Focus, Don’t Prune: Identifying Instruction-Relevant Regions for Information-Rich Image Understanding
논문 리뷰
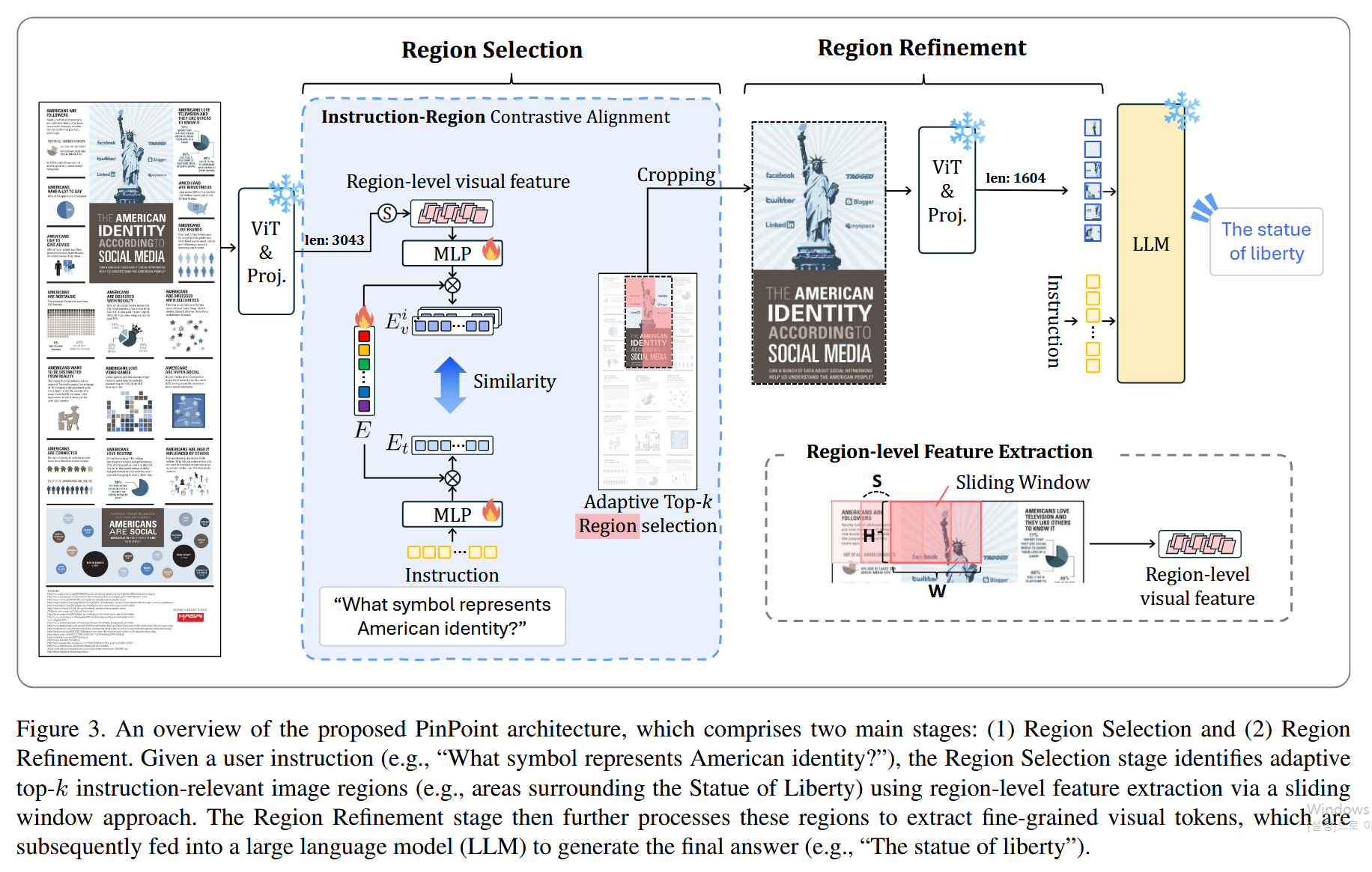
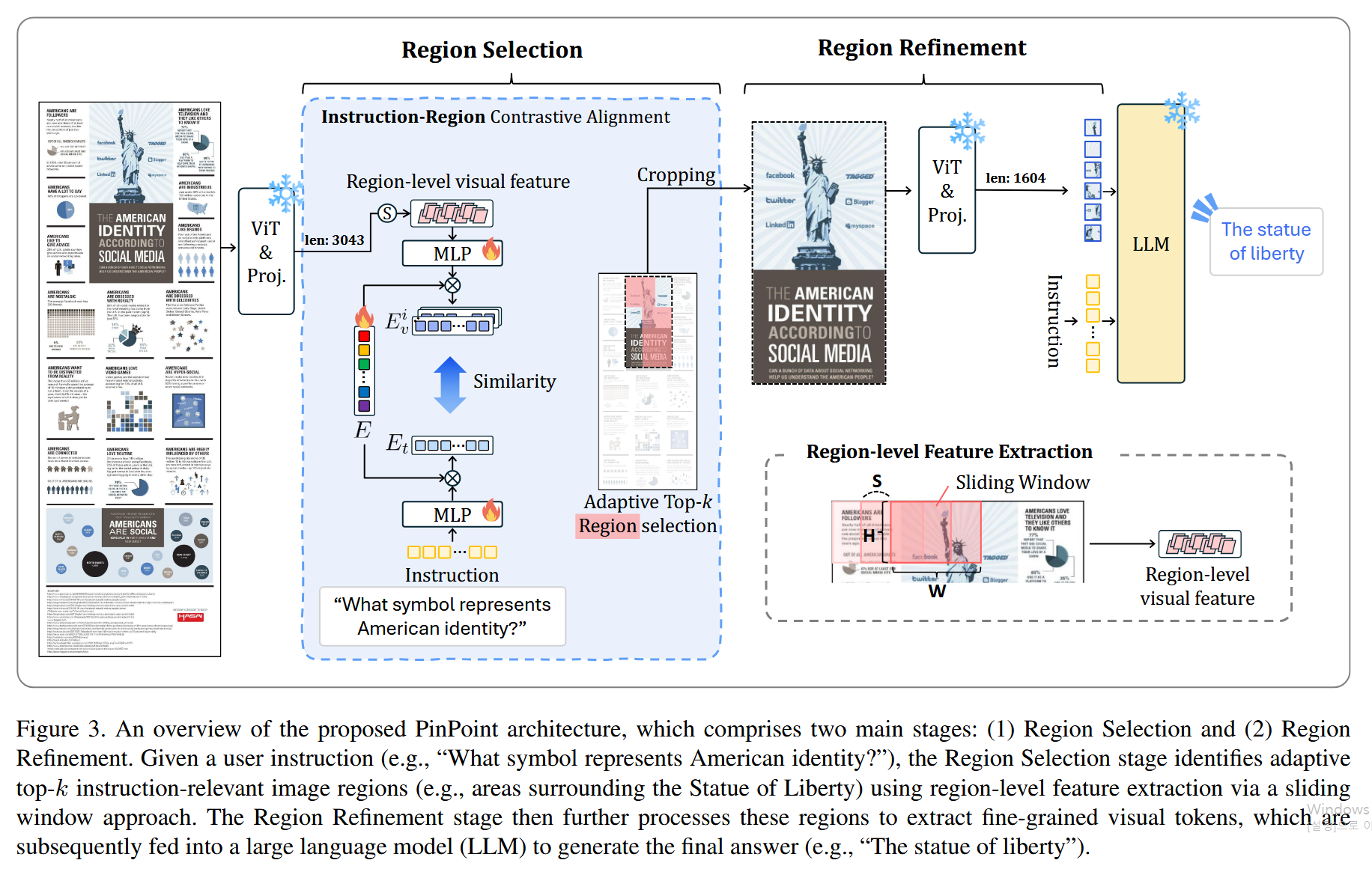
Focus, Don’t Prune: Identifying Instruction-Relevant Regions for Information-Rich Image Understanding
Abstract
PinPoint는 두 단계로 구성됨.
1단계: Region Selection
먼저 입력 이미지를 ViT와 프로젝션 레이어에 통과시켜 비전 토큰을 얻음. 이 토큰들을 2D 공간 그리드로 재배열한 뒤, 슬라이딩 윈도우(W×H, stride S)를 적용해서 여러 개의 영역별 특징()을 추출함.
그다음 Instruction-Region Alignment이 수행됨. 학습 가능한 가이던스 쿼리()가 각 영역의 비전 특징과 텍스트 특징에 각각 scaled dot-product attention을 적용해서 (비전 인식 표현)와 (텍스트 인식 표현)를 만들어냄. 가이던스 쿼리는 두 모달리티를 공통 특징 공간으로 연결하는 매개체 역할을 함. 실제 유사도 비교는 이렇게 생성된 와 사이의 코사인 유사도로 수행되며, 유사도가 높은 순서대로 영역을 랭킹함. 그 후 선택된 영역들의 합산 면적이 전체 이미지의 사전 정의된 비율()을 초과할 때까지 상위 영역을 적응적으로 선택함.
