
데이터 정의어(DML)
- Data Manipulation Language
- 데이터베이스의
내부 데이터를 관리하기 위한언어
(1) SELECT : 데이터베이스에서 데이터를 검색(조회)하는 역할
(2) INSERT : 테이블에 데이터를 추가하는 역할
(3) UPDATE : 테이블에서 데이터를 수정하는 역할
(4) DELETE : 테이블에서 데이터를 삭제하는 역할
CRUD
- 대부분의 컴퓨터 소프트웨어가 가지는 기본적인 처리 기능
INSERT
- 테이블에 데이터를 추가하기 위해 사용
 -> 필드를 명시하지 않을 때는 테이블의 모든 컬럼에 값을 추가할 때만 사용할 수 있다.
-> 필드를 명시하지 않을 때는 테이블의 모든 컬럼에 값을 추가할 때만 사용할 수 있다.
-> 필드 순서와 값 순서는 대응되게 써야한다. (값1은 필드1에 추가되고, 값2는 필드2에 추가됌)
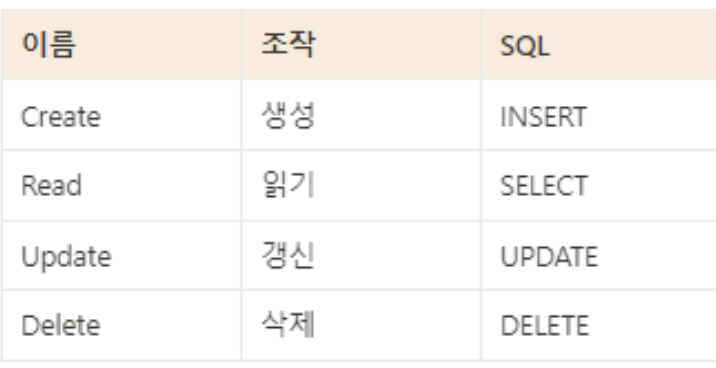
SELECT 문
데이터를 검색하는 기본 문장- 질의어(query)라고도 함
- 가장 많이 사용되는 문법
- 데이터를 가져오거나 조회할 때 사용!
SELECT 속성이름, ... FROM 테이블이름 [WHERE 검색조건];-> 해석 - [테이블명]에서 ~속성(컬럼이름)을 조회해라.
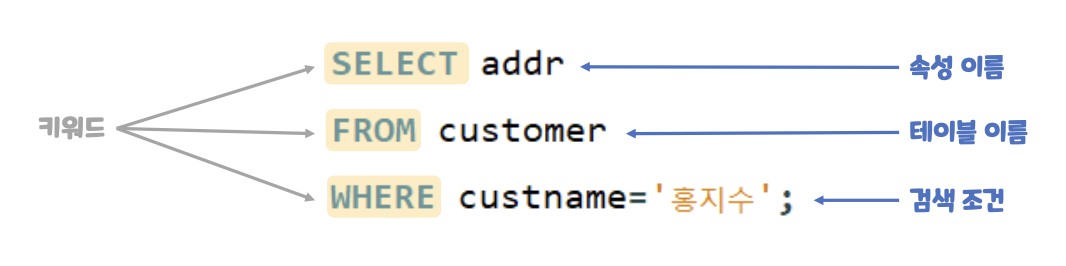
WHERE 절 - 비교연산자

WHERE 절 - 부정연산자
WHERE 절 - 범위, 집합, 패턴, NULL
(1) BETWEEN a AND b : a와 b의 값 사이에 있으면 참(a와 b의 값도 포함)
(2) IN(list) : 리스트에 있는 값 중에서 어느 하나라도 일치하면 참
(3) LIKE 비교문자열 : 비교문자열과 형태가 일치하면 사용(%, _ 사용)
%: 0개 이상의 어떤 문자_: 1개의 단일문자
SELECT * FROM 테이블명 WHERE 컬럼명 LIKE '%-06-%'; //06월이 포함되는 값들 출력
SELECT * FROM 테이블명 WHERE 컬럼명 LIKE '__라면'; //라면이라는 단어 앞에 두개의 문자만 있는 값 출력(4) IS NULL : NULL 값인 경우, true 아니면 false
WHERE 절 - 논리연산자
(1) AND : 앞에 있는 조건과 뒤에 오는 조건이 참이 되면 결과도 참
(2) OR : 앞에 있는 조건과 뒤에 오는 조건 중 하나라도 참이면 결과는 참
(3) NOT : 뒤에 오는 조건과 반대되는 결과를 돌려준다.
