1. Introduction to Dense Embedding
Passage Embedding

목표는 어떠한 Passage를 벡터화 하는 것이며 이 중 우리는 Sparse Embedding을 사용했다.
Sparse Embedding
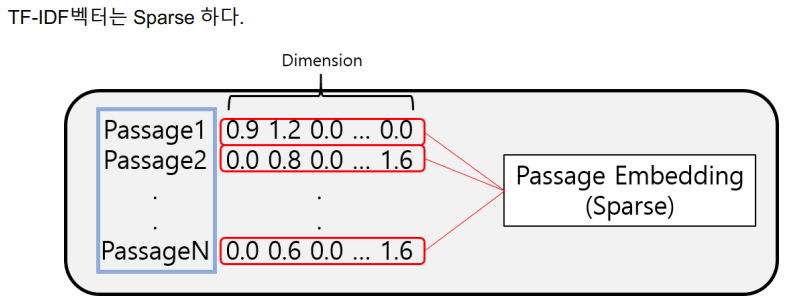
Bag of Words론을 택하기 때문에 특정 단어에 해당하는 벡터의 차원만이 non-zero가 된다. 사실상 90% 이상이 zero인 sparse matrix가 된다.
Limitations of sparse embedding
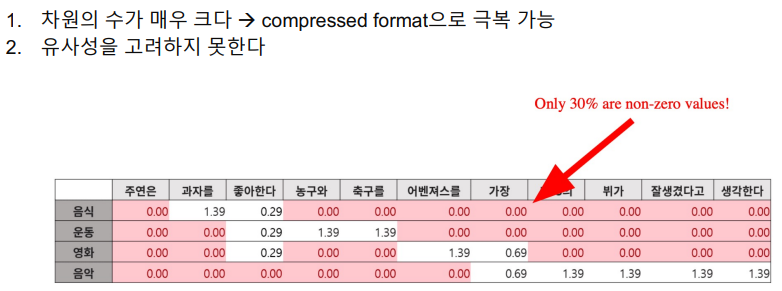
non-zero의 위치와 값만 저장하는 방식을 채택하면 벡터 전체를 저장하지 않더라도 상당히 효율적으로 저장할 수 있다. 그러나 sparse embedding의 가장 큰 문제점은 유사성을 쉽게 고려하지 못한다는 것이다. 어떤 두 단어가 아주 비슷한 의미를 가진다고 할지라도 두 텍스트가 언어적으로 다르게 구성되어 있다면 vector space에서는 완전 다른 차원을 차지하는 형태로 구성되며, 따라서 이 vector space에서는 두 단어의 유사성을 전혀 고려할 수가 없는 형태가 된다. 이 점이 sparse embedding의 제일 큰 단점이다.
Dense Embedding 이란?
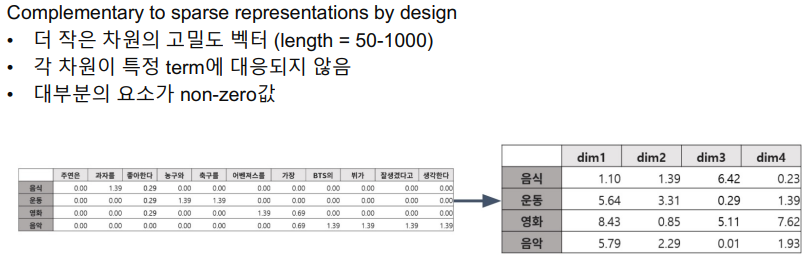
이러한 단점 때문에 Dense Embedding을 많이 쓰고 있다. 일반적인 Sparse representation에 많은 단점을 보완한 방법이다.
각 차원이 특정 term에 대응되지 않기 때문에 이 차원이 모두 합쳐져서 vector space상에서의 위치가 의미를 나타내도록 복합적인, 부분적인 의미를 가지게 된다. 그래서, non-zero인 값이 많고 상당히 compact하다.
