Rethinking Token Reduction for Large Vision-Language Models
Abs. & 1. Introduction
기존 문제점
1. 기존 Token Reduction은 Single-Turn VQA에만 맞춰져 있음
대부분의 token reduction 방법은 "한 번의 질문에 한 번 답하는" single-turn VQA를 전제로 설계되어 있다. 하지만 실제 사용 환경은 하나의 이미지에 대해 여러 턴에 걸쳐 질문하는 Multi-Turn VQA(MT-VQA) 가 훨씬 현실적이다. MT-VQA에서는 후속 질문이 이미지의 어떤 영역을 참조할지 미리 알 수 없어서 기존 방법이 직접 적용되기 어렵다.
2. Prompt-Dependent 방식의 한계
FastV 등은 첫 번째 질문(prompt)과의 attention을 기준으로 visual token을 선별한다. 이 경우 첫 질문과 관련 없는 영역의 token이 삭제되며, KV cache 구조상 삭제된 token은 이후 턴에서도 복구가 불가능하다. 결과적으로 후속 질문에 필요한 정보가 유실된다.
3. Prompt-Agnostic 방식의 한계
LLaVA-PruMerge 등은 prompt 없이 이미지 자체의 attention score(예: [CLS] token attention)를 기준으로 token을 줄인다. MT-VQA에 기술적으로 적용 가능하지만, 이 기준은 인간의 직관에서 나온 휴리스틱이며 최적성이 보장되지 않는다. 논문 Section 4의 실험에서, 학습으로 찾은 최적 compression이 유지하는 token들이 [CLS] attention이나 prompt attention과 거의 무관함을 실증했다.
MetaCompress의 해결법
1. Token Reduction을 학습 가능한 최적화 문제로 통합
기존에 별개로 다뤄지던 token pruning과 merging을 하나의 compression matrix 로 통합한다. 핵심 목표는 "P로 압축한 visual sequence를 사용했을 때, 원본 대비 LLM 응답의 차이가 최소가 되는 P를 찾는 것"이다.
2. 휴리스틱을 배제한 학습 기반 접근
