Double Deep Q Network(DDQN)
DDQN algorithm은 DQN의 단점을 보완한 알고리즘으로 [Deep Reinforcement Learning with Double Q-learning (AAAI 2016)] 논문을 통해서 소개된 알고리즘이다. DQN에 관하여 잘 모르겠으면 DQN 해당 포스팅을 보고 오자.
Outline
DQN과 같은 Q-learning계열의 알고리즘들은 Q-value overestimation 문제가 있었다. 하지만 이러한 문제가 실제로 잦은지, 실제로 알고리즘 성능에 악영향을 미치는지, 이런 문제를 예방할 수 있는지에 대한 것은 알려지지 않았다. 위 논문에서는 이러한 것들에 대한 답변을 제시해 줌과 동시에 Q-value overestimation 문제를 완화하는 알고리즘인 Double DQN 알고리즘을 제시한다.
Q-learning & DQN
전통적인 Q-learning에서 주어진 정책 하에서의 state 에서 에 대한 가치는 는 discount factor 일때 다음과 같이 정의된다.
이때 optimal Q-value는 와 같으므로 optimal policy는 각 state에서 가장 높은 가치를 가지는 action을 선택하는 것으로 유도할 수 있다. Table 기반으로 각 Q(s,a)값을 찾아가는 방식은 앞선 포스팅에서 설명했듯이 state-action space가 넓은 환경에 적용하기 어렵다는 한계가 있었다. 이를 극복하기 위해서 모든 Q-value값을 찾는 것이 아닌 parameterized value function 학습하는 것을 목표로 할 수 있다. Standard Q-learning은 다음과 같이 state 에서 action 를 선택했을 때 관찰되는 보상 과 next state 를 이용해서 다음과 같이 update한다.
이는 SGD방법과 유사하다. 이때 이다.
Deep Q Network(DQN)는 multi-layer neural network를 Q-learning에 도입한 것이다. 이 과정에서 발생하는 moving target problem과 sample들 간의 높은 correlation문제를 해결하기 위해 target network와 experience replay buffer를 도입했다(DQN). 는 target network의 parameter 일때 DQN의 target value는 다음과 같다.
Overestimation problem
위 Standard Q-learning과 DQN에서 연산시에 target value에 대한 선택과 평가를 동일한 parameter가 수행하였다 :
위와 같이 동일한 파라미터를 이용하여 연산을 통해 계산된 target Q-value 는 특정 상수 만큼 overestimate된다. Overestimation은 행동을 반복할 수록(학습을 반복할 수록) 그 정도가 심해진다.
Standard Q-learning에서 모든 값의 진짜 가치가 로 동일한 state 를 가정하자. 는 임의의 에서의 값들에 대한 전체적으로 편향되지 않은(whole un-biased) 추정치일 때, . 해당 추정치는 편향되진 않았지만 모든 값들이 완벽하게 정확하지는 않다(분산이 0은 아님). 즉, action 개수가 개라고 했을때 이다. 이러한 조건에서 연산을 통한 추정치는 와 같다. 즉, 적어도 만큼 과대추정된다. 같은 조건에서 Double Q-leraning의 오차 하한선은 이다.

