[CHAPTER 04. 이미지 분할과 객체 인식]
1. 이미지 분할
= 디지털 이미지를 여러 세그먼트(픽셀 세트)로 분할하는 프로세스로(=의미론적 분할)
이미지 분할 개념이란 ?
= 같은 객체 클래스에 속하는 이미지 픽셀을 함께 클러스터링(=데이터 포인트의 그룹화와 관련된 머신러닝 기술)해서 분류한 결과를 나타냄
- 전통적인 이미지 분할 : 객체와 관계없이 이미지의 모든 픽셀을 객체 클래스별로 분류했음
--> CNN 영상분석을 적용해 발전을 이뤄 객체 인식이 가능한 객체 분할까지 수행하는 기법으로 발전함!! - 딥러닝 기반 이미지 분할 : 클래스별뿐 아니라 객체별로 클러스터링된 픽셍들을 같은 색상으로 표시까지 가능함.

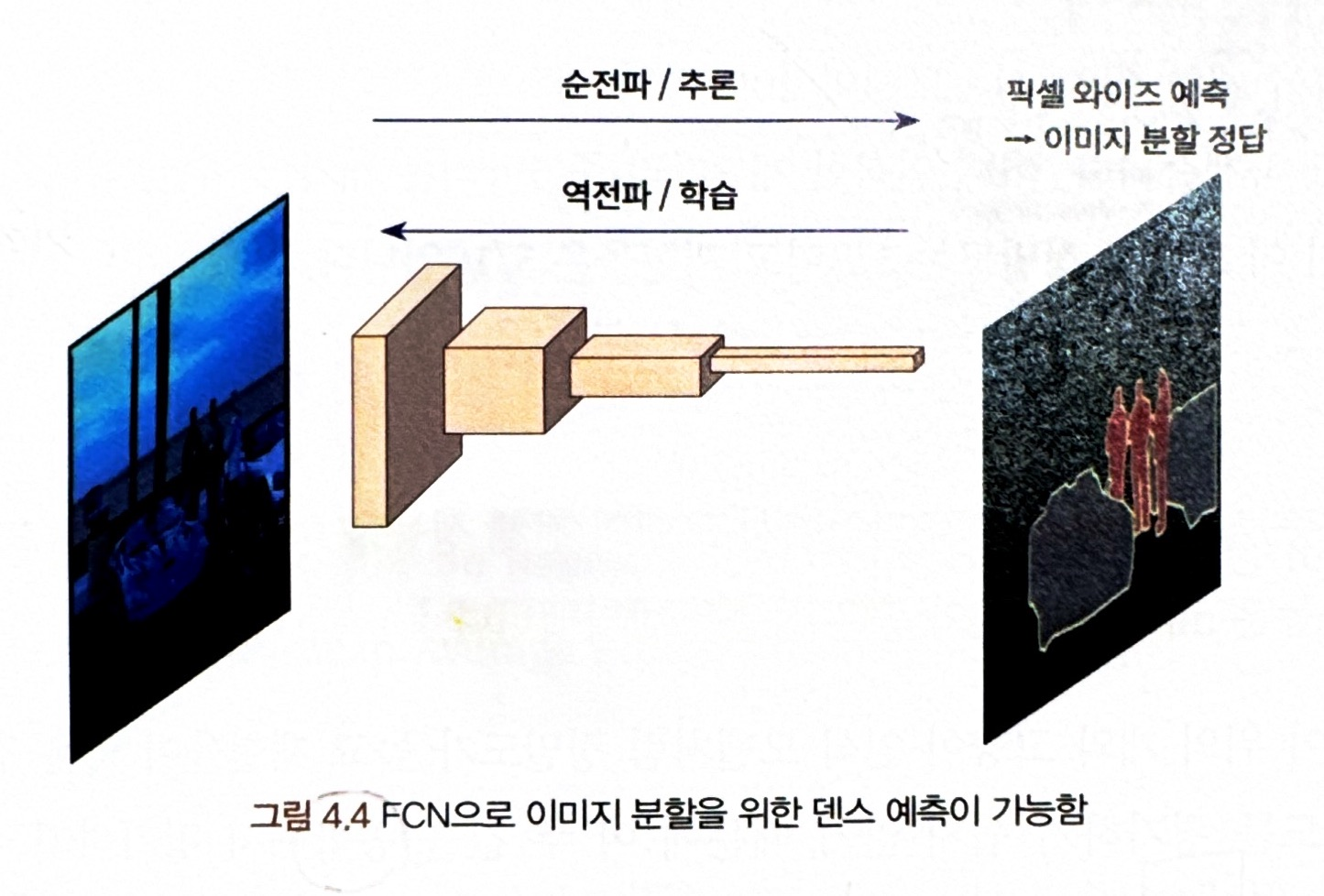
- 이미지 분할을 수행하면 이미지의 각 픽셀은 범주에 따라 분류되므로 픽셀 수준 예측이라고 할 수 있음.
픽셀 수준 예측이란 ?
= 아래 그림과 같이 이미지의 각 픽셀이 어느 클래스에 속하는지 예측 (=덴스 예측)

모델의 평가 지표는 ?
= 일반적으로 평균 IOU(=Mean Intersection-Over-Union) 및 재현율(=recall)과 정밀도(=precision)나 mAP(=mean Average Precision)으로 평가됨.
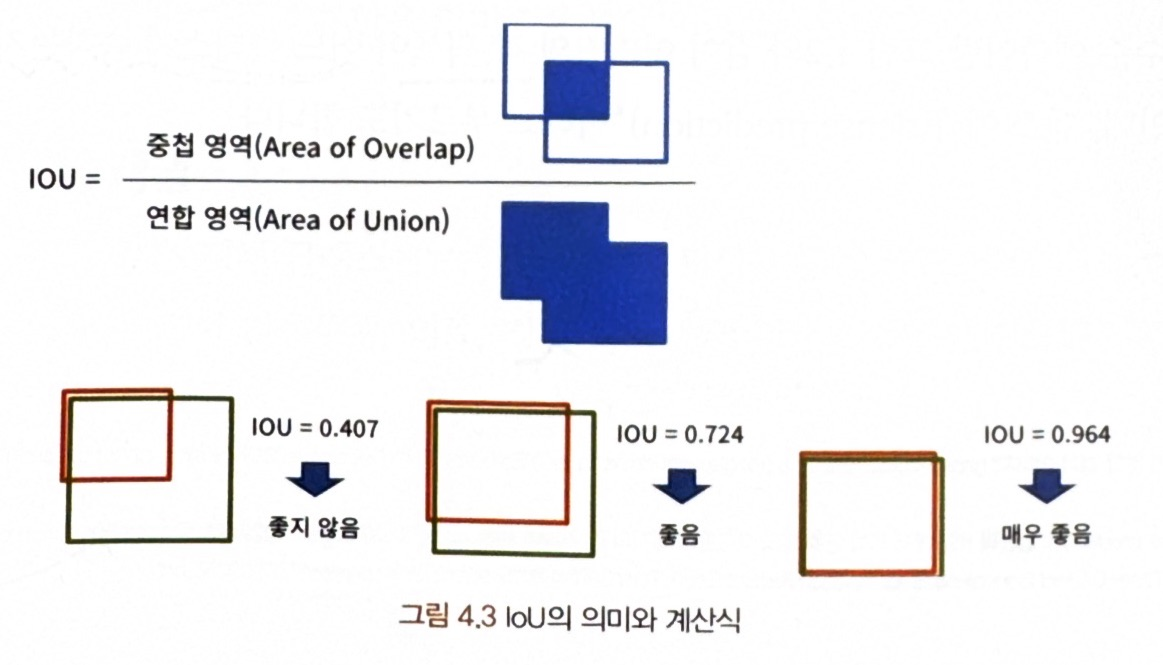
1) IOU
= 기본적으로 대상과 예측간의 겹쳐진 정도(=percent overlap)를 정량화하는 방법(=자카드 인덱스라고도 불림)
* IOU 측정 방법
= 대상과 예측 사이의 공통 픽셀 수를 총픽셀 수로 나누는 것
- 결과는 값이 클수록 좋음 = 실제 영역과 예측 영역이 많이 겹친다는 의미 --> 좋은 예측
2) 재현율과 정밀도
= 객체 인식의 정확도를 나타내는 표현에는 재현율과 정밀도라는 것이 있다
- 재현율 : 전체에서 인식된 객체의 비율 (=감도라고도 함)
- 정밀도 : 검색된 객체 중 올바르게 인식된 경우의 비율
ex) 10마리의 개와 5마리의 고양이가 있을 때, 사진에서 개를 인식하는 모델이 8마리를 인식했고 그 중 5마리만 올바르게 개로 인식했다고 하자.
- 정밀도 : 5/8 (=검색된 객체 8마리 중 5마리만 올바르게 인식됨)
- 재현율 : 5/10 (=전체 개 10마리 중 5마리만 개로 인식됨)
3) mAP
= 다중 클래스 객체 감지 작업에서 모델의 전체 성능을 하나의 숫자로 요약하는데 유용
- 높은 mAP은 모델의 좋은 성능을 나타냄
- 어떤 모델이 정밀도가 높고 재현율이 낮은 경우, 그 모델의 정확도를 평가하기 쉽지 않음
--> 정밀도, 재현율 이 두 값을 종합해서 평가하기 위한 것이 APAP(Average Precision) 란 ?
= 모든 객체 클래스에 대해 개별적으로 정밀도와 재현율 사이의 트레이드오프를 시각화한 그래프인 정밀도-리콜 곡선을 계산한 후, 그래프의 아래 면적(Area Under the Curve, AUC)을 계산한 결과
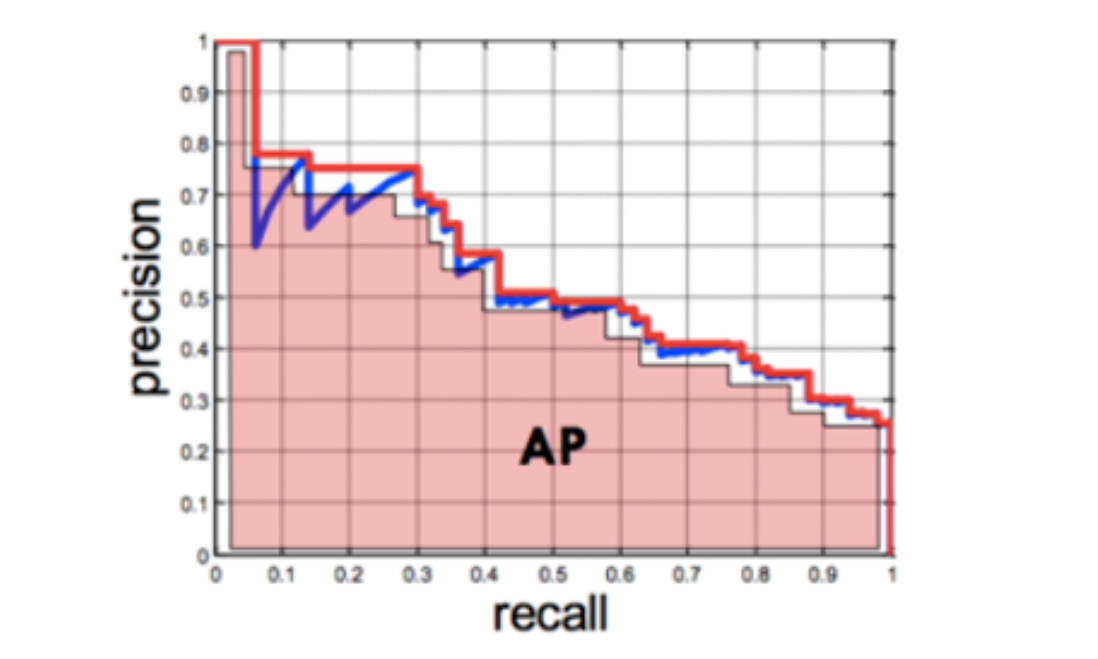
* 모든 클래스의 AP의 값을 평균 계산한 결과가 mAP !!
FCN 이미지 분할이란 ?
-
FCN 이미지 분할 방법은 콘볼루션 네트워크 자체가 최고의 의미적 이미지 분할(시맨틱 세그먼테이선 : semantic segmentation) 기술이라 할 수 있음.
--> 기술의 핵심 : 임의의 크기의 입력을 넣어서 효율적인 추론과 학습으로 원하는 크기의 출력을 생성하는 '완전한 콘볼루션(Fully Convolutional)' 네트워크를 구축하는 것FCN 이란 ?
