이전글까지 quick-union과 quick-find 알고리즘을 살펴봤다.
둘 다 구현은 쉽지만, 아주 큰 동적 연결성(dynamic connectivity) 문제를 해결할 순 없다.
그렇다면 우린 이걸 어떻게 향상시킬 수 있을까? 이에대해서 한번 살펴보도록 하자.
Improvement 1: weighting
아주 효과적인 개선법 중 하나는 소위 가중치 할당 기법(weighting)이다. 이 전글에서의 알고리즘들을 유심히 보다보면 이 방법이 떠올랐을 수도 있다.
아이디어는 바로 quick-union 알고리즘을 구현할 때 트리가 커지는 걸 회피하도록 구현하는 것이다. 만약 규모가 큰 트리와 작은 트리를 합쳐야 한다면, 큰 트리를 작은 트리 밑으로 넣으면 안된다. 안 그러면 아주 높이가 높은 트리가 만들어 질 테니까 말이다. 그렇게 하기 위한 비교적 간단한 방법이 있다.
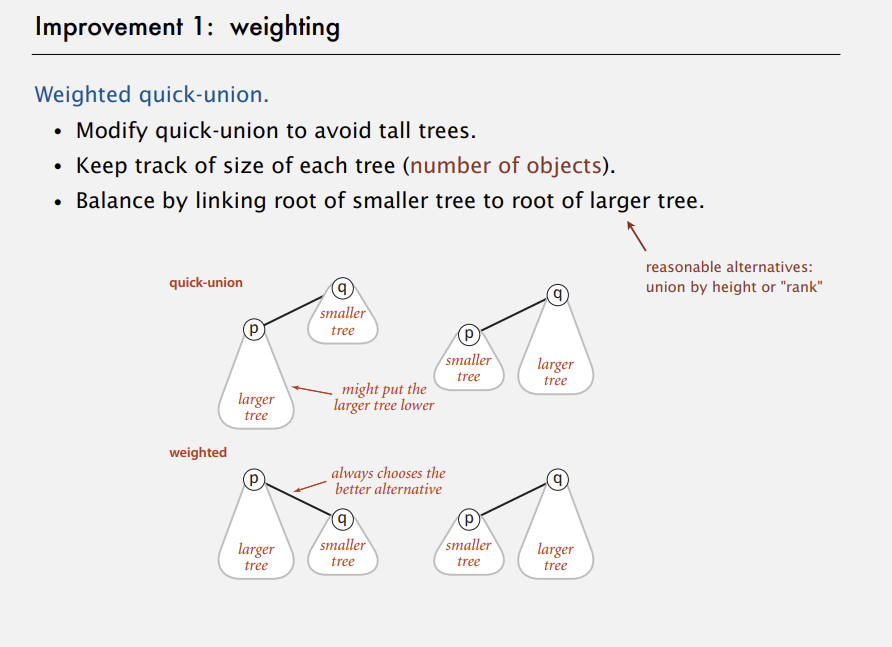
각 트리에 있는 요소의 수를 계속 기록해 트리의 규모를 파악하고, 큰 트리의 루트 아래에 작은 트리의 루트를 연결해서 균형을 유지하도록 하는 것이다.
그렇게 함으로써 키가 큰 트리가 작은 트리 아래로 가는 첫 번째 상황을 피할 수 있다. 가중치 알고리즘에서는 항상 작은 트리가 큰 트리의 아래로 들어가게 해야 한다. 어떻게 구현할 지 보도록 하자.
다시 일반적인 시작점에서 출발하자. 각 요소가 각자 트리를 이룬 상태이다.
union(4, 3) 아이템이 두개만 있으면 연결하면 되고, 이전처럼 동작한다.
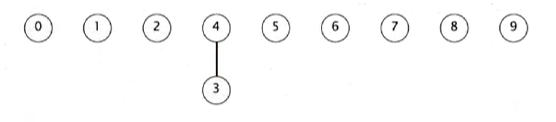
그런데 union(3, 8)이 주어지니 이제 8로 구성된 트리와 4와 3으로 구성된 트리를 합쳐야 하는데, 우리는 8을 자식으로 놓는다. 인자의 순서가 무엇이든 간에 8이 더 작은 트리여서 그렇다.