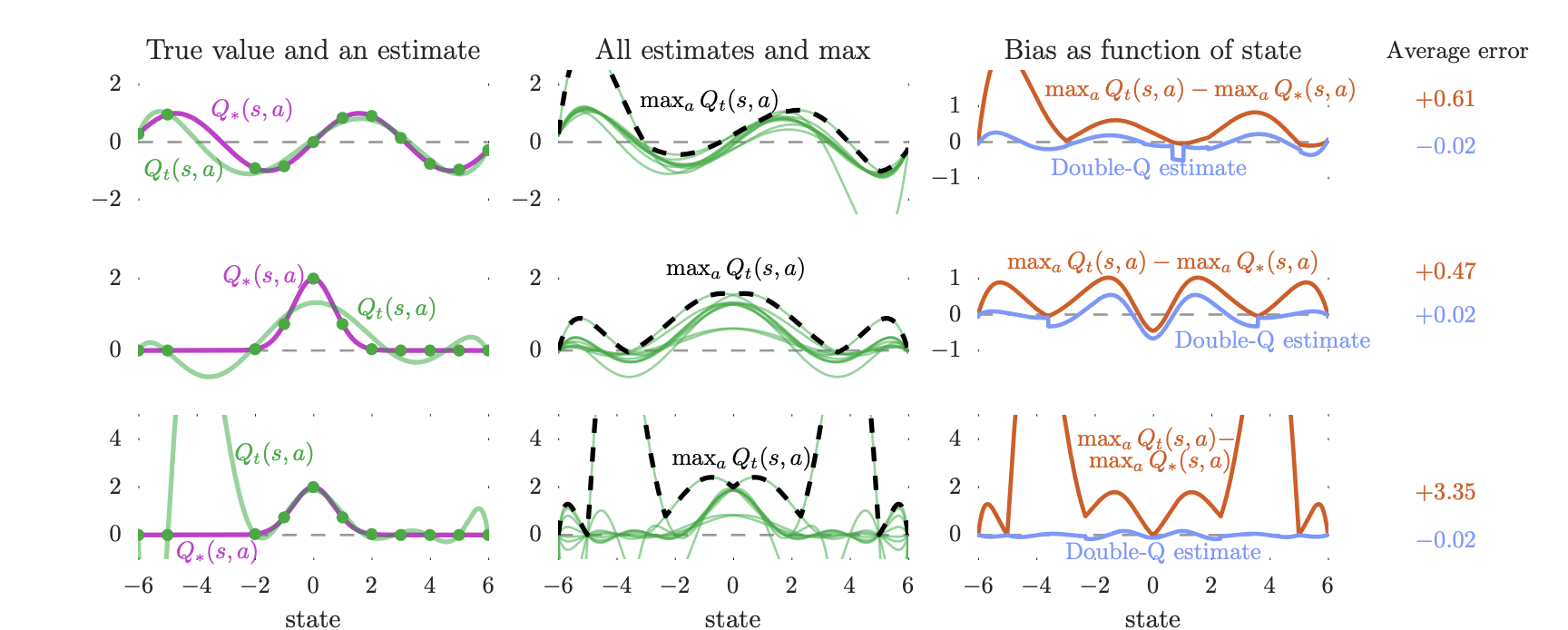
이러한 overestimation문제의 영향을 실제 function approximation상황에서 알아본 것이 다음 실험이다. 다음은 실험의 가정들이다.
- 에서 선택 가능한 의 개수는 10개이다.
- True optimal action value는 다음과 같다:
- 1st row :
- 2nd, 3rd row :
- 학습에 주어지는 sample들은 true value와 완벽히 일치한다. 즉, 환경에 의한 noise는 없다.
- 1st row, 2nd row의 추정 함수()는 6차원 다항식이며 3rd row는 9차원 다항식이다.
- 맨 왼쪽열의 plot의 초록색 점은 학습에 사용된 smaple이며 초록색깔 선은 function approximation의 결과이다.
1열의 초록색 점은 approximation에 쓰인 state set이며, 초록색 실선은 approximation function이다. 2열의 초록색 실선들은 모든 action들의 approximation function이고 검은색 점선은 해당 action들의 추정치들중 max값을 의미한다. 3열의 오렌지색 실선은 최대값과 실제값의 차이를 나타내고, Double Q-learning 알고리즘을 사용했을 때의 실제값과 추정치의 max값의 차이를 나타낸다.
첫번째 행과 두번째 행의 true value function은 다르다. 그럼에도 불구하고 3번째 열과같은 결과가 나왔다는 것은 overestimation problem이 특정 true value function에 따른 인위적인 문제는 아니라는 것을 시사한다.