= AlexNet, VGGNet, GoogLeNet과 같은 분류 네트워크를 미세 조정해 이미지 분할을 위해 전이학습을 한 다음, 깊은 레이어의 의미 정보와 얕은 레이어 모양 정보를 결합해 정확하고 자세한 세그먼트를 생성하는 딥러닝 네트워크 기법
* FCN은 기존 CNN 기반 분류 모델을 기반으로 만드는데, '이미지 분할 모델' 이라는 목적을 위해 다음의 세 과정을 이용
- 완전한 콘볼루션화 (fully convolutionalization)
- 디콘볼루션 (deconvolution)
- 스킵 아키텍쳐 (skip architecture)
1) 완전한 콘볼루션화
= 이미지 분류 네트워크들이 내부 구조와 관계없이 분류를 위해 구성하고 있던 FC(Fully-Connected) 계층을 모두 Conv 계층으로 대체하는 것
* Conv계층 대체 전 (=마지막 특징 맵이 FC 계층으로 평활화하는 과정)
- 이미지의 위치 정보가 사라져 수용 영역 개념도 사라짐
- FC 레이어가 행렬 곱셈 계산의 형태로 가중치의 차원 수가 고정된 형태이기에 특징 맵의 크기와 입력 이미지의 크기도 고정돼야 함
* 이미지 분할의 목적
= 원본 이미지의 각 픽셀에 대해 클래스를 구분하는 것이므로 위치 정보가 매우 중요함!
* FC 계층의 변환이 모두 Conv 계층으로 대체되면 특징 맵에 추출된 위치 정보도 대부분 보존 가능 !!
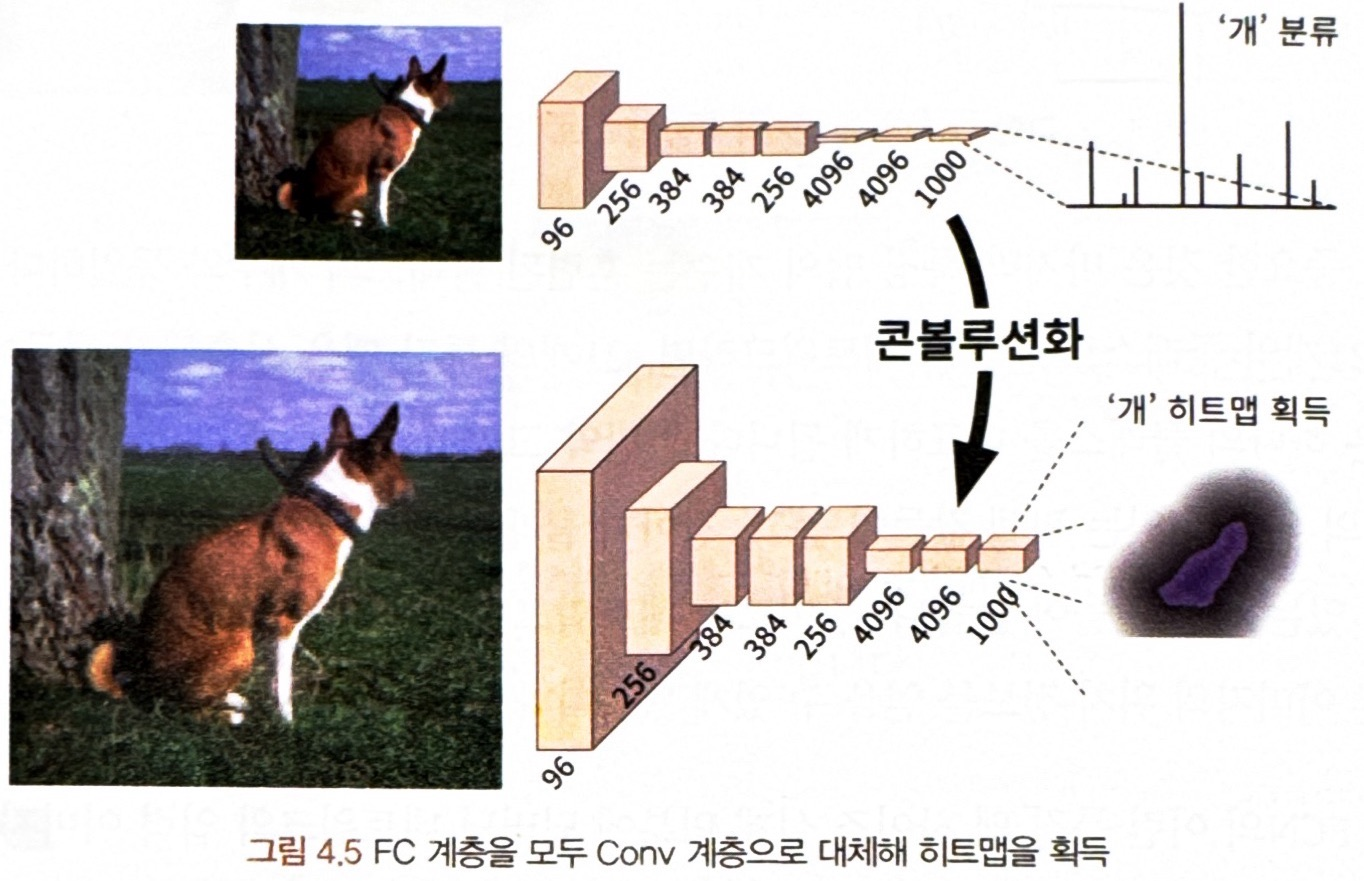
** 이렇게 얻은 마지막 계층의 특징 맵은 어느 정도의 위치 정보와 클래스 정보를 갖고 있어 히트맵(heatmap)라고 불린다.
-
전부 콘볼루션 층들을 거치고 나면 특징 맵의 크기가 H/32 * W/32가 됨
--> 특징 맵의 한 픽셀이 입력 이미지의 32 x 32 크기를 대표함.
--> 이때 특징 맵은 입력 이미지의 위치 정보를 대략 유지하고 있는 상태(사진 넣고)
* 중요!!) 마지막 특징 맵의 개수는 훈련된 클래스의 개수와 동일하다는 것
ex) 21개의 클래스로 훈련된 네트워크라면 21개의 특징 맵 산출 (각 특징 맵은 하나의 클래스를 대표)
--> 고양이 클래스에 대한 특징 맵 = 고양이의 위치 픽셀 값들이 높음
--> 강아지 클래스에 대한 특징 맵 = 강아지의 위치 픽셀 값들이 높음* 결론
- 네트워크 출력층의 특징 맵에서 유지하고 있는 원본 이미지의 위치 정보를 얻을 수 있게 됨
- FCN의 이런 특징 맵 사이즈 설계 덕분에 딥러닝 네트워크의 입력 이미지 크기를 제한하는 제약에서 벗어남
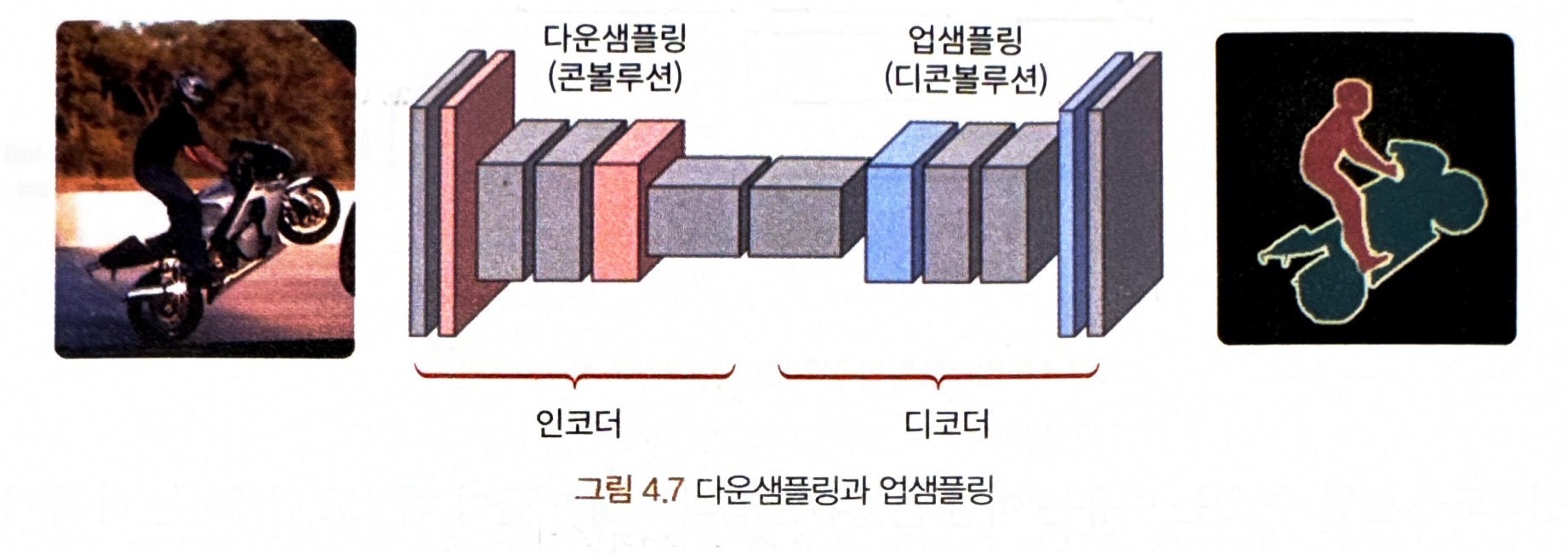
2) 디콘볼루션
= 이미지 분할의 결과물을 위해 덴스 결과 맵이라고 하는 해상도가 높은 상태로 만들어주는 과정
- FCN에서 콘볼루션 네트워크 레이어를 거쳐 얻어진 출력 특징 맵을 이용한 이미지 분할의 결과물은 이미지 원본 크기에서 픽셀 단위 예측에 사용하기엔 해상도가 너무 부족 --> 이 상태를 '거친 결과 맵'(coarse output map)