Retrieval: Sparse vs Dense

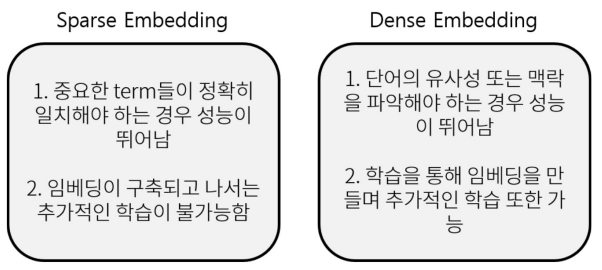
Sparse의 경우 단어의 존재 유무를 파악하기는 매우 좋아서 Retrieve할 때 강점을 가지지만, 의미적으로 파악하기는 쉽지가 않다. 반면 Dense는 단어가 다르게 표현되었더라도 의미가 같다면 이 둘을 detect 할 수 있는 방법론을 쓴다.
또, Sparse의 경우 차원이 Dense에 비해 매우 크기 때문에 활용할 수 있는 알고리즘이 적어지지만, Dense는 많은 알고리즘을 활용할 수 있다.
그렇지만, Sparse Embedding의 장점도 뚜렷이 있기 때문에 Retrieve를 구축할 때는 두 임베딩을 같이 사용하거나, Dense만을 가지고 구축하는 것이 추천된다.
특히, 사전학습 모델의 등장으로 인해 Dense Embedding을 학습하는 것이 용이해졌고, 훨씬 높은 수준으로 학습하는 것이 가능해졌다. 그래서 최근의 Retrieve accuracy도 많이 증가했다. 반면, Sparse 임베딩은 NN을 이용한 학습이 아니라 엔지니어적인 구현이 많이 있기 때문에 이러한 혜택을 받을 수 없었다.
Overview of Passage Retrieval with Dense Embedding

질문 q에 대해 버트 모델에 입력시켜 얻은 CLS 토큰에 해당하는 벡터 를 얻는다. Passage 역시 동일한 방법, 다른 파라미터를 이용한 버트를 통해 라는 벡터를 얻는다. 중요한 점은 두 개의 벡터의 크기가 동일해야 한다는 것이다. 이후 유사도를 측정하기 위해 내적을 한다. 이렇게 하나의 질문에 대한 하나의 지문의 유사도를 측정한 것이고, 모든 지문에 대해 이 유사도를 측정해 가장 높은 유사도를 가진 지문을 MRC에서 활용할 수 있다.
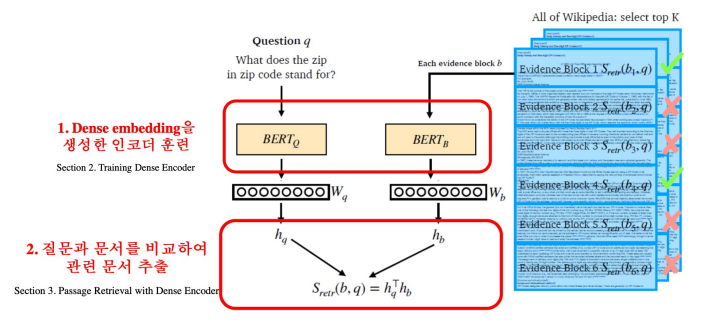
실제로 여기서 훈련을 해야하는 대상은 버트이며, 이 버트는 질문과 지문이 서로 다른 파라미터의 버트를 사용한다. 모델 구조는 동일하며 같은 인코더를 쓰는 경우도 있다.
2. Training Dense Encoder
What can be Dense Encoder?
현재는 버트만 이야기를 하고 있지만, 흔히 말하는 PLM, Pretrained Language Model에 속하는 많은 모델을 사용할 수 있다. Retrieve에서 버트를 사용하는 방식은 MRC와 조금 유사하다. 차이점은 MRC는 Passage와 Question을 둘 다 입력으로 넣어주지만 Retrieve에서는 Passage와 Question을 각각 넣어주고 각각 임베딩을 하기 때문에 독립적으로 넣어주게 된다.