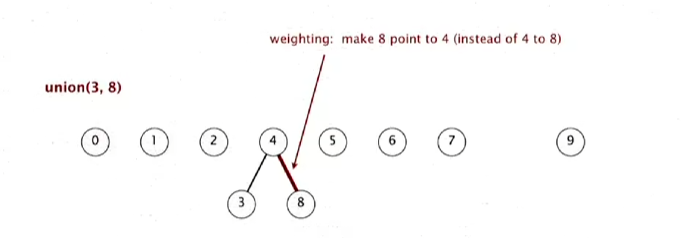
union(6, 5)는 어떤게 아래로 가든 별 문제가 없다.
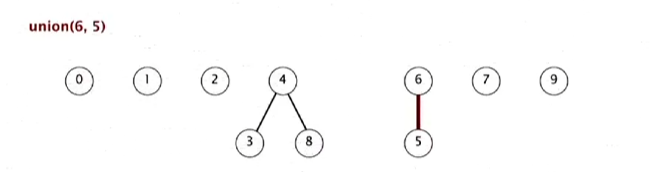
union(9, 4)는 9가 더 작고, 4가 속한 트리가 더 크다. 그래서 9가 4 아래로 간다.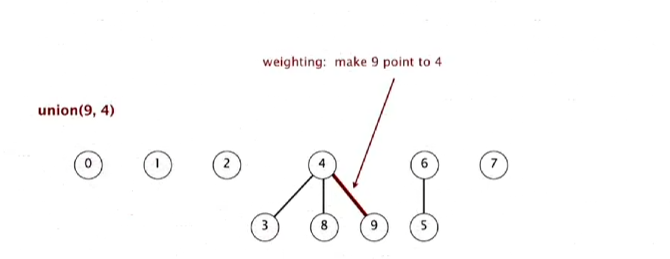
union(2, 1)은 별 것 없고, union(5, 0)에서, 5 측이 더 큰 트리이므로 0이 5가 있는 큰 트리의 루트 아래, 즉 6 아래로 간다.
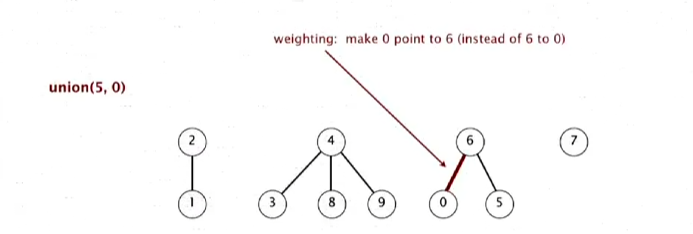
union(7, 2)는 2가 더 큰트리이므로 7이 2 밑으로 간다.
union(6, 1) 이건 같은 크기라 한 쪽이 다른 쪽으로 가면 된다.