<거친 맵에서 원래 이미지 크기로 복원하기 위해 덴스 맵으로 변경하는 과정>
- 특징 맵을 만드는 과정인 다운샘플링과 대비해 업샘플링이라고 표현
- 업샘플링 과정을 통해 각 클래스에 해당하는 거친 맵을 원래 사이즈 크기로 키워줌
* 최종적인 분할 맵을 만드는 방법
= 업샘플링된 특징 맵을 종합해서 각 픽셀당 확률이 가장 높은 클래스를 선정하는 것
** 단순히 업샘플링을 시행하면 특징 맵으로부터 원래 이미지 크기의 분할 맵을 얻게 되지만, 여전히 거친 상태 --> 스킵 컴바이닝 기법 제안 !!
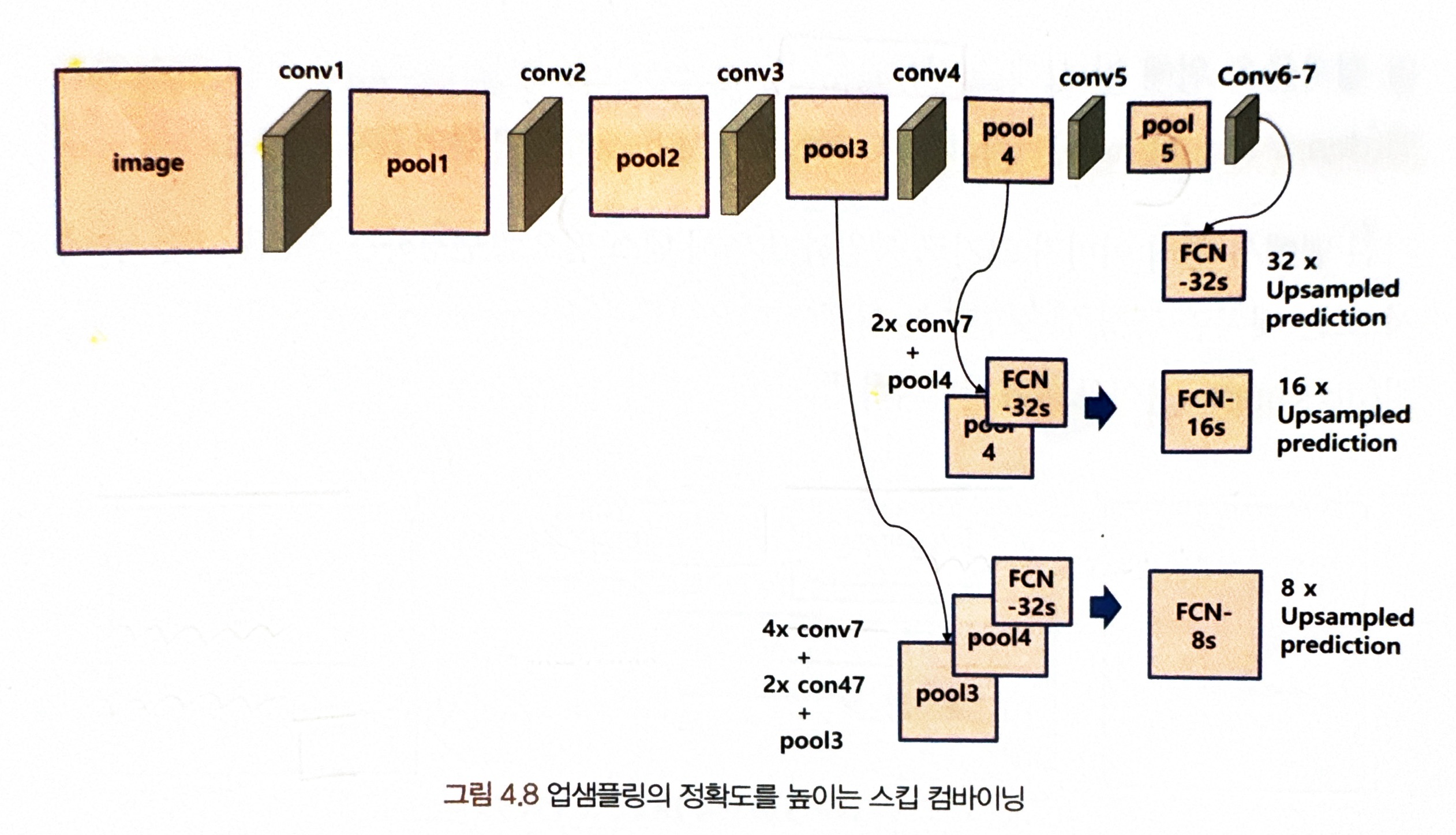
3) 스킵 구조
= FCN은 더 상세한 분할 맵을 얻기 위해 스킵 컴바이닝 기법을 제안
= 스킵 컴바이닝은 콘볼루션과 풀링 단계로 이뤄진 이전 단계의 콘볼루션 층의 특징 맵을 참고해 업샘플링해 줄 때 정확도를 높이는 방법
정확도를 높일 수 있는 이유
= 이전 콘볼루션 층의 특징 맵들이 해상도 면에서는 더 좋기 때문
- FCN-16s는 마지막 특징 맵(conv7)을 2배 업샘플링한 후 바로 전 Conv 계층의 특징 맵(pool4)과 더해줌
--> 그 결과(pool + 2 x conv7)를 16배 업샘플링해서 얻은 특징 맵으로 분할 맵을 얻음
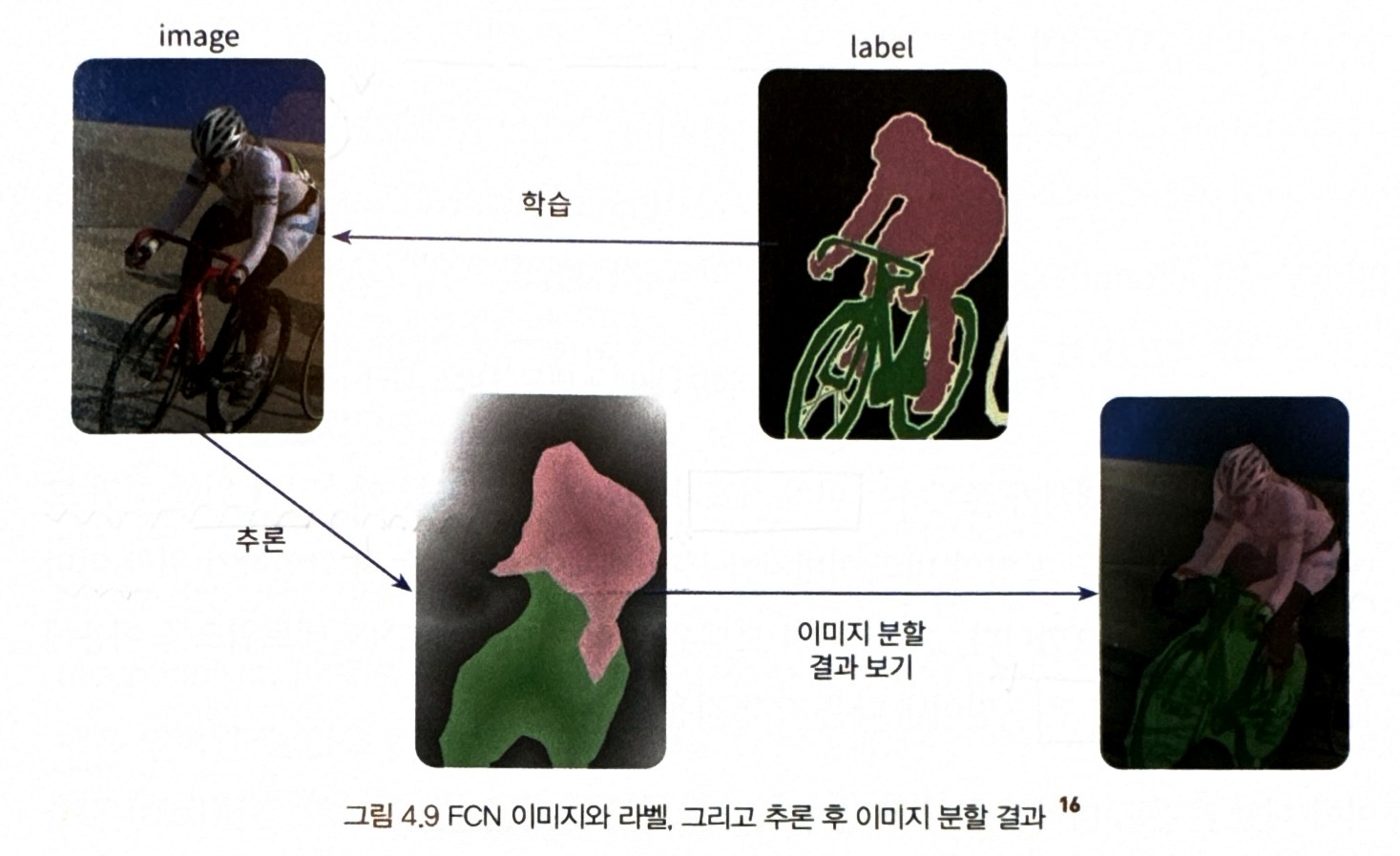
* FCN의 훈련을 위한 이미지와 라벨, 모델 훈련이 완성된 후 추론한 이미지 분할 결과
이러한 FCN의 연구 결과로, 향후 CNN 이미지 분석을 하기 위해 얻은 중요한 개념
1. 콘볼루션 과정의 입력은 사이즈 제약이 필요 없다.
2. 콘볼루션의 결과인 특징 맵에는 사물의 위치 정보가 들어 있다.
3. 최종 특징 맵뿐 아니라 중간 레이어의 특징 맵도 유용하게 이용할 수 있다.
2. 이미지 객체 인식(Object Dectection)
- 이미지 객체 인식의 목표 : 이미지에 있는 객체 중 원하는 클래스에 속하는 객체를 찾아 그 위치를 이미지상 좌표계에서 바운딩 박스로 나타내는 것
이미지 객체 인식의 기본 개념은 ?
= 객체 인식은 한 이미지에 여러 클래스의 객체가 동시에 존재하는 상황을 가정
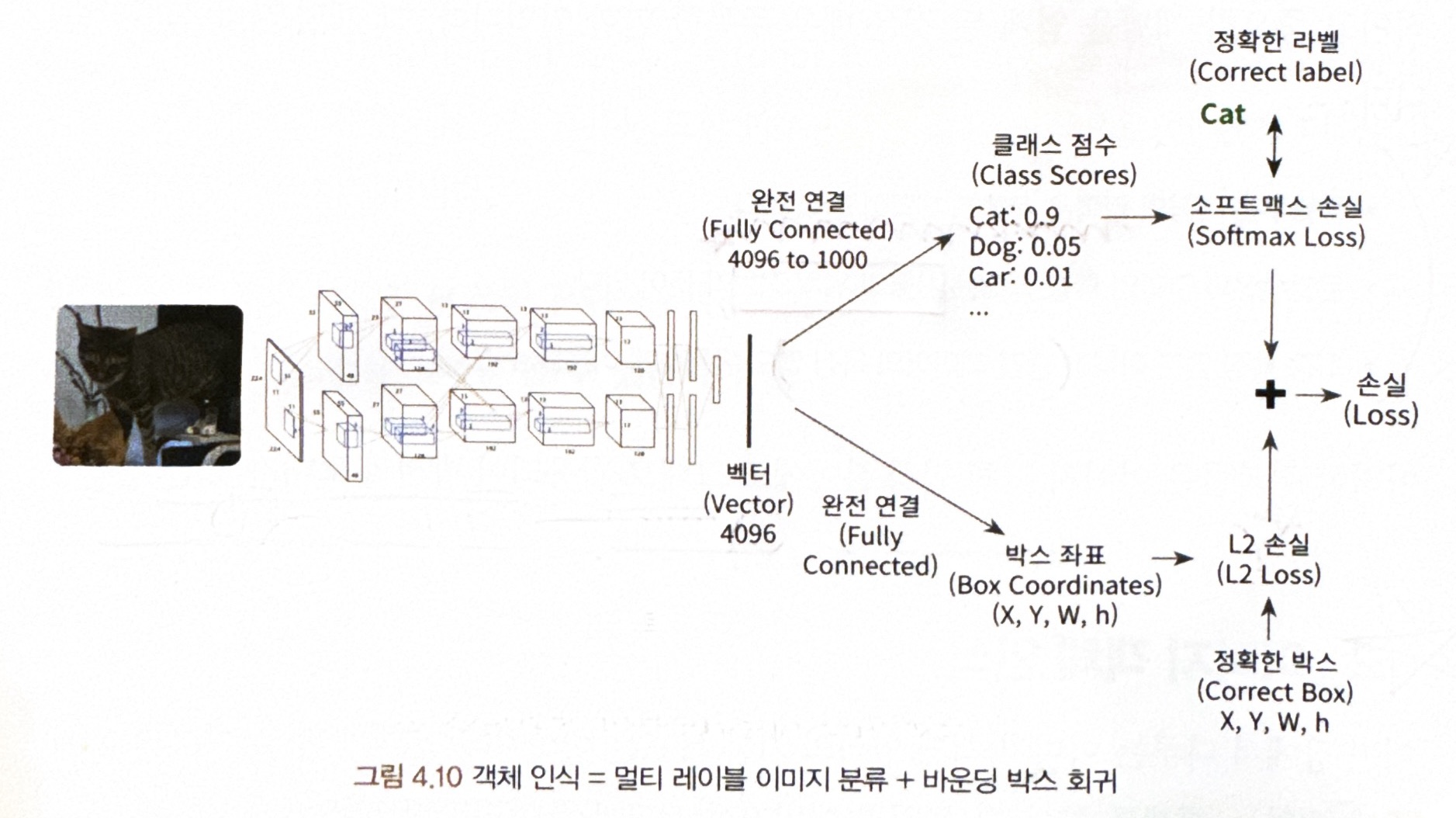
= 즉, 멀티 레이블 이미지 분류와 바운딩 박스 회귀의 두 기능이 합쳐있음
** 객체 인식 = 멀티 레이블 이미지 분류 + 바운딩 박스 회귀
1단계) 필요한 모델 : 회귀 모델 & 분류 모델
= 두 가지 모델은 입력 이미지에 CNN 네트워크를 이용해 특징이 추출된 특징 맵을 얻어낸 다음에 각각 적용 가능
- 회귀 모델 : 이미지 내에 특정 객체가 존재하는 위치 좌표가 있다면, 그 좌표를 예측하기 위한 모델 필요
- 이미지 분류 모델 : 좌표 영역 내의 이미지가 특정 객체에 해당하는지 확인하기 위한 모델 필요
2단계) 모델 훈련
= 이미지 분류 모델과 회귀 모델에서 계산된 각각의 손실 값을 더해 얻은 전체 손실 값을 경사 하강법으로 감소시키면서 진행됨.
