1. Passage Retrieval and Similarity Search
지난 강의 복습
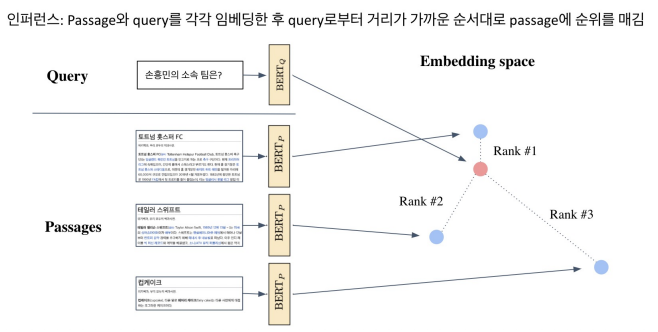
Passage가 많아질수록 아무리 내적이라 할지라도 연산량이 부담될 수 밖에 없으며 6강에서는 어떻게 가장 가까운 Passage를 효율적으로 찾을까에 대해 이야기한다.
MIPS, Maximum Inner Product Search
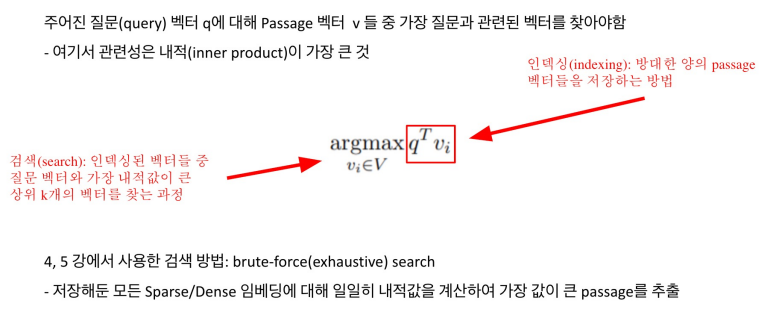
Nearest Neighbor와 같은 L2 Distance를 측정하는 것보다 두 개의 벡터의 dot product중 maximum을 찾는 것이 좀 더 수월하다. 그래서 가장 가까운 두 벡터를 찾는다고 하면 최대 내적 값을 찾는다고 생각하면 된다. 대신, 이 개념을 상상할 때는 유클리드 공간에서 두 점의 거리로 생각하는 것이 이해하기에 좋다.
MIPS in Passage Retrieval
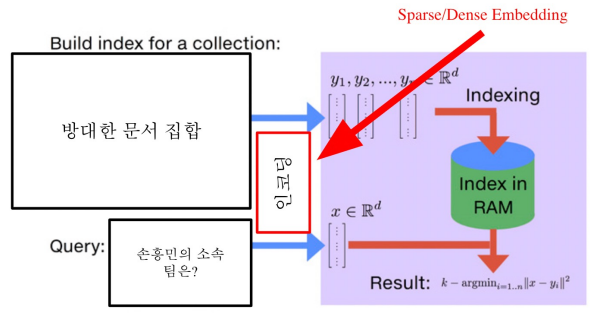
현재는 다음과 같이 질문이 들어올 때 마다 실시간으로 Passage의 벡터들과 비교하는 방법을 사용한다.