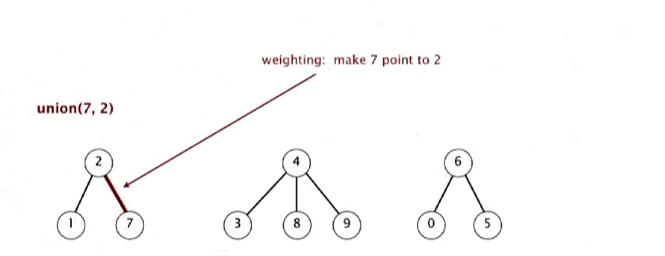
union(7, 3)은 3이 더 작은 측의 트리니 아래로 간다.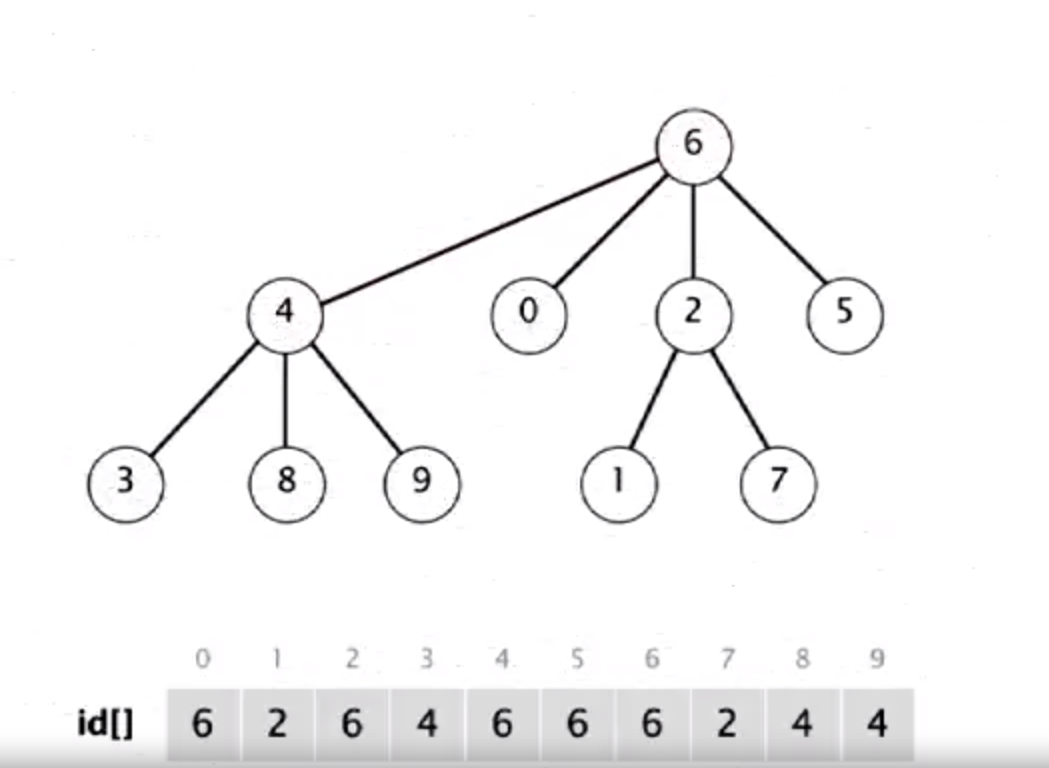
가중치 알고리즘에서는 항상 작은 트리가 아래로 가게 된다. 이제 다시 모든 요소들이 속한 하나의 트리를 구성했다. 그러나 이번엔 어떤 요소도 루트로부터 아주 멀리 떨어져 있지 않음을 보장할 수 있다. 조금 있다가 자세히 살펴보자.
다음 사진은 가중치에 따른 quick union 알고리즘의 동작을 보여준다.

완전히 같은 union 연산을 처리했는데, 가중치를 준 quick union은 언제나 작은 트리를 큰 트리 아래에 넣었다. 100 개의 원소와 88번의 union 연산을 한 것이고. 상단을 보면 큰 트리가 있는데, 이를 구성하는 작은 트리나 노드들이 루트로부터 꽤 떨어져 있다.
Weighted quick-union: Java implementaion
이제 Java 구현을 살펴보고, 그 뒤에 정량적인 정보에 대해 살펴보자.
앞서 사용한 같은 자료구조를 사용할 거지만, 추가적인 배열 sz[]를 필요로 한다. 이 새 배열은 각 요소 i에 대해서, i를 루트로 하여 만든 트리의 요소 수를 기록한다. 이 배열은 union 연산을 하는 과정에서 갱신 될 것이다. find 연산의 구현은 quick union과 동일하다. 주어진 두 요소의 루트가 같은지를 확인한다. union 연산의 구현에서는 앞에서 말한 크기를 확인하도록 코드를 변경할 것이다. 그리고, 경우를 나누어, 작은 트리의 루트가 큰 트리의 루트 아래에 가도록 연결한다. 배열 id[]에 저장된 링크 정보를 수정하고 나서, 배열sz[]또한 변경한다. 즉, id[i]가 j와 같도록 해서 i가 j의 자식이 되게 하면 j의 크기 sz[j]를 sz[i]만큼 키울 필요가 있다. 만약 j가 i의 자식이 되면 i의 크기 sz[i]를 j의 크기 sj[j]만큼 키워야한다.
