Unifying Vision, Text, and Layout for Universal Document Processing (CVPR 2023)
Paper Review
목록 보기
27/51

Introduction
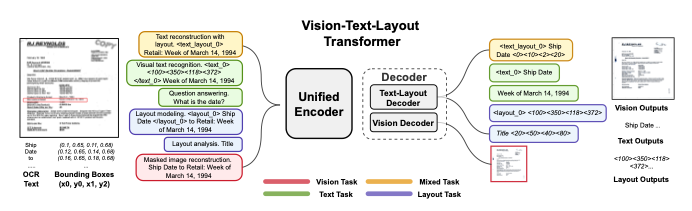
- Document AI는 vision information과 spatial layout을 동시에 포착해야 함
- 따라서 효율, 효과적인 information extraction은 제목 추출, 공문서 검사, 표 처리, 문서 분류 등 다양한 downstream task을 위해 선행 되어야 함
- text와 image 사이의 cross-modal interaction이 타 vision-language domain에 비해 중요
- 더 나아가 downstream task는 도메인과 패러다임에 대해 매우 다양
- DQA, Layout Detection, Classification, information extraction
- 총 두 가지 challenge
- How to utilize correlation image, text, layout modal and unify them to model
- 모델이 어떻게 효과적, 효율적으로 vision, text, layout을 다양한 domain에서 학습할 수 있는지
- 현재 document ai 모델은 다음과 같이 파편화
- vision network로 image를 encoding (ViT 등)
- text와 image를 multimodal encoder를 통해 encoding
- text, image를 jointly encoding (LayoutLMv3)
- document를 text-only input으로 간주
- 이와 같은 연구에서 layout modal은 단순히 2D positional embedding을 add하는 수준의 shallow
- Strong correlation between modalities inherent in document가 제대로 쓰여지지 않음
- 또한 task 마다 different head를 사용해야 하기에, 비 효율적이고 manual한 desing이 요구됨
- 우리의 Universal Document Processing (UDOP)는 Document AI의 foundation이 될 것
- vision, text, layout 등 different document를 통합
- Image와 text를 분리된 input으로 사용한 기존 연구와 달리 uniform layout-induced representation을 통해 한꺼번에 input으로 사용
- Input stage에서 text token이 위치한 image patch feature에 text embedding을 추가해주는 것
- 또한 uniform paradigm을 위해 동질적인 vocab을 만들어줌 (vision, text, layout)
- Vision-Text-Layout(VTL) Transformer를 제안
- Modal에 무관한 encoder이며, text-layout과 vision decoder로 구성
- UDOP가 jointly하게 vision, text, layout을 encoding, decoding하게 만들어 줌
- 기존 연구의 또 다른 문제는 objective가 single-modal에 특화 (MLM, contrastive learning)
- 우리는 총체적인 novel learning objective를 제안
- 마지막으로, 우리의 평등한 sequence-to-sequence generation 프레임워크는 major한 document supervised learning task를 통합시킴
- Document layout analysis, information extraction, document classification, document Q&A, Table QA/NLI
- 반면 pretraining 시에는 제한된 unlabled data를 통해 학습됨
- modeling 유연성을 위해 양질의 labeled data는 사용하지 않음
- ablation study를 통해 pretraining 만으로 이전 모델을 넘어섬과 동시에, supervise를 추가할 시 더욱 성능 향상하는 것을 보임
- Summary
- 문서 AI에서의 총 3가지 모달을 통합한 representation, modeling
- sequence-to-sequence generation framework를 통해 여러 문서 task를 통합
- novel한 self-supervised objective와 supervised dataset을 통합
- text, vision, layout을 함께 처리하고 생성하는 첫 번째 문서 AI
- 8개 task에서 SOTA
Universal Document Processing
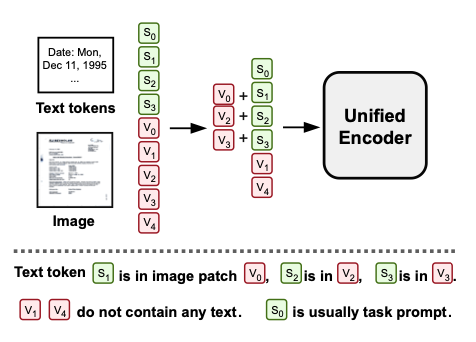
- OCR을 사용해 text와 bounding box를 추출
- (이미지, 텍스트, bounding box)의 triple 형태로 저장
A Unified Vision, Text, and Layout Encoder
- vision, text, layout modal을 unified한 transformer encoder
- text embedding이 image에 포함되어 있음
- text와 image pixel이 correspondence
- 이를 처리하기 위한 Vision-Text-Layout Transformer architecture를 제안
- patch로 분리 후, D 차원으로 encoding, 이후 이를 sequence of vector로 저장
- text token 또한 D 차원으로 embedding
Layout-Induced Vision-Text Embedding