MIPS & Challenges
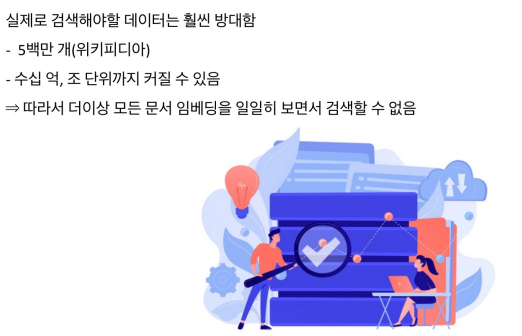
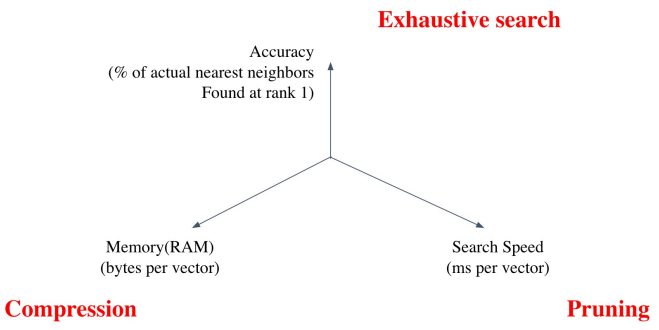
Tradeoffs of similarity search

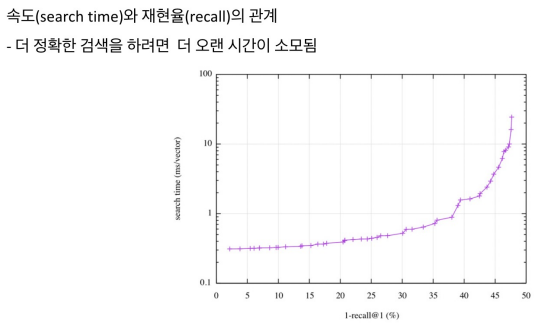
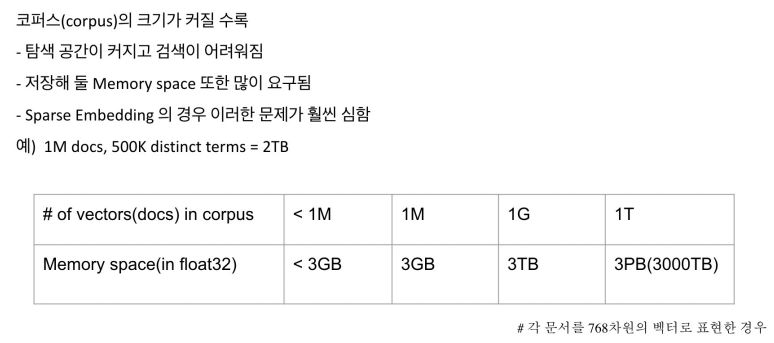
Increasing search space by bigger corpus
아무런 압축이 없다고 가정한다.
2. Approximating Similarity Search
Compression - Scalar Quantization, SQ
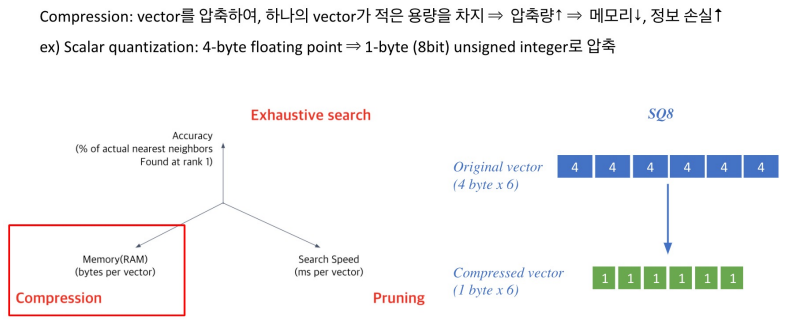
보통 숫자를 저장할 때는 float32라는 4바이트 체계를 활용하는데, 실제 inner product를 진행할 때는 이만큼 필요하지 않다. 1바이트로 근사를 한다음에 저장하더라도 상당히 정확한 경우가 많다.
Pruning - Inverted File, IVF
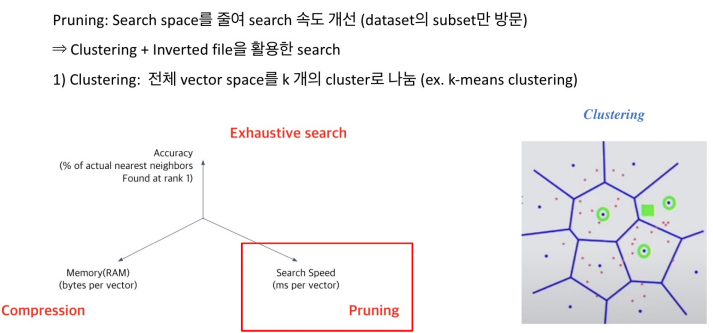
점들을 정해진 Cluster로 소속시켜서 군집을 일으키는 형태를 말한다. 군집이 있을 때 쿼리가 입력되면 모든 점들과 비교하는 것이 아니라 붙어있는 군집의 점과만 비교를 한다. 그림에서는 한 점에 대해서 이웃하고 있는 3개의 군집의 모든 점과 Exhaustive Search로 모두 비교를 한다.