[CLS] attention, prompt attention 등 인간이 설계한 기준 대신, 데이터로부터 직접 최적 압축 전략을 학습한다. 이를 통해 기존 휴리스틱의 suboptimal 문제를 근본적으로 해소한다.
3. Dynamic Resolution에 대응하는 Compression Matrix Generator
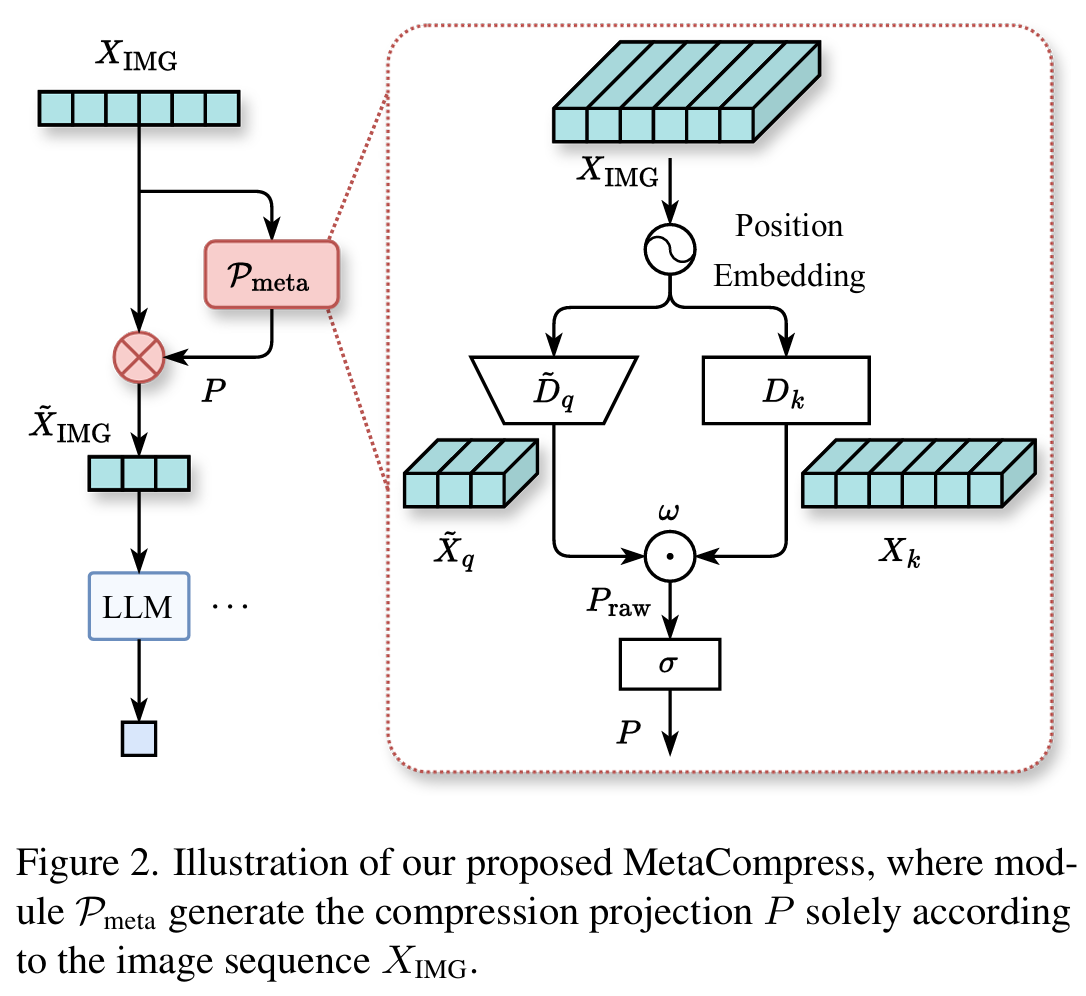
에서 n은 입력 visual token의 수인데, 실제 이미지는 해상도가 제각각이다. LLaVA-NeXT나 InternLM-XComposer-2.5 같은 최신 LVLM은 multi-scale vision tower를 사용하기 때문에, 이미지에 따라 visual token 수 n이 달라진다. 이는 곧 이미지마다 P의 크기 자체가 달라져야 한다는 뜻이다. 이때 가능한 모든 해상도에 대해 각각의 P를 미리 학습해 놓는 것은 조합이 방대하여 비현실적이고 우아하지도 않다. 이를 해결하기 위해 MetaCompress는 고정된 P를 학습하는 대신, 입력 이미지로부터 P를 동적으로 생성하는 모듈 를 설계한다. 는 position embedding, query down-sample projection, key projection, weighted inner product로 구성되며, 어떤 길이의 visual sequence가 들어오더라도 그에 맞는 크기의 P를 자동으로 생성한다.
2. Related Work
생략
3. Preliminaries
생략
4. Which Tokens to Keep?
최적 Compression Matrix P의 초기화와 학습
하나의 이미지-대화 쌍 에 대해, 휴리스틱 없이 데이터가 직접 알려주는 최적의 압축 행렬 를 찾는 실험이다.
초기화: 의 각 원소를 가우시안 분포 에서 독립적으로 샘플링한다. 이 시점에서 는 아무런 패턴 없는 랜덤 상태이다.
P 생성: 에 행 단위 softmax를 적용하여 를 얻는다. 행 단위로 정규화하는 이유는 의 번째 행이 "압축된 번째 token을 원본 개 token의 어떤 가중합으로 만드는가"를 나타내기 때문이다. 각 행의 가중치 합이 1이 되어야 의미 있는 조합이 된다.
