Each Complexity Deserves a Pruning Policy
- 축1 (Modality): Image
- 축2 (압축 메커니즘): Pruning
- 축3 (학습 필요성): Training-free
- 축4 (압축 시점): LLM 내부 layer
- 축5 (Guidance 신호): Cross-modal attention 기반 상호 + 정보량(Mutual Information)
- 축6 (적응성): Sample/Task-adaptive (상호 정보량에 따라 프루닝 곡선이 동적으로 결정)
- 축7 (타겟 모델): General VLM + VLA (자율 주행)
칼
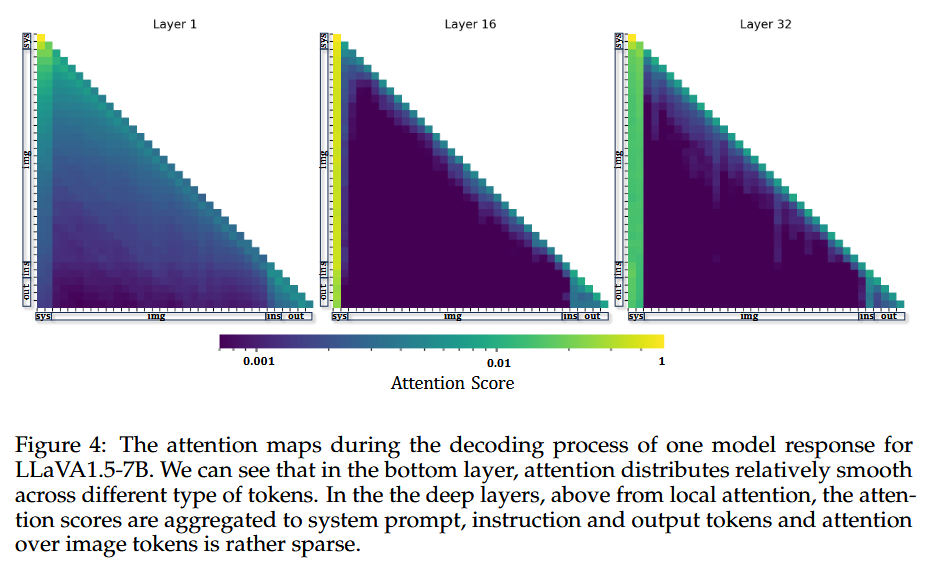
- FastV의 Figure 4: 디코딩 과정에서 LLaVA-1.5-7B의 각 레이어별 어텐션 맵을 시각화한 것임. 보려고 한 것은 시각적 토큰이 레이어 깊이에 따라 얼마나 주의를 받는지임. 각 출력 토큰이 시스템 프롬프트, 이미지 토큰, 사용자 인스트럭션, 출력 토큰에 부여하는 어텐션 점수 분포를 레이어별로 계산하여 어텐션 맵으로 나타냄. 이를 통해 얕은 레이어에서는 어텐션이 다양한 토큰 유형에 비교적 고르게 분포하지만, 깊은 레이어에서는 시스템 프롬프트의 특정 앵커 토큰에 어텐션이 집중되고 이미지 토큰에 대한 어텐션은 극도로 희소해진다는 것을 보임.
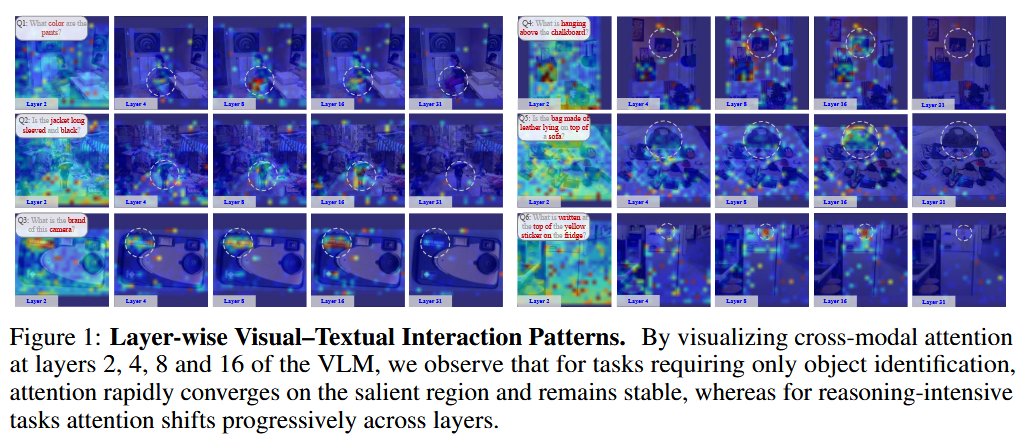
- AutoPrune의 Figure 1: 교차 모드 주의(cross-modal attention)가 레이어에 따라 어떻게 변화하는지를 작업 복잡도별로 시각화한 것임. 보려고 한 것은 단순한 작업과 복잡한 작업에서 시각-텍스트 간 주의 패턴이 어떻게 다른지임. 텍스트 토큰이 시각적 토큰에 부여하는 교차 모드 어텐션을 레이어 2, 4, 8, 16, 31에서 계산하여 이미지 위에 히트맵으로 나타냄. 이를 통해 단순한 작업(Q1~Q3)에서는 초기 레이어에서 주의가 대상 영역에 빠르게 수렴하여 안정적으로 유지되지만, 복잡한 작업(Q4~Q6)에서는 주의가 레이어마다 다른 영역으로 이동하며 점진적으로만 정답 영역에 수렴한다는 것을 보임.
