1. 국내 언어 데이터의 구축 프로젝트

대학교 자체에서 만든 말뭉치들도 있었지만, 국가적으로 10년 계획을 가지고 수행한 프로젝트가 21세기 세종 계획이다.
-
국어학자와 언어학자의 의견이 많이 반영됐다.
엑소브레인 프로젝트는 인공지능을 개발하기 위해 수행하는 프로젝트이다. 현재 진행중인 프로젝트이고 많은 언어 자원이 있다.
2016년 알파고 이후에 많은 말뭉치 데이터셋을 제작하려고 했다.
2. 21세기 세종 계획과 모두의 말뭉치

학습, 검증, 평가용 데이터가 나누어져 있지 않아서 사용자가 직접 나누어 사용해야한다.
21세기 세종 계획은 언어학적으로 엄밀한 주석이 많고 모두의 말뭉치는 원시 언어 자료가 많다.

문어가 90%, 구어가 10%이다.
이 당시만 해도 "Pretrained" 이라는 개념이 없었기 때문에, 텍스트에 대해 다양한 레이블을 가지고 특징을 학습시키려는 시도가 있었다. 그래서 이렇게 다양하게 말뭉치를 구성한 것

문어는 문장단위로 끊어져 있는 것을 알 수 있다.

구어의 음성적인 특성을 최대한 살리려고 했다.
웃음소리 또한 표현해놓은 것을 알 수 있다.
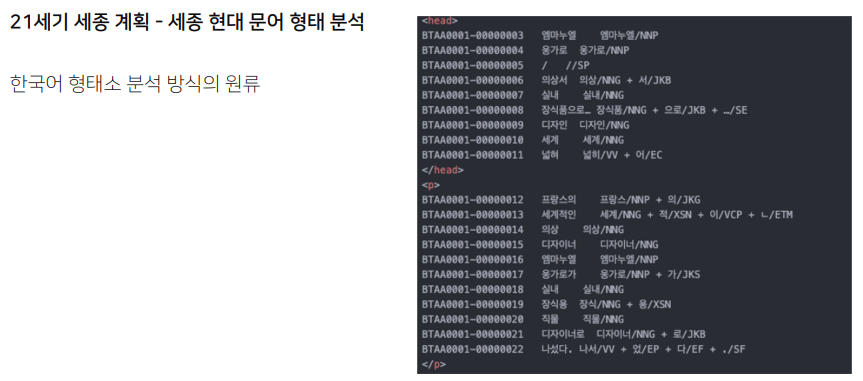
단어 뒤에 슬래시가 오고 형태사 종류를 나타내는 태그가 온다.

어미, 접두사, 접미사, 어기는 품사나 단어는 아니다. 이들은 앞 단어에 붙여서 쓴다. 또, 격조사, 보조사, 접속조사도 마찬가지로 앞 단어에 붙여서 쓴다.
주제어를 뽑을 때는 단순히 명사라고 해서 N* 을 뽑는게 아니다. 대명사 수사도 제외하고 의존명사도 제외한 NNG와 NNP를 가지고 뽑아야 한다. 이러한 지식이 있어야 데이터를 잘 정제할 수 있다.

자연어 처리에서는 구조 분석보다는 의존 분석이 편하기 때문에 잘 쓰지 않는다. 엑소브레인에서도 의존 분석을 사용한다.
왼쪽 아래에 영어, 전자는 구조 분석 후자는 의존 분석
3. 엑소브레인



