이전글에서 설명한대로 QuickFind는 큰 문제에 대해서는 너무 느리다. 그래서 어떻게 더 잘할 수 있을까? 우리의 첫 번재 시도는 Quick-union이라고하는 대안이다.
Quick-union [lazy approach]
이 방식은 알고리즘 설계에서 (조급한(eager) 접근법과 대비되는) 게으른 접근법(lazy apparoach)이다. 이 방식은 우리가 정말 해야 할 때까지 일을 하지 않는 방식이다.

이 알고리즘은 같은 자료구조, 즉 N 개의 크기를 가진 배열을 사용하지만 이제는 다르게 해석을 붙이게 된다. 우리는 배열이 오른쪽에 그려져 있는, 숲(forest)이라고 불리는 트리(tree) 구조들의 집합을 표현한다고 생각할것이다. 배열에 들어있는 각각의 값은 그것이 포함되어 있는 트리에서의 부모 값을 의미한다. 예를들어서, 3의 부모는 4이고, 4의 부모는 9이다. 그래서 3번 인덱스의 값은 4이고 4번 인덱스의 값은 9가 된다. 이제 배열 안의 각 값은 루트로 연결된다. 그것이 트리에서의 루트(root)이다. 요소 하나로만 구성된 트리는 스스로만이 연결 컴포넌트이므로, 자기 자신을 가리킨다. 그래서 1은 스스로 1을 가리키는 것이다. 하지만 9 또한 스스로를 가리키는데, 9는 트리구조의 루트로, 2, 4 그리고 3을 포함한다. 그래서, 이런 자료구조로부터 우리는 각각의 요소들을 연결 컴포넌트를 대표하는 루트와 대응시켜 생각할 수 있다.