그래서 quick union 구현의 전체 코드가 흰 색으로 표시되어 있다.

코드량은 별로 없지만, 훨씬 성능이 뛰어나다. 사실 수행시간을 수학적으로 분석해보면, 정의한 연산이 트리에 있는 노드들이 얼마나 멀리 떨어져 있는지에 비례해 시간이 걸림을 보일 수 있다. 그러나 트리 내의 어떤 노드 x라도 최대 깊이가 밑이 2인 로그 N이라는 걸 보여줄 수 있다. lg는 밑이 2인 로그를 가리키기로 하자. 그래서 N이 만약 1000 이라면 최대 높이는 10이 될 거고, N이 만약 10억이라면 30이 된다. 이 값은 N에 비해 아주 작은 숫자다.
그럼 이제 그 증명을 보자.
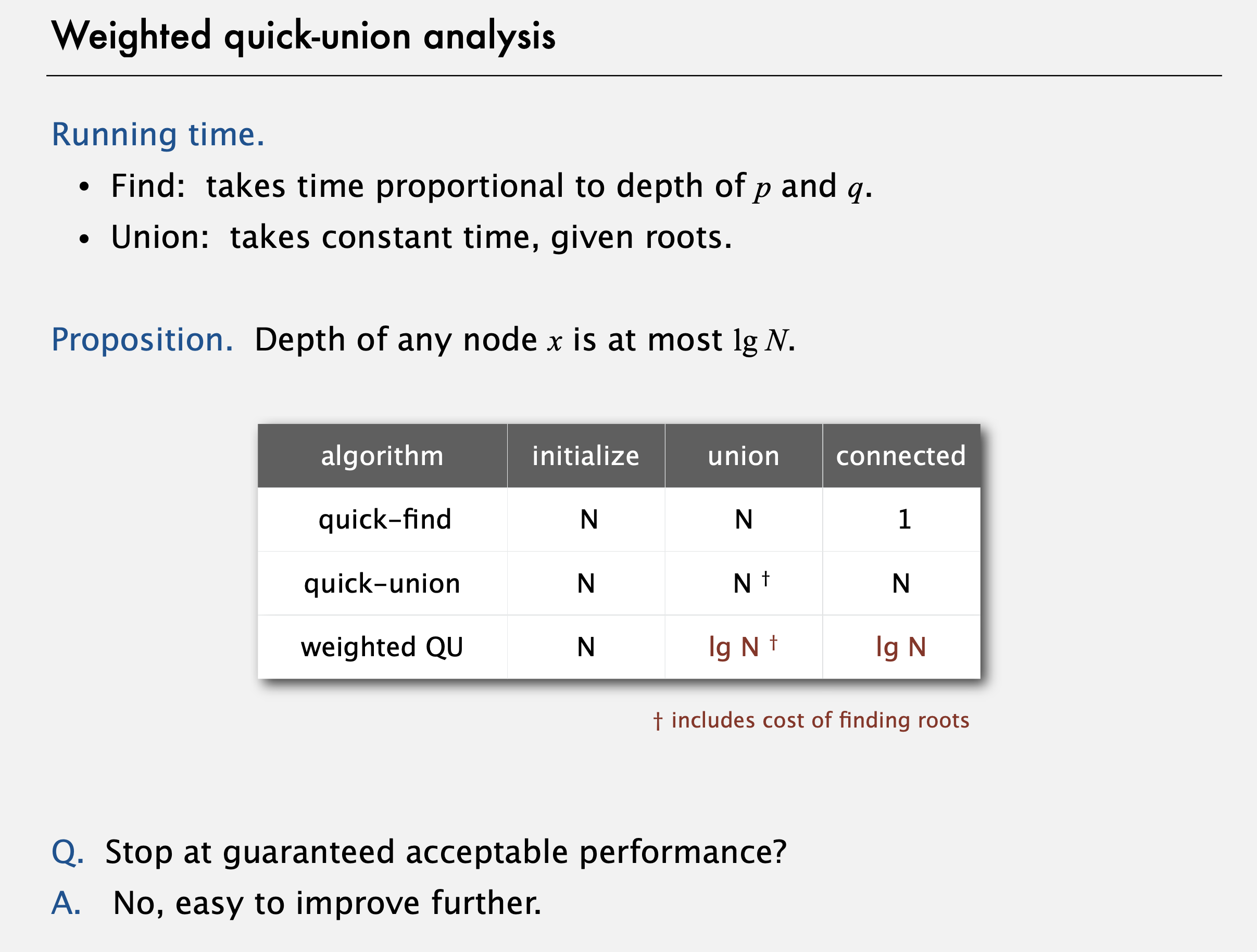
Weighted quick-union analysis
여기에선 이처럼 중요한 명제에 대해서는 다소 수학적인 증명을 할 것이다. 그럼 어떤 노드 x 의 깊이가 기껏해야 lg N이라는게 어째서 사실일까? 이걸 이해하는 데 있어 핵심은 어떤 노드의 깊이가 언제 증가하는지를 살펴보는 것이다. 언제 트리에서 더 아래로 내려갈까?

