
도입
기존 추천 시스템은 두 가지 전략으로 나뉨
-
Content Based
각 유저 혹은 아이템의 특징을 통해 매칭
데이터 수집 및 구성하는 과정 필요 -
Collaborative Filtering
유저-아이템 매트릭스를 통해 유사성을 기반으로 매칭
Cold-start problem에 취약
입력 데이터 또한 두 가지로 나뉨
-
Explicit Feedback
유저가 직접 표현한 선호도 (별점 등) -
Implicit Feedback
유저 행동 기반 관측치 (구매 내역, 검색 히스토리 등)
Explicit data는 수집이 어렵기에, Implicit Feedback을 활용한 연구에 집중할 필요가 있음
Implicit Feedback
- No negative feedback
선호를 암시할 수 있지만, 비선호를 나타내기는 어려움 - Inherently noise
유저 로그만으로는 정확한 동기와 선호도를 찾기 힘듬 (Noise가 내재되어 있음) - Confidence
반복된 행동은 유저의 선호를 나타낼 수 있으나, 단발적 행동은 다양한 이유로 발생됨 (Implicit feedback은 preference가 아닌, confidence를 의미) - Appropriate measures
적절한 평가 척도에 대한 고민이 요구
과거 연구
Neighborhood Model
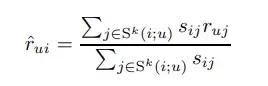
- rui
유저 u의 i번째 item에 대한 평가 - Sij
아이템 i와 j의 유사도 - Sk(i;u)
아이템 i와 유사한 아이템 k개의 유저 u의 선호도
Implicit feedback은 scale이 모두 다르기에 유사도 계산이 힘듬
즉 적용하기 힘든 방법론
Latent Factor Model
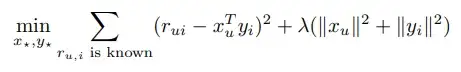
유저 아이템 매트릭스를 두 잠재 벡터의 행렬곱으로 표현할 수 있다는 가정 하에 잠재 벡터를 예측하는 모델
본 논문은 Implicit feedback에 적용할 수 있는 Latent factor model을 제안
본문
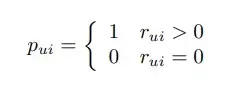
선호도를 나타내는 변수(preference)를 유저 u가 아이템 i에 행동을 했으면 1, 아니면 0으로 정의
다만 이 변수만으로는 관측치에 대한 설명이 부족
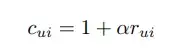
따라서 기존 변수가 커질수록 강한 선호의 지표로 증가함수인 confidence 변수를 추가 (알파는 사용자가 정의하는 값)
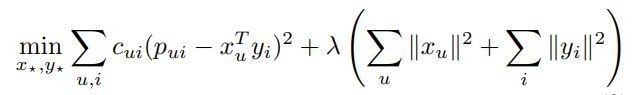
이후 다음과 같은 Loss function을 최소화 하는 user/item latent factor를 찾는 것이 본 모델의 목적
SGD, ALS 방식 둘다 가능하나 본 논문에서는 ALS 방법이 효율적이라고 강조
- 두 개의 행렬 X와 Y의 내적으로 이루어지기에 SGD는 Non-convex
- M명의 user, N개의 item으로도 MxN matrix는 매우 커지고 따라서 SGD의 최적값 탐색을 방해 (Explicit data일 경우와 대표적인 차이)
ALS는 X를 학습할 때 Y를 상수 취급하고, Y를 학습할 때는 거꾸로 적용하는 것
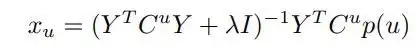
ALS를 진행하였을 때 Loss fnc을 X로 미분하면 다음과 같은 식이 유도
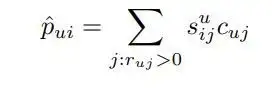
따라서 preference는 u 번째 x vector와 i 번째 y vector의 내적이기에, 다음과 같이 선호도를 신뢰도와 유사도로 표현할 수 있음
즉 설명가능한 추천을 가능케 함
실험
TV 프로그램별 시청시간 데이터를 4주간 학습하여 마지막 1주의 시청기록을 테스트
전처리
-
각 test data의 item이 train에도 존재한다면 제거
지속적으로 시청하는 program을 추천하는 것은 의미가 없음 -
test data에서 0.5시간 이하로 본 데이터는 0으로 처리
즉 유저가 좋아하지 않는다고 판단 -
연속적인 program들은 down-weighting
틀어놓고 가만히 있는 경우라고 판단
평가 함수
- 각 User별로 가장 덜 추천된 program부터 많이 추천된program이 sorting된 list를 산출
주의
Implicit data는 비선호를 나타낼 수 없기에 추천에 대한 반응을 알 수 없음, 즉 precision이 아닌 recall 기반 지표를 사용해야 함
Precision = TP / TP + FP 인데, 예측이 실패한(FP) 값을 구할 수 없기 때문
- Implicit feedback 이기에 recall 기반 rank_bar를 제안
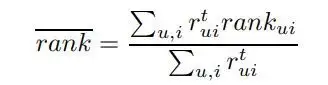
rank_ui가 0%이면 item i에 대해 가장 추천된 item을 의미하고, 50%이면 중간 정도로 추천 됨을 의미
낮은 rank_bar 일수록 우수한 모델
당시 다른 모델과 비교하였을때 본 논문의 모델이 가장 좋은 성능을 보임
결론
본 논문에서 제안한 모델은 Implicit dataset에서 당시 기준 높은 성능을 얻음
나의 감상
- 수식을 손으로 유도해보고 싶은데 꽤나 어려움
개강하면 교수님들께 여쭈어 볼 예정 - 실제로 이 모델을 사용하려면 평가 함수 선택과 변수 재정의 작업에 심혈을 기울여야 할 듯
