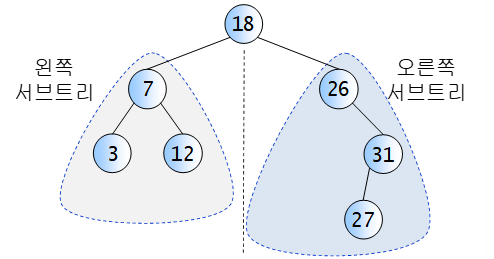
📌이진탐색트리 개요
= 효율적인 탐색 작업을 위한 자료구조
Key(왼쪽서브트리) < key(루트노드) < key(오른쪽서브트리)
- 중복된 값 X
- 이진탐색을 inorder 순회하면 오른차순으로 정렬된 값을 얻을 수 있음
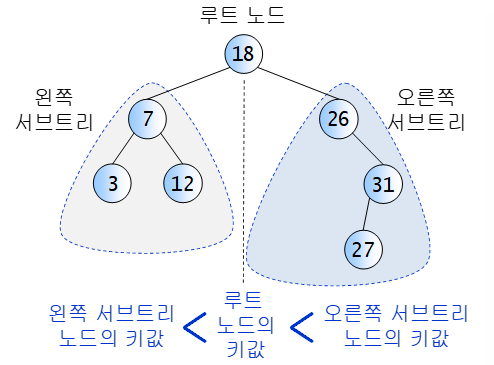
📌이진탐색트리 연산
✅ Search
= search(key), 키 값이 key인 노드를 찾아 반환하는 연산
탐색 과정
1. 비교한 결과가 같으면 탐색이 성공적으로 끝남
2. key < root --> 왼쪽 서브트리 탐색
3. key > root --> 오른쪽 서브트리 탐색
- 모든 노드에서 동일하게 반복 : 재귀
⭐ 탐색 연산 코드
//키 값으로 노드를 탐색하는 함수
// 처음에는 루트노드에서부터 시작함
BinaryNode* searchRecur(BinaryNode* n, int key) '''(1)
{
if (n == NULL) return NULL; // n이 NULL : key를 못찾은 경우 '''(2)
if(key == n->getData()) // (1) key == 현재노드의 data(key를 찾은 경우)
return n; '''(3)
else if(key < n->getData()) //(2) key < 현재노드의 data
return searchRecur(n->getLeft(), key); '''(4)
else
return searchRecur(n->getRight(), key); '''(5)
}📢 코드 설명
(1) 재귀 함수 선언
- 현재 노드를 탐색한 후 재귀적으로 왼쪽/오른쪽 자식을 계속 탐색
- 반환형 BinaryNode* : BinaryNode 객체가 가리키는 포인터 반환, 노드의 주소를 반환함 --> 그럼 노드에도 접근 가능
(2) 종료 조건, 리프 노드에 해당하는 경우, 탐색 실패- n = NULL // 리프 노드는 자식이 없기 때문에 NULL 포인터가 존재
(3) key 값을 찾은 경우- 찾고자 하는 키 값(key)이 현재 노드의 데이터(n->getData())와 일치할 경우 해당 노드를 반환함
- 왜 n->getDate()를 사용 ? --> n은 포인터이기 때문에, n이 가리키는 노드의 데이터를 가져오기 위해(getData()) 화살표 연산사 -> 사용
🔖포인터는 변수의 주소를 가리키는 변수. 포인터를 통해 노드의 데이터에 접근할 때는 -> 연산자 사용
(4) key < 찾고자 하는 값 --> 왼쪽 자식을 탐색- 만약 key가 현재 노드의 데이터보다 작다면, 왼쪽 자식을 재귀적으로 탐색한다.