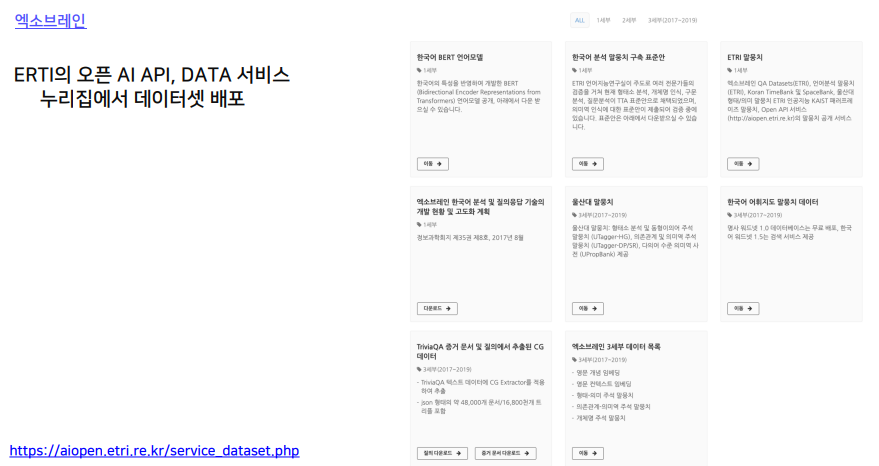
국어원의 말뭉치들이 에트리에서 연장된다.
보통 NER 과제에서는 PLO(Person, Location, Organization)를 주로 매칭한다. 여기에 숫자나 사건등을 더하는 식. 근데 한국 ner은 태그가 매우 많다. 적어도 20개 많으면 100개정도. 장학퀴즈에서 우승을 목표로 하다보니 QA를 위해 자세하게 NER을 함.
4. AI허브
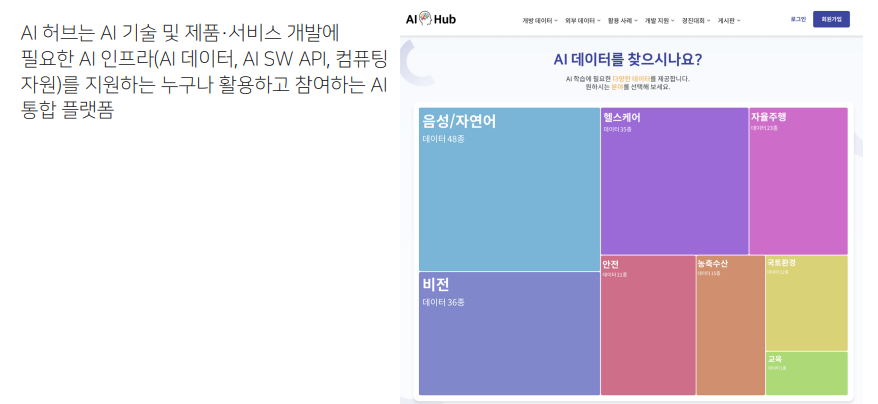
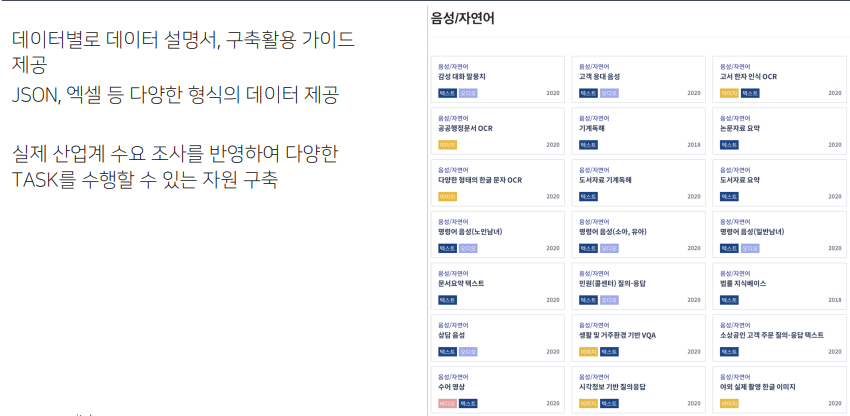
국어원은 담당자가 승인을 해야해서 시간이 좀 걸리는데 AI허브는 신청만 하면 바로 사용이 가능하다.
5. 민간 주도 데이터셋
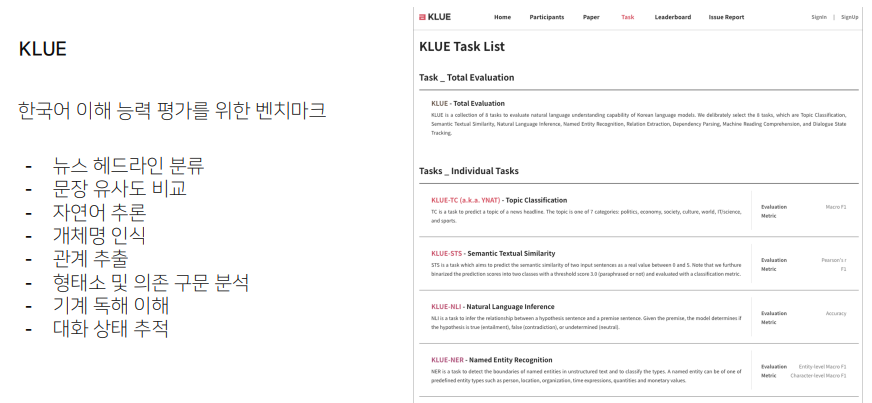
순수하게 한국어로 된 원시 말뭉치를 가공해서 각각의 데이터를 만들었다는 것이 특별한 점이다.

민간 주도로 나온, 가장 유명해진 데이터셋이다.
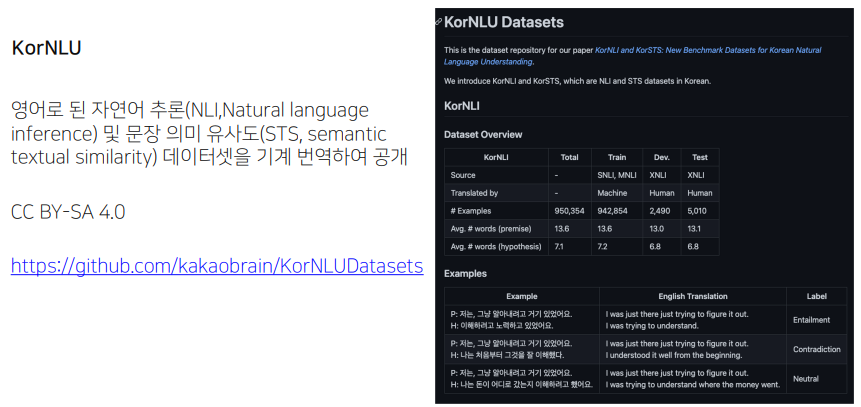
단순히 기계번역과 검수로만 이루어진 데이터셋이 문제가 약간 있다.