또한, MRC는 Passage내에 답변이 어디있는 가를 추측하기 위해 각 token 별로 score를 내는것이 목적이었다면 Retrieve에서는 embedding을 output 하는것이 목적이기 때문에 CLS토큰을 보면서 최종 임베딩이 무엇인지 보고 이를 통해 Passage를 Encoding 하게 된다. Question도 동일한 방법을 적용하게 된다. 파라미터를 같게 할지 다르게 할지는 design-choice적인 부분을 실험적으로 결정하는 것을 추천한다.
Dense Encoder 구조
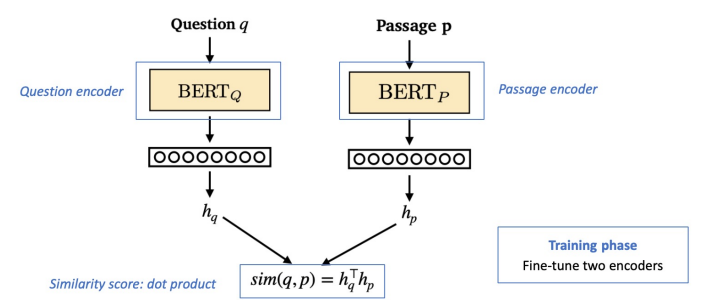
이후 얻은 두 인코딩 벡터를 내적한다. 학습시에는 버트를 fine tuning하며 실제로 정답이었던 경우 유사도 점수가 더 높도록 학습하며 오답이었을 경우 유사도 점수가 음수에 가깝도록 학습해서 최종적으로 모델을 완성하게 된다.
Dense Encoder 학습 목표와 학습 데이터
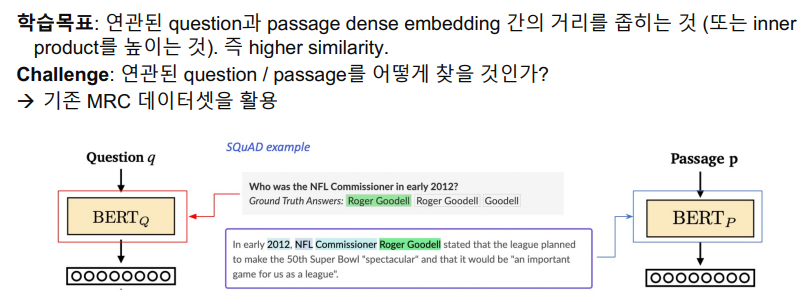
기존 MRC 데이터셋을 활용하게 되면, 질문과 지문의 정답쌍으로 간주할 수 있으며 그 외의 Passage들은 관련이 없는 Passage로 판단할 수 있다.
Dense Encoder 학습 목표와 학습 데이터 – Negative Sampling

두 가지 방법으로 학습을 진행할 수 있다.

Negative를 뽑을 때는 어떻게 뽑아야 할까? 위와 같은 두 가지 방법이 있다. 최근 work에서는 2번 방법을 고르는 것이 더 좋다.
Objective function
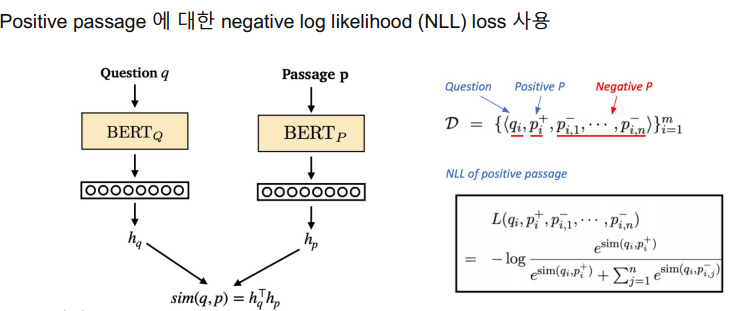
Positive passage의 score를 확률로 표현하기 위해 Positive pair와 Negative Passage를 가져와서 Softmax를 거친 뒤 NLL을 적용한다.
