1. OT
강의 목적

2. 데이터 제작의 중요성
데이터 제작의 P;ㅠ
P;ㅠ는 피땀눈물을 의미한다!!
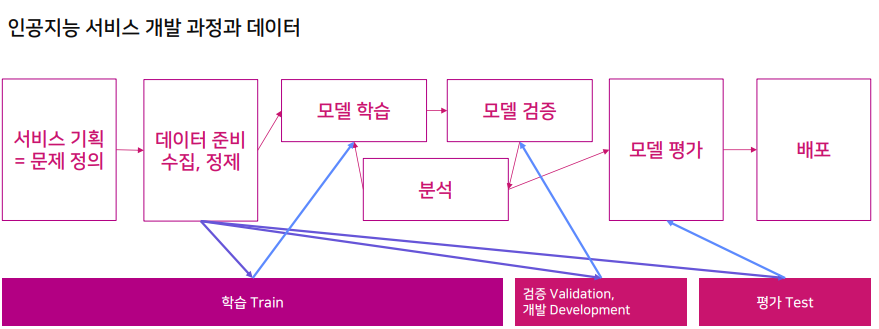
각각의 과정은 끊임없이 상호작용한다. 이 때 각각의 작업이 소요되는 시간은 얼마나 될까?
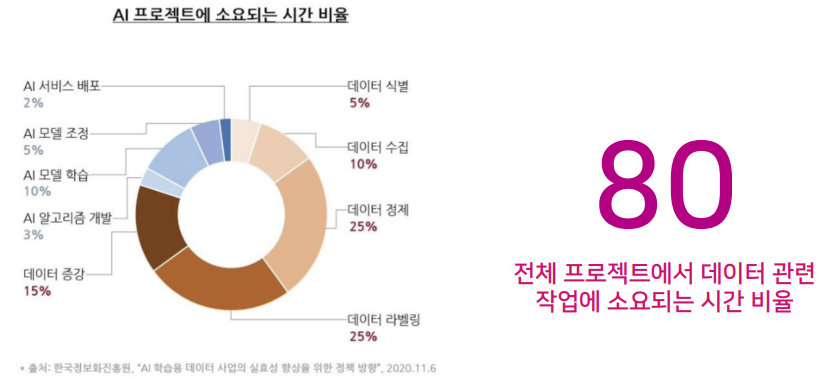
데이터 제작에 대해서는 등한시 되기가 쉽다. 왜냐하면 데이터 제작에는 이렇게 해야 한다. 라는 왕도가 없고, 경험적으로 깨닫는것이 일반적이기 때문이다. 본 강의에서는 이러한 시행착오를 통해 얻을 수 있는 노하우를 제공하고자 한다.
3. 데이터 구축 과정과 설계 기초
데이터 구축 과정
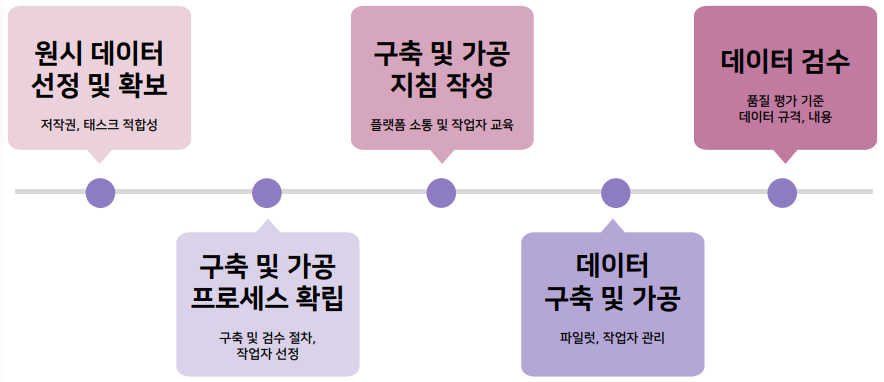
원시 데이터 선징 및 확보
저작권이 잘 준수되고 주어진 태스크에 잘 적합한지 파악해야 하는데, 이 과정이 제일 어렵고 고민스러운 부분이다. 첫걸음 때는 이미 만들어진 데이터를 활용하는 것이 좋다.
구축 및 가공 프로세스 확립
누구에게 얼마만큼의 양을 맡겨서 구축을 할지. 그리고 구축된 것은 어떠한 방식으로 검토를 할지. 작업자가 교차검수를 할지. 전문가가 샘플링 검수를 할지 정해야 한다. 이 때 작업자를 선정하는 과정도 진행되어야 한다
구축 및 가공 지침 작성
데이터를 구축하고 가공하는데 필요한 지침을 작성해야 한다. 레이블 에이전시나 클라우드 소싱 플랫폼을 통해 작업을 한다면 소통하는 작업이 필요하다. 가이드라인을 만들면서, 작업자 교육도 필요하다.
데이터 구축 및 가공
실제로 데이터를 구축 및 가공하는 단계이다. 단순히 한차례에 거쳐서 이루어 지는 것은 아니며 최초의 계획대로 순조롭게 진행된다는 기대도 절대 하면 안된다.
데이터 검수
프로젝트 막바지에 가면 이 과정이 등한시 되기 쉬운데 데이터 품질을 결정하는 단계이므로 꼭 거쳐야한다.
AI 데이터 설계의 구성 요소
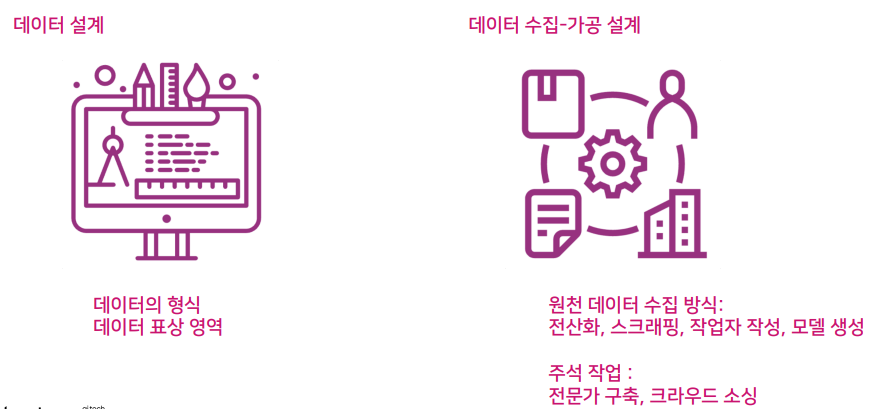
데이터 설계