2단계: Region Refinement
1단계에서 선택된 영역들만 원본 이미지에서 크롭함. 크롭된 영역을 ViT와 프로젝션 레이어로 다시 인코딩함. 이렇게 하는 이유는 1단계에서 얻은 비전 토큰이 ViT의 글로벌 셀프 어텐션 때문에 무관한 영역의 정보에 오염되어 있기 때문임. 재인코딩을 통해 선택된 영역만의 깨끗하고 세밀한 비전 토큰을 얻을 수 있음. 이 정제된 토큰들은 원본 전체 토큰보다 훨씬 적은 수이면서도 답변에 필요한 정보가 더 밀집되어 있음. 최종적으로 이 토큰들이 텍스트 지시어와 함께 LLM에 입력되어 답변을 생성함.
1. Introduction
배경 문제
인포그래픽이나 문서 이미지처럼 정보가 밀집된 이미지를 이해하려면 고해상도 처리가 필요하고, 이는 대량의 비전 토큰을 생성해서 컴퓨팅 비용이 크게 증가함.
기존 해결책과 한계
기존 토큰 프루닝 방법들은 LLM 디코딩 레이어의 어텐션 가중치로 토큰 중요도를 추정하고 덜 중요한 토큰을 제거하는 방식인데, 세 가지 문제가 있음.
1. 불완전한 어텐션 맵 문제
LLM 디코딩 레이어의 어텐션 가중치 자체가 신뢰할 수 없는 경우가 있어서, 이를 기반으로 프루닝하면 중요한 토큰이 제거되고 환각이 발생할 수 있음.
→ PinPoint: LLM 디코딩 레이어의 어텐션 맵을 사용하지 않음. 대신 ViT + Projection 출력인 비전 토큰을 영역 수준으로 묶고, 학습된 가이던스 쿼리를 통해 텍스트와의 유사도를 직접 계산함.
🗡️ 공격: 결국 Region Selection에서 사용하는 비전 토큰도 ViT를 통과한 결과이므로, ViT 내부의 셀프 어텐션 과정을 모두 거친 것임. LLM 어텐션 맵은 회피했지만, ViT 어텐션을 통해 이미 오염된 정보를 기반으로 유사도를 계산하는 것이므로 신호의 신뢰성 문제가 완전히 해결된 것은 아님.
2. 의미론적 단편화 문제
이미지 속 텍스트 같은 비전 요소는 여러 토큰에 걸쳐 표현되는데, 개별 토큰 단위로 프루닝하면 이 요소들의 전체적인 문맥 의미가 깨질 수 있음.
→ PinPoint: 개별 토큰 단위가 아니라 슬라이딩 윈도우 단위로 영역을 선택함. 비전 요소가 여러 토큰에 걸쳐 있어도 윈도우 안에서 통째로 보존되므로 의미론적 단편화 문제를 해결함.
3. 문맥적 얽힘 문제
ViT의 글로벌 셀프 어텐션 때문에 정답 관련 영역의 비전 토큰이 무관한 정보와 뒤섞이게 됨.
→ PinPoint: Region Refinement에서 선택된 영역만 크롭해서 ViT에 다시 통과시킴. 무관한 영역의 토큰이 입력에 없으므로 셀프 어텐션에서 정보가 섞이지 않음.
🗡️ 공격: 크롭할 영역을 결정하는 Region Selection 자체가 전체 이미지를 ViT에 통과시킨 결과를 사용함. 즉 이미 문맥적 얽힘이 발생한 오염된 토큰을 기반으로 영역을 선택하는 것임. Region Refinement가 문맥적 얽힘을 해결하는 건 맞지만, 그 전 단계인 Region Selection이 오염된 정보로 판단하므로 영역 선택 자체의 정확성이 보장되지 않음. Table 4에서 Region Accuracy가 84~98%로 보고되지만, 오염되지 않은 토큰으로 선택했을 때와의 비교가 없어 이 수치가 충분히 높은 것인지 판단할 근거가 부족함.
