PACT: Pruning and Clustering-Based Token Reduction for Faster Visual Language Models
PACT
코드
축1 (Modality): Image VLM + Video
축2 (압축 메커니즘): Pruning + Merging
축3 (학습 필요성): Training-free
축4 (압축 시점): LLM 내부 layer
축5 (Guidance 신호): Key-Query 내적 + Hidden state norm
축6 (적응성): Fixed ratio
축8 (타겟 모델): General VLM
칼
Abstract
FastV는 attention score로 토큰 중요도를 정의함PACT: Attention score없이 토큰 중요도를 정의
FastV는 only pruningPACT: pruning + merging (by DBDPC (Distance Bounded Density Peak Clustering))
1. Introduction
1단계: EUTI로 중요하지 않은 토큰을 prune 2단계: DBDPC로 남은 중요 토큰들을 클러스터링 3단계: 1단계에서 제거된 토큰 중 클러스터 센터에 충분히 가까운 것들을 다시 해당 클러스터에 편입 시켜 정보 손실을 복구4단계: 각 클러스터 내 토큰들을 하나의 대표 토큰으로 merge 하여 최종 토큰 수를 줄임
2.1. VLM
LLaVA-OneVision
이미지를 384×384 크롭으로 분할
SigLIP으로 인코딩 후 쌍선형 보간법으로 토큰 축소
최대 8,748개 토큰
InternVL2
이미지를 448×448 타일로 분할 (이미지당 최대 40타일)
InternViT로 처리 후 픽셀 셔플로 토큰 축소
최대 10,240개 토큰
Qwen2-VL
2D Rotary Positional Embeddings로 동적 해상도 지원
MLP 레이어로 인접 토큰 병합
고해상도 이미지 시 여전히 10,000개 이상 토큰 필요
2.2. Visual token reduction
LLaVA-PruMerge의 병합: 가지치기로 버려진 토큰의 정보를 유지된 토큰에 흡수시키는 것임. 목적은 프루닝으로 인한 정보 손실 완화임. 유지된 토큰들 사이의 중복은 건드리지 않으므로, 결과적으로 "무관한 토큰 제거"만 수행함.
PACT의 병합: DBDPC로 유지된 토큰들 중 시각적으로 유사한 것들을 클러스터링한 뒤 하나의 대표 토큰으로 합치는 것임. 목적은 시각적 중복 제거임. 여기에 프루닝(EUTI)까지 결합하므로, "무관한 토큰 제거"와 "중복 토큰 통합"을 동시에 수행함.
정리하면, LLaVA-PruMerge는 프루닝 후 정보 복구를 위해 병합하고, PACT는 프루닝과 별도로 중복 토큰을 줄이기 위해 병합한다는 점에서 근본적으로 다름.
3. Method
기호 의미 값 n n n 시각적 토큰 수 4 d d d 은닉 상태 차원 6 n h n_h n h 어텐션 헤드 수 2 d h d_h d h 헤드당 차원 3
참고로 보통 d = n h × d h d = n_h \times d_h d = n h × d h 6 = 2 × 3 6 = 2 \times 3 6 = 2 × 3
1. 은닉 상태 H ∈ R n × d H \in \mathbb{R}^{n \times d} H ∈ R n × d R 4 × 6 \mathbb{R}^{4 \times 6} R 4 × 6
이미지를 4개의 패치(토큰)로 나눴다고 생각하면:
H = [ p 1 p 2 p 3 p 4 ] = [ 0.1 0.3 0.5 0.2 0.4 0.6 0.2 0.1 0.4 0.3 0.5 0.1 0.5 0.2 0.3 0.1 0.6 0.4 0.3 0.4 0.1 0.5 0.2 0.3 ] H = \begin{bmatrix} p_1 \\ p_2 \\ p_3 \\ p_4 \end{bmatrix} = \begin{bmatrix} 0.1 & 0.3 & 0.5 & 0.2 & 0.4 & 0.6 \\ 0.2 & 0.1 & 0.4 & 0.3 & 0.5 & 0.1 \\ 0.5 & 0.2 & 0.3 & 0.1 & 0.6 & 0.4 \\ 0.3 & 0.4 & 0.1 & 0.5 & 0.2 & 0.3 \end{bmatrix} H = ⎣ ⎢ ⎢ ⎢ ⎡ p 1 p 2 p 3 p 4 ⎦ ⎥ ⎥ ⎥ ⎤ = ⎣ ⎢ ⎢ ⎢ ⎡ 0 . 1 0 . 2 0 . 5 0 . 3 0 . 3 0 . 1 0 . 2 0 . 4 0 . 5 0 . 4 0 . 3 0 . 1 0 . 2 0 . 3 0 . 1 0 . 5 0 . 4 0 . 5 0 . 6 0 . 2 0 . 6 0 . 1 0 . 4 0 . 3 ⎦ ⎥ ⎥ ⎥ ⎤
각 행이 하나의 시각적 토큰(이미지 패치)의 표현입니다.
2. 키 행렬 K ∈ R n × n h × d h K \in \mathbb{R}^{n \times n_h \times d_h} K ∈ R n × n h × d h R 4 × 2 × 3 \mathbb{R}^{4 \times 2 \times 3} R 4 × 2 × 3
이것은 3차원 텐서 입니다. 각 토큰(n n n n h n_h n h d h d_h d h
구조를 직관적으로 보면:
토큰 1: 헤드1 → [0.1, 0.3, 0.5] 헤드2 → [0.2, 0.4, 0.6]
토큰 2: 헤드1 → [0.2, 0.1, 0.4] 헤드2 → [0.3, 0.5, 0.1]
토큰 3: 헤드1 → [0.5, 0.2, 0.3] 헤드2 → [0.1, 0.6, 0.4]
토큰 4: 헤드1 → [0.3, 0.4, 0.1] 헤드2 → [0.5, 0.2, 0.3]3. 아래첨자·위첨자 표기법: k i ( j ) k_i^{(j)} k i ( j )
k i ( j ) k_i^{(j)} k i ( j ) i i i j j j
위 표에서 몇 가지를 꺼내보면:
k 1 ( 1 ) = [ 0.1 , 0.3 , 0.5 ] ← 토큰 1, 헤드 1 k_1^{(1)} = [0.1,\ 0.3,\ 0.5] \quad \leftarrow \text{토큰 1, 헤드 1} k 1 ( 1 ) = [ 0 . 1 , 0 . 3 , 0 . 5 ] ← 토큰 1, 헤드 1
k 1 ( 2 ) = [ 0.2 , 0.4 , 0.6 ] ← 토큰 1, 헤드 2 k_1^{(2)} = [0.2,\ 0.4,\ 0.6] \quad \leftarrow \text{토큰 1, 헤드 2} k 1 ( 2 ) = [ 0 . 2 , 0 . 4 , 0 . 6 ] ← 토큰 1, 헤드 2
k 3 ( 1 ) = [ 0.5 , 0.2 , 0.3 ] ← 토큰 3, 헤드 1 k_3^{(1)} = [0.5,\ 0.2,\ 0.3] \quad \leftarrow \text{토큰 3, 헤드 1} k 3 ( 1 ) = [ 0 . 5 , 0 . 2 , 0 . 3 ] ← 토큰 3, 헤드 1
k 4 ( 2 ) = [ 0.5 , 0.2 , 0.3 ] ← 토큰 4, 헤드 2 k_4^{(2)} = [0.5,\ 0.2,\ 0.3] \quad \leftarrow \text{토큰 4, 헤드 2} k 4 ( 2 ) = [ 0 . 5 , 0 . 2 , 0 . 3 ] ← 토큰 4, 헤드 2
쿼리도 동일한 구조입니다. 예를 들어 q 2 ( 1 ) q_2^{(1)} q 2 ( 1 ) R 3 \mathbb{R}^{3} R 3
3.1. Unimportant tokens identification
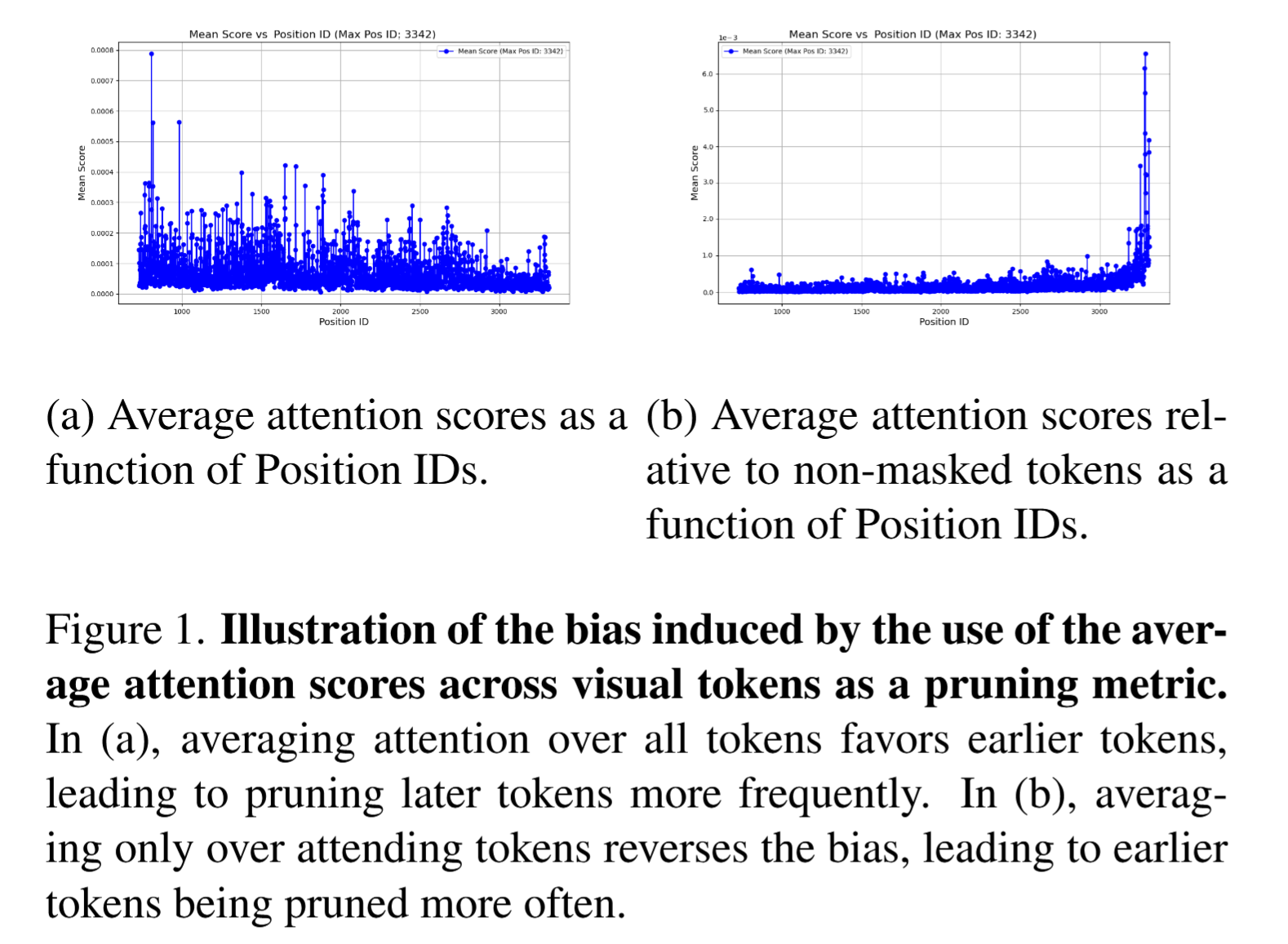
토큰 중요도 를 어떤 토큰이 다른 모든 토큰으로부터 받는 총 어텐션 점수 로 정의하는 것에는 세 가지 주요 단점이 있음.
현재의 VLMs는 attention score 출력을 지원하지 않는 FlashAttention을 사용.
Attention score는 masking으로 인해 편향이 발생.