그럼에선 T1이라 표기된 트리가 다른 트리, 그림에선 T2에 합쳐지면, x의 깊이는 1만큼 증가한다. 그리고, 이와 같은 성질은 T2가 T1보다 크기 측면에서 크거나 같을때에만 성립한다. 즉, x의 깊이가 증가할 때 그 트리는 적어도 2배가 된다. 이게 핵심이다. x 가 속한 트리의 크기가 최대 lg N 배만큼 커지는 걸 의미하기 때문이다. 왜냐하면 1 부터 시작해 lg N 번만큼 두 배를 하면 N이니까, 이 트리엔 최대 N 개의 노드만 있게 된다. 이것이 어떤 노드 x 의 깊이도 최대 ln N 임을 보이는 증명의 그림이다. 증명한 명제는 알고리즘의 성능에 막대한 영향을 미친다. 초기화에서 매번 N에 비례해 시간이 걸리는 것이, 이젠 union 연산과 connected (또는 find) 연산은 ln N 에 비례한다. 이 알고리즘은 확장성이 있다. N이 백만에서 10억으로 증가하면 비용은 20 에서 30 이 되는데, 이건 꽤 수용할 만 하다.
지금까지 매우 쉬운 구현이였는데, 이제 그만할 수도 있지만 알고리즘 설계 과정을 살펴보았고, 얼마만큼의 성능인지도 보았으므로 더욱더 향상가능한지를 살펴보자. 사실 이 경우는 성능을 더욱더 향상시키는 게 매우 쉽다. 향상시키는 방법은 경로 압축(path compression) 이라 불리는 아이디어이다.