3단계) 손실 값의 최소화
= 손실 값의 최소화가 이뤄지면 최종적으로 이미지 객체 인식 모델이 완성
** 객체 인식 과정에 필요한 과제
1) '이미지 내에 특정 객체가 존재하는 위치 좌표'를 최초에 어떻게 얻어내는지에 대한 것
2) 두 가지 모델을 적용하기 위해 우선 CNN 네트워크로 특징 맵을 추출해야 하는데, 어떤 네트워크를 이용할지 선택 필요 ( 특징 맵을 얻어내는 CNN 네트워크의 선택은 객체 인식 모델의 성능에 중요!!!)
AlexNet 이후 CNN 네트워크가 발전하는 동안 이미지 객체 인식 분야에서 연구가 활발히 일어남
< 객체 인식 네트워크의 발전 >
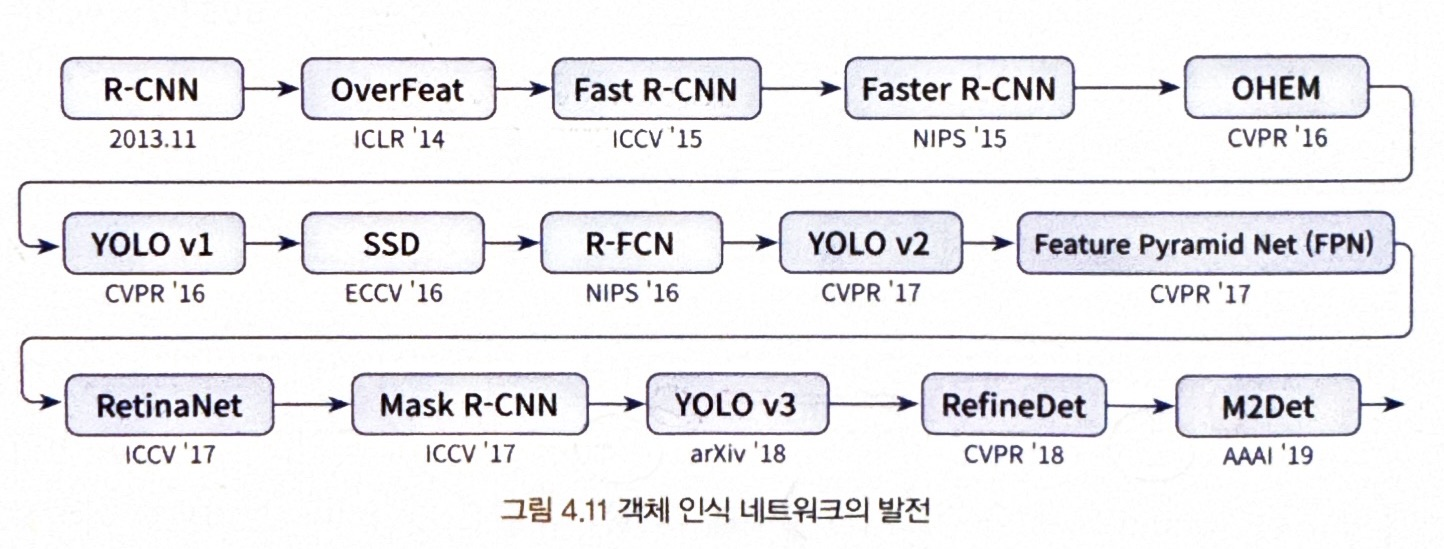
= 이렇게 발전하는 상황 속에서도 객체 인식 기술의 활용이 진입 장벽이 높기에 쉽지 않음!!
** 객체 인식 기술이 쉽지 않은 이유
1) 이미지에서 특정 대상을 검출하고자 할 때 멀티 레이블 이미지 분류와 바운딩 박스 회귀를 위한 기본적인 영역을 정하기 어려움
2) 이미지 내에서 대상 객체의 존재 여부, 개수 및 위치를 알지 못한다면 객체 인식 자체를 어떻게 시작할지 결정하기 어려움
** 객체 인식은 산출 결과의 수를 예측하기 어렵다는 문제가 있다.

만약에 첫 번째 문제점이 없어 이미지에 대상 객체가 존재하는 기본 영역이 있다면 ?
= 그 기본 영역에서 차례로 원하는 대상이 있는지에 대한 분류 모델 & 정확한 영역인지에 대한 회귀 모델,
이 두 가지 모델에 대한 다중 손실을 감소시키기 위한 훈련을 할 수 있음--> 이미지 객체 인식을 위해선 대상 객체들의 탐색을 위한 영역 제안이 필요 !!!
- 전통적인 영역 제안 : 슬라이딩 윈도(sliding window) or HOU(Histogram of Oriented Gradients) 알고리즘 기반의 영역 제안 방식을 적용한 셀렉티브 서치 기법
* 셀렉티브 서치 기법이란 ?
= CPU에서 계산되는 알고리즘이며, CNN과 무관하게 외부에서 진행하는 프로세스 - Fast R-CNN : 딥러닝을 적용한 객체 인식 네트워크로서 최초로 성공적으로 평가됨 , 영역 제안에 셀렉티브 서치 방법을 활용
--> Fast R-CNN 의 문제점 : 테스트 시간이 길게 소요됨 (개선 필요!! ; Faster R-CNN)
Faster R-CNN이란?
= 객체 인식을 위한 통합 네트워크
= 두 개의 모듈로 구성되며 첫 번째 모듈은 영역을 제안하는 네트워크이고, 두 번째 모듈은 FCN에서 제안된 영역을 사용하는 Fast R-CNN 검출기이다.
<Faster R-CNN의 영역 제안 과정>
1단계) 영역 제안을 위해 마지막 특징 맵 위로 작은 네트워크를 이용
2단계) 작은 네트워크는 입력 특징 맵의 N x N 공간 창을 입력받아 영역을 제안
3단계) 영역 제안한 결과는 바운딩 박스를 위한 회귀 계층과 분류 계층에 제공
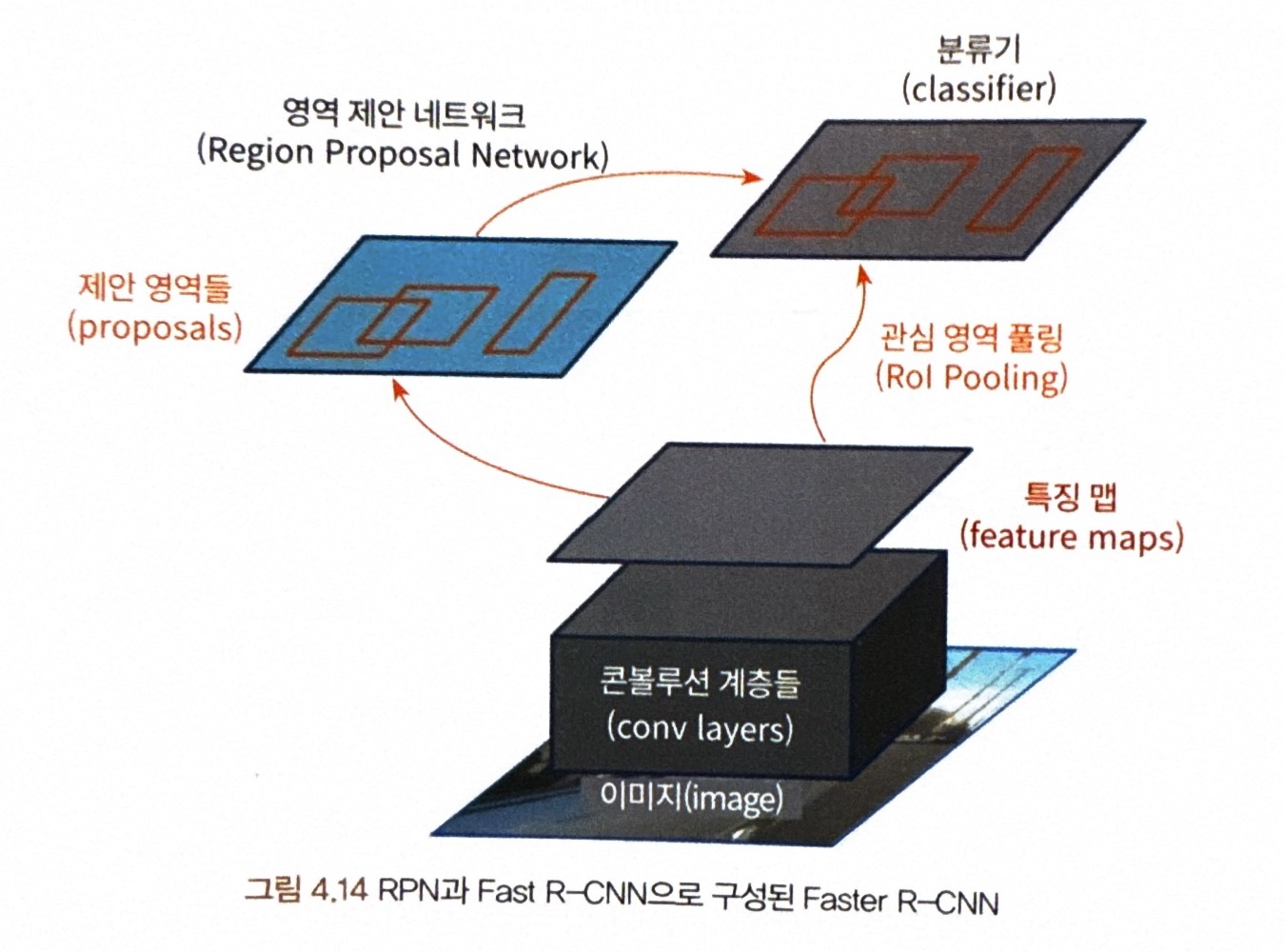
- Faster R-CNN은 GPU의 이점을 최대한 활용하고 CNN 내부에서 진행하기 위해 RPN(영역 제안 네트워크: Region Proposal Network)을 도입
* RPN 이란 ?
= 이미지를 입력받아 사각형 형태의 각 위치의 객체 경계(object bounds)와 사물의 존재 점수(objectness score)를 동시에 예측하는 FCN
- Fast R-CNN 객체 탐지 네트워크와 CNN 레이어들을 공유하는 구조임.
