데이터제작(NLP)
1.(1강) 데이터 제작의 A to Z
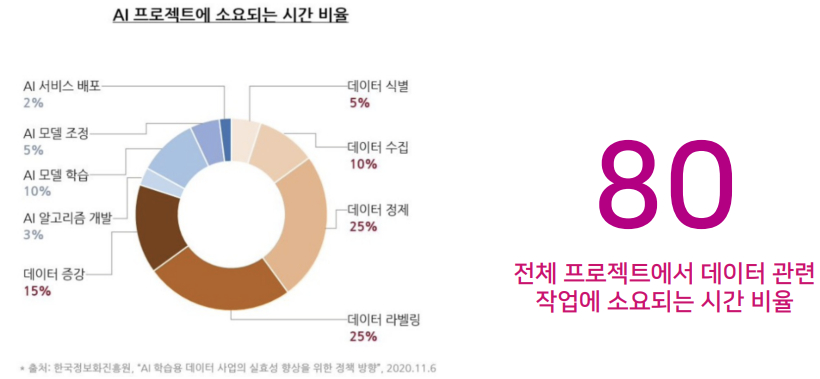
P;ㅠ는 피땀눈물을 의미한다!!각각의 과정은 끊임없이 상호작용한다. 이 때 각각의 작업이 소요되는 시간은 얼마나 될까?데이터 제작에 대해서는 등한시 되기가 쉽다. 왜냐하면 데이터 제작에는 이렇게 해야 한다. 라는 왕도가 없고, 경험적으로 깨닫는것이 일반적이기 때문이다.
2.(2강) 자연어처리 데이터 기초
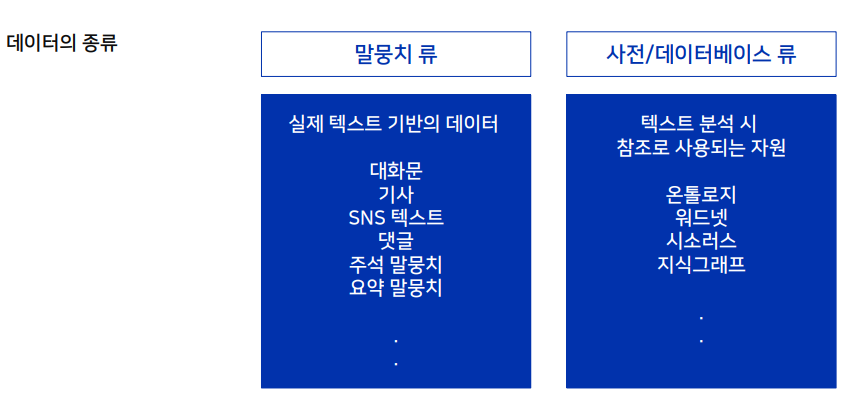
두 종류로 거의 나타낼 수 있다. 기술 자체는 변화해왔지만 풀고싶어하는 문제는 그대로이다. 물론, 최초에는 존재하지 않았던 문제도 있긴하다.이전에 쓰던 데이터는 그대로 쓴다. 데이터에 소모되는 비용이 크기 때문에 되도록이면 그대로 사용한다.종합적인 언어모델의 성능을 평
3.(3강) 자연어처리 데이터 소개 1

1. 국내 언어 데이터의 구축 프로젝트 대학교 자체에서 만든 말뭉치들도 있었지만, 국가적으로 10년 계획을 가지고 수행한 프로젝트가 21세기 세종 계획이다. 국어학자와 언어학자의 의견이 많이 반영됐다. 엑소브레인 프로젝트는 인공지능을 개발하기 위해 수행하는 프로젝트이다. 현재 진행중인 프로젝트이고 많은 언어 자원이 있다. 2016년 알파고 이후...