Abstract
기존에는 디코더 후반부의 시각적 토큰이 상대적으로 적은 주의를 받는다는 경험적 관찰을 바탕으로, 레이어별로 미리 정해진 고정 스케줄에 따라 토큰을 제거하는 휴리스틱 기반 프루닝 방식이 주로 사용되었음.
⇒ 입력마다 다른 복잡도를 반영하지 못하고 모델의 실제 추론 과정에 맞춰 토큰 제거를 조정할 수 없다는 한계가 있었음.
⇒ AutoPrune은 시각적 토큰과 텍스트 토큰 간의 상호 정보량을 측정한 뒤, 이 신호를 예산 제약이 적용된 로지스틱 유지 곡선에 투영함으로써 샘플 및 작업의 복잡도에 따라 프루닝 정책을 동적으로 조정함.
1. Introduction
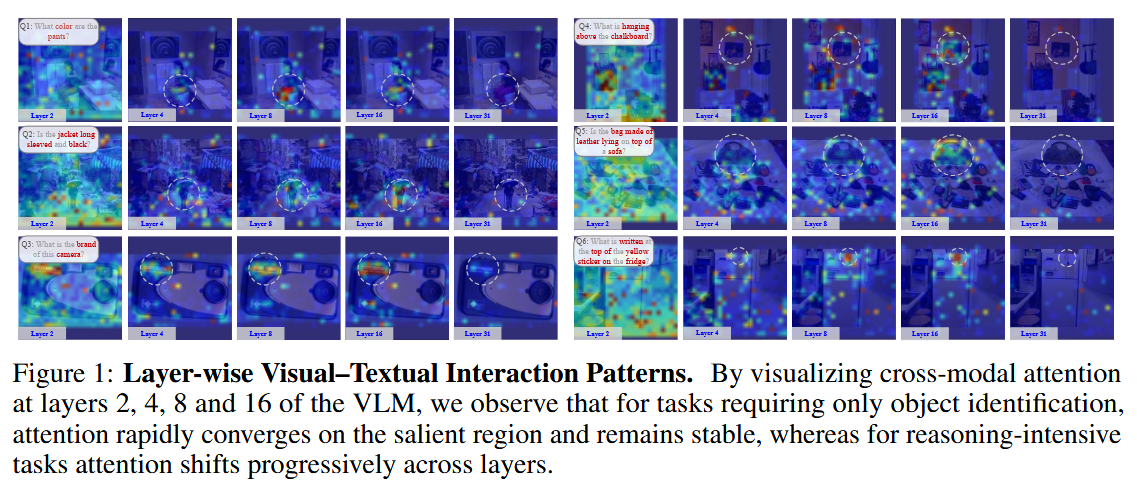
실험적으로도 돌출도 패턴이 이미지와 쿼리에 따라 크게 달라짐이 확인되었음. 이에 본 연구는 신경과학에서 영감을 얻어, 단순한 작업에서는 주의가 초기 레이어에서 빠르게 수렴하고 복잡한 작업에서는 분산된 주의가 여러 레이어에 걸쳐 유지된다는 탐색-활용 패턴이 VLM에서도 동일하게 나타남을 확인했으며, 이를 통해 고정된 프루닝 스케줄로는 다양한 복잡도의 추론 요구를 충족할 수 없음을 보임.