자세하게 이 값은 분자에는 Positive값만 있으며 분모에는 Positive와 Negative의 값의 합이 있고 이에 대해 -log를 취한 값이 NLL이다.
- 여기서 값은 이미 softmax를 거친 값을 의미한다.
Evaluation Metric for Dense Encoder
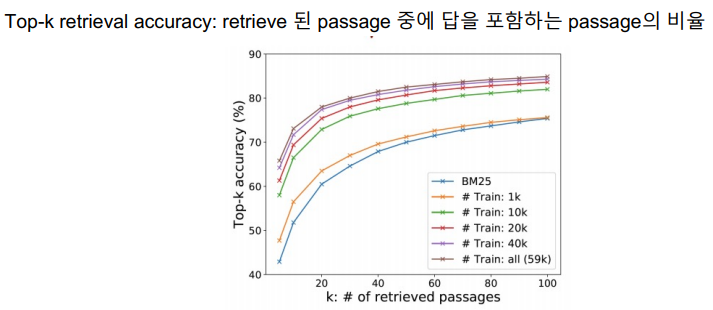
Retrieve의 성능 측정 방법은 1) Ground Truth Passage를 알고 있기 때문에 Retrieve된 Passage 중에서 GTP가 있는지를 확인하는 방법이 있고 2) 좀 더 나아가서 MRC와 관련이 있는 Metric으로 답을 포함하는 Passage 비율을 볼 수 있다. 여기서 답이라 함은 최종 MRC의 답을 나타낸다. 다른 말로는, Extracted한 MRC가 Passage내에 답이 없다면 절대 답을 낼 수 없기 때문에 Upper bound라고 볼 수 있다.
- Upper Bound란 원하는 값 k를 초과한 값이 처음 나오는 위치를 찾는 과정이다.
3. Passage Retrieval with Dense Encoder
From dense encoding to retrieval

인코딩 이후 Retrieval 하는 과정은 매우 간단하다. Corpus에 대한 임베딩은 사전에 미리 구해놓아 오프라인에서 저장해 놓는다. 이후, Question이 들어올 때 마다 임베딩을 구한 뒤 사전에 미리 구축한 Passage 임베딩과의 거리를 재고 가장 유사도가 높은 Passage를 반환하는 방식으로 이루어진다.
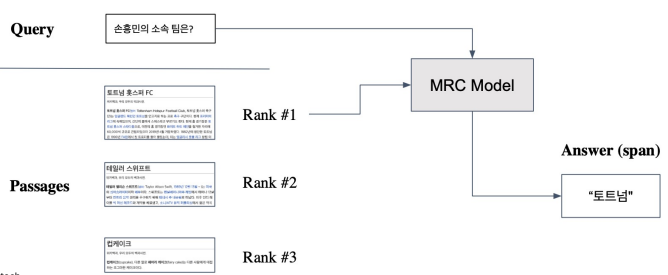
최종적으로 이를 MRC에 넘겨줌으로써 연결할 수 있다. 만약 좋은 Retrieve 모델과 좋은 MRC 모델이 있다면 질문 하나만으로도 좋은 답변을 줄 수 있게된다.
How to make better dense encoding

MRC의 성능 개선도 매우 중요하고 Retrieve의 성능 개선도 매우 중요하다.
실습
Requirements
!pip install datasets -q
!pip install transformers -q데이터셋 로딩
from datasets import load_dataset
dataset = load_dataset("squad_kor_v1")
corpus = list(set([example['context'] for example in dataset['train']]))
len(corpus)
>>> 9606토크나이저 준비 - Huggingface 제공 tokenizer 이용
from transformers import AutoTokenizer
import numpy as np
model_checkpoint = "bert-base-multilingual-cased"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
tokenizer
>>> PreTrainedTokenizerFast(name_or_path='bert-base-multilingual-cased', vocab_size=119547, model_max_len=512, is_fast=True, padding_side='right', special_tokens={'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'})- 토크나이저가 잘 불러와진 것을 확인할 수 있다.
