RoBERTa: A Robustly Optimized BERT Pretraining Approach
Abstract
언어 모델을 pretraining 하는 것은 엄청난 성능 향상을 이끌었지만 이에 대한 접근버비 다 다르기 때문에 각 모델들을 서로 비교하는 것이 어려웠다. 학습은 계산 비용이 비싸고 또, 각자 다른 크기의 개인 데이터셋으로 이루어지는데, 우리가 곧 보여줄거긴 하지만 이 때 하이퍼 파라미터를 잘 고르는 것이 결과에 매우 중요한 역할을 하게 된다. 많은 학습 데이터 크기와 하이퍼 파라미터를 통해 측정한 BERT를 소개하겠다. 우리는 버트가 학습이 많이 덜되었고 그래서 학습이 충분히 된 이후에는 현존하는 모델들의 성능 이상을 낼 수 있다. 우리 모델은 GLUE, RACE와 SQuAD에서 신기록을 냈다. 이 결과는 이전에 관과한 모델 구조(=design) 선택의 중요성을 시사하며 최근에 알려진 모델의 성능 개선이 어디서부터 오는것인지에 대한 궁금증을 자아낸다. 우리는 우리의 모델과 코드를 공개한다.
1 Introduction
ELMo나 GPT, BERT, XLM, XLNet같은 자가학습 방법은 중요한 성능 향상을 가져다 주었지만 (그들의 접근법에서는) 어떤 방법이 제일 (성능 향상에) 기여했는지 말하기란 쉽지않다. 학습은 계산 비용이 비싸고 tuning의 양을 감소시키고 주로 다양한 크기의 개인 데이터셋으로 학습이 되기 때문에 모델링의 발전으로 얻는 효과를 측정하기가 어려워진다.
(그래서) 우리는 하이퍼 파라미터와 학습 데이터의 크기의 영향을 평가할 수 있는 버트를 하나 구현했다. 우리는 버트가 학습이 덜 되었다는 것을 알게되었고 버트 모델을 학습하는 데 있어 좀 더 개선된 방법을 제안한다. 우리는 이를 RoBERTa(이하 로버타) 라고 부르기로 했고 이는 이전의 어떤 버트를 이용한 방법보다도 성능이 좋다. 우리가 수정한 것은 간단하다. (1) 모델을 기존보다 더 큰 배치사이즈와 더 큰 데이터 크기로 오래 학습했다. (2) NSP 방법을 제거했다. (3) 기존보다 더 긴 시퀀스에 대해 학습했다 (4) 시퀀스에 마스킹이 되는 방법을 학습 데이터에 맞게 동적으로 변경했다. 우리는 매우 큰 새로운 데이터셋 CC-News를 모았다. 이는, 기존에 사용하던 개인 데이터셋만큼 경쟁력 있으며 학습 데이터의 크기에 따른 효과를 조절하는 데는 더 좋다.
학습 데이터를 조절할 때 우리가 개선시킨 학습 과정이 기존의 버트에서 GLUE와 SQuAD에서 성능이 향상되었다. 더 많은 데이터를 더 오래 학습할 때 모델은 기존 점수 88.4에서 88.5가 되었다. 우리 모델은 GLUE의 tasks 9개 중 4개에서 신기록을 세웠다. MNLI, QNLI, RTE, STS-B가 바로 그것이다. 또, SQuAD와 RACE에서 최고 점수를 달성했다. 버트의 마스킹을 이용한 학습 방법은 AR LM들을 어렵게 하는(=perturbed) 학습방법들 만큼 우수했기 때문에 전반적으로 우리는 버트의 마스킹을 (사용하되) 재구성했다.
정리하면, 우리 연구의 공헌은 다음과 같다 (1) 버트의 구조 결정과 학습 전략의 중요성을 시사하고 down stream task에서 기존 것 보다 더 좋은 성능을 낼 수 있는 방법을 소개했다. (2) 우리는 소설 데이터 셋인 CC-NEWS를 사용했고 더 많은 데이터를 pre-training에 사용할 수록 down stream task에서 성능이 더 개선된다는 것을 확인했다. (3) 학습에서 개선이 있었던 것은 올바른 모델 구조를 선택함에 있어 MLM pre-training이 최근에 고안된 다른 방법들과 같이 우수하다는 점이다. 우리는 모델과 파이토치로 구현된 pre-training code, fine-tuning code를 공개한다.