- getData()는 현재 노드의 데이터를 반환하는 메서드. 이진탐색 트리에서는 이 데이터 값과 탐색하려는 key를 비교하여 객체를 진행 --> 현재 노드에 접근을 해야하기 때문에 포인터, n->getData()를 이용해 접근
- n->getData()는 포인터 n이 가리키는 노드 객체의 데이터에 접근하는 방법
(5) key > 찾고자 하는 값 --> 오른쪽 자식을 탐색- 재귀 호출을 통해 n->getRight()를 다음 탐색 대상으로 하여 오른쪽 서브트리로 내려감
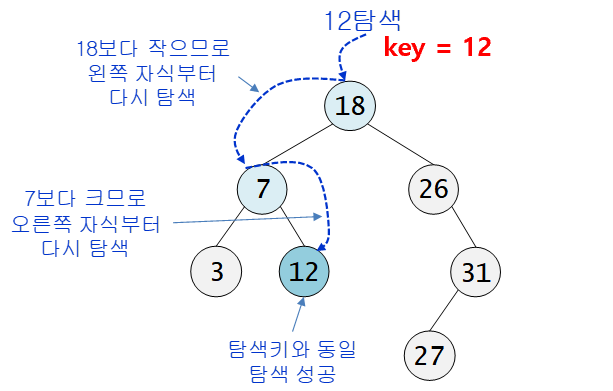
< 트리 탐색 예시1>

🌟 key = 40을 찾는 과정
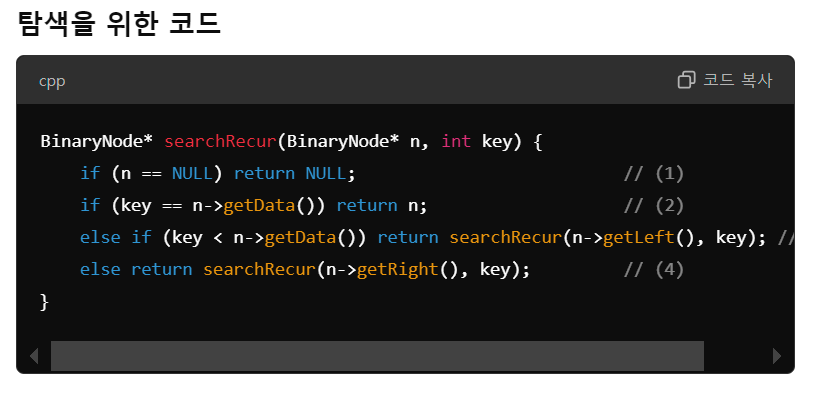



<트리 탐색 예시2 : 더 간단한 ver>

✅ Insert
= insert(n), 이진탐색트리의 특성을 유지하면서 새로운 노드 n을 삽입
- 이진탐색트리에 원소를 삽입하기 위해선 먼저 탐색 수행 필요
** 탐색에 실패한 위치가 바로 새로운 노드를 삽입하는 위치
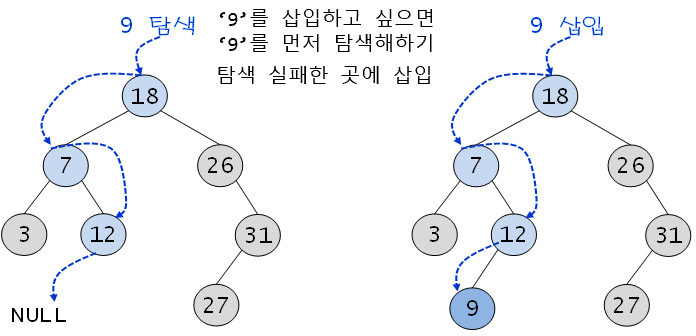
📝 기본 아이디어 : 순환 알고리즘
- key < root : 왼쪽 서브트리로 가기
- 왼쪽 서브트리가 null이면 그 자리에 삽입
- null이 아닌 경우 재귀적으로 왼쪽 서브트리 탐색
- key > root : 오른쪽 서브트리로 가기
- 오른쪽 서브트리가 null이면 그 자리에 삽입
- null이 아닌 경우 재귀적으로 오른쪽 서브트리 탐색
⭐ 삽입 연산 코드
// 이진 트리 탐색의 삽입 함수 (루트 노드r, 삽입할 노드n)
void insertRecur(BinaryNode* r, BinaryNode* n){ '''(1)
if(n->getData == r->getData()) // 중복 허용 X '''(2)
return;
//key가 더 작으면 왼쪽으로 '''(3)
else if(n->getData() < r->getData()){
// null이면 그 자리에 삽입'''(4)
if(r->getLeft == NULL) r->setLeft(n);