print(corpus[0])
tokenized_input = tokenizer(corpus[0], padding="max_length", truncation=True)
tokenizer.decode(tokenized_input['input_ids'])제정 초기는 정부는 공화정의 형태를 가장하였다. 로마 황제는 그저 제1시민(priceps)일 뿐이었으며, 원로원은 과거 민회가 보유하던 입법권과 모든 법적 권한을 가지게 된다. 그러나 시간이 갈수록 황제의 권력은 점차 전제 권력으로 발전했으며, 원로원은 황제가 임명하는 자문 기구로 전락하였다. 로마 제국은 공화정 시대의 행정 체제를 물려받지 않았는데, 공화정에는 원로원 외에 영속적인 행정 기구가 없었기 때문이었다. 아우구스투스는 최고위 행정가와 원로원 의원, 자신의 친구, 전문 법률가 등을 모아 조언을 구하였으며, 원로원 의원, 기사, 피해방인, 심지어 노예까지 각계 각층의 사람들을 공무원으로 기용하여 곡물, 수도, 치안, 법, 재정 등 일종의 행정 조직을 구성하였다.
[CLS] 제정 초기는 정부는 공화정의 형태를 가장하였다. 로마 황제는 그저 제1시민 ( priceps ) 일 뿐이었으며, 원로원은 과거 민회가 보유하던 입법권과 모든 법적 권한을 가지게 된다. 그러나 시간이 갈수록 황제의 권력은 점차 전제 권력으로 발전했으며, 원로원은 황제가 임명하는 자문 기구로 전락하였다. 로마 제국은 공화정 시대의 행정 체제를 물려받지 않았는데, 공화정에는 원로원 외에 영속적인 행정 기구가 없었기 때문이었다. 아우구스투스는 최고위 행정가와 원로원 의원, 자신의 친구, 전문 법률가 등을 모아 조언을 구하였으며, 원로원 의원, 기사, 피해방인, 심지어 노예까지 각계 각층의 사람들을 공무원으로 기용하여 곡물, 수도, 치안, 법, 재정 등 일종의 행정 조직을 구성하였다. [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]Dense encoder (BERT) 학습 시키기
from tqdm import tqdm, trange
import argparse
import random
import torch
import torch.nn.functional as F
from transformers import BertModel, BertPreTrainedModel, AdamW, TrainingArguments, get_linear_schedule_with_warmup
torch.manual_seed(2021)
torch.cuda.manual_seed(2021)
np.random.seed(2021)
random.seed(2021)- tqdm은 progress를 볼 수 있는 utility
- argparse와 random은 python의 utility
- transformers에서 모델과 학습에 용이한 함수들을 가져온다.
- 재현성(=reproducibility)을 위해 seed를 고정한다.
# Use subset (128 example) of original training dataset
sample_idx = np.random.choice(range(len(dataset['train'])), 128)
training_dataset = dataset['train'][sample_idx]
print(len(dataset['train']), len(training_dataset))
>>> 60407 5- 학습데이터를 준비한다. 여기서는 모든 데이터를 쓰지 않고
np.random.choice를 이용해 20개를 샘플링한다.
from torch.utils.data import (DataLoader, RandomSampler, TensorDataset)
q_seqs = tokenizer(training_dataset['question'], padding="max_length", truncation=True, return_tensors='pt')
p_seqs = tokenizer(training_dataset['context'], padding="max_length", truncation=True, return_tensors='pt')- 토크나이저를 설정한다. 지문과 질문에 대한 토크나이저를 각각 만든다.
train_dataset = TensorDataset(p_seqs['input_ids'], p_seqs['attention_mask'], p_seqs['token_type_ids'],
q_seqs['input_ids'], q_seqs['attention_mask'], q_seqs['token_type_ids'])- 데이터셋을 학습하기 위해 tensor dataset으로 변경한다. train_dataset은 두 데이터셋을 합쳐주며 학습이 용이하게 진행되도록 한다. 사실상 6개의 벡터들을 학습할 때 편하게 접근할 수 있도록 concat 하는 과정으로 볼 수 있다.