돌출도 패턴
돌출도(Saliency)는 각 시각적 토큰이 모델의 추론 과정에서 얼마나 중요하게 취급되는지를 나타내는 지표임. 구체적으로는 교차 모드 주의(cross-modal attention)에서 텍스트 토큰이 특정 시각적 토큰에 얼마나 높은 주의 가중치를 부여하는지를 의미함.
돌출도가 높은 토큰은 모델이 답변을 생성하는 데 중요하다고 판단하는 영역에 해당하고,
낮은 토큰은 상대적으로 불필요한 영역에 해당함.
그림 1에서 복잡한 작업은 오른쪽에 해당하는 Q4~Q6임.
- Q4는 "칠판 위에 걸려 있는 것이 무엇인가?"
- Q5는 "가죽 가방이 소파 위에 놓여 있는가?"
- Q6는 "냉장고의 노란 스티커 상단에 무엇이 적혀 있는가?"
이런 복잡한 작업의 특징은 두 가지로 요약할 수 있음.
첫째, 주의가 초기 레이어에서 넓게 분산된 상태를 유지하며 점진적으로만 감소함. 이는 모델이 정답과 관련된 증거가 어디에 있는지 불확실해하기 때문임.
둘째, 레이어 간 돌출도 위치가 변동함.
예컨대 Q4의 경우 모델이 처음에는 칠판에 주의를 주다가 중간 레이어에서 주변 영역으로 시선을 옮기고, 레이어 16에 이르러서야 실제 정답 영역으로 돌아오는 탐색 과정을 거침.
즉 복잡한 작업에서는 모델이 여러 후보 영역을 반복적으로 탐색하며 점진적으로 정답을 좁혀가는 패턴을 보임.
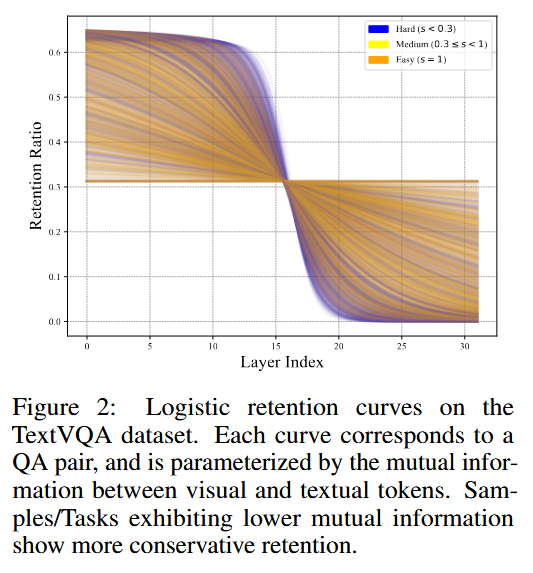
AutoPrune은 초기 레이어에서 시각적 토큰과 텍스트 토큰 간의 상호 정보량을 측정하여 입력 복잡성을 정량화한 뒤, 이 값을 인간의 탐색-전념-안정화 패턴을 모방한 로지스틱 유지 곡선에 매핑함.
상호 정보량이 높으면(단순한 샘플) 곡선이 초기 레이어에서 급격히 하강하여 공격적으로 프루닝하고,
낮으면(복잡한 샘플) 곡선의 하강을 후반 레이어로 지연시켜 보수적으로 프루닝함.
이때 곡선의 기울기와 변곡점이 상호 정보량에 의해 선형적으로 조절되며, 곡선을 적분하여 면적이 사용자가 지정한 계산 예산과 일치하도록 스케일링함으로써 고정된 예산 준수를 보장함.
2. Related Work
-
디코더 이전(Pre-decoder) 프루닝은 시각적 토큰이 LLM에 입력되기 전에 비지도 유사도나 경량 점수를 기반으로 토큰의 부분 집합을 미리 선택하는 방식이며, TopV와 FasterVLM이 대표적임.
-
디코더 내부(Intra-decoder) 프루닝은 LLM 레이어를 거치는 추론 과정 중에 미리 설정된 레이어별 스케줄이나 어텐션 통계량을 활용하여 토큰을 점진적으로 제거하는 방식이며, PyramidDrop과 ZipVL이 대표적임.
Q: 디코더 내부(Intra-decoder) 프루닝은 어느 단계에서 수행되는 것인가?