2 Background
이번 장에서는 버트의 사전 학습 방법과 실험적으로 알아낸 학습 요소들에 대해 간단히 요약한다.
2.1 Setup
버트는 두 segments의 연결을 입력으로 받는다. 이 segment는 x1, ... ,xn과 y1, ... ,ym 으로 이루어져 있다. segments는 보통 한 개 이상의 문장으로 이루어져있다. 두 개의 segments는 버트로 들어가는 하나의 입력 시퀀스로 나타나게 되며 이는 스페셜 토큰에 의해 구별된다. 꼴은 [CLS] x1, ... , xn, [SEP], y1, ... , ym, [EOS] 이다. M과 N은 M+N < T 여야 한다. T는 시퀀스의 최대 길이를 나타낸다.
segment는 직역하면 부분이며 문장의 일부라는 뜻으로 생각하면 된다. 의역하면 sequence, 즉 문장으로 봐도 무방하며 두 개의 문장을 segment token으로 나누기 때문에 segment라는 표현을 사용했다.
모델은 라벨링 되지않은 대형 말뭉치로 제일 먼저 사전학습되며 이어서 end-task labeled data로 fine tuning 된다.
2.2 Architecture
버트는 현재 흔한(=ubiquitous) 트랜스포머 구조를 사용하고 있는데, 이에 대해 자세히 다루지는 않겠다. 우리는 L개의 레이어로 이루어진 트랜스포머 구조를 사용한다. 각각의 블락(=L개의 레이어)은 A개의 self-attention heads를 사용하며 H의 히든 차원을 사용한다.
2.3 Training Objectives
사전학습동안에는 버트는 두 가지 방법을 사용한다. 마스킹과 다음 문장 예측
Masked Language Model, MLM
입력 시퀀스로 들어온 토큰들을 무작위로 뽑아 [MASK] 라는 스페셜 토큰으로 대체한다. MLM은 masked token을 예측하는 대해 목적 함수로 cross-entropy loss를 사용한다. 버트는 균등하게 (마스크 토큰으로) 대체 가능한 15%의 입력 토큰들을 뽑는다. 이 (15%의) 토큰들 중에서 80%는 [MASK]로, 10%는 바뀌지 않으며, 10%는 임의로 사전에서 선택된 단어로 바뀐다.
원래 구현에서는 마스킹 작업이 학습 초기에 한번 수행되며 학습동안 유지된다. 그렇지만 실제로 데이터는 매번 동일한데, 우리의 모델에서는 매 학습 시기마다 마스크가 동일하지 않다.
epoch마다 동일한 데이터를 보는데, 로버타에서는 동일한 데이터에 대해 마스크의 위치가 매번 바뀐다는 점을 이야기하고 있다.
Next Sentence Prediction, NSP
NSP는 다음 문장이 이전 문장과 이어지는지에 대한 예측(이어진다, 안이어진다)을 위해 binary classification loss를 사용한다. 정답이 이어지는 문장이라면 말뭉치에서 이어지는 두 개의 문장을 가져오고 정답이 이어지지 않는 문장이라면 서로 다른 문서에서 두 개의 문장을 가져온다. 두 라벨은 동일한 비율로 구성된다.
NSP는 자연어 추론과 같은 downstream task에서 성능이 잘 나오게 하기 위해 설계되었다. 자연어 추론은 두 개의 문장의 관계애 대한 근거를 필요로 한다.
2.4 Optimization
버트는 Adam으로 최적화를 하며 b1 = 0.9, b2 = 0.999, e = 1e-6, L2 weight decay = 0.01의 파라미터를 사용한다. 학습률은 1만 warmup step으로 1e-4까지 상승하며 이후 선형적으로 감소한다. 버트는 모든 레이어에서 0.1의 dropout으로 학습하며 attention weights과 GELU 활성화 함수를 사용해서 학습한다. 모델은 1백만번의 가중치 갱신을 거치며 사전학습되는데 이 때의 배치는 256, 최대 시퀀스 길이는 512이다.