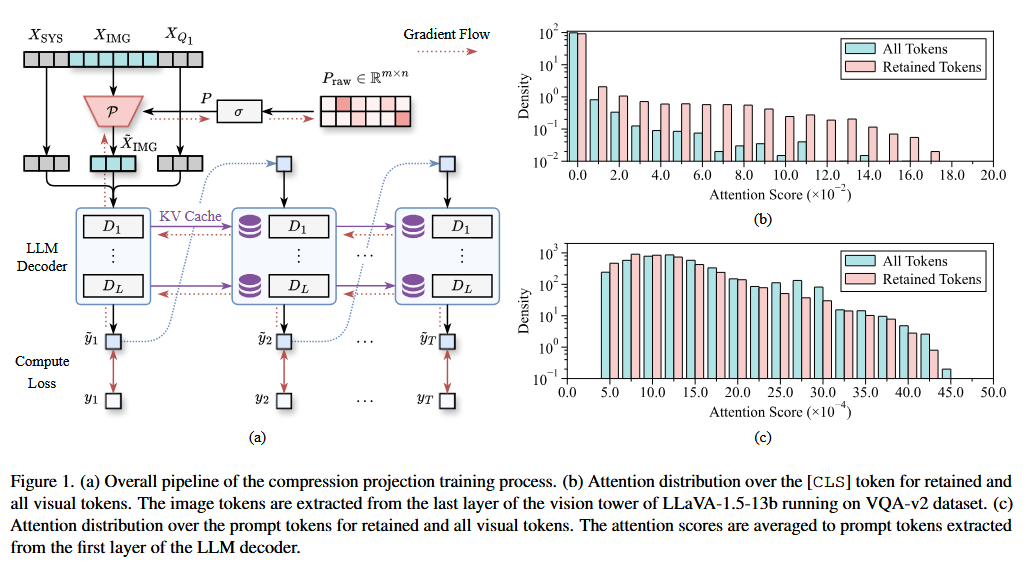
학습 과정 (Figure 1. (a)):
1. 원본 를 LLM에 넣어 응답 분포 를 얻는다 (gradient 없이 고정).
2. 압축된 를 LLM에 넣어 응답 분포 를 얻는다 (gradient 있음).
3. 두 분포의 차이인 KL divergence 를 계산한다.
4. 추가로 의 각 행에 대한 엔트로피 정규화 를 적용하여 가 sparse해지도록 유도한다.
5. 최종 목표: 를 gradient descent로 풀어 만 업데이트한다 (LLM 파라미터는 고정).
이를 통해 "이 이미지에서 어떤 token을 남겨야 LLM 응답 차이가 최소가 되는가"의 정답을 데이터로부터 직접 얻는다.
학습 결과와 휴리스틱의 비교 (Figure 1. (b), (c))
학습으로 얻은 가 유지한 token들이 기존 휴리스틱 기준과 일치하는지를 검증한다.
(데이터가 찾은 최적 compression)가 유지한 token들을 분석해보면, [CLS] attention이 높은 token이 일부 포함되어 있긴 함. 하지만 그 비율은 전체 retained token의 약 1.71%에 불과함.
이건 결국, 기존 휴리스틱(PruMerge 등)이 "[CLS] attention이 높은 token을 남기자"라는 전략으로 token을 골랐을 때, 실제 최적해인 의 선택과 98.29%가 불일치한다는 뜻임.
Prompt attention에 대해서도 마찬가지임. 가 유지한 token들은 prompt attention score와도 뚜렷한 상관을 보이지 않음.
따라서 attention score를 기준으로 token을 선별하는 기존 휴리스틱은, 데이터가 알려주는 최적 선택과 거의 일치하지 않으므로 suboptimal이라는 결론임.
