References
PRIORITIZED EXPERIENCE REPLAY (2016, ICLR)
Pattern Recognition and Machine Learning (2006, Christopher Michael Bishop)
What is Importance Sampling?
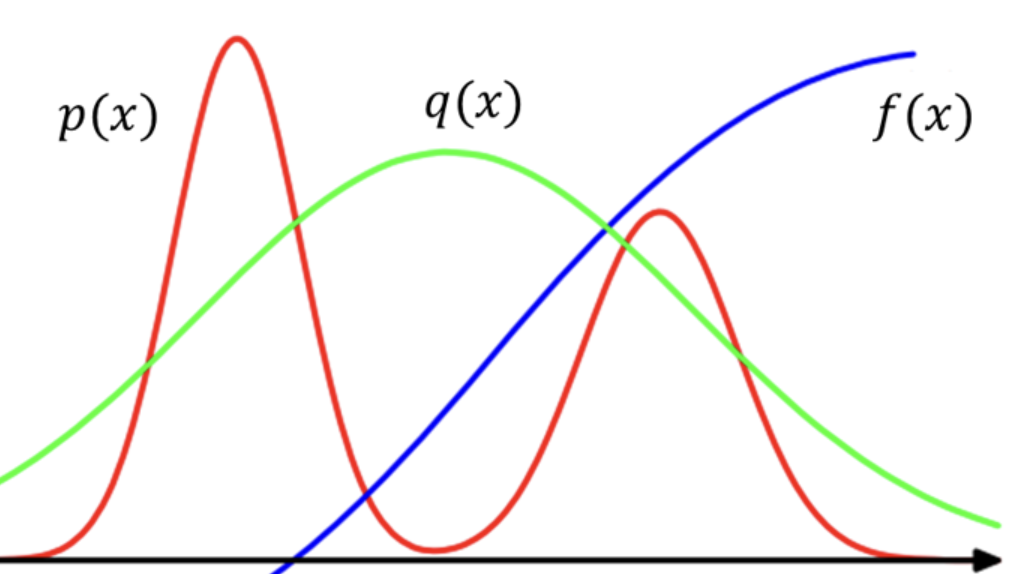
Importance Sampling(IS)이란 확률 분포 p(x)를 따르는 확률변수 x가 있고, x에 대한 함수 f(x)의 기댓값 Ex∼p[f(x)]를 Monte Carlo method를 이용해서 추정을 할 때 본래의 확률 분포 p(x)가 아닌 다른 확률 분포 q(x)에서의 sampling으로 Ex∼p[f(x)]의 값을 추정하고자 하는 방법이다.
Importance Weight
위에서 언급한 것처럼 Ex∼p[f(x)]=∫f(x)p(x)dx 를 직접 계산할 수 없을 때 아래와 같이 Monte Carlo method를 이용해서 f(x)의 기댓값을 근사 시킬 수 있다.
Ex∼p[f(x)]=∫f(x)p(x)dx≈N1i=1∑Nf(xi)
이때 원래의 확률 분포 p(x)가 아닌 새로운 새로운 확률 분포 q(x)에서의 sampling으로 Ex∼p[f(x)]를 얻고자 할 때 위 기댓값 계산식을 아래와 같이 수정할 수 있다.
Ex∼p[f(x)]=∫f(x)q(x)p(x)q(x)dx=∫(q(x)p(x)f(x))q(x)dx=Ex∼q[q(x)p(x)f(x)]
여기서 Monte Carlo method에 의한 근사를 수행하면 아래와 같이 표현된다.
Ex∼p[f(x)]=Ex∼q[q(x)p(x)f(x)]≈N1i=1∑Nq(xi)p(xi)f(xi)
이때 q(x)p(x)를 importance weight라고 하며 확률 분포 q(x)에서 sampling을 수행해서 Ex∼p[f(x)]를 추정했을 때 발생하는 bias를 보정하는 역할을 한다. 이때 importance sampling의 성공 여부는 새로운 분포 q(x)는 원 분포 p(x)와 얼마나 잘 맞는지에 달려 있다.
Utilization of Importance Sampling in PER
Ex∼p[f(x)]=∫f(x)p(x)dx≈N1i=1∑Nf(xi)
위 식에서 x의 차원수가 늘어남에 따라 합산항이 커지며, 이때 대부분의 값들은 x공간상의 상대적으로 작은 부분에 몰려있다. 이러한 고차원 문제에서 Ex∼p[f(x)]를 추정할 때 p(x)에서 uniform sampling하는 것은 비효율 적이다. p(x)가 큰 구역에서 표본들을 선택하거나 p(x)f(x)가 큰 구역에서 sampling을 하는 것이 이상적이다. Prioritized Experience Replay(PER)에서는 이를 위해 TD-error(δ)값으로 도출한 priority기반의 새로운 분포 q(x)하에서 transition sampling을 하고자 한다. Importance sampling의 목적이 x∼p(x) 상황에서 Ex∼p[f(x)]를 추정하는 것이라고 할 때, 각 요소는 DQN과 같은 가치기반 DRL에서 각각 다음과 같다.
-
x : Replay buffer내부의 개별 transition
-
p(x) : transition x가 sampling될 확률 (buffer에 N개의 transition이 있을때 p(x)=N1)
-
f(x) : x의 loss값
-
Ex∼p[f(x)] : Replay buffer안에 들어있는 전체 transition의 loss의 평균값.
위에서 언급 했듯이 p(x)f(x)가 큰 구역에서 sampling을 하는 것이 이상적일 때, p(x)f(x)에서 p(x)=N1로 상수이다. 또한 f(x)값 즉, x의 loss값의 크기는 ∣δ∣의 크기에 의존하므로 ∣δa∣<∣δb∣ 이면 p(xa)f(xa)<p(xb)f(xb)를 만족한다. 이 말은 즉, ∣δ∣가 큰 구간에서 sampling을 집중해서 하는 것이 유리하다는 말이된다. 이는 개별 transition의 priority를 ∣δ∣로서 측정하고 이를 이용해서 priority가 높은 transition을 집중적으로 sampling하고자 하는 PER의 본질적인 아이디어와 일치한다. PER에서는 원분포를 대신하는 새로운 분포 q(x)를 아래와 같이 설정한다.
q(x)=P(i)=∑kρkαρiα
이때 ρi=∣δ∣+ϵ이다. q(x)가 위와 같을 때 importance sampling weight는 다음과 같다.
wi=(N1⋅P(i)1)β
β=1 일때 q(x)p(x)와 완전 동일한 형태인 것을 볼 수 있다.