ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS
ABSTRACT
버트와 같은 MLM pretraining 방법은 입력을 기존의 것과 다르게 하는데(=corrupt) 입력의 몇개의 토큰을 MASK로 바꾸고 모델이 MASK 토큰을 원래의 단어로 재구성하도록 학습하게 한다. MLM이 적용된 모델(=they)들은 downstream NLP task들에 대해 좋은 결과를 냈지만 효율적으로 큰 계산량을 처리하는 방법이 필요하다. (이에 대한) 대안으로서, 우리는 (replace 되어야 한다고 탐지한) 토큰을 교체하는, 더욱 효과적으로 sample을 뽑는 pre-training task를 제안한다. 입력에 마스킹을 적용하는 대신에 우리의 방법은 몇개의 토큰을 그럴듯한 토큰으로 교체하면서 입력을 바꾼다. 그리고 교체할 때에는 생성 구조를 사용한다. 그래서 모델이 mask된 토큰의 원래의 토큰을 예측하기 보다는 변환된 입력의 각각의 토큰들이 생성자(이하 generator)에 의해 교체되었는지를 예측하는 구분자(또는 판별자, 이하 discriminator)를 학습한다. 철저한 실험으로 기존 MLM보다 새로운 pre training task가 더욱 효과적임을 증명했다. 왜냐하면 이 task는 마스크된 토큰 일부만을 보는 것이 아닌 모든 토큰들에 대한 task이기 때문이다. 결과적으로 우리의 방법으로 학습한 문맥적 특징(=representation)은 똑같은 모델 크기와 데이터, 계산량으로 학습된 버트 모델을 능가했다. 이 장점은 특히 작은 모델에서 두드러진다. 예를 들어 우리는 30배는 더 많이 학습한 GPT의 GLUE NLU 벤치마크 점수를 단지 한 개의 GPU로 4일동안 학습한 모델로 압승했다. 우리의 방법은 모델의 크기에 있어서 RoBERTa나 XLNet과 비교해 1/4 이하의 계산량만을 가지고도 비슷한 성능을 냈으며 똑같은 계산량을 사용할 때는 압도했다.
1 INTRODUCTION
현재의 제일 좋은(roberta를 의미) 언어의 표현 학습 방법은 오토인코더의 노이즈를 제거하는 것을 학습하는 것이다.(여기서 노이즈는 masking이고 이 masking된 단어에 대해 original을 예측하는 것을 제거한다고 표현) 오토인코더는 라벨링 되지 않은 입력 시퀀스의 작은 일부분(보통 15%)을 고르고 이 토큰들 자체를 마스킹 하거나(버트 처럼) 이 토큰의 어텐션을 마스킹 했고(XLNet 처럼) 그러고 나서 원래의 input으로 돌려놓기 위해 학습을 했다. 양방향으로 특징을 학습하면서 기존의 언어 모델들보다 더 효과적이게 된 반면에 이러한 MLM 방법은 각 입력 당 겨우 15%의 토큰들만을 학습하는데에 많은 계산 비용을 쓰게 되었다.
대안책으로, 우리는 replaced toekn detection이라는 방법을 제안한다. 이는 모델이 그럴듯하지만 인의적으로 생성된 토큰과 실제 토큰을 구별하는 능력을 학습하게 되는 pre-training 방법이다. 마스킹 대신에 우리의 방법은 어떤 토큰을 (해당 토큰과 바꿔도 적절하다고) 제안된 분포에서 뽑은 샘플로 대체하는 것으로 입력을 변환하며, 이 분포는 일반적으로 소형 MLM의 output으로 구성되어 있다. 이러한 변환(=corruption) 과정은 버트에서의(비록 XLNet에서는 아니었지만) pre-train 당시에는 [MASK] 토큰을 볼 수 있지만 fine-tuning 당시에는 볼 수 없는 불일치 문제를 해결한다. 그러고 나서, 모든 토큰이 진짜인지 모조품인지를 구별하는 판별자가 되도록 신경망을 사전학습한다. 이와 다르게 MLM은 훼손된 토큰으로부터 원래의 토큰을 예측할 수 있는 생성자로 신경망을 사전학습한다. 판별자를 가지는 가장 큰 이점은 모델이 단지 일부의 마스킹된 토큰만을 학습하는 것이 아니라 계산을 좀 더 효과적으로 하면서 모든 입력된 토큰으로부터 학습을 한다는 점이다. 비록 우리의 방법이 GAN의 판별자를 학습시키는 것이 연상되기는 하지만, 우리의 방법은 (판별자와 생성자가) 적대적인 관계는 아니다. 그대신 변형된 토큰을 만드는 생성자를 최대우도로 학습한다. 왜냐하면 GAN을 텍스트에 적용하기란 어렵기 때문이다.