기존 방법에서는 우리가 주어진 노드가 속한 루트 p를 찾으려 할 때 노드 p에서 루트로의 경로에 있는 모든 노드를 건드리게 된다. 이 아이디어에서는 그러지 말고 각 노드가 루트를 가리키게 한다. 그렇게 하면 안 될 이유가 없다. p의 루트를 찾으려고 할 때, 루트를 찾은 뒤로 돌아가 경로에 있는 모든 노드가 루트를 가리키게 한다. 이건 추가적인 상수 시간이 걸릴 것이다. 일단 루트를 찾기 위해 경로를 거슬러 간 바 있다. 이제 트리를 평평하게 하기 위해 다시 거슬로 올라갈 것이다. 그렇게 안할 이유가 없기 때문이다.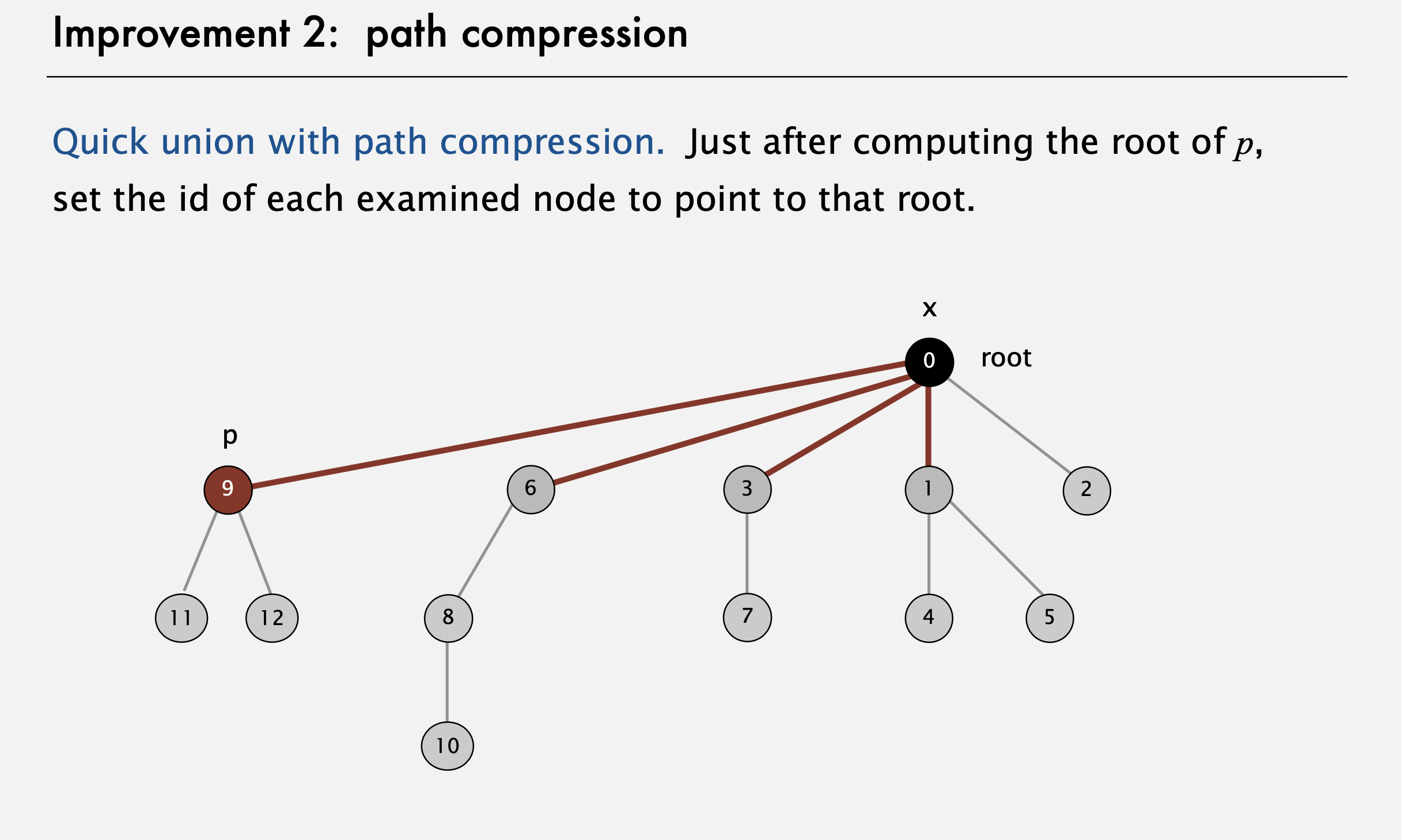
놀랍게도, 단 한줄의 코드로 트리를 평평하게 할 수 있다.
Path compression: Java Implementaion
사실, 코드 수를 줄이기 위해 간단히 변형해서 경로 상의 각 노드들이 원 트리 상에서의 할아버지 노드를 가리키게 하였다. 완전히 평평하게 만들지는 않아 꼭 좋은 건 아니지만 실용적 측면에서는 대략 좋을 것이다. 그래서 한 줄의 코드로 트리를 거의 평평하게 유지 할 수 있게 되었다.