결론 ) Faster C-RNN은 하나의 network(RPN)으로 detection을 수행하는 방법으로 특징 맵을 RPN에 통과시켜 bounding box를 출력
### <앵커박스> = 슬라이딩 윈도의 각 위치에서 바운딩 박스의 후보로 사용되는 상자 - **사용되는 방식** : 동일한 크기의 슬라이딩 윈도를 이동하며, 윈도의 위치를 중심으로 사전에 정의된 다양한 비율/크기의 **앵커 박스를 적용해 특징을 추출**하는 것 > #### 특정 앵커가 검출 레이블(positive lable)로 할당되려면 ? > - 조건1 : 해당 앵커(anchor)가 가장 IoU를 가져야함 > - 조건2 : 조건1 만족 & IoU > 0.7 만족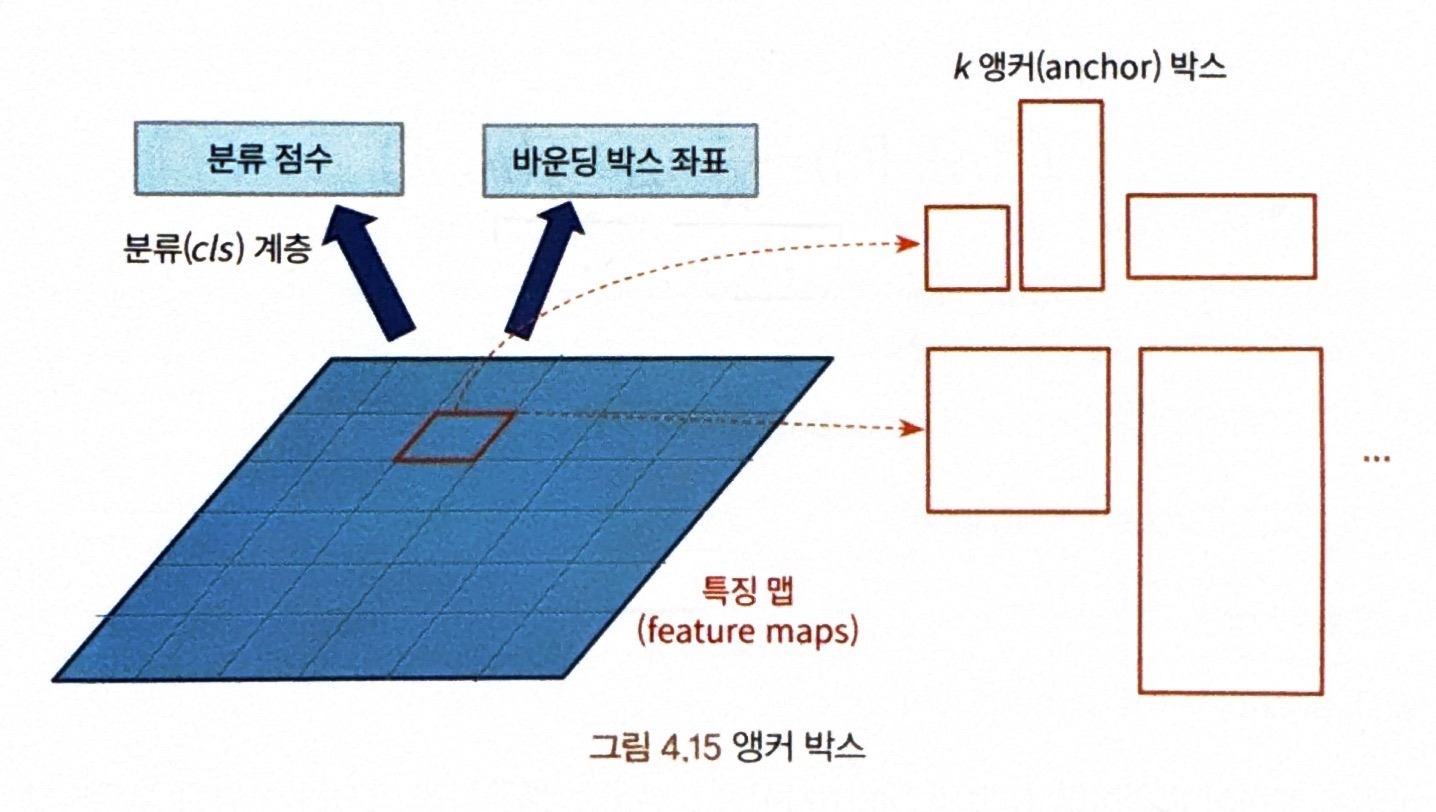
<학습>
= Faster R-CNN은 RPN과 Fast R-CNN 간에 특징을 공유하기 위해 4단계에 걸쳐서 모델을 번갈아 학습시키는 대체 학습(Alternating Training)기법을 적용
* 대체 학습 단계
1단계) ImageNet 데이터세트로 미리 훈련된 모델을 불러온 다음, RPN을 학습시킴
2단걔) 1단계에서 RPN에서 제안된 결과를 이용해 Fast R-CNN을 학습시킴
3단계) 공유하고 있는 CNN 레이어를 고정해 RPN을 위한 레이어만 미세 조정
4단계) 마지막으로 Fast R-CNN에 해당하는 레이어만 미세 조정
<손실 함수>
* RPN의 손실 함수

<결과>
- Faster R-CNN은 영역 제안에 대한 작업을 RPN을 넘김으로써 추론 시간이 기존 방법보다 시간 단축 !
- 2개의 네트워크에서 이뤄지는 바운딩 박스 회귀의 결과로 현재까지도 매우 높은 정확도를 가진 객체 인식 네트워크라는 평가를 받음
3. YOLO : 최초의 실시간 객체 인식 네트워크
- Faster R-CNN의 객체 검출 기본 기능은 분류와 바운딩 박스 회귀를 수행하는 Fast R-CNN과 후보 영역에 객체가 있는지 판단해 제안해 주는 RPN의 두 가지로 네트워크가 구성
--> 정확도는 뛰어나지만, 작업 시간이 길어지는 단점이 존재
--> 즉, 실시간 객체 인식을 하기 어려운 구조!! - YOLO가 제안하는 실시간 객체 인식 방안은 Fast R-CNN, RPN 두 가지 네트워크를 하나로 합해 효율성을 극대화
* 대표적인 객체 인식 네트워크
- 투 스테이지 네트워크(ex:Faster R-CNN) : 정확도 높음 but 느림
- 원 스테이지 네트워크(ex:YOLO,SDD) : 빠름 but 정확도 떨어딤
--> 근래 들어 원 스테이지의 경우에도 정확도 크게 향상
1) YOLO: 최초의 실시간 객체 인식 네트워크
= 이미지를 한 번에 단일 신경망에 통과시켜 바운딩 박스의 위치와 크기, 신뢰도 점수, 그리고 클래스를 예측하는 방법
** 아래 사진과 같이 하나의 네트워크에서 후보 영역에 있는 객체가 있는 판단하는 객체성을 이미지 분류와 바운딩 박스 회귀와 함께 진행하는 것!!
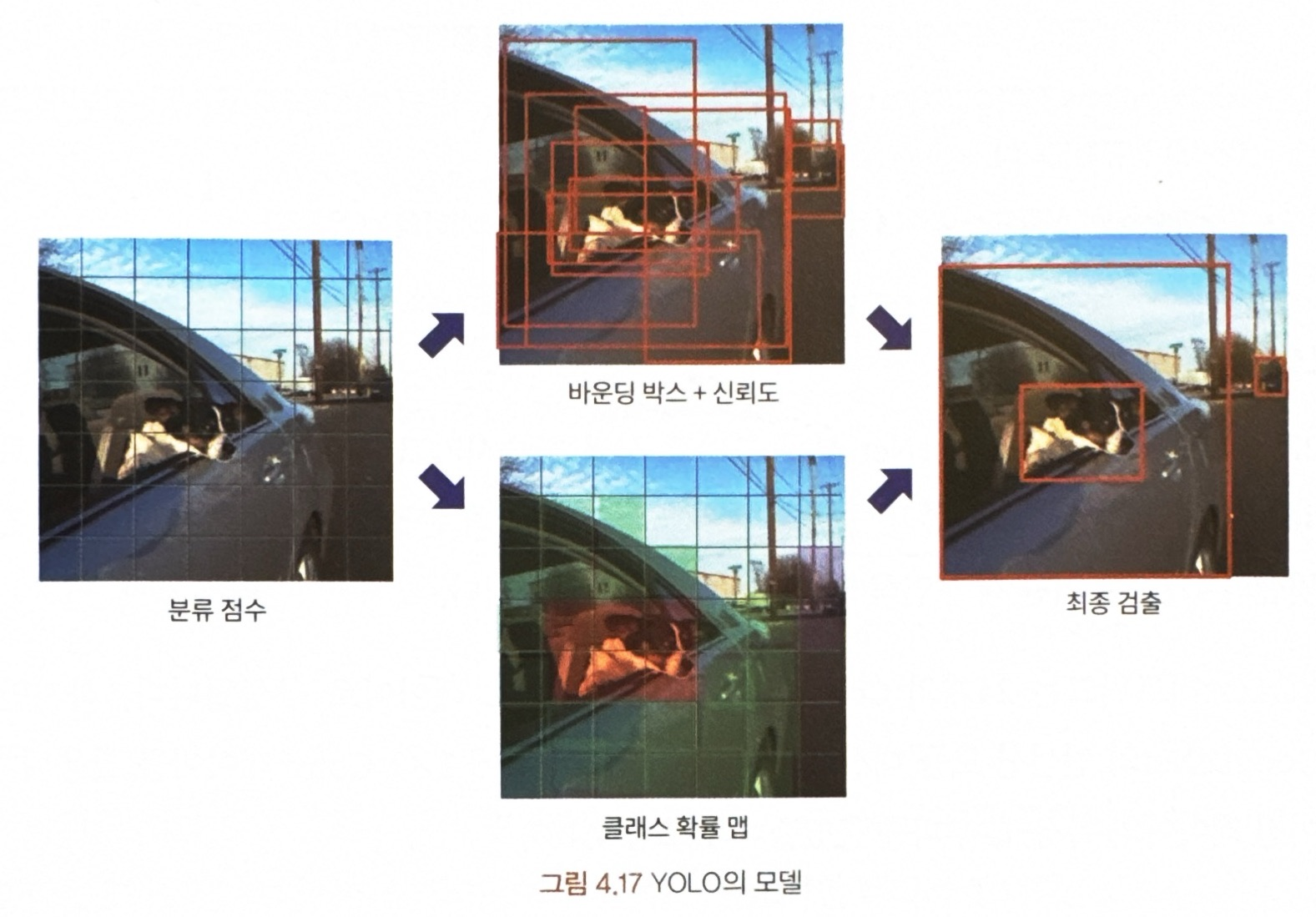
<모델>
1단계) 입력 이미지를 S x S 그리드 영역으로 나눈 후 각 그리드 영역에서 먼저 물체가 있을 만한 후보 바운딩 박스를 B개 예측
2단계) 각 후보 박스에서 신뢰도(confidence)를 계산
* 신뢰도 점수 수식
= 해당 그리드에 물체가 있을 확률 Pr(Object)과 예측한 박스와 정답(ground truth) 박스가 겹치는 영역의 비율을 나타내는 IoU를 곱해서 계산함.
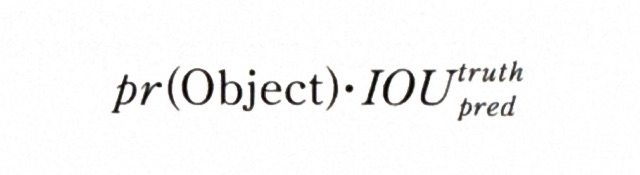
3단계) 그리드마다 C개의 클래스에 대해 해당 클래스가 될 확률을 계산함
* 클래스 확률 수식

결론) YOLO 모델은 입력 이미지를 그리드로 나누고, 그리드별로 바운딩 박스 회귀와 분류를 동시에 수행함
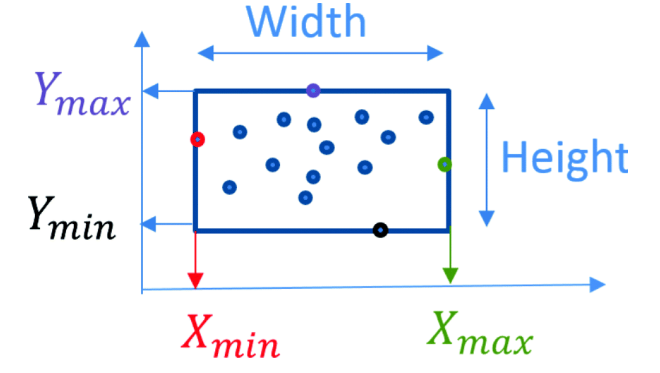
* 바운딩 박스의 구성
- x,y좌표 : 바운딩 박스의 중심점 좌표로, 그리드 셀 안에서 정의되며 0~1로 정규화된다
- width, height : 전체 이미지의 너비, 높이의 비율로 정의되는데, 바운딩 박스의 크기를 나타내며, 0~1로 정규화
- Confidence : 신뢰도는 예측된 바운딩 박스와 정답 바운딩 사이의 IoU 임.