두번째 행과 세번째 행은 function approximation의 flexiblity에 차이점이 있다(6-dimension, 9-dimension). 해당 행의 왼쪽 열에서 결과를 살펴보면 flexibility가 높을 수록 관측하지 않은 state에 대한 overestimation문제는 더욱 크게 나타난다. 이는 강화학습이 주로 고차원의 flexible function approximator를 사용한다는 점에서 해당 실험 결과는 의미가 있다.
이러한 overestimation된 행동 가치를 기반으로 부트스트래핑을 진행하면 잘못된 추정치가 전반적인 추정치들에 전파되어 정책 품질에 악영향을 미친다. 이론적으로 모든 가치를 균일하게 overestimation하면 정책 품질에 영향을 끼치지 않을 수도 있지만 실제로는 와마다 overesimation정도가 다르기 때문에 대게 정책 품질 저하를 유발한다.
Double DQN (DDQN)
앞선 실험결과(3열)에서도 알 수 있듯이 Double Q-learning 알고리즘 overestimation problem을 완화한다. Double Q-learning의 main idea는 target value 추정시에 action selection과 evaluation을 분리하는 것이다. 이를 기존 DQN algorithm에 적용하면 target value는 다음과 같이 정의된다:
기존 DQN에서는 target value를 계산할 때 target network에서 의 선택과 평과가 모두 일어났다면 Double DQN(DDQN)에서는 이 두가지가 분리되어, online network()에서 greedy policy에 의해 가 선택되고 target network는 이렇게 선택된 의 에서의 가치를 추정한다.
Numerical Experiments
Atari game에서의 수치 실험을 통해서 Double DQN의 action selection과 evaluation과정의 decoupling이 기존 DQN의 Q-value overestimation problem을 얼마나 잘 해결했는지를 볼 수 있다.
