이번학기 캡스톤에 활용하는 모델에 관한 논문이라, 기억할 겸 레퍼런스를 남길 겸 정리해두었다
논문 링크

서론
- 기존 모델들의 문제점:
- Misalignment : 옷을 착용자의 신체에 맞게 변형(warping)하는 과정에서 옷 이미지가 신체 부위와 정확히 정렬되지 않으면 아티팩트 발생
- Pixel Squeezing : 신체 부위가 옷을 가리는 상황에서 옷이 비정상적으로 변형되어 옷 패턴 왜곡
- 제안된 모델이 제시하는 해결책:
- Try-On Condition Generator : Warping과 Segmentation 단계를 통합하여 한 번에 처리함으로써 misalignment와 pixel squeezing 문제를 해결합니다.
- Discriminator Rejection : 잘못된 Segmentation Map을 걸러내어 최종 이미지의 품질을 보장합니다.
제시된 모델
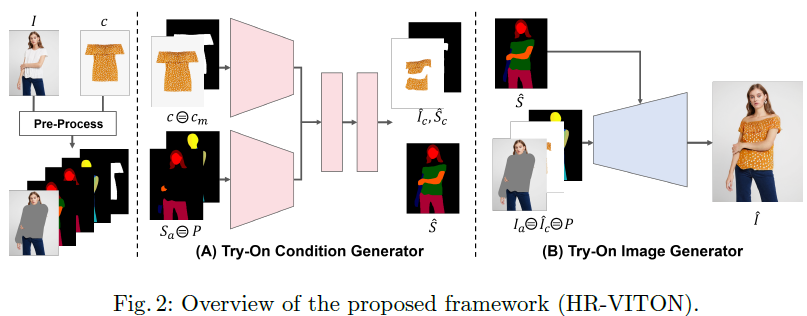
1. Try-On Condition Generator
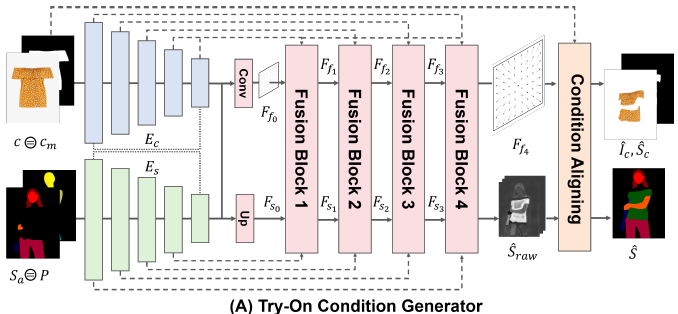
-
옷 이미지 를 사용자의 신체에 맞게 변형하여 최종적으로 정확하게 정렬된 Segmentation Map 과 변형된 옷 이미지 를 생성함
-
Clothing Encoder (): 옷 이미지 와 옷 마스크 에서 Feature Pyramid 를 추출
→ 옷의 모양과 패턴 정보를 분석하여 이후 단계에서 사용할 수 있도록 준비함
-
Segmentation Encoder (): Clothing-Agnostic Segmentation Map 와 Pose Map 에서 Feature Pyramid 를 추출
→ 인체의 형태와 자세 정보를 분석하여 옷과 정확히 정렬할 수 있게 함
-
Feature Fusion Block:
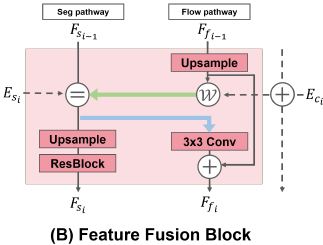
- Flow Pathway: 옷 이미지의 각 픽셀이 신체의 어느 부분에 위치해야 할지를 결정하는 Appearance Flow Map 을 생성 → 옷 이미지를 왜곡하여 신체에 맞게 정렬하는 데 사용
- Segmentation Pathway: 옷이 신체에서 어디에 위치할지를 나타내는 Segmentation Feature 를 생성
- 정보 교환: 이 두 경로는 서로의 정보를 교환 → 두 정보가 일관되게 정렬되어야 misalignment 문제를 방지할 수 있기 때문
- Flow Pathway : Segmentation Feature()를 참고하여 옷 변형을 수행
- Segmentation Pathway : Flow Map()을 활용하여 정확한 Segmentation 수행
- Flow Pathway: 옷 이미지의 각 픽셀이 신체의 어느 부분에 위치해야 할지를 결정하는 Appearance Flow Map 을 생성 → 옷 이미지를 왜곡하여 신체에 맞게 정렬하는 데 사용
-
Condition Aligning:
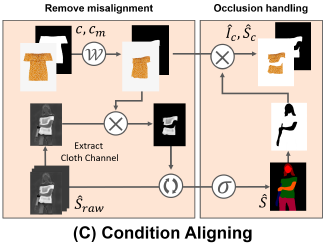