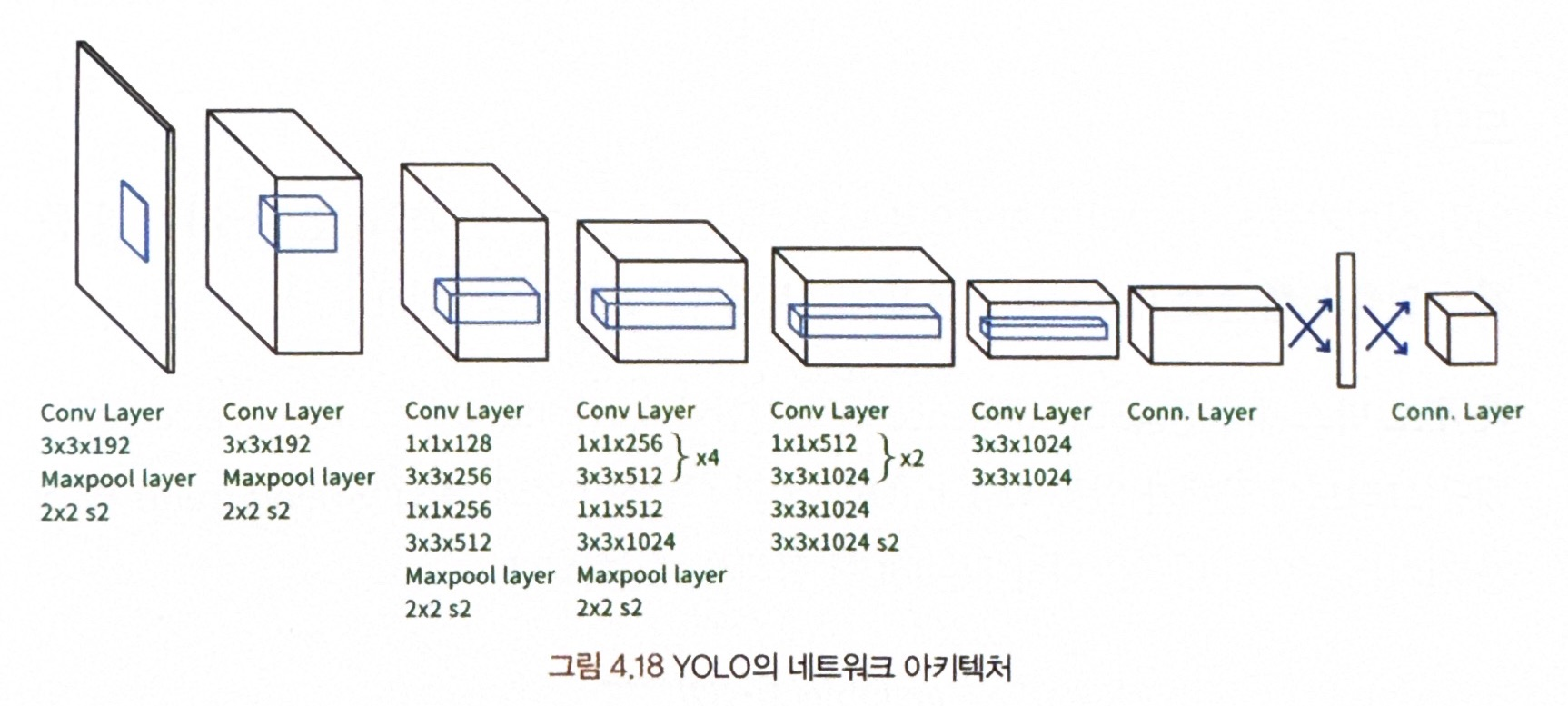
<네트워크 설계>
- 2224 x 224 크기의 GoogLeNet 분류 모델로 사전 학습시키고, 이후에는 입력 이미지로 448 x 448 크기의 이미지를 받음
- 앞쪽 20개의 콘볼루션 레이어는 고정한 채, 뒷단의 4개의 레이어만 객체 인식 테스크에 맞게 학습
- YOLO 네트워크는 24개의 Conv 레이어와 2개의 FC 레이어로 구성됨.
--> GoogLeNet의 인셉션 모듈 대신 3 x 3 Conv 레이어 뒤에 1 x 1 Conv 레이어를 활용해 이전 레이어의 특징 맵 부피를 줄임.
- ImageNet 분류 작업에서 해상도의 절반(224 x 224 입력 이미지)으로 콘볼루션 계층을 통해 사전 훈련함 (검출할 땐 시각적 정보를 위해 해상도를 448 x 448로 증가시켜야함.)
ex) 입력 이미지를 7 x 7 그리드 영역으로 나누고 각 그리드 영역에서 바운딩 박스를 2개 예측한다고 하고, 그리드마다 20개의 클래스가 있다고 가정하자
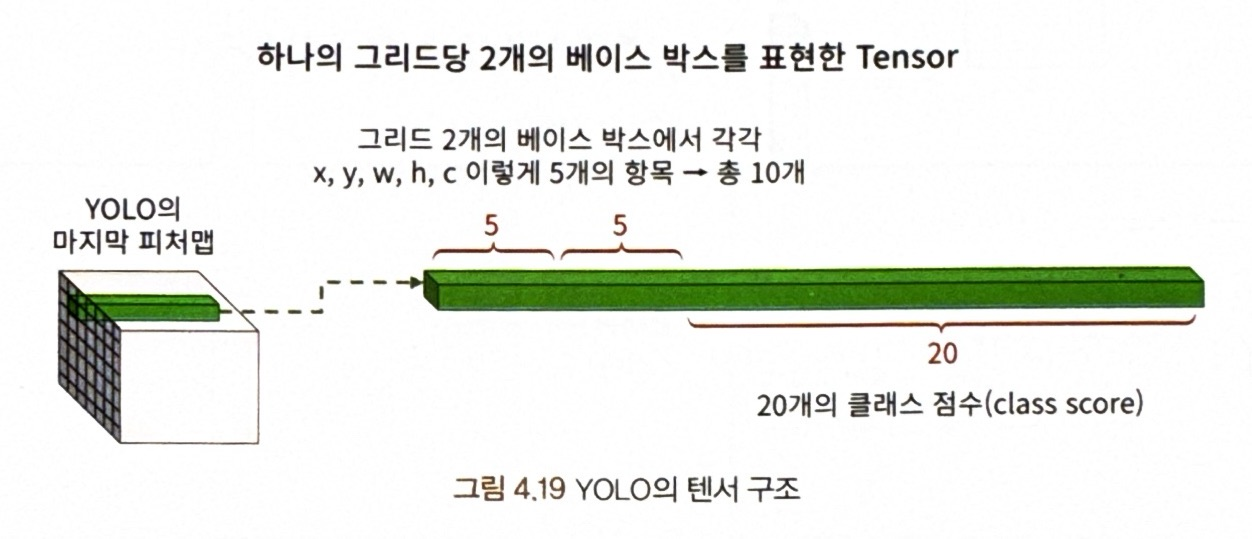
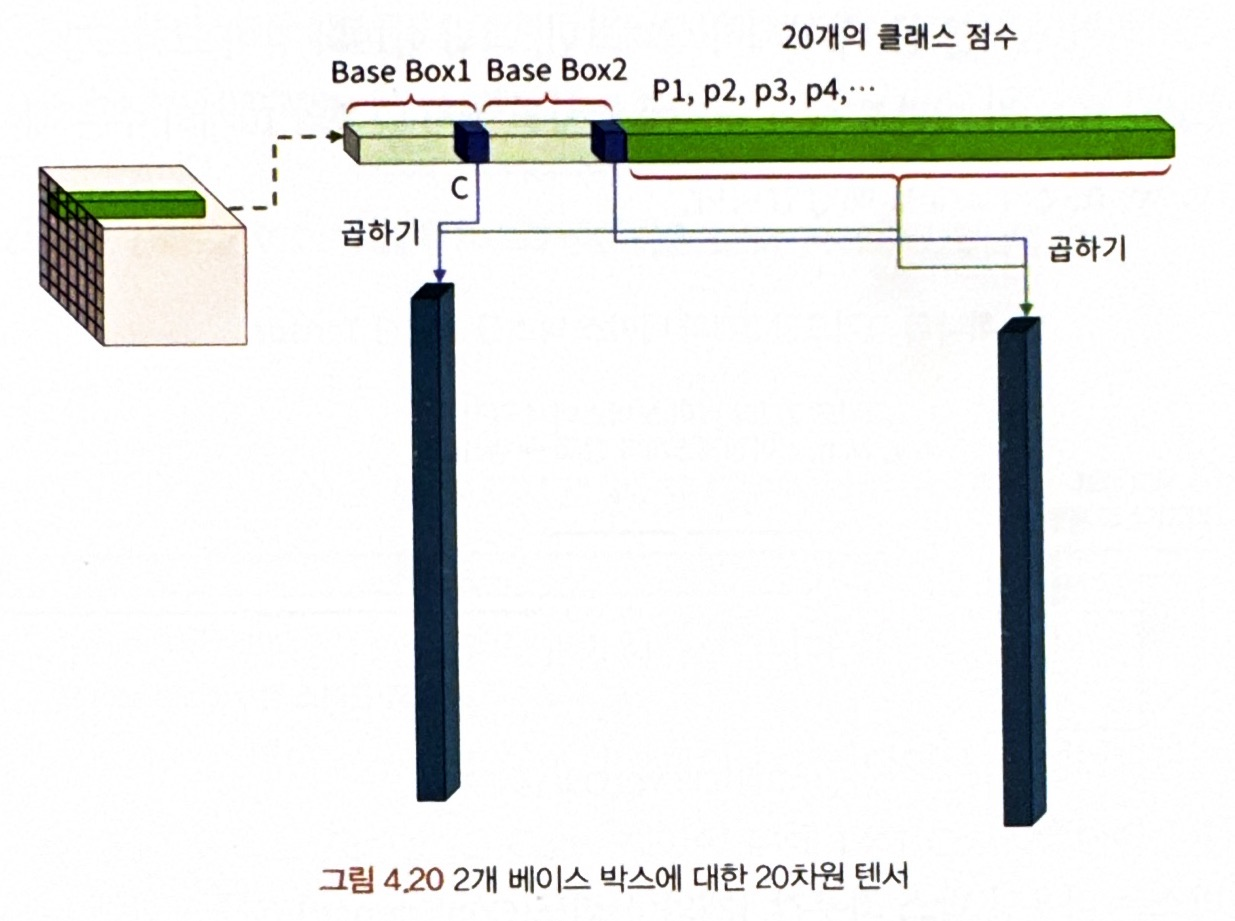
--> 이 모델의 마지막 레이어의 결과는 7 x 7 x 30 텐서가 됨.
* YOLO의 마지막 레이어 텐서 구조
- 그리드당 2개의 베이스 박스(=앵커박스)가 있다고 했으니, 30차원 벡터 앞쪽의 10개의 수는 베이스 박스 항목 x,y,w,h,c의 2개에 해당
- 하나의 박스는 바운딩 박스 좌푯값 4개와 신뢰도 C를 포함해 (x,y,w,h,C)라는 5차원의 벡터
- 박스가 2개이기 때문에 10차원 벡터가 됨.
- 20차원 벡터(=클래스 갯수) : 해당 인덱스가 특정 클래스일 확률값
<클래스 점수 구하는 방법>
** 특정 클래스일 확률값 = 각 박스의 신뢰도를 클래스별 확률값과 곱해서 얻음
- 박스의 신뢰도 : Pr(obj) * IoU
- 클래스별 확률값 : Pr(class i | object) --> 조건부 확률 : 이 박스에 객체가 존재할때, 그 객체가 클래스 i일 확률
* 결론) {Pr(obj) IoU} {Pr(class i | object)}
= {Pr(obj) Pr(class i | object)} IoU
= Pr(class i) * IoUPr(obj) * Pr(class i | object) 이 Pr(class i)인 이유
= 객체가 존재하고 & 객체가 존재할때 그 객체가 클래스 i일 확률은 즉, 그 객체가 클래스 i일 확률 = Pr(class i) - 이 작업을 모든 베이스 박스마다 적용함
- 이러한 베이스 박스의 클래스 점수 벡터를 7 x 7 그리드 숫자만큼 시행하면 2 x 7 x 7개의 벡터를 얻음
- 이제 내림차순 정렬을 한 후 마지막으로 NMS 과정을 거치면 각 그리드별, 클래스별로 가장 신뢰도가 높은 박스 정보를 얻어낼 수 있음
NMS(Non Maximum Suppression)란 ?