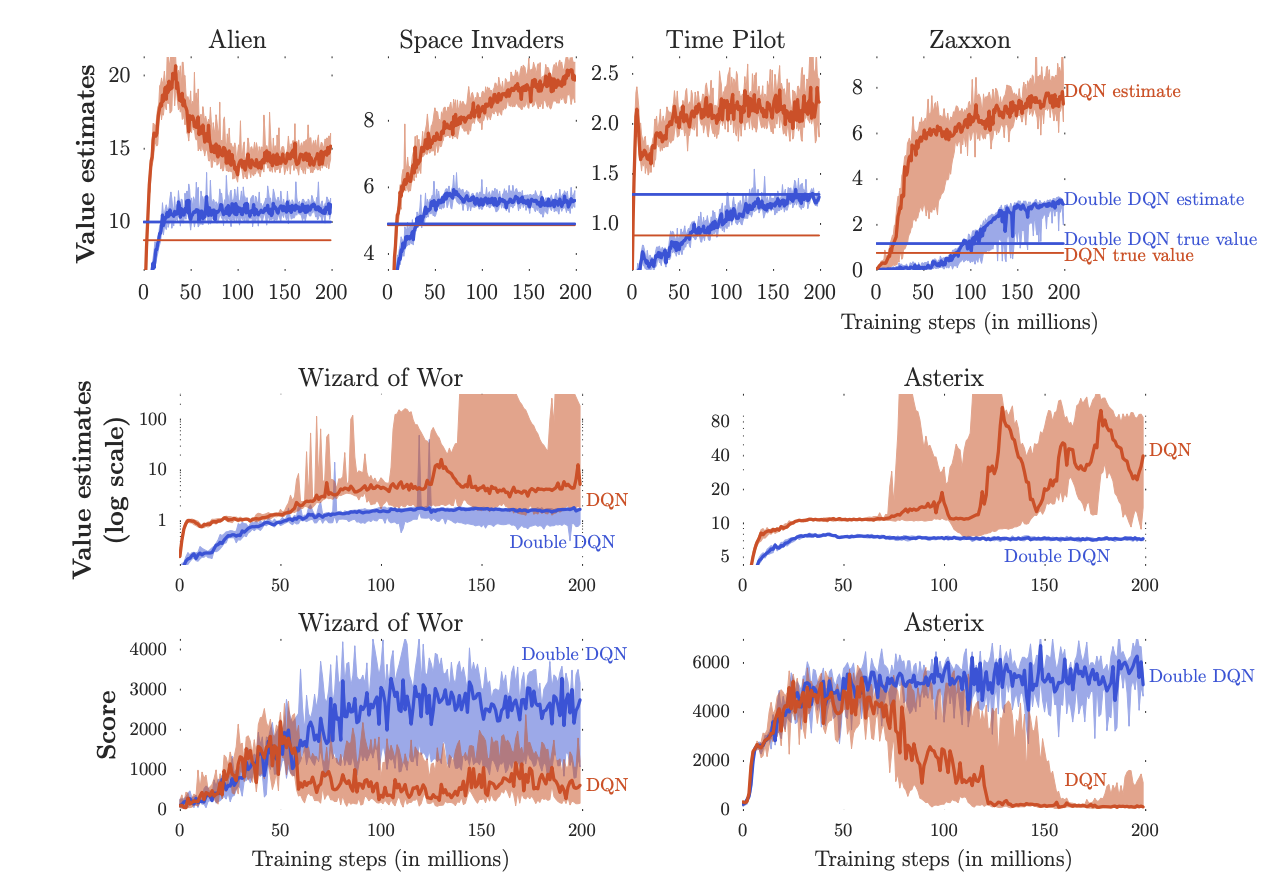 [Figure 1] Comparison of Q-value overestimation and performance between DQN and DDQN
[Figure 1] Comparison of Q-value overestimation and performance between DQN and DDQN
Figure 1의 1행과 2행의 Value estimates는 정해진 train step마다 모델의 가중치를 고정한 뒤 125,000step동안 환경에서 움직이게 한 다음 관찰되는 Q-value를 평균을 내는 방식으로 평가한다. 즉, 일때 일정 step마다 을 통해 해당 지점에서의 Q-value값을 산출한다. 또한 실선으로 표현되어 있는 true value란 학습된 모델이 실제 게임에서 얻은 점수(total rewad)를 의미한다. 1행, 2행의 실험 결과를 보면 Double DQN에서도 여전히 실제값보다 Q-value를 과대추정하는 경향이 있지만 DQN과 비교했을 때 이러한 문제를 상당부분 완화한것으로 보인다. 더하여 2행과 3행의 결과로부터 Q-value overestimation이 실제로 모델 성능과 안정성에 안좋은 영향을 끼치는 것을 볼 수 있다.49개의 Atari game에서 30분간 플레이 했을 때 성능차이는 Figure 2와 같다. 이때 사용한 성능지표는 과 같다. 이는 사람에 대한 상대적인 성능 차이를 의미한다.
 [Figure 2] summary of normalized performance up to 30 minutes of play on 49 games with human starts.
[Figure 2] summary of normalized performance up to 30 minutes of play on 49 games with human starts.
Implementation: DQN vs DDQN
DDQN의 main idea는 Target Q value계산시에 선택과 에 대한 평가를 분리하는 것이다. 아래 code1을 보면 구현상 차이점이 뚜렷하게 보인다.
