1. Introduction to Open-domain Question Answering (ODQA)
Linking MRC and Retrieval: Open-domain Question Answering (ODQA)
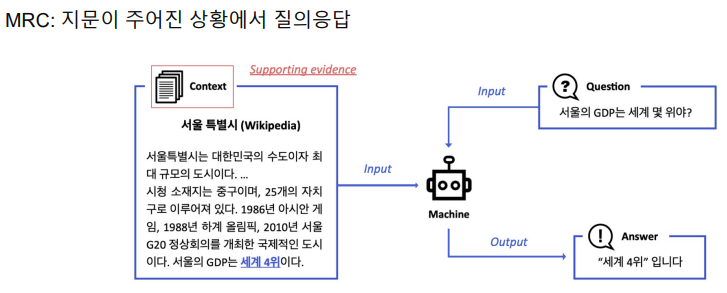
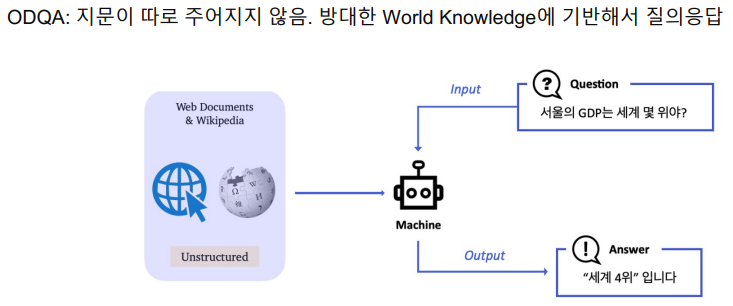
- input과 output은 비슷하다. 단지 지문을 참고해야 하는 수가 다르다. ODQA는 엄청난 양의 passage를 read해야한다.
- 최근에 구글 등의 검색 엔진 사이트는 검색어에 대한 연관문서 뿐만 아니라 질문의 답을 같이 제공한다.
History of ODQA
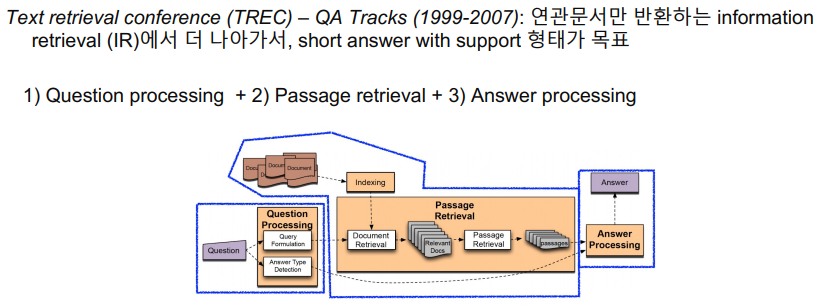
- 이는 예전에도 한번 다뤄졌던 주제이다. 3개의 주제로 공개했 최근의 접근법과 크게 다르지는 않았다.
- 당시에는 Advanced한 방법이 없었기 때문에 지문으로부터 keyword를 선택해서 answer type으로 선택하는 방식이 유일했다.

- 예를 들어, 이 질문에 대한 답은 "장소" 여야한다. 또는 "장소" 중에서도 "나라" 여야한다. 등을 rule-based 또는 keyword로 정의해주었다.

- 2번과 같은 경우 TF-IDF나 BM25같은 방법론을 아직도 사용하고 있다.
- 3번은 feature들과 heristic을 활용해서 classifier를 만들었고 주어진 question이 어떤 passage와 관련되있을지 판단한다.
- 최근 MRC의 경우 단순히 지문뿐만 아니라 지문 내에 어떤 범위내에 답이 있을지를 알아내야 하므로 더 진화했다고 볼 수 있으며, 이는 당시에 span 레벨로 답을 낼 수 있는 기술력이 없었기 때문이다. 또, 기술의 발전으로 유저의 니즈가 더 구체화되었기 때문이기도 하다.