5. Method
5.1. MetaCompress
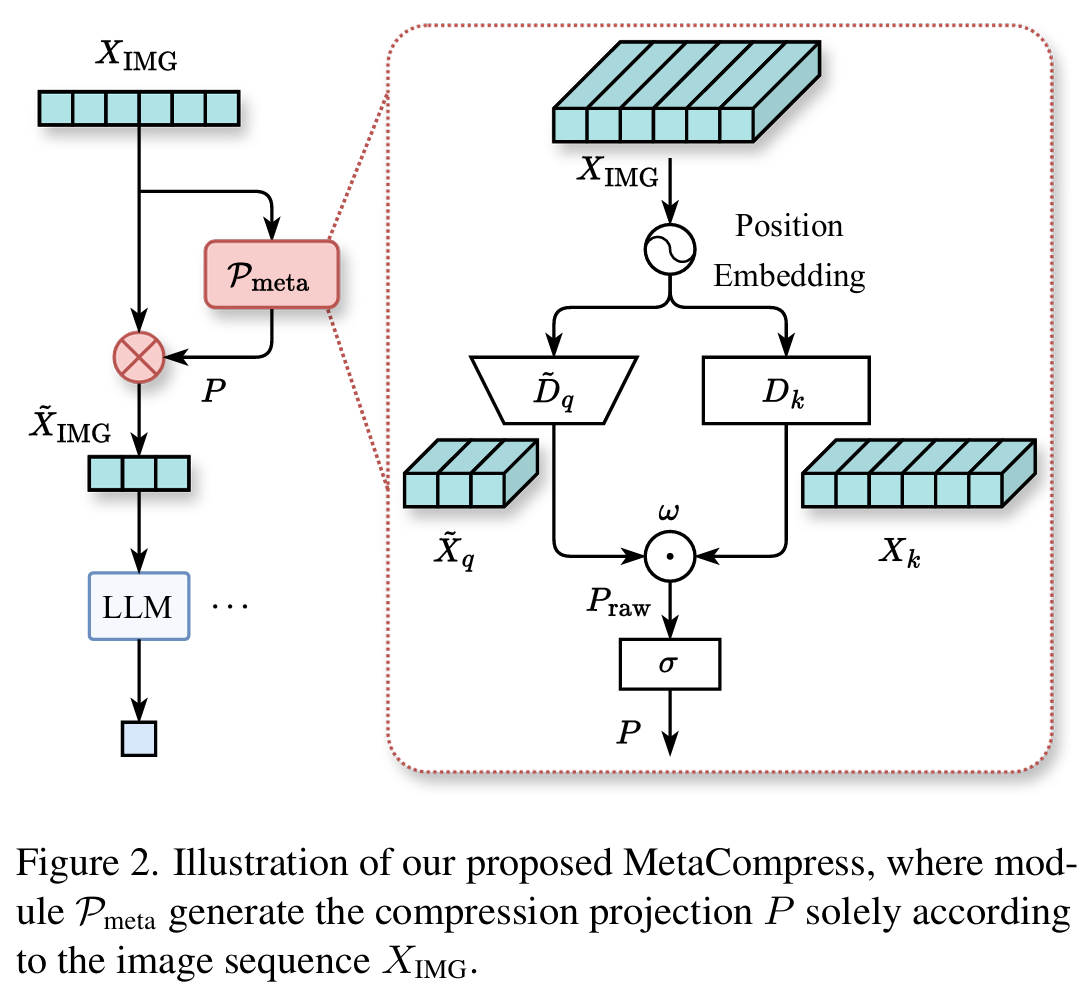
입력
- : 원본 visual token sequence. 은 token 수 (이미지 해상도에 따라 가변), 는 embedding 차원 (예: LLaVA-1.5-7b에서 )
- 목표: 개 token을 개로 압축 ()
Step 1: Position Embedding 추가
에 절대 위치 정보를 더한다.
- : position embedding
- 결과:
Step 2: Key 생성
- : key projection. 로 설정하여 연산 효율화
- 차원 흐름:
Step 3: Query 생성 (Down-sampling 포함)
3-1. Fractional Pooling: 시퀀스 길이를 으로 줄인다. stride (소수점 허용)으로 설정하여 어떤 이든 정확히 개로 줄일 수 있다.
3-2. Linear Projection: pooling된 시퀀스를 차원으로 변환한다.
- : query projection
- 차원 흐름:
Step 4: Compression Matrix 계산
- , (learnable 대각 행렬),
- 차원 흐름:
- 행 단위 softmax 적용하여 (각 행의 합 = 1)
Step 5: Visual Token 압축
- 차원 흐름:
- 압축된 가 LLM decoder에 입력된다.