= 다수의 제안된 영역에서 몇 가지 기술에 따라 필터링하는 기술
* NMS 알고리즘은 그림과 같이 객체 인식의 결과를 나타낼 때 필요한 과정- 입력 : 제안된 영역 목록 B, 해당 신뢰도 점수 S, 중첩 임곗값 N
- 출력 : 필터링된 영역 목록 D. (초깃값은 비어 있는 상태)

- 임곗값에 따라 결과가 달라질 수 있기에 객체 인식 모델에서 임곗값의 선택은 중요한 과정
<손실함수>
= 객체 인식에 사용되는 여러 가지 성분에 대한 오차를 별도로 구한 후 모두 더해 총 손실을 구하는 방식
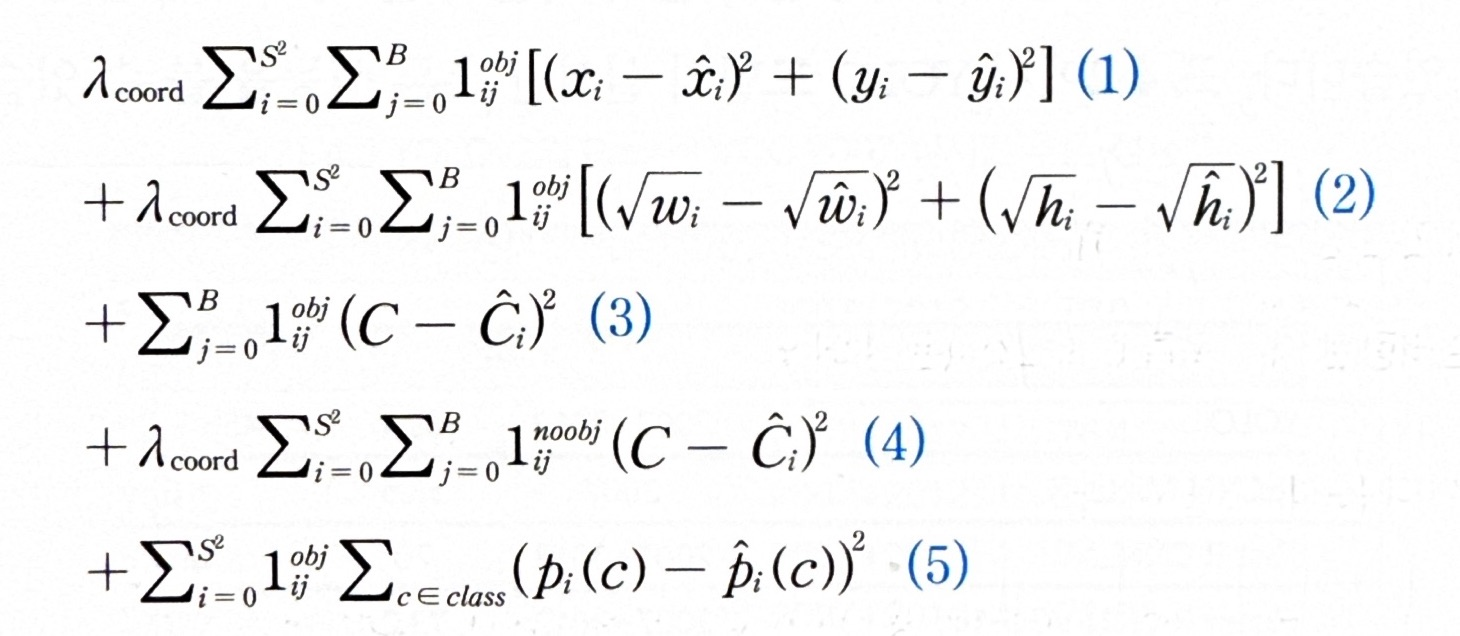
(1) : 그리드에 있는 객체의 바운딩 박스 중 x,y 좌표 오차
(2) : 그리드에 있는 객체의 바운딩 박스 중 w,h 좌표 오차
(3) : 객체가 있는 경우에 대한 신뢰도 오차
(4) : 객체가 있는 경우에 대한 신뢰도 오차
(5) : 클래스별 확률값 오차
<결과>
* YOLO의 장단점
<장점>
1. 빠르다
2. 다른 알고리즘과 비슷한 정확도를 가짐
3. 다른 도메인에서 좋은 성능을 보임
<단점>
1. 각 그리드 셀은 하나의 클래스만을 예측하기 때문에 객체가 겹쳐 있으면 제대로 예측하기 어려움
2. 바운딩 박스의 형태가 트레이닝 데이터를 통해서만 학습되므로 새로운 형태의 경우 정확히 예측 X
3. 박스 위치가 다소 부정확하다
2) YOLOv2: 더 좋은, 더 빠른, 더 강력한
= YOLOv2 는 네트워크의 크기를 조절해 FPS(Frame Per Second)와 mAP(Mean Average Precision)을 균형있게 조절할 수 있음.
- 어떤 경우에도 SSD의 성능을 능가함
* YOLOv2의 성능 향상 요인

<배치 정규화>
특징 맵을 채널별로 정규화하기 위해 미니 배치 단위로 특징 맵의 각 채널의 평균과 표준 편차를 구한 다음 이 평균과 표준 편차를 이용해 정규화함.
** 배치 정규화의 핵심
1단계) 정규화된 특징 맵에 다시 한번 채널별로 감마를 곱해주고 베타를 더해주는 식을 만들어줌
2단계) 만들어준 식을 배치 정규화 레이어로서 CNN 네트워크에 추가해줌
3단계) 역전파 과정을 통해 훈련 시간동안 최적화함.
<고해상도 이미지 분류>
객체 인식 네트워크에서 크게 권장되는 방법으로 2단계 학습 방법이라고 함.
* 과정
1단계) Darknet-19를 이미지 분류 네트워크로 사용해 이미지넷 데이터를 10에포크로 학습시킴
2단계) 학습시킨 마지막 Conv 레이어와 평균 풀링(Avgpool), 소프트맥스를 제거하고 객체 인식 레이어 4개를 추가
** 이 최종 네트워크로부터 2단계 학습인 바운딩 박스와 객체 검출에 대한 학습이 되는 형태
- 2단계로 나눠서 학습하는 이유 : 처음부터 바운딩 박스와 클래스 분류를 같이 학습시키기 어려워 전이학습 기법을 사용
- 전이학습 : 네트워크의 앞 단을 선행학습 시키고 2단계 학습 과정에서 앞쪽 레이어의 가중치를 미세 조정하는 것
<콘볼루션과 멀티 스케일링 훈련>
= YOLOv2는 FCN 방식을 도입해 입력 레이어와 특징 맵의 크기를 원하는 방식으로 조절할 수 있게 했음
추론 속도도 향상되고, 최종 그리드 셀들의 수용 영역(receptive field)이 더 커지는 효과도 생김
--> 수용 영역이란 ? 출력 레이어의 뉴런 하나에 영향을 미치는 입력 뉴런들의 공간 크기
변화된 것
- 최종 특징 맵의 크기가 홀수가 됨
--> 그리드 셀이 특징 맵의 중앙 부분에 위치
--> 중앙 그리드 셀은 이미지에서 중앙의 객체를 검출하는데 효과적
ex) 객체의 크기가 매우 큰 경우 그 위치가 영상의 중앙인 경우가 많음- YOLOv2는 FCN이기에 다양한 해상도로 입력 이미지를 취할 수 있음
--> FCN에선 CNN 최종 특징 맵까지 진행하면서 이미지를 1/32로 줄이는 구조이므로 입력 이미지가 커지면 최종 그리드의 셀 크기가 커짐.
<앵커박스와 차원 클러스터>
= 앵커박스를 이용하면서 공간 위치로부터의 클래스 예측 메커니즘도 분리함(=차원 클러스터)
(모든 앵커 박스에 대해서 그것이 객체일 확률을 예측하고 클래스를 분류하는 방식)
- 앵커박스를 이용하면 학습 초기 단계에서 모델이 불안정해지는 문제를 해결가능
- 학습 불안정의 주요 원인 : 학습 초기에 박스의 (x,y) 위치가 너무 랜덤하게 예측되기 때문
- 조건부 확률 이용 : 예측된 바운딩 박스가 객체일 때 그것이 어떤 클래스인지를 예측하기 때문
- 좋은 IoU 점수로 이어지는 k-평균 클러스터링 사용 (k=5가 적절한 균형을 유지하는 최상의 값)
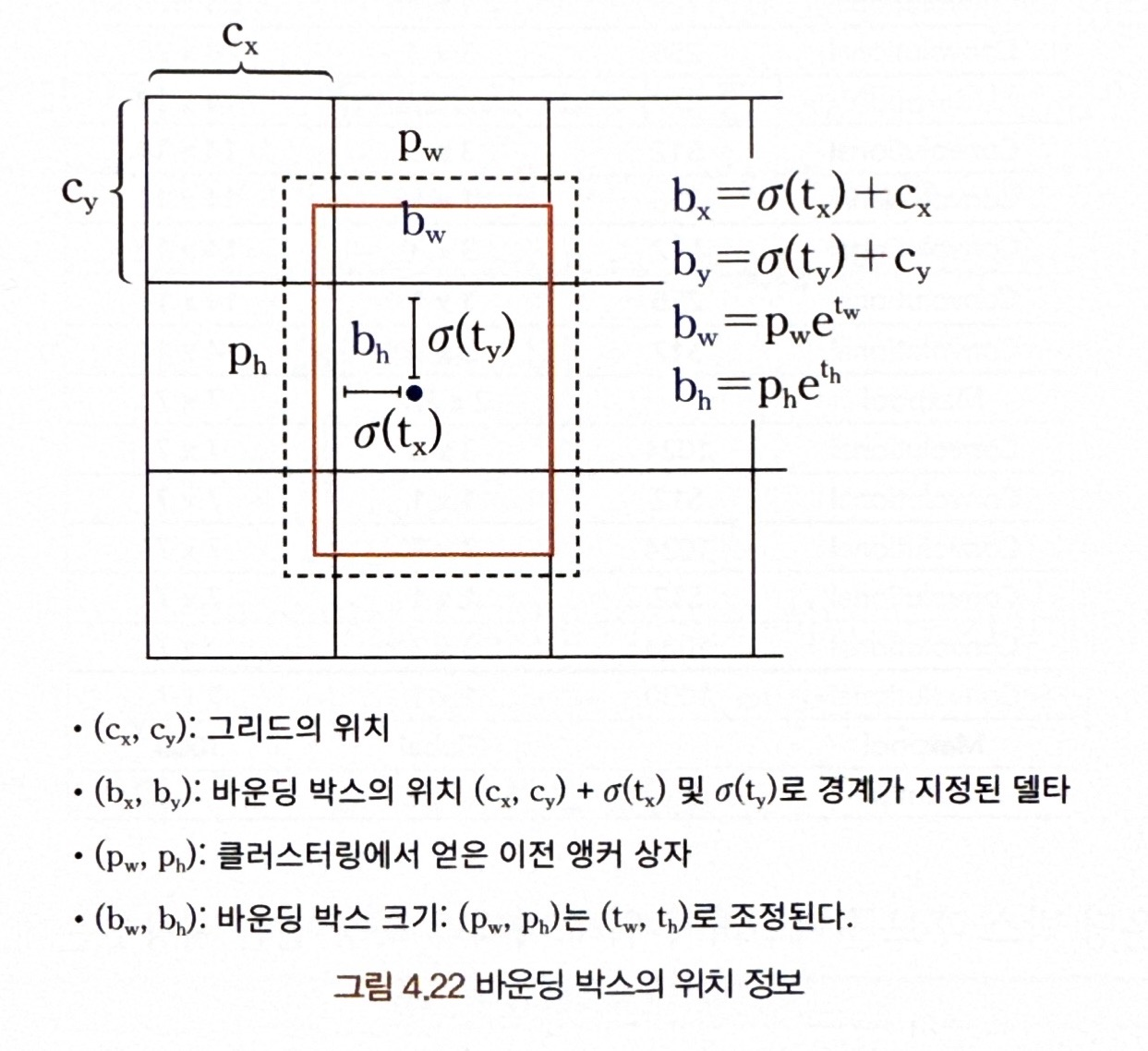
<직접 측위 예측>
YOLOv1에는 위치 예측에 대한 제약이 없기 때문에 초기 훈련에서 불안정성이 있어 예측된 바운딩 박스가 실제 위치에서 멀리 떨어져 있음.
- 그림과 같이 위치 예측 식을 업그레이드함.
<새로운 네트워크와 패스스루 네트워크>
1) 새로운 네트워크, Darknet-19
YOLOv2는 자체 개발된 Darknet-19를 백본 네트워크로 사용해 특징을 추출함
- Darknet-19는 VGG-19와 유사하지만, 연산량이 훨씬 적음.