A: decoding(토큰 생성) 단계가 아니라 prefill 단계에서 수행됨. 시각적 토큰이 LLM 디코더의 여러 트랜스포머 레이어를 순차적으로 통과하는 과정 중에, 특정 레이어에서 토큰을 제거하는 방식임.
3. Method
3.1. Preliminaries
-
ξ(토큰 할당 정책)는 각 디코더 레이어에서 몇 개의 시각적 토큰을 유지할지를 결정하는 정책
-
π(토큰 선택 정책)는 유지할 토큰으로 결정된 수량 내에서 구체적으로 어떤 토큰을 남길지를 결정하는 정책
-
ρ(토큰 회생 정책)는 이전 레이어에서 제거된 토큰을 이후 레이어에서 다시 복원하여 재매핑할지를 결정하는 정책
토큰 프루닝의 목적은, 전체 계산 비용이 사전에 정한 예산 를 초과하지 않도록 하면서 모델의 성능 손실(기대 손실 L)을 최소화하는 것.
즉, 제한된 계산 자원 안에서 불필요한 시각적 토큰을 효과적으로 제거하여 효율성과 정확도를 동시에 확보하는 것이 핵심임.
3.2. Neuroscience Inspiration and Analysis
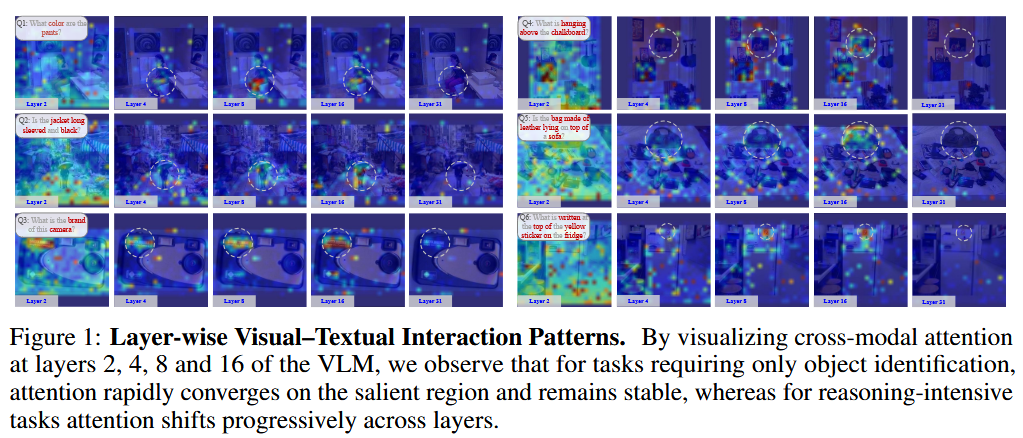
작업-샘플 적응형 토큰 수 감소:
-
단순한 작업: 교차 모드 주의가 초기 레이어에서 빠르게 대상 영역으로 수렴하므로 얕은 깊이에서 공격적인 프루닝이 가능함.
-
복잡한 작업: 주의가 넓게 분산된 채 점진적으로만 감소하므로, 토큰 제거를 더 깊은 레이어까지 미루는 것이 유리함.
이는 입력의 복잡도에 따라 글로벌 토큰 궤적을 동적으로 조절하는 적응형 프루닝 정책의 필요성을 시사함.
레이어 간 돌출도 위치 변동:
-
단순한 작업: 주의가 초기 레이어에서 수렴한 뒤 안정적으로 유지됨.
-
복잡한 작업: 돌출도의 위치가 레이어마다 변화하며, 모델이 여러 후보 영역을 탐색하다가 고차원 특징이 나타나면서 점진적으로 정답 영역으로 수렴함.
따라서 복잡한 작업에서는 이러한 탐색 과정을 지원하기 위해 레이어 전반에 걸쳐 더 많은 토큰을 유지해야 함.
3.3. Complexity-Adaptive Pruning
복잡도 지표:
상호 정보량(Mutual Information). 초기 레이어에서 시각적 토큰과 텍스트 토큰 간의 상호 정보량 I(V,T)를 계산하여 샘플·작업의 복잡도를 정량화함. 어텐션 가중치를 확률로 해석하여 결합 확률과 주변 확률을 추정하고, 이로부터 상호 정보량을 직접 산출함.