기존 벤치마크의 한계
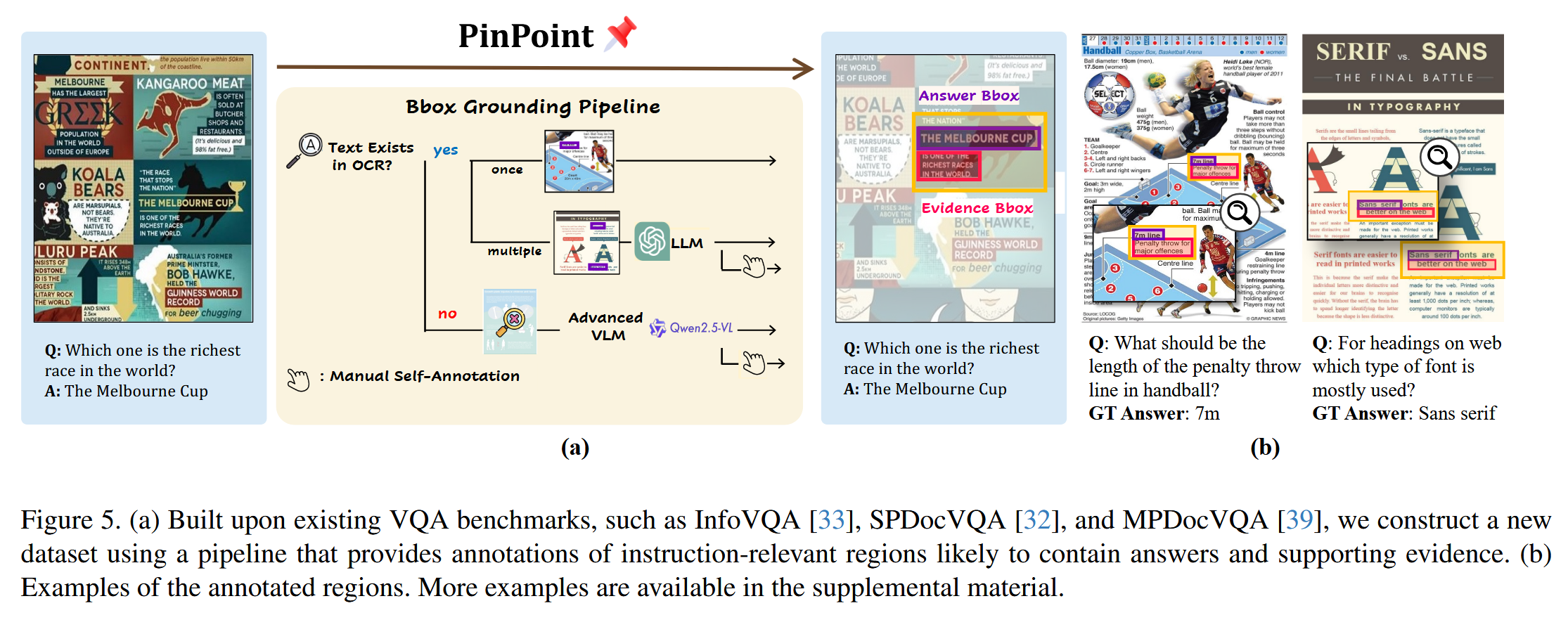
기존 VQA 벤치마크에는 질문-답변 쌍은 있지만, 이미지에서 어떤 영역을 봐야 답을 알 수 있는지에 대한 위치 정보는 없었음. Visual CoT [37] 같은 논문에서 정답 위치를 바운딩 박스로 어노테이션한 적은 있지만, 정답이 위치한 단일 바운딩 박스만 표시하는 수준이었음.
예를 들어 "가장 부유한 경주는 무엇인가?"라는 질문에 대해 "멜버른 컵"이라는 텍스트 위치 하나만 박스로 표시하는 방식임.
PinPoint의 새로운 어노테이션
PinPoint 팀은 기존 벤치마크 위에 질문에 답하기 위해 봐야 하는 이미지 영역의 좌표를 새로 만들어 추가함. 이 어노테이션이 있어야 Region Selection 모듈을 학습시킬 수 있음. 핵심적인 차이는 PinPoint가 정답 영역뿐 아니라 추론에 필요한 근거 영역까지 여러 바운딩 박스로 표시한다는 점임. 같은 예시에서 "멜버른 컵" 위치(answer bbox), "가장 부유한 경주"라는 문맥이 담긴 주변 영역(evidence bbox), 그리고 이 둘을 모두 포함하는 통합 영역(encompass bbox)까지 어노테이션함.
2. Related Work
생략
3. Method
3.1. Region-Level Feature Extraction
먼저 입력 이미지를 사전 학습된 ViT와 프로젝션 레이어에 통과시켜 비전 토큰 를 얻음.
는 전체 비전 토큰 수, 는 임베딩 차원임.
이 토큰들은 LLM에 입력되기 직전 단계의 표현을 사용함.