//null이 아니면 다시 왼쪽 서브트리로 재귀적으로 삽입 연산 수행
else insertRecur(r-<getLeft(), n); '''(5)
}
else { //key가 root보다 더 크면 오른쪽으로 '''(6)
if(r->getRight()==NULL){ r->setRight(n); '''(7)
//오른쪽 서브트리 다시 탐색 '''(8)
else insertRecur(r->getRight), n));
📢 코드 설명
(1) 함수 정의 및 매개변수 설명
(2) 중복 검사 및 함수 종료 조건
- 이미 삽입할 값이 트리에 존재하면 삽입을 하지 않고 함수를 종료함
(3) 왼쪽 서브트리로 이동 결정
(4) 왼쪽 자식 노드에 직접 삽입하는 경우
(5) 왼쪽 서브트리로 재귀 호출- 왼쪽 자식 노드가 이미 존재하는 경우
- 이미 존재하는 그 노드, 왼쪽 서브트리를 대상으로 insertRecur 함수를 재귀적으로 호출
(6) 오른쪽 서브트리로 이동 결정
(7) 오른쪽 자식 노드에 직접 삽입
(8) 오른쪽 서브트리로 재귀 호출
재귀호출이란 ❓
= 함수가 자기 자신을 반복적으로 호출하는 것
🏷️삽입연산으로 BST 생성
= 반복적인 삽입 연산으로 BST 구성 --> 처음에 삽입하려는게 루트노드임!!
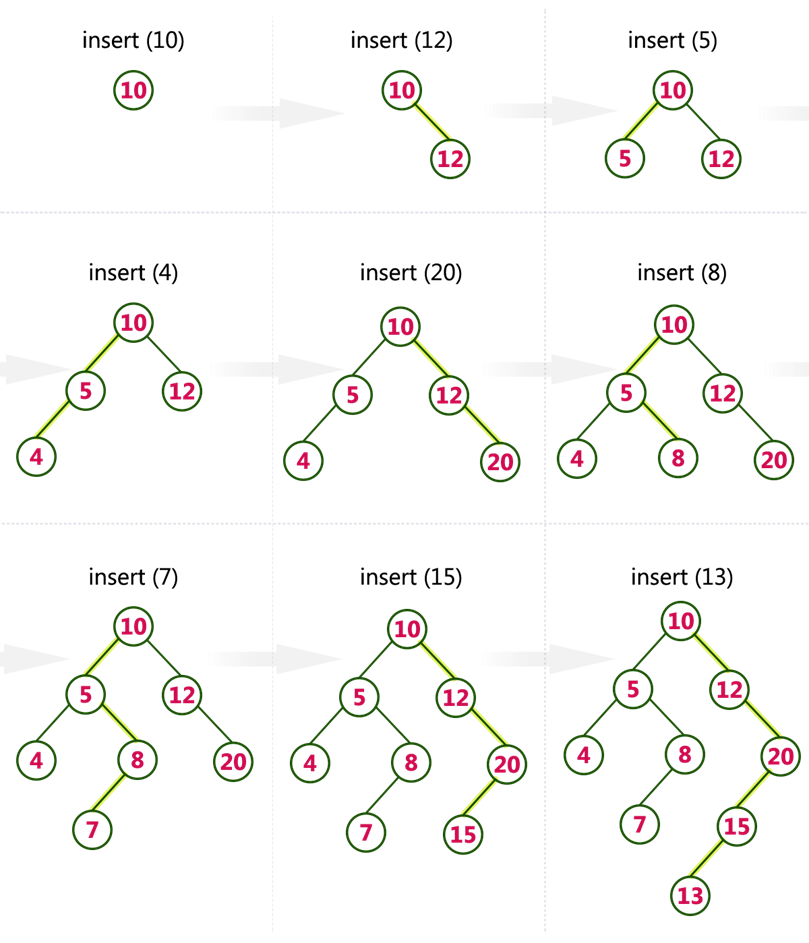
📌이진탐색트리 구현
✅ BinSrchTree Class
⭐ BinaryTree와 BinSrchTree는 상속관계
= BinSrchTree가 BinaryTree를 상속받았음(=BinaryTree의 기능에서 더 확장)
= BinaryTree의 모든 기능을 가지고 있으면서 이진 탐색 트리에 필요한 추가 기능을 포함
⭐ BinaryNode와 BinaryTree는 구성관계
= BinaryTree가 BinaryNode 객체들을 사용하여 트리를 구성
= BinaryTree는 여러 BinaryNode로 이뤄진 트리
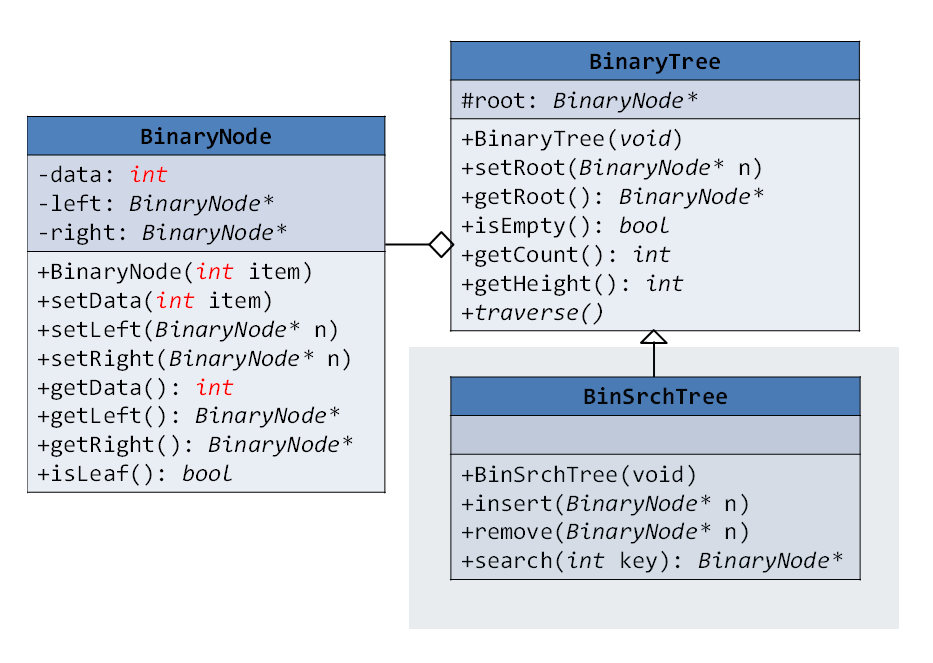
⭐ BinaryTree 클래스 : 수정사항 1개
- class BinaryTree로부터 상속