-
값이 크면 텍스트가 시각적 해석을 강하게 제약하는 단순한 작업이므로 공격적 프루닝이 가능
-
값이 작으면 대응이 약한 복잡한 작업이므로 보수적으로 토큰을 유지해야 함
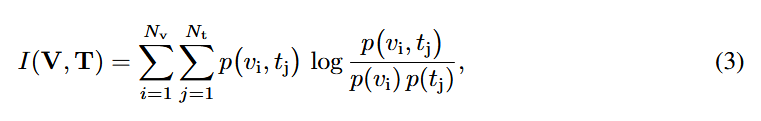
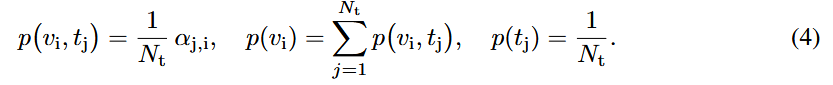
- : 시각, 텍스트 토큰 수
- : 텍스트 토큰 에서 시각 토큰 로의 attention score
프루닝 정책:
로지스틱 유지 함수. 이 상호 정보량 스칼라를 로지스틱(S자형) 유지 곡선에 매핑하여 레이어별 토큰 유지 비율을 결정함.
-
단순한 작업에서는 초기 레이어에서 급격히 토큰을 제거
-
복잡한 작업에서는 후반 레이어까지 토큰 제거를 지연시킴
로지스틱 함수를 선택한 이유는 형태가 단순하고, 하이퍼파라미터 조정만으로 곡선의 형태를 쉽게 변형하여 상호 정보량 지표와 직접 연동할 수 있기 때문임.
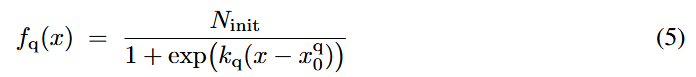
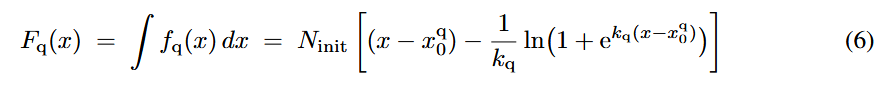
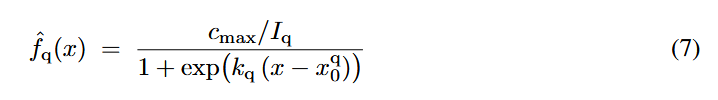
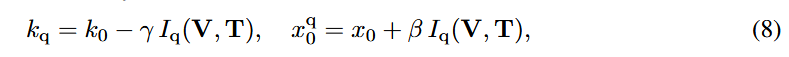
전체 과정
1단계: 상호 정보량 계산. 입력 이미지와 텍스트가 들어오면, 초기 레이어의 교차 모드 어텐션 맵에서 시각-텍스트 토큰 간 상호 정보량 I(V,T)를 계산함. (식 3, 4 사용)
2단계: 로지스틱 곡선 생성. 계산된 I(V,T)를 식 (8)에 대입하여 기울기 와 변곡점 를 산출하고, 이 값을 식 (5)에 넣어 해당 입력에 맞는 로지스틱 유지 곡선을 생성함.
3단계: 예산 맞춤 스케일링. 생성된 곡선을 식 (6)으로 적분하여 면적을 구한 뒤, 식 (7)로 곡선을 스케일링하여 곡선 아래 면적이 사전에 지정된 계산 예산 c_max와 일치하도록 함.
4단계: 레이어별 프루닝 실행. 각 레이어를 통과할 때마다 스케일링된 곡선에서 해당 레이어의 retention ratio를 읽어와 유지할 토큰 수를 정하고, 어텐션 점수가 낮은 토큰부터 제거함.