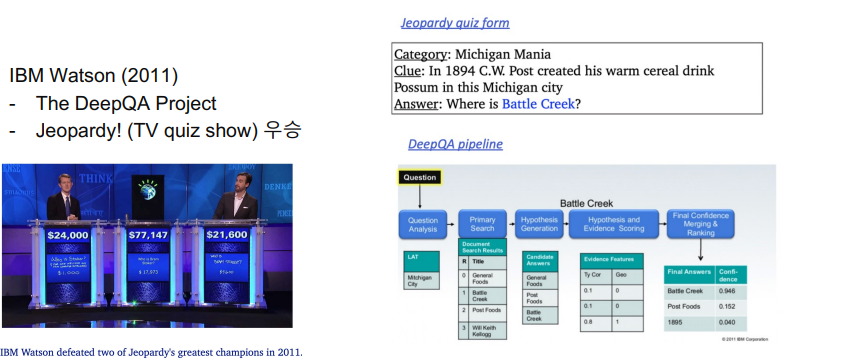
- IBM에서 만든 Watson이라는 AI가 TV quiz show에서 우승하면서 주목이되었다.
- 실제 방법론은 이전에 했던 방법과 크게 다르지 않았다. 여러가지 feature들과 이 feature들을 위해 쌓아올린 SVM같은 초기 머신러닝 테크닉을 적용했다.
- 이 이후로 딥러닝의 큰 발전으로 패러다임이 바뀌게 되면서 NLP의 패러다임 쉬프트가 발생한다.
Recent ODQA Research
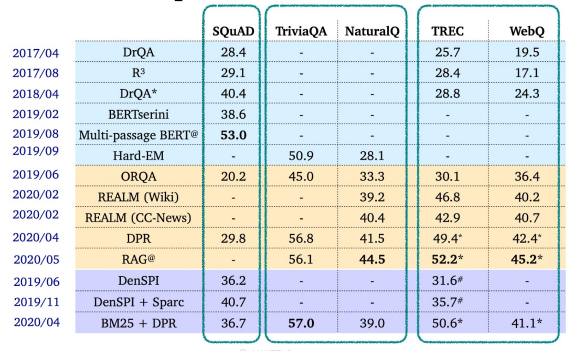
- 17년부터 본격적인 발전이 시작되었다.
2. Retriever-Reader Approach
Retriever-Reader 접근 방식


- 두 방법을 연결하면 되기 때문에 간단한 접근 방식이다.
학습 단계

Distant supervision

- 학습을 할 때, 데이터를 추가하고 싶다면 Distant supervision을 활용할 수 있다.
- MRC의 경우 질문과 답변이 주어지고, 지문에서 얻은 답변과 비교해 학습을 하는 방식이지만, 일반적인 경우 답변이 어느 지문에 주어지는지 알 수 없기 때문에 직접 찾아야한다.
- 위키피디아에 우선 질문을 가지고 지문을 찾아낸다. 이 때 위 조건을 가지고 찾는다.
- 위 조건을 가지고 filtering을 했다고 하더라도 해당 지문이 질문에 대한 답변을 줄 수 없을지도 모른다. 그렇지만, 우리는 이렇게 필터링 함으로써 그 가능성을 높였기 때문에 찾으리라 가정하고 이를 수행한다.

- 이를 활용해서, question-answer-passage pair를 많이 만들 수 있고 또 없는 경우(question-answer pair만 존재하더라도) 위키피디아에서 passage를 가지고 올 수 있게된다.
Inference

- 이 5개는 늘릴수도 줄일수도 있다.
3. Issues and Recent Approaches
Different granularities of text at indexing time
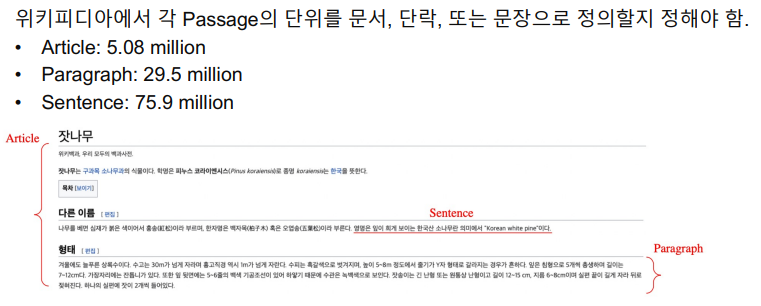
- 위키피디아에는 문서단위로는 5백만개, 문단 단위로는 3천만개, 문장 단위로는 7.5천만개가 존재한다.