(a)의 경우:
(b)의 경우:
단일 레이어의 키·쿼리만으로는 전체 모델에 걸친 토큰의 중요도를 포착하기 어려움. 각 레이어마다 저수준(색상, 엣지)부터 고수준(객체, 의미)까지 서로 다른 특징에 집중 하기 때문에, 한 레이어의 관점만으로 판단하면 다른 레이어에서 중요한 토큰을 놓칠 수 있음.
Efficient Unimportant Tokens Identification (EUTI)
Hidden state 의 norm 이 각 visual token이 network를 통해 얼마나 많은 정보 를 전달하는지를 반영한다고 가정.
다음 과정을 따라가면 중요한 토큰들, 않은 토큰들을 구분 가능.
예시)
1. 은닉 상태 H ∈ R n × d H \in \mathbb{R}^{n \times d} H ∈ R n × d R 4 × 6 \mathbb{R}^{4 \times 6} R 4 × 6
이미지를 4개의 패치(토큰)로 나눴다고 생각하면:
H = [ h 1 h 2 h 3 h 4 ] = [ 0.1 0.3 0.5 0.2 0.4 0.6 0.2 0.1 0.4 0.3 0.5 0.1 0.5 0.2 0.3 0.1 0.6 0.4 0.3 0.4 0.1 0.5 0.2 0.3 ] H = \begin{bmatrix} h_1 \\ h_2 \\ h_3 \\ h_4 \end{bmatrix} = \begin{bmatrix} 0.1 & 0.3 & 0.5 & 0.2 & 0.4 & 0.6 \\ 0.2 & 0.1 & 0.4 & 0.3 & 0.5 & 0.1 \\ 0.5 & 0.2 & 0.3 & 0.1 & 0.6 & 0.4 \\ 0.3 & 0.4 & 0.1 & 0.5 & 0.2 & 0.3 \end{bmatrix} H = ⎣ ⎢ ⎢ ⎢ ⎡ h 1 h 2 h 3 h 4 ⎦ ⎥ ⎥ ⎥ ⎤ = ⎣ ⎢ ⎢ ⎢ ⎡ 0 . 1 0 . 2 0 . 5 0 . 3 0 . 3 0 . 1 0 . 2 0 . 4 0 . 5 0 . 4 0 . 3 0 . 1 0 . 2 0 . 3 0 . 1 0 . 5 0 . 4 0 . 5 0 . 6 0 . 2 0 . 6 0 . 1 0 . 4 0 . 3 ⎦ ⎥ ⎥ ⎥ ⎤
각 행이 하나의 시각적 토큰(이미지 패치)의 표현입니다.
2. 키 행렬 K ∈ R n × n h × d h K \in \mathbb{R}^{n \times n_h \times d_h} K ∈ R n × n h × d h R 4 × 2 × 3 \mathbb{R}^{4 \times 2 \times 3} R 4 × 2 × 3
3차원 텐서입니다. 각 토큰(n n n n h n_h n h d h d_h d h
토큰 1: 헤드1 → [0.1, 0.3, 0.5] 헤드2 → [0.2, 0.4, 0.6]
토큰 2: 헤드1 → [0.2, 0.1, 0.4] 헤드2 → [0.3, 0.5, 0.1]
토큰 3: 헤드1 → [0.5, 0.2, 0.3] 헤드2 → [0.1, 0.6, 0.4]
토큰 4: 헤드1 → [0.3, 0.4, 0.1] 헤드2 → [0.5, 0.2, 0.3]3. 아래첨자·위첨자 표기법: k i ( j ) k_i^{(j)} k i ( j )
k i ( j ) k_i^{(j)} k i ( j ) i i i j j j
k 1 ( 1 ) = [ 0.1 , 0.3 , 0.5 ] ← 토큰 1, 헤드 1 k_1^{(1)} = [0.1,\ 0.3,\ 0.5] \quad \leftarrow \text{토큰 1, 헤드 1} k 1 ( 1 ) = [ 0 . 1 , 0 . 3 , 0 . 5 ] ← 토큰 1, 헤드 1
k 1 ( 2 ) = [ 0.2 , 0.4 , 0.6 ] ← 토큰 1, 헤드 2 k_1^{(2)} = [0.2,\ 0.4,\ 0.6] \quad \leftarrow \text{토큰 1, 헤드 2} k 1 ( 2 ) = [ 0 . 2 , 0 . 4 , 0 . 6 ] ← 토큰 1, 헤드 2
k 3 ( 1 ) = [ 0.5 , 0.2 , 0.3 ] ← 토큰 3, 헤드 1 k_3^{(1)} = [0.5,\ 0.2,\ 0.3] \quad \leftarrow \text{토큰 3, 헤드 1} k 3 ( 1 ) = [ 0 . 5 , 0 . 2 , 0 . 3 ] ← 토큰 3, 헤드 1
k 4 ( 2 ) = [ 0.5 , 0.2 , 0.3 ] ← 토큰 4, 헤드 2 k_4^{(2)} = [0.5,\ 0.2,\ 0.3] \quad \leftarrow \text{토큰 4, 헤드 2} k 4 ( 2 ) = [ 0 . 5 , 0 . 2 , 0 . 3 ] ← 토큰 4, 헤드 2
쿼리도 동일한 구조입니다. 예를 들어 q 2 ( 1 ) q_2^{(1)} q 2 ( 1 ) R 3 \mathbb{R}^{3} R 3
4. 쿼리 행렬 Q Q Q
토큰 1: 헤드1 → [0.3, 0.1, 0.4] 헤드2 → [0.5, 0.2, 0.1]
토큰 2: 헤드1 → [0.1, 0.5, 0.2] 헤드2 → [0.3, 0.4, 0.3]
토큰 3: 헤드1 → [0.4, 0.3, 0.6] 헤드2 → [0.1, 0.6, 0.5]
토큰 4: 헤드1 → [0.2, 0.1, 0.8] 헤드2 → [0.7, 0.2, 0.1]단계 1: 글로벌 쿼리 Q g l o b a l Q_{global} Q g l o b a l
Q g l o b a l = 1 n ∑ i = 1 n Q i = 1 4 ( Q 1 + Q 2 + Q 3 + Q 4 ) Q_{global} = \frac{1}{n}\sum_{i=1}^{n} Q_i = \frac{1}{4}(Q_1 + Q_2 + Q_3 + Q_4) Q g l o b a l = n 1 ∑ i = 1 n Q i = 4 1 ( Q 1 + Q 2 + Q 3 + Q 4 )
헤드 1
q g l o b a l ( 1 ) = 1 4 ( [ 0.3 , 0.1 , 0.4 ] + [ 0.1 , 0.5 , 0.2 ] + [ 0.4 , 0.3 , 0.6 ] + [ 0.2 , 0.1 , 0.8 ] ) q_{global}^{(1)} = \frac{1}{4}\big([0.3, 0.1, 0.4] + [0.1, 0.5, 0.2] + [0.4, 0.3, 0.6] + [0.2, 0.1, 0.8]\big) q g l o b a l ( 1 ) = 4 1 ( [ 0 . 3 , 0 . 1 , 0 . 4 ] + [ 0 . 1 , 0 . 5 , 0 . 2 ] + [ 0 . 4 , 0 . 3 , 0 . 6 ] + [ 0 . 2 , 0 . 1 , 0 . 8 ] )
= 1 4 [ 1.0 , 1.0 , 2.0 ] = [ 0.25 , 0.25 , 0.50 ] = \frac{1}{4}[1.0,\ 1.0,\ 2.0] = [0.25,\ 0.25,\ 0.50] = 4 1 [ 1 . 0 , 1 . 0 , 2 . 0 ] = [ 0 . 2 5 , 0 . 2 5 , 0 . 5 0 ]
헤드 2
q g l o b a l ( 2 ) = 1 4 ( [ 0.5 , 0.2 , 0.1 ] + [ 0.3 , 0.4 , 0.3 ] + [ 0.1 , 0.6 , 0.5 ] + [ 0.7 , 0.2 , 0.1 ] ) q_{global}^{(2)} = \frac{1}{4}\big([0.5, 0.2, 0.1] + [0.3, 0.4, 0.3] + [0.1, 0.6, 0.5] + [0.7, 0.2, 0.1]\big) q g l o b a l ( 2 ) = 4 1 ( [ 0 . 5 , 0 . 2 , 0 . 1 ] + [ 0 . 3 , 0 . 4 , 0 . 3 ] + [ 0 . 1 , 0 . 6 , 0 . 5 ] + [ 0 . 7 , 0 . 2 , 0 . 1 ] )
= 1 4 [ 1.6 , 1.4 , 1.0 ] = [ 0.40 , 0.35 , 0.25 ] = \frac{1}{4}[1.6,\ 1.4,\ 1.0] = [0.40,\ 0.35,\ 0.25] = 4 1 [ 1 . 6 , 1 . 4 , 1 . 0 ] = [ 0 . 4 0 , 0 . 3 5 , 0 . 2 5 ]
결과
Q g l o b a l = { 헤드 1: [ 0.25 , 0.25 , 0.50 ] 헤드 2: [ 0.40 , 0.35 , 0.25 ] Q_{global} = \begin{cases} \text{헤드 1:} & [0.25,\ 0.25,\ 0.50] \\ \text{헤드 2:} & [0.40,\ 0.35,\ 0.25] \end{cases} Q g l o b a l = { 헤드 1: 헤드 2: [ 0 . 2 5 , 0 . 2 5 , 0 . 5 0 ] [ 0 . 4 0 , 0 . 3 5 , 0 . 2 5 ]
의미 : 4개의 토큰이 "전체적으로 어떤 정보를 찾고 있는지"를 평균낸 대표 쿼리입니다.
단계 2: 각 토큰의 중요도 점수 계산 (내적)
각 토큰 i i i k i ( j ) k_i^{(j)} k i ( j ) q g l o b a l ( j ) q_{global}^{(j)} q g l o b a l ( j ) 내적 을 헤드별로 구합니다.
헤드 1: q g l o b a l ( 1 ) = [ 0.25 , 0.25 , 0.50 ] q_{global}^{(1)} = [0.25,\ 0.25,\ 0.50] q g l o b a l ( 1 ) = [ 0 . 2 5 , 0 . 2 5 , 0 . 5 0 ]
토큰 k i ( 1 ) k_i^{(1)} k i ( 1 ) 내적 계산 점수 1 [0.1, 0.3, 0.5] 0.25 × 0.1 + 0.25 × 0.3 + 0.50 × 0.5 0.25 \times 0.1 + 0.25 \times 0.3 + 0.50 \times 0.5 0 . 2 5 × 0 . 1 + 0 . 2 5 × 0 . 3 + 0 . 5 0 × 0 . 5 0.350 2 [0.2, 0.1, 0.4] 0.25 × 0.2 + 0.25 × 0.1 + 0.50 × 0.4 0.25 \times 0.2 + 0.25 \times 0.1 + 0.50 \times 0.4 0 . 2 5 × 0 . 2 + 0 . 2 5 × 0 . 1 + 0 . 5 0 × 0 . 4 0.275 3 [0.5, 0.2, 0.3] 0.25 × 0.5 + 0.25 × 0.2 + 0.50 × 0.3 0.25 \times 0.5 + 0.25 \times 0.2 + 0.50 \times 0.3 0 . 2 5 × 0 . 5 + 0 . 2 5 × 0 . 2 + 0 . 5 0 × 0 . 3 0.325 4 [0.3, 0.4, 0.1] 0.25 × 0.3 + 0.25 × 0.4 + 0.50 × 0.1 0.25 \times 0.3 + 0.25 \times 0.4 + 0.50 \times 0.1 0 . 2 5 × 0 . 3 + 0 . 2 5 × 0 . 4 + 0 . 5 0 × 0 . 1 0.225
헤드 2: q g l o b a l ( 2 ) = [ 0.40 , 0.35 , 0.25 ] q_{global}^{(2)} = [0.40,\ 0.35,\ 0.25] q g l o b a l ( 2 ) = [ 0 . 4 0 , 0 . 3 5 , 0 . 2 5 ]
토큰 k i ( 2 ) k_i^{(2)} k i ( 2 ) 내적 계산 점수 1 [0.2, 0.4, 0.6] 0.40 × 0.2 + 0.35 × 0.4 + 0.25 × 0.6 0.40 \times 0.2 + 0.35 \times 0.4 + 0.25 \times 0.6 0 . 4 0 × 0 . 2 + 0 . 3 5 × 0 . 4 + 0 . 2 5 × 0 . 6 0.370 2 [0.3, 0.5, 0.1] 0.40 × 0.3 + 0.35 × 0.5 + 0.25 × 0.1 0.40 \times 0.3 + 0.35 \times 0.5 + 0.25 \times 0.1 0 . 4 0 × 0 . 3 + 0 . 3 5 × 0 . 5 + 0 . 2 5 × 0 . 1 0.320 3 [0.1, 0.6, 0.4] 0.40 × 0.1 + 0.35 × 0.6 + 0.25 × 0.4 0.40 \times 0.1 + 0.35 \times 0.6 + 0.25 \times 0.4 0 . 4 0 × 0 . 1 + 0 . 3 5 × 0 . 6 + 0 . 2 5 × 0 . 4 0.350 4 [0.5, 0.2, 0.3] 0.40 × 0.5 + 0.35 × 0.2 + 0.25 × 0.3 0.40 \times 0.5 + 0.35 \times 0.2 + 0.25 \times 0.3 0 . 4 0 × 0 . 5 + 0 . 3 5 × 0 . 2 + 0 . 2 5 × 0 . 3 0.345
중요도 점수 요약
토큰 헤드 1 점수 헤드 2 점수 토큰 1 0.350 0.370 토큰 2 0.275 0.320 토큰 3 0.325 0.350 토큰 4 0.225 0.345
토큰 1 이 두 헤드 모두에서 가장 높은 점수를 받았습니다. 이는 토큰 1의 키가 "전체 토큰들이 평균적으로 찾고 있는 정보(글로벌 쿼리)"와 가장 잘 부합한다는 뜻입니다.