2.5 Data
버트는 BOOKCORPUS와 영어 위키피디아의 두 개의 셋으로 학습되는데 이 둘은 압축을 했는데도 16GB나 된다.
3 Experimental Setup
이번 장에서 버트의 여러 세팅에 대한 실험을 소개한다.
3.1 Implementation
우리는 버트(페이스북에서 처음 만든)를 재구현했다. 우리는 초반에 2장에서 소개한 버트의 원래 최적화 하이퍼 파라미터를 그대로 사용했다. 단, 최대 학습률, warmup steps는 각각의 setting마다 개별적으로 설정됐다. 우리는 추가적으로 학습이 Adam의 엡실론에 매우 민감하다는 것을 발견했고 이를 조절하는 것만으로도 더욱 좋은 성능을 얻거나 안정성이 향상된 결과를 얻었다. 비슷하게 배치 사이즈가 클수록 b2를 0.98로 설정하는 것이 안정성을 개선시키는데 좋다는 결과도 얻었다.
최대 시퀀스 길이를 512개로 설정하고 사전학습 했다. 그치만 기존 버트와 달리 짧은 문장들을 사용하지 않았고 90%의 길이가 줄어든 문장을 사용하지 않았다. (기존 버트에서는 학습 비용을 위해 90%의 문장을 128(또는 256)의 길이로 줄였다. 개선된 버트에서는 이러한 90%의 줄인 문장을 사용하지 않고 최대 길이 512로만 사용하겠다는 의미) 최대 길이의 시퀀스로만 학습했다. (100%의 가중치 갱신중에서 90%는 모두 512 길이의 최대 시퀀스 만으로 학습했다는 의미인 듯)
우리는 학습하는 데에 있어 DGX-1를 가지고 다중(=mixed) 정확도 계산을 했고 각각의 DGX-1은 8개의 32GB V100 GPU가 달려있다. 각각의 DGX-1은 Infiniband를 이용해 연결되어있다.
3.2 Data
버트 방식의 사전학습은 결정적으로 방대한 양의 텍스트에 의존하고 있다. "Cloze-driven Pretraining of Self-attention Networks / Baevski et al. (2019)" 논문은 데이터의 크기를 증가시킬수록 end-task 성능향상에 기여한다는 것을 증명했다. (이 증명 때문에) 버트보다 더 다양하고 더 많은 데이터셋을 학습하려는 시도가 이루어졌다. (하지만) 불행하게도 모든 추가 데이터들이 공개되지 않았고 우리의 연구를 위해 우리는 실험에 사용될 가능한 많은 데이터를 모으는 데에 초점을 두었다. 이 때 모은 데이터들을 서로 비교하며 전체적으로 양질의 데이터만을 모았다.
우리는 5개의 말뭉치들을 생각했다. 이들은 사이즈와 도메인이 다양하며 전체 용량이 비압축 기준 160GB를 넘었다. 우리는 다음 말뭉치들을 사용한다.
-
BOOKCORPUS + English WIKIPEDIA. 원래 버트에서 사용되던 16GB의 데이터이다.
-
CC-NEWS. CommonCrawl News dataset에서 영어 부분만을 모았다. 데이터는 6.3천만개의 기사가 있으며 2016년 9월부터 2019년 2월까지의 기사들이다. 필터링을 거친 기사들은 76GB.
-
OPENWEBTEXT. WebText 말뭉치를 재구성한 오픈 소스이며 GPT-2에서 언급되었다. Reddit에서 최소 3표의 추천을 받은 URL들에서 추출한 web content이다. 38GB
-
STORIES. "A Simple Method for Commonsense Reasoning / Trinh and Le
(2018)" 에서 소개된 데이터셋이다. CommonCrawl data의 일부를 사용했으며 Winograd schemas의 방식으로 필터링 했다.