이 비전 토큰들을 2D 공간 그리드로 재배열한 뒤, 크기 , 스트라이드 인 슬라이딩 윈도우를 적용함.
번째 윈도우 내의 모든 토큰을 모아서 영역 수준 표현 를 만듦. 전체 그리드에 슬라이딩 윈도우를 적용하면 영역 컬렉션 을 얻음. 은 총 영역 수이며 입력 이미지에 따라 달라짐.
이와 동시에 입력 텍스트(질문)는 BPE로 토큰화되고 임베딩되어 텍스트 표현 를 형성함. 은 텍스트 토큰 수임.
결과적으로 이 단계에서는 이미지 쪽에서 영역별 비전 특징 , 텍스트 쪽에서 텍스트 임베딩 를 준비하여 다음 단계인 Instruction-Region Alignment의 입력으로 제공함.
3.2. Instruction-Region Alignment
문제
3.1에서 얻은 영역 수준 비전 특징 와 텍스트 특징 를 직접 비교하는 것은 두 가지 근본적인 문제가 있음.
첫째, CLS 토큰의 부재.
BERT 같은 인코더 모델에는 CLS 토큰이 있어서 전체 시퀀스의 의미를 하나의 벡터로 요약해줌. 그런데 LLaVA-NeXT 같은 디코더 전용 모델에는 CLS 토큰이 없음. 텍스트 토큰이 개 있으면 개의 개별 토큰 임베딩만 있을 뿐, "이 질문 전체의 의미"를 대표하는 단일 벡터가 없음. 그래서 영역 수준의 비전 특징과 비교하려 할 때, 텍스트 쪽에서 어떤 벡터를 대표로 써야 하는지가 불명확함.
둘째, 서브워드 토큰화와 비전 특징 간의 불일치.
둘 다 차원을 갖지만, 같은 차원이라고 해서 같은 의미 공간에 있는 건 아님. BPE 토큰화는 "retirement"를 "retire" + "ment" 같이 서브워드 단위로 쪼개는데, 이런 서브워드 하나하나의 임베딩은 비전 토큰의 임베딩과 의미적으로 대응되지 않음. 비전 토큰은 이미지의 공간적 패치를, 텍스트 토큰은 언어적 서브워드를 나타내므로 같은 차원 공간에 있어도 서로 다른 방식으로 정보를 인코딩하고 있어 직접 유사도를 계산하면 의미 있는 결과를 얻기 어려움.
해결 방법: 학습 가능한 가이던스 쿼리
이 두 문제를 해결하기 위해 학습 가능한 가이던스 쿼리 를 도입함. 는 쿼리의 개수임. 가이던스 쿼리는 비전과 텍스트 두 모달리티를 연결하는 공통 특징 공간의 매개체 역할을 함.
처리 과정
1단계: MLP를 통한 특징 변환
두 모달리티 간의 정렬을 용이하게 하기 위해, 영역 수준 비전 특징 와 텍스트 특징 를 각각 별도의 MLP 레이어에 통과시켜 와 를 생성함.
2단계: 가이던스 쿼리를 통한 모달리티 인지 표현 추출
가이던스 쿼리 가 각 모달리티의 변환된 특징과 scaled dot-product attention을 수행함.
비전 쪽: 와 번째 영역 비전 특징 사이에 어텐션을 적용하여 비전 인지 표현 를 얻음.
텍스트 쪽: 동일한 메커니즘으로 와 텍스트 특징 사이에 어텐션을 적용하여 텍스트 인지 표현 를 얻음.
여기서 는 스케일링 팩터임.
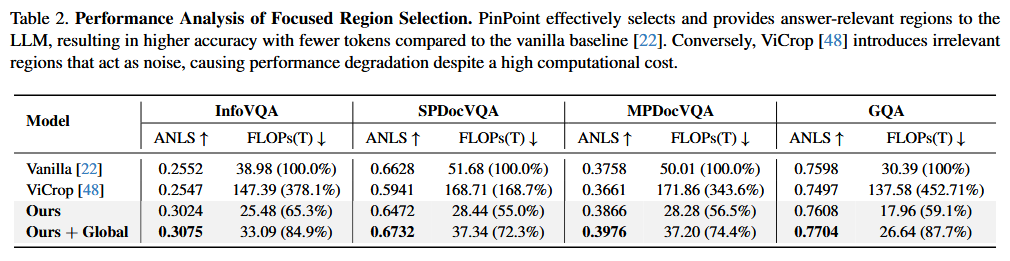
3.3. Selecting and Refining Instruction-Relevant Regions
Region Selection
와 사이의 코사인 유사도로 후보 영역에 순위를 매기고, 선택된 영역의 합산 면적이 전체 이미지의 비율 을 초과할 때까지 상위 영역을 적응적으로 선택함.
