[CHAPTER 03. 딥러닝 영상분석을 위한 학습 과정]
이번 장에서는 딥러닝 학습을 위해 준비해야 하는 사항과 학습이 이뤄진 후 모델의 결과인 예측 정확도를 높이기 위해 사용하는 방법을 알아보자.
1. 가중치의 최적화 솔버들
솔버(Solver)란 ?
= 모델을 최적화하고자 할 때 사용하는 알고리즘을 솔버라고 부름.
- 기본적으로 최적화 솔버로 SGD(확률적 경사 하강법)를 사용함. --> 모든 딥러닝 모델을 최적화할 수 없음!!
- SGD는 손실이 가장 적은 가중치 파라미터를 찾는 과정에서, 가중치의 변화량이 가장 적은, 즉 경사각이 가장 작아지는 지점을 찾아가는 알고리즘
이러한 특성 때문에, 복잡한 딥러닝 네트워크에서 SGD를 사용하면 문제가 발생할 수 있다.
* 대표적인 문제
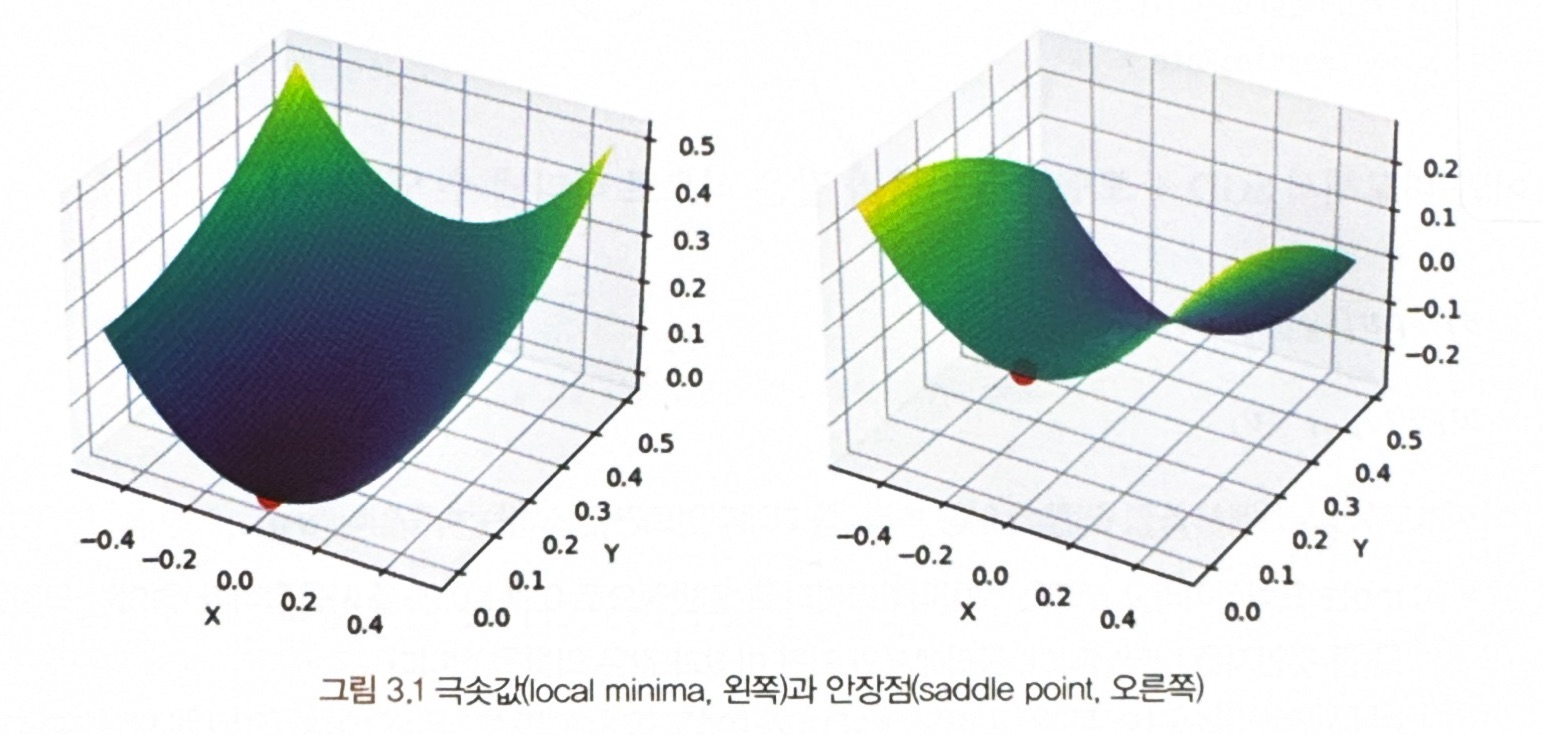
- 중간에 값이 국소적으로 작아졌다가 커지는 극솟값 (왼쪽 그림)
- 변화량이 국소적으로 거의 변화가 없다가 내려가는 안장점 (오른쪽 그림)
--> 그래디언트가 0에 가까워지면서 학습을 진행할 수가 없!!