- 멤버 변수 root 노드에 접근이 필요함
수정 전) 루트 노드가 public으로 선언되었음
수정 후) 루트 노드가 protected:으로 선언됨

✅ class BinSrchTree 구현
🏷️class BinaryNode는 동일
🏷️ class BinaryTree : 멤버 변수 public -> protected
class BinaryTree{
protected:
BinaryNode* root; '''(1)
public:
BinaryTree():root(NULL){} '''(2)
~BinaryTree() {} '''(3)
void setRoot(BinaryNode* = node) {root = node;} '''(4)
BinaryNode* getRoot() {return root;} '''(5)
bool isEmpty() {return root == NULL;} '''(6)
// 필요에 따라서 트리 연산 함수 추가해주기 📢 코드 설명
(1) protected 접근 지정자
- protected로 선언됨으로써, 이 클래스(BinaryTree)와 이를 상속받는 파생 클래스(BinSrchTree) 에서만 접근이 가능
(2) 디폴트 생성자 --> 처음에는 비어있음- root(NULL) : 루트 포인터를 초기 상태인 빈 상태로 설정함
- root를 NULL로 초기화하여 트리가 처음에는 비어 있음을 명시적으로 나타냄
- 초기화 방식 : 멤버이름(초기값) 형태
(3) 소멸자 : 메모리 해제
(4) 루트 설정- root 멤버 변수를 주어진 node로 설정하는 멤버 함수
- 포인터를 파라미터로 받아서 root에 직접 할당
- root는 트리의 루트 노드를 가리키는 포인터임, 설정할 때도 노드의 주소를 받아야함,
- {root = node;] -> root가 node가 가리키는 노드의 주소를 갖도록함 root = 5; 이렇게 선언하면 타입 에러남 --> 값을 직접 넣는거는 노드 생성할때, ex) BinaryNode* node = new BinaryNode(5);
(5) 루트 반환하기- 반환형이 BinaryNode* 포인터여야 루트 노드의 값이나 자식 노드에 접근이 가능함.