ORDER BY
- 결과가 출력되는 순서 조절
- where절과 함께 사용 가능
단, where 절 뒤에 나와야함 ASC: 오름차순(기본값)DESC: 내림차순 (최신순)- 순서대로 쌓이는
auto_increment와 자주 같이 쓰인다.
-- 모든 회원목록을 가져오는데, 이때 birthday 컬럼의 값을 기준으로 내림차순 정렬
SELECT * FROM membership ORDER BY birthday DESC;DISTINCT
- 중복된 데이터 제거
SELECT [DISTINCT] 속성이름, ... FROM 테이블이름 [WHERE 검색조건] [ORDER BY 속성이름];LIMIT
- 출력 개수 제한
ASC LIMIT 1이면 가장 오래된 데이터 한개 가져오고, DESC면 가장 최근꺼 한개 가져오게 조건을 줄 수 있다.
SELECT [DISTINCT] 속성이름, ... FROM 테이블이름 [WHERE 검색조건] [ORDER BY 속성이름] [LIMIT 개수];집계함수

select count(*) as count_employees from employees where department = 'IT개발팀';
-- "employees" 테이블에서 "department"가 'IT개발팀'인 직원의 수를 계산. "count_employees"라는 별칭을 사용하여 직원 수를 표시 + 전체 행이 몇개인지 알고싶을때도 사용됨GROUP BY
GROUP BY: 속성이름끼리 그룹으로 묶는 역할having: group by 절의 결과를 나타내는 그룹의 조건 걸기
SELECT [DISTINCT] 속성이름, ... FROM 테이블이름 [WHERE 검색조건][GROUP BY]속성이름[HAVING]조건식[ORDER BY 속성이름][LIMIT 개수];- 특별한 그룹을 묶어서 해당되는 값들의 평균 급여를 구하는 등의 예제에서도 많이 사용된다.
select department, avg(salary) as avg_salary from employees group by department having avg(salary) > 4000;
-- "employees" 테이블에서 "department"와 "salary" 컬럼을 사용하여 부서별 평균 급여를 계산한다. "avg_salary"라는 별칭을 사용하여 평균 급여를 표시하며, "having" 절을 통해 평균 급여가 4000보다 큰 부서만 선택.UPDATE, DELETE
- 대부분
WHERE절과 함께 사용한다. UPDATE: 데이터를 수정하기 위해 사용
UPDATE 테이블명 SET 필드1 = 값1 WHERE 필드2 = 조건2; //조건을 따로 주지 않으면 모든 필드의 값이 값1로 변경해버림. DELETE: 데이터를 삭제하기 위해 사용
DELETE FROM 테이블명 WHERE 필드1= 값1;
DELETE FROM user WHERE id = 10; //KEY는 삭제하는 순간 무결성원칙 때문에 날라가버림. id=10번은 없어지는 것.실습코드(select문을 활용하여 여러 SQL문 작성)
-- 데이터베이스 사용
use kdt;
-- 테이블 생성
CREATE TABLE membership (
id VARCHAR(10) NOT NULL PRIMARY KEY,
pw VARCHAR(20) NOT NULL,
name VARCHAR(5) NOT NULL,
gender ENUM(‘F’ , ‘M’ , ‘’) DEFAULT ‘’,
birthday DATE NOT NULL,
age INT(3) NOT NULL DEFAULT 0
);
-- 값 추가
INSERT INTO membership (id, pw, name, gender, birthday, age) VALUES