이 문제를 해결하고자 도입된 개선된 최적화 솔버
1) SGD + 모멘텀
= 경사 하강으로 최적화하는 과정에 운동량이라는 개념을 추가한 방법
- 효과 : 극솟값 문제나 안장점을 피할 수 있는(중간에 머물지 않고 내려갈 수 있는) 과정이다.
<SGD 식>

* 이를 적용한 수식
- get_gradient(x) : 그래디언트를 얻는 함수
- learningRate : 학습률 변수
while True:
dx = get_gradient(x)
x += learningRate * dx<SGD + 모멘텀 식>

* 이를 적용한 수식
vx = 0
while True:
dx = get_gradient(x)
vx = rho * vx + dx
x += learningRate * vx모멘텀의 역할
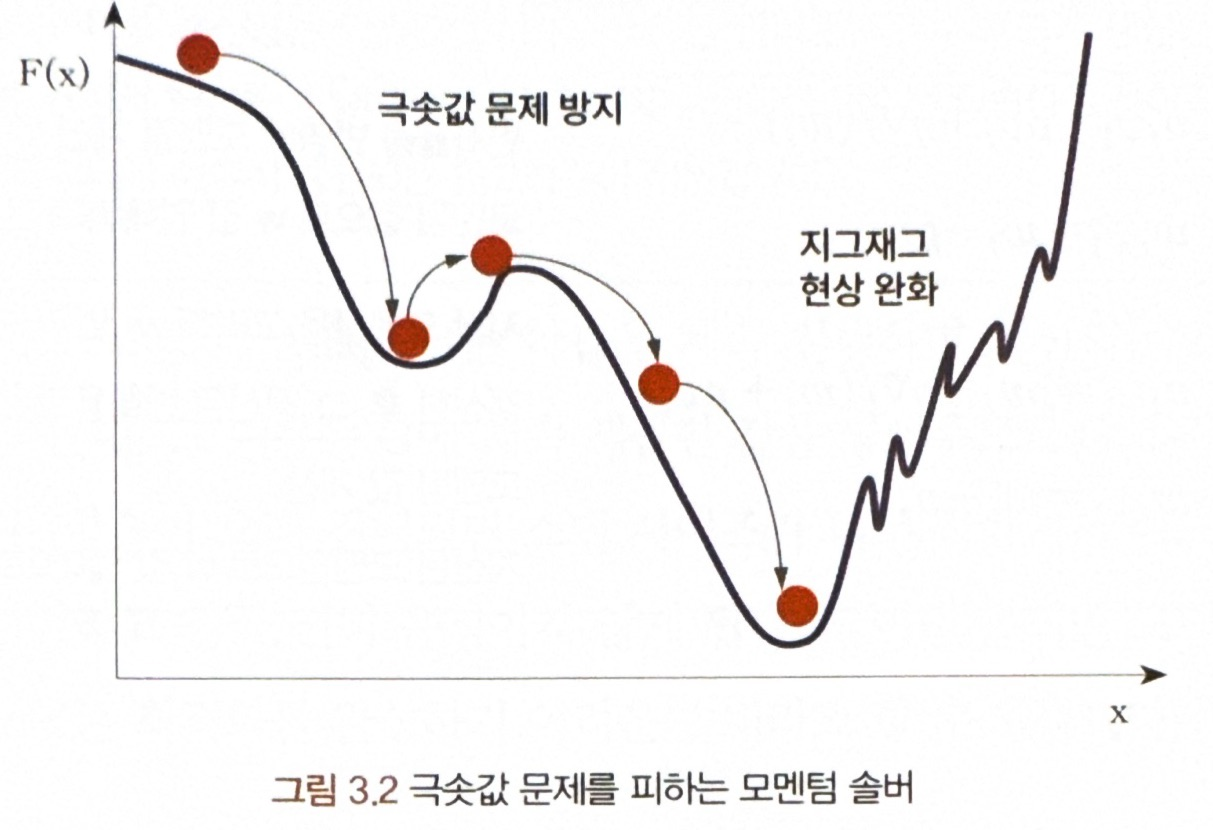
= 경사 하강으로 진행되는 x의 변화를 가속하는 역할
= 경사 하강에서 일어나는 지그재그 현상으로 속도가 떨어지는 것을 방지해서 빠른 속도로 수렴하게 해줌
- 모멘텀은 경사 하강 중인 가중치가 변화하는 관성을 이용해 극솟값에서 머물지 않고 지속적으로 변화할 수 있게 함
* 변화율을 지속해 극솟값 문제가 발생하지 않게 함!!