4. Experiments
-
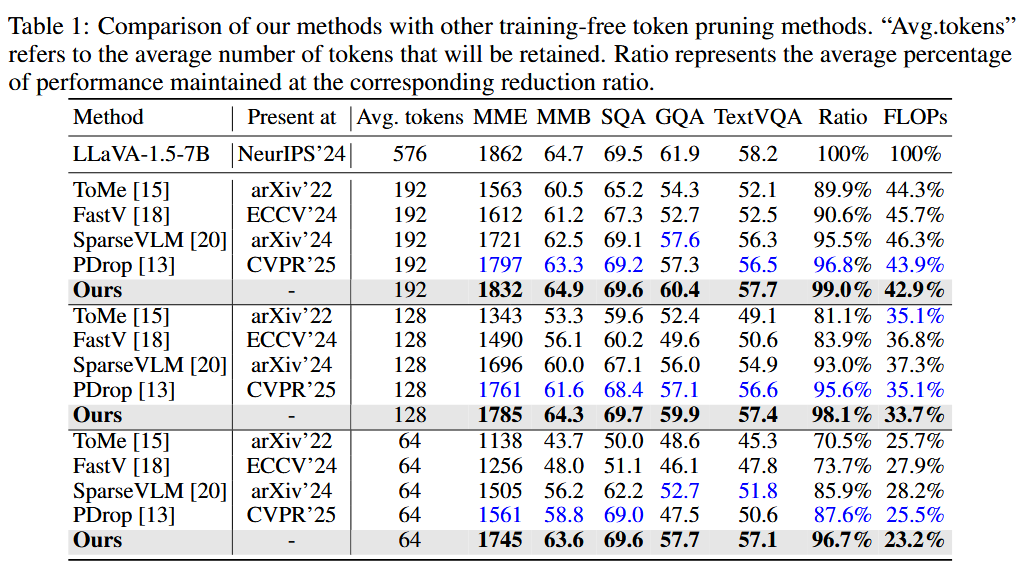
표 1 (LLaVA-1.5-7B 결과): 5개 벤치마크(MME, MMB, SQA, GQA, TextVQA)에서 기존 프루닝 방법들과 비교
-
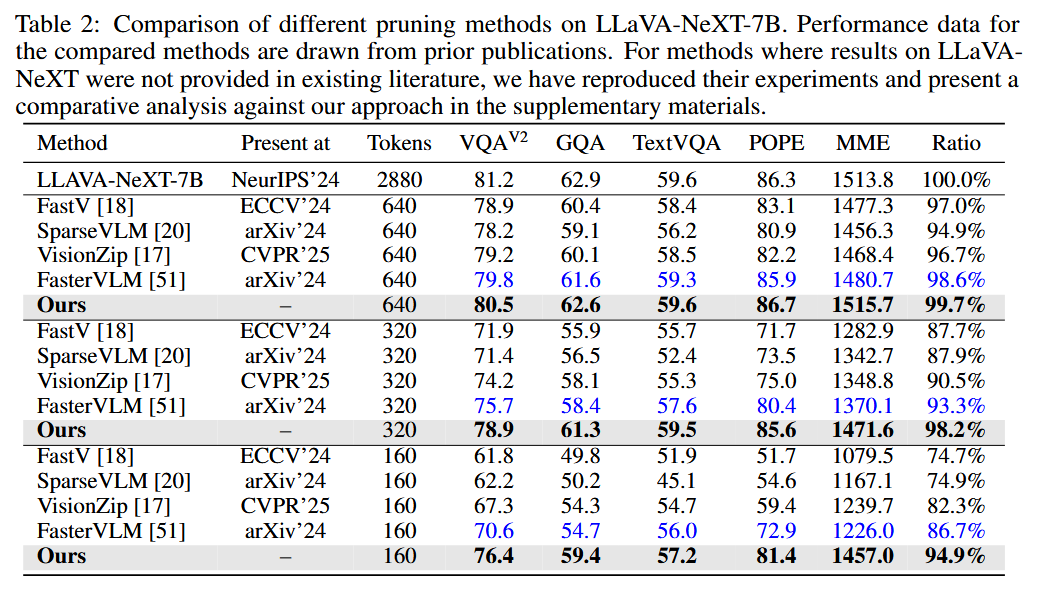
표 2 (LLaVA-NeXT-7B 결과): 다른 VLM에 적용하여 일반화 가능성을 검증
-
표 3 (자율 주행 Senna 모델 결과): 하이퍼파라미터 변경 없이 VLA 모델에 적용
4.1. LLaVA-1.5-7B에서 다양한 기존 방법들
4.2. LLaVA-NeXT-7B
4.3. 자율 주행

자율 주행은 속도가 성능에 영향을 줄 수 있을 듯. 왜냐하면, 빨리 핸들을 꺾어야 되는데, 전체 토큰으로 추론하면, 느려서 오히려 사고가 나는...
⇒ 좋은 접근인데, 그런 걸 평가하는 게 아님.
4.4. Ablation studies
생략
5. Conclusion and Limitation
생략
