통해 몇 개의 파티션을 생성할 것인지 명시한다.
파티션 추가
해시 파티션은 특정 파티션 키 값을 테이블의 파티션 개수로 MOD 연산한 결괏값에 의해 각 레코드가 저장될 파티션을 결정한다. 즉, 새로운 파티션이 추가된다면 기존의 각 파티션에 저장된 모든 레코드가 재배치 되어야 한다.
ALTER TABLE orders ALGORITHM=INPLACE, LOCK=SHARED,
ADD PARTITION PARTITIONS 6;위의 명령을 통해 동시에 6개의 파티션을 추가할 수 있다. 하지만, 실제로 이렇게 파티션을 추가하면 기존의 모든 파티션 레코드를 새로운 파티션으로 재분배해야한다. 그렇기에 테이블 읽기 잠금이 필요하다. 즉, 해시 파티션에서 파티션을 추가하는 작업은 많은 부하를 발생시키는 작업이다.
파티션 삭제
해시나 키 파티션은 파티션 단위로 레코드를 삭제하는 방법이 없다.
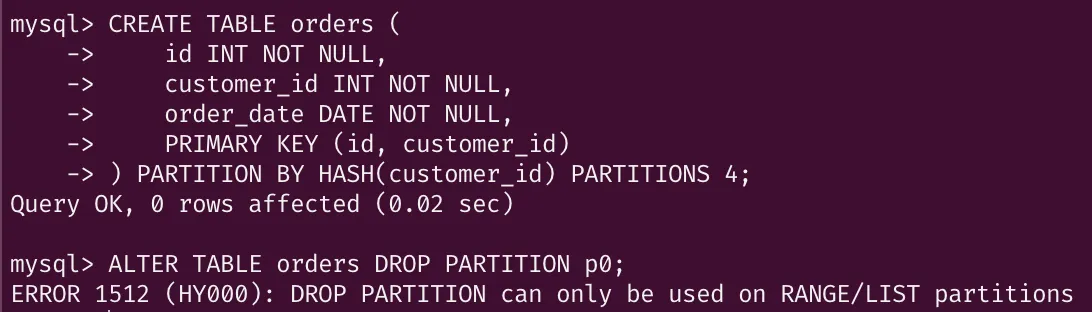
위와 같이 특정 파티션을 삭제하려고 하면 에러가 발생한다. 결국 MySQL 서버가 데이터를 각 파티션으로 분산한 것이므로 저장된 레코드가 어떤 데이터인지 예측할 수 없다. 그렇기에 파티션 단위의 삭제는 의미가 없는 작업이다.
파티션 분할
같은 의미로 특정 파티션을 분할하는 작업도 의미 없는 작업이다. 그냥 단순히 파티션 개수를 늘리면 이게 분할인 것이다.
파티션 병합
ALTER TABLE orders ALGORITHM=INPLACE, LOCK=SHARED COALESCE PARTITION 1;파티션 병합도 생각해보면 의미 없는 작업이다. 단순히 PARTITION을 하나 줄이는 것이 병합이랑 다를 바가 없다.
파티션을 줄이는 것도 마찬가지로 모든 파티션 데이터의 재분배를 요구하는 작업이며 읽기 잠금이 필요하다.
키 파티션
키 파티션은 해시 파티션과 거의 유사하지만 다른 점은 해시 파티션은 해시 값을 계산하는 방법을 파티션 키나 표현식에 사용자가 명시하는 방식이다. 하지만, 키 파티션에서는 해시 값의 계산도 MySQL이 수행한다. 보통 MD5()함수를 이용해 해시 값을 계산하고, MOD연산을 통해 각 파티션의 분배한다.
즉, 해시 파티션에서는 파티션 키 값에 무조건 정수 혹은 정수 값을 반환하게 해시를 주어야했다. 하지만, 키 파티션은 대부분 데이터 타입에 대해서 파티션 키로 지정 가능하다. (어차피 내부에서 해시 함수를 한번 돌리기 때문)
테이블 생성
CREATE TABLE logs (
id INT NOT NULL,
log_date DATE NOT NULL,
message TEXT NOT NULL,
PRIMARY KEY (id, log_date)
) PARTITION BY KEY(log_date) PARTITIONS 4;위의 명령 처럼 PARTITION BY KEY키워드로 키 파티션을 정의한다. 이때, 키 값을 따로 명시하지 않을 수도 있는데 이러면 PK의 모든 칼럼이 파티션 키가 된다.
리니어 해시/ 리니어 키 파티션
해시 파티션이나 키 파티션은 새로운 파티션을 추가하거나 개수를 줄일 때 테이블의 전체 파티션에 저장된 레코드의 재분배 작업을 필요로 한다. 이러한 문제를 해결하기 위해 리니어 파티션이 고안되었고, Power-of-two알고리즘을 사용하여 다른 파티션에 미치는 영향을 최소화 한다.
Power-of-two 알고리즘이란?
Power-of-two 알고리즘은 MOD를 대체하여 비트 연산(&)를 사용하여 연산 속도를 최적화 하는 방식이다.
partition_number = hash_value & (N - 1);| value | hash(value) & (4-1) | 파티션 |
|---|---|---|
| 10 | 10 & 3 = 2 | p2 |
| 15 | 15 & 3 = 3 | p3 |
| 18 | 18 & 3 = 2 | p2 |
만약, 이 상황에서 N을 4가 아니라 8로 증가 시키면, 일부 데이터(value & 4가 0이 아닌 값)만 새로운 파티션으로 이동하면 된다.
즉, 기존 데이터 중 절반만 재배치 되는 것이다.
테이블 생성
CREATE TABLE logs (
id INT NOT NULL,
log_date DATE NOT NULL,
message TEXT NOT NULL,
PRIMARY KEY (id, log_date)
) PARTITION BY LINEAR HASH(YEAR(log_date)) PARTITIONS 4;테이블 생성은 LINEAR HASH 혹은 LINEAR KEY로 가능하다.
파티션 추가
파티션의 추가하는 명령은 일반 해시 파티션이나 키 파티션과 동일하나, power-of-two알고리즘을 통해 파티션의 일부만 재분배할 수 있다.
파티션 삭제
파티션을 삭제하는 과정도 일부 파티션에 대해서만 레코드 통합 작업이 이루어 지면 된다.
주의 사항
리니어 파티션은 MOD연산을 사용하는 것이 아니라 Power-of-two 알고리즘을 통해 작업 범위를 최소화 한다. 하지만 각 파티션이 가지는 레코드의 건수는 덜 균등해 질 수 있다. 만약, 파티션을 조정 할 일이 많다면 리니어 파티션 그렇지 않다면 일반 해시 파티션이나 키 파티션을 사용하는 것이 좋을 것이다.
참조
https://hoing.io/archives/8527#Linear_HashKey_Partition
https://www.devart.com/dbforge/mysql/studio/partition-mysql.html
https://www.datasunrise.com/professional-info/what-is-partitioning/
https://dev.mysql.com/doc/refman/5.7/en/partitioning-linear-hash.html