4.(4강) 자연어처리 데이터 소개 2
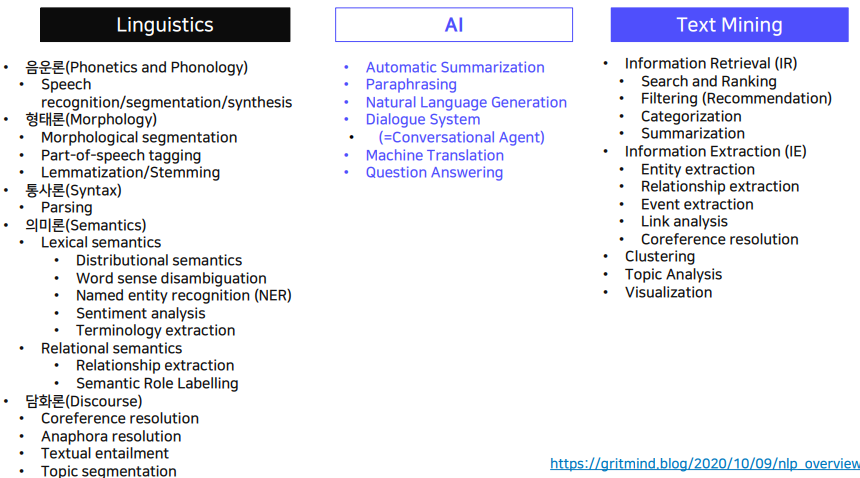
1. 더 알아보기 좋은 데이터를 만들기 위해서는 사람들이 앞서서 어떤 데이터를 만들었는지 찾아보고 좋은점을 본받아야 된다. 이런 과제들이 자연어 처리에서 다루어지는데, 이들에 대해 세부적으로 모든 것을 알고있는 사람은 없다. 대부분은 몇가지 태스크들에 대해서만 세부적으로만 알고 깊게 경험을 가지고 있다. 그러니 모두를 다 깊게 알 필요는 없지만, 전반적...
5.(5강) 원시 데이터의 수집과 가공
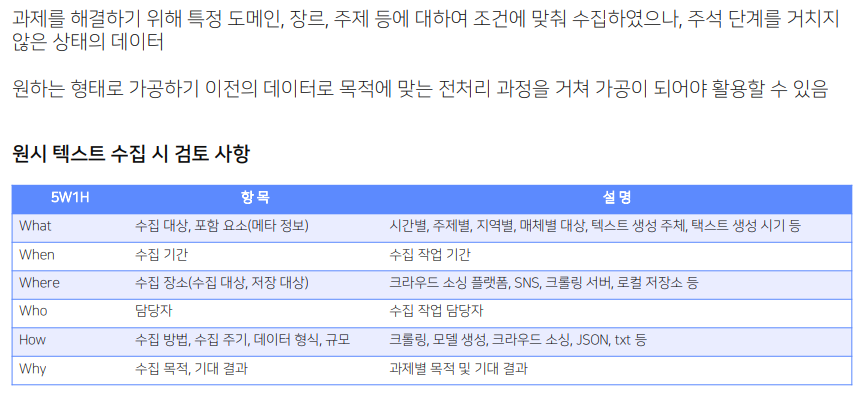
1.원시 데이터의 정의 원시 데이터란? 원시 말뭉치와 동일한 개념이다. 아무런 텍스트는 아니고 내가 원하는 텍스트를 원하는 형태로 가공하지 않은 형태. 전처리를 거쳐야 활용할 수 있다. 수집 기간 : 프로젝트 기간. 기사로 예를 들면 21년 1월부터 10월까지 기사를 모으겠다 등 수집 장소 : 어디에 있는 데이터를? 어디에 저장할 것인가? 원시 데이...