Region Refinement
선택된 영역만 원본 이미지에서 크롭하여 ViT로 재인코딩함. 글로벌 셀프 어텐션으로 인한 무관한 문맥 오염을 제거하고, 더 적으면서도 답변에 밀집된 깨끗한 비전 토큰을 얻어 LLM에 입력함.
🗡️ 공격: 크롭하면 전체 이미지에서의 위치 정보를 잃지 않나?
전체 이미지의 비전 토큰은 순서대로 입력되므로 각 패치가 이미지의 어느 부분인지 알 수 있음. 그런데 크롭된 영역만 재인코딩하면, 해당 내용이 원본 이미지의 초반인지 중반인지 알 수 없게 됨.
🛡️ 방어 1: 내용 정보가 위치 정보보다 중요함
크롭된 영역 자체가 질문에 답하기 위한 충분한 시각 정보를 담고 있음. "이 영역이 어디에 있는가"보다 "이 영역 안에 무엇이 있는가"가 답변 생성에 더 중요하며, 실제로 기본 PinPoint만으로도 vanilla 모델(전체 토큰 사용)보다 높은 성능을 보임.
🛡️ 방어 2: "Ours + Global" 변형으로 보완 가능함
Table 2에서 재인코딩된 영역 토큰 + 전체 이미지의 저해상도 토큰(글로벌 컨텍스트)을 함께 LLM에 제공하는 설정이 모든 데이터셋에서 가장 높은 성능을 기록함. 위치 맥락이 필요한 경우 이 방식으로 보완할 수 있음.
🗡️ 재공격: 그러면 "Ours + Global"이 더 좋다는 건, 크롭만으로는 부족하다는 반증 아닌가?
🛡️ 방어 3: 트레이드오프의 문제임
맞음. 논문 자체도 위치 정보 손실을 인지하고 있음. 다만 "Ours + Global"은 FLOPs가 84.9%로 증가하는 반면, 기본 PinPoint는 65.3%만으로도 vanilla를 초과하는 성능을 달성함. 위치 정보 손실보다 무관한 토큰 제거의 이득이 더 크기 때문에, 효율성과 정확도 간의 트레이드오프에서 합리적인 선택임.
🗡️ 재공격: Qwen2-VL에서도 M-RoPE 위치 정보 손실이 문제인데, Qwen2.5-VL에서는 더 치명적이지 않나?
Qwen2-VL의 M-RoPE는 시간·높이·너비 3축으로 위치를 인코딩하는 수준이었음. Qwen2.5-VL은 여기서 더 나아가서, 공간 차원에서 좌표를 정규화 없이 이미지의 실제 크기 스케일로 직접 표현하고, 시간 차원에서도 절대 시간 인코딩을 도입함. 즉 M-RoPE의 위치 정보 의존도가 Qwen2-VL보다 더 높아진 것임. 크롭 후 재인코딩하면 이 강화된 절대 좌표 기반 위치 정보가 크롭 이미지 기준으로 완전히 재생성되므로, Qwen2-VL보다 위치 정보 손실의 영향이 더 클 수 있음. PinPoint 논문에는 Qwen2.5-VL 실험이 없어서 이에 대한 직접적인 반박 근거가 존재하지 않음.
3.4. Training with Contrastive Loss
전체 목적
3.2에서 만든 가이던스 쿼리와 MLP를 잘 학습시켜서, 질문과 관련된 영역의 와 가 가까워지고, 관련 없는 영역의 와 는 멀어지도록 만드는 것임.
포지티브/네거티브 정의
슬라이딩 윈도우로 나눈 영역들 중에서 GT(정답) 영역의 중심과 가장 가까운 영역이 포지티브()임. 정답과 관련 없는 영역들이 네거티브()임.
Inter-modal Contrastive Loss ()
배치 내 서로 다른 샘플들 간의 정렬을 다룸. 예를 들어 배치에 3개의 샘플이 있다고 하면:
- 샘플A: "미국인 평균 퇴직 저축은?" + 인포그래픽 이미지
- 샘플B: "개는 어디에 있나요?" + 자연 이미지
- 샘플C: "매출은 얼마인가?" + 문서 이미지
는 샘플A의 포지티브 영역 가 샘플A의 텍스트 와는 가까워지고, 샘플B·C의 텍스트 와는 멀어지도록 함. 는 반대 방향으로 같은 작업을 수행함. 즉 서로 맞는 질문-영역 쌍은 당기고, 다른 샘플의 질문-영역 쌍은 밀어내는 대칭적 손실임.
