1. 더 알아보기
좋은 데이터를 만들기 위해서는 사람들이 앞서서 어떤 데이터를 만들었는지 찾아보고 좋은점을 본받아야 된다.
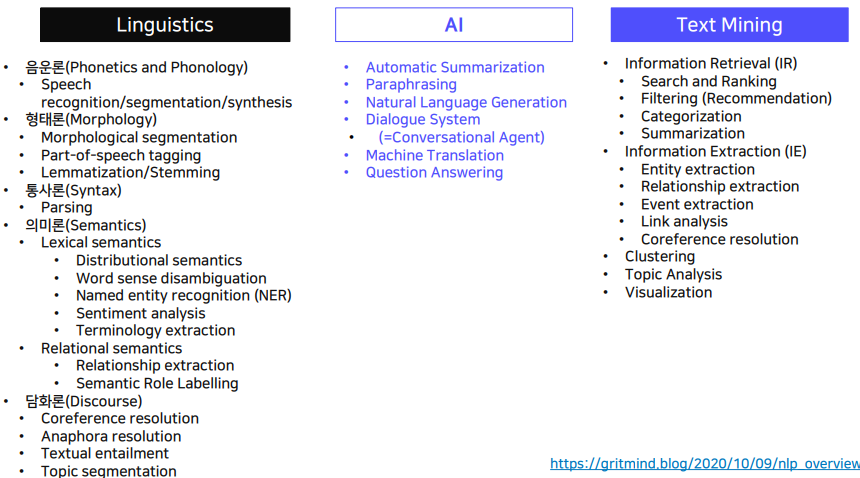
이런 과제들이 자연어 처리에서 다루어지는데, 이들에 대해 세부적으로 모든 것을 알고있는 사람은 없다. 대부분은 몇가지 태스크들에 대해서만 세부적으로만 알고 깊게 경험을 가지고 있다. 그러니 모두를 다 깊게 알 필요는 없지만, 전반적으로 이들을 알고 있다면 다른 태스크들을 응용하거나 벤치마크를 사용할 수 있으므로 알고 있으면 좋다.
자연어 처리에는 언어학, 인공지능, 텍스트 마이닝에서 관심을 가진다. 각각의 목적이 다 다른데, 언어학은 "언어를 분석하고 연구하는데에 전산화 된 데이터를 사용하자" 라는 목적을 가진다. 기존 언어학에는 언어학자에 의해서 옳고 그름을 판단되었다면 말뭉치 언어학에서는 실제 데이터에서 드러난 언어 현상을 분석하고 파악해서 정의를 내린다.
최신 자연어처리 데이터를 찾는 법
- http://nlpprogress.com/
- https://paperswithcode.com/search?q_meta=&q_type=&q=lexical+semantic
- https://aclweb.org/aclwiki/Main_Page
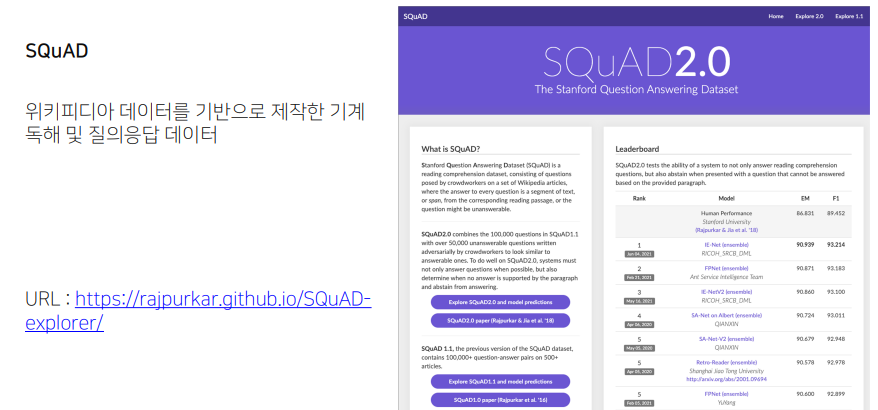
2. 질의응답 Question Answering





3. 기계 번역 Machine Translation

4. 요약 Text Summarization

기사에서 뽑은 데이터셋. 추출은 텍스트 속에서 찾아내는 것이며 추상은 generate 하는 것.
개인정보 이슈 때문에 중간중간 단어들은 @entity 로 대체되었음
5. 대화 Dialogue

기계 번역과 양대산맥인 분야

깊게 배우고 신박하게 개발할래