단계 3: 헤드별 소프트맥스 적용
소프트맥스는 같은 헤드 내의 4개 토큰 사이에서 적용합니다.
Softmax ( x i ) = e x i ∑ k = 1 4 e x k \text{Softmax}(x_i) = \frac{e^{x_i}}{\sum_{k=1}^{4} e^{x_k}} Softmax ( x i ) = ∑ k = 1 4 e x k e x i
헤드 1: 내적값 [0.350, 0.275, 0.325, 0.225]
e 0.350 = 1.419 , e 0.275 = 1.317 , e 0.325 = 1.384 , e 0.225 = 1.252 e^{0.350} = 1.419, \quad e^{0.275} = 1.317, \quad e^{0.325} = 1.384, \quad e^{0.225} = 1.252 e 0 . 3 5 0 = 1 . 4 1 9 , e 0 . 2 7 5 = 1 . 3 1 7 , e 0 . 3 2 5 = 1 . 3 8 4 , e 0 . 2 2 5 = 1 . 2 5 2
합 = 1.419 + 1.317 + 1.384 + 1.252 = 5.372 \text{합} = 1.419 + 1.317 + 1.384 + 1.252 = 5.372 합 = 1 . 4 1 9 + 1 . 3 1 7 + 1 . 3 8 4 + 1 . 2 5 2 = 5 . 3 7 2
토큰 e x e^{x} e x 소프트맥스 1 1.419 1.419 / 5.372 = 1.419 / 5.372 = 1 . 4 1 9 / 5 . 3 7 2 = 0.2642 2 1.317 1.317 / 5.372 = 1.317 / 5.372 = 1 . 3 1 7 / 5 . 3 7 2 = 0.2452 3 1.384 1.384 / 5.372 = 1.384 / 5.372 = 1 . 3 8 4 / 5 . 3 7 2 = 0.2577 4 1.252 1.252 / 5.372 = 1.252 / 5.372 = 1 . 2 5 2 / 5 . 3 7 2 = 0.2330
헤드 2: 내적값 [0.370, 0.320, 0.350, 0.345]
e 0.370 = 1.448 , e 0.320 = 1.377 , e 0.350 = 1.419 , e 0.345 = 1.412 e^{0.370} = 1.448, \quad e^{0.320} = 1.377, \quad e^{0.350} = 1.419, \quad e^{0.345} = 1.412 e 0 . 3 7 0 = 1 . 4 4 8 , e 0 . 3 2 0 = 1 . 3 7 7 , e 0 . 3 5 0 = 1 . 4 1 9 , e 0 . 3 4 5 = 1 . 4 1 2
합 = 1.448 + 1.377 + 1.419 + 1.412 = 5.656 \text{합} = 1.448 + 1.377 + 1.419 + 1.412 = 5.656 합 = 1 . 4 4 8 + 1 . 3 7 7 + 1 . 4 1 9 + 1 . 4 1 2 = 5 . 6 5 6
토큰 e x e^{x} e x 소프트맥스 1 1.448 1.448 / 5.656 = 1.448 / 5.656 = 1 . 4 4 8 / 5 . 6 5 6 = 0.2560 2 1.377 1.377 / 5.656 = 1.377 / 5.656 = 1 . 3 7 7 / 5 . 6 5 6 = 0.2434 3 1.419 1.419 / 5.656 = 1.419 / 5.656 = 1 . 4 1 9 / 5 . 6 5 6 = 0.2509 4 1.412 1.412 / 5.656 = 1.412 / 5.656 = 1 . 4 1 2 / 5 . 6 5 6 = 0.2496
단계 4: 헤드 간 평균
avg i = 1 n h ∑ j = 1 n h Softmax ( k i ( j ) ⋅ q g l o b a l ( j ) ) \text{avg}_i = \frac{1}{n_h}\sum_{j=1}^{n_h} \text{Softmax}(k_i^{(j)} \cdot q_{global}^{(j)}) avg i = n h 1 ∑ j = 1 n h Softmax ( k i ( j ) ⋅ q g l o b a l ( j ) )
토큰 헤드 1 헤드 2 평균 1 0.2642 0.2560 0.2601 2 0.2452 0.2434 0.2443 3 0.2577 0.2509 0.2543 4 0.2330 0.2496 0.2413
단계 5: 은닉 상태 노름 ∥ h i ∥ 2 \|h_i\|_2 ∥ h i ∥ 2
처음에 설정한 H H H
토큰 h i h_i h i ∥ h i ∥ 2 \|h_i\|_2 ∥ h i ∥ 2 1 [0.1, 0.3, 0.5, 0.2, 0.4, 0.6] 0.01 + 0.09 + 0.25 + 0.04 + 0.16 + 0.36 = 0.91 = \sqrt{0.01+0.09+0.25+0.04+0.16+0.36} = \sqrt{0.91} = 0 . 0 1 + 0 . 0 9 + 0 . 2 5 + 0 . 0 4 + 0 . 1 6 + 0 . 3 6 = 0 . 9 1 = 0.954 2 [0.2, 0.1, 0.4, 0.3, 0.5, 0.1] 0.04 + 0.01 + 0.16 + 0.09 + 0.25 + 0.01 = 0.56 = \sqrt{0.04+0.01+0.16+0.09+0.25+0.01} = \sqrt{0.56} = 0 . 0 4 + 0 . 0 1 + 0 . 1 6 + 0 . 0 9 + 0 . 2 5 + 0 . 0 1 = 0 . 5 6 = 0.748 3 [0.5, 0.2, 0.3, 0.1, 0.6, 0.4] 0.25 + 0.04 + 0.09 + 0.01 + 0.36 + 0.16 = 0.91 = \sqrt{0.25+0.04+0.09+0.01+0.36+0.16} = \sqrt{0.91} = 0 . 2 5 + 0 . 0 4 + 0 . 0 9 + 0 . 0 1 + 0 . 3 6 + 0 . 1 6 = 0 . 9 1 = 0.954 4 [0.3, 0.4, 0.1, 0.5, 0.2, 0.3] 0.09 + 0.16 + 0.01 + 0.25 + 0.04 + 0.09 = 0.64 = \sqrt{0.09+0.16+0.01+0.25+0.04+0.09} = \sqrt{0.64} = 0 . 0 9 + 0 . 1 6 + 0 . 0 1 + 0 . 2 5 + 0 . 0 4 + 0 . 0 9 = 0 . 6 4 = 0.800
단계 6: 최종 중요도 점수 s i s_i s i
s i = 1 n h ∑ j = 1 n h Softmax ( k i ( j ) ⋅ Q g l o b a l ( j ) ) ⋅ ∥ h i ∥ 2 s_i = \frac{1}{n_h} \sum_{j=1}^{n_h} \text{Softmax} \left( k_i^{(j)} \cdot Q_{global}^{(j)} \right) \cdot \|h_i\|_2 s i = n h 1 ∑ j = 1 n h Softmax ( k i ( j ) ⋅ Q g l o b a l ( j ) ) ⋅ ∥ h i ∥ 2
즉, s i = avg i × ∥ h i ∥ 2 s_i = \text{avg}_i \times \|h_i\|_2 s i = avg i × ∥ h i ∥ 2
토큰 헤드 평균 × 노름 s i s_i s i 1 0.2601 × 0.954 0.2481 2 0.2443 × 0.748 0.1827 3 0.2543 × 0.954 0.2426 4 0.2413 × 0.800 0.1930
점수 순위: 토큰 1 (0.2481) > 토큰 3 (0.2426) > 토큰 4 (0.1930) > 토큰 2 (0.1827)
단계 7: λ \lambda λ
λ \lambda λ
S i m p o r t a n t = { i ∣ s i ≥ Percentile ( s , λ ) } S_{important} = \{i \mid s_i \geq \text{Percentile}(s, \lambda)\} S i m p o r t a n t = { i ∣ s i ≥ Percentile ( s , λ ) }
S u n i m p o r t a n t = { i ∣ s i < Percentile ( s , λ ) } S_{unimportant} = \{i \mid s_i < \text{Percentile}(s, \lambda)\} S u n i m p o r t a n t = { i ∣ s i < Percentile ( s , λ ) }
예시 A: λ = 0.5 \lambda = 0.5 λ = 0 . 5
점수를 정렬하면: [0.1827, 0.1930, 0.2426, 0.2481]
50번째 퍼센타일 = 하위 2개와 상위 2개의 경계 ≈ 0.2178
S i m p o r t a n t = { i ∣ s i ≥ 0.2178 } = { 토큰 1 , 토큰 3 } S_{important} = \{i \mid s_i \geq 0.2178\} = \{\text{토큰 1},\ \text{토큰 3}\} S i m p o r t a n t = { i ∣ s i ≥ 0 . 2 1 7 8 } = { 토큰 1 , 토큰 3 }
S u n i m p o r t a n t = { i ∣ s i < 0.2178 } = { 토큰 2 , 토큰 4 } S_{unimportant} = \{i \mid s_i < 0.2178\} = \{\text{토큰 2},\ \text{토큰 4}\} S u n i m p o r t a n t = { i ∣ s i < 0 . 2 1 7 8 } = { 토큰 2 , 토큰 4 }
예시 B: λ = 0.25 \lambda = 0.25 λ = 0 . 2 5
25번째 퍼센타일 ≈ 0.1879 (하위 1개만 걸림)
S i m p o r t a n t = { 토큰 1 , 토큰 3 , 토큰 4 } S_{important} = \{\text{토큰 1},\ \text{토큰 3},\ \text{토큰 4}\} S i m p o r t a n t = { 토큰 1 , 토큰 3 , 토큰 4 }
S u n i m p o r t a n t = { 토큰 2 } S_{unimportant} = \{\text{토큰 2}\} S u n i m p o r t a n t = { 토큰 2 }
전체 흐름 요약
내적 ⏟ 토큰이 얼마나 "찾는 정보"와 맞는가 → softmax 상대 확률 ⏟ 헤드 내 정규화 → 헤드 평균 어텐션 중요도 ⏟ 헤드 간 종합 → × ∥ h i ∥ 2 s i ⏟ 표현 크기까지 반영 \underbrace{\text{내적}}_{\text{토큰이 얼마나 "찾는 정보"와 맞는가}} \xrightarrow{\text{softmax}} \underbrace{\text{상대 확률}}_{\text{헤드 내 정규화}} \xrightarrow{\text{헤드 평균}} \underbrace{\text{어텐션 중요도}}_{\text{헤드 간 종합}} \xrightarrow{\times \|h_i\|_2} \underbrace{s_i}_{\text{표현 크기까지 반영}} 토큰이 얼마나 " 찾는 정보 " 와 맞는가 내적 softmax 헤드 내 정규화 상대 확률 헤드 평균 헤드 간 종합 어텐션 중요도 × ∥ h i ∥ 2 표현 크기까지 반영 s i
3.2. Clustering-based merging of visual tokens
다음 과정을 따라가면 클러스터 집합을 얻을 수 있음.