우리는 이 방법을 ELECTRA, Efficiently Learning an Encoder that Classifies Token Replacements Accurately 라고 부르기로 했다. 이전 연구에서는 이 방법을 트랜스포머의 문자 인코더를 downstream task에서 fine tune 할 수 있도록 pre train 하는 방법에 적용했다. 몇개의 ablations(모델에서 일부 특징을 제거해서 해당 특징이 모델의 성능에 얼마나 기여했는지 알아내는 실험)을 통해 우리는 모든 입력 토큰들을 사용해 학습하는 것이 ELECTRA가 BERT보다 훨씬 더 빠르게 학습할 수 있는 이유임을 보여줄 것이다. 또, ELECTRA가 완전히 학습되었을 때는 downstream task에 더 높은 정확도를 획득한다는 사실도 보여줄 것이다.
대부분의 현존하는 매우 큰 계산을 하는 사전학습 방법은 효과적일 필요가 있으며 모델의 비용이나 접근성에 대해 관심을 가질 필요가 있다. 많은 계산량을 가지고 pre train 하는 방법은 항상 downstream task의 정확도에 대해 더 좋은 성능을 보여줬기 때문에 우리는 사전학습 방법에 있어서 중요한 고려 사항으로 down stream task의 성능뿐만 아니라 계산의 효율성도 포함되어야 되어야 한다고 생각한다. 이러한 관점에서부터 우리는 ELECTRA 모델을 다양한 크기로 학습했고 모델의 필요 계산량과 비교한 downstream 성능을 평가했다. 특히 이러한 실험은 GLUE NLU와 SQuAD QA 벤치마크를 가지고 했다. ELECTRA는 충분히 MLM을 기반으로 사용되는 BERT나 XLNet을 모델을 똑같은 크기와 데이터셋, 계산량의 조건에서 능가했다. 예를 들어, 4일동안 1개의 GPU를 가지고 학습된 ELECTRA-Small 모델을 만들었다. 이것은 소형 버트 모델과 비교해 GLUE에서 5점 차이를 냈으며 심지어 이보다 매우 큰 GPT 모델도 넘어섰다. 우리의 방법은 크기가 큰 모델에서도 잘 적용되었는데, RoBERTa나 XLNet의 1/4의 계산량만을 가지고 학습을 했는데도 이들과 비교할 수 있는 성능을 냈으며 더 나아가 SQuAD 2.0과 GLUE에서 ALBERT보다 좋은 강한 모델이 되었다. 이를 종합해보면, 우리의 결과는 쉽지 않은 오답 샘플로부터 실제 데이터를 구별하는 판별자 태스크가, 현존하는 학습을 통한 언어 특징을 생성하는 방법들보다 계산적으로나 파라미터를 사용함에 있어 매우 효율적이라는 것을 보여준다.