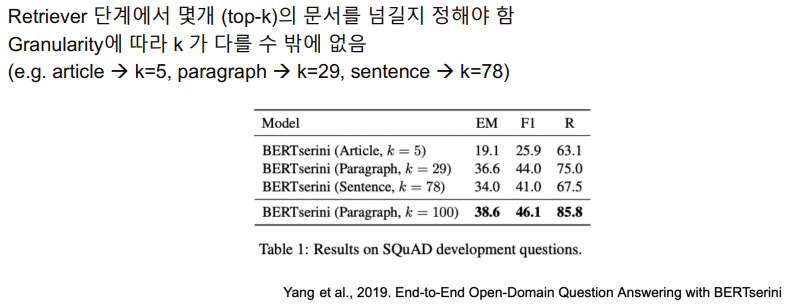
- 이러한 비율에 따라 몇개의 Passage를 넘겨야 할지 고려해야한다. 꼭 비율에 따를 필요는 없지만, 일반적으로 비율에 따라 이를 가져오게된다.
- k를 늘리면 늘릴수록 성능이 올라갈 것 같지만 꼭 그렇지만은 않다.
Single-passage training vs Multi-passage training

- 이는 직접적인 비교가 아닌 간접적인 비교로 볼 수 있다. 그래서 전체적으로 보는 맥락이 필요.
- 단점은 메모리 리소스와 연산량이 많이 필요. 모델을 튜닝할 때 많은 고민을 해야한다.
Importance of each passage
리더 입장에서는 top-k passage를 받는 것이지 점수를 고려한 것은 아닌데, 최종 결과에 top-k score를 합연산으로 더해서 고려하면 성능이 잘 나오는 경우도 있다.
실습
Requirements
!pip install datasets==1.4.1 > /dev/null 2>&1 # execute command in silence
!pip install transformers==4.4.1 > /dev/null 2>&1
!pip install tqdm==4.41.1 > /dev/null 2>&1import random
import numpy as np
from pprint import pprint
from datasets import load_dataset, load_metric
from sklearn.feature_extraction.text import TfidfVectorizer- pprint는 print를 이쁘게 하기 위한 utility이다.
- TF-IDF를 수행하기 위해 sklearn에서 이를 불러온다.
데이터 및 평가지표 불러오기
dataset = load_dataset("squad_kor_v1")
# metric = load_metric('squad')Sparse Retriever 가져오기
corpus = list(set([example['context'] for example in dataset['train']]))
corpus.extend(list(set([example['context'] for example in dataset['validation']])))
tokenizer_func = lambda x: x.split(' ')
vectorizer = TfidfVectorizer(tokenizer=tokenizer_func, ngram_range=(1,2))
sp_matrix = vectorizer.fit_transform(corpus)- train dataset에서 context를 가져오면서 corpus를 구성하고 validation dataset과 합쳐서 tokenize한다.
- vectorizer는 unigram과 bigram만 사용한다. 이후, 이에 대해 fit_transform하고 corpus에 대한 모든 sparse matrix를 생성한다.
corpus = list(set([example['context'] for example in dataset['train']]))
corpus.extend(list(set([example['context'] for example in dataset['validation']])))
tokenizer_func = lambda x: x.split(' ')
vectorizer = TfidfVectorizer(tokenizer=tokenizer_func, ngram_range=(1,2))
sp_matrix = vectorizer.fit_transform(corpus)- 질문을 던졌지만 데이터셋에 질문에 대한 vocab이 없기 때문에 이 때는 assert로 에러를 발생시킨다.
- result는 모든 질문에 대해 TF-IDF를 구한값이며 이를 sort해서 score와 ids를 반환한다.