모든 점의 밀도 ρ \rho ρ
밀도 1위 → 무조건 첫 번째 중심점.
밀도 2위 → 기존 중심점들과의 최소 거리가 d c d_c d c
밀도 3위, 4위, ... 같은 방식으로 반복.
중심이 다 정해지면, 중심이 아닌 모든 점을 가장 가까운 중심에 할당.
예시)
단계 8: DBDPC 입력 준비 — K ′ K' K ′
K ′ = { u i ∈ K ∣ i ∈ S i m p o r t a n t } K' = \{u_i \in K \mid i \in S_{important}\} K ′ = { u i ∈ K ∣ i ∈ S i m p o r t a n t }
DBDPC는 하나의 어텐션 헤드 의 키 벡터를 사용합니다. 여기서는 헤드 1을 사용합니다.
벡터 원래 토큰 u i u_i u i u 1 u_1 u 1 토큰 1 [0.1, 0.3, 0.5] u 2 u_2 u 2 토큰 3 [0.5, 0.2, 0.3] u 3 u_3 u 3 토큰 4 [0.3, 0.4, 0.1]
입력: q = 3 q = 3 q = 3 d 1 = 3 d_1 = 3 d 1 = 3
단계 9: 거리 행렬 계산
d i j = 1 − u i ⋅ u j ∥ u i ∥ 2 ∥ u j ∥ 2 d_{ij} = 1 - \frac{u_i \cdot u_j}{\|u_i\|_2 \|u_j\|_2} d i j = 1 − ∥ u i ∥ 2 ∥ u j ∥ 2 u i ⋅ u j
이것은 코사인 거리 입니다. 값이 0이면 완전히 같은 방향, 1이면 직교, 2이면 정반대 방향입니다.
먼저 노름 계산
∥ u 1 ∥ = 0.01 + 0.09 + 0.25 = 0.35 = 0.5916 \|u_1\| = \sqrt{0.01 + 0.09 + 0.25} = \sqrt{0.35} = 0.5916 ∥ u 1 ∥ = 0 . 0 1 + 0 . 0 9 + 0 . 2 5 = 0 . 3 5 = 0 . 5 9 1 6
∥ u 2 ∥ = 0.25 + 0.04 + 0.09 = 0.38 = 0.6164 \|u_2\| = \sqrt{0.25 + 0.04 + 0.09} = \sqrt{0.38} = 0.6164 ∥ u 2 ∥ = 0 . 2 5 + 0 . 0 4 + 0 . 0 9 = 0 . 3 8 = 0 . 6 1 6 4
∥ u 3 ∥ = 0.09 + 0.16 + 0.01 = 0.26 = 0.5099 \|u_3\| = \sqrt{0.09 + 0.16 + 0.01} = \sqrt{0.26} = 0.5099 ∥ u 3 ∥ = 0 . 0 9 + 0 . 1 6 + 0 . 0 1 = 0 . 2 6 = 0 . 5 0 9 9
d 12 d_{12} d 1 2 u 1 ⋅ u 2 = 0.1 × 0.5 + 0.3 × 0.2 + 0.5 × 0.3 = 0.05 + 0.06 + 0.15 = 0.26 u_1 \cdot u_2 = 0.1 \times 0.5 + 0.3 \times 0.2 + 0.5 \times 0.3 = 0.05 + 0.06 + 0.15 = 0.26 u 1 ⋅ u 2 = 0 . 1 × 0 . 5 + 0 . 3 × 0 . 2 + 0 . 5 × 0 . 3 = 0 . 0 5 + 0 . 0 6 + 0 . 1 5 = 0 . 2 6
d 12 = 1 − 0.26 0.5916 × 0.6164 = 1 − 0.26 0.3647 = 1 − 0.7128 = 0.2872 d_{12} = 1 - \frac{0.26}{0.5916 \times 0.6164} = 1 - \frac{0.26}{0.3647} = 1 - 0.7128 = \mathbf{0.2872} d 1 2 = 1 − 0 . 5 9 1 6 × 0 . 6 1 6 4 0 . 2 6 = 1 − 0 . 3 6 4 7 0 . 2 6 = 1 − 0 . 7 1 2 8 = 0 . 2 8 7 2
d 13 d_{13} d 1 3 u 1 ⋅ u 3 = 0.1 × 0.3 + 0.3 × 0.4 + 0.5 × 0.1 = 0.03 + 0.12 + 0.05 = 0.20 u_1 \cdot u_3 = 0.1 \times 0.3 + 0.3 \times 0.4 + 0.5 \times 0.1 = 0.03 + 0.12 + 0.05 = 0.20 u 1 ⋅ u 3 = 0 . 1 × 0 . 3 + 0 . 3 × 0 . 4 + 0 . 5 × 0 . 1 = 0 . 0 3 + 0 . 1 2 + 0 . 0 5 = 0 . 2 0
d 13 = 1 − 0.20 0.5916 × 0.5099 = 1 − 0.20 0.3017 = 1 − 0.6629 = 0.3371 d_{13} = 1 - \frac{0.20}{0.5916 \times 0.5099} = 1 - \frac{0.20}{0.3017} = 1 - 0.6629 = \mathbf{0.3371} d 1 3 = 1 − 0 . 5 9 1 6 × 0 . 5 0 9 9 0 . 2 0 = 1 − 0 . 3 0 1 7 0 . 2 0 = 1 − 0 . 6 6 2 9 = 0 . 3 3 7 1
d 23 d_{23} d 2 3 u 2 ⋅ u 3 = 0.5 × 0.3 + 0.2 × 0.4 + 0.3 × 0.1 = 0.15 + 0.08 + 0.03 = 0.26 u_2 \cdot u_3 = 0.5 \times 0.3 + 0.2 \times 0.4 + 0.3 \times 0.1 = 0.15 + 0.08 + 0.03 = 0.26 u 2 ⋅ u 3 = 0 . 5 × 0 . 3 + 0 . 2 × 0 . 4 + 0 . 3 × 0 . 1 = 0 . 1 5 + 0 . 0 8 + 0 . 0 3 = 0 . 2 6
d 23 = 1 − 0.26 0.6164 × 0.5099 = 1 − 0.26 0.3143 = 1 − 0.8273 = 0.1727 d_{23} = 1 - \frac{0.26}{0.6164 \times 0.5099} = 1 - \frac{0.26}{0.3143} = 1 - 0.8273 = \mathbf{0.1727} d 2 3 = 1 − 0 . 6 1 6 4 × 0 . 5 0 9 9 0 . 2 6 = 1 − 0 . 3 1 4 3 0 . 2 6 = 1 − 0 . 8 2 7 3 = 0 . 1 7 2 7
거리 행렬 요약
u 1 u_1 u 1 u 2 u_2 u 2 u 3 u_3 u 3 u 1 u_1 u 1 0 0.2872 0.3371 u 2 u_2 u 2 0.2872 0 0.1727 u 3 u_3 u 3 0.3371 0.1727 0
u 2 u_2 u 2 u 3 u_3 u 3 가장 가까움
단계 10: 국소 밀도 ρ i \rho_i ρ i
ρ i = ∑ j e − d i j / d n \rho_i = \sum_{j} e^{-d_{ij} / d_n} ρ i = ∑ j e − d i j / d n
정규화 인자를 d n = 0.3 d_n = 0.3 d n = 0 . 3
ρ 1 \rho_1 ρ 1 ρ 1 = e 0 + e − 0.2872 / 0.3 + e − 0.3371 / 0.3 = 1 + e − 0.957 + e − 1.124 \rho_1 = e^{0} + e^{-0.2872/0.3} + e^{-0.3371/0.3} = 1 + e^{-0.957} + e^{-1.124} ρ 1 = e 0 + e − 0 . 2 8 7 2 / 0 . 3 + e − 0 . 3 3 7 1 / 0 . 3 = 1 + e − 0 . 9 5 7 + e − 1 . 1 2 4
= 1 + 0.384 + 0.325 = 1.709 = 1 + 0.384 + 0.325 = \mathbf{1.709} = 1 + 0 . 3 8 4 + 0 . 3 2 5 = 1 . 7 0 9
ρ 2 \rho_2 ρ 2 ρ 2 = e − 0.2872 / 0.3 + e 0 + e − 0.1727 / 0.3 = 0.384 + 1 + e − 0.576 \rho_2 = e^{-0.2872/0.3} + e^{0} + e^{-0.1727/0.3} = 0.384 + 1 + e^{-0.576} ρ 2 = e − 0 . 2 8 7 2 / 0 . 3 + e 0 + e − 0 . 1 7 2 7 / 0 . 3 = 0 . 3 8 4 + 1 + e − 0 . 5 7 6
= 0.384 + 1 + 0.562 = 1.946 = 0.384 + 1 + 0.562 = \mathbf{1.946} = 0 . 3 8 4 + 1 + 0 . 5 6 2 = 1 . 9 4 6
ρ 3 \rho_3 ρ 3 ρ 3 = e − 0.3371 / 0.3 + e − 0.1727 / 0.3 + e 0 = 0.325 + 0.562 + 1 \rho_3 = e^{-0.3371/0.3} + e^{-0.1727/0.3} + e^{0} = 0.325 + 0.562 + 1 ρ 3 = e − 0 . 3 3 7 1 / 0 . 3 + e − 0 . 1 7 2 7 / 0 . 3 + e 0 = 0 . 3 2 5 + 0 . 5 6 2 + 1
= 1.887 = \mathbf{1.887} = 1 . 8 8 7
밀도 순위
ρ 2 ( 1.946 ) > ρ 3 ( 1.887 ) > ρ 1 ( 1.709 ) \rho_2\ (1.946) > \rho_3\ (1.887) > \rho_1\ (1.709) ρ 2 ( 1 . 9 4 6 ) > ρ 3 ( 1 . 8 8 7 ) > ρ 1 ( 1 . 7 0 9 )
u 2 u_2 u 2
단계 11: 클러스터 중심 선택
컷오프 거리를 d c = 0.25 d_c = 0.25 d c = 0 . 2 5
밀도가 높은 순서대로 처리합니다:
① u 2 u_2 u 2 ρ = 1.946 \rho = 1.946 ρ = 1 . 9 4 6
아직 선택된 중심이 없으므로 → u 2 u_2 u 2
② u 3 u_3 u 3 ρ = 1.887 \rho = 1.887 ρ = 1 . 8 8 7
이미 선택된 중심 u 2 u_2 u 2 d 23 = 0.1727 d_{23} = 0.1727 d 2 3 = 0 . 1 7 2 7
0.1727 < d c = 0.25 0.1727 < d_c = 0.25 0 . 1 7 2 7 < d c = 0 . 2 5 중심으로 지정하지 않음
③ u 1 u_1 u 1 ρ = 1.709 \rho = 1.709 ρ = 1 . 7 0 9
이미 선택된 중심 u 2 u_2 u 2 d 12 = 0.2872 d_{12} = 0.2872 d 1 2 = 0 . 2 8 7 2
0.2872 > d c = 0.25 0.2872 > d_c = 0.25 0 . 2 8 7 2 > d c = 0 . 2 5 u 1 u_1 u 1
결과
C c e n t e r s = { u 2 , u 1 } = { 토큰 3 , 토큰 1 } C_{centers} = \{u_2,\ u_1\} = \{\text{토큰 3},\ \text{토큰 1}\} C c e n t e r s = { u 2 , u 1 } = { 토큰 3 , 토큰 1 }
단계 12: 나머지 벡터 할당
중심이 아닌 벡터 u 3 u_3 u 3
벡터 중심 u 2 u_2 u 2 중심 u 1 u_1 u 1 할당 u 3 u_3 u 3 0.1727 0.3371 클러스터 A (u 2 u_2 u 2
클러스터링 결과
C e l e m e n t s = { 클러스터 A (중심: 토큰 3): { 토큰 3 , 토큰 4 } 클러스터 B (중심: 토큰 1): { 토큰 1 } C_{elements} = \begin{cases} \text{클러스터 A (중심: 토큰 3):} & \{\text{토큰 3},\ \text{토큰 4}\} \\ \text{클러스터 B (중심: 토큰 1):} & \{\text{토큰 1}\} \end{cases} C e l e m e n t s = { 클러스터 A ( 중심 : 토큰 3): 클러스터 B ( 중심 : 토큰 1): { 토큰 3 , 토큰 4 } { 토큰 1 }
보장되는 성질 확인
"각 벡터에서 해당 클러스터 중심까지의 거리가 d c d_c d c
벡터 소속 중심 거리 < d c = 0.25 < d_c = 0.25 < d c = 0 . 2 5 u 3 → u 2 u_3 \to u_2 u 3 → u 2 토큰 4 → 토큰 3 0.1727 ✅ u 1 → u_1 \to u 1 → 토큰 1 → 토큰 1 0 ✅ u 2 → u_2 \to u 2 → 토큰 3 → 토큰 3 0 ✅
단계 13: 비중요 토큰 복구
처음에 비중요(S u n i m p o r t a n t S_{unimportant} S u n i m p o r t a n t 충분히 가깝다면 오분류되었을 가능성이 큽니다. 정보 손실을 줄이기 위해 이런 토큰을 해당 클러스터에 다시 추가합니다.