class BertEncoder(BertPreTrainedModel):
def __init__(self, config):
super(BertEncoder, self).__init__(config)
self.bert = BertModel(config)
self.init_weights()
def forward(self, input_ids,
attention_mask=None, token_type_ids=None):
outputs = self.bert(input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids)
pooled_output = outputs[1]
return pooled_output
-
버트를 학습시키기 위해 버트 클래스를 정의한다. 여기서
input_ids는 반드시 필요하며attention_mask와token_type_ids는 필수적인 인자는 아니다. -
우리가 필요한 것은 전체 output이 아니라 CLS 토큰이기 때문에 outputs[1]로
pooled_output으로 선언한 CLS 토큰을 가져온다.
# load pre-trained model on cuda (if available)
p_encoder = BertEncoder.from_pretrained(model_checkpoint)
q_encoder = BertEncoder.from_pretrained(model_checkpoint)
if torch.cuda.is_available():
p_encoder.cuda()
q_encoder.cuda()fine-tuning을 위한 시작점을 지정해준다. 또, GPU를 사용할 것이기 때문에 cuda가 사용가능하면 이를 할당한다.
def train(args, dataset, p_model, q_model):
# Dataloader
train_sampler = RandomSampler(dataset)
train_dataloader = DataLoader(dataset, sampler=train_sampler, batch_size=args.per_device_train_batch_size)
t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total)
# Start training!
global_step = 0
p_model.zero_grad()
q_model.zero_grad()
torch.cuda.empty_cache()
train_iterator = trange(int(args.num_train_epochs), desc="Epoch")
for _ in train_iterator:
epoch_iterator = tqdm(train_dataloader, desc="Iteration")
for step, batch in enumerate(epoch_iterator):
q_encoder.train()
p_encoder.train()
if torch.cuda.is_available():
batch = tuple(t.cuda() for t in batch)
p_inputs = {'input_ids': batch[0],
'attention_mask': batch[1],
'token_type_ids': batch[2]
}
q_inputs = {'input_ids': batch[3],
'attention_mask': batch[4],
'token_type_ids': batch[5]}
p_outputs = p_model(**p_inputs) # (batch_size, emb_dim)
q_outputs = q_model(**q_inputs) # (batch_size, emb_dim)
# Calculate similarity score & loss
sim_scores = torch.matmul(q_outputs, torch.transpose(p_outputs, 0, 1)) # (batch_size, emb_dim) x (emb_dim, batch_size) = (batch_size, batch_size)
# target: position of positive samples = diagonal element
targets = torch.arange(0, args.per_device_train_batch_size).long()
if torch.cuda.is_available():
targets = targets.to('cuda')
sim_scores = F.log_softmax(sim_scores, dim=1)
loss = F.nll_loss(sim_scores, targets)
print(loss)
loss.backward()
optimizer.step()
scheduler.step()
q_model.zero_grad()
p_model.zero_grad()
global_step += 1
torch.cuda.empty_cache()
return p_model, q_model- 데이터로더와 옵티마이저를 설정한다.
t_total은 얼만큼 학습할지에 대한 변수이다.- 학습을 위해
zero_grad()를 수행한다. 이후, 본격적으로 iteration을 실행한다. - iteration에서는 배치만큼 passage output과 question output을 얻게된다. 여기서는 in-batch negative라는 방법을 사용할 것인데, 하나의 example에 있는 question과 passage similiarity score는 최소화 시키면서 다른 example에 있는 passage와의 similiarity score는 최대화 시키는 방식을 택하려고 한다.
- 모든 question은 모든 passage와의 유사도를 측정해야 하며 이를 위해 모든 경우의 수를 따져야 하므로 matmul을 통해 구하게 된다. 그리고 이를 softmax해서 거치게된다.
- loss함수를 정의하며 NLL Loss를 사용해서 Positive는 점수가 높게, Negative는 점수가 낮게 학습한다.