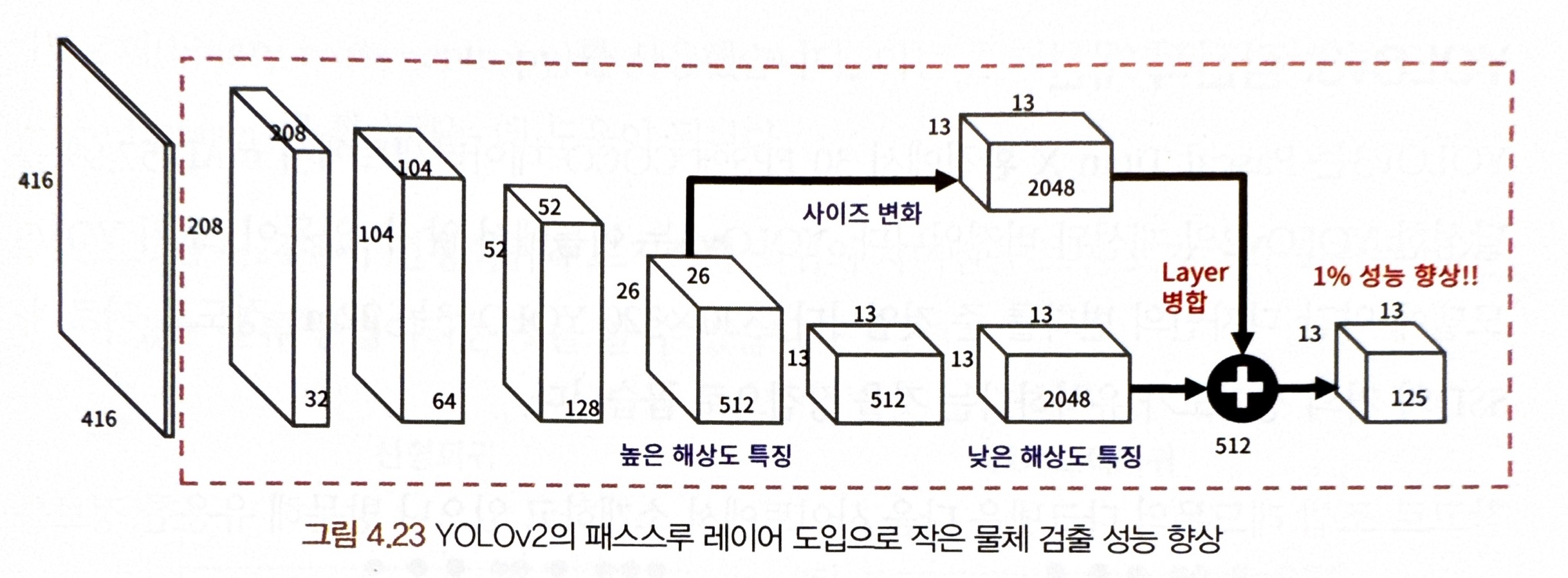
2) 패스스루 네트워크(pass-through)
YOLO는 바운딩 박스 후보를 제안하기 위해 마지막 특징 맵만 사용했는데, 하나의 특징 맵은 검출하고자 하는 대상의 크기에 따라 정보가 불충분할 수 있음!!
= YOLOv2는 이러한 문제에 대한 해결방법으로 패스스루 레이어를 사용
패스스루 네트워크란 ?
= 26x26 크기의 상위 레이어의 특징맵을 하위 레이어의 특징맵 13x13 레이어에 병합(concatenate)하는 방식 사용
- 두 개의 크기가 다른 특징 맵을 붙일 순 없어서 26x26의 특징 맵을 13x13x(2048) 특징 맵으로 변환한 후 26x26 특징 맵의 한 포인트에서 주위 2x2의 데이터를 4채널로 모양을 바꿔줌
최종 성능
기능들을 하나씩 추가할 때마다 성능이 향상되어 YOLOv2가 완성됨
--> 그 결과 YOLOv2 네트워크는 더 작은 크기의 이미지에서 더 빠르게 실행됨
3) YOLOv3: 점진적 개선
초기 YOLO 모델에 약간 디자인의 변화를 준 것
YOLOv3는 SSD 시리즈 네트워크 중 가장 정확하다고 이름난 RetinaNet과 비교해도 더 정확하면서도 빠르다고 함
<바운딩 박스 예측(Bounding Box Prediction)>
= YOLOv3에선 바운딩 박스의 4개 좌표 tx,ty,tw,th를 예측함
- 바운딩 박스, 너비와 높이를 클러스터 중심으로부터의 오프셋으로 예측함
- 필터 적용 위치를 기준으로 상자의 중심 좌표를 예측할 때는 시그모이드 함수를 사용
<클래스 예측(Class Prediction)>
각 바운딩 박스는 다중 라벨 분류를 사용해 경계 상자에 포함될 수 있는 클래스를 예측함.
- YOLOv3에선 소프트맥스 함수 대신 독립적인 로지스틱 회귀를 사용
- 훈련 중엔 클래스 예측을 위해 바이너리 교차 엔트로피 사용(binary cross-entropy)
--> 복잡한 데이터 세트(Open Image Dataset)를 학습하는 데 도움이 됨>
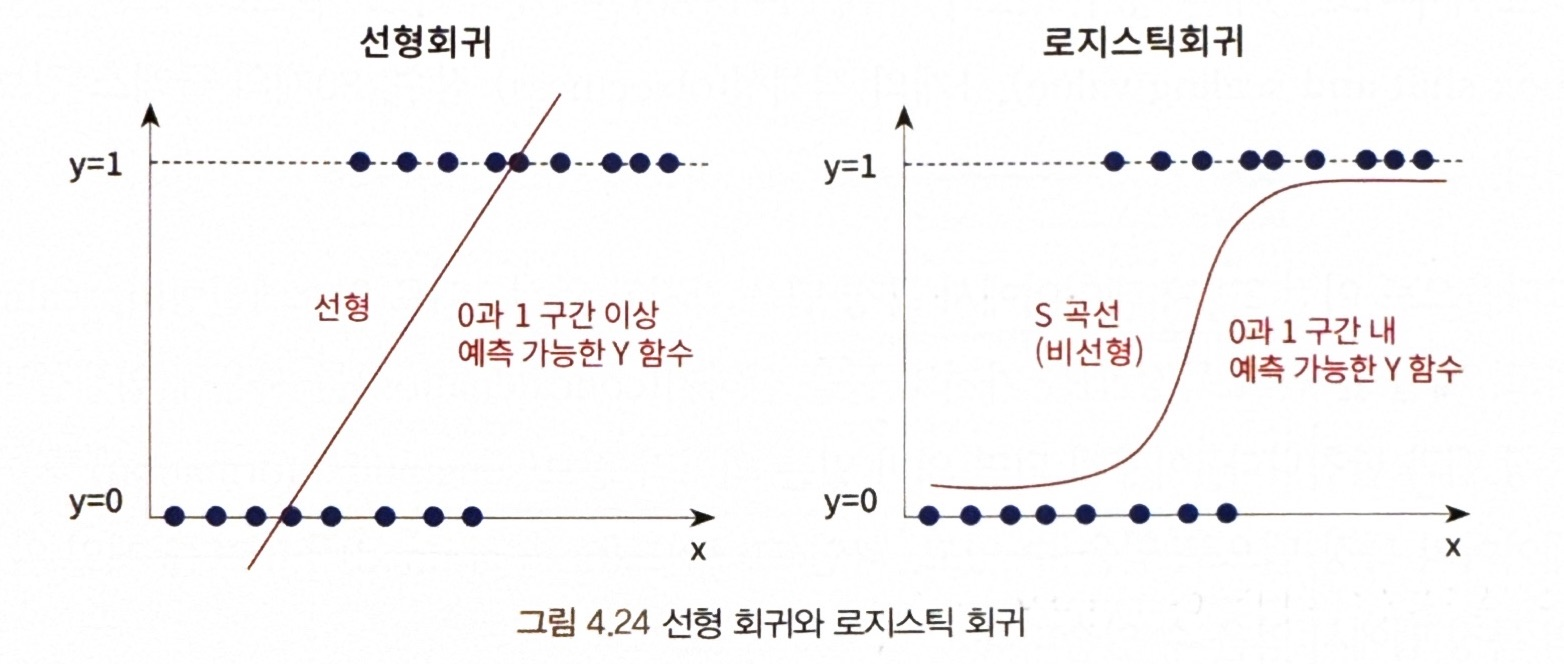
** 로지스틱 회귀란 ?
= 비선형성이 있는 분류 방법
<어크로스 스케일 예측(Across Scales Predictions)>
YOLOv3는 3개의 특징 맵을 사용해 각각에서 3개의 다른 스케일 박스를 예측함 (FCN과 유사)
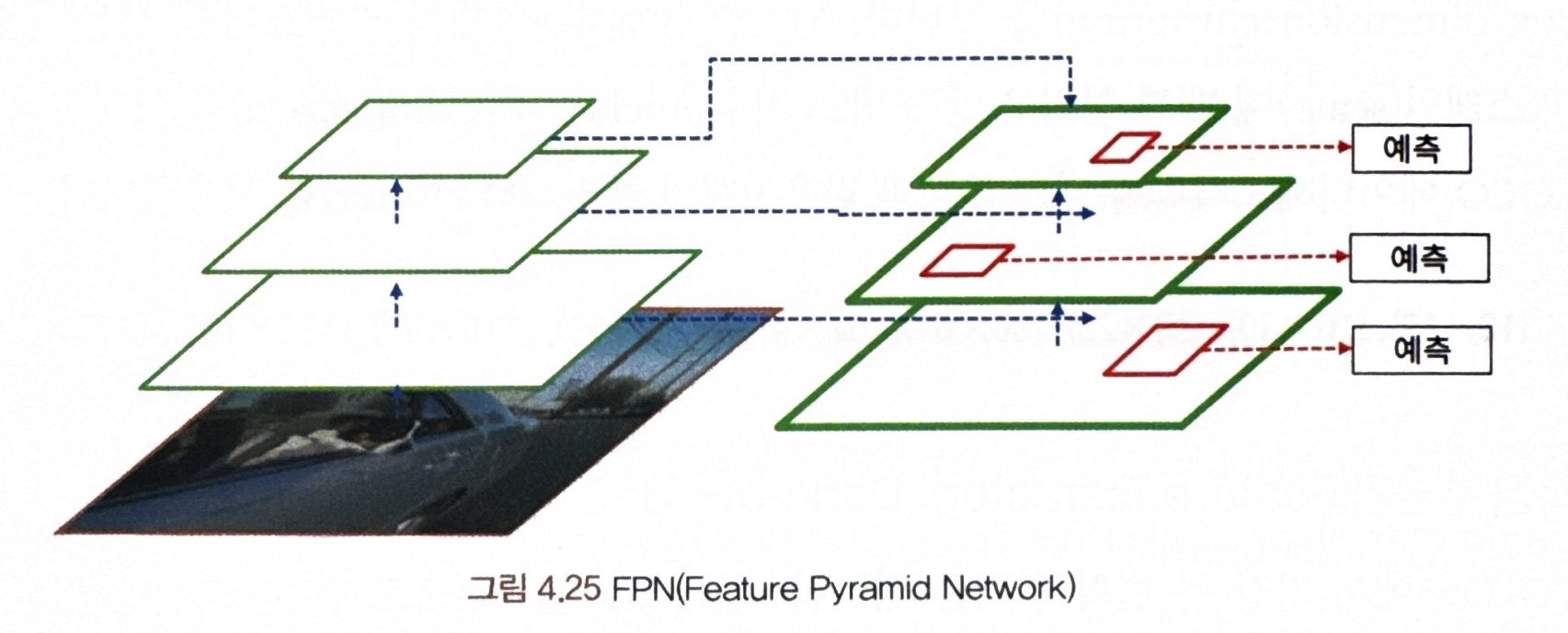
- YOLOv3는 3차원 텐서를 출력값으로 얻는데, 거기에는 박스에 대한 정보와 객체성, 클래스에 대한 정보 존재
ex) COCO 데이터에서 실험한 경우 각 스케일에서 3개의 박스를 예측하므로 N x N x [3*(4+1+80]의 형태로 출력
--> N : 특징 텐서의 그리드 개수
--> 3개는 앵커 박스의 개수,
--> (4+1+80)은 4개의 박스 시프트와 스케일링 값, 1개의 객체성 점수, 80개의 클래스 정보 - 여전히 k-평균을 이용한 앵커 박스 차원 클러스터링을 함
<특징 추출기 : Darknet-53>
YOLOv3에서 가장 큰 변화는 백본 네트워크를 Darknet-53으로 변경했다는 것
= Darknet-53 에선 Darknet-19에 ResNet에서 제안된 스킵 커넥션 개념을 적용해 레이어를 훨씬 더 많이 쌓은 모습을 보여줌.
- Max Pooling 대신에 콘볼루션의 스트라이드(stride)를 2로 취해 특징 맵의 해상도를 줄여 나감
- 스킵 커넥션을 활용해 나머지 값을 전달하고 마지막 레이어에서 에버리지 풀링과 FC 레이어를 통과한 뒤, 소프트 맥스를 거쳐 분류 결과를 출력
* YOLOv3 정리
= 원 스테이지 객체 인지 네트워크 중에서 SSD보다 훨씬 더 우수하며 DSSD와 유사한 성능을 제공
- 전반적으로 APs(작은 크기 객체 검출 정확도)에서 상대적으로 좋은 성능을 보이지만, APm(중간 크기 객체 검출 정확도)과 APL(큰 크기 객체 검출 정확도)에서 상대적으로 나쁜 성능을 보임
- YOLOv3는 ResNet, FPN을 사용하는 투 스테이지 객체 인지 네트워크인 Faster R-CNN의 변형 버전들보다 APs가 훨씬 더 좋음.
- YOLOv2과 비교했을때 오검출률이 낮아서 더 정확하게 검출 바운딩 박스를 보여줌