복구 조건
계수 α \alpha α u i u_i u i s ∈ C c e n t e r s s \in C_{centers} s ∈ C c e n t e r s d i s d_{is} d i s
S a d d e d ( s ) = { i ∈ S u n i m p o r t a n t ∣ s = arg min s ′ ∈ C c e n t e r s d i s ′ and d i s < α ⋅ d c } S_{added}(s) = \{i \in S_{unimportant} \mid s = \arg\min_{s' \in C_{centers}} d_{is'} \text{ and } d_{is} < \alpha \cdot d_c\} S a d d e d ( s ) = { i ∈ S u n i m p o r t a n t ∣ s = arg min s ′ ∈ C c e n t e r s d i s ′ and d i s < α ⋅ d c }
C e l e m e n t s ( s ) ← C e l e m e n t s ( s ) ∪ S a d d e d ( s ) C_{elements}(s) \leftarrow C_{elements}(s) \cup S_{added}(s) C e l e m e n t s ( s ) ← C e l e m e n t s ( s ) ∪ S a d d e d ( s )
파라미터 설정
α = 0.8 , d c = 0.25 ⇒ 임계값 = α ⋅ d c = 0.8 × 0.25 = 0.20 \alpha = 0.8, \quad d_c = 0.25 \quad \Rightarrow \quad \text{임계값} = \alpha \cdot d_c = 0.8 \times 0.25 = 0.20 α = 0 . 8 , d c = 0 . 2 5 ⇒ 임계값 = α ⋅ d c = 0 . 8 × 0 . 2 5 = 0 . 2 0
비중요 토큰 확인
S u n i m p o r t a n t = { 토큰 2 } S_{unimportant} = \{\text{토큰 2}\} S u n i m p o r t a n t = { 토큰 2 }
u 토큰2 = [ 0.2 , 0.1 , 0.4 ] , ∥ u 토큰2 ∥ = 0.04 + 0.01 + 0.16 = 0.21 = 0.4583 u_{\text{토큰2}} = [0.2,\ 0.1,\ 0.4], \quad \|u_{\text{토큰2}}\| = \sqrt{0.04 + 0.01 + 0.16} = \sqrt{0.21} = 0.4583 u 토큰 2 = [ 0 . 2 , 0 . 1 , 0 . 4 ] , ∥ u 토큰 2 ∥ = 0 . 0 4 + 0 . 0 1 + 0 . 1 6 = 0 . 2 1 = 0 . 4 5 8 3
토큰 2 → 각 클러스터 중심까지 거리 계산
중심 u 2 u_2 u 2
u 토큰2 ⋅ u 2 = 0.2 × 0.5 + 0.1 × 0.2 + 0.4 × 0.3 = 0.10 + 0.02 + 0.12 = 0.24 u_{\text{토큰2}} \cdot u_2 = 0.2 \times 0.5 + 0.1 \times 0.2 + 0.4 \times 0.3 = 0.10 + 0.02 + 0.12 = 0.24 u 토큰 2 ⋅ u 2 = 0 . 2 × 0 . 5 + 0 . 1 × 0 . 2 + 0 . 4 × 0 . 3 = 0 . 1 0 + 0 . 0 2 + 0 . 1 2 = 0 . 2 4
d = 1 − 0.24 0.4583 × 0.6164 = 1 − 0.24 0.2825 = 1 − 0.8496 = 0.1504 d = 1 - \frac{0.24}{0.4583 \times 0.6164} = 1 - \frac{0.24}{0.2825} = 1 - 0.8496 = \mathbf{0.1504} d = 1 − 0 . 4 5 8 3 × 0 . 6 1 6 4 0 . 2 4 = 1 − 0 . 2 8 2 5 0 . 2 4 = 1 − 0 . 8 4 9 6 = 0 . 1 5 0 4
중심 u 1 u_1 u 1
u 토큰2 ⋅ u 1 = 0.2 × 0.1 + 0.1 × 0.3 + 0.4 × 0.5 = 0.02 + 0.03 + 0.20 = 0.25 u_{\text{토큰2}} \cdot u_1 = 0.2 \times 0.1 + 0.1 \times 0.3 + 0.4 \times 0.5 = 0.02 + 0.03 + 0.20 = 0.25 u 토큰 2 ⋅ u 1 = 0 . 2 × 0 . 1 + 0 . 1 × 0 . 3 + 0 . 4 × 0 . 5 = 0 . 0 2 + 0 . 0 3 + 0 . 2 0 = 0 . 2 5
d = 1 − 0.25 0.4583 × 0.5916 = 1 − 0.25 0.2712 = 1 − 0.9218 = 0.0782 d = 1 - \frac{0.25}{0.4583 \times 0.5916} = 1 - \frac{0.25}{0.2712} = 1 - 0.9218 = \mathbf{0.0782} d = 1 − 0 . 4 5 8 3 × 0 . 5 9 1 6 0 . 2 5 = 1 − 0 . 2 7 1 2 0 . 2 5 = 1 − 0 . 9 2 1 8 = 0 . 0 7 8 2
판정
비중요 토큰 가장 가까운 중심 거리 < α ⋅ d c = 0.20 < \alpha \cdot d_c = 0.20 < α ⋅ d c = 0 . 2 0 결과 토큰 2 토큰 1 (중심 u 1 u_1 u 1 0.0782 ✅ (0.0782 < 0.20 0.0782 < 0.20 0 . 0 7 8 2 < 0 . 2 0 복구!
토큰 2는 중심 u 1 u_1 u 1 클러스터 B에 복구 됩니다.
S a d d e d ( u 1 ) = { 토큰 2 } S_{added}(u_1) = \{\text{토큰 2}\} S a d d e d ( u 1 ) = { 토큰 2 }
C e l e m e n t s ( u 1 ) ← { 토큰 1 } ∪ { 토큰 2 } = { 토큰 1 , 토큰 2 } C_{elements}(u_1) \leftarrow \{\text{토큰 1}\} \cup \{\text{토큰 2}\} = \{\text{토큰 1},\ \text{토큰 2}\} C e l e m e n t s ( u 1 ) ← { 토큰 1 } ∪ { 토큰 2 } = { 토큰 1 , 토큰 2 }
복구 후 최종 클러스터
C e l e m e n t s = { 클러스터 A (중심: 토큰 3): { 토큰 3 , 토큰 4 } 클러스터 B (중심: 토큰 1): { 토큰 1 , 토큰 2 } ← 토큰 2 복구됨! C_{elements} = \begin{cases} \text{클러스터 A (중심: 토큰 3):} & \{\text{토큰 3},\ \text{토큰 4}\} \\ \text{클러스터 B (중심: 토큰 1):} & \{\text{토큰 1},\ \text{토큰 2}\} \leftarrow \text{토큰 2 복구됨!} \end{cases} C e l e m e n t s = { 클러스터 A ( 중심 : 토큰 3): 클러스터 B ( 중심 : 토큰 1): { 토큰 3 , 토큰 4 } { 토큰 1 , 토큰 2 } ← 토큰 2 복구됨 !
직관 : 토큰 2는 EUTI 중요도 점수에서는 가장 낮았지만, 실제 키 벡터의 방향이 토큰 1과 매우 유사했습니다(코사인 거리 0.0782). 이는 토큰 2가 토큰 1과 비슷한 시각 정보를 담고 있어서, 단순히 제거하면 정보 손실이 발생할 수 있음을 의미합니다. α \alpha α
단계 14: 병합 — 클러스터별 은닉 상태 평균
각 클러스터에 속한 토큰들의 은닉 상태 h i h_i h i
클러스터 A: 토큰 3, 토큰 4
h 3 = [ 0.5 , 0.2 , 0.3 , 0.1 , 0.6 , 0.4 ] h_3 = [0.5,\ 0.2,\ 0.3,\ 0.1,\ 0.6,\ 0.4] h 3 = [ 0 . 5 , 0 . 2 , 0 . 3 , 0 . 1 , 0 . 6 , 0 . 4 ] h 4 = [ 0.3 , 0.4 , 0.1 , 0.5 , 0.2 , 0.3 ] h_4 = [0.3,\ 0.4,\ 0.1,\ 0.5,\ 0.2,\ 0.3] h 4 = [ 0 . 3 , 0 . 4 , 0 . 1 , 0 . 5 , 0 . 2 , 0 . 3 ] h A ′ = 1 2 ( h 3 + h 4 ) = 1 2 [ 0.8 , 0.6 , 0.4 , 0.6 , 0.8 , 0.7 ] = [ 0.40 , 0.30 , 0.20 , 0.30 , 0.40 , 0.35 ] h'_A = \frac{1}{2}(h_3 + h_4) = \frac{1}{2}[0.8,\ 0.6,\ 0.4,\ 0.6,\ 0.8,\ 0.7] = [0.40, 0.30, 0.20, 0.30, 0.40, 0.35] h A ′ = 2 1 ( h 3 + h 4 ) = 2 1 [ 0 . 8 , 0 . 6 , 0 . 4 , 0 . 6 , 0 . 8 , 0 . 7 ] = [ 0 . 4 0 , 0 . 3 0 , 0 . 2 0 , 0 . 3 0 , 0 . 4 0 , 0 . 3 5 ]
클러스터 B: 토큰 1, 토큰 2
h 1 = [ 0.1 , 0.3 , 0.5 , 0.2 , 0.4 , 0.6 ] h_1 = [0.1,\ 0.3,\ 0.5,\ 0.2,\ 0.4,\ 0.6] h 1 = [ 0 . 1 , 0 . 3 , 0 . 5 , 0 . 2 , 0 . 4 , 0 . 6 ] h 2 = [ 0.2 , 0.1 , 0.4 , 0.3 , 0.5 , 0.1 ] h_2 = [0.2,\ 0.1,\ 0.4,\ 0.3,\ 0.5,\ 0.1] h 2 = [ 0 . 2 , 0 . 1 , 0 . 4 , 0 . 3 , 0 . 5 , 0 . 1 ] h B ′ = 1 2 ( h 1 + h 2 ) = 1 2 [ 0.3 , 0.4 , 0.9 , 0.5 , 0.9 , 0.7 ] = [ 0.15 , 0.20 , 0.45 , 0.25 , 0.45 , 0.35 ] h'_B = \frac{1}{2}(h_1 + h_2) = \frac{1}{2}[0.3,\ 0.4,\ 0.9,\ 0.5,\ 0.9,\ 0.7] = [0.15,\ 0.20,\ 0.45,\ 0.25,\ 0.45,\ 0.35] h B ′ = 2 1 ( h 1 + h 2 ) = 2 1 [ 0 . 3 , 0 . 4 , 0 . 9 , 0 . 5 , 0 . 9 , 0 . 7 ] = [ 0 . 1 5 , 0 . 2 0 , 0 . 4 5 , 0 . 2 5 , 0 . 4 5 , 0 . 3 5 ]
최종 결과
H ′ = { h A ′ , h B ′ } = [ 0.40 0.30 0.20 0.30 0.40 0.35 0.15 0.20 0.45 0.25 0.45 0.35 ] H' = \{h'_A,\ h'_B\} = \begin{bmatrix} 0.40 & 0.30 & 0.20 & 0.30 & 0.40 & 0.35 \\ 0.15 & 0.20 & 0.45 & 0.25 & 0.45 & 0.35 \end{bmatrix} H ′ = { h A ′ , h B ′ } = [ 0 . 4 0 0 . 1 5 0 . 3 0 0 . 2 0 0 . 2 0 0 . 4 5 0 . 3 0 0 . 2 5 0 . 4 0 0 . 4 5 0 . 3 5 0 . 3 5 ]
단계 15: 위치 ID (Position IDs) 할당
병합된 H ′ H' H ′ 위치 ID 를 부여해야 합니다. Rotary embeddings를 사용하는 모델에서는 이 위치 ID가 이미지의 공간 구조나 비디오의 시간 순서를 결정하기 때문에 매우 중요합니다.