Weighted quick-union with path compression: amortized analysis
이 알고리즘은 가중치 할당 기법이 논의된 뒤로 꽤 초기에 발견되었는데 글의 내용을 벗어나지만 분석하기에 꽤 매력적인 것으로 판명되었다.

예시를 통해 그 점을 보고, 이를 통해 이 간단한 알고리즘이 얼마나 복잡도 분석에서 흥미로운지 보자. 이 명제는 John E. Hopcroft (코넬대 교수)-Jeffrey D. Ullman (스탠퍼드대 교수)과 Robert E. Tarjan (프린스턴대 교수)에 의해 증명되었는데, N 개의 객체(=노드)가 있을 때, M 번의 union 연산과 find 연산이 어떤 순서로 실행되든 기껏해야 c(N+M lg N) 번 배열에 접근한다는 것이다.
여기서 lg N은 재밌는 함수인데, N이라는 숫자를 1로 바꾸기 위해 lg N을 취해야 하는 횟수를 나타내는 함수이다. 이 함수를 반복 로그 함수(iterate log function) 이라 부른다. 그리고 N=2^(65536)에 대한 반복 로그 함수값은 5이므로 실세계에선 그보다 작은 수로 생각하면 좋다. 즉 경로 압축이 적용된 가중치 기반 quick union의 수행시간은 실세계에서는 선형함수에 가깝다.
사실 이 결과는 Ackermann 함수 a(M,N)로 불리는 함수로 더 개선될 수 있다. 이 함수는 lg * 함수보다도 훨씬 천천히 증가한다. 이 함수의 또 다른 면은 M에 대한 느린 증가 함수에 N을 곱한 함수보다는 선형 함수, 즉 N에 비례하는 함수에 '근접한' 실행 시간을 가진 것처럼 동작한다. 그러면 선형 함수를 따르는 실행 시간을 가진 더 단순한 알고리즘이 있을까? 오랫동안 사람들이 찾고자 노력했지만, 이 경우에서는 실제로는 그러한 알고리즘이 없다는 것을 증명할 수 있다.
우리가 사용하는 알고리즘의 이면에는 아주 많은 이론이 깔려있다. 그래서 그 이론을 아는 것은 중요할 뿐만 아니라, 우리가 현실에서 어떤 알고리즘을 사용할 지 결정할 때에도 사용 가능하지만, 보다 더 나은 알고리즘을 찾기 위해 우리의 노력을 어디에 집중할 지를 결정할 때도 도움을 준다. Union find 문제에서는 선형 시간 알고리즘이 없다는 이 놀라운 사실은 최종적으로 Michael L. Fredman (럿거스대 교수)과 Michael E. Saks (럿거스대 교수)에 의해 증명되었다.
그러나 경로 압축이 적용된 가중치 기반의 quick union 은 현실에서 큰 문제에 적용하기에 충분하다.
Summary
이제 동적 연결성 문제를 푸는 알고리즘들에 대해 요약해 보자.
경로 압축이 적용된 가중치 기반의 quick union을 통해 다른 방법으로는 해결될 수 없었던 문제를 풀 수 있었다. 예를 들어 십억 개의 연산과 십억 개의 객체가 있었다면, 전글에서 말했듯이 30년이 걸렸을 지도 모른다.
우리는 이제 그걸 6초 내에 할 수 있다. 이로부터 가장 중요한 걸 알 수 있는데, 알고리즘 설계는 문제에 대한 해법을 가능케 한다는 것이다. 빠른 컴퓨터는 그리 많은 도움이 되지 않는다. 수백만 개의 슈퍼 컴퓨터를 사용할 수 있을 지라도 30년 대신 6년 정도 또는 한 두달이 걸리게 되겠지만 빠른 알고리즘을 이용하면 집에있는 컴퓨터로도 단지 수 초 내에 가능하다.
이 글은 해당 링크를 보고 공부한 내용을 바탕으로 정리한 글입니다.
코세라