code1. DQN vs DDQN
# DQN
states, actions, rewards, next_states, dones = replay_buffer.sample(batch_size=batch_size)
dones = dones.to(torch.float32)
q_values = q_network(states)
q_value = q_values.gather(1, actions.unsqueeze(1)).squeeze(1)
with torch.no_grad():
next_q_values = target_network(next_states)
max_next_q = next_q_values.max(1)[0]
target_q = rewards + gamma * max_next_q * (1 - dones)
optimizer.zero_grad()
loss = F.smooth_l1_loss(q_value, target_q)
loss.backward()
optimizer.step()
# DDQN
states, actions, rewards, next_states, dones = replay_buffer.sample(batch_size=batch_size)
dones = dones.to(torch.float32)
q_values = q_network(states)
q_value = q_values.gather(1, actions.unsqueeze(1)).squeeze(1)
with torch.no_grad():
next_q_values_main = q_network(next_states)
best_next_actions = next_q_values_main.argmax(dim=1, keepdim=True)
next_q_values_target = target_network(next_states)
max_next_q = next_q_values_target.gather(1, best_next_actions).squeeze(1)
target_q = rewards + gamma * max_next_q * (1 - dones)
optimizer.zero_grad()
loss = F.smooth_l1_loss(q_value, target_q)
loss.backward()
optimizer.step()
DQN에서 target값을 계산하는 코드를 보면 target network에서 에서의 에 대한 선택과 평가가 동시에 일어나는 것을 볼 수 있다. 반면 DDQN의 target value계산 코드를 보면 next_q_values_main = q_network(next_states), best_next_actions = next_q_values_main.argmax(dim=1, keepdim=True) 해당 두 줄의 코드로 볼 수 있듯이 main network에서 에서 이 선택되고 이후 target network에서는 해당 값들에 대한 평가만 이루어지는 것을 볼 수 있다. Frozen Lake환경에서 이 두가지 알고리즘을 간단하게 실험해봤을 때 DDQN이 DQN이 비해 확연히 빠른 수렴속도를 보여준다.
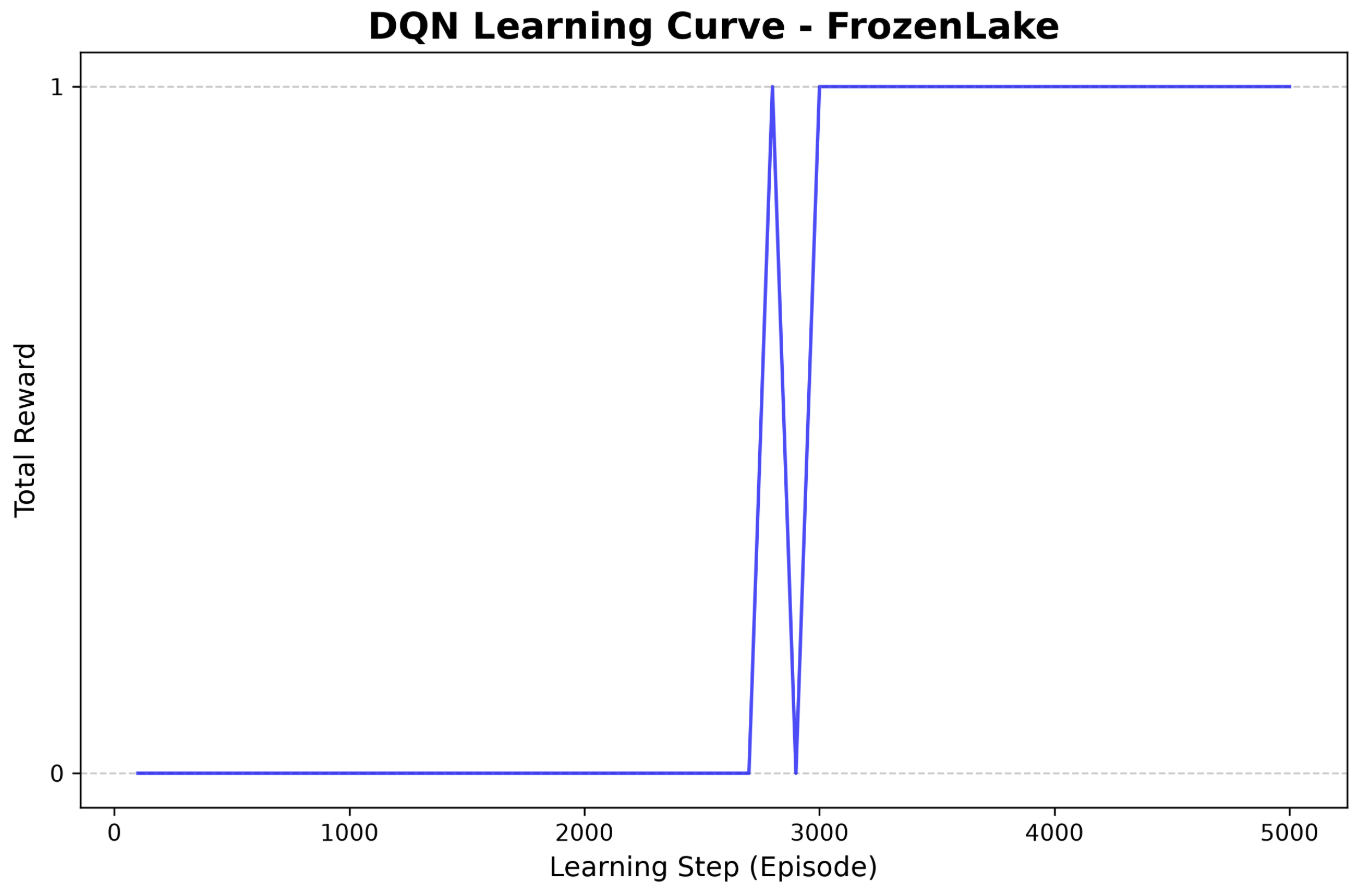 [Figure 2]. Frozen Lake환경에서 DQN의 learning curve
[Figure 2]. Frozen Lake환경에서 DQN의 learning curve
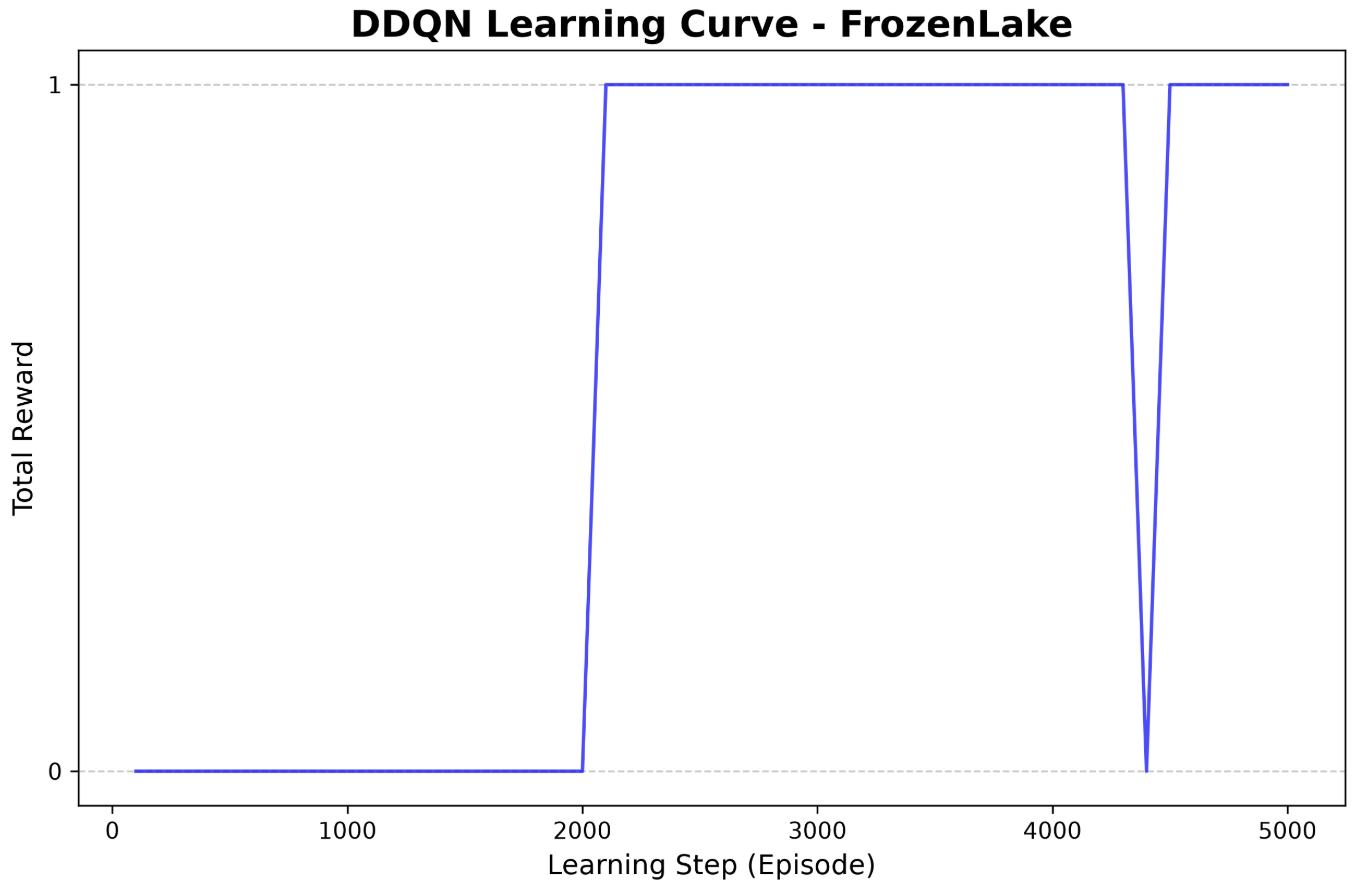 [Figure 3]. Frozen Lake환경에서 DDQN의 learning curve
[Figure 3]. Frozen Lake환경에서 DDQN의 learning curve
아래는 Frozen Lake 환경에서의 DDQN 전체 예제 코드이다.
import gymnasium
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.optim import SGD
import numpy as np
from typing import List
import matplotlib.pyplot as plt
# Replay Buffer 정의
class ReplayBuffer:
def __init__(self, capacity: int):
self.buffer = deque(maxlen=capacity)
def __len__(self):
return len(self.buffer)
def push(self, state: Tuple[float], action: int, reward: float, next_state: Tuple[float], done: bool):
self.buffer.append((state, action, reward, next_state, done))
def sample(self, batch_size, device = "cpu"):
"""state, action, reward, next_state, done = zip(*random.sample(self.buffer, batch_size)) # Replay buffer에서 random sampling 이후 unpacking해서 각 요소들끼리 모은다.
return (np.array(state), np.array(action), np.array(reward), np.array(next_state), np.array(done)) # doen즉 종료 여부는 빼도 되지 싶다. => 어짜피 한 에피소드 기준으로 학습을 시킬 것이다."""
state, action, reward, next_state, done = zip(*random.sample(self.buffer, batch_size))
return (
torch.tensor(state, dtype=torch.float32, device=device),
torch.tensor(action, dtype=torch.long, device=device),
torch.tensor(reward, dtype=torch.float32, device=device),
torch.tensor(next_state, dtype=torch.float32, device=device),
torch.tensor(done, dtype=torch.bool, device=device)
)
def sample_all(self):
if len(self.buffer) == 0:
raise Exception("Replay buffer가 비어있습니다.")
return self.buffer
def clear(self):
"""
replay buffer를 비운다.