- text boundig box의 center가 포함된 image patch의 경우 1
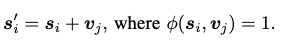
- Indicator function이 1인 경우, image patch encoding에 해당하는 text embedding을 더함
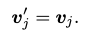
-
어떠한 text token도 포함되지 않은 경우, 이미지 patch encoding은 그 자체를 유지
-
Layout Modal을 unify하기 위해, 우리는 최근 연구에서 사용된 layout modal을 discrete화
- Bounding box 좌표를 layout token으로 변환
-
이외에도 TILT에서 사용한 2D relative attention bias를 사용
- 1D positional embedding은 이미 충분히 반영했다고 판단하여, 제외
Vision-Text Layout Decoder
- VTL decoder는 vision, text, layout을 한꺼번에 generate
- vision decoding은 MAE를 사용하여 image pixel, text, layout을 한번에 생성
Unified Generative Pretraining
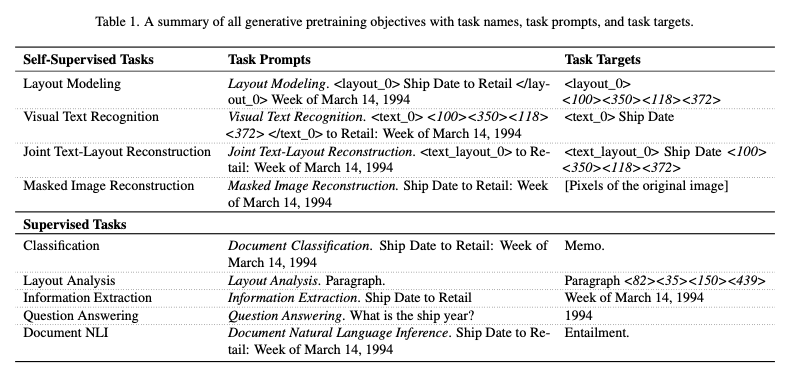
- 다양한 training objective와 dataset을 통합하기 위해, universal generative task format with prompt를 제안
- self-supervised하게 UDOP를 pretrain
Self-Supervised Pretraining Tasks
- Various Innovatie Self-Supervised Learning Objectives
- unlabeled document는 OCR output과 image를 보유
Joint Text-Layout Reconstruction

- missing text와 그 layout을 predict하는 task
- <text_layout_n>은 text-layout sentinel token
- MLM 국룰 15% masking
Layout Modeling

- Joint Reconstruction과 다른 sentinel token을 사용
- text를 제외하고 layout만 생성하기 때문
Visual Text Recognition

- model이 vision-text correspondence를 통해 joint vision-text embedding을 학습할 수 있게 하기 위함
- making 비율 50%
Masked Image Reconstruction with Text and Layout
- image, text, layout을 reconstruct
- MAE objective 사용
- Some patch를 masking해 encoding하여 masked patch를 decoding
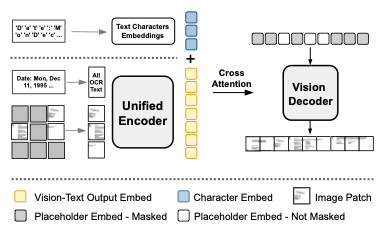
Cross-Attention with Character Embeddings
- 대부분의 textual content는 alphabet, number, 문장부호로 구성
- 문자 level의 composition은 vision generation에 도움이 될 것
- vision decoder는 cross-attention을 가짐 (character embedding and unified encoder)
- 이 문자 embedding은 학습 가능
- 선형복잡도를 유지하며 image generation quality를 상승시킬 수 있음
Image Decoding
- Unified encoder output은 direct하게 feed할 수 없음
- joint vision-text embedding이 non-masked image patch만 포함하고 있으며 image patch가 text token과 혼재되어 있기 때문
- learnable placeholder embedding을 통해 해결 하려함
Supervised Pretraining Tasks
- Document Classification, Layout Analysis, Information Extraction, Question Answering, Document Natural Language Inference 등의 task로 진행
Analysis
Visualization Analysis
Masked Image Reconstruction

- masking이 광범위함에도 높은 퀄리티의 reconstruction 성공
Document Generation & Editing

- 높은 해상도, 일관적인 글자의 폰트 크기 양식을 reconstruct
Layout Customization

- Layout 기반으로 customizing이 자유로워 짐