Winograd schemas는 토론토 대학의 컴퓨터 과학자가 제안한 기계 지능 테스트이며 Tuning 테스트를 개선하기 위해 고안되어 매우 구체적인 구조의 문제를 사용하는 선다형 테스트이다.
3.3 Evaluation
이전 연구에서 우리는 다음과 같이 3개의 벤치마크를 통해 우리의 pre-trained model을 평가했다.
GLUE
GLUE 벤치마크는 NLU 구조를 평가하는 9개의 데이터셋으로 이루어져있다. 과제들은 단일 문장 분류 또는 한 쌍의 분류 문제로 구성되어 있다. GLUE 제작자는 학습 및 개발 데이터셋을 제공하며 제출 서버와 리더보드를 제공해 참가자들이 private test data로 자신의 모델을 평가하고 비교할 수 있도록 한다.
- hold out은 데이터를 train, valid, test로 나누는 방식을 의미한다.
4장에서 (GLUE 벤치마크에 대한)우리 모델의 성능을 확인하고자 single task 학습 데이터로 pretrain한 model을 finetuning하고 valid set에 대한 결과를 소개한다. (각각의 task에 대해 다른 학습 데이터를 사용하거나 앙상블 하지 않았다) 우리의 finetuning 과정은 버트의 기존 방법을 유지했다.
5장에서는 추가적으로 리더보드를 통해 얻은 결과를 소개한다. 이 결과는 몇개의 특정 task에 맞춰 (데이터가)수정된 결과이며 5.1에서 다룬다.
SQuAD
SQuAD는 지문과 질문으로 이루어진 문단을 제공한다. 문제에 대한 답을 내놓는 것이 목표이며 답은 지문에서 관련있는 부분을 추출하는 방법으로 얻는다. 우리는 SQuAD 1.1ver과 2.0ver의 두 가지 버전에 대해 측정했다. 1.1v에서는 지문에 항상 답이 존재했는데 2.0v에서는 몇개의 질문은 답이 아예 존재하지 않을 수도 있었기 때문에 더 어려웠다.
1.1v에서는 기존 버트와 동일한 범위 예측 방법을 채택했고 2.0v에서는 이 문제에 대한 답을 내놓을 수 있는지 없는지에 대해 분류(결과 또는 확률)와 부분 오차(특정 범위를 예측했을 때의 loss)를 합하는 방식으로 학습되는 이진 분류기를 추가했다.
RACE
RACE는 2.8만개의 지문과 대략 10만개의 질문으로 이루어진 대형 독해 데이터셋이다. 데이터셋은 중국에서 중학생이나 고등학생들이 보는 시험을 위에 만들어진 영어시험 문제 모음집이다. RACE에서는 각각의 지문이 여러개의 질문과 관련이 있다. 각각의 질문에서는 4개의 선택지로 부터 1개의 정답을 골라야 한다. RACE는 다른 독해 데이터셋보다 훨씬 더 길며 추론 질문이 매우 많다.
4 Training Procedure Analysis
이번 장에서는 버트를 성공적으로 사전학습하는데 어떤 것이 가장 중요한지 알아보고 측정해보자. 모델 구조는 BERT-base의 설정과 모두 동일하게 설정했다.
4.1 Static vs Dynammic Masking
2장에서 이야기한 바와 같이 버트는 무작위로 masking을 하고 이 토큰을 예측한다. 기존의 버트는 전처리 기간동안 한번 마스킹을 수행하며 이는 정적인 단일 마스킹의 결과를 낸다. 매 학습마다 동일한 마스크를 사용하지 않기 위해 학습 데이터를 10배로 증강하고 각각의 데이터를 10개의 서로다른 방식으로 40번의 에포크동안 학습시켰다. 따라서 학습에 사용되는 시퀀스들은 학습 기간동안 총 4번 사용되게된다.
우리는 동적 마스킹을 적용한 방법을 비교하기 위해 모델에 입력되는 시퀀스에 매번 적용했다. 이는 더 오래 학습하거나 더 많은 데이터셋을 학습할 때 중요하게 작용했다.