"""
self.buffer.clear()
# 1. Define Network
class Network(nn.Module):
def __init__(self, n_states, n_actions):
super().__init__()
self.n_states = n_states
self.n_actions = n_actions
self.q_head = nn.Sequential(
nn.Linear(in_features=self.n_states, out_features=self.n_actions)
)
def forward(self, state):
state = torch.tensor(state) if not torch.is_tensor(state) else state
if state.dim() == 0:
state = state.unsqueeze(0)
features = F.one_hot(state.to(torch.int64), num_classes=self.n_states).to(torch.float32)
q_values = self.q_head(features)
return q_values
def get_q_values(self, state):
return self.forward(state)
# 2. ENV 및 Parameter 셋팅
env = gymnasium.make('FrozenLake-v1', is_slippery=False)
n_states = env.observation_space.n
n_actions = env.action_space.n
num_episode = 5000
max_step = 100
exploration_prob = 1.0
min_exploration_prob = 0.01
exploration_decay = 0.999
gamma = 0.99
lr = 0.01
batch_size = 32
buffer_capacity = 1000
# 3. Model, Loss, Optimizer, Replay Buffer 생성
q_network = Network(n_states=n_states, n_actions=n_actions)
target_network = Network(n_states=n_states, n_actions=n_actions)
target_network.load_state_dict(q_network.state_dict())
optimizer = SGD(params=q_network.parameters(), lr=lr)
replay_buffer = ReplayBuffer(capacity=buffer_capacity)
results: List[int] = []
# 4. Training Loop
for i in range(num_episode):
current_state, _ = env.reset()
all_reward = 0
done = False
step = 0
while not done and step < max_step:
q_network.eval()
# Epsilon-greedy Policy
if torch.rand(1) < exploration_prob:
action = env.action_space.sample()
else:
with torch.no_grad():
Qs = q_network.get_q_values(current_state)
action = torch.argmax(Qs).item()
# Environment step
next_state, reward, terminated, truncated, _ = env.step(action=action)
done = terminated or truncated
all_reward += reward
# Replay buffer에 저장
replay_buffer.push(current_state, action, reward, next_state, done)
# Replay buffer에서 샘플링 및 학습
if len(replay_buffer) >= batch_size:
q_network.train()
states, actions, rewards, next_states, dones = replay_buffer.sample(batch_size=batch_size)
dones = dones.to(torch.float32)
q_values = q_network(states)
q_value = q_values.gather(1, actions.unsqueeze(1)).squeeze(1)
with torch.no_grad():
next_q_values_main = q_network(next_states)
best_next_actions = next_q_values_main.argmax(dim=1, keepdim=True) # (Batch, 1)
next_q_values_target = target_network(next_states)
max_next_q = next_q_values_target.gather(1, best_next_actions).squeeze(1) # best_next_action에 해당하는 Q-value들을 가져온다. 이후 squeeze(1)를 통해서 (Batch, 1) -> (Batch,)로 한차원 낮춰줘야한다.
target_q = rewards + gamma * max_next_q * (1 - dones)
# Loss 계산 및 업데이트 (Huber Loss)
optimizer.zero_grad()
loss = F.smooth_l1_loss(q_value, target_q)
loss.backward()
optimizer.step()
current_state = next_state
step += 1
# 에피소드 종료 후 타겟 네트워크 업데이트
target_network.load_state_dict(q_network.state_dict())
exploration_prob = max(min_exploration_prob, exploration_prob * exploration_decay)
if (i + 1) % 100 == 0:
results.append(all_reward)
if (i + 1) % 500 == 0:
print(f"Episode {i + 1:5d} | Total Reward: {all_reward:.1f} | Epsilon: {exploration_prob:.3f}")
env.close()
# Results
episodes = [x * 100 for x in range(1, len(results) + 1)]
plt.figure(figsize=(10, 6))
plt.plot(episodes, results, linestyle='-', color='blue', alpha=0.7)
plt.title('DDQN Learning Curve - FrozenLake', fontsize=16, fontweight='bold')
plt.xlabel('Learning Step (Episode)', fontsize=12)
plt.ylabel('Total Reward', fontsize=12)
plt.yticks([0.0, 1.0])
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.savefig('value_base/ddqn/learning_curve.png', dpi=300, bbox_inches='tight')
plt.show()