테스트
""" 1. 정답이 있는 데이터셋으로 검색해보기 """
# random.seed(1)
# sample_idx = random.choice(range(len(dataset['train'])))
# query = dataset['train'][sample_idx]['question']
# ground_truth = dataset['train'][sample_idx]['context']
# answer = dataset['train'][sample_idx]['answers']
""" 2. 원하는 질문을 입력해보기 """
query = input("Enter any question: ") # "미국의 대통령은 누구인가?"
# query = "미국의 대통령은 누구인가?"
_, doc_id = get_relevant_doc(vectorizer, query, k=1)
""" 결과 확인 """
print("{} {} {}".format('*'*20, 'Result','*'*20))
print("[Search query]\n", query, "\n")
print(f"[Relevant Doc ID(Top 1 passage)]: {doc_id.item()}")
print(corpus[doc_id.item()])
# print(answer)Enter any question: 에이핑크의 리더는 누구인가
******************** Result ********************
[Search query]
에이핑크의 리더는 누구인가
[Relevant Doc ID(Top 1 passage)]: 446
오바마는 어린 시절에 대하여 "아버지는 내 주변 사람들과 전혀 다르게 생겼다는 점 - 아버지는 피치처럼 시꺼멓고, 어머니는 우유처럼 하얗다 - 을 나는 개의치 않았다"라고 회상하였다. 그는 그의 투쟁을 자신의 다민족 혈통과 사회적 인식을 화해시키기 위한 어린 성년이라고 말하였다. 오바마는 호놀룰루에서 지낸 자신의 성장기를 반추하며, "하와이에서 얻는 기회 - 상호 존중의 분위기 속에서 다양한 문화를 경험한 것 - 는 내 세계관에서 중요한 부분이 되었으며, 내가 가장 아끼는 가치의 근간이 되었다"라고 썼다. 오바마는 또 십대 시절 알코올, 마리화나, 코카인을 복용한 사실에 대해 "나는 누구인가 하는 질문을 머리 속에서 잊으려" 했던 것이라고 밝혔다. 2008년 대통령 후보 공개 토론(Civil Forum on the Presidency)에서 오바마는 자신의 고등학교 시절 마약에 손 댄 일이 자신의 "최대의 도덕적 과오"라고 말하였다.훈련된 MRC 모델 가져오기
import torch
from transformers import (
AutoConfig,
AutoModelForQuestionAnswering,
AutoTokenizer
)
model_name = 'sangrimlee/bert-base-multilingual-cased-korquad'
mrc_model = AutoModelForQuestionAnswering.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(
model_name,
use_fast=True
)
mrc_model = mrc_model.eval()- korQuAD를 학습된 모델을 불러온다. 실습에서는 이것을 직접 학습하기는 오래걸리기 때문
def get_answer_from_context(context, question, model, tokenizer):
encoded_dict = tokenizer.encode_plus(
question,
context,
truncation=True,
padding="max_length",
max_length=512,
)
non_padded_ids = encoded_dict["input_ids"][: encoded_dict["input_ids"].index(tokenizer.pad_token_id)]
full_text = tokenizer.decode(non_padded_ids)
inputs = {
'input_ids': torch.tensor([encoded_dict['input_ids']], dtype=torch.long),
'attention_mask': torch.tensor([encoded_dict['attention_mask']], dtype=torch.long),
'token_type_ids': torch.tensor([encoded_dict['token_type_ids']], dtype=torch.long)
}
outputs = model(**inputs)
start, end = torch.max(outputs.start_logits, axis=1).indices.item(), torch.max(outputs.end_logits, axis=1).indices.item()
answer = tokenizer.decode(encoded_dict['input_ids'][start:end+1])