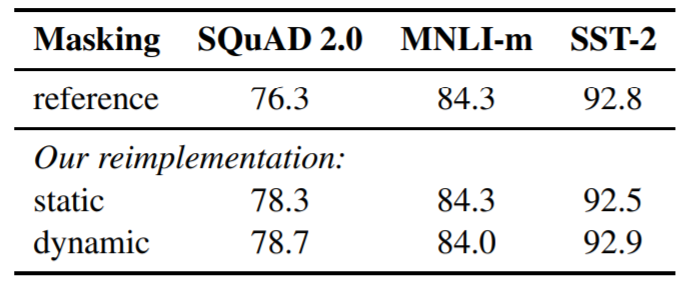
Table 1
버트에대한 static and dynamic masking의 비교 결과이다. SQuAD의 F1과 MNLI-m, SST-2의 정확도를 제시한다. 제시된 결과는 5번의 랜덤 초기화로 얻은 결과의 중간값이다. 결과는 Yang et al. (2019)를 참고했다.
Results
표 1에서 버트 베이스를 가지고 우리의 방식으로 재구성한 모델에 적용한 static과 dynamic masking을 비교한다. static masking에 경우 기존 버트 모델과 유사한 성능을 냈고 dynamic masking은 비슷하거나 살짝 더 좋은 성능을 냈다.
이러한 결과와 dynamic masking의 장점을 고려했을 때 우리는 dynamic masking을 나머지 실험에 사용하기로 했다.
4.2 Model Input Format and Next Sentence Prediction
기존 버트의 pretraining 과정에서 모델은 두 개의 연결된 segment를 입력받는다. 이 segment는 같은 문서에서 얻은 이어지는 문장인지, 서로 다른 문장에서 얻은 이어지는 문장인지에 대해 0.5의 동일한 비율로 구성된다. MLM을 추가하면서 모델은 NSP loss를 참고하여 입력받은(=observe) 시퀀스가 동일한 문서에서 구성되었는지 또는 다른 문서에서 구성되었는지에 대한 예측한다.
NSP loss는 원래 버트 모델에서는 중요한 요소로 판단되었다. 버트 논문에서는 NSP가 없으면 성능이 나빠지고 특히 QNLI, MNLI 그리고 SQuAD에서는 두드러지게 나빠지는 것을 관측했다. 그러나 몇몇 연구는 이에 대해 NSP가 필수적인 부분인지 의아해했다.
이런 불일치(누구는 맞다 누구는 틀리다)를 잘 이해하기 위해 학습 방식의 몇개의 대안책들을 실험해보았다.
-
SEGMENT-PAIR + NSP
원래 버트에서 사용하던 입력 포맷이다. 각각의 입력은 segment의 쌍으로 이루어져 있으며 각각의 segment는 여러개의 자연어 문장으로 이루어져있다. segment의 길이는 512 token 보다 작다. -
SENTENCE-PAIR + NSP
각각의 입력은 자연어 한 문장의 쌍으로 구성되어 있으며 문장쌍은 이어지거나 이어지지 않는 쌍이다. 이 입력들은 최대 길이 512보다 현저히 짧기 때문에 배치 사이즈를 증가시켰다. 그래서 전체 토큰 수는 SEGMENT-PAIR + NSP와 비슷하다. NSP Loss는 유지했다. -
FULL-SENTENCES
각각의 입력은 한 문서에서 연속적이거나 다른 문서에서 샘플링 된 꽉찬 문장이며, 꽉찼다는 의미는 입력이 길이가 적어도 512라는 뜻이다. 입력들은 문서의 끝을 넘길 수 있기 때문에 한 문서의 끝에 도달하게 되면 다음 문서에서 샘플링 해오고 이에 대한 추가적인 special token을 문서간에 추가해주었다. NSP Loss는 제거했다. -
DOC-SENTENCES
입력은 FULL-SENTENCES와 비슷하게 구성되어 있으나 무조건 한 문서에서만 샘플링한다. 그렇게 되면 끝쪽의 문장은 512보다 작을 수가 있는데 그래서 우리는 FULL-SENTENCES와 비슷한 수의 전체 토큰을 사용하기 위해 동적으로 배치 사이즈를 늘렸다. NSP Loss는 제거했다.