2) 모멘텀 계열의 솔버 : NAG
= 모멘텀이 지역 최저점에서도 멈추지 못하는 경우가 있기 때문에 제안됨
* NAG과 모멘텀의 차이점
= NAG는 모멘텀으로 이동해 발생하는 변화율을 먼저 계산한 다음 모멘텀을 계산함
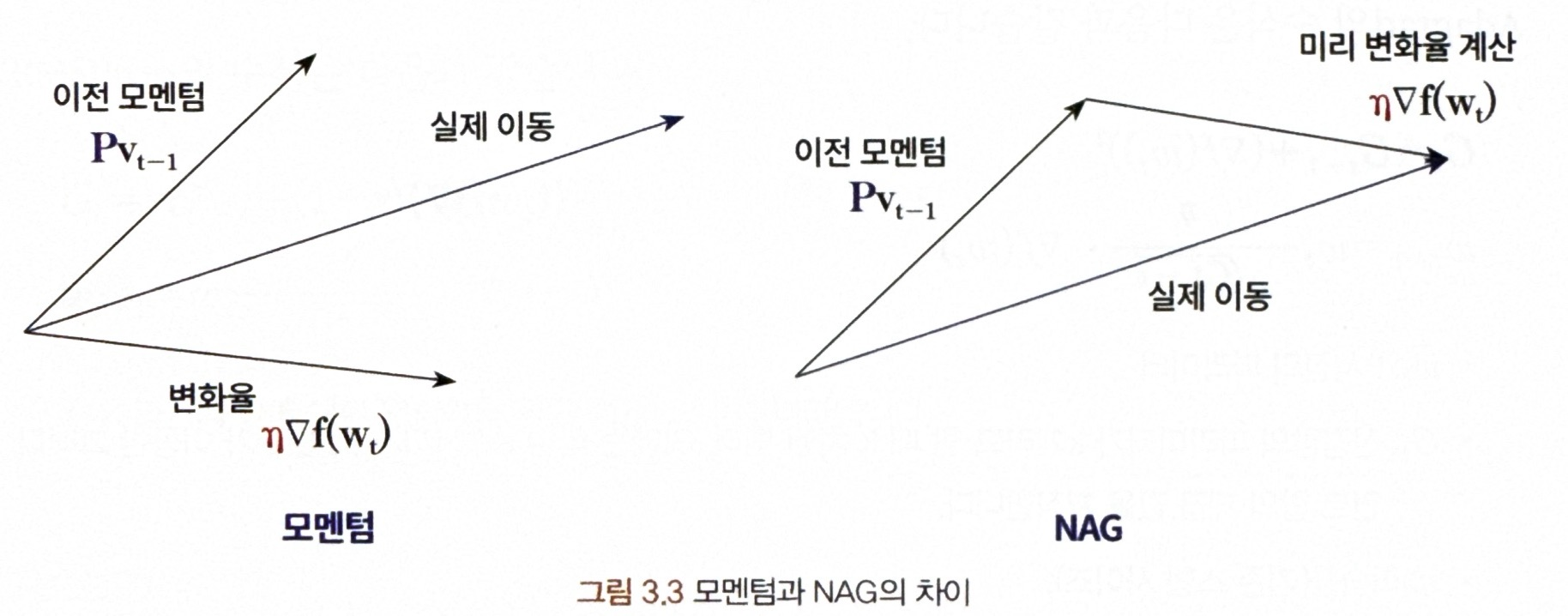
* 수식에서의 차이점

3) Adagrad
= 신경망 학습에서 Adagrad(Adaptive Gradient)는 가중치의 파라미터를 갱신할 때 변수마다 스텝 사이즈를 다르게 설정해 주는 방식
- 가중치 중 많이 변화한 파라미터의 경우 최적화가 많이 진행됐을 확률이 높음 --> 작은 크기로 이동하면서 세밀하게 조정
- 적게 변화한 파라미터는 최적화하기 위해 많이 이동해야 할 확률이 높음 --> 빠르게 이동하는 방식