원래 토큰의 위치 ID
이미지를 2×2 그리드로 나눴다고 하면, 원래 4개 토큰의 위치 ID는 다음과 같습니다:
토큰 위치 ID 이미지 내 위치 토큰 1 0 좌상단 토큰 2 1 우상단 토큰 3 2 좌하단 토큰 4 3 우하단
클러스터 중심의 위치 ID를 그대로 사용
각 클러스터의 대표 벡터에는 해당 클러스터 중심 토큰의 위치 ID 를 할당합니다.
병합 벡터 클러스터 중심 중심의 위치 ID 할당되는 위치 ID h A ′ h'_A h A ′ 토큰 3 2 2 h B ′ h'_B h B ′ 토큰 1 0 0
비례 어텐션
토큰 병합 시 영향력이 줄어드는 문제를 보상하기 위해, 각 병합 토큰의 클러스터 크기를 가중치로 어텐션 스코어에 반영함. 예를 들어 3개가 합쳐진 토큰은 어텐션을 3배 더 받도록 조정하여, 원래 여러 토큰을 대표하고 있음을 어텐션 메커니즘에 반영함. 텍스트 토큰은 병합되지 않으므로 가중치 1로 영향 없음.
토큰 감소를 위한 레이어 L 선택
레이어 L은 계산 효율을 위해 최대한 초기 레이어를 선택하되, 키 벡터들 간 최대 거리가 충분히 확보되는 가장 이른 레이어를 선택함. 초기 레이어에서는 키들이 너무 유사해 구별이 어려우므로, 특징적 차별성이 확보되는 시점을 찾아야 함.
공격: 초기 레이어에서 키가 유사하면 오히려 병합이 잘 되는 것 아닌가? 유사한 토큰끼리 합치는 게 목적이니까 더 효율적일 수 있음.
방어: 초기 레이어의 유사성은 토큰들이 실제로 같은 정보를 담고 있어서가 아니라, 아직 셀프 어텐션을 충분히 거치지 않아 키의 표현력이 부족하기 때문임. 이 상태에서 병합하면 실제로는 다른 정보를 가진 토큰들이 잘못 합쳐져 정보 손실이 발생함. 프루닝 역시 중요한 토큰과 불필요한 토큰을 구별할 수 없으므로 정확도가 떨어짐.
4. Experiments
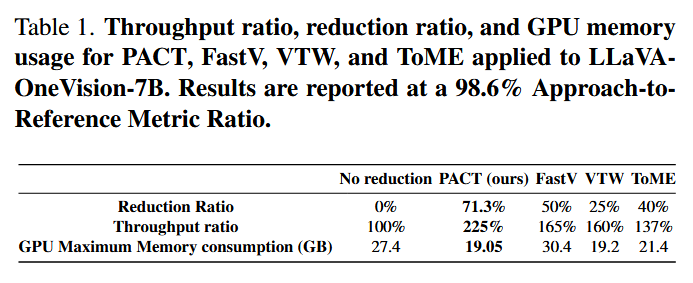
Table 1: LLaVA-OneVision-7B에서 동일 성능(98.6% Metric Ratio) 기준으로 각 방법의 감소율, 처리량, GPU 메모리를 비교함.
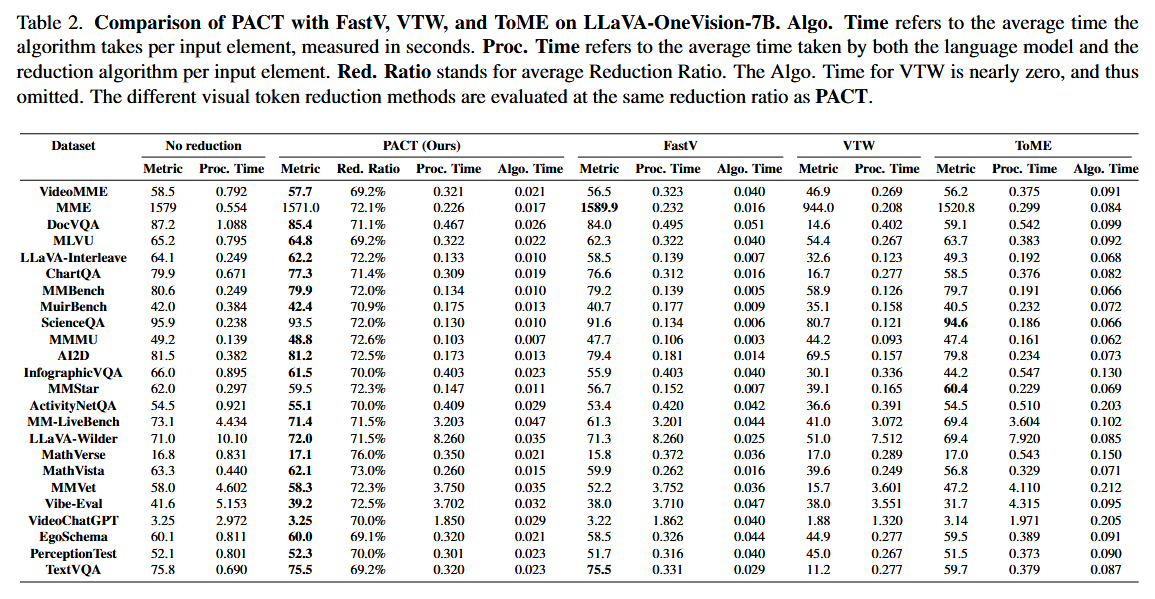
Table 2: LLaVA-OneVision-7B에서 PACT가 대부분의 테스트 데이터셋에서 FastV, VTW, ToME보다 우수한 성능을 보임.
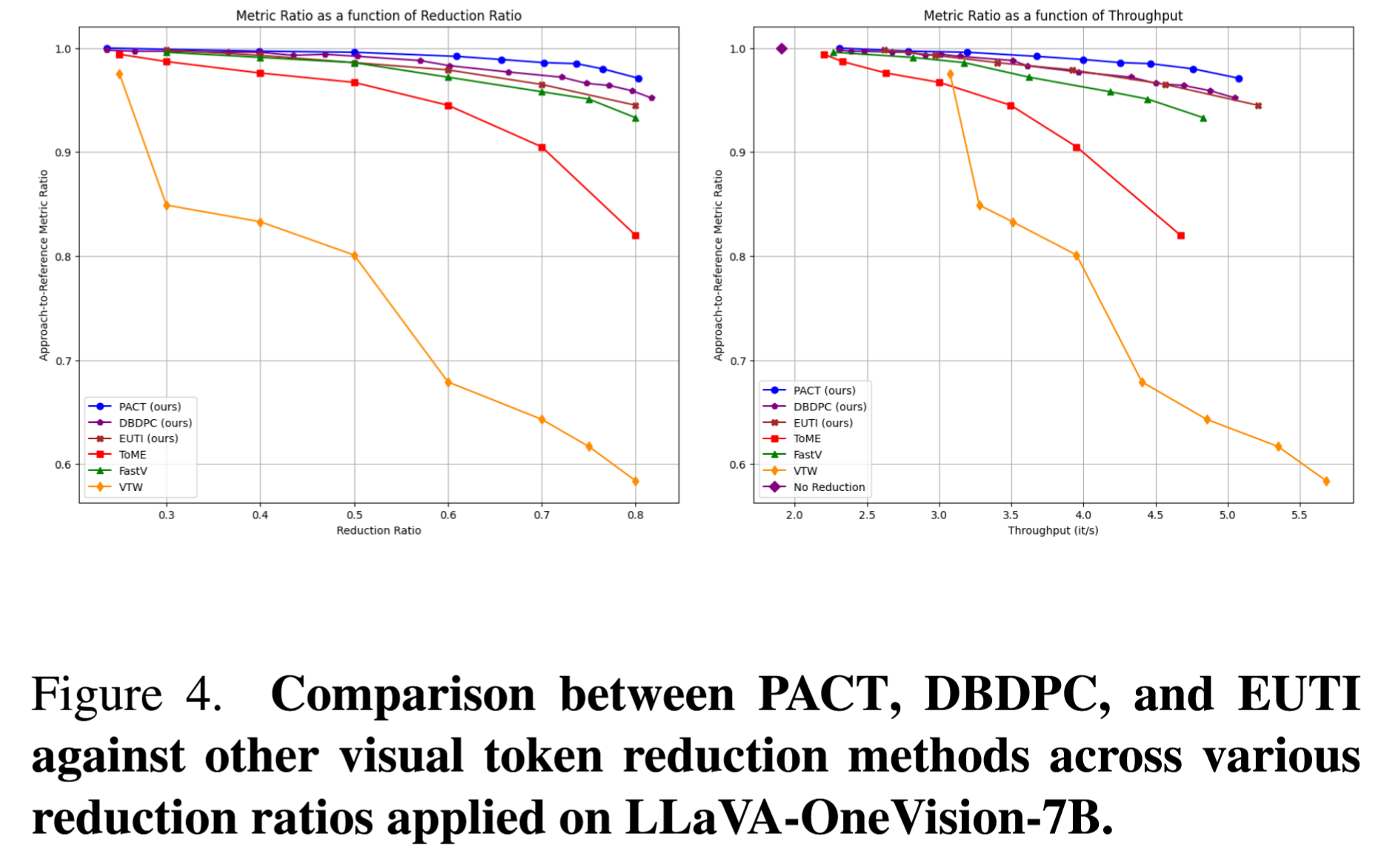
Figure 4: LLaVA-OneVision-7B에서 PACT, DBDPC, EUTI를 다른 방법들과 다양한 감소율에서 비교함.