그래서 3의 루트는 따라올라가 보면 9이다. 이제 루트를 계산해낼 수 있으니 우리는 단지 '두 개의 요소가 같은 루트를 가져서 연결되는가'를 체크함으로써 find 연산을 구현할 수 있다. 이는 '두 요소가 같은 연결 컴포넌트에 포함되는가?'라고 말하는 것과 동치(equivalent)이다. 그래서 각 요소의 루트를 찾아가는 것은 좀 번거롭지만, Union 연산은 매우 쉽다. 다른 컴포넌트에 있는 두 다른 요소p, q가 포함되는 새로운 컴포넌트를 생성하는 Merge를 위해 우리가 해야할 것은 그냥 p의 루트의 id를 q의 루트의 id로 설정해주는 것이다. p의 트리가 q의 트리를 가리키도록 해보자.
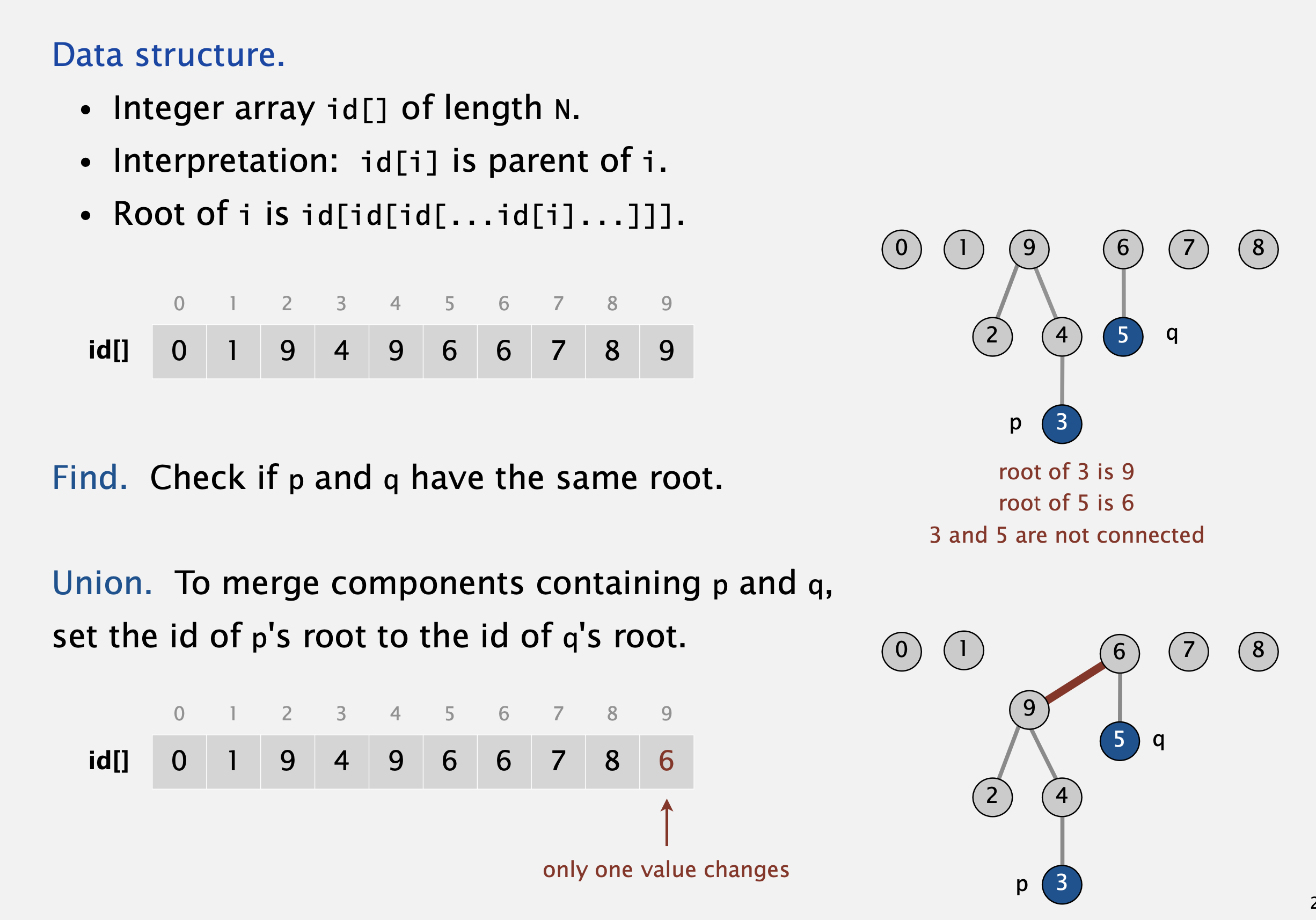
이 경우엔, 3과 5를 합치기 위해서 우리는 id[9]의 값을 6으로 바꾸어야 한다. 단지 배열의 값 하나를 바꿈으로써 3과 5를 포함하는 큰 2개의 연결 컴포넌트들을 서로 합칠 수 있다. 이것이 Quick-union 알고리즘이다. Quick이라고 하는 건 이 Union 연산이 오직 배열의 값 하나만을 바꾸기 때문이다. Find 연산은 조금 더 많은 일을 해야 한다. 그럼 첫 번째로 연산중 하나를 구현해 보자.
Quick-union 연산
그럼 우리는 다시 같은 방법으로 시작하지만 이제 배열의 값은 실제 요소들 각자가 그 스스로를 가리키는 노드 하나의 작은 트리 구조를 이룬다는 의미이다. 스스로는 각 트리 구조의 루트이기도 하다. 이제 (union(4, 3)이 주어졌으니) 우리가 4와 3을 같은 구성 컴포넌트에 넣어야 하면, 첫 번째 요소(4)를 포함하는 컴포넌트의 루트를 취해 그 두 번째 요소(3)을 포함하는 컴포넌트의 루트의 자식이 되게 하는 것이다.
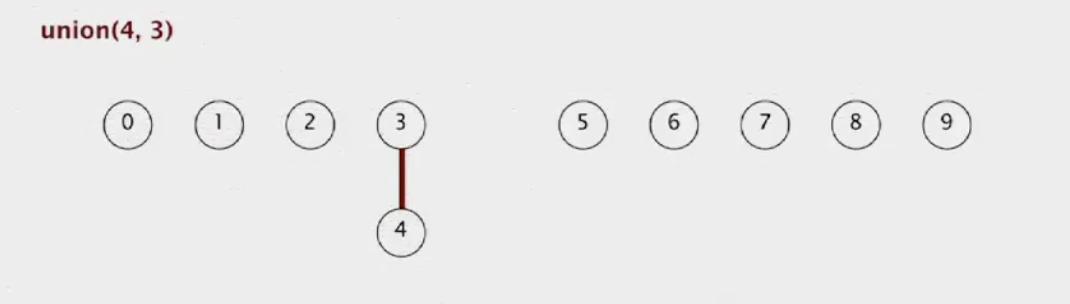
이 경우에 우리는 단지 3을 4의 부모로 만들면 된다. 이제 union(3, 8)이 주어졌다.