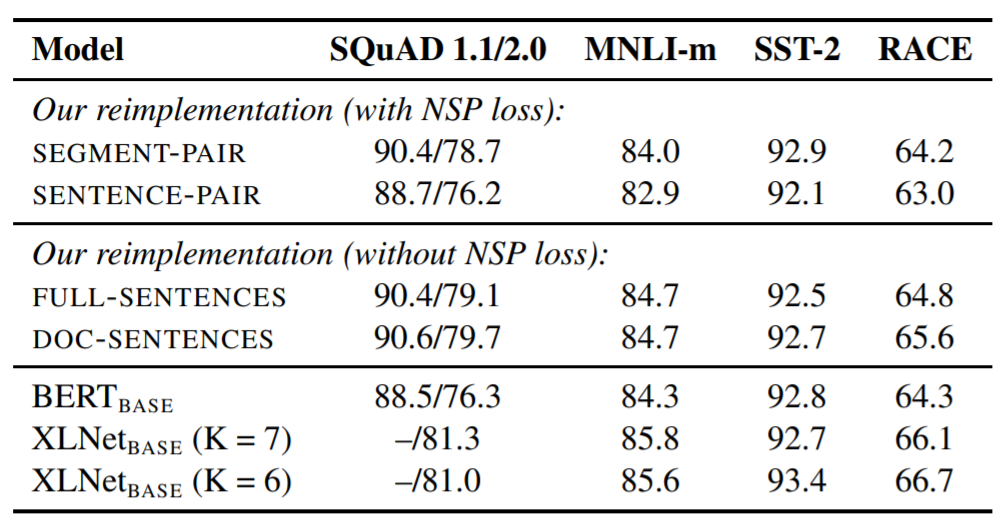
Table 2
BOOKCORPUS와 WIKIPEDIA로 pretrain한 base model에 대한 검증셋 결과이다. 모든 모델은 배치 사이즈 256의 1백만번의 step으로 학습했다. SQuAD는 F1을, 정확도는 MNLI-m과 SST-2 그리고 RACE의 지표로 사용했다. 실험된 결과는 5개의 랜덤 초기화 된 모델의 성능들에서의 중앙값이며 버트 베이스와 XLNet 베이스는
"Yang et al. (2019)." 에서 언급된 모델로 사용하였다.
Results
표 2에서는 4개의 다른 세팅에 대한 결과를 보여준다. 첫번째는 SEGMENT-PAIR 인풋 형식을 버트 논문에서 소개된 SENTENCE-PAIR 형식과 비교한다. 둘 다 NSP loss 함수는 유지하지만 후자는 단일 문장을 사용한다.
(여기서) 우리는 개별적인 문장을 사용하는 것은 downstream task이 성능을 해친다는 것을 발견했고 이에 대해 모델이 넓은 범위의 (각 단어들의) 관계성(=depencencies)을 파악할 수 없기 때문이라고 추측하고 있다.
다음으로는 NSP Loss가 없는 하나의 문서와 여러 개의 문서(=blocks of text, 여러 개가 될 수도 있는 문서)를 비교했다. 우리는 이 세팅이 기존의 버트 베이스의 결과를 압도했고(여기서의 성능 개선은 NSP loss를 제거해서가 아니라 input format을 변경시켜서) 기존 버트 연구에서 말한 것과 달리 NSP loss를 제거하는 것이 downstream task 성능을 살짝 증가시키거나 동일했다. 기존의 버트 구현에서 SEGMENT-PAIR 입력 형식은 유지하되, loss 부분을 제거하는 것은 가능하다.
마지막으로 우리는 DOC-SENTENCES에서 얻은 문장이 FULL-SENTENCES에서 얻는 문장보다 성능적으로 살짝 더 좋다는 것을 발견했다. 하지만 DOC-SENTENCES 입력 형식은 다양한 배치 사이즈로 구성되었기 때문에 실험에서 좀 더 비교가 편한 FULL-SENTENCES를 우리 연구에서 사용하였다.
4.3 Training with large batches