Intra-image Contrastive Loss ()
하나의 이미지 내부에서의 분리를 다룸. 같은 이미지 안에서 질문 를 포지티브 영역 에는 가깝게, 같은 이미지의 다른 네거티브 영역들 과는 멀어지게 함. Inter가 "이 질문은 저 이미지가 아니라 이 이미지와 매칭된다"를 학습한다면, Intra는 "이 이미지 안에서도 이 영역이 아니라 저 영역이 정답이다"를 학습하는 것임.
최종 손실
학습 범위
LLM, ViT, 프로젝터는 모두 동결하고, 가이던스 쿼리 와 두 개의 MLP 레이어만 학습함. 전체 파라미터의 1.4%만 학습하면 되므로 매우 효율적임.
🗡️ 공격: Intra-image contrastive loss만으로 충분하지 않나? 왜 배치 내 다른 샘플 정보까지 써야 하는가?
🛡️ 방어 1: Intra만으로는 절대적 정렬 품질을 보장할 수 없음
Intra loss는 같은 이미지 내에서 포지티브 영역이 네거티브 영역보다 텍스트에 상대적으로 더 가깝기만 하면 loss가 줄어듦. 예를 들어 포지티브 유사도가 0.3이고 네거티브가 0.1, 0.2이면 순서만 맞으므로 loss는 감소함. 비전-텍스트가 실제로 잘 정렬되어 포지티브가 0.9인 것과 구분하지 못함. 즉 상대적 순서만 맞으면 통과할 수 있어서, 공통 의미 공간에서의 진정한 정렬이 보장되지 않음.
🛡️ 방어 2: Inter loss가 학습 신호를 풍부하게 만듦
배치에 샘플 3개가 있을 때, intra만 쓰면 각 이미지 내부에서 3번의 독립적인 비교만 수행됨. Inter를 추가하면 각 텍스트를 배치 내 모든 비전 영역과 비교하므로 개의 비교가 생김. 같은 데이터에서 더 많은 비교 관계가 생기고, 이로 인해 학습 신호가 풍부해짐.
🗡️ 재공격: 그러면 inter loss만 쓰면 되지 않나? Intra는 왜 필요한가?
🛡️ 방어 3: 둘은 서로 다른 관점의 학습 신호를 제공함
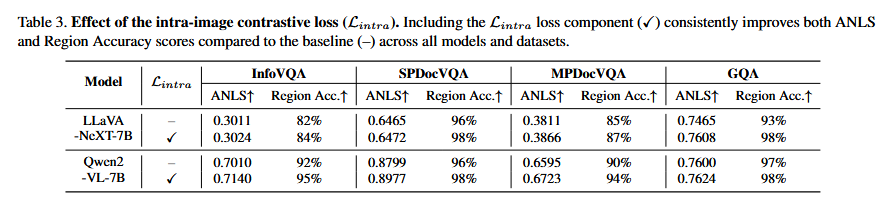
Inter는 "이 텍스트는 이 이미지의 영역과 매칭되고, 다른 이미지의 영역과는 아니다"를 학습함 (이미지 간 구분). Intra는 "같은 이미지 안에서도 이 영역이 정답이고 저 영역은 아니다"를 학습함 (이미지 내 구분). Inter만으로는 같은 이미지 내에서 어떤 영역이 질문과 관련 있는지 세밀하게 구분하기 어렵고, intra만으로는 비전-텍스트 간 절대적 정렬이 부족함. Table 3의 ablation에서도 intra를 추가했을 때 모든 데이터셋에서 ANLS와 Region Accuracy가 일관되게 향상됨을 확인할 수 있음.
4. PinPoint Dataset
5. Experiments
5.1. Datasets
- InfoVQA: 인포그래픽 이미지. 텍스트와 비전 요소가 조밀하게 배치되어 있어 세밀한 멀티모달 추론이 필요함. 가장 도전적인 벤치마크.
- SPDocVQA: 단일 페이지 문서. 문서 수준의 이해와 질의응답을 평가함.
- MPDocVQA: 다중 페이지 문서. 표, 수기 메모, 다이어그램 등 다양한 콘텐츠를 포함하며 페이지 간 추론이 필요함.