데이터의 유형
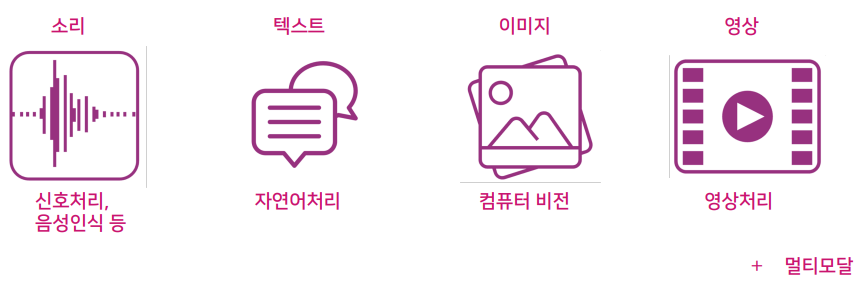
한 가지의 데이터로만 이루어질 수 있고 혼합되어 이루어질 수도 있다.
데이터의 In/Out 형식

언제든지 바뀔 수 있는 형식이다. 효율적인 형식을 사용해야함
데이터별 규모와 구분 방식

사전에 얼마만큼의 규모로 나눌 것이고 어떤 기준으로 나눌 지 정해야한다.
보통 레이블의 분포가 동일하지가 않다. imbalnace한 데이터가 많기 때문에 이를 학습과 평가에서 골고루 나뉘게 해야할 수도 있다.
데이터 주석 유형 : 자연어처리
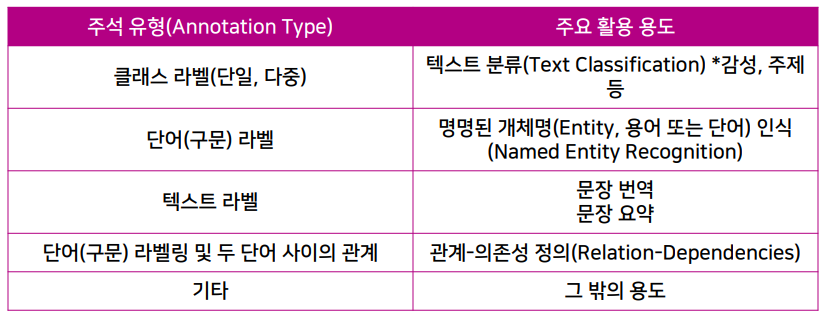
데이터 수집-가공 설계