첫 번째 요소(3)를 두 번째 요소(8)를 포함하는 트리의 루트 자식으로 만든다. 이제 3, 4, 8은 같은 구성 요소이다. 
union(6, 5)연산은 6을 5밑으로 보낸다 9와 4의 union 연산을 하려면 4를 포함하고 있는 트리의 루트는 8임을 안 뒤, 9를 포함하는 트리의 투르가 9임을 알 수 있으므로, 우리는 9를 8의 자식으로 만든다. 2와 1에 대한 union 연산은 쉽다.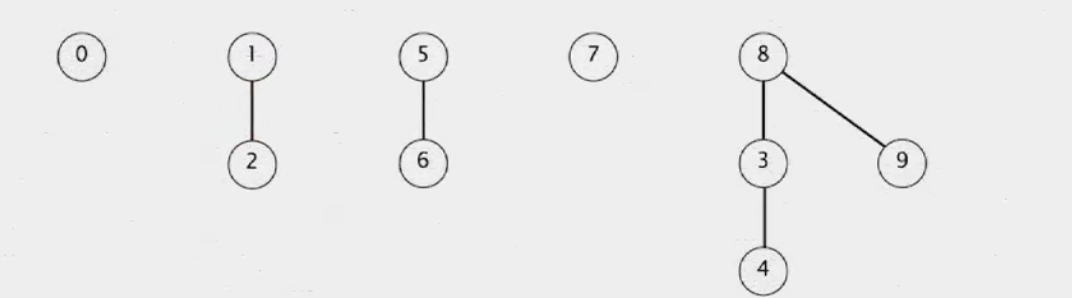
connected(8, 9)연산은 8과 9를 연결되어있는지 확인하려면, 그 두 요소가 같은 루트를 가지고 있는지 확인해야 한다. 그리고 그들은 8이라는 같은 루트를 가지고 있으므로 연결되어 있다.
5와 4의 연결성을 살펴보면, 4의 루트는 8이고, 5의 루트는 5이다. 다르다. 연결되어 있지 않음을 알 수 있다. union(5, 0)연산은 5를 0의 자식으로 보낸다.
union(7, 2)연산은 7을 2의 루트인 1의 자식으로 보낸다.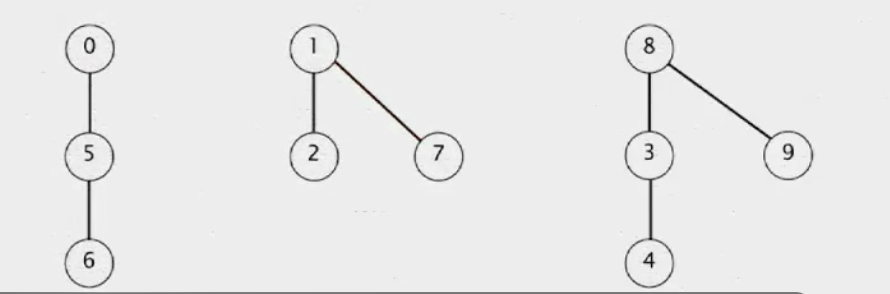
union(6, 1) 연산은 6의 루트는 0이고 1은 스스로가 루트이므로 0이 1의 자식이 된다. 각각의 union 연산은 단지 배열의 값 하나만을 바꾼다. 마지막으로 7과 3에 대한 union이다.
7의 루트는 1이고 3의 루트는 8이므로 1이 8의 자식이 된다.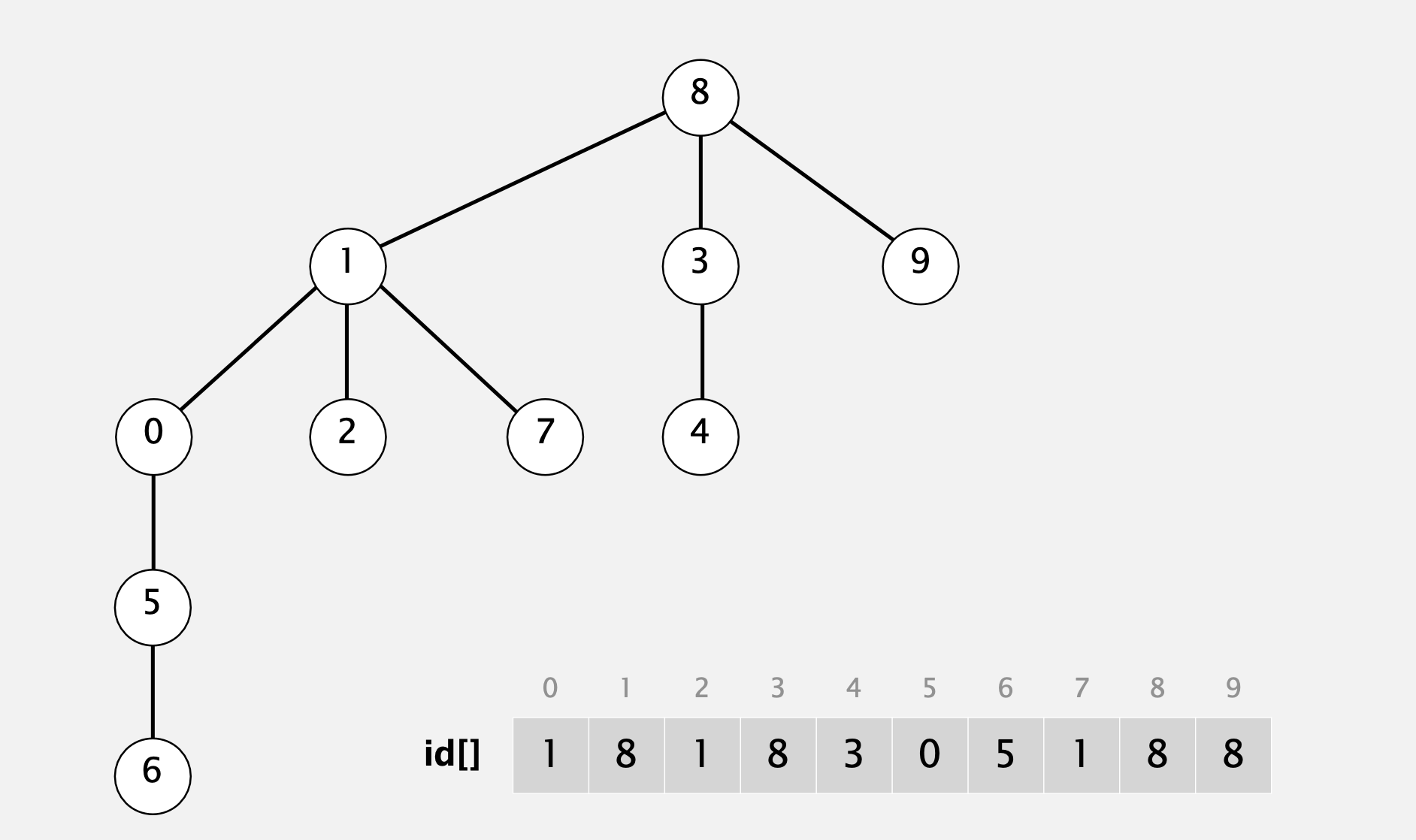
이제 우리는 모든 항목을 포함하는 하나의 연결 컴포넌트를 가진다.
Quick-union: Java implementation
이제 Quick-union을 구현한 코드를 살펴보자. 생성자는 앞의 버전과 똑같다.

우리는 배열을 만들고 각 항목들을 그 스스로의 루트로 설정해준다. 이제 우리는 해당 요소의 인덱스와 값이 같은 요소를 발견할 때 까지 부모의 포인터를 따라감으로써 루트를 찾는 과정을 구현한 private 메소드를 가진다. 인덱스 i와 값 id[i]가 같아질 때까지 단순히 i가 그 부모 id[i]를 가리키는 작업을 반복해 인덱스 i와 값 id[i]가 일치해질 때, i를 리턴한다.