ex) Binar
(6) 트리가 비어있는지 확인하는 함수- root가 NULL이면 true를 반환
🏷️ class BinSrchTree : BinaryTree를 상속 받아야함.
class BinSrchTree : public BinaryTree{
public:
BinSrchTree(void) {} '''(1)
~BinSrchTree(void) {}
BinaryNode* search(int key); '''(2)
BinaryNode* search(BinaryNode* n, int key); '''(3)
void insert(BinaryNode* n);
void insert(BinaryNode* r, BinaryNode* n);
}
// remove 함수는 다음 차시에 계속 ~📢 코드 설명
(1) BinSrchTree 클래스의 기본 생성자
- BinSrchTree 생성자 안에선 특별히 초기화해야할 멤버 변수가 없음
--> BinSrchTree는 BinaryTree를 상속받았기 때문에, BinaryTree의 생성자가 먼저 호출되어 root를 이미 NULL로 초기화함.- 부모 클래스인 BinaryTree의 생성자가 자동으로 호출되어 필요한 초기화를 처리해서 void임
(2) 특정 키 값을 가진 노드를 검색하는 함수- 매개변수로 키 값만 받기 때문에, 검색의 시작점은 루트 노드임
- 내부적으로 실제 검색 로직을 수행하는 다른 함수 search(BinaryNode* n, int key)를 호출함
(3) 특정 노드 n부터 시작해 재귀적으로 key를 가진 노드를 검색하는 함수(실제 로직 구현)
❓ 함수 오버로딩이란 ?
= 같은 이름의 함수를 매개변수 목록이 다르게 여러 개를 정의하는 것
// 함수 오버로딩된 search 함수들
BinaryNode* search(int key);
BinaryNode* search(BinaryNode* node, int key);❔ tree.setRoot(rootNode) 와 tree->setRoot(node)의 차이점
= tree 변수의 타입이 객체인지 포인터인지에 따라 달라짐
- tree.setRoot(rootNode) : tree가 객체일 때 사용
// BinaryTree 클래스 객체 생성 BinaryTree tree; // 루트 노드 생성 BinaryNode* rootNode = new BinaryNode(5); // setRoot 함수 호출 (객체이므로 . 연산자 사용) tree.setRoot(rootNode); **``` - tree->setRoot(node) : tree가 객체에 대한 포인터일 때 사용
// BinaryTree 클래스 객체에 대한 포인터 생성 BinaryTree* tree = new BinaryTree(); // 루트 노드 생성 BinaryNode* rootNode = new BinaryNode(5); // setRoot 함수 호출 (포인터이므로 -> 연산자 사용) tree->setRoot(rootNode);
🏷️ search 함수 정의
⭐ insert(int key)함수는 search(root, key)를 호출하여 검색을 시작
BinaryNode* BinSrchTree::search(int key){
// root는 BinaryTree 클래스로부터 상속받은 보호된 멤버 변수
// 반환된 결과를 node 포인터에 저장, 주소를 저장
BinaryNode* node = search(root,key); //!!parent class 변수 : root => protected
// node가 NULL이 아닌 경우 --> 탐색 성공
if(node! = NULL)
cout << "탐색 성공 : 키 값이" << node->getData()
<< " 인 노드 =0x " << node << endl; //이건 실제 메모리 주소 출력
// node가 NULL인 경우 --> 탐색 실패
else
cout << "탐색 실패 : 키 값이 " << key << "인 노드 없음" << endl;
return node;
}// 재귀적으로 호출되어 실제 검색을 수행하는 멤버 함수
BinaryNode* BinSrchTree::search(BinaryNode* n, int key){
if (n==NULL) return NULL;
if(key == n->getData()) return n;
else if(key < n->getData())
return search(n->getLeft(), key);
else
return search(n->getRight(), key);
📢 코드 설명
⭐ 재귀 호출의 반환 값은 상위 호출 함수,
insert(int key)함수로 전달됨
--> search(int key)함수에서 반환된 노드 포인터를 이용해 결과를 처리하고, 호출자에게 반환함.