6.(6강) 데이터 구축 작업 설계
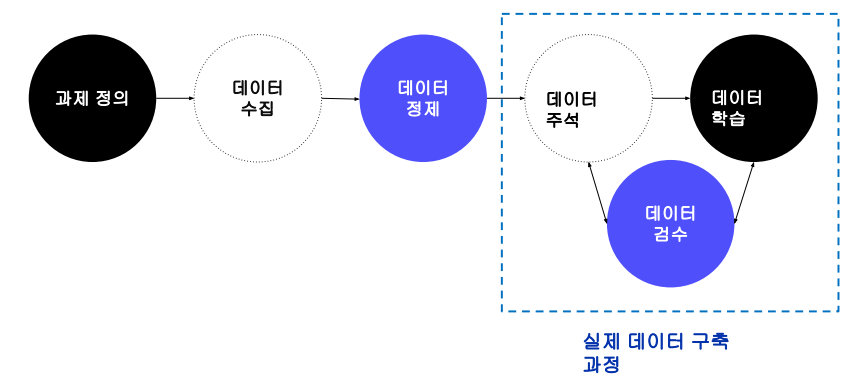
1. 데이터 구축 프로세스 매우 클래식한 단계이다. 마마라는 작업. 예시 1차 구축, 2차 구축을 하지 않을 수도 있고 1차와 2차의 성질이 아예 다를 수도 있다. ![]
7.(7강) 데이터 구축 가이드라인 작성 기초
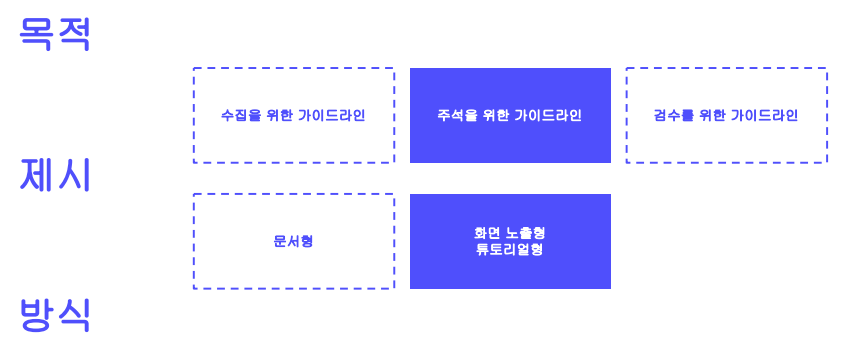
1. 가이드라인의 유형 이렇게 공들여서 가이드라인을 구성하면 좋긴한데, 보통 이만큼 하지 않기도 한다. 2. 가이드라인의 구성 요소 작업의 의도를 잘 모르고 결과를 내는 날것이 더 효과적일 때도 있다. 보통은 작업의 의도를 잘 알려주고 데이터를 주석한다. 최대한 다양한 단어를 사용하는 것이 좋다. 라는 목적을 알고있으면 좀 더 좋은 품질의 데이터를 ...
8.(8강) 관계 추출 과제의 이해
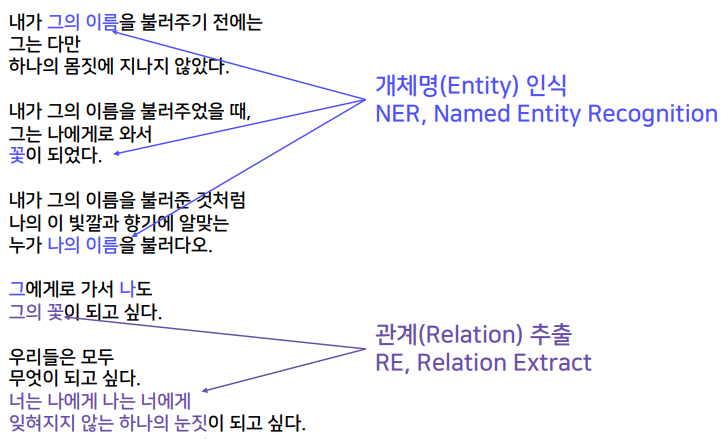
1. 관계 추출 관련 과제의 개요 실제 태스크는 좀 더 복잡하고 두껍다. 관계 추출 관련 과제의 이해 외국은 PLO의 간단한 타입으로 분류하지만, 우리나라는 좀 더 체계화 된 지식을 모델이 습득하기 위해 여러가지 타입을 정의했다. 대분류는 20가지, 소분류는 100가지 이상이라고 한다.  관계 추출 데이터 구축 실습

1. 과제 정의 구어에 대해서는 관계 추출이 잘 이루어지지 않기 때문에 잘 행하지는 않는다. ![](https://images.velog.io/images/sangmandu/post