어느 노드에서 시작하더라도 우리는 인덱스 i와 값 id[i]가 일치할 때까지 따라가면 루트에 도달한다. 이 메소드는 find 연산이나 connected 연산을 구현하기 위해 사용할 수 있는 private 메소드이다. connected 연산에선 단순히 p와 q의 루트를 찾아 비교하기만 하면 된다.
union 연산은 단순히 p와 q의 루트 i, j를 찾은 뒤 p의 루트 i의 id 값, 즉 p의 루트를 기록한 id[i]를 q의 루트 j로 변경하는 아이디어를 사용하면 된다. 사실상 Quick find 보다 코드가 적다. for 루프가 없으니까 말이다. 단지 하나의 while 루프만을 염려하면 된다.
하지만 여기 있는 Quick-union 코드는 동적 연결 문제를 푸는 빠르고 우아한 구현이다.
이제 우리는 이 코드가 커다란 문제에서도 효율적으로 동작할지를 살펴볼 것이다.
Quick-union is also too slow
불행히도 Quick-union은 더 빠르지만 또한 너무 느리기도 하다. Quick-find와는 다른 측면에서 너무 느린 것이다. 빠른 경우도 있지만, 너무 느린 경우도 있는 것이다. 그리고 Quick-union의 결점은 트리구조가 너무 길어질 수 있다는 점에서 온다. 무슨 뜻이냐면 find 연산의 실행 시간이 너무 오래 걸릴 수 있다는 것이다.

크고 마른 (long skinny) 트리를 생각해보자. 맨 아래의 요소에 대한 find 연산을 하기 위해 각 요소가 트리의 모든 요소를 계속 따라가야 할 수 있다. find 연산을 하기 위해 배열 접근을 하는 비용이 있을 때 많은 연산을 하게 되면 매우 느려질 수 있을 것이다.
이 문서는 해당 링크를 보고 공부한 내용을 정리한 글입니다.
coursera