보통 클러스터에서 가장 많이 활용되는 방법은 k-means clustering이다. 이러한 방법으로 cluster를 정의하고 각각의 포인트를 군집에 속하게 한 뒤 질문이 들어오면 가장 가까운 클러스터만 비교함으로써 속도를 비약적으로 늘릴 수 있다.
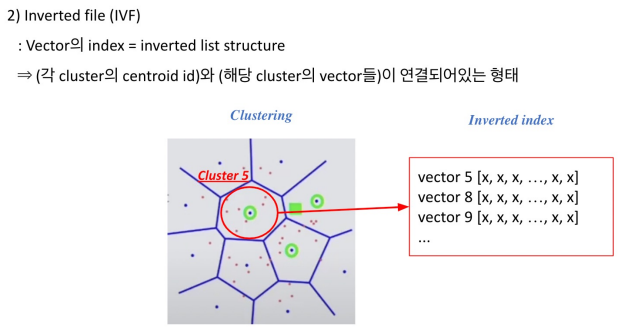
각 클러스트에 속해있는 포인트들을 역으로 인덱스로 가지고 있기 때문에 Inverted list structure라고 부른다.
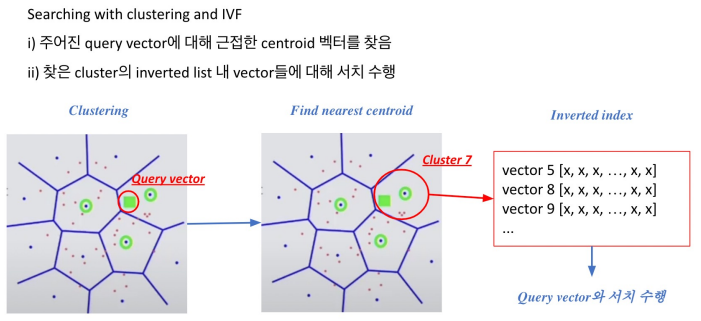
클러스터를 찾은다음에 클러스터에 속해있는 벡터들을 빠르게 확보 가능함으로써 search space를 비약적으로 빠르게 줄일 수 있다.
3. Introduction to FAISS
우리가 주로 사용할 라이브러리이며, Facebook에서 만든, multi-train할 수 있는 라이브러리이며 fast-approximation을 위한 모든 것이 오픈소스로 공개되어있다. 사용하기도 편하고 Large-scale에 특화되어 있어서 scale-up할 때 유용하다. backbone은 c++로 되어있지만 mapping은 python으로 되어있어서 python만 사용하더라도 쉽게 활용할 수 있다.
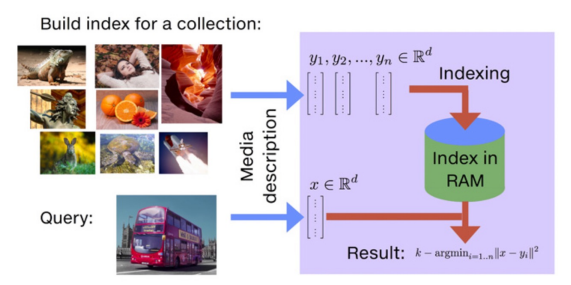
인덱싱쪽을 도와주며 인코딩쪽에 도움을 주는 부분은 아니다.
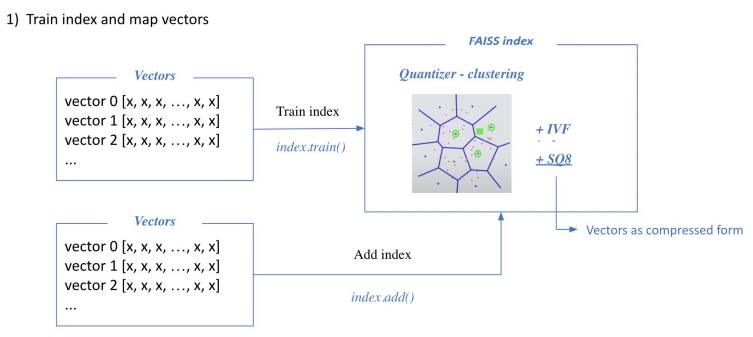
벡터들을 확보하게 되면 이 벡터들을 가지고 학습을 한다. faiss를 활용하려면 cluster들을 확보해야 하며, 랜덤하게 cluster를 지정하면 매우 비효율적이므로 data point의 분포를 보고 cluster를 지정해야한다. 이를 위해 학습 데이터가 필요하며, float32를 int8로 바꿔주는 sqale quantization 하는 과정에서도 float의 max와 min을 파악할 필요가 있기 때문에 학습단게가 필요하다.