학습 가능한 파라미터 (시퀀스 길이 과 무관한 고정 크기)
| 파라미터 | 차원 | 역할 |
|---|---|---|
| Query projection | ||
| Key projection | ||
| 채널별 가중치 (대각 행렬) |
이 세 파라미터는 개별 token의 차원 변환()만 수행하므로 시퀀스 길이 에 의존하지 않는다. 의 변화는 fractional pooling의 stride 조절과 inner product 연산이 자동으로 처리한다. 따라서 어떤 해상도의 이미지가 들어와도 동일한 파라미터로 적절한 크기의 를 생성할 수 있다.
6. Experiments
6.1. 실험 설정
벤치마크: 3개의 MT-VQA 벤치마크에서 평가한다.
- MT-VQA-v2: VQA-v2 validation set 기반, 25k개의 3-turn 대화 쌍
- MT-GQA: GQA testdev-balanced set 기반, 4061개의 3-turn 대화
- ConvBench: 577개의 native multi-turn 대화, 3단계 멀티모달 능력 계층 평가
LVLM 아키텍처: 5개 모델에서 일반화 성능을 평가한다. - LLaVA-1.5-7b/13b (single-scale vision tower)
- LLaVA-NeXT-7b/13b (multi-scale vision tower)
- InternLM-XComposer-2.5-7b (multi-scale vision tower)
학습: MT-GQA training-balanced split과 MT-VQA-v2 training set에서 약 20k 샘플만 사용. ConvBench에서는 MT-VQA-v2에서 학습한 가중치로 평가 (transfer 성능 검증).
비교 baseline:
- Base: token reduction 없이 원본 LVLM 그대로 평가
- Random: LLM decoder 입력 전에 visual token을 랜덤으로 제거 (3개 seed 평균)
- Sample: visual sequence에서 등간격 down-sampling