-
misalignment를 방지하기 위해 의 채널과 간에 겹치지 않는 부분을 제거하여 최종 를 얻음
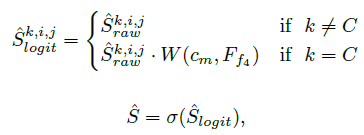
-
: 최종 Segmentation Map.
-
: Occlusion(신체 부위에 의해 가려진 부분)을 처리한 후 변형된 옷 이미지.
→ 최종 Segmentation Map 는 로 정의 됨, 여기서 는 depth-wise softmax
→ ReLU 활성화를 적용하여 가 음수가 되지 않도록 함
-
-
Body Part Occlusion Handling : Occlusion(가려짐) 상황을 처리하여 pixel-squeezing 아티팩트를 제거
- 최종 변형된 옷 이미지 와 Segmentation Map 는 에 body part occlusion handling을 적용하여 생성됨
- 의 신체 부위 정보로 옷 이미지 와 옷 마스크 의 ‘신체로 가려진 영역’을 제거하여 pixel-squeezing 을 방지함
-
<참고>

- 손실 함수
- 목적: 네트워크가 옷을 사용자의 포즈에 맞게 왜곡시키도록 훈련하며, 중간 흐름 지도(intermediate flow maps)가 사라지지 않도록 보장하고 성능을 향상시킴.
- 주요 손실 함수들:
- Cross-Entropy Loss (CE): 예측된 Segmentation Map 과 실제 Segmentation Map 간의 픽셀 단위의 차이
- L1 Loss (L1): 옷 마스크 과 Flow Map 를 사용하여 예측된 옷 이미지 와 실제 옷 이미지 간의 L1 거리
- Perceptual Loss (VGG): 예측된 이미지와 실제 이미지 간의 인식적인 차이
- : VGG 네트워크의 피처 맵
- : 각 항목 간의 상대적 중요도를 조정하는 가중치
- Total-Variation Loss (TV): Appearance Flow 의 부드러움을 강제하기 위해 사용됨 흐름 추정이 매끄럽게 이루어지도록 돕는 역할을 함
- 전체 목표 함수:
- 종합적인 목표 함수를 사용하여 end-to-end로 훈련
- 여기서 은 예측된 Segmentation Map 과 실제 Segmentation Map 간의 조건부 GAN 손실을 나타냄
- , , 는 각 손실 항목의 상대적 중요도를 조절하는 하이퍼파라미터
- 종합적인 목표 함수를 사용하여 end-to-end로 훈련
2. Try-On Image Generator
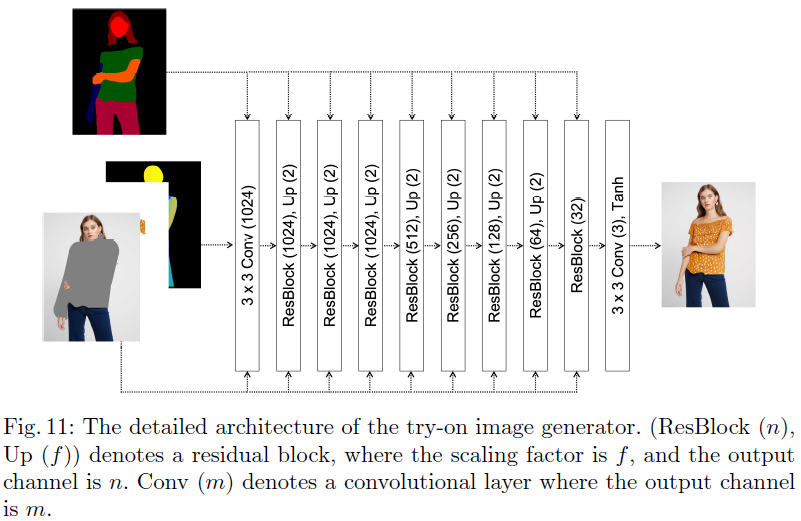
- 최종 가상 착용 이미지 를 생성하는 단계로, 옷을 제거한 신체 이미지 , 변형된 옷 이미지 , 포즈 맵 를 결합하여 의 지시에 따라 최종 이미지를 생성함
- 구조
- Residual Block 들은 Normalization layer로 SPADE (Spatially-Adaptive Normalization) 레이어를 활용