다만, 이 때 학습에 사용하는 데이터와 ADD 하는 데이터를 따로 구분짓지는 않는다. 만약 다르게 한다면, 더할 데이터가 너무 많아서 전부를 학습하기는 비효율적일 때 ADD할 데이터의 일부만을 샘플해서 학습 데이터로 사용한다.
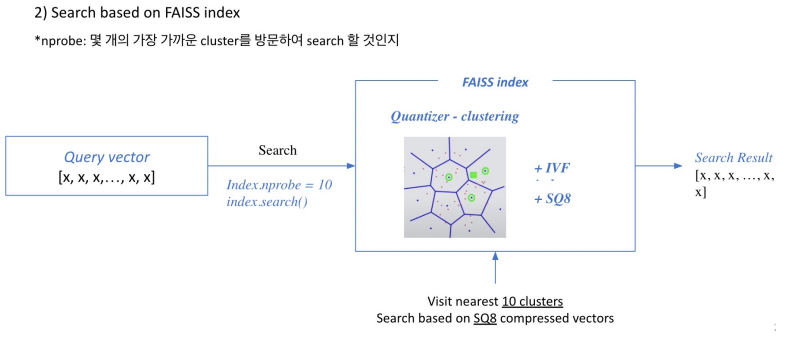
인퍼런스 시에는 쿼리가 들어오면 검색을 통해 가장 가까운 클러스터들을 방문하게 되고 클러스터 내에 모든 벡터와 비교해 top-k를 뽑게된다.
4. Scaling up with FAISS
FAISS Basics

학습을 따로 하지 않는데, 왜 그러냐면 pruning과 scale qunatization을 사용하지 않기 때문이다. 이를 활용할 때만 학습을 진행한다.
IVF with FAISS

클러스터 끼리의 거리를 재는 방식은 L2 방식을 사용한다. 학습할 때는 일부만을 가지고 학습한다. 모두 학습하면 오래걸리므로, 단 ADD할 때는 학습을 했든지 안했든지 상관없이 한다.
IVF-PQ with FAISS
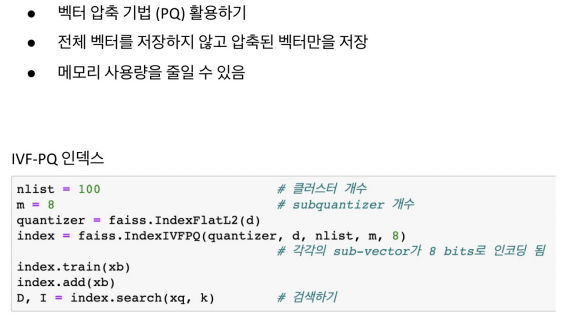
SQ보다 좀 더 압축량을 높일 수 있는 PQ 방법이 있다. SQ는 4바이트를 1바이트로 줄였다면(4배 압축), PQ는 20배정도는 더 줄인다.
Using GPU with FAISS

FAISS의 연산 속도를 높이기 위해 GPU를 사용할 수 있다. 속도가 매우 증가하지만, 몇개의 알고리즘만GPU 위에서 사용 가능하다.
Using Multiple GPUs with FAISS
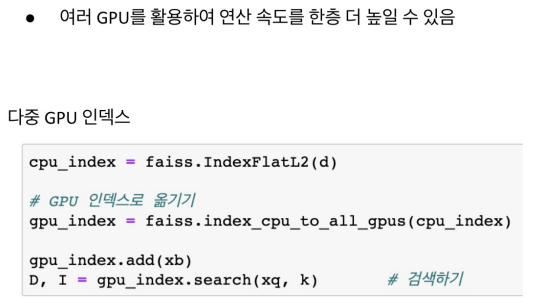
멀티 GPU를 사용할 수도 있지만 잘 사용하지는 않을 것임.