- FastV: prompt attention 기반으로 token 중요도를 측정하여 pruning (prompt-dependent)
- PruMerge: attention 기반으로 pruning + merging (LLaVA-1.5에서만 호환)
6.2. 비교 결과 (Table 1, Figure 3)
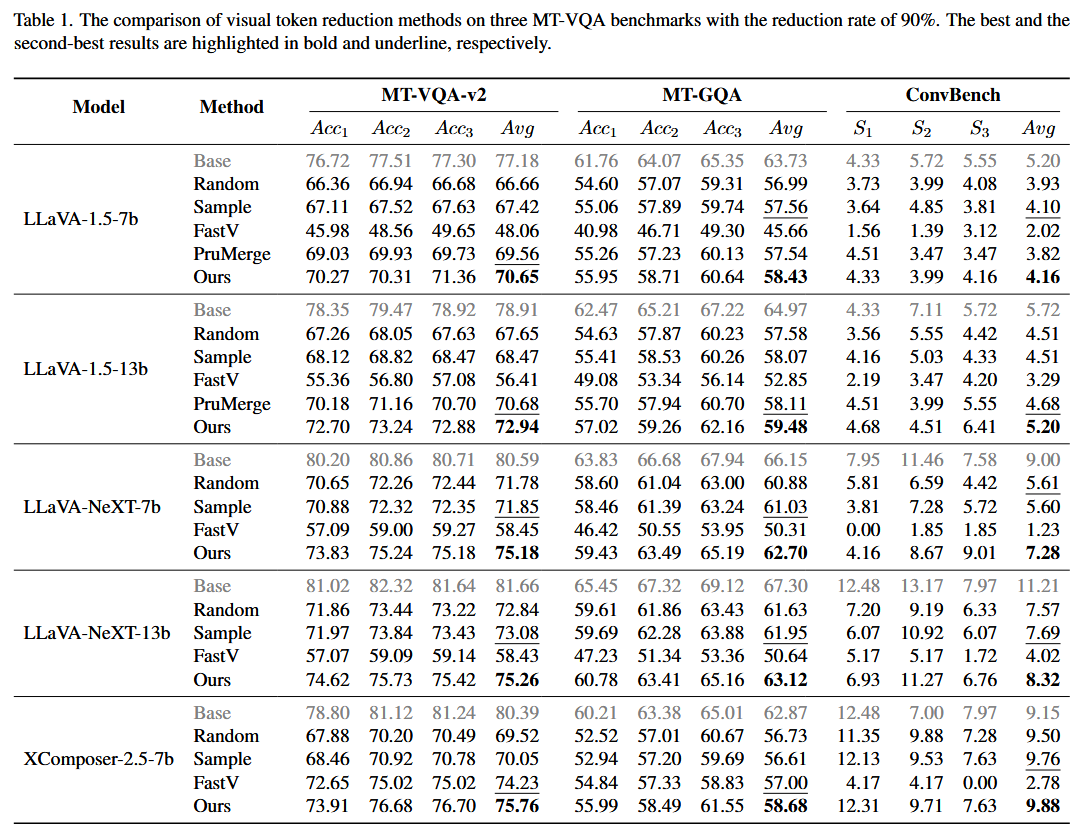
Table 1 — 90% reduction rate 결과:
MetaCompress가 모든 LVLM 아키텍처와 모든 벤치마크에서 일관되게 최고 성능을 달성한다. 주목할 점들:
- FastV의 실패: FastV는 대부분의 설정에서 Random이나 Sample보다도 성능이 낮다. 예를 들어 LLaVA-NeXT-7b의 ConvBench에서 FastV Avg = 1.23인 반면 Random Avg = 5.61이다. 이는 Section 4에서 밝힌 "attention 기반 휴리스틱은 suboptimal"이라는 결론과 일치한다.
- PruMerge의 한계: LLaVA-1.5에서는 Sample보다 약간 나은 정도이며, multi-scale vision tower(LLaVA-NeXT, XComposer)와는 호환 불가하다.
- MetaCompress의 우위: ConvBench에서 학습하지 않았음에도 baseline을 큰 폭으로 능가하여 transfer 능력을 입증한다.
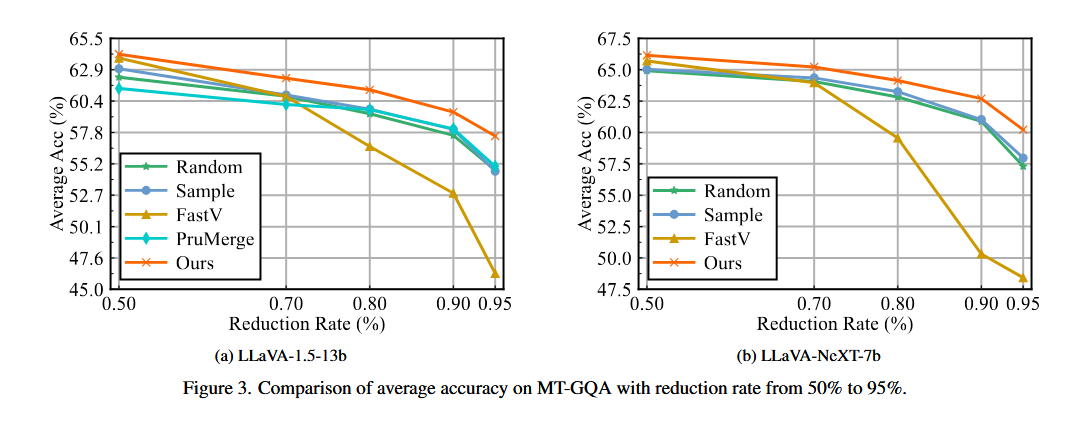
Figure 3 — Reduction rate 50%~95%에서의 성능 곡선:
MetaCompress(빨간색)가 모든 reduction rate에서 일관되게 최상위를 유지한다. FastV는 낮은 reduction rate(50%)에서는 상대적으로 선방하지만, reduction rate가 높아질수록 급격히 하락한다. PruMerge는 높은 reduction rate에서 상대적으로 나은 편이지만 MetaCompress에는 미치지 못한다.