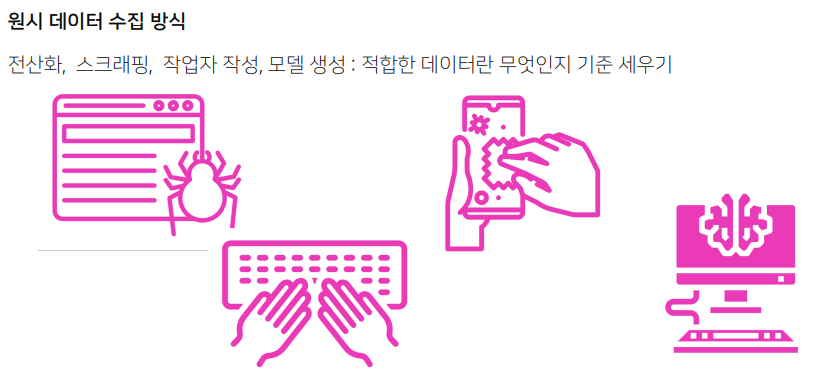
- 전산화 : 이미 있는 책등을 텍스트 파일로 만드는 일
- 스크래핑 : 웹에 있는 데이터 획득
- 작업자 작성 : 작업자를 통해서 대화나 발화를 작성하게 함
- 모델 생성 : 모델을 통해서 모델이 자동 생성한 데이터를 원시 데이터로 삼음
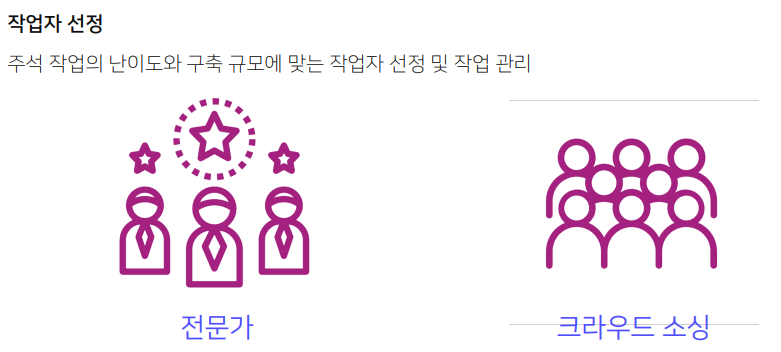
전문가를 사용하면 데이터의 품질이 증가할 수 있지만 단가가 높고 데이터의 양이 적다.
반면에 크라우드 소싱은 단순하고 직관적인 작업을 맡길 수 있으며 전문적인 지식이 아니라 단순한 정도의 가이드 라인만 읽고 작업할 수 있는 작업을 맡긴다.
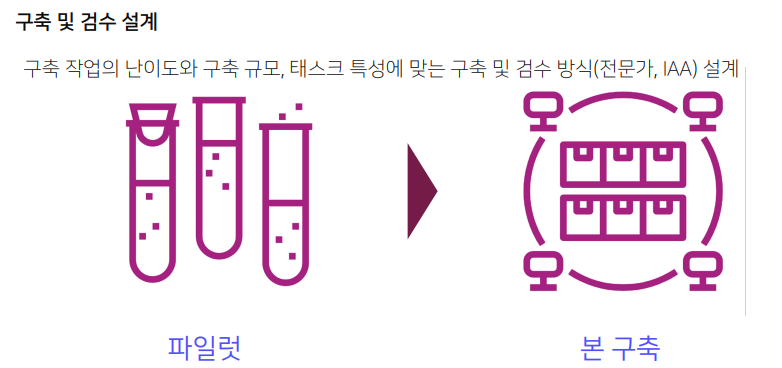
데이터를 어떻게 구축하고 검수할 지 결정한다. 몇 차례에 거쳐 할지, 한 사람만 볼지 여러 사람이 볼지, 구축 작업의 난이도, 구축 규모, 테스트 특성에 따라 이루어져야 한다.
보통 파일럿작업을 하고 본 구축을 한다. 파일럿 작업은 적게는 100개, 많게는 1~2천개의 데이터를 작업해본다. 본 구축은 1~3만개정도 되기 때문에 그 중 10% 정도로 파일럿을 한다.