4) RMSProp
= Adagrad의 식에서 과거 그래디언트를 제곱해서 계속 더한 Gt를, 과거 그래디언트는 서서히 반영을 줄이고 타임 스텝 t까지 각 변수가 이동한 그래디언트 합을 구하도록 바꾼 방법
- Adagrad처럼 Gt가 무한정 커지지는 않으면서도 변화량에서 상대적인 크기 차이는 유지 가능
5) Adam(Adaptive Moment Estimation)
= RMSProp과 모멘텀 방식을 통합해 정확도와 속도를 모두 얻고자 하는 알고리즘
- 최근 영상분석 기법에 활용되는 솔버
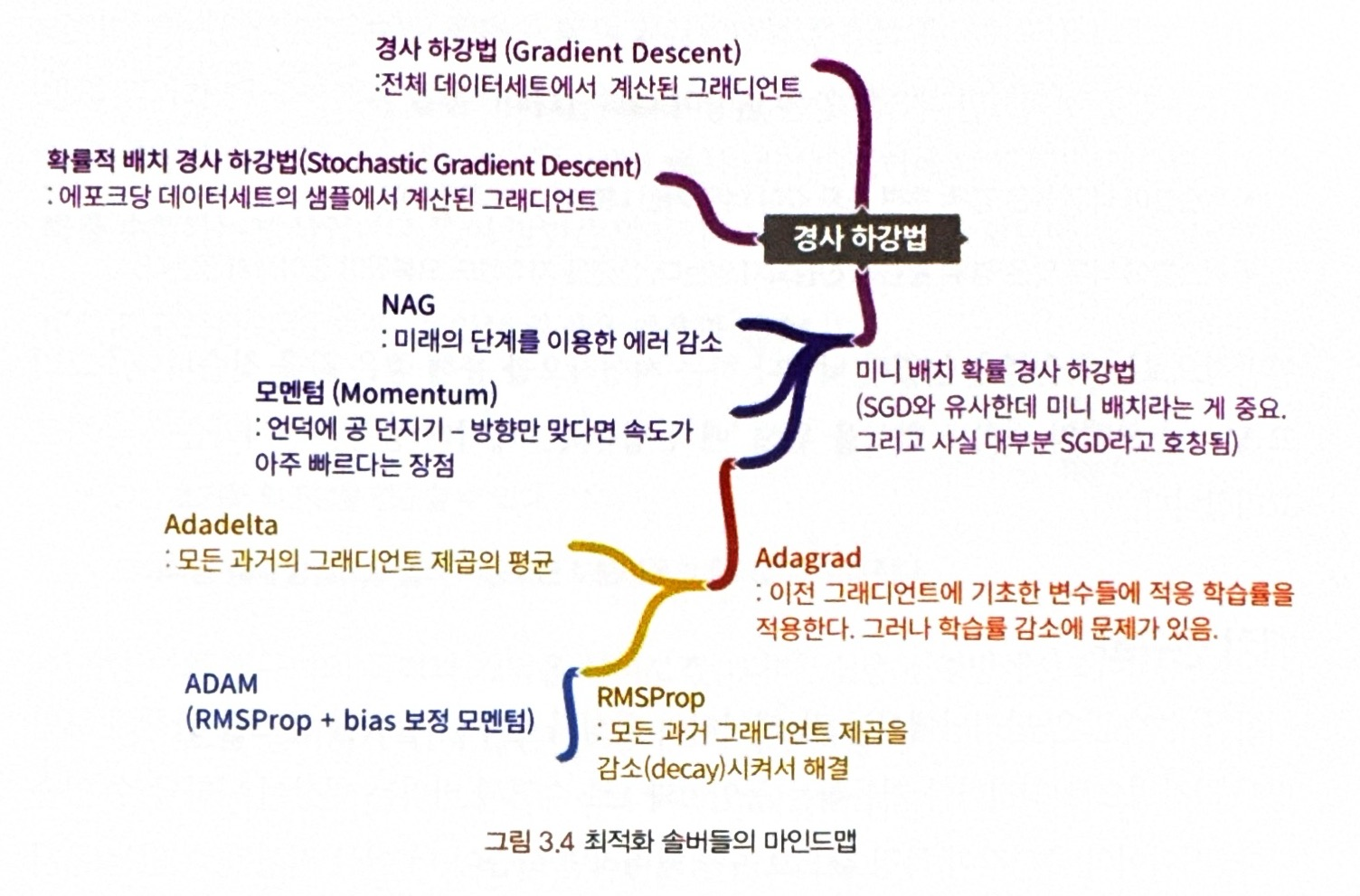
* 경사 하강법부터 개선된 솔버들의 마인드 맵

개발 & 공부 기록