- Normalization layer의 Modulation Parameter가 Segmentation Map 을 기반으로 추론됨
- 입력 데이터 는 각 Residual Block 전에 활성화에 결합되고, 이후 업샘플링 레이어를 통해 해상도가 점진적으로 증가함
- Upsampling Layer: 입력된 Clothing-Agnostic Image (), Warped Clothing Image (), 포즈 맵() 등을 결합하여 해상도를 점진적으로 높이며 최종 이미지를 생성
- Residual Block 들은 Normalization layer로 SPADE (Spatially-Adaptive Normalization) 레이어를 활용
- SPADE와 pix2pixHD에서 사용된 동일한 손실 함수들로 훈련됨
3. Discriminator Rejection
- 테스트 시 잘못된 Segmentation Map을 식별하고 제거하여 최종 이미지의 품질을 보장함.
- 구조
- Discriminator (D): Try-On Condition Generator에서 생성된 Segmentation Map의 품질을 평가함
- Acceptance Probability (paccept): Discriminator의 출력을 기반으로 계산되며, Segmentation Map이 충분히 품질이 좋지 않다고 판단되면 해당 샘플을 거부함
- Normalizing Constant (L): 데이터셋 전체에서 Discriminator의 출력을 기반으로 계산되며, 샘플의 수용 가능성을 결정하는 기준이 됨.
- 적용 이유
- 이 방법은 잘못된 Segmentation Map이 최종 이미지에 반영되지 않도록 함으로써, 실제 응용에서 더 높은 품질의 가상 착용 이미지를 생성할 수 있음. 특히, 다양한 입력 데이터에 대해 강건한 성능을 제공하여 실제 온라인 쇼핑 환경에 적합함
실험
-
질적 결과

- CP-VTON, ACGPN, VITON-HD 등의 기존 방법들과 비교했을 때, 제안된 방법은 더 현실감 있는 이미지를 생성하며, 특히 Occlusion 상황에서도 픽셀 왜곡 없이 뛰어난 성능을 발휘함
-
양적 결과
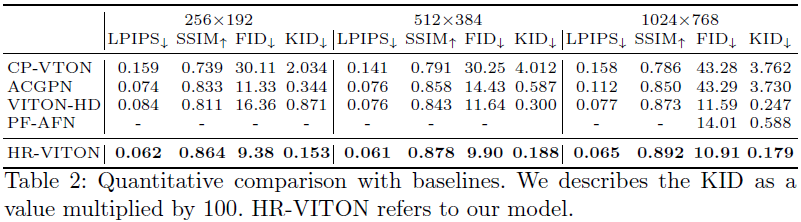
- FID, KID 등의 지표에서 제안된 방법이 기존 방법들보다 우수한 성능을 보여주며, 특히 1024x768 해상도에서의 성능이 뛰어남
결과
- 제안된 모델은 고해상도 가상 착용 작업에서 Misalignment와 Occlusion 문제를 효과적으로 해결하여 기존 방법들보다 우수한 성능을 보임
- 특히, Warping과 Segmentation을 통합하여 처리함으로써 발생할 수 있는 정보 불일치 문제를 근본적으로 해결하였음
- 그러나 Discriminator Rejection의 한계로 인해, 실제 응용에서 발생할 수 있는 Out-of-Distribution 입력에 대해 추가적인 연구가 필요함

wannabe dev