본 구축은 여러 차수로 구성되어 수행된다. 가이드라인에 맞지 않은 데이터가 있으면 수정하거나 제외한다.
4. 자연어처리 데이터
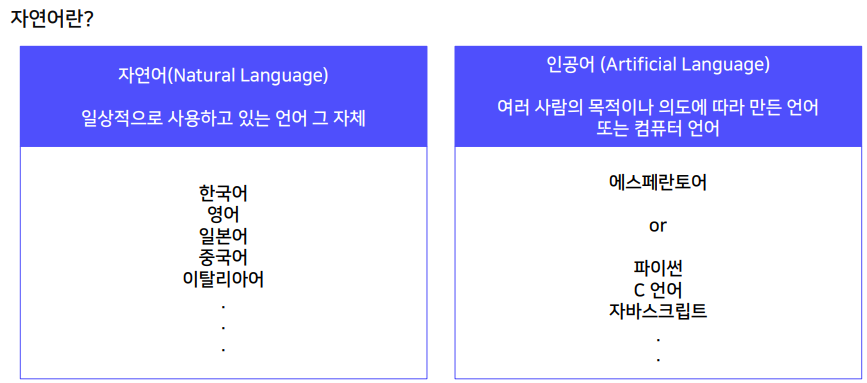
인공어와 구분하기 위해 "자연어" 라는 단어를 사용했다.

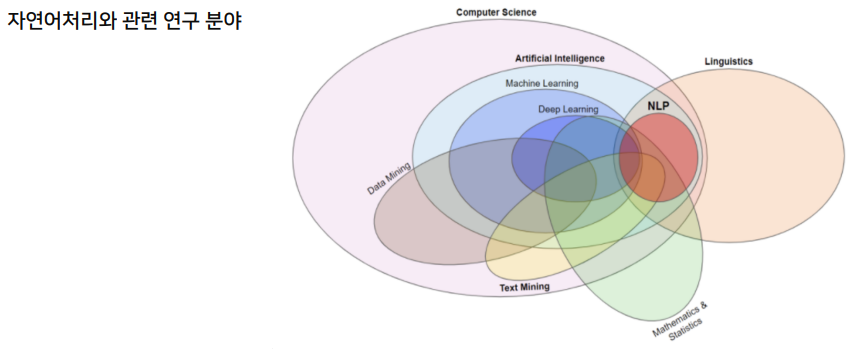
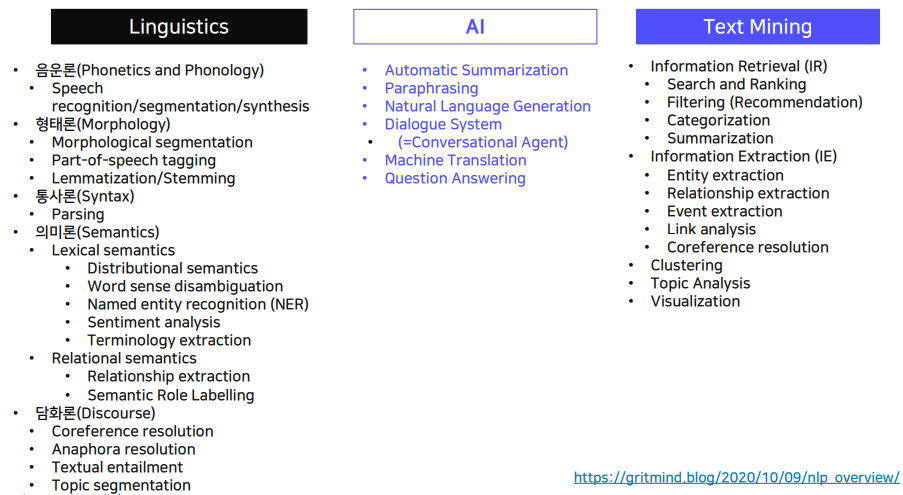
각각 한개의 개념당 한 한기 수업을 해야 할 정도로 깊고 넓은 분야임.

