1. 인공지능 모델 개발을 위한 데이터
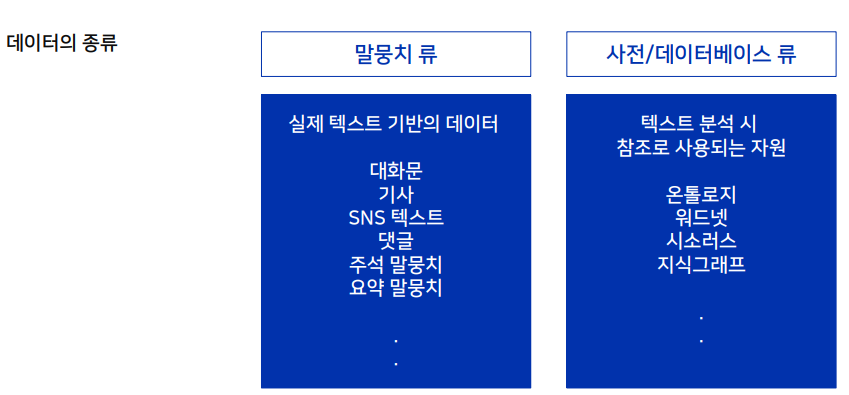
두 종류로 거의 나타낼 수 있다.
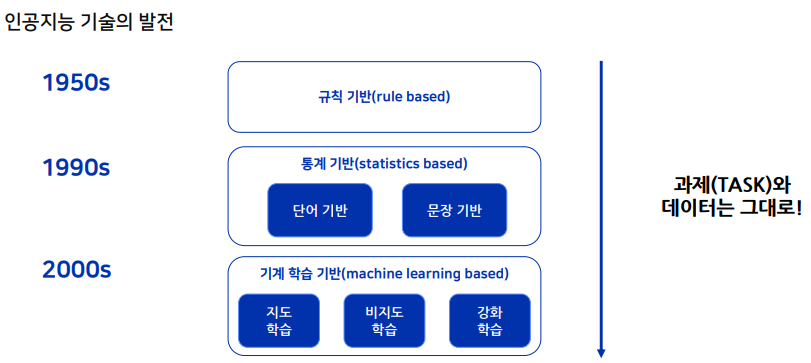
기술 자체는 변화해왔지만 풀고싶어하는 문제는 그대로이다. 물론, 최초에는 존재하지 않았던 문제도 있긴하다.
이전에 쓰던 데이터는 그대로 쓴다. 데이터에 소모되는 비용이 크기 때문에 되도록이면 그대로 사용한다.
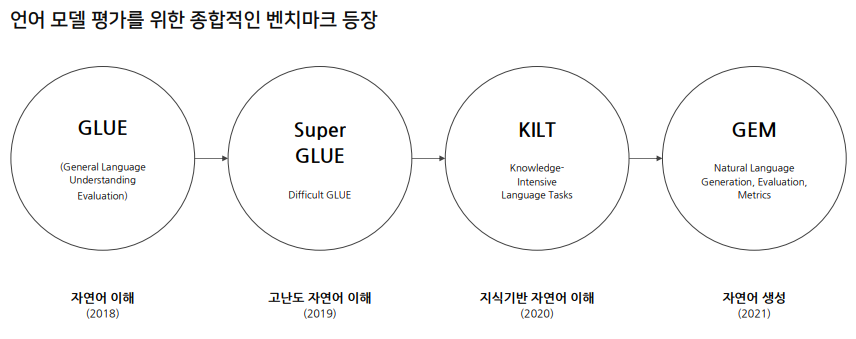
종합적인 언어모델의 성능을 평가해보자는 아이디어 등장.
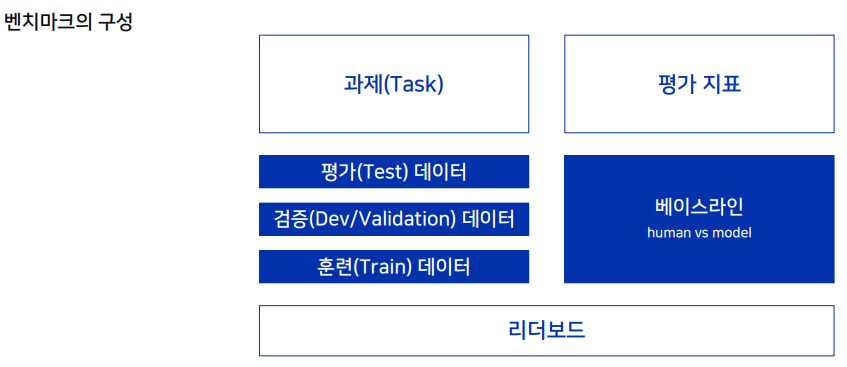
보통의 벤치마크에서는 평가 데이터가 공개되지 않는다. 서비스를 제공할 때는 세 가지의 데이터 종류를 만들어야 한다.
2. 데이터 관련 용어 정리

반드시 이렇게 써야만 한다는 것은 아니며, 맥락에서 명확하게 이해하는 데 도움이 되고자 하는 바.
텍스트는 기준이 없고, 말뭉치는 기준을 가지고 모아 둔 차이가 있지만, 엄밀한 의미로 쓰이지는 않는다. 정제된 데이터가 말뭉치이다 정도로만 알고 있으면 된다.