⭐ 노드를 찾으면return n을 통해 해당 노드의 포인터를 반환함
--> 재귀 호출에서 번환된 노드 포인터는 상위 함수로 그대로 전달됨 -->node에 저장
🏷️ insert 함수 정의
// 삽입할 노드만을 인자로 받음
void BinSrchTree::insert(BinaryNode* n){
if( n == NULL) return; // 삽입하려는 노드가 NULL이면 실행 종료
if(isEmpty()) root = n; // 트리가 비어 있는지 확인함
else insert(root,n); // 트리가 비어 있지 않다면, insert 함수의 재귀 버전(아래 코드)를 호출
}⭐ 첫 번째 함수는 트리의 루트부터 시작해, 두 번째 함수를 호출하고, 두 번째 함수는 재귀적으로 트리를 순회하며 노드를 적절한 위치에 삽입함
// 재귀적으로 호출되는 내부 함수 --> 함수 오버로딩
void BinSrchTree::insert(BinaryNode* r, BinaryNode* n){
if(n->getData() == r-<getData()) return;
else if(n->getData < r->getData()) {
if(r->getLeft == NULL) r->setLeft(n);
else insert(r->getLeft(), n);
}
else{
if(r->getRight() == NULL) r->setRight(n);
else insert(r->getRight(), n);
}
}ex) insert 코드 예시
// 이진 탐색 트리 객체 생성 BinSrchTree tree; //값이 35인 새로운 노드를 생성하여 트리에 삽입 tree.insert(new BinaryNode(35))
- newBinaryNode(35)는 값이 35인 새로운 BinaryNode 객체를 동적으로 생성 --> 이때 생성된 노드는 주소(포인터를 반환함),
- 즉 new -BinaryNode(35)는 BinaryNode 타입의 포인터를 반환함
** insert 함수는 매개변수 BinaryNode 타입의 노드 포인터를 받는거나 마찬가지!!
⭐정리) tree,insert(new BinaryNode(35))는 새로운 노드를 생성하고, 그 노드를 트리에 삽입하는 과정 --> 생성된 노드의 주소를 insert 함수에 전달해, 트리의 적절한 위치에 노드를 삽입함.
✅ class BinSrchTree 활용
= 삽입 연산 insert으로 이진탐색트리를 만들어보고, search 연산으로 탐색해보기
#include <iostream>
using namespace std;
// class BinaryNode 정의 필요
// class BinaryTree 정의 필요
// class BinSrchTree 정의 필요
int main(){
// 이진탐색트리 객체 생성 --> 이름을 tree로 설정
BinSrchTree tree;
// 삽입 연산으로 이진탐색트리 생성하기, 일일이 삽입
tree.insert(new BinaryNode(35));
tree.insert(new BinaryNode(18));
tree.insert(new BinaryNode(7));
tree.insert(new BinaryNode(26));
tree.insert(new BinaryNode(12));
tree.insert(new BinaryNode(3 ));
tree.insert(new BinaryNode(68));
tree.insert(new BinaryNode(22));
tree.insert(new BinaryNode(30));
tree.insert(new BinaryNode(99));
//탐색 연산 테스트
cout << endl << " 탐색 연산" << endl;
tree.search(26); // cout을 쓸 필요가 없음. searh 함수 내에 cout 존재
tree.search(25);
// 26인 노드는 탐색 성공, 25는 탐색 실패
}