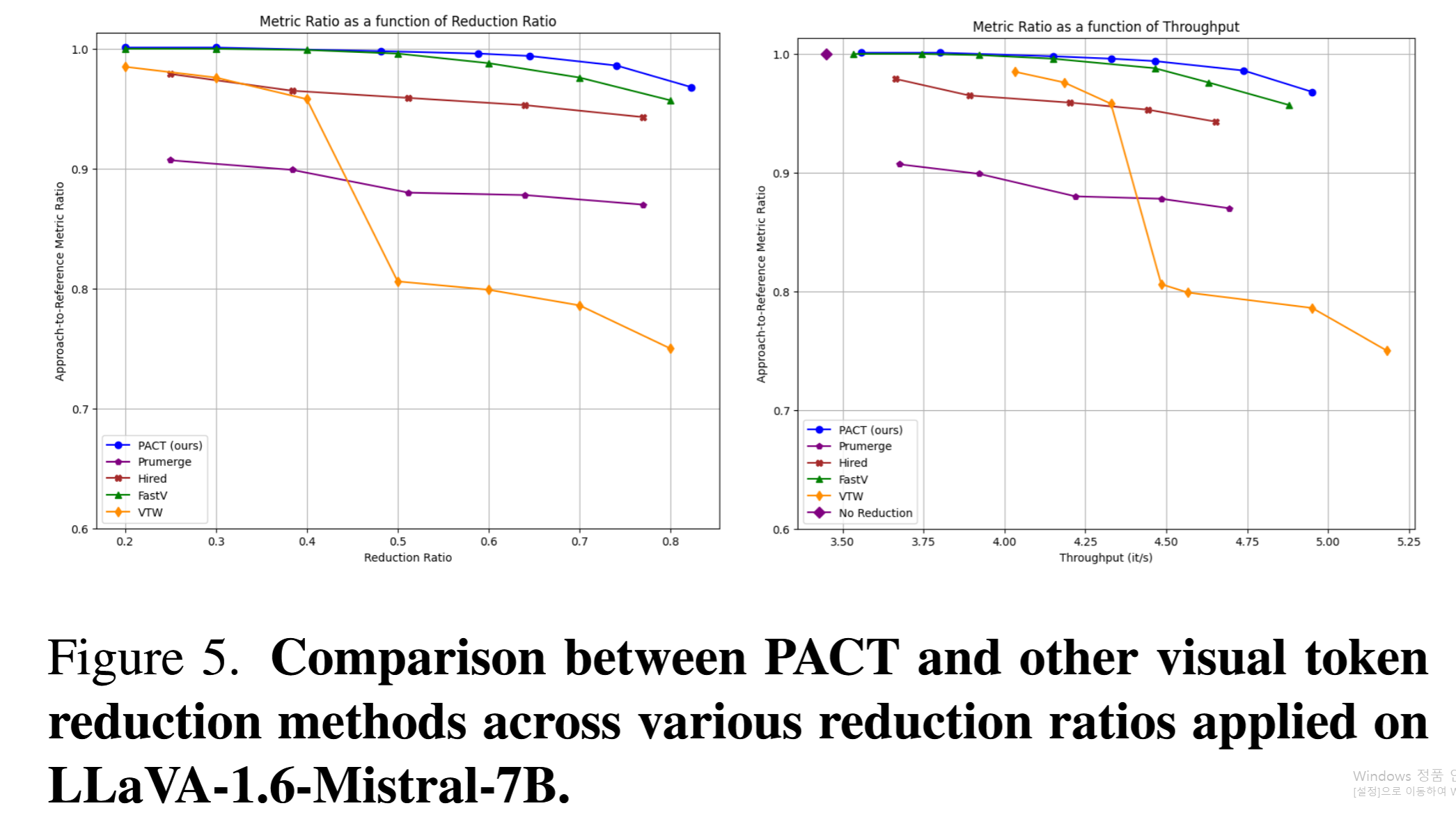
Figure 5: LLaVA-1.6-Mistral-7B에서의 비교. PACT가 다른 방법들을 일관되게 능가함.
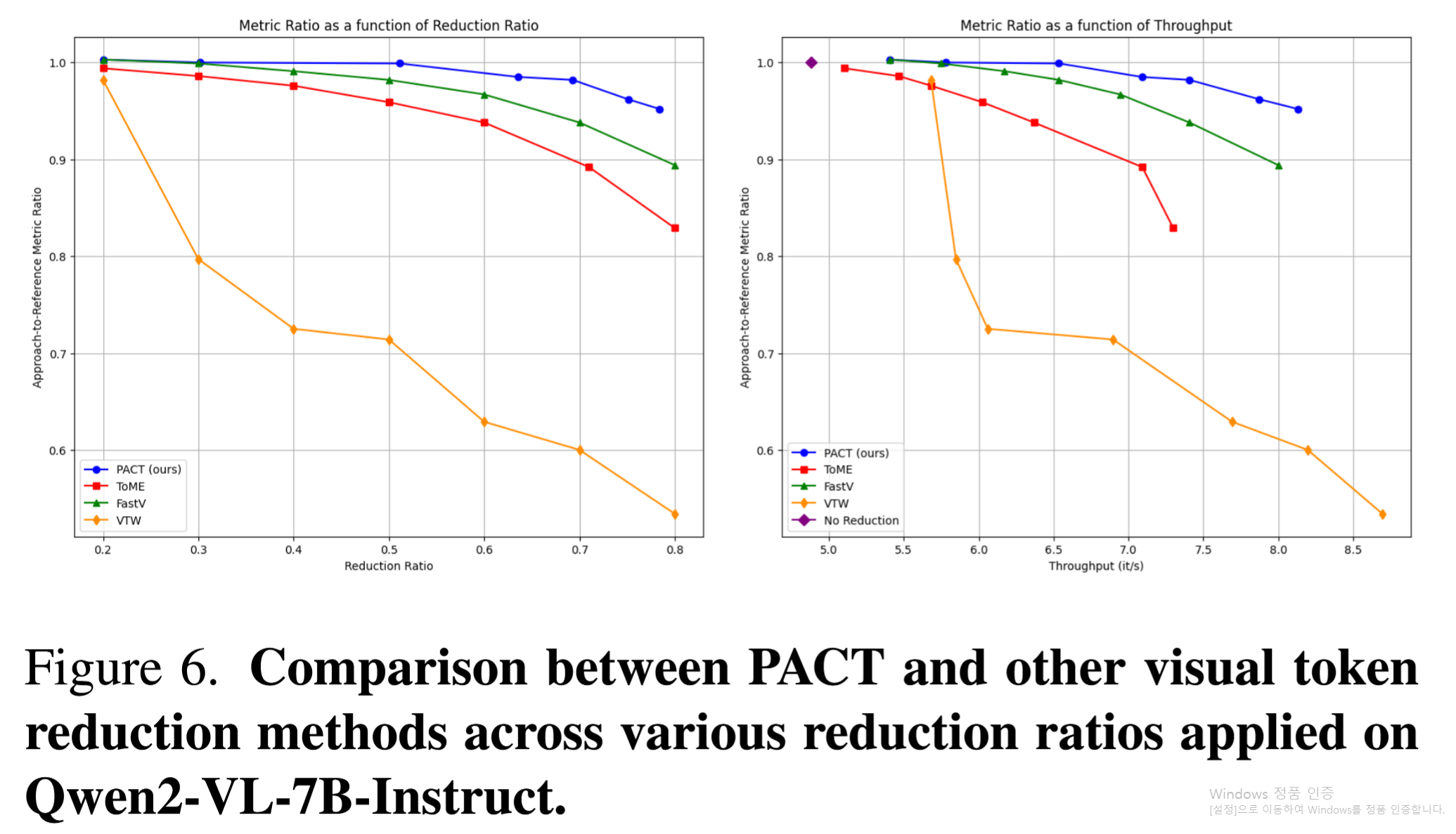
Figure 6: Qwen2-VL-7B-Instruct에서의 비교. PACT가 일관되게 우수함.
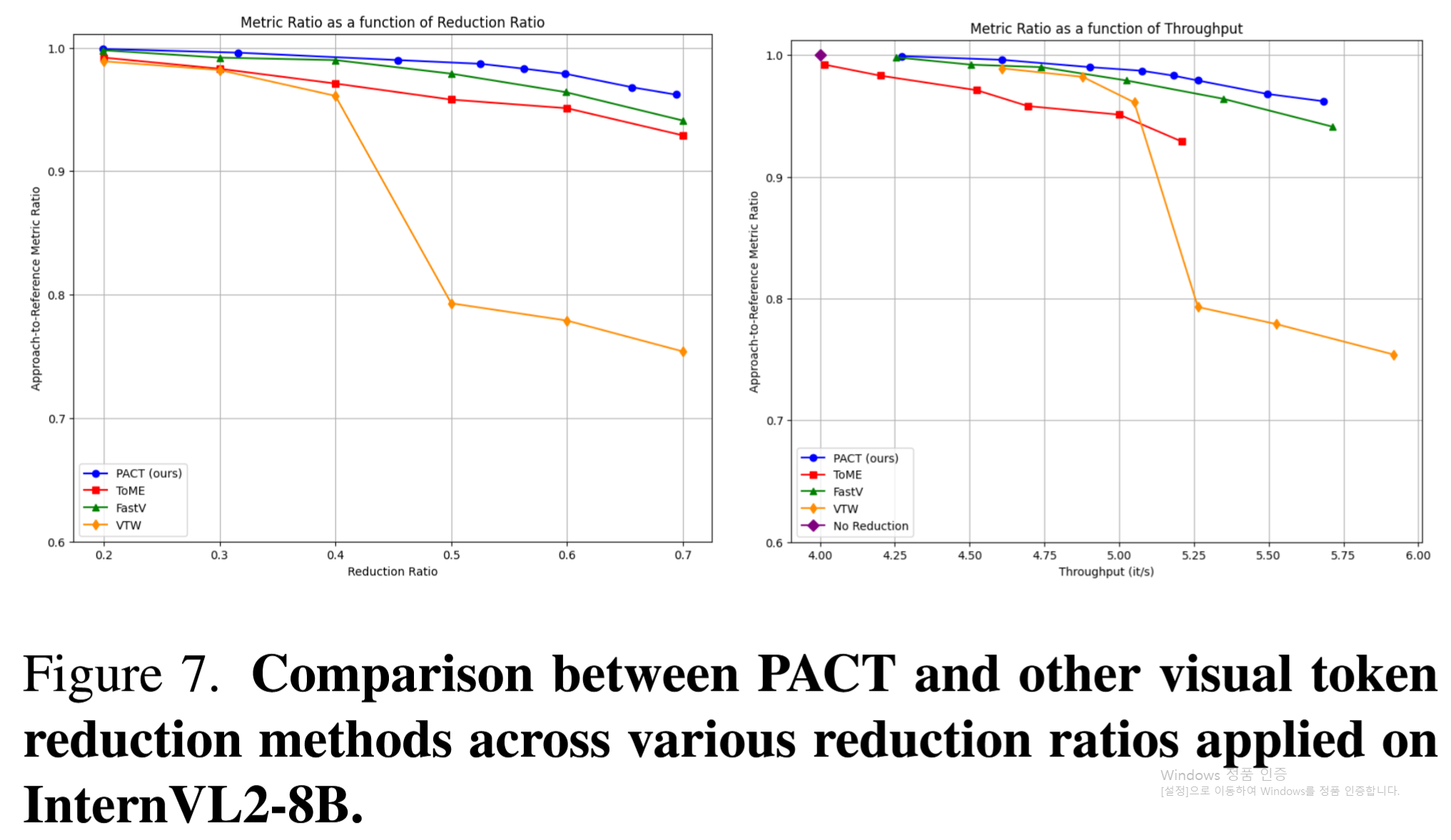
Figure 7: InternVL2-8B에서의 비교. PACT가 일관되게 우수함.