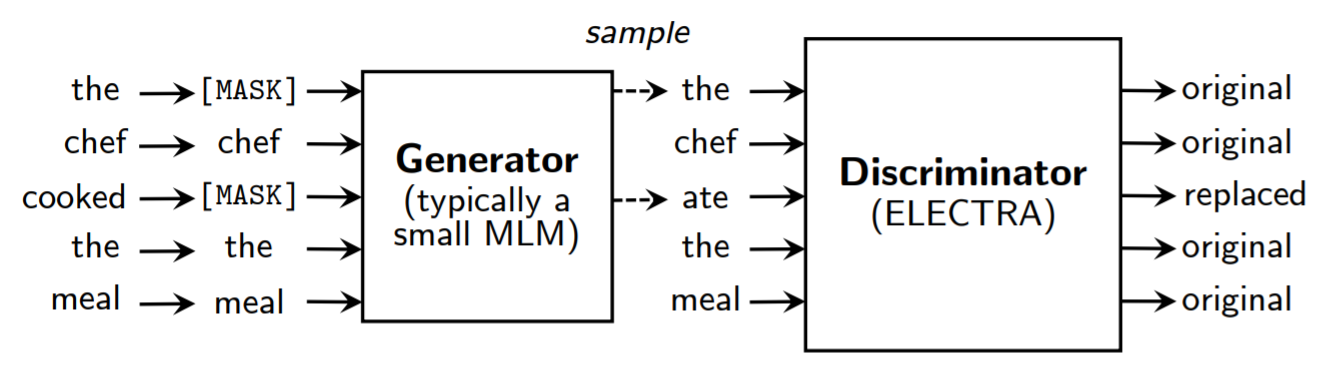
Figure 2
교체된 토큰 탐지에 대한 개요이다. 생성자는 토큰과 관련된 출력 분포를 생성할 수 있는 어떤 모델도 될 수 있지만 우리는 판별자와 공동으로 학습된 작은 MLM을 보통 사용했다. 비록 모델의 구조는 GAN과 비슷하지만 GAN을 텍스트에 적용하는 데 한계가 있다보니 적대적 구조를 사용하지 않고 최대 가능도를 사용해 생성자를 학습한다. 사전학습이 끝나면 우리는 생성자를 버리고 오로지 판별자만을 fine tuning해서 down stream에 사용한다.
2 METHOD
우선 교체된 토큰 탐지라는 사전 학습 TASK에 대해 이야기해보자. 전반적인 내용을 위해 그림 2를 보자. 우리는 3.2에서 소개할 방법을 위해 몇가지 모델리 개선을 제안하고 평가한다.
우리의 방법은 두 가지 신경망을 학습하는 것이다. 생성자 G와 판별자 D이다. 각각의 신경망은 주로 입력 토큰 x와 시퀀스의 문맥정보가 담긴 특징 벡터 h를 매핑하는 인코더로 구성되어 있다. 포지션 정보 t가 주어지면 (이 경우에는 t는 항상 [MASK] 를 가리키는 xt로만 사용된다) 생성자는 xt라는 특정 토큰값을 생성하고 softmax layer를 거쳐서 확률을 반환한다.

여기에서 e는 token embeddings를 의미한다. 위치정보 t가 주어지면 판별자는 token x_t가 real인지 예측한다. 이 때 "real" 이라는 것은 이 토큰이 생성자의 (real token 처럼 보이게 하는 그럴듯한 단어들의) 분포로부터 sigmoid output layer를 거쳐서 온 것이 아니라 실제 data에서 왔다는 것이다.
식 설명
- h는 쉽게 말해 attention을 의미한다. e는 각 단어가 버트 모델에 들어가기 전 임베딩을 의미한다. 제너레이터에서 각

식 설명
생성자는 MLM을 수행하도록 학습된다. 입력 x = [x1, ... , xn]가 주어진 MLM은 우선 몇개의 포지션(1부터 n까지의 정수)을 무작위로 고른다. 선택된 포지션에 있는 토큰은 [MASK] 토큰으로 대체된다. 이제부터 이에대한 수식 표기는 와 같다. 그러고나서 생성자는 마스킹된 토큰으로부터 원래의 토큰 자체를 예측하도록 학습한다. 판별자는 생성자 표본(=분포)으로 대체된 토큰으로부터 실제 데이터를 구별해야 하도록 학습한다. 더 자세하게는, 우리는 작업이 된 토큰 를 만든다. 이는 masking된 토큰을 생성자 표본으로 대체함으로써 생성된다. 그리고 판별자는 작업된 토큰 중 어떤 토큰이 실제 인지를 예측하도록 학습된다. 형식적으로 모델의 입력은 다음과 같이 구성되어있다.
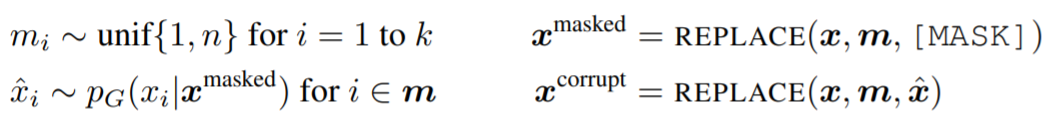
식 설명
그리고 로스 함수는 다음과 같다.

식 설명