return answercontext = corpus[doc_id.item()]
answer = get_answer_from_context(context, query, mrc_model, tokenizer)
print("{} {} {}".format('*'*20, 'Result','*'*20))
print("[Search query]\n", query, "\n")
print(f"[Relevant Doc ID(Top 1 passage)]: {doc_id.item()}")
pprint(corpus[doc_id.item()], compact=True)
print(f"[Answer Prediction from the model]: {answer}")******************** Result ********************
[Search query]
에이핑크의 리더는 누구인가
[Relevant Doc ID(Top 1 passage)]: 446
('오바마는 어린 시절에 대하여 "아버지는 내 주변 사람들과 전혀 다르게 생겼다는 점 - 아버지는 피치처럼 시꺼멓고, 어머니는 우유처럼 '
'하얗다 - 을 나는 개의치 않았다"라고 회상하였다. 그는 그의 투쟁을 자신의 다민족 혈통과 사회적 인식을 화해시키기 위한 어린 성년이라고 '
'말하였다. 오바마는 호놀룰루에서 지낸 자신의 성장기를 반추하며, "하와이에서 얻는 기회 - 상호 존중의 분위기 속에서 다양한 문화를 '
'경험한 것 - 는 내 세계관에서 중요한 부분이 되었으며, 내가 가장 아끼는 가치의 근간이 되었다"라고 썼다. 오바마는 또 십대 시절 '
'알코올, 마리화나, 코카인을 복용한 사실에 대해 "나는 누구인가 하는 질문을 머리 속에서 잊으려" 했던 것이라고 밝혔다. 2008년 '
'대통령 후보 공개 토론(Civil Forum on the Presidency)에서 오바마는 자신의 고등학교 시절 마약에 손 댄 일이 '
'자신의 "최대의 도덕적 과오"라고 말하였다.')
[Answer Prediction from the model]: [CLS]통합해서 ODQA 시스템 구축
def open_domain_qa(query, corpus, vectorizer, model, tokenizer, k=1):
# 1. Retrieve k relevant docs by usign sparse matrix
_, doc_id = get_relevant_doc(vectorizer, query, k=1)
context = corpus[doc_id.item()]
# 2. Predict answer from given doc by using MRC model
answer = get_answer_from_context(context, query, mrc_model, tokenizer)
print("{} {} {}".format('*'*20, 'Result','*'*20))
print("[Search query]\n", query, "\n")
print(f"[Relevant Doc ID(Top 1 passage)]: {doc_id.item()}")
pprint(corpus[doc_id.item()], compact=True)
print(f"[Answer Prediction from the model]: {answer}")query = input("Enter any question: ") # "미국의 대통령은 누구인가?"
open_domain_qa(query, corpus, vectorizer, mrc_model, tokenizer, k=1)Enter any question: 미국의 마지막 대통령은 누구인가
******************** Result ********************
[Search query]
미국의 마지막 대통령은 누구인가
[Relevant Doc ID(Top 1 passage)]: 7859
('리오넬 조스팽 전 프랑스 총리는 "김 대통령은 나에게 살아가야 할 힘, 살아가야 할 도덕적 스승이자 길잡이다"라고 극찬했다. 요하네스 '
'라우 전 독일 대통령은 "김 대통령에 대한 존경심이 독일이 한국의 금융위기 때 한국을 돕는 동기가 됐다"라고 밝혔다. 빌 클린턴 전 미국 '
'대통령은 한미 정상 백악관 기자회견에서 대북정책에 대해 "김 대통령은 지금 한반도의 정세를 본질적으로 변화시키는 전주곡을 연주하고 '
'있습니다. 김 대통령의 일관된 비전과 강인한 의지는 이를 성공작으로 만들것이라 믿습니다. 그렇게 되면 국방예산을 줄여 사회복지를 늘릴 수 '
'있겠지요"라고 평가했다. 클린턴 전 대통령이 김대중에게 "나에게 1년이라는 시간만 더 있었다면 한반도의 명운이 달라졌을 것"이라며 '
'아쉬워했다고 밝혔다. 한종우 시러큐스 대학교 교수는 "김 전 대통령은 민주화에 가장 큰 공헌을 하셨고, IMF 경제위기를 극복하시고, '
'북한과의 교류를 탄탄대로에 올려놓으셨다"라고 평가했다.')
[Answer Prediction from the model]: 빌 클린턴
깊게 배우고 신박하게 개발할래