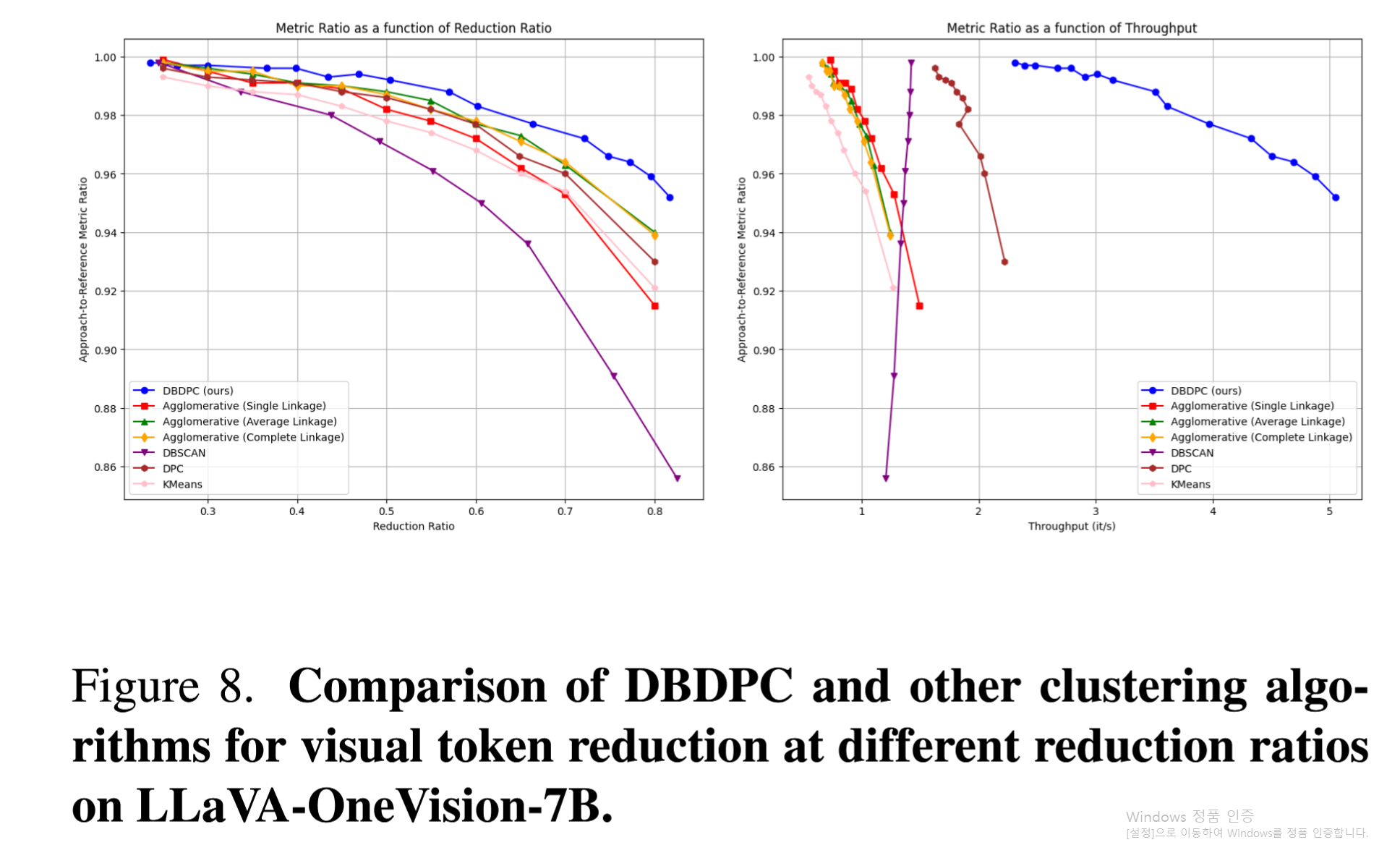
Figure 8: DBDPC를 응집형 클러스터링, k-means, DPC, DBSCAN과 비교함.
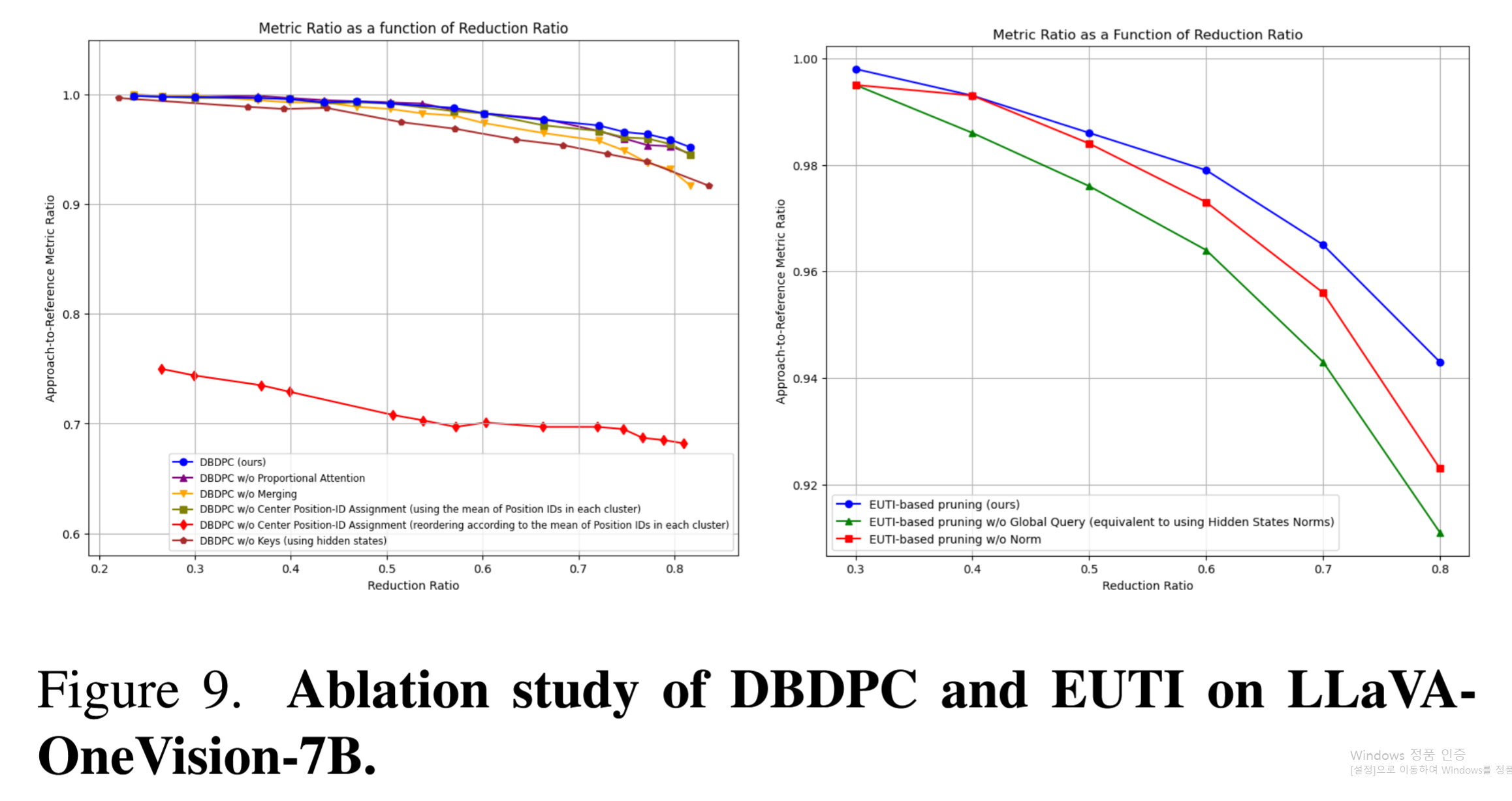
Figure 9: DBDPC와 EUTI의 절제 실험 결과.
토큰 병합 vs 센터 선택: 감소율 50% 초과 시 병합이 더 우수함
비례 어텐션: 높은 감소율에서 효과적
위치 ID 할당: 클러스터 센터의 위치 ID를 사용하는 것이 가장 중요함 (이미지 구조, 비디오 시간 순서 반영)
클러스터링 입력: 키 벡터가 히든 스테이트보다 코사인 유사도 기반 거리 계산에 적합함
EUTI 절제: 글로벌 쿼리 점수와 히든 스테이트 노름을 결합하는 것이 각각 단독보다 우수하며, 두 지표가 상호 보완적임을 확인함
Q: 토큰에 위치 ID라는 게 있나? 그냥 순서 정하는 용도 아닌가?
Q: 그래서 병합 후 위치 ID 할당이 왜 중요한가?
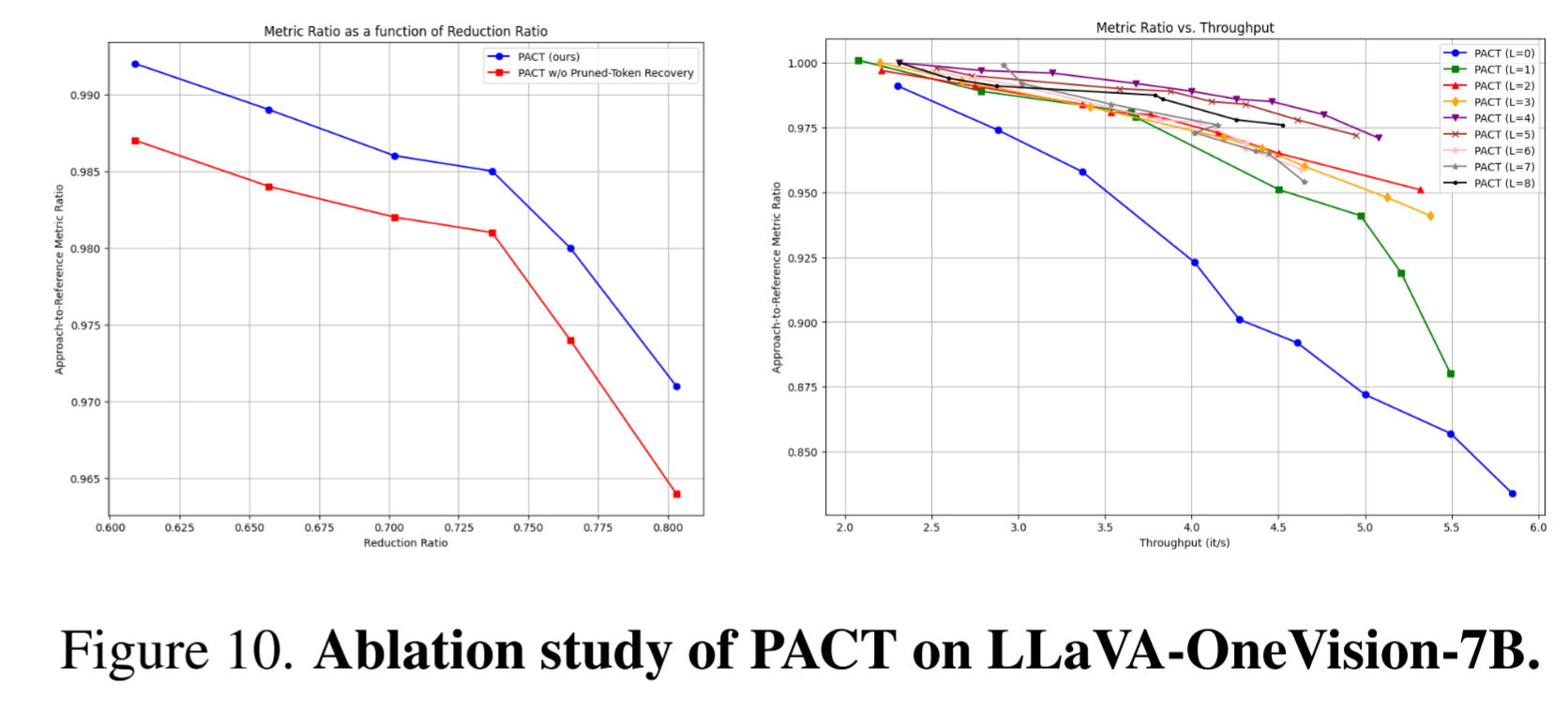
Figure 10: PACT의 절제 실험 결과.
프루닝된 토큰 복구(α > 0): 클러스터 센터에 가까운 토큰을 재편입하면 다양한 감소율에서 일관되게 성능이 향상됨. 해당 토큰들이 EUTI에 의해 잘못 분류되었을 가능성을 뒷받침함.
감소 레이어 선택: 레이어 선택이 성능에 영향을 미치며, 논문의 레이어 식별 방식의 효과를 입증함.