('hong1234', 'dkkek', '강혁', 'M','1990-01-31',33),
('sexysung' , 'd98skjf','리리' , 'F' , '1992-03-31' ,31),
('pweosl', 'dkfj39', '한조' ,'M' ,'1970-05-02',53),
('sswindown','39rkso','위도우', 'F','1984-10-18',39),
('lalaland','99slowp','크랠','M','1976-06-27',47),
('mamamlis','29dfemsi','미리미' ,'F','2001-06-03',22),
('lastli', '30spoqp','마지막','M','1999-11-11',24);
-- 테이블 보기
SELECT * FROM membership;
-- select문으로 여러 SQL문 작성
-- 5.1 : 모든 회원목록을 가져오는데, 이때 birthday 컬럼의 값을 기준으로 오름차순 정렬
SELECT * FROM membership ORDER BY birthday ASC;
-- 5.2 : 회원 목록 중 gender 컬럼의 값이 'M' 인 회원목록을 가져오는데, 이때 name 컬럼의 값을 기준으로 내림차순 정렬
SELECT * FROM membership where gender = 'M' ORDER BY name DESC;
-- 5.3 : 1990년대 태어난 회원의 id, name 컬럼을 가져오기
SELECT id, name FROM membership where birthday LIKE '199%';
-- 5.4 : 6월생 회원의 목록을 birthday 기준으로 오름차순 정렬하여 가져오시오
SELECT * FROM membership where birthday LIKE '%-06-%' ORDER BY birthday ASC;
-- 5.5 : gender 값이 'M'이고, 1970년대에 태어난 회원의 목록을 가져오시오.
SELECT * FROM membership where gender = 'M' AND birthday LIKE '197%';
-- 5.6 : 모든 회원목록 중 age를 기준으로 내림차순 정렬하여 가져오는데, 그때 처음 3개의 레코드만 가져와라.
SELECT * FROM membership ORDER BY age DESC LIMIT 3;
-- 5.7 : 모든 회원목록 중 나이가 25이상 50이하인 회원의 목록 출력
SELECT * FROM membership where age BETWEEN 25 AND 50;
-- 5.8 : id 컬럼의 값이 hong1234인 레코드와 pw 컬럼의 값을 12345678로 변경
-- update or delete는 조회하는게 아니므로 select문으로 보여달라고 하기전에는 즉각적으로 테이블이 보여지는 것이 아님!
UPDATE membership SET pw = '12345678' WHERE id = 'hong1234';
-- 5.9 : id 컬럼의 값이 lastli 레코드 삭제
DELETE FROM membership WHERE id = 'lastli';
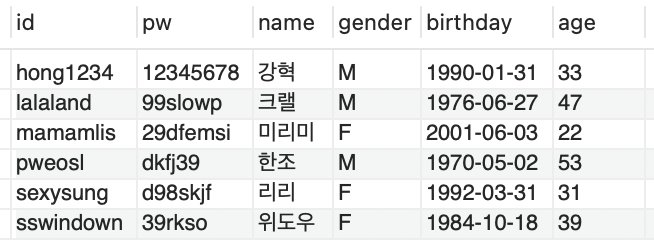
SELECT * FROM membership;
마무리
SQL문 중 가장 많이 쓰이는 문법인 SELECT를 여러 방법으로 사용해보았다. MySQL로 table을 생성하고 수정하는 것은 어렵지 않지만 가끔 생각치 못한 에러가 떠서 당황할 때가 좀 있었다..ㅎ 그래도 내가 데이터를 넣고, 수정할 수 있는 게 너무 신기하고 더 배우고 싶다.

중요한 건 꺾여도 다시 일어서는 마음