- 모든 학습이 끝나면 두 개의 모델을 return한다.
args = TrainingArguments(
output_dir="dense_retireval",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
num_train_epochs=2,
weight_decay=0.01
p_encoder, q_encoder = train(args, train_dataset, p_encoder, q_encoder)
)
Dense Embedding을 활용하여 passage retrieval 실습해보기
valid_corpus = list(set([example['context'] for example in dataset['validation']]))[:10]
sample_idx = random.choice(range(len(dataset['validation'])))
query = dataset['validation'][sample_idx]['question']
ground_truth = dataset['validation'][sample_idx]['context']
if not ground_truth in valid_corpus:
valid_corpus.append(ground_truth)
print(query)
print(ground_truth, '\n\n')
# valid_corpus
>>> 유아인에게 타고난 배우라고 말한 드라마 밀회의 감독은?
화보 촬영을 위해 미국에 있을 때, 김희애의 연락을 통해 JTBC 드라마 《밀회》의 캐스팅을 제안받았다. 당시 영화 《베테랑》에 이미 캐스팅된 상태였으나, 유아인은 류승완 감독과 제작사의 양해를 얻어 《밀회》에 출연한다. 천재 피아니스트 ‘이선재’ 역할을 위해 피아니스트들의 영상을 보고 곡의 스피드와 건반 위치 등을 외워 실제 타건을 하며 촬영했다. 피아노 울림판을 수건으로 막고 타건을 하면, 그 후 대역 피아니스트의 소리를 덧입히는 방식이었다. 《밀회》는 작품성을 인정받고 숱한 화제를 낳으며 당시 종편으로서는 높은 시청률을 기록했다. 유아인은 섬세한 연기력을 선보여 순수함으로 시청자들을 매료시켰다는 호평을 얻었고, 특히 피아노 연주에 있어서 클래식 종사자들에게 인정을 받았다. 연출을 맡은 안판석 감독은 유아인에 대해 “느낌으로만 연기를 하는 게 아니고 감성을 지적으로 통제해 가면서 연기한다. 그 나이에”라며 “타고난 배우”라고 말했다. 유아인은 《밀회》를 통해 예술적인 면모를 구체화할 수 있어서 만족감을 느꼈다고 밝혔으며, 종영 후 자신의 페이스북 계정에 긴 소감글을 남겼다. 특히 ‘이선재’ 캐릭터를 배우 유아인이 가진 소년성의 엑기스로 생각하며, 2015년 10월 부산국제영화제 오픈토크에서는 본인이 가장 좋아하는 캐릭터로 꼽았다. def to_cuda(batch):
return tuple(t.cuda() for t in batch)
with torch.no_grad():
p_encoder.eval()
q_encoder.eval()
q_seqs_val = tokenizer([query], padding="max_length", truncation=True, return_tensors='pt').to('cuda')
q_emb = q_encoder(**q_seqs_val).to('cpu') #(num_query, emb_dim)
p_embs = []
for p in valid_corpus:
p = tokenizer(p, padding="max_length", truncation=True, return_tensors='pt').to('cuda')
p_emb = p_encoder(**p).to('cpu').numpy()
p_embs.append(p_emb)
p_embs = torch.Tensor(p_embs).squeeze() # (num_passage, emb_dim)
print(p_embs.size(), q_emb.size())
>>> torch.Size([11, 768]) torch.Size([1, 768])11개의 Passage와 1개의 Question에 대한 임베딩이다.
dot_prod_scores = torch.matmul(q_emb, torch.transpose(p_embs, 0, 1))
print(dot_prod_scores.size())
rank = torch.argsort(dot_prod_scores, dim=1, descending=True).squeeze()
print(dot_prod_scores)
print(rank)얻은 임베딩을 가지고 유사도를 구한다.
k = 5
print("[Search query]\n", query, "\n")
print("[Ground truth passage]")
print(ground_truth, "\n")
for i in range(k):
print("Top-%d passage with score %.4f" % (i+1, dot_prod_scores.squeeze()[rank[i]]))
print(valid_corpus[rank[i]])Top-5 Passage를 뽑아 Ground Truth와 비교한다.