LLaVA-NeXT는 다중 페이지를 지원하지 않아 페이지들을 연결해 하나의 이미지로 변환하여 사용함. - GQA: 자연 이미지. 공간적 관계, 객체 속성, 논리적 추론을 포함하는 질문을 다룸. 원래 데이터셋에 GT 영역이 제공되어 있어 그대로 사용하고, 나머지 세 데이터셋은 PinPoint로 구축한 어노테이션을 사용함.
5.2. Implementation and Evaluation Details
모델 및 하이퍼파라미터
- 평가 모델: LLaVA-NeXT-Vicuna-7B, Qwen2-VL-7B
- 윈도우 크기: , 스트라이드: , 목표 비율 : , 가이던스 쿼리 수 :
- 학습: 배치 크기 , 학습률 -, , 에포크
평가 지표
- ANLS: OCR 오류나 오타 같은 미세한 차이를 허용하며 예측 정답과 GT 간 유사도를 측정
- FLOPs / Latency: 입력 처리부터 출력 생성까지의 총 컴퓨팅 비용 측정
비교 대상
- 토큰 감소 방법 (효율성 목표): ToMe, PyramidDrop, FastV, SparseVLM
- 영역 집중 방법 (정확도 목표): ViCrop (rel-attention 변형)
- 베이스라인: 랜덤 토큰 샘플링
5.3. Quantitative Analysis
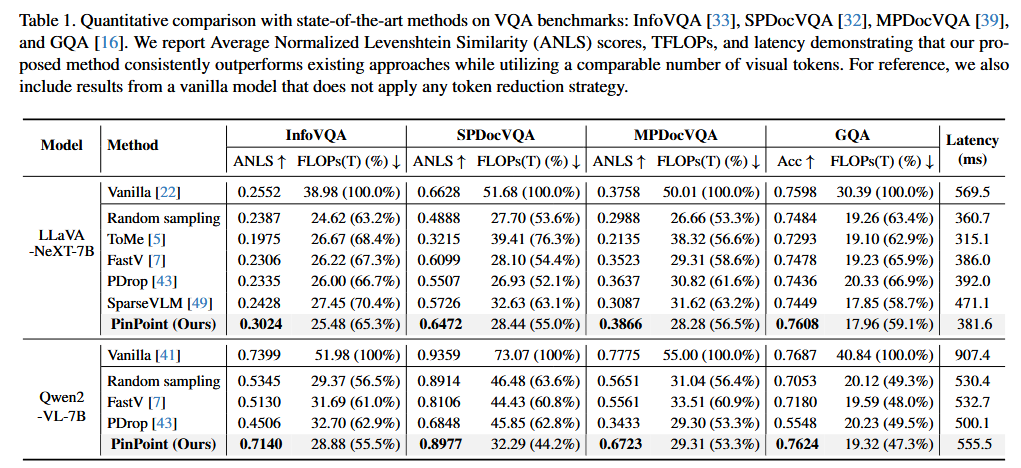
"Ours + Global" 설정: LLaVA-NeXT vs Qwen2-VL
LLaVA-NeXT
LLaVA-NeXT의 AnyRes 모듈은 입력 이미지를 고해상도 패치(최대 6개)와 저해상도 패치(1개, 원본을 축소한 것)로 나눠 각각 ViT로 인코딩함. "Ours + Global"은 PinPoint가 정제한 토큰(크롭 후 재인코딩)에 추가로, 저해상도 토큰(전체 이미지를 축소해서 ViT에 통과시킨 것)을 LLM에 함께 넣는 설정임. 저해상도 토큰은 1개 패치 분량이므로 FLOPs 증가가 상대적으로 제한적임.
Qwen2-VL
Qwen2-VL은 Naive Dynamic Resolution 방식으로 이미지를 한 번만 인코딩하여 가변적 수의 토큰을 생성하므로, 별도의 저해상도 패치가 없음. 따라서 "Ours + Global"을 적용하면 전체 이미지 토큰을 통째로 추가해야 할 가능성이 높아, LLaVA-NeXT보다 FLOPs 증가가 더 클 수 있음.
Table A2에서 Qwen2-VL "Ours + Global"의 ANLS만 보고되어 있고(InfoVQA 0.7560, SPDocVQA 0.9380, MPDocVQA 0.8071, GQA 0.7682), FLOPs/latency는 제공되지 않아 정확한 연산량 증가는 확인 불가함.
5.4. Qualitative Analysis

정답 관련 영역 내의 토큰을 빈번하게 가지치기하며, 이는 흔히 환각을 일으키거나 의미론적으로 일관되지 않은 응답으로 이어짐.
5.5. Effiiency of PinPoint in Training
생략
5.6. Ablation Studies
생략