6.3. 효율성 결과 (Table 2)
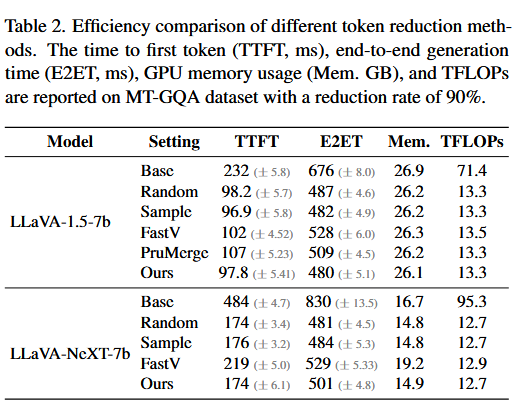
Table 2 — 추론 효율 비교 (90% reduction, MT-GQA):
MetaCompress는 가장 효율적인 baseline인 Sample과 거의 동일한 효율을 보인다.
- LLaVA-1.5-7b: Base 대비 TTFT 232ms → 97.8ms (2.4배 감소), TFLOPs 71.4 → 13.3 (5.4배 감소)
- LLaVA-NeXT-7b: Base 대비 TTFT 484ms → 174ms (2.8배 감소), TFLOPs 95.3 → 12.7 (7.5배 감소)
- FastV는 다른 reduction 방법들보다 TTFT와 E2ET 모두 느리고 메모리도 더 사용한다 (중간 attention matrix 계산 때문).
6.4. Transfer 결과
MetaCompress가 특정 학습 데이터셋에 과적합되지 않음을 검증한다.
- Cross-dataset transfer: MT-GQA에서 학습 → MT-VQA-v2 평가 (또는 반대)에서도 성능 하락이 적다.
- ConvBench transfer: MT-VQA-v2에서 학습한 가중치로 ConvBench를 평가해도 baseline을 능가한다 (Table 1에서 확인 가능).
- Video QA transfer: 이미지 MT-VQA에서 학습한 가중치로 MT-Video-MME(비디오 QA)를 평가해도 baseline을 능가한다 (Table 8, Supplementary).
6.5. Ablation Study (Table 3, Figure 4)
생략
6.6. 시각화 (Figure 5)
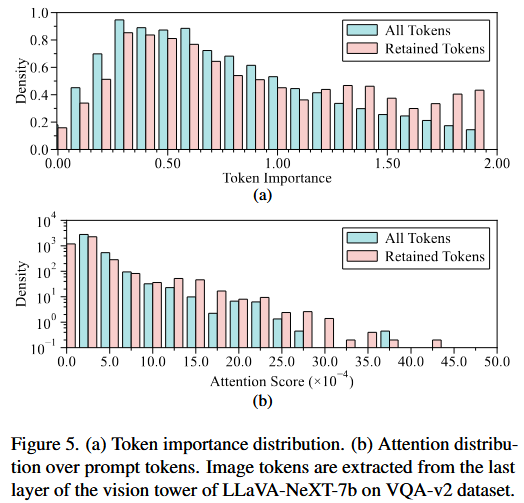
Figure 5 — LLaVA-NeXT-7b에 대한 추가 시각화:
Section 4의 Figure 1(b), 1(c)와 동일한 분석을 LLaVA-NeXT-7b에서 수행한 결과이다.
- (a) Token importance 분포: FastV 스타일의 token importance로 측정. All Tokens와 Retained Tokens의 분포가 뚜렷하게 다르지 않으며, importance가 높은 token이 특별히 더 많이 유지되지 않았다.
- (b) Prompt attention 분포: Figure 1(c)와 동일한 결론. 가 유지한 token들이 prompt attention과 무관하게 선택되었다.
이는 Section 4의 결론(attention 기반 휴리스틱은 suboptimal)이 LLaVA-NeXT-7b에서도 동일하게 성립함을 재확인한다.