감정 분석에서는 Positive, Negative가 주석이 된다.
언어 모델이 주석을 하는 것을 "분석" 이라고 보았기 때문에 형태소 주석기라고 하지 않고 형태소 분석기라고 하게 되었다.
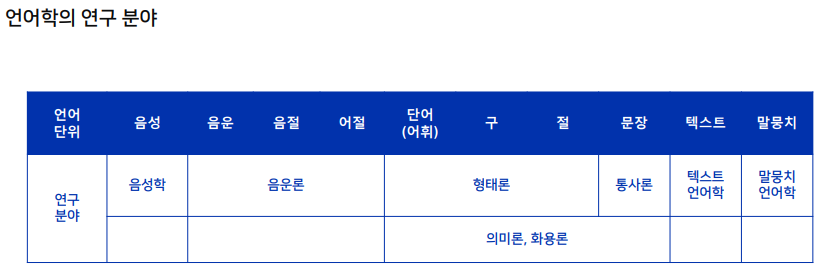
음성과 음운은 자연어 태스크에서 다루는 대상은 아님.
말뭉치는 보통 단어나 문장을 기준으로 이야기 한다.

영어의 단어와 한국어의 어절은 둘 다 띄어쓰기 단위라는 공통점이지만, 한국어는 단어가 띄어쓰기의 단위가 아니다.

설명이 직관적이지는 않아서 예시로 파악하는 것이 좋다.


표현보다는, 컴퓨터가 알도록 표현한다는 의미에서 표상으로 쓰는게 더 자연스럽다.
3. 자연어처리 데이터 형식
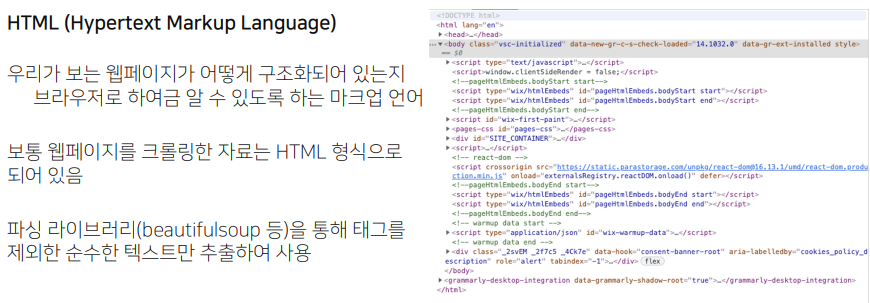
우리가 보는 웹 페이지를 브라우저가 알게끔 한 언어
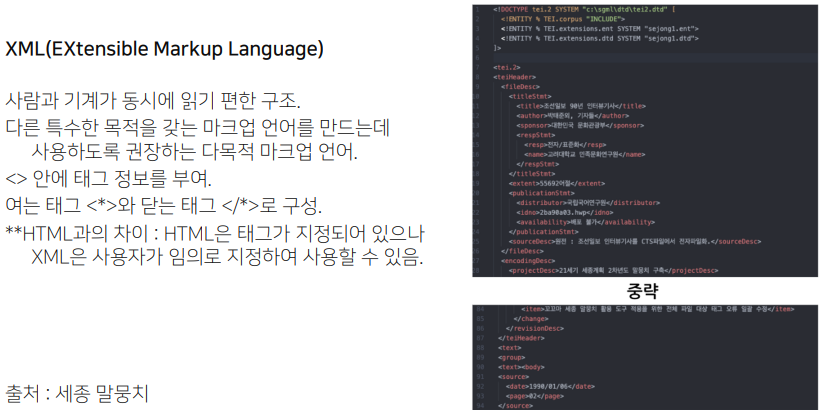
사람과 기계가 동시에 알기 편한 언어. html은 전 세계 규격으로 정해져있지만 xml은 마음대로 태그를 지정할 수 있다.


어떤 구분자로 데이터를 구분할지에 대한 차이이다. 보통 문자열에는 쉼표가 포함될 확률이 크기 때문에 tsv를 사용하는 것을 권장한다.
4. 공개 데이터

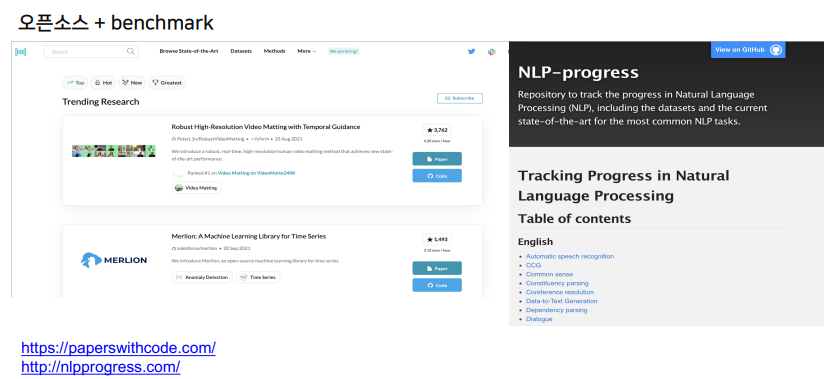
공인을 받은 데이터셋을 사용하는 것은 굉